1. Introduction
Direction of arrival (DOA) estimation is a topic that has received a great deal of attention in the last several decades. It arises in many practical scenarios, such as radar, sonar, and communications [
1,
2,
3,
4]. For example, in radar and sonar systems, objects including airplanes, birds, missiles, submarines, and fish torpedoes can be tracked by estimating their DOAs. In communication systems, the DOAs of the sources can be used to improve the communication quality.
Higher-order cumulants (HOCs)-based DOA estimation methods have been developed for non-Gaussian sources [
1,
5,
6,
7,
8], mainly to overcome the limitations of second-order statistics-based DOA estimation methods such as MUltiple SIgnal Classification(MUSIC) [
9] and Estimation of Signal Parameters via Rotational Invariance Techniques (ESPRIT) [
10]. Their limitations include identifiable number of sources, colored Gaussian noise, and modeling errors. The famous 4-MUSIC method [
5] uses the fourth-order cumulants (FOCs) to form a MUSIC-like method. Then, the
-MUSIC [
6] and rectangular
-MUSIC [
7] methods extend 4-MUSIC by utilizing
th-order cumulants. The rectangular
-MUSIC method achieves a trade-off between performance and maximal identifiable number of sources compared with the 2
q-MUSIC method. To further increase the degrees of freedom (DOFs) of the FOCs-based methods, a kind of sparse linear array named multiple level nested array and the corresponding spatial smoothing MUSIC (SS-MUSIC) method were developed, which make the DOFs increase from
to
[
8], where
M is the number of sensors in the array. However, HOCs-based methods always suffer from performance degradation when snapshots are limited, mainly because accurate estimations of HOCs require a large number of snapshots.
Recently, a series of covariance vector-based DOA methods were proposed [
11,
12,
13] which built a single measurement vector (SMV) model by covariance vector and were solved by sparse methods such as L1-norm-based methods [
14] and sparse Bayesian learning (SBL) [
15]. Consequently, these methods always perform better than other covariance-based DOA methods such as MUSIC when snapshots are limited, mainly because estimation errors of covariance are utilized to build their sparse models. Moreover, the DOFs of these methods increase to
, which is more than MUSIC. Analogously, the FOCs vector-based L1-norm method (4-L1) is applied in [
16,
17,
18]. Compared with FOCs vector-based SS-MUSIC (4-SS-MUSIC) in [
8], the 4-L1 method can utilize all the virtual sensors in the fourth-order difference co-array (FODCA) [
8], which may give a better performance than 4-SS-MUSIC. Moreover, the 4-L1 method can be applied to any array, while 4-SS-MUSIC only suits for linear arrays. Nonetheless, the 4-L1 method is inconvenient to use in practice, since the parameter of allowable error bound is difficult to choose, and the solution of 4-L1 is sensitive to it. The allowable error bound usually needs to be chosen manually through trial-and-error for each scenario, as in [
16,
17,
18]. Furthermore, it has been demonstrated both theoretically and empirically that the SBL technique induces less structural error (biased global minimum) and convergence error (failure in achieving the global minimum) than the L1 methods [
11,
19,
20,
21]. On the other hand, an advanced denoising procedure of the FOCs vector may further promote the performance of FOCs vector-based DOA estimation methods. An analogous procedure can be found in covariance vector-based DOA methods in [
22].
In this paper, we establish a novel denoised SMV model by FOCs vector, and solve it by an off-grid sparse Bayesian inference (OGSBI) method [
21]. By utilizing the concept of the fourth-order difference co-array, the advanced denoising or dimension reduction procedure of FOCs vector is presented for any geometry. The estimation errors of FOCs are integrated in the proposed SMV model, and are approximately estimated in a simple way. A necessary condition of our method regarding the number of identifiable sources is presented such that in order to uniquely identify all sources, the number of sources
K must fulfill
. The proposed method suits for any geometry, does not require prior knowledge of the number of sources, has maximum identifiability
, and is insensitive to associated parameters. The off-grid parameter estimation in our method promotes superior performance in overdetermined cases when the number of snapshots is large and signal–noise-ratio (SNR) is high, and also ensures good performance when choosing a relatively coarse grid. Numerical simulations illustrate the superior performance of the proposed method.
2. Data Model
One-dimensional DOA estimation is discussed in this paper. Consider an array with any geometry which consists of
M identical, omnidirectional, unpolarized and isotropic sensors. The sensor locations
are measured by
, and collected by the vector set
, where
is expressed in three dimensions for
,
is the transpose operator,
is the wavelength, and
denotes the set of real numbers. The cardinality of
is denoted by
, and
. Each sensor receives the contribution of
K zero-mean statistically independent stationary narrowband non-Gaussian sources. We denote by
,
and
the observed signals of the sensors, the source signals, and the noises of the observed signals at the
tth snapshot, respectively, where
. The observed signals are modeled as:
where
denotes the array manifold matrix,
is the steering vector for
,
is an imaginary number,
,
denotes the azimuth angle of the
kth source, and
is the set of complex numbers. The noises are assumed to be statistically independent zero-mean white Gaussian and independent from each source.
Build the FOCs vector
, where the
ith entry is
with
,
denotes the cumulant operator,
denotes complex conjugate, and the indexes
and
are integers satisfying
and
, respectively. Due to model (
1), the above assumptions of the sources and noises, and the properties of the cumulants [
23,
24], we can obtain
where
with
,
is the
th element of
, and
. Then, we have
where
,
,
, and ⊗ denotes the Kronecker product.
3. The Proposed Method
In this section, we present an FOCs vector-based method to perform DOA estimation. Firstly, we provide a dimension reduction method to build a novel data model by employing the concept of a fourth-order difference co-array [
8]. This method can also be treated as a denoising procedure to reduce the estimation errors of FOCs. Next, according to the newly built data model, our sparse model is efficiently established and solved by the OGSBI method. Some information about the proposed method (e.g., identifiability, complexity, and comparison with the state-of-the-art methods) is also discussed.
3.1. Dimension Reduction or Denoising Procedure
In this subsection, the dimension of model (
3) is reduced by utilizing a fourth-order difference co-array. Here we supplement several definitions and properties to facilitate dimension reduction.
Definition 1. Fourth-order difference co-array (FODCA): Given an array with arbitrary geometry , the fourth-order difference co-array is defined as the set of distinct vector elements from the setwhere , as described in Section 2. Let denote the distinct elements in , where is the cardinality of . The following definition gives the concept of a transformation matrix, which describes the relation between and the steering vector on (see Property 2 in this subsection).
Definition 2. The transformation matrix : Given array , the associated FODCA can be obtained by Definition 1. The transformation matrix is an matrix, where the ξth column corresponds to the vector , and the th entry of satisfieswhere the index , and recall that in Section 2. Property 1. The transformation matrix has full column rank.
Property 2. Let be the steering vector of (i.e., ), we havewhere , is the steering vector for θ, and . Property 3. Define , where is the function that maps to by Definition 1. Then the supremum of is From Property 2, we have
, where
. Substituting it to (
3), we obtain
. Due to Property 1, we have
where
is the Moore–Penrose inverse of
. Comparing the model (
8) with (
3), it is clear that the row dimension decreases from
to
.
Remark 1: An analogous procedure can be found in covariance vector-based DOA estimation methods [
22]. Among HOCs-based DOA estimation methods, rectangular
-MUSIC provides two strategies to reduce the dimension of a rectangle FOCs matrix (i.e., selection strategy and averaging strategy), by eliminating redundancies of associated left and right virtual steering vectors [
7]. From this perspective, the proposed dimension reduction procedure is the essential realization of the averaging strategy applying to FODCA, with an explicit formulation (
8). It is clear that the averaging strategy is better than the selection strategy due to the averaging of the noise in the associated observation components [
7], if the computation burden is not taken into consideration. Thus, the averaging strategy can also be treated as a denoising procedure. In addition, it can be seen that FODCA has the same geometry as a fourth-order virtual array with parameters
[
25], which is deduced from an eighth-order cumulants-based array processing problem. In TABLE IX from [
25], the max number of identical virtual sensors in the fourth-order virtual array, with parameters
and space diversity (without angular and polarization diversity), is illustrated, and it is equal to (
7) after simplification due to the same geometry. The detailed derivation of (
7) is provided in
Appendix C, since it is not provided in [
25].
Remark 2: It is clear that when
, the limiting root mean square error (RMSE) of covariance vector-based methods is not necessarily zero [
22,
26], while the RMSE of the traditional MUSIC method converges to zero as signal–noise-ratio (SNR) approaches infinity. As the FODCA can be regarded as two levels of second-order difference co-array [
8,
18], applied to construct covariance vector-based methods, it can be deduced that the FOCs vector-based DOA estimation methods, including [
8,
16,
17,
18], will be outperformed by traditional MUSIC in high-SNR regions when
. From this point, we only suggest to use these methods (including the proposed method) in underdetermined cases (
).
3.2. Sparse Model
In this subsection we develop the sparse model from (
8). Let
be a fixed sampling grid in the DOA range, where
. Let
be a uniform grid with a grid resolution
. Suppose
is the nearest grid point to
, where
. Then, the steering vector
can be approximated by its first-order Taylor series
Denote
and
, where for
,
if
for any
and
otherwise, and
denotes the operator to form a diagonal matrix by a vector or to form a vector by diagonal entries of a matrix. Neglecting approximation errors of (
9), model (
8) can be expressed as:
where
is the zero-padded extension of
from
to
.
Consider the case of existing estimation errors of FOCs. Let
, where
is the estimate of
, and
is the estimation errors vector. Then, model (
12) becomes
Assume
[
1], where
denotes the asymptotic normal distribution,
denotes zero vector with
elements, and
is a positive definite (Hermitian) matrix. The estimation of FOCs and the matrix
are discussed in
Section 3.3. Following this assumption, we have
, where
. Furthermore, we can obtain
, where
is
dimensional identity matrix. We denote by
Then, we can obtain the following SMV off-grid sparse model
with
. Note that if setting
for
, the model (
17) is simplified to an on-grid DOA model.
3.3. Estimation of FOCs and the Matrix
To facilitate the implementation of the proposed method, in this subsection we present the estimation methods of FOCs and the matrix .
Let us introduce the following general notations:
,
, and
. Their empirical estimators are
,
, and
, respectively, where
L is the number of snapshots. Due to the assumptions of sources and noises,
can be expressed as [
25]:
Utilizing the corresponding empirical estimators of terms in (
18),
can be estimated by
Consider complex variables
for
. It is obvious that
. According to central limit theorem, as
, the sample average
converges in distribution to a complex normal. This solution theoretically supports the assumption that
in
Section 3.2, and we aim for a robust estimation of
in the following derivation.
Consider signals given by
It is obvious that
. Let
denote the
gth element of
,
, and
, then we have
Rewrite (
18) as:
where
is given by (
20).
Lemma 1. Given two joint distributed complex-valued random variables and with snapshots index , , and are independent from snapshot to snapshot, respectively. As L approaches infinity, it holds true thatwhere is variance, and , , and are sample averages of , , and with L snapshots, respectively. Due to Lemma 1, from (
19) and (
22), it is easy to find that when the snapshots number
L is large, the term
has much larger variance than the other two terms in (
22). This implies that the estimation error of
is mainly caused by the term
, giving rise to the following approximate expression of
:
Since the signals are independent from snapshot to snapshot, and
, we can obtain
where
,
,
, and
.
In (
25), the term
contains the eighth-order statistics of
, which significantly aggravates the inaccuracy of estimation if the number of snapshots is not large enough. In addition, as the number of snapshots number approaches infinity, we get
. Therefore, we neglect this term to obtain a robust estimation of
, given by
Rewrite (
26) in matrix form
where
,
, and
is the
th column of
.
Note that the estimator
in (
30) need to be revised in certain cases. It is clear that, for the noise-free case,
, and
. When
, the ranks of both matrices
and
are
. As a result, the estimator (
27) may be singular, which may lead to a singular matrix
. This is unallowable for model (
17). Therefore, when
, and SNR is high, to avoid above problems,
is estimated by
where
is a small positive number.
Specially, if the observed signals are circular, we have
and
for
. Then, we obtain
, and
can be estimated by
Furthermore, it is obvious that
and
become zero in (
25). Then, the estimator of
in (
27) becomes:
Accordingly, when
and SNR is high, for circular sources,
is estimated by
where
is a small positive number.
Remark 3: Approximate expressions for the covariances of FOCs which are more precise than (
25) are derived in [
5]. However, it is not easy to use in our method in practice, because several higher-order (greater than four) moments need to be estimated, which may cause the estimation of
to be not as robust as FOCs. For example, if the number of snapshots is large enough to generate precise estimates of FOCs, but not large enough to generate ones of higher-order (greater than four) moments, the DOA estimation results may suffer from a mass of outliers in independent experiments. In comparison, (
26) contains at most fourth-order statistics, which means that it is more robust and has lower computational cost. We will show that our estimators work well for the proposed method in numerical simulations.
3.4. DOA Estimation by OGSBI Method
In this subsection, the sparse model (
17) is solved to obtain the DOAs by the off-grid sparse Bayesian inference (OGSBI) method. Recall the sparse model (
17):
In
Section 3.3, we showed that the estimation errors of FOCs obey
, and the robust estimators of
are also given. As
, it is obvious that
. Following the sparse Bayesian formulation in [
21], further assume
for simplicity. Then, we have
Adopt the two-stage hierarchical prior for
that
, in which
where
,
,
,
is the probability density function (PDF) of the Gamma distribution with parameters (
), and
is the
wth entry of
. Here the Gamma hyperprior is assumed for
, since it is a conjugate prior of the Gaussian distribution, and it is widely used in SBL techniques and demonstrated with good performance and robustness [
13,
21,
27,
28].
Assume a uniform prior for
:
. By combining the stages of the hierarchical Bayesian model, the joint PDF is
The posterior distribution of
can be obtained
with
As a single snapshot case of the OGSBI method, we can obtain the following updates of
from the deduction in [
21]:
where
,
is the
wth entry of
, and
is
th entry of
. For
, by maximizing
, we can obtain the updates
where
,
,
takes the real part of a complex variable and ⊙ is the Hadamard product. An easier way to estimate
is provided in [
21]. We use
,
, and
hereafter to denote their truncated versions for simplicity. By (
41) and
, we have
if
is invertible and
. Otherwise, we update
elementwise. That is, at each step we update one
by fixing up the other entries of
. For
, we first let
, where
denotes
without the
kth entry. Then, by constraining
, we have
The OGSBI is terminated if
or the maximum number of iterations is reached, where
is the iteration and
is the predefined tolerance parameter. Then,
can be treated as the pseudo-spectrum
By finding the grid indices of highest
K peaks of
, denoted by
, we can obtain
K estimated DOAs by
Note that the parameter
in the method should be given in advance. According to associated information in [
21] and our testing results, the OGSBI method is insensitive to
if
is not too large. Furthermore, we have observed that by setting
, the sparse Bayesian learning methods in [
13,
21,
28] always achieve a good performance in a wide range of scenarios. By contrast, the 4-L1 method [
16,
17,
18] is sensitive to the parameter of allowable error bound, which is not easy to estimate (it was chosen to give the best results through trial-and-error for each scenario in the corresponding simulations in [
16,
17,
18]). Therefore, compared with the 4-L1 method, the OGSBI method has the advantage of convenience in setting parameters.
Finally, we summarize our method in Algorithm 1.
| Algorithm 1 The proposed sparse method using denoised FOCs vector |
| 1) | Input: , , and d. |
| 2) | Initialization: r, , , , and . |
| 3) | According to the associated scenarios, calculate by (19) or (29). |
| 4) | According to the associated scenarios, calculate by (27), (28), (30), or (31). |
| 5) | Calculate , , , and by Definition 2, (10), (11), and (14), respectively. |
| 6) | Repeat the following: |
| | a) Calculate and by (38) and (39), respectively. |
| | b) Update by (40). |
| | c) Update by (42). |
| | d) If or the maximum number of iterations is reached, iteration terminates. |
| 7) | Find the grid indices of the highest peaks of (43), and output the DOAs by (44). |
3.5. Identifiability of the Number of Sources
According to the theorems about parameter identifiability in [
29,
30,
31] and the model (
8), we have the following proposition.
Proposition 1. Any K sources can be uniquely identified from model (17) if and only ifwhere is defined as the smallest number of elements in that are linearly dependent [32], , and Θ
is for linear array and for planar array. It is generally difficult to compute
, except for when
is a uniform linear array (ULA). In this circumstance,
is hole-free,
, and then
sources can be identified. However, hole-free FODCA with
DOFs has not been studied so far to the best of our knowledge. Recently, [
16,
17,
18] provided several methods to construct FODCA with larger ULA segments, with which
sources can be identified, where
is defined as the largest ULA segment in
.
For general arrays, because
, it is obvious that
According to Property 3, (
46), and Proposition 1, we can obtain a necessary condition regarding the identifiability of the number of sources.
Theorem 1. Consider model (17), a necessary condition to uniquely identify all sources is that the number of sources K fulfills In other words, any more than
sources cannot be uniquely identified by model (
17).
In addition, there are
distinct elements in
for certain sparse linear arrays (SLAs), such as four-level nested arrays [
8] and arrays constructed from a expanding and shift scheme which consists of coprime arrays or nested arrays [
18]. Therefore, our proposed method can identify
sources at most, if these arrays (not limited to) are used.
3.6. Complexity
Consider the worst case of complexity. For non-circular sources, the estimation of
using (
19) needs
multiplications. The estimation of
using (
27) or (
28) needs
multiplications. Note that all the symmetries of
and
are not taken into account here, while it does not affect the order of complexity. Each iteration of (
38) and (
39) needs
multiplications, which are much more than each iteration of (
40) and (
42). Let
T denote the iteration number, and consider the worst case that
. Combing all of the above processes, we can obtain that the complexity of the proposed method is
.
3.7. Comparison with State-of-the-Art Methods
In this subsection, we compare the proposed method with state-of-the-art FOCs-based ones, in terms of required geometry, identifiability, prior knowledge of the number of sources, ability to handle correlated sources, numerical complexity, and sensitivity to parameters. Associated methods are listed as follows:
4-MUSIC [
5,
6]: non-redundant version with averaging strategy [
7], denoted by A-4-MUSIC;
4-SS-MUSIC [
8]: with averaging strategy, denoted by A-4-SS-MUSIC;
Associated comparison results are illustrated in
Table 1.
In
Table 1,
and
denote the iteration number of the proposed method and 4-L1, respectively. All comparison results are obvious or were discussed in the previous subsections, except for the comparison of complexity. Recall that
M is the number of sensors,
L is the number of snapshots, and
I is the number of grid points. It should be noted that the complexities of four methods are derived under the assumption that
, which gives the best identifiability and highest complexities for all methods. Due to the condition
required to perform the sparsity in the proposed method and 4-L1, it is clear that
, which results in
and
. Consequently, the proposed method and 4-L1 always have higher complexity than A-4-MUSIC and A-4-SS-MUSIC.
Next, we make a comparison of complexity between the proposed method and 4-L1. Firstly, if the number of snapshots
L is large enough that the terms
and
can be negligible, the proposed method has higher complexity than 4-L1 due to the term
which is caused by the estimation of
. Secondly, if
L is small, we limit the comparison between
and
. It is clear that
, implying that the proposed method has lower complexity than 4-L1 in one iteration. However, it is a fact that 4-L1 always has less iterations than the proposed method (i.e.,
). Thus, it is not easy to draw a conclusion. In fact, to achieve the super resolution, 4-L1 needs a dense grid, while the proposed method only needs a coarser grid due to the off-grid parameter estimation, which gives our method an advantage for complexity comparison. It should be noted that off-grid parameter estimation technique has been successfully applied to L1-norm minimization methods in [
33,
34]. However, to the best of our knowledge, the off-grid version of the 4-L1 method has not been published, and it is beyond the scope of this paper.
4. Numerical Simulations
Numerical simulations were carried out to demonstrate the superior performance of the proposed method. In the following simulations, the sampled analytic signals of statistically independent quaternary phase-shift keying (QPSK) signals were used as circular sources. The RMSE was chosen as the performance criterion, and is computed by
where
F is the number of independent experiments, and
is the estimate of
in the
fth independent experiment. The RMSE performances of the four methods in
Table 1 with respect to number of snapshots, grid, adjacent sources, SNR, modelling errors, geometry, and circularity of sources were further investigated. In the proposed method, we set that
and
for all scenarios, and set
or
for the case that
and
dB. 4-L1 was solved by the SeDuMi toolbox [
35], and the associated allowable error bound was chosen to give the best results through trial-and-error for each scenario as done in [
16,
17,
18]. Each simulation executed
independent experiments for all methods.
4.1. Identifiability
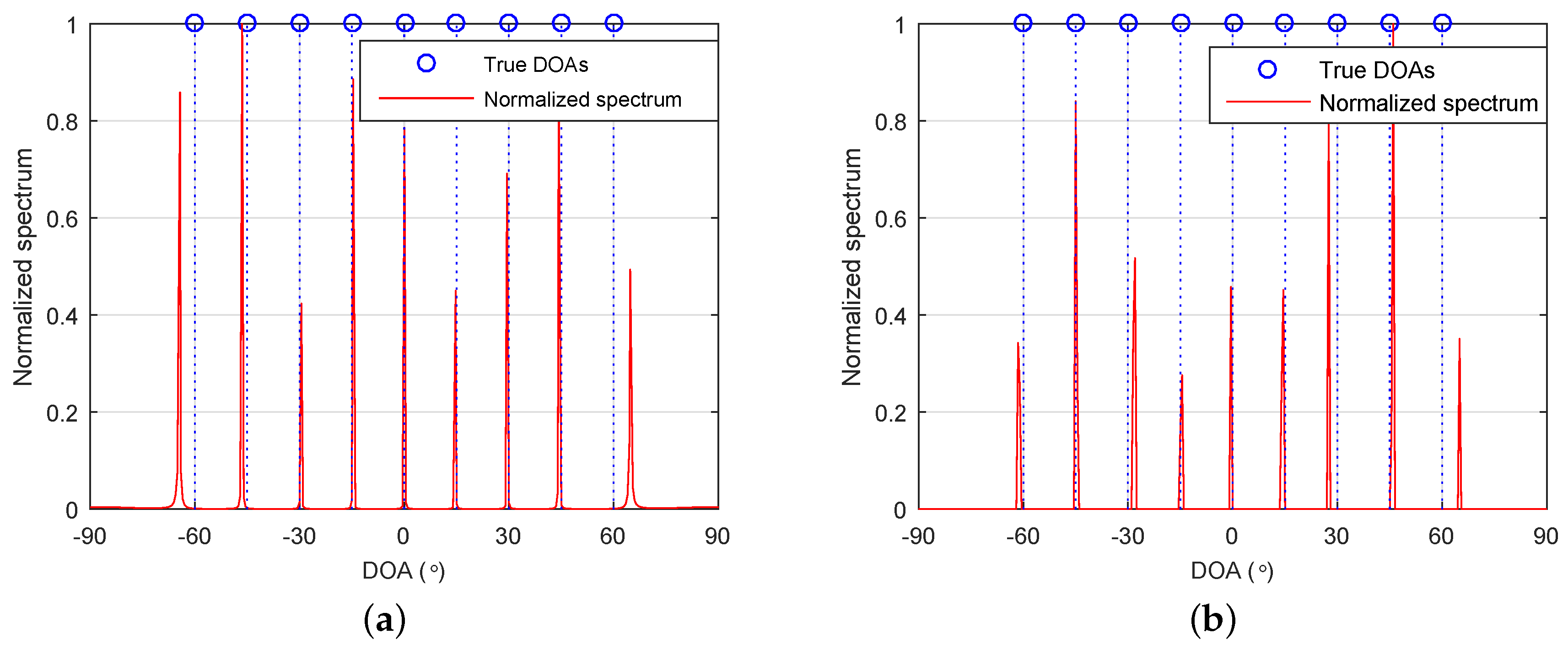
Consider an SLA with three sensors located at
. It can be deduced that the associated FODCA has 19 distinct elements. That is,
, which is equal to
when
. According to Theorem 1, any greater than nine sources cannot be uniquely identified for the proposed method. Let us consider nine sources with DOAs
. The number of snapshots and SNR were set as
and
dB, respectively. Grid resolution was set to
.
Figure 1a,b shows the normalized spectra of the proposed method and 4-L1, respectively. As can be seen, all DOAs of the sources were identified successfully. Note that this was unachievable for A-4-MUSIC and A-4-SS-MUSIC. The virtual array of A-4-MUSIC contained seven distinct virtual sensors, which could identify six sources at most. The largest ULA segment of the FOCDA contained 13 distinct elements, giving rise to a maximum identifiable number of six for A-4-SS-MUSIC.
4.2. Impact of the Grid Resolution
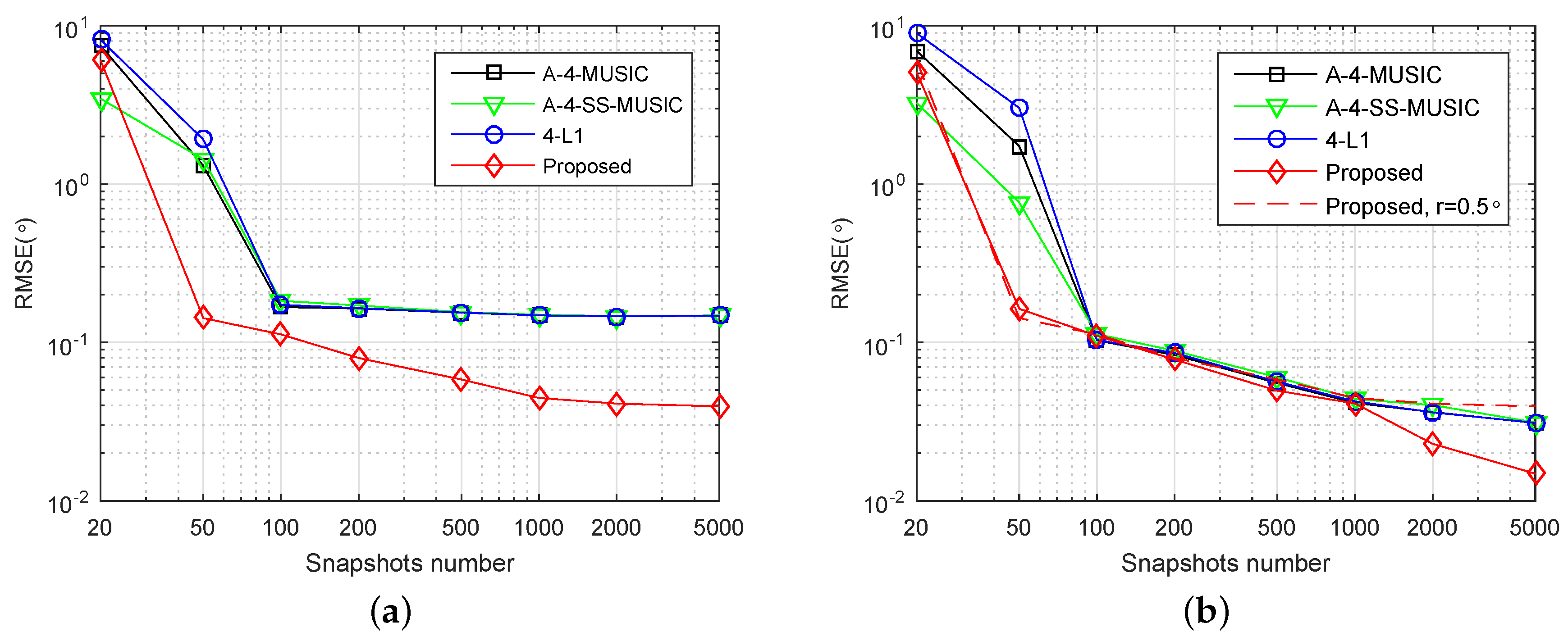
Consider an SLA
, which is constructed from an expanding and shift scheme that consists of two nested arrays
and
[
18]. It can be obtained that the number of distinct elements of the corresponding FODCA and associated largest ULA segment is
and
, respectively. Consider two independent sources with DOAs
, where
is a random variable chosen uniformly within
. SNR was set at
dB.
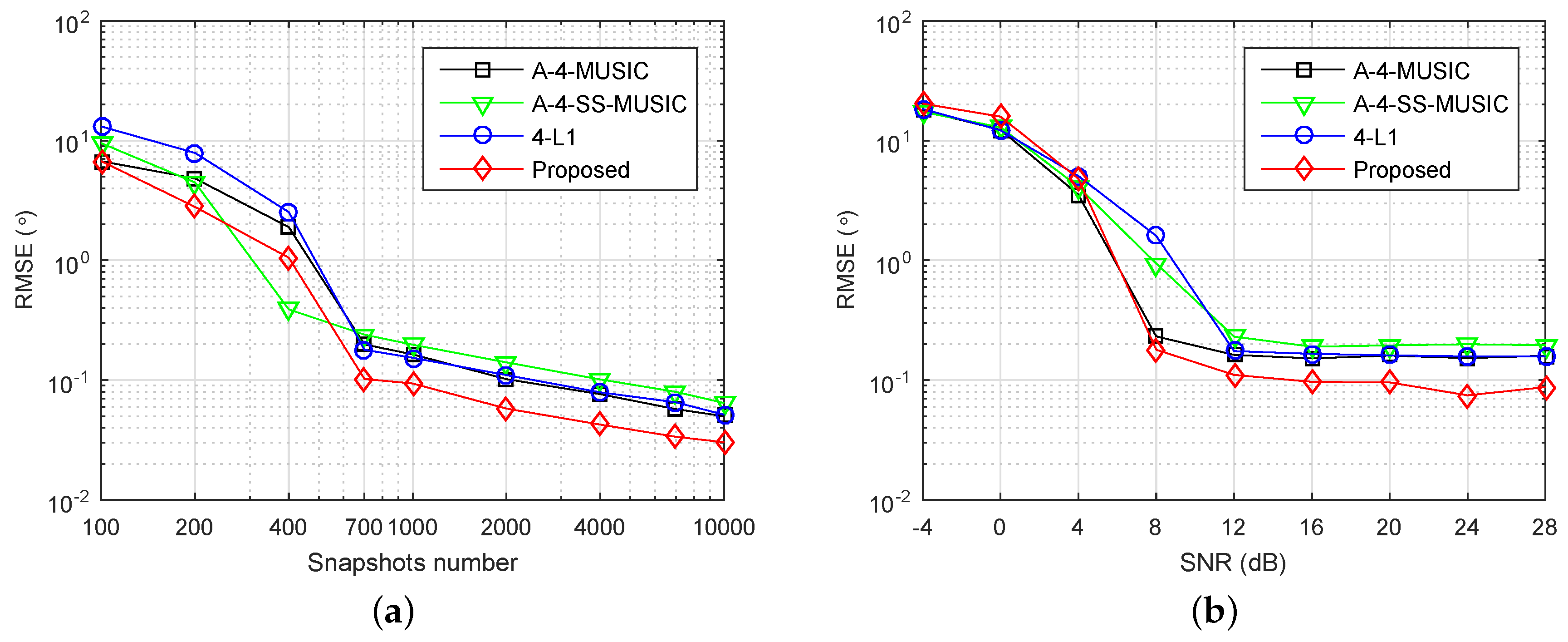
Figure 2a,b shows the RMSE performance of the four methods with respect to number of snapshots, with grid resolution
and
, respectively. In
Figure 2a, when snapshots number was large, the RMSEs of A-4-MUSIC, A-4-SS-MUSIC, and 4-L1 did not reduce as snapshots increased, mainly because of the mismatch errors between grid and true DOAs. Due to the off-grid parameters estimation, the proposed method outperformed the other three methods for most of simulated snapshot numbers. In
Figure 2b, the grid resolution is
, and it is clear that the RMSEs of A-4-MUSIC, A-4-SS-MUSIC, and 4-L1 increased to the same level of the proposed method when snapshots were greater than 50 and less than 2000. Nonetheless, the proposed method still outperformed the other three methods when snapshots were more than or equal to 2000. It can also be observed that the proposed method had smaller RMSE than A-4-MUSIC and 4-L1 when snapshots were less than 100. The RMSEs of A-4-SS-MUSIC were slightly larger than the other three methods when snapshots were greater than 50 and less than 5000, which may be caused by the fact that 4-SS-MUSIC does not utilize all the virtual sensors in associated FODCA. In addition, the dashed line in
Figure 2b gives the RMSEs of the proposed method for
, and it is clear that the grid resolution seldom affected the RMSEs of the proposed method when snapshots were less than 2000, which implies that when snapshots are not too large, the proposed method can reduce the computational complexity by selecting a relatively coarser grid without heavy loss of RMSE performance.
4.3. Identifiability for Adjacent Sources
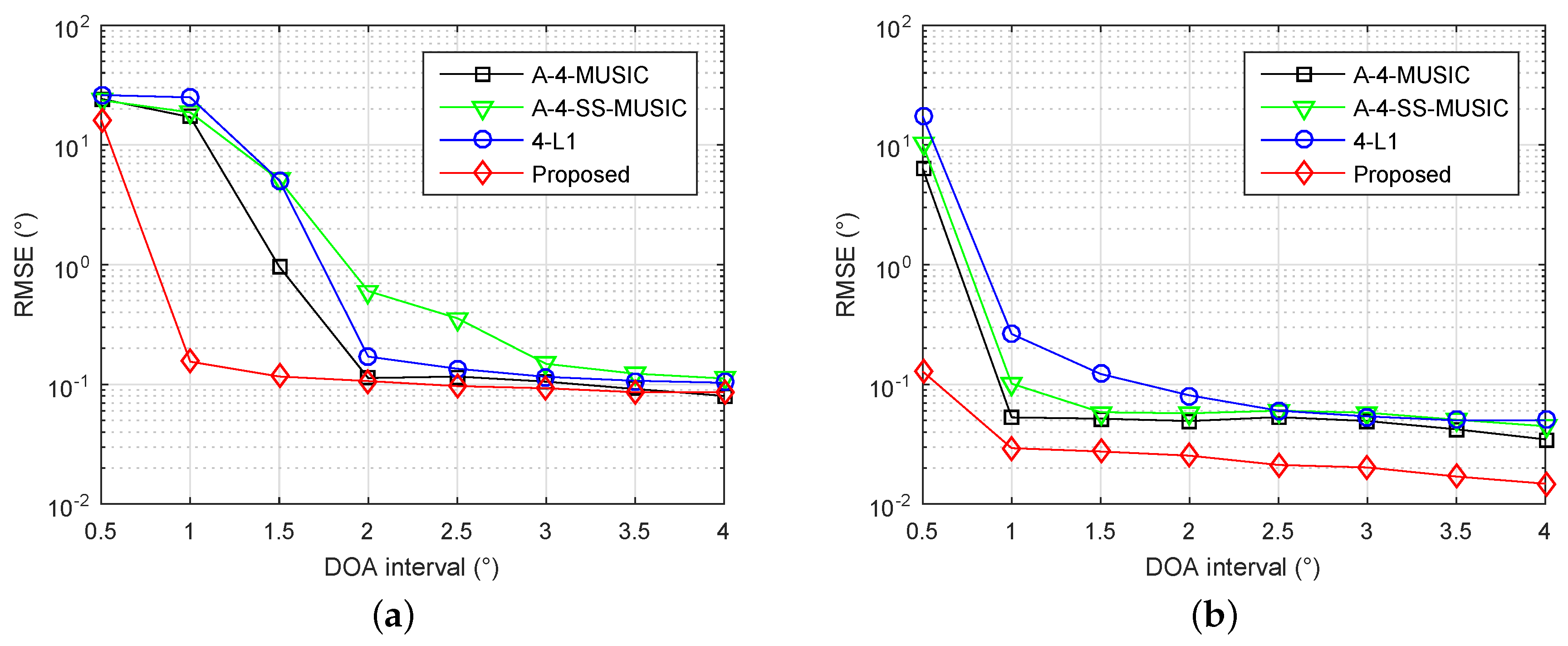
Next, we investigated the identifiability of adjacent sources using the proposed method. The array and parameters were set as in
Section 4.2, except the grid resolution was set to
, and the DOAs of sources were set to
, where
is a random variable chosen uniformly within
, and
are the different DOA intervals.
Figure 3a,b shows the RMSE performance of four methods with different DOA intervals, when the number of snapshots is 300 and SNR is 3 dB, and when the number of snapshots is 1000 and SNR is 10 dB, respectively. It is clear that the proposed method had smallest RMSEs for most simulated DOA intervals in both simulations, demonstrating the superior identifiability of adjacent sources with the proposed method.
4.4. Impact of SNR
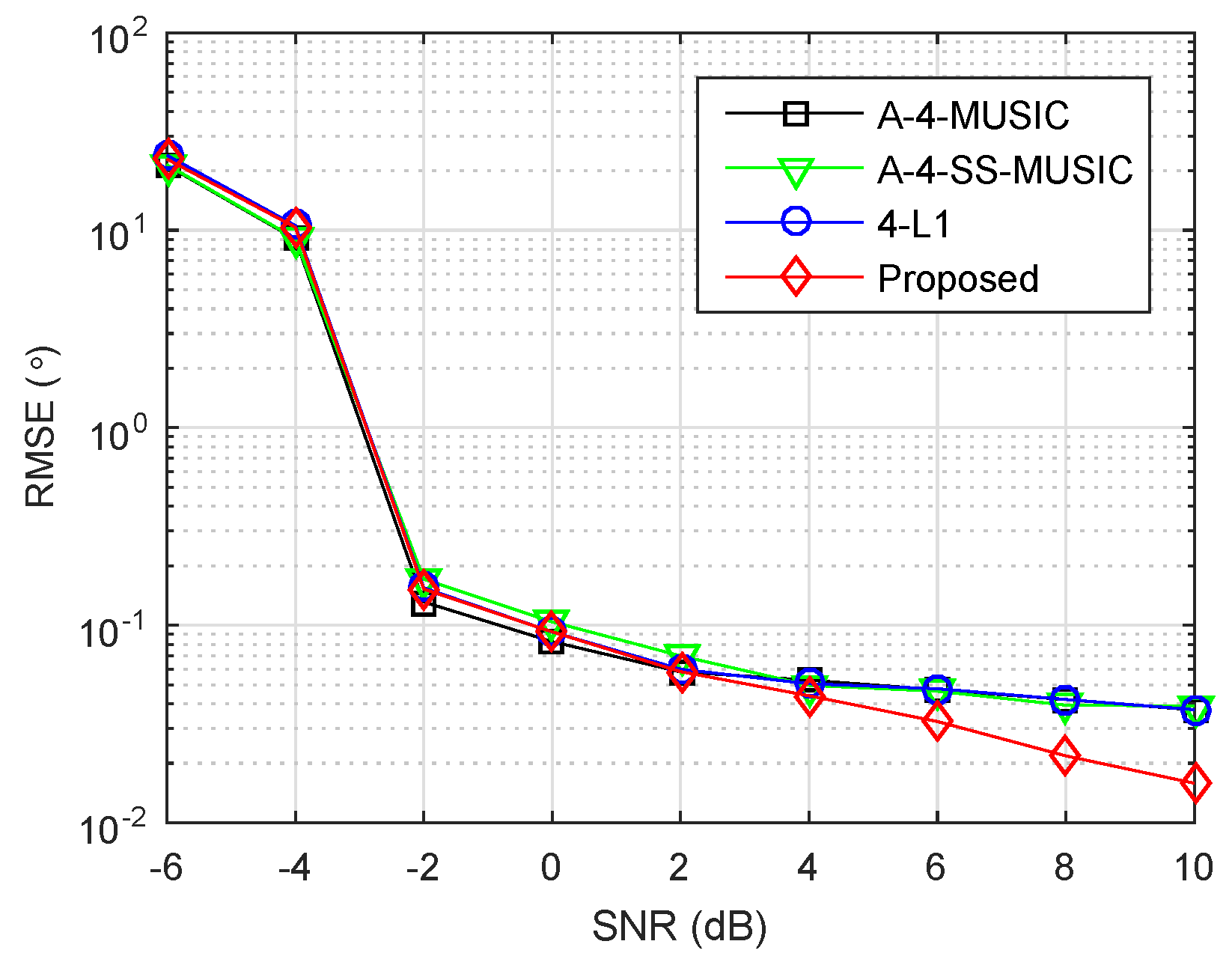
The array and parameters were set as in
Section 4.2, except the grid resolution was set to
.
Figure 4 plots the RMSEs of four methods as a function of SNR, where the number of snapshots was set to
. It is clear that the four methods had almost equal RMSEs when SNR was smaller than 4 dB. In the high SNR region, a relatively better performance of the proposed method appeared, benefiting from the off-grid parameter estimation as discussed in the large snapshot number region in
Section 4.2.
4.5. Impact of Modelling Errors
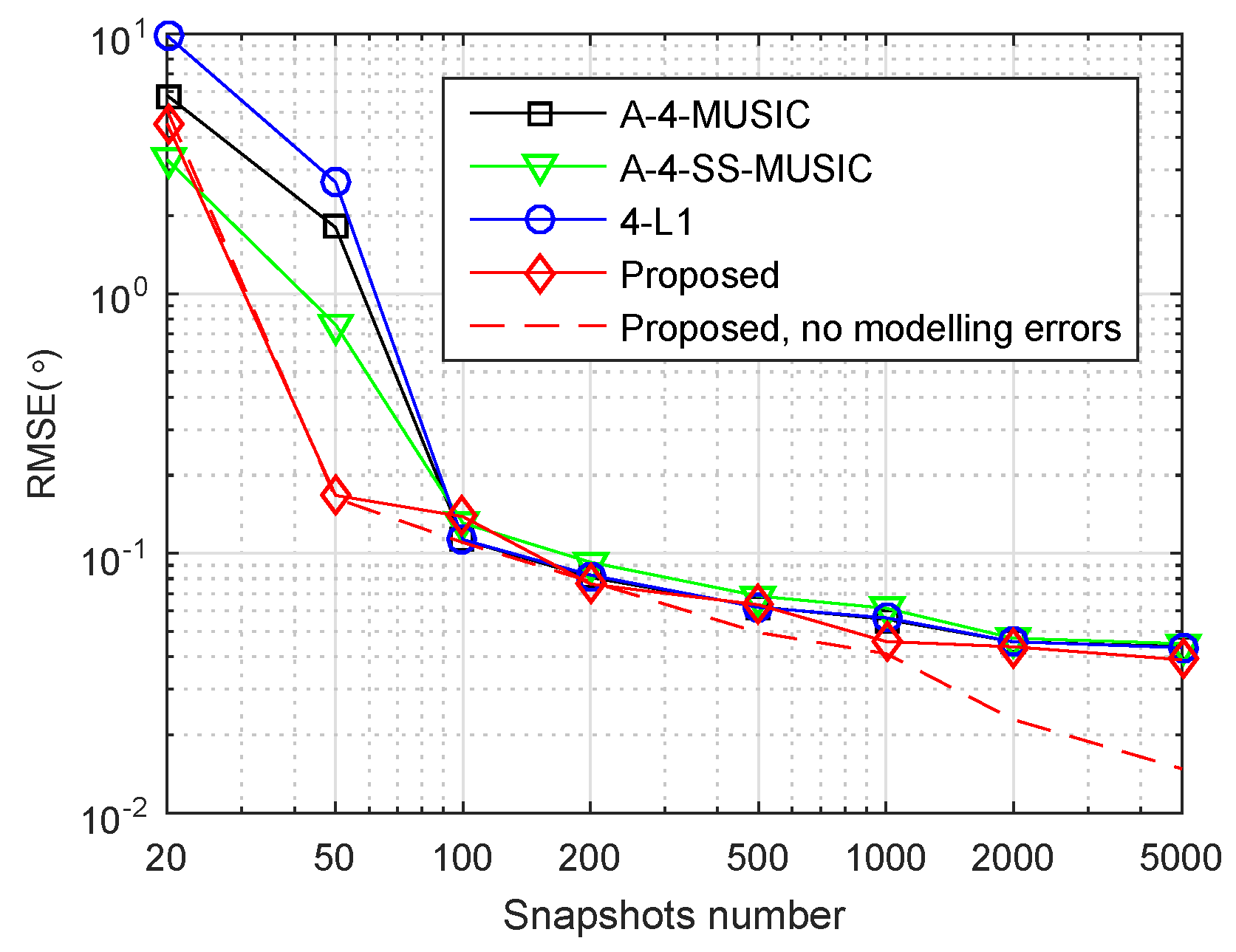
We also studied the effect of modelling errors on the proposed method. We used the same array geometry and parameters, and the same way of generating
DOAs as in
Section 4.4. We perturbed the steering vector by adding a modelling error vector
to get the perturbed steering vector as
, where
, and
are assumed to be zero mean statistically independent Gaussian distributed with
, where
.
Figure 5 shows the RMSE performance of four methods with such modelling errors. In order to facilitate comparison, the RMSEs of the proposed methods with no modelling errors are also plotted in a dashed line. It can be observed that the RMSE performance of the four methods did not degrade heavily. However, when snapshots were more than 1000, the superior performance of the proposed method disappeared, suggesting that modelling errors did have a large impact on the off-grid parameters estimation of the proposed method.
4.6. Underdetermined Case
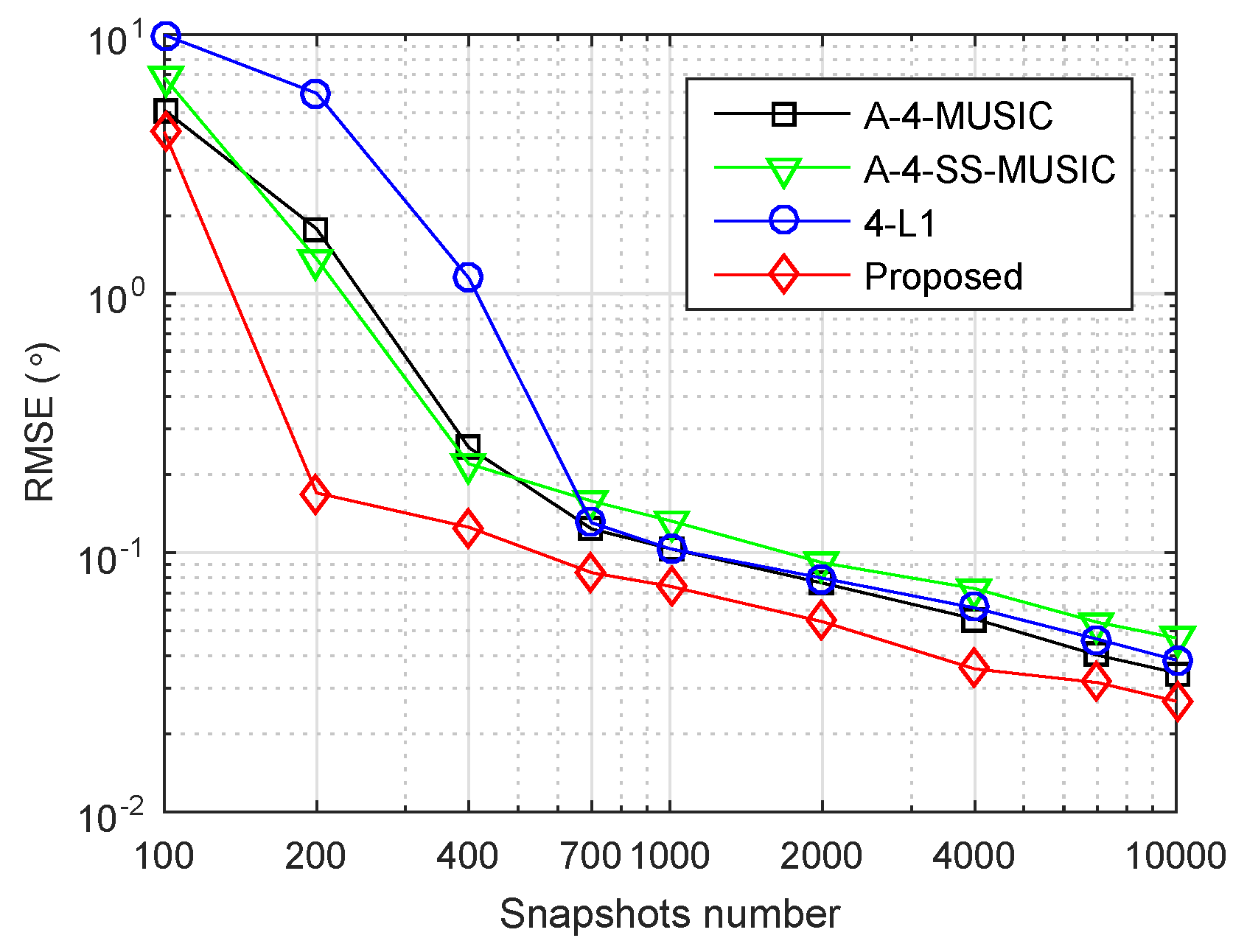
We investigated the performance of the proposed method in underdetermined cases. The same array
was used, and the grid resolution
, while six independent sources with DOAs
were set.
Figure 6 shows the RMSE performance of the four methods. In
Figure 6a, the number of snapshots varying from 100 to 10,000 and the SNR was fixed at 20 dB. It is clear that the proposed method had the smallest RMSEs for most of the simulated snapshot numbers. In
Figure 6b, SNR varied from −4 dB to 28 dB and the snapshots number was fixed at 1000. It can be observed that the proposed method had smaller RMSEs when
dB, but had slightly larger values when
dB, when compared with the other three methods. The RMSE performance of A-4-SS-MUSIC was obviously outperformed by the other three methods in the large snapshot number and high SNR regions, because 4-SS-MUSIC does not utilize all the virtual sensors in the associated FODCA. Moreover, the RMSEs of each method seemed to converge to a positive constant as SNR increased. A similar phenomenon can be observed and explained in covariance vector-based methods in the underdetermined case [
22,
26].
4.7. Non-Linear Array Case
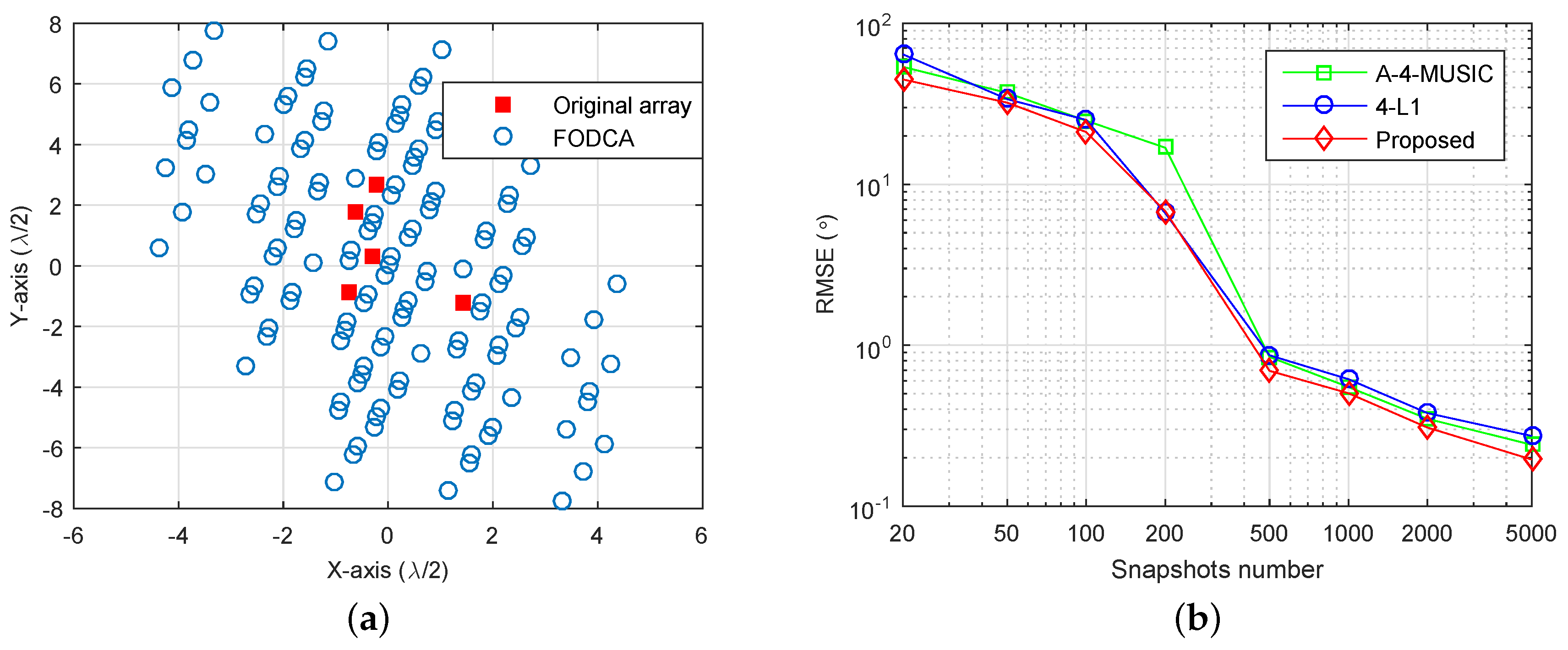
We now give an example to show the effectiveness of the proposed method in the non-linear array case. We randomly generated a planar array as shown in
Figure 7a, where the minimum distance between sensors was half of the wavelength. The corresponding FODCA geometry is also illustrated, which had
distinct elements. Note that the A-4-SS-MUSIC cannot be applied for the non-linear array case. We set three sources with DOAs
, where
is a random variable chosen uniformly within
. SNR was set at
dB, and the RMSEs of A-4-MUSIC, 4-L1, and the proposed method were plotted as a function of the number of snapshots (
Figure 7b). It can also be seen that the proposed method had better RMSE performance when snapshots were greater than 200.
4.8. Effectiveness for Non-Circular Sources
Finally, we consider the case of non-circular sources, using the same array
, and six independent sources with DOAs
as in
Section 4.6. In contrast, we replaced the imaginary parts of sources by their real parts. That is,
, where
is the non-circular sources to be simulated. We set
dB and
. We estimated the FOCs by (
19) for all the methods, and estimated
by (
27) for the proposed method.
Figure 8 shows the RMSEs of the four methods versus the number of snapshots. Similar to
Figure 6a, it is clear that the proposed method had the smallest RMSEs for all simulated snapshot numbers. Beyond doubt, all the methods were effective for non-circular sources with the estimation of FOCs by (
19).
5. Conclusion
In this paper, a novel SMV sparse model for non-Gaussian sources using denoised FOCs vector is established to perform DOA estimation, and solved efficiently by the OGSBI method. An advanced denoising and dimension reduction procedure of FOCs vector is provided. The estimation errors of FOCs are integrated in the proposed SMV model, and are approximately estimated in a simple way. The proposed method suits any geometry, does not need prior knowledge of the number of sources, has maximum identifiability , and is insensitive to associated parameters. The off-grid parameter estimation in our method promotes superior performance when the number of snapshots is large and SNR is high, and also ensures good performance when choosing a relatively coarse grid. Numerical simulations illustrate that the proposed method has superior identifiability or RMSE performance in different scenarios, namely grid resolution, adjacent sources, SNR, modelling errors, geometry, and non-circular sources, when compared with other state-of-the-art methods.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}