1. Introduction
The Unmanned Aerial Vehicle (UAV) is an aircraft that flies without an onboard pilot while it is controlled remotely by a person or a computer system. The UAV is being applied in many sorts of different application fields. The cost reduction and technological advances are some of the reasons for this popularization. Applications in fields such as robotics and computer vision are the most popular. UAV have many benefits compared to land vehicles [
1], such as: (i) a UAV has more degrees of freedom to dodge obstacles; and (ii) a UAV can cover a wide area in fewer time [
2]. In comparison with computer vision applications using satellites, the UAV shows a remarkable advantage related to the increased amount of details provided in the captured images, allowing the detection of small objects; this is called tactical coverage [
3].
The tactical coverage allows using UAV in military and civilian applications, either in life-threatening or tiresome/stressful situations. The life-threatening situations include all situations that may lead to injuries of search and rescue staff, for instance, rescue missions in a hostile environment or in an environment contaminated by some toxicity. The tiresome/stressful situations include tasks such as surveillance in border regions or search and rescue missions in wide areas. All these tasks demand a higher degree of concentration for many hours in a row, which can be difficult for a person to maintain. Many academic studies have been conducted using UAV platforms in several applications: (i) detection and surveillance [
1,
4,
5,
6,
7,
8,
9,
10]; (ii) agriculture [
11,
12,
13]; (iii) 3D modeling [
14]; and (iv) remote sensing [
15,
16,
17].
Object detection is one of the main computer vision applications that employs UAV. This task includes search and rescue missions in areas, the access to which is difficult, wide searching areas or areas affected by natural disasters [
18]. Examples of these situations include the nuclear plant accident in Fukushima (Japan), Europe’s borders control, the hurricane disasters in the South of the United States or the disaster caused by Samarco’s dam collapse in Brazil. In all of these situations, surveillance actions are required as soon as possible in order to provide medical assistance effectively to the affected population. Fast and planned actions are crucial for saving as many lives as possible. However, in most of the cases, wide areas must be covered within a minimal amount of time, and thus, many UAV must be employed. As a result, an exploding number of images is captured, and they need to be analyzed in a reduced time frame. This analysis cannot be performed manually by a group of persons since this task is very tiresome, stressful and error-prone. Thus, the autonomous detection of pedestrians in aerial images must be applied.
Computer vision applications using images from UAV are complex because they involve many variables. These applications are sensitive to variations of the captured images: (i) images’ instability; (ii) small objects present a fewer number of pixels; and (iii) changes in camera position and angle due to the degrees of freedom of the UAV [
1]. The image instability occurs due to the platform movement and instability, which generates blurred images. UAV position (and its corresponding movement) changes the visual shape of the object, i.e., the target object size and position within the image changes. Such visual changes transform the appearance of the object, hindering the detection task. This behavior is called multi-viewpoint [
19]. The multi-viewpoint is influenced by the roll, pitch and yaw movements, i.e., the rotation of the UAV on the
x-,
y-,
z-axes. Image variations strongly influence the image recognition performed by computer vision systems. Visual variations affect the object shape, and thus, the systems are not able to generalize the problem [
20] (the term “problem” is used in this text to refer to both: (a) a thing that is difficult to achieve or accomplish; and (b) the process of detecting target objects within a PRS). This leads to a situation in which an autonomous system is efficient in several situations, but not in all possible situations. Such a system cannot be used in applications that require precision, such as surveillance tasks.
Recent studies have concentrated efforts on pedestrian and vehicle detection. We can separate the techniques used into two main approaches: (i) monolithic models [
1,
7] and (ii) part-based models [
5,
21]. The monolithic model considers the target object as a single object. On the other hand, the part-based models split the object into several parts. Each part can be learned by a classifier, turning the problem into multiple classification tasks. Most of the recent studies are based on hand-crafted features extracted from the images and submitted to a classifier [
1,
5,
7,
21]. However, this traditional pattern recognition approach is not efficient in problems that present a high influence of multi-viewpoint. As an alternative, the deep learning approaches have been applied. The Convolutional Neural Network (CNN) is one of the most successful deep learning techniques employed to classify images [
22]. For problems with strong multi-viewpoint influence, the CNN provides efficient solutions, since it is invariant to shift, scale and distortion [
23].
Despite the CNN recognition and detection capacity, such a technique requires many computational resources, e.g., processing units and memory. Another traditional technique used to detect pedestrians in aerial images is the sliding window. The algorithm splits an image into parts with a size of M × N pixels creating a sequence of Regions Of Interest (ROI), i.e., the algorithm extracts the first ROI from the pixels at the (0, 0) position, the second ROI from the pixels at (0 + stepX, 0) position, and so on. Thereafter, the classification algorithm is executed on all extracted ROI. Thus, depending on the size of both the image and the window, this technique processes thousands of ROI.
The CNN requires the use of at least one Graphics Processing Unit (GPU) to process the image within soft real-time constraints [
22,
24]. A GPU is an expensive processing unit (in comparison with regular CPUs) that consumes a higher amount of energy, which may raise several issues for the embedded computing system with which the UAV is equipped. In this situation, the use of a Mobile Ground Control Station (MGCS) emerges as an alternative to process the images captured by the UAV. The captured images are transmitted from the UAV to the MGCS, which, in turn, may use a GPU to process the aerial images. However, such a system architecture demands a reliable communication infrastructure that must fulfill not only the minimal bandwidth requirements but also the time constraints.
MGCS and embedded systems equipped with a GPU are still expensive computing platforms. Their use in conjunction with multiple UAV may create an unaffordable technology for search and rescue forces, especially in less developed regions. More economical computing platforms could help to overcome the cost issues. Therefore, it is worth investigating whether it is possible to decrease the PRS processing time, opening room for using less expensive computing systems in pedestrian detection systems. In this case, techniques to reduce the number of ROI to be analyzed by the classifiers improve the search and detection task performance. These techniques employ simple and efficient algorithms to detect the target objects of interest with a higher match probability, allowing the PRS to respond within a shorter time frame.
In this work, we propose to develop and assess some PRS using distinct machine learning techniques to detect pedestrians in UAV aerial imagery, considering the multi-viewpoint problem and a monolithic model. For that, we used robust techniques for pedestrian detection in images: Haar Cascade, Cascade with Local Binary Patterns (LBP), Histograms of Oriented Gradient (HOG) with Support Vector Machine (SVM) and Convolutional Neural Network (CNN). Considering the CNN, two distinct implementations have been created: one based on the architecture proposed by [
22] and the other based on [
25]. Both implementations use the Caffe Framework [
26]. To reach soft real-time detection constraints, we use two techniques to reduce the number of analyzed ROI: Saliency Map (SM) and Thermal Images Processing (TIP). It is important to highlight that the main contribution of this work is the evaluation and comparison of various PRS implemented using a combination of distinct techniques commonly applied in computer vision systems for pedestrian detection. Although we performed some modifications of the techniques used to implement these PRS, tailoring them to the pedestrian detection application is not a major contribution. We are interested in assessing the entire PRS and some of its steps individually. We aim to identify which combination of techniques can provide feasible and suitable results considering a set of low-cost sensors and processing units, e.g., inexpensive single-board embedded computers (such as Raspberry PI) and laptops without a GPU.
We conducted several experiments to assess the classification performance and the real-time processing capabilities of the developed PRS. For that, we evaluated each technique on its capacity to detect and classify pedestrians within the aerial images in two situations: (a) a person appears entirely in the images; and (b) only a part of the person appears in the images due to partial occlusion. The obtained results show that the CNN has the higher capacity for generalization, achieving 99.71% accuracy, followed by HOG + SVM with 92.36%. In the occlusion scenario, the better result of CNN is 71.1% accuracy. For the computing time performance evaluation, the experiments have been carried out on different platforms without GPU: MGCS (Intel i5-based laptop) and an embedded platform (Raspberry Pi 2). By using CNN and TIP, the PRS achieved a computing time performance of 2.43 fps running on the MGCS and 0.18 fps running on the embedded platform, both reaching a good classification performance (88.15% sensitivity and 99.43% specificity). Combining CNN with SM achieved the best classification performance (92.37% sensitivity and 88.93% specificity), but the computing time performance was 2× worse than CNN + TIP (1.35 fps running on the MGCS and 0.09 fps running on the embedded platform). On the other hand, by using HOG + SVM and thermal image processing, the PRS achieved 100 and 14 fps running on the MGCS and the embedded systems, respectively, both reaching a limited classification performance (62.96% sensitivity and 87.54% specificity). Combining SM, HOG, and SVM provides a better classification performance (74.05% sensitivity and 79.87% specificity), but the computing time performance is worse: 3.33 and 0.25 fps running on the MGCS and the embedded system, respectively. These results show that it is feasible to design a PRS for detecting pedestrians in aerial images that execute on a less expensive computing platform (in this case, the MGCS) with an acceptable computing time performance and a good classification rate.
In summary, this work’s contribution concentrates on the analysis and the assessment of combining distinct computer vision techniques to implement a pattern recognition system that executes on low-cost and resourceless computing systems. Therefore, this work presents the following contributions:
We evaluated the AlexNet [
22] performance (in terms of both classification and computational) on a classification task, which was not the original target application. We performed small modifications on AlexNet in order to allow detecting pedestrians in aerial images.
We evaluated another CNN architecture [
25], which has been successfully used in real-world situations for human biometric identification; not pedestrian detection in aerial images. This CNN presents a fewer number of parameters and layers. Such a feature impacts the computational performance by reducing the number of operations, which in turn, may allow the use of low-cost hardware.
We created a large dataset of aerial images depicting pedestrians that is suitable for deep learning techniques. For that, we combined existing datasets and performed a data augmentation process.
We assessed the performance of the classifiers in situations of pedestrian partial occlusion. We did not include any image of an occluded pedestrian in the training dataset and process.
We performed several experiments in real-world situations. These experiments included low-quality images captured by low-cost cameras affected by the instability generated during the UAV flight. These images have not been used in the training process either.
We evaluated the classification performance of some traditional computer vision techniques and also their computational performance running on low-cost hardware, e.g., Raspberry PI 2 and a laptop computer that uses an x86-based CPU without GPU. The goal was to check the feasibility and suitability of applying such techniques to low-cost embedded systems, in order to decrease the cost of a UAV equipped with a pedestrian detection system.
The remainder of this paper is organized as follows.
Section 2 discusses some related works.
Section 3 provides an overview of the important concepts and techniques used in image pattern matching problems.
Section 4 details the proposed approach.
Section 5 discusses the obtained results. Finally,
Section 6 draws some conclusions and indicates some future work directions.
2. Related Work
Several methods and techniques have been used in object detection in aerial imagery. Most of these works target the following objects of interest: people, vehicles, forests, towns, and plantations. The methods used can be separated into two main categories: Movement-Based Detection (MBD) and Stationary-Based Detection (SBD). The main difference between these methods is how the regions of interest are pre-classified. However, both methods use machine learning techniques to classify these regions.
The MBD techniques are able to detect objects that present movement between a set of frames [
27,
28]. This is a serious limitation for search and rescue missions since static objects are ignored and processed as background. On the other hand, SBD uses information from a single frame to detect ROI. This method requires brute-force approaches for segmentation and detection, such as sliding windows, or more sophisticated algorithms to reduce the space of search. An extensively-used technique is thermal image processing [
1,
10,
21,
29]. This kind of technology provides thermal information that can be used in applications where the object of interest has a constant temperature, e.g., people or other species of mammals.
In the region classification step, two main methods are used [
5]: monolithic models and part-based models. The monolithic model processes the object as a single element; thus, the classification is based on all parts of the object. On the other hand, in the part-based model, the object is decomposed into several elements that can be independent or interconnected. The monolithic model is simplistic, but it has disadvantages in situations of object occlusion. In another way, the part-based model is more robust, but it demands complex machine learning techniques and also requires much information to be processed. For aerial imagery applications, the monolithic model is more suitable, since the objects of interest in these applications have a small set of pixels to be processed.
The study conducted in [
5] focused on people detection in indoor environments for search and rescue missions. In fact, the images used by the authors suggested an application closer to pedestrian detection. However, the main contribution of the work was in the situations of object occlusion. Part-based models are used for this task since, in several situations, people are partially occluded by desks, chairs and other objects commonly found in corporate environments. Three algorithms are used in combination: Pictorial Structures (PS) [
5], Discriminately-Trained Models (DPM) [
30] and Poselet-Based Detection (PBD) [
31]. The PS divides the people body image into several independent elements, where the recognition is realized using AdaBoost [
32]. Similar to PS, the DPM also splits the person body image into several parts, but in this algorithm, one element is defined as the main element to which all other elements are attached. The DPM uses support vector machine [
33] to detect the body elements. The PBD is similar to PS; the difference is that the PBD classifier is executed by the template matching algorithm.
The people detection in aerial imagery is the main subject of [
34]. In this work, the rotation on the
x-,
y-,
z-axes (i.e., pitch, roll and yaw) is considered. Using Integral Channel Features (ICF) [
35] and Cluster Boosting Tree (CBT) [
36], some detectors were proposed. According to the authors, these features and classifiers were chosen due to the good computational performance in situations in which the cameras’ angles change frequently. Three detectors were proposed based on the rotational degrees of freedom: Pitch-trained Detector (PD), Roll-trained Detector (RD) and Pitch- and Roll-trained Detector (PRD). The experiments evaluated the classification rate and processing time and with roll and pitch variation. In comparison with [
34], this work employs different feature descriptors and classifiers, as well as it analyzes the model’s performance in some distinct angle ranges. In addition, our work performs an extensive and more comprehensive analysis of the computing time performance.
Some studies [
7,
37,
38] applied shadow detection algorithms to detect people and vehicles in aerial imagery. Shadows are often hindering in this sort of applications because it is difficult to separate the shadow of the object of interest. The work presented in [
7] uses shadow detection and also geographic metadata to estimate the shadow position and reduce the time of the classification step. To detect the person in the estimated region, the sliding window algorithm was used; each ROI was processed by a pre-trained SVM with Haar features.
A popular approach used by several authors in the literature [
1,
4,
10,
29,
39,
40] is thermal image processing. Some approaches use only thermal images, ignoring RGB images, while others use thermal images only in the detection process. By using thermal images, it is possible to obtain solutions to the traditional problems in people detection and recognition: low contrast, crowds, changes in visual conditions and others. Thermal images are especially suitable for applications in which the target object temperature is constant. The segmentation process using thermal images does not demand much processing time, making such a technique suitable to be used for embedded applications, such as a UAV equipped with an embedded PRS. In addition, in [
4], thermal images were used to detect ROI that have a high chance of depicting pedestrians in aerial images before the classification step, which in turn, is executed on the RGB image. On the other hand, Ref. [
1] applied Haar cascade [
41] to detect vehicles and people in thermal images, whereas the work presented in [
10] applied HOG features and SVM to detect and track people in aerial images in several scenes.
The study conducted in [
8] used the image processing algorithm, the Felzenszwalb graph cut method, to detect regions’ disparities and to classify them as a pedestrian or not. Multi-Scale Histogram of Oriented Gradients (MS-HOG) was used in combination with several classifiers. The study reached good results with more than 95% of the ROC curve area, despite the low resolution of the images in the experiments. It is important to notice that PRS implemented in [
8] demands a higher processing time, due to a large number of objects detected by the segmentation algorithm. Our work, on the other hand, provides a computing time performance assessment in order to check what combinations of computer vision techniques can execute on low-cost computing devices and also reach the system time constraints.
In general, the studies presented in the literature focused just on recognition or detection process. Several approaches in the literature are not suitable for real-world applications, due to the long processing time of the systems. Furthermore, some detection techniques are not robust enough to deal with several camera angle variations or object pose diversity. In this work, we used a deep learning technique to detect pedestrians in aerial imagery and compared the results with traditional hand-crafted feature approaches that are usually used in this sort of PRS. We also compared the computing time of an entire PRS executing on top of two different computing platforms; the worst-case scenario is analyzed and discussed. Another contribution is the use of low-resolution thermal cameras for detection (80 × 60 pixels resolution), while the mentioned related works used cameras with higher resolution, e.g., at least 320 × 240 pixels.
4. Materials and Methods
4.1. Overview of the Research Method
This work is focused on autonomous pedestrian detection in UAV aerial imagery for search and rescue missions. For that, we used the pattern recognition systems concepts. Therefore, it is necessary to establish an adequate classifier and to train it properly. Following the PRS concept, we defined a workflow based on a dataset that contains several situations in pedestrian detection. These situations include pedestrians in different poses, as well as distinct rotational degrees of the aerial platform. Thus, we used the dataset to train, validate and test the classifiers. Lastly, we performed some experiments using the proposed techniques in several real-world situations in order to evaluate the combined techniques in terms of both classification capacity and computational performance.
Figure 3 shows the workflow used in this work.
In the first step, we defined a consistent dataset for pedestrian detection in aerial imagery. The dataset contains the objects of interest in several situations, i.e., people in several activities. Moreover, the dataset contains images captured by onboard cameras of aerial platforms including several variations of roll, pitch and yaw angles. Since the CNN needs a large-scale set of data for the training step [
47], we conducted a data augmentation process to increase the number of samples in the dataset.
Following the traditional training procedure of machine learning algorithms, it is necessary to split the dataset into training, validation and test sets [
44]. The training samples are used to train the classifier and to tune its parameters. The validation samples are used in the classifier training to evaluate the training result and improve the parameters’ adjustment. The validation process is used to prevent the overfitting, i.e., when the classifier becomes too closely or exactly adjusted to the training data. An overfitted classifier is not able to classify new samples submitted to the classifier correctly; only the ones used during training. We executed the classifier training according to the best parameters (see more details in
Section 4.4) adjusted for our image datasets. We used the same set of images for all classifiers for the training, validation, and test. Thereafter, the test images are used to validate the classifier model created in the training step. Finally, it is worth mentioning that, by combining distinct computer vision techniques, we implemented and assessed five distinct PRS. We combined Haar features and LBP features with the cascade classifier, which are extensively used in the literature [
29,
48,
49]. We combined HOG features with the SVM classifier since it is widely used in pedestrian detection [
50,
51]. We used the convolutional neural networks due to the solid results obtained in object identification competitions [
22] and other applications for people detection [
24,
25].
In the experiment phase, we carried out four sorts of experiments: (i) detecting objects of interest (detection experiments); (ii) detecting objects of interest that are partially occluded; (iii) PRS classification performance and (iv) PRS computing time performance executing on two distinct hardware platforms. In the detection experiments, we assessed Haar + cascade, LBP + cascade, HOG + SVM and two architectures of CNN on their capacity to classify pedestrians in aerial imagery correctly. The occlusion experiments are aimed at assessing the classifiers’ capability of generalization. For that, we added the image of a tree overlapping the pedestrian image artificially. This procedure hides a portion of the object of interest simulating the partial occlusion, which is a common situation in aerial imagery.
Finally, we evaluated the PRS detection and computational performance. For that, we varied the implementation of the PRS by combining the five classifications methods with two distinct segmentation techniques: Saliency Map (SM) and Thermal Image Process (TIP). Therefore, ten distinct combinations were implemented and assessed in terms of classification and computing time performance. The classification performance was evaluated by means of accuracy, sensitivity and specificity metrics. The computing time performance was evaluated by measuring the execution time of the ten PRS combinations on two low-cost computing platforms: an inexpensive single-board embedded computer (Raspberry PI 2) and a regular laptop without a GPU. Details are provided in the following sections.
4.2. Images Dataset
In this study, we merged some image datasets to create a larger dataset that presents pedestrians in several poses. The dataset includes a wide diversity of images in several rotational angles captured by onboard cameras on UAV platforms. We selected three image datasets: GMVRT-v1 [
42], GMVRT-v2 [
34] and UCF-ARG Dataset [
43]. These datasets contain aerial RGB images of pedestrians (positive samples) and non-pedestrians (negative samples). All samples are segmented images. Most of these images depict pedestrian silhouettes. It is important to notice that these RGB images were used in the classifiers’ training and testing, whereas the thermal images were used just in PRS experiments.
The image dataset GMVRT-v1 [
42] contains pedestrian and non-pedestrian images. It presents a broad variety of pedestrian images in several rotational angles, roll, pitch, and yaw, with a variation between 0
and 90
. The dataset provides images of pedestrians in several poses with different kinds of clothes. The negative samples (non-pedestrian) are a set of urban and countryside segments of objects. Originally, the images were available in the RGB format with a color depth of 24 bits per pixel in JPEG format and a resolution of 64 × 128 (width × height) pixels. The dataset contains 4223 positive images and 8461 negative samples.
Figure 4a,d depicts some samples of the GMVRT-v1 dataset.
The GMVRT-v2 dataset [
34] provides 3846 pedestrians samples in a large variety of poses and rotational angles. While the GMVRT-v1 contains images of several people in the same environment, the GMVRT-v2 contains pedestrians on beaches, streets, grass, sidewalks and other places. Moreover, the dataset provides 13,821 negative samples with the same variety of places. The pedestrian images are segmented into 128 × 128 pixels, 24 bits and PNG format. In addition to the training samples, the GMVRT-v2 contains a set of 210 test images. These images contain three or four pedestrians in the rural environment. The camera angles vary between 45
and 90
. To increase the number of samples to train and test the classifiers, we selected two positive samples of each image with a size of 128 × 128 pixels. A total of 420 new pedestrian samples in PNG format has been added to the dataset. The original images of the GMVRT-v2 test set are in JPEG format with a size of 1280 × 720 and 24 bits of color depth.
Figure 4b,e shows some samples of the GMVRT-v2 dataset.
The UCF-ARG dataset [
43] is a video dataset. It provides a total of 1440 videos that have been captured from three cameras from different point views: aerial, terrestrial and on a rooftop. For each camera position, the dataset contains 480 videos with a resolution of 960 × 540 pixels and 30 fps. These videos show pedestrians executing ten sorts of actions, e.g., punching, carrying objects, walking and digging. We extracted one frame randomly from the 480 videos from the aerial perspective. From these frames, we selected 410 frames and extracted manually the pedestrian images with 128 × 128 pixel resolution in PNG format. A total of 70 frames were excluded because the pedestrian images presented noise or distortions Such a dataset is an interesting dataset for pedestrian applications since it provides images with small variations of scale and poses for the same pedestrian.
Figure 4c depicts some samples of the UCF-ARG dataset.
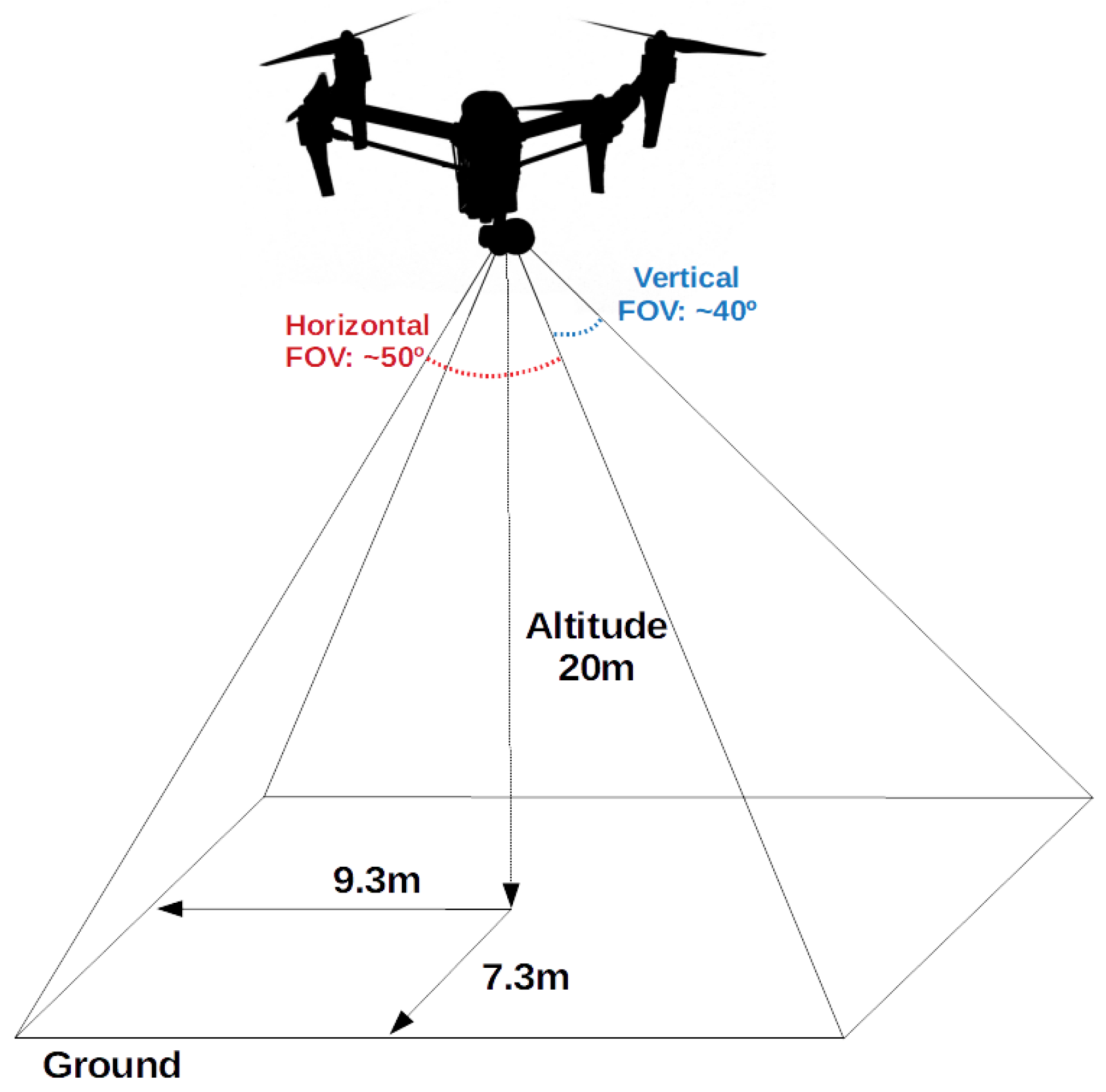
For the PRS experiments, we also collected a set of seventeen RGB and thermal images. The RGB and thermal cameras were positioned on the top of a building to simulate the situation of UAV flying with an altitude of 20 m. The target environment is a garden between two buildings. We obtained the RGB images with a resolution of 1280 × 720 pixels and thermal images with 80 × 60 pixels, both with 24-bit color depth and PNG format.
Figure 5 shows the RGB and thermal images used in the experiments. We also collected images using a quad-rotor UAV to perform an experiment similar to the real-world situation.
Figure 6 shows the UAV platform used in the image extraction. The platform comprises one FLIR Lepton Long Wave Infrared sensor, one Raspicam and one Raspberry Pi 2. The videos were collected in three environments: (i) a grass field; (ii) a grass field with a building and (iii) a street with the sidewalk. For that, we collected eight RGB and eight thermal short videos with the quad-rotor UAV flying at an altitude between 15 and 20 m. Each video has a length of 30 s and 10 fps. Each RGB video was collected with a resolution of 1280 × 720, whereas the thermal video has a resolution of 80 × 60. We extracted randomly 15 frames from each video to perform the PRS experiments. Actually, we selected only 15 frames from each video since we performed the analysis manually. It is important to highlight that these images contain several situations commonly found in the real world such as blurred objects and images with noise. Moreover, each image depicts only one person, and hence, in the 120 selected images, 120 people must be identified. Finally, we merged the images captured in these two ways (i.e., by flying with the UAV and also with the cameras positioned on top of a building) into a single dataset. Therefore, this image dataset contains 137 images with 137 people in real-world situations. Such a dataset can also be considered a contribution of this work since it is available for others to use (see
https://github.com/lesc-utfpr/pedestrian-detection).
4.3. The Dataset Augmentation
The convolutional neural network is a type of feed-forward artificial neural network. CNN is a machine learning method that uses an extensive set of parameters during the training process. However, like other traditional machine learning techniques, the CNN is susceptible to the curse of dimensionality [
52], i.e., as the problem dimensionality increases, more data are necessary to build a model that satisfies the problem requirements and criteria. As the CNN is larger than an ordinary neural network, the number of weights to balance the network increases, leading to the curse of dimensionality problem. For most of the computer vision applications, it is very hard to acquire a large image dataset. An enormous effort is also necessary to label the data for a supervised training process. An option to decrease the effect of the curse of dimensionality is to perform the data augmentation process, i.e., artificially augmenting the number of samples in a dataset. The image dataset augmentation consists of generating “new” samples applying small modifications and also filters on the original dataset samples. In addition to increasing the amount of data, the data augmentation is useful to balance classes when the dataset is unbalanced.
In this work, we applied a data augmentation process similar to [
25]. The process consists of image processing filters that randomly change the original dataset samples, and thus, each sample can be modified by one or more image transformation filters. The transformations performed randomly are: (i) translation (±20 pixels on
x and/or
y axis); (ii) scale (between 0.95 and 1.2) and/or (iii) rotation (between −20
and 20
). Each transformation is performed on a given sample with a probability of 50%.
Figure 7 shows some new samples created during the data augmentation process.
After the data augmentation, the number of dataset images increased from 31,184 samples to 44,765, i.e., an increase of 13,381 positive sample images. The augmentation process created a balance in that the dataset provides 22,483 pedestrian samples and 22,282 non-pedestrian samples.
4.4. Classifiers Training
In this work, we applied different classifiers to train and detect pedestrians in aerial imagery: the cascade classifier, SVM, and CNN. These classifiers have a distinct training process and parameter definitions. In order to achieve better results, we executed some preliminary training with all classifiers, and according to the results, we defined the most suitable parameters for each classifier. For this process, we split the dataset into three parts: training, validation and test samples. We split the dataset using the holdout cross-validation [
44]. We intended to use k-fold cross-validation. However, due to time constraints for using the GPU cluster to train the neural networks, we chose to use holdout (instead of k-fold) to have more time to run more experiments. The dataset was split following a given proportion. Each sample set is used once in the process, i.e., the training set is used during training to train the classifier, the validation set is to validate the classifier while it is being trained, whereas the test set is used to test the trained classifier. A sample defined as a training sample was not used in the validation or test. This process ensures that the classifier will not be affected by overfitting, allowing the model to generalize the problem efficiently. In this work, we split the dataset as follows: 80% of the samples for training, 10% for validation and 10% for the test.
We executed the cascade training using the implementation available in the OpenCV library. This implementation does not require validation; thus we discard the validation set sample. We trained the classifiers using Haar and LBP features descriptors with the classic AdaBoost version [
53]. Cascade was configured as follows: 15 levels in training, false alarm rate of 0.5 and true positive rate of 0.95.
Similar to the cascade classifier training, we trained the SVM using the OpenCV implementation without executing a validation step. The SVM was trained with HOG features, a linear kernel and stop criteria of error or 100 thousand iterations. We defined the HOG features with nine bins, a block size of 32 × 32 and a cell size of 16 × 16, which totaled 8100 features per sample.
Unlike cascade and SVM, the CNN requires many more parameters for configuration. The CNN requires the architecture definition: a set of convolutional filters must be defined to automatically extract representational features. In this work, we used two CNN architectures, which were named CNN1 and CNN2.
The CNN1 architecture was proposed in [
25] for human biometric identification based on clothes and gender. The CNN1 achieved high accuracy results (greater than 70%). We used the CNN1 architecture because it is used in an application related to people identification, and hence, it has a good chance to achieve good results in pedestrian identification in aerial imagery. Moreover, this architecture was defined with a lower number of layers that may reduce computing time processing since a reduced number of floating point and dot product operations need to be executed. It is important to mention that the computational performance of this CNN architecture was not assessed in [
25].
Figure 8 and
Table 1 show the CNN1 architecture. The first six layers (Conv1, Pool1, Conv2, Pool2, Conv3 and Pool3) are related to the feature extraction. These feature extractors are defined during the training step, according to the training sample information. As one can see, there is a ReLU max function between Convolutional (Conv) and Pooling (Pool). The ReLU (rectifier) function is the activation function. ReLU max allows non-linearity instead of linear activation functions commonly used in CNN. The following two layers are called fully-connected layers, and they are responsible for the classification using the features extracted in the previous layers. Fully-connected layers are similar to shallow neural networks (i.e., the conventional neural networks), in which all neurons are connected to each other. The last layer produces the final decision, i.e., the classification result. As the problem has two classes, this layer comprises two neurons; one to represent the pedestrian classification and the other to indicate the non-pedestrian classification.
The CNN2 architecture is the well-known AlexNet that was proposed in [
22]. This architecture is widely used in various CNN applications since it was the first CNN used in the ImageNet Large Scale Image Recognition Competition (ILSVRC) [
54]. In ILSVRC 2012, AlexNet beat the second-place competitor by 9.7% accuracy. Recently, other effective architectures [
55,
56] have been proposed and used in the ILSVRC; it is worth mentioning that the top rates in this competition have been obtained by CNN approaches. We chose to use the AlexNet architecture due to its reduced number of layers and low complexity in comparison with other CNN architectures and also because we did not have access to a dataset with millions of samples. As we already commented, the larger the number of CNN layers, the larger the dataset needed to obtain adequate results. Moreover, the pedestrian detection in UAV imagery is an application that presents soft real-time constraints, and thus, a complex CNN can hardly meet such constraints running on a low-cost computing system such as an embedded system.
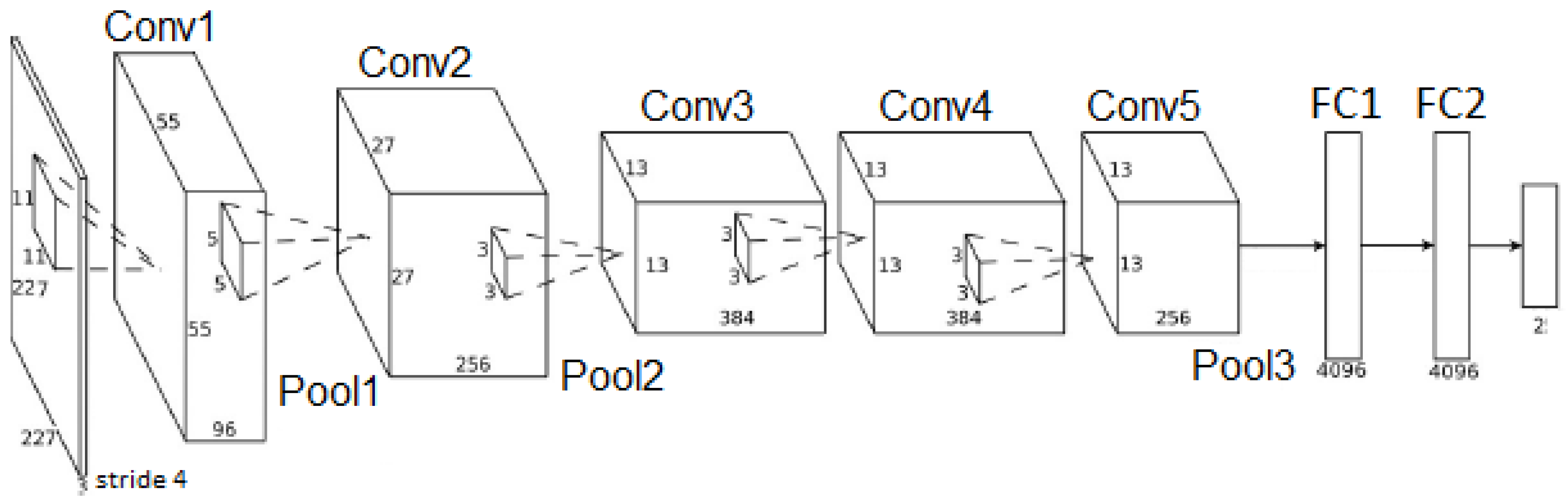
Figure 9 and
Table 2 show the AlexNet architecture. The first eight layers (Conv1, Pool1, Conv2, Pool2, Conv3, Conv4, Conv5 e Pool3) are dedicated to feature extraction. A ReLU function acts as the activation function after each convolutional layer. Similar to CNN1, CNN2 contains two fully-connected layers to execute the classification step, and also, the last layer presents two neurons that correspond to pedestrian and non-pedestrian classes. It is important to highlight that the original AlexNet was adopted in this work. As the target application presents only two classes (i.e., pedestrian and non-pedestrian), we reduced the number of output neurons from 1000 to two neurons in the last CNN layer.
For training both CNN architectures, we used the training and validation sets with holdout cross-validation. The weights are adjusted by the back-propagation algorithm with SoftMax as the loss validation metric [
23]. We used the Step Gradient Descent (SGD) algorithm to optimize the CNN. We adjusted the learning rate to 0.005, which is increased by the product of 0.1 every 30 epochs. Furthermore, we used 0.9 as the momentum used to converge the training method. Lastly, we defined the maximum number of epochs as 1000. We defined the number of epochs based on our preliminary experiments [
4] in which the CNNs converged between 600 and 800 epochs. We defined the 1000 epochs limit to prevent any loss if any CNN took more epochs to converge. To avoid overfitting, we applied the dropout technique with a 50% rate. The dropout randomly excludes some neurons of the fully-connected layers on each training step with a probability of 50%. This technique is widely used in CNN and significantly improves the network generalization process. These parameters have been used in [
22,
25].
The CNN training process demands an enormous amount of processing due to a large number of parameters and weights that need to be adjusted during the process. Therefore, we executed the training using a general purpose GPU. The GPU is able to provide a faster training by applying the mini batch approach [
22]. The mini batch selects a set of images that are loaded into the GPU memory; these images are used in the weights’ adjustment with back-propagation on each step. According to [
22], the mini batch influences the loss function; the smaller the mini batch, the more instability the loss function presents. Thus, a large mini batch results in stability, but it requires a GPU with more memory. In this work, we used a mini batch of 128 images for each step.
4.5. Combining Computer Vision Techniques to Implement PRS for Pedestrian Detection in Aerial Imagery
As mentioned, one of the goals is to evaluate the feasibility and suitability of combining distinct computer vision techniques to implement a PRS to detect pedestrians in aerial images captured by onboard cameras of multi-rotor UAV. Therefore, we implemented 10 different PRS. Each PRS was evaluated on its classification capacity in two situations: (i) when the pedestrians appear entirely in the images and (ii) when some part of the pedestrians is hidden due to partial occlusion. Furthermore, these PRS are expected to run on top of low-cost computing platforms, e.g., single-board embedded computers such as the Raspberry Pi or regular laptops without a GPU. Therefore, we performed: (i) an assessment of classification performance; and (ii) an assessment of the computational time performance. The set of implementations follows the PRS steps discussed in
Section 3.2.
Figure 10 shows the PRS steps and the techniques used in each step. As one can see, we combined two segmentation methods with five features and classifiers, resulting in 10 implementations of pedestrian detection PRS.
In the acquisition step, we used two low-cost sensors: a thermal camera and an RGB camera. The former has a FLIR Lepton Long Wave Infrared sensor (
http://cvs.flir.com/lepton-data-brief) that captures thermal images with a resolution of 80 × 60 pixels (the maximum resolution of the device) at 60 fps. The FLIR camera seems a fair alternative to be used in this sort of application, instead of an expensive solution using thermal cameras with higher resolutions, which may cost much more than the UAV itself. The latter is a Raspicam camera module v1 (
https://www.raspberrypi.org/documentation/hardware/camera/README.md). Raspicam captures images with a maximum resolution of 2592 × 1944 up to 15 fps; they are sent via a serial interface. To keep the coherence between the images generated by the thermal and RGB cameras, the acquisition processes were executed in parallel. Hence, the images generated by both cameras contain information of the same scene captured almost at the same time instant. It is important to mention that a difference of 10 ms may exist between one thermal image and one RGB image due to the difference in the frame rate of the cameras. However, this difference is not significant in the detection and classification process for the target application.
In the segmentation step, we used two methods to segment and detect the pedestrian: Saliency Map (SM) and Thermal Image Processing (TIP). SM uses the RGB images to detect small discrepancies in the scene. The SM algorithm takes the RGB image as input and outputs a grayscale image with small discrepancies. In our PRS, the grayscale image is submitted to a thresholding process that transforms the image into a binary image. Such a binary image allows a faster object search process since the algorithm needs only to look for pixels the value of which is equal to 1. Thus, the Regions Of Interest (ROI) are extracted when the algorithm finds a set of neighbor pixels the value of which is 1. This ROI is checked before being submitted to the feature extraction. Objects that show a width or height less than 256 pixels are discarded, to remove regions that hardly contain an ROI that depicts pedestrians. Objects with higher dimensions are normalized; thus, all objects submitted to the classifiers have the same dimensions of the training samples: 256 × 256 pixels.
On the other hand, the TIP segmentation detects pedestrians by checking their thermal signature. The thermal image was captured in grayscale format and was submitted to a thresholding process, as well. Pixels whose value is between 95 and 105 (the gray values’ interval between 95 and 105 corresponds to temperatures between 29
C and 36
C, approximately) receive a value of 1, whereas the other pixels receive a value of 0. We defined this interval during the experimentation by observing the thermal images and comparing them with the corresponding RGB image. The detection process is similar to the SM process, i.e., the ROI is identified as a set of neighbor pixels the value of which is 1. In the TIP segmentation, the thermal image ROI are not submitted to the classifier. The ROI is extracted from the corresponding RGB image by using the centroid of the thermal image ROI as the reference. The following equations are used to identify the centroid of the RGB image ROI based on the thermal image ROI:
where
x and
y are the centroid coordinates in the thermal image ROI,
W is the image width and
H is the image height. By using the calculated centroids, an ROI with a size of 256 × 256 pixels is extracted from the RGB image and submitted to the classifier.
After the segmentation and detection, the ROI was submitted to the trained classifiers. Since we used deep learning techniques to extract features and classify them, we consider these two steps as a single one. Therefore, the following techniques were combined: (i) Haar features and cascade; (ii) LBP features and cascade; (iii) HOG features and SVM; (iv) CNN1; and (v) CNN2. Using the parameters and the model constructed during the training phase, each ROI extracted from the image samples were submitted to all of these classifiers, which, in turn, classify the ROI as either pedestrian or non-pedestrian.
Finally, in the decision step, the image objects were labeled according to the result provided by the classification step. In order to better visualize the results, the ROI classified as a pedestrian are highlighted with red rectangles in the image.
6. Conclusions
New applications that employ UAV have emerged due to the popularity and cost reduction of UAV platforms, especially multi-rotor UAV. One of these applications is the detection of pedestrians in aerial imagery using computer vision and pattern recognition techniques. This application can be used in many situations such as search and rescue missions and surveillance. Search and rescue missions require much time and effort from the rescue teams, especially when the analysis of the captured image is done manually by a human being. Such a repetitive and error-prone task can be executed autonomously by a computer vision system. In this work, we developed and evaluated various pattern recognition systems (based on [
44]) for an autonomous pedestrian detection system. These PRS have a sequence of steps that include: image acquisition, detection and segmentation, feature extraction, classification and post-processing. We implemented each step with different techniques. For the segmentation and detection algorithms, we used: saliency map and thermal image processing. In feature extraction and classification, we used: HOG + SVM, LBP cascade, Haar cascade and two CNN architectures. We performed several experiments to assess the implemented PRS in terms of their classification capacity and their respective computing time performance. We evaluated both the entire PRS implementations and also some of their steps separately. The goal was to assess the feasibility and suitability of executing these PRS on low-cost computing systems such as embedded systems or regular computers without a dedicated GPU.
The experiments reveal exciting results, especially in classification performance assessment. By using the CNN, we achieved the best classification rates, which were close to 100%. This seems to justify the increasing interest in using CNN in computer vision applications. The results obtained in the HOG + SVM experiments show that such an approach is suitable and robust for people classification tasks. HOG + SVM was able to classify with more than a 90% accuracy rate in spite of the presence of variations in the perspective and object poses and shapes. On the other hand, the cascade classifiers presented the worst results: less than a 70% accuracy rate. This classification performance seems to indicate that texture-based feature descriptors are not suitable for pedestrian detection in aerial images. In the experiments that included object occlusion, CNN2 showed impressive results, achieving more than 70% accuracy. This accuracy indicates good performance in spite of the occlusion of 25% on the ROI that depicted the pedestrians. The others classifier achieved only 50% or less in their classification rate in the occlusion situations, indicating a classification performance closer to a random classification.
The combination of computer vision techniques used to implement different PRS has also been assessed in terms of classification capacity and computing time performance. We assessed the entire PRS and also some of its steps. We performed some experiments with segmentation and detection techniques, namely SM and TIP. Both techniques show advantages and disadvantages in several aspects. SM detects more ROI, which presents a direct impact on the number of objects to be classified, demanding more computational resources to process all selected information. On the other hand, SM presents a better precision of the segmented ROI as an advantage, since this leads to less translation, improving some classifiers’ results such as HOG + SVM. TIP requires fewer computing resources as it detects a lower number of ROI, and hence, it submits less ROI to the classification step, decreasing the computing time as a whole. However, TIP presented some issues during image segmentation related to some translation effects that influence the classification step. In addition, TIP has some limitations associated with the environmental conditions. For instance, in environments with a temperature greater than 30 Celsius degrees, the thermal camera used is not able to detect the thermal signature of a human being. Finally, the detection and segmentation techniques influence the PRS performance since they reduce the number of objects submitted to classifiers. Other popular approaches as sliding windows require that several ROI be classified, which consumes much time and computational resources. Using the sliding window with ROI of 256 × 256 and with a one-pixel step in images of 1280 × 720, it would be necessary to classify 476,625 ROI. Using the HOG + SVM to classify all ROI of the sliding window in images of 1280 × 720 would require more than 330 s.
We have also assessed the execution time of the PRS on two platforms: an embedded system (a Raspberry Pi 2) and a Mobile Ground Control Station (a notebook with Intel Core i5-3210 2.5 GHz without a dedicated GPU). In general, the experiments carried out with the embedded system did not show good results because only the PRS implemented with HOG + SVM + TIP achieved a performance of at least 1 fps. On the other hand, most PRS implementations executed on the MGCS achieved a performance of more than 1 fps. Segmentation and detection steps have a considerable influence on the PRS computing time performance. SM is responsible for a great percentage of the total PRS computing time, whereas TIP used only 1% of the total execution time. Since the classification is the most time-consuming step in PRS, the detection algorithm influences the entire system performance: the lower the number of segmented ROI, the shorter the time (as a whole) needed to classify them. In the classification step, PRS implemented with CNN presented a higher execution time (but the best classification performance), followed by the cascades and HOG + SVM, respectively. It is important to highlight that HOG + SVM+TIP achieved an impressive result of 100 fps when executed on the MGCS and 14 fps on the embedded system both without using GPU acceleration. However, it is important to highlight that HOG + SVM classification performance degrades when there is occlusion of the pedestrian.
As future work, we will continue studying CNN, since it has shown great potential for pedestrian detection, even in situations with partial occlusion. Despite demanding more computational resources, our CNN implementation can be optimized and used in real-world applications by means of using GPUs, FPGAs or even special resources of ARM processors to improve parallelism. The NVIDIA Jetson platform seems to be a good option to use in future works since it provides a GPU embedded into a small-sized printed circuit board. Such a parallel hardware can provide the required computing time performance for the CNN-based PRS for pedestrian detection in aerial imagery. Another option is the optimization of CNN architectures by using techniques to reduce the number of parameters and multiplications with floating-point operations.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}