1. Introduction
With the development of smartphones and web Geographic Information System (GIS), location-based services (LBS) are changing people’s daily lives. For people in an indoor environment, indoor positioning is required. There are many technical approaches of smartphone indoor positioning [
1], including inertial navigation system (INS)-based [
2], WiFi-based [
3], and Bluetooth-based [
4] methods, but these methods have low accuracy [
1], for example INS drifts along the time. To obtain high accuracy, such as less than 1 m, is expensive respect to the image based localization algorithms [
5].
Mobile mapping technology has resulted in different indoor mobile mapping systems, which can produce effectively indoor high-precision three dimensional (3D) photorealistic maps, consisting of a 3D point cloud and images with known pose parameters. A 3D photorealistic map is one of the indoor spatial data infrastructures for indoor space digitalization and provides various LBSs. Cameras are also widely available in smartphones, mobile robots or wearable devices. Using an existing indoor 3D photorealistic map and camera sensor, a visual indoor positioning solution is zero-cost, and of comparatively high precision.
In photogrammetric vision, the most popular positioning methods, i.e., structure from motion (SfM) [
6,
7] and simultaneous location and mapping (SLAM) [
8,
9] methods, are relative localization methods, and provide a high accuracy image location. This study proposes an indoor visual positioning solution which matches smartphone camera image with high-precision 3D photorealistic map. The proposed visual positioning solution is an absolute localization on a global scale, given the used photorealistic map is aligned with a global coordinate reference. The advantages of proposed absolute localization include: (1) sharing the infrastructure of an indoor map between different positioning systems; (2) absolute positioning on a global scale is required by many LBSs [
10], such as iParking [
11]. Indoor/outdoor seamless positioning is achieved by integrating multiple positioning techniques, for example, global navigation satellite system positioning and SLAM [
12]. High accuracy is needed for some applications, such as indoor automatic moving robots. Visual-based methods are an effective method with prior GIS information. Matching light detection and ranging (LiDAR) point clouds with 2D digital line graphs are used to obtain the indoor positioning of mobile unmanned ground vehicles [
13].
Image-based positioning has been the focus of research in the outdoors. These methods usually contain two steps, namely, place recognition [
14] and perspective-n-point(PnP) [
15], which calculates the extrinsic parameters. Place recognition is an important procedure. Many studies have focused on place recognition, and some benchmark datasets exist, for example, the INRIA Holidays dataset [
16], Google Street View [
17], and the San Francisco Landmark Dataset [
18]. These methods can be classified into two categories, i.e., machine learning based and visual words based methods. Machine learning is widely used in place recognition, such as support vector machine and deep learning [
19,
20]. With the development of convolutional neural networks, end to end methods have been used to obtain the positioning of images, for example, PoseNet [
21] and PlaNet [
22]. However the accuracy of end to end based methods are lower than that of geometry based methods [
23]. Supervised based methods also require many training datasets to train the parameters.
Visual words-based methods including bag of visual words (BOW) [
24], vector of locally aggregated descriptors (VALD) [
25,
26], and Fisher vector (FV) [
27] are widely used in place recognition, especially BOW [
28]. To improve the recognition efficiency, binary VALD is used for place recognition [
26]. Hamming embedding is used to increase the recognition accuracy, and the angle and scale of feature points are also used to assess weak geometric consistency [
16]. The automatic adjustment of parameters in the hamming embedding can improve its accuracy [
29]. To handle the repetition structure of a building, geometry voting based is used to decrease the geometric burstiness [
30]. Matching images with the feature point cloud instead of database images improves the efficiency of the localization procedure [
31].
Most of these methods are used in outdoor environments. Due to the lack of texture, indoor scenes are more difficult than outdoor environments. To obtain global positioning, a reference database is needed [
32]. Coded reference labels on walls are used to locate indoor images. These methods obtain a high accuracy from decimeters to meters [
33]. The coded labels are needed to be measured by total station, and not convenient to be used. SFM method sometime fails when there is not enough feature [
23], so SLAM with geometry information is used to collect large scale indoor dataset [
34]. With the development of LiDAR and camera sensors, obtaining a high-precision 3D photorealistic map has become easier [
34]. Backpacks with LiDAR and cameras are used to obtain large scale reference images using LiDAR based SLAM, only 55 percent of the images have a location error less than 1 m [
35]. Kinect is also used to obtain the indoor visual database of the image positioning using SLAM with depth information. Then use the same data with the database, i.e., Kinect data, as query images, obtain an average location error in 0.9 m [
36]. RGB and distance (RGBD) images are generated from LiDAR and image data, and these RGBD images are used as a database, then a 3D model based place recognition algorithm [
37] is used to recognize the best image, and extrinsic parameters are calculated using direct linear transformation with the calibrated intrinsic parameters. The result shows a large root mean square error(RMSE) in dataset 3 in Y direction from 10 query images, i.e., 2.13 m, due to lack of features [
38].
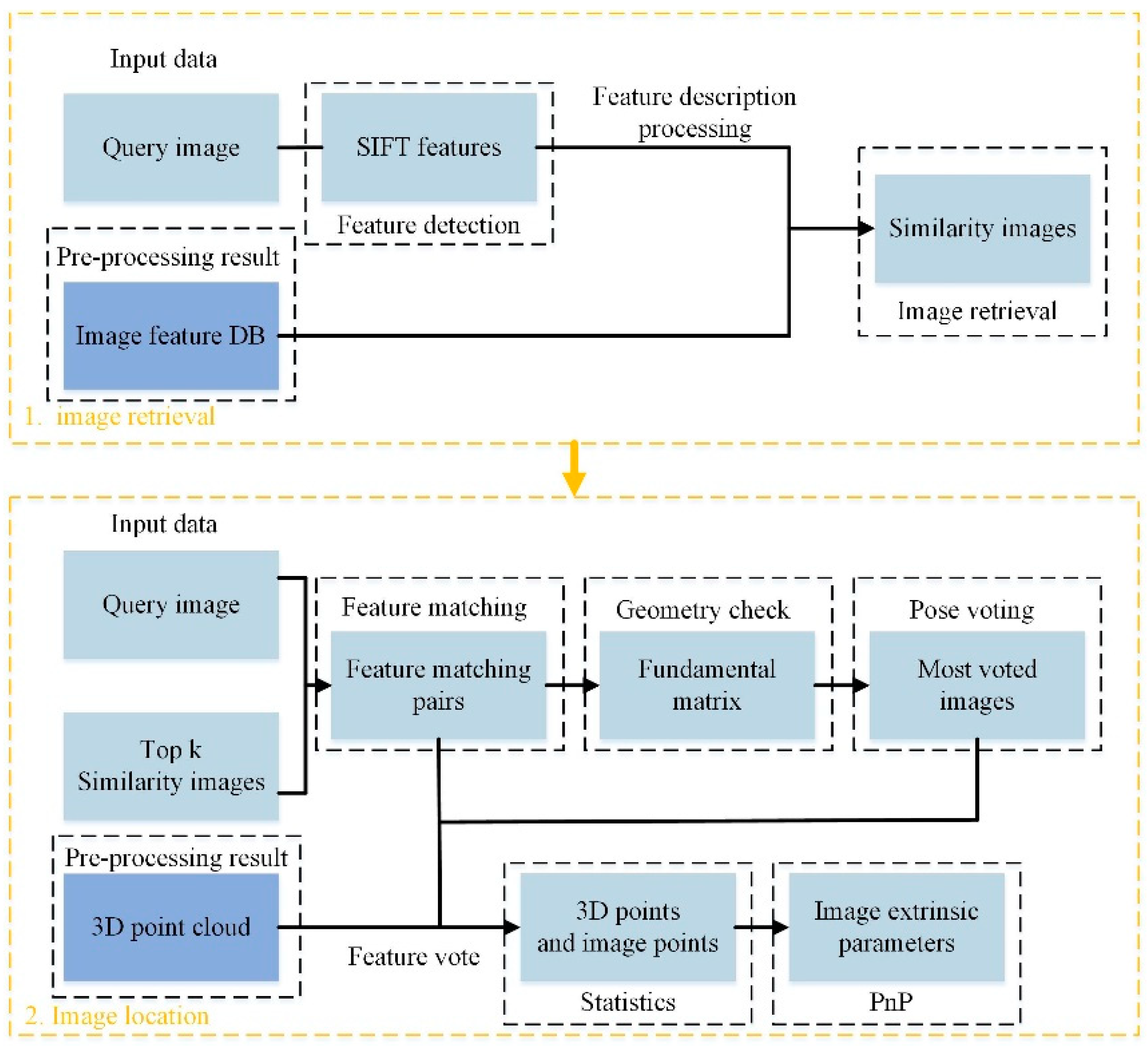
In this paper, using large scale indoor images with known pose parameters as a database, an automatic and robust visual positioning method is proposed. Place recognition and perspective-n-point (PnP) are used to calculate the pose parameters of images from smartphones. The method uses the Navvis M3 trolley [
39] data as a geographic reference. The images are used as a database. Due to the lack of texture in indoor environments, appropriate image selecting in place recognition is difficult, and a posture voting to select images method is proposed. Because the focal length of the camera in a smartphone may change when capturing images [
40], perspective-four-point with unknown focal length (P4Pf) [
41] and random sample consensus (RANSAC) [
42] are used to calculate the intrinsic and extrinsic parameters of the query image. Due to the coarse focal length can be obtained from the exchangeable image file format (EXIF) information, perspective-three-point (P3P) [
43] is used to remove the outlier points. A large number of images are used to prove the effectiveness of the proposed method. The remainder of the paper is structured as follows:
Section 2 formulates the proposed visual positioning method.
Section 3 describes the experimental analysis.
Section 4 is the discussion.
Section 5 is the conclusion.
4. Discussion
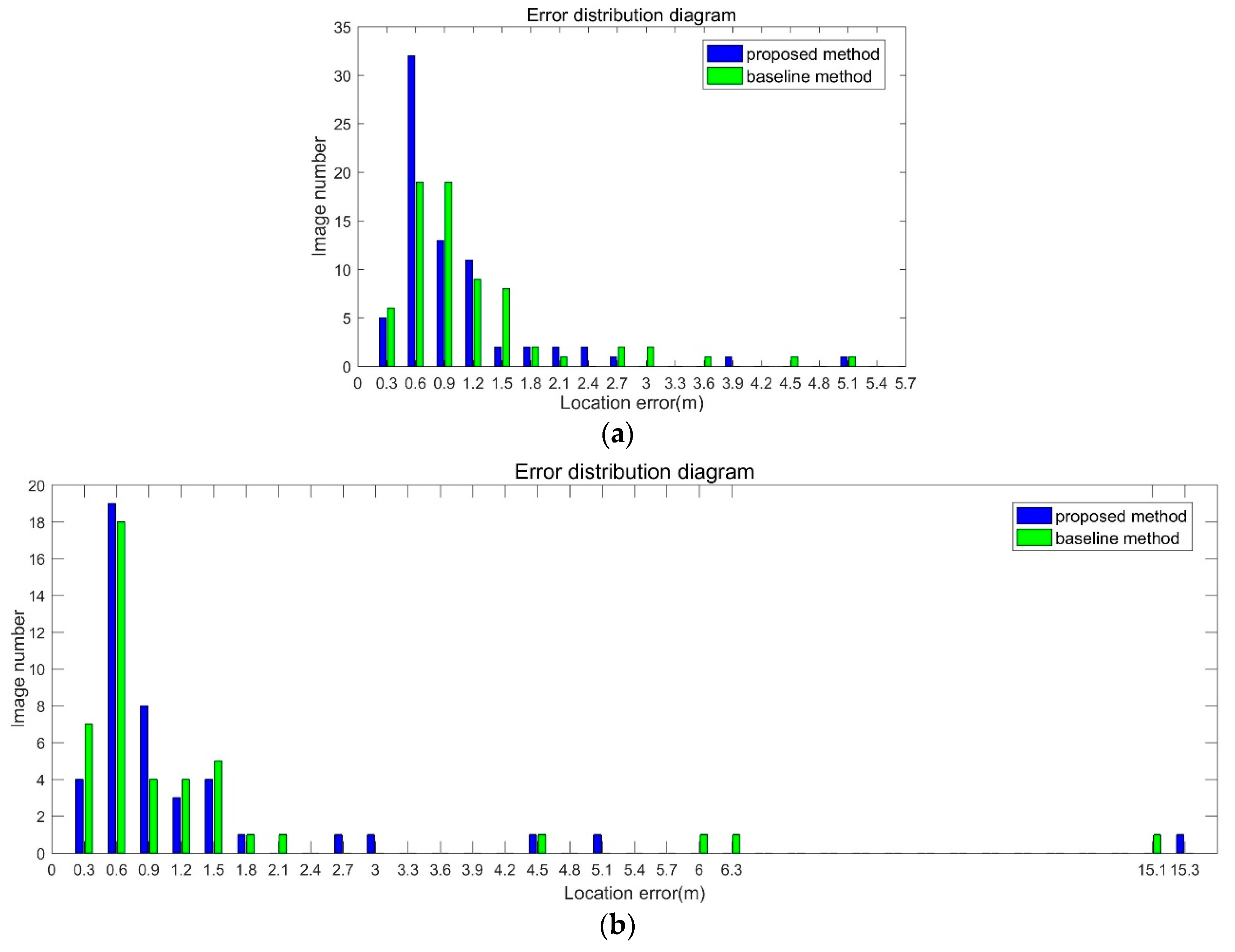
Indoor environments are challenging for visual positioning because there are weak texture regions or textureless regions. In the weak texture scenes, there is no result, for example 15 in 159 images could not be matched in
Table 2.
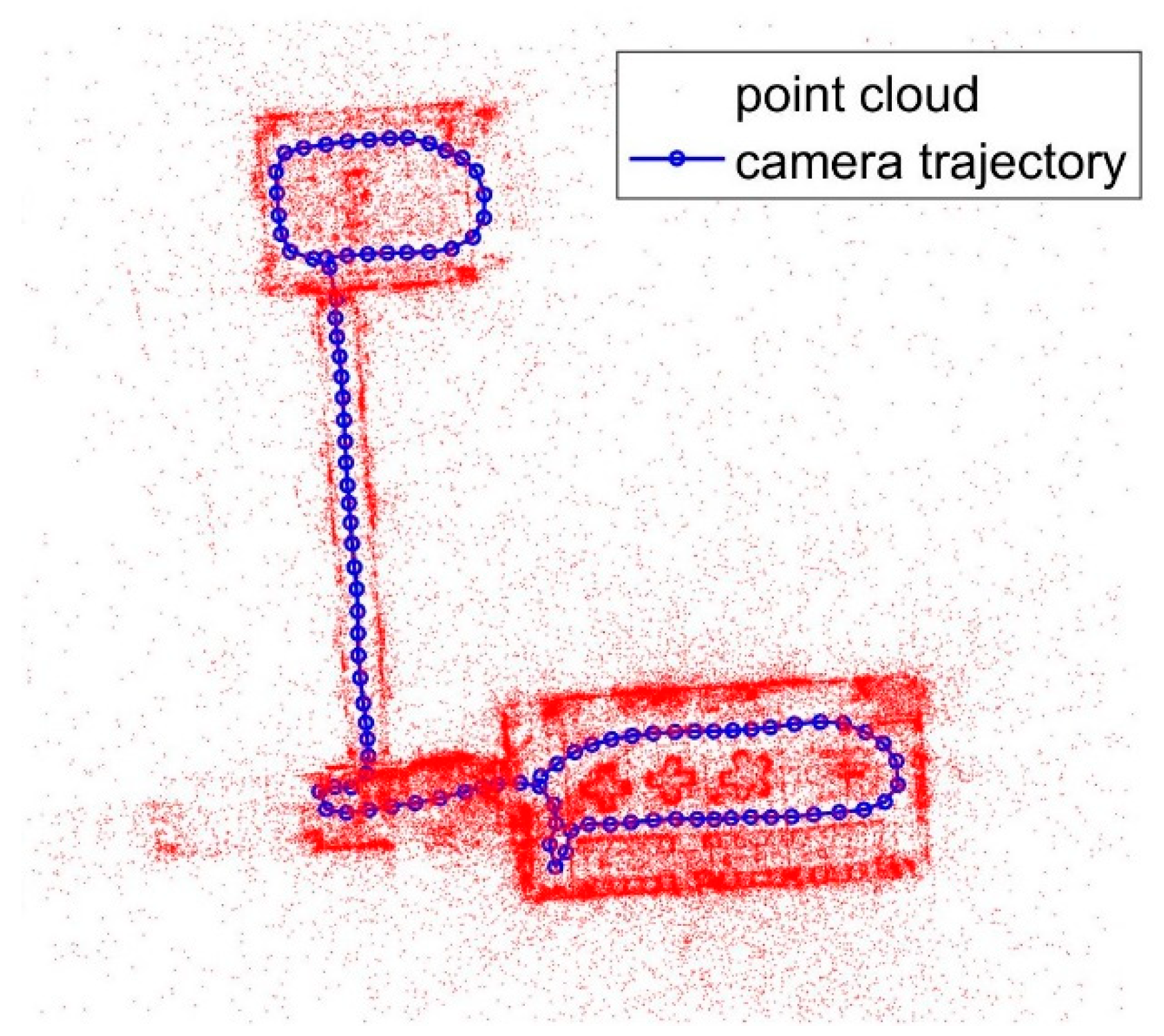
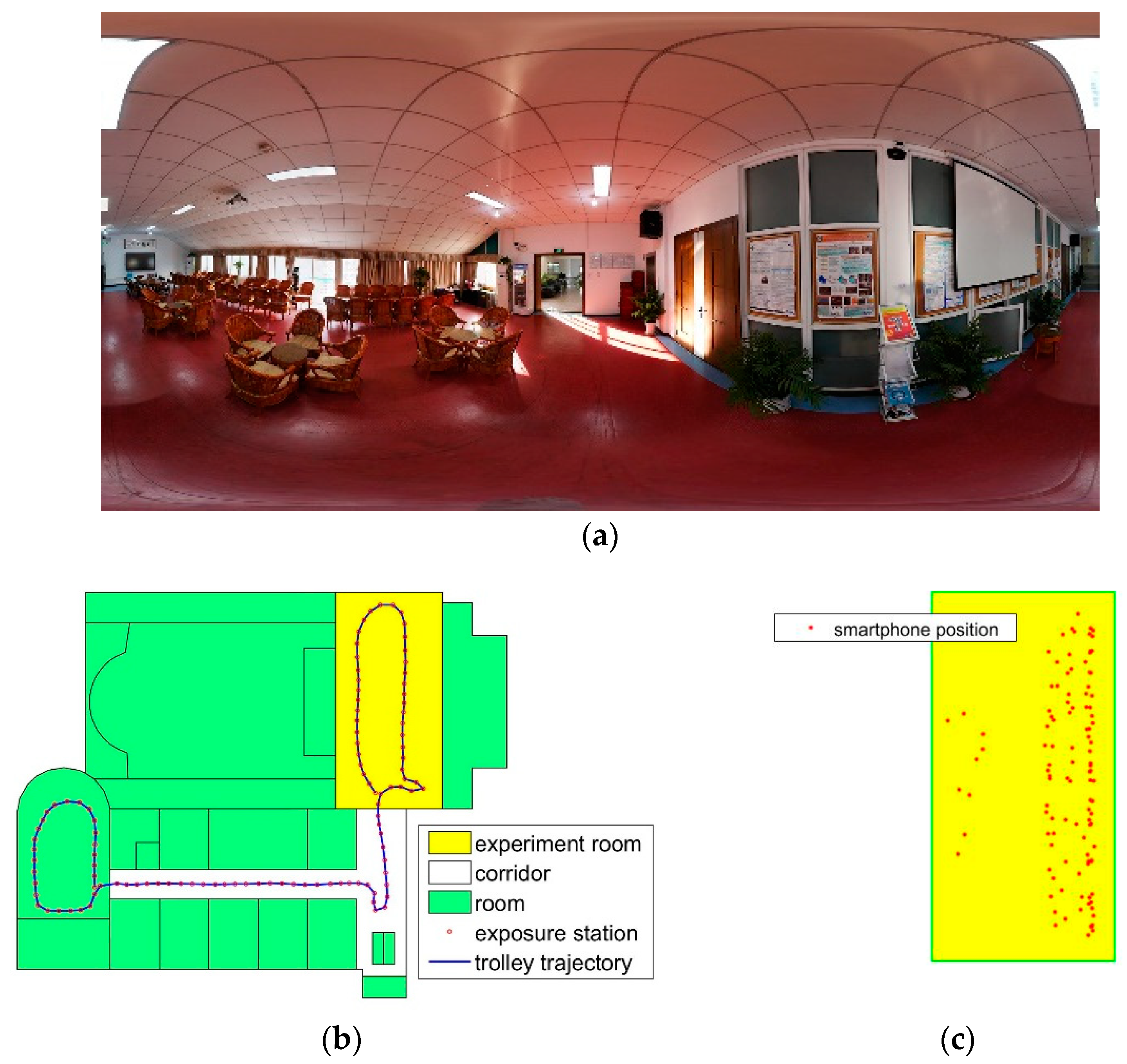
In the method that relies on the 3D photorealistic map, the accuracy of the image database has a great influence on the positioning result on the smartphones. In the experiment, the 2D pose results are from 2D LiDAR SLAM. The pose parameters of the image are calculated using the SLAM result and calibration information. The error is accumulated with the trolley moving. The accumulation error is large in the scanning trajectory, resulting in the inconsistency of the extrinsic parameters along different positions because of error propagation. In the multiview intersection, the intersection error of the control points on the image is big. The error has a great difference on the forward intersection result. In the experiment, the 3D coordinates in image database space of the control points on the wall, as shown in
Figure 9c, are using the forward intersection. The reprojection error is big when the exposure station is far away from each other. The min error is 1.0 pixel, and the max error is 43.3 pixel, as shown in
Table 4. The exposure locations of cameras are discontinuous, for example, 1.5 m one time. In the experiment, the distance is 0.8 m in average. The first row is the exposure station index, the second row is the reprojection error in pixel, and the third row is the multi-view forward intersection result in meter. The number headings 14-0 and 14-1 are the two images at the same station. The standard deviation of the errors is 15.96. If the exposure station is adjacent, the error is coincident, for example from 13 to 17, reprojection errors are all small, on the other hand, form 61 to 68, reprojection errors are all large. It is a long way for the trolley to move from station 17 to station 61, and the error accumulation is big, which brings error to the pose parameters of database images. As shown in
Table 4, the fourth row is the reprojection errors if separating the measurements into two parts, i.e., from 13 to 17 are group 1 and from 61 to 68 are group 2. The last row is the forward intersection result of each group. The difference of the results is 0.14 m.
After obtaining the coordinates of the control points in image database space, the spatial transformation can be calculated. The optimization in the spatial transformation adjustment does not converge [
51], because the error is gross. As shown in
Table 5, the average error is about 0.037 m, and the max error is 0.071 m.
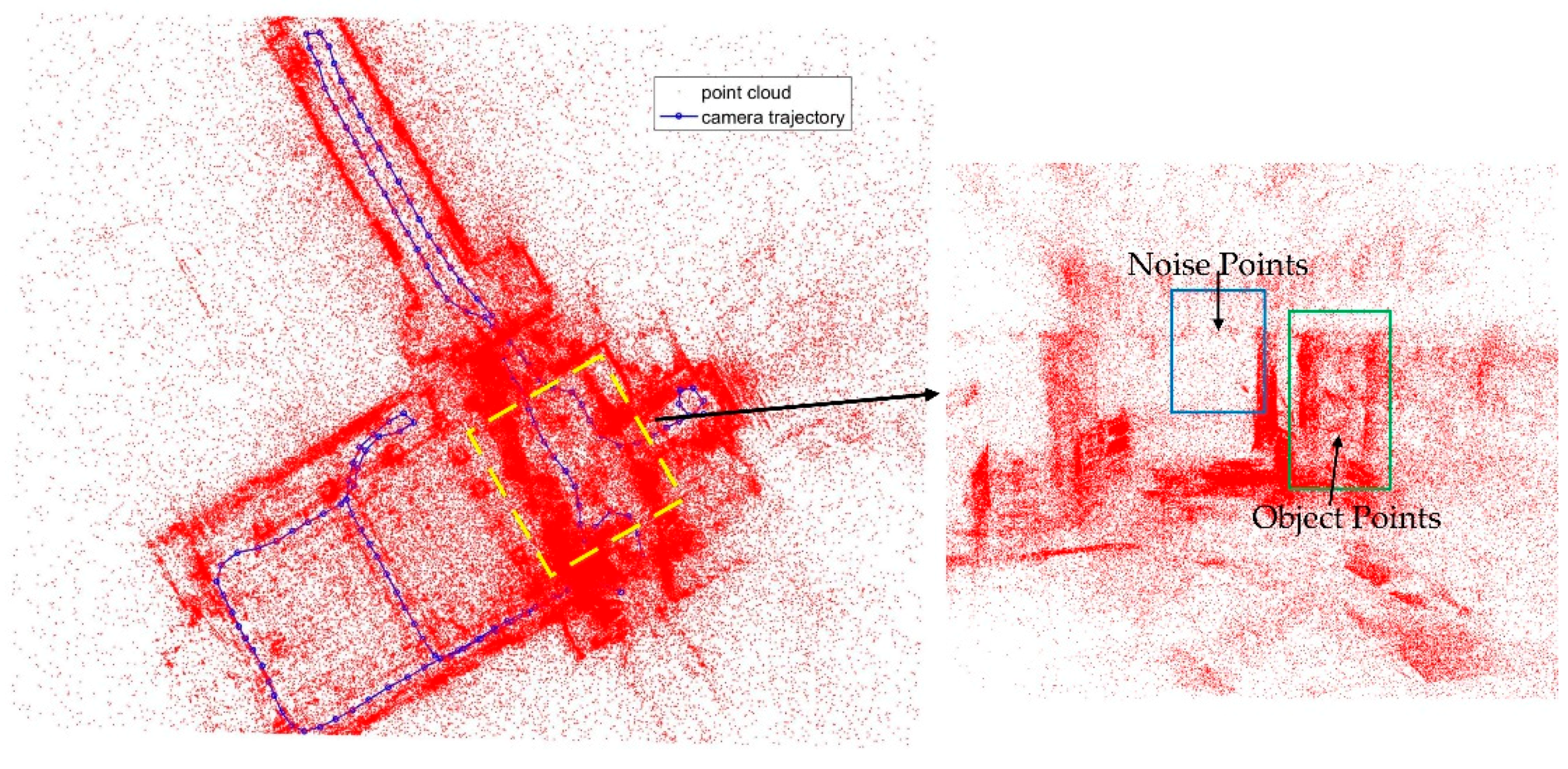
In the feature matching, because there are repetition features, and the number of overlap images is small, mostly 2 or 3 in the experiment, so there are many noise points in the feature point cloud. As shown in
Figure 14, there are some wrong points in the point cloud, mainly the low density points in the blue rectangle. This will bring errors to positioning result [
52].
In the PnP pose estimator, only focal length is calculated. The principal point and distortion parameters are not solved in P4Pf. An experiment with fixed focal length is adopted to analyze the error. Before capturing the images, the camera is calibrated.
As shown in
Table 6, in general, calibration of camera can improve the accuracy. The position error of 8 images is smaller than 0.6 m after calibration. The PnP methods are both sensitive to noise, for example image 3, 8, 9. On the other hand, the distribution of feature points has effect on the result.
After calibration, the focal length is obtained, i.e., f
x is 3365.81 and f
y is 3379.74 in pixel. As listed in
Table 6, the gross errors occur when the focal length is far away from the calibration result, for example image 2, 4 and 9. The difference is larger than 800. This is a useful threshold in RANSAC procedure. Using the constraint that the difference between the coarse length in EXIF information and the focal length of P4Pf is larger than a threshold, i.e., 800, in the experiment can improve the position accuracy.
Even though camera calibration improves the location accuracy, this brings a great problem to unprofessional users. Camera calibration is not easy for unprofessional users. In the experiment, after exiting from the build-in photo APP, the APP will be autofocus when opened in next time. The focal length will change and the calibration is needed again.
In the experiment, the distribution of feature points has an effect on the PnP result. Non-uniform distributed feature points give unstable pose estimates and sometime cause gross error [
44]. In dataset 1, the walls contain some features, and the distribution is better than dataset 2, as shown in
Figure 15. As shown in the blue rectangle in
Figure 15b, the number of feature points is 23, but they gather in a small region. This brings gross error in PnP estimator.
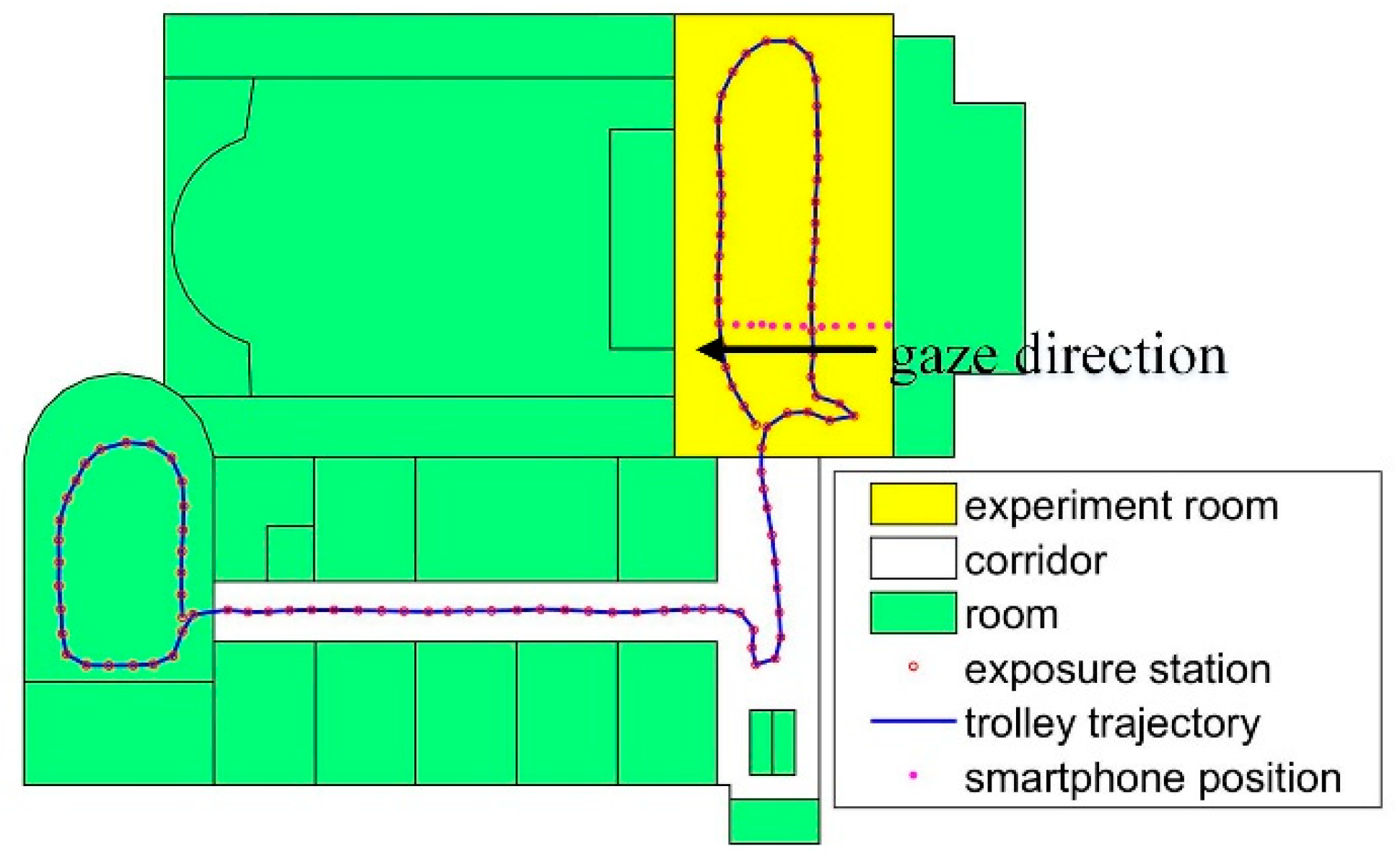
To analyze the effect of the distance to the objects, the images are collected in a line in the experiment, as shown in
Figure 16. The distance to the wall is from 2.20 m to 7.64 m.
There are 11 images in the test. The gaze direction is the black arrow shown in
Figure 16. The result is listed in
Table 7. Δ
d is the distance error from ground-truth point. There is no relationship between the accuracy and the distance to the objects, and the feature match errors and the distribution of feature points influence the location accuracy.
Changes in the scene also affect the method, as shown in
Figure 17, and sometimes, the furniture may move frequently in the scene. Some images could not be matched because of the changes, which results in gross errors.
The proposed method is a prototype system for smartphone indoor visual positioning. The processing of database images can be done offline, so only the computational time of processing the smartphone image is discussed following. The images are processed in the original size. The procedure is computed on the computer without parallel optimization, except the feature extraction and matching is using SiftGPU [
53]. The method is implemented with Microsoft Visual C++ under the Microsoft Windows 10 operating system. A personal computer with Intel Corei7-6700HQ, 2.59 GHz CPU, NIVIDA Quadro M1000M, 4 GB GPU, 16 GB memory is used. The image size and the number of feature points make a difference on the computational time. In the experiment, five images are used and average time is listed in
Table 8.
As shown in
Table 8, the total time is 1–2 min, and the feature matching takes the most time. In the experiment, only top 50 similar images are matched. Using hamming embedding to find similar images also costs a lot of time. In the experiment, the number of database images is 642, and if the number is larger, more time is needed. To reduce the computational time, a coarse position can be useful when only the adjacent images are compared in query. Using downsampled images can also improve computational efficiency in engineering.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}