Advanced Heterogeneous Feature Fusion Machine Learning Models and Algorithms for Improving Indoor Localization †

Abstract
:1. Introduction
1.1. Related Works
1.2. Motivation and Contribution
1.3. Organizations
2. Machine Learning for Indoor Localization
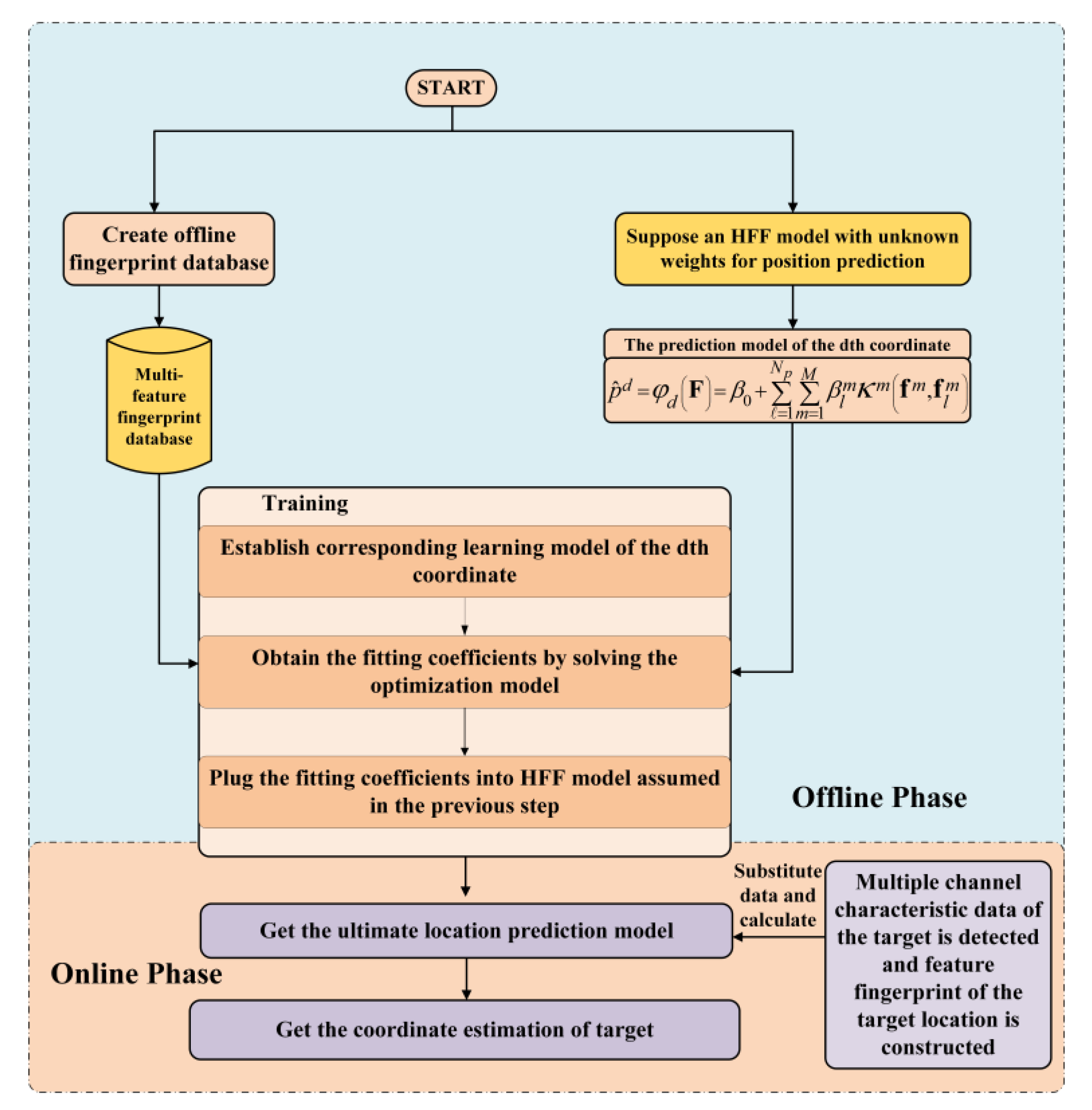
3. Fusion Machines Models and Algorithms
3.1. Heterogeneous Feature Fusion Ridge Regression (HFF-RR)
3.2. Heterogeneous Feature Selection using Group LASSO Penalty (HFS-GLP)
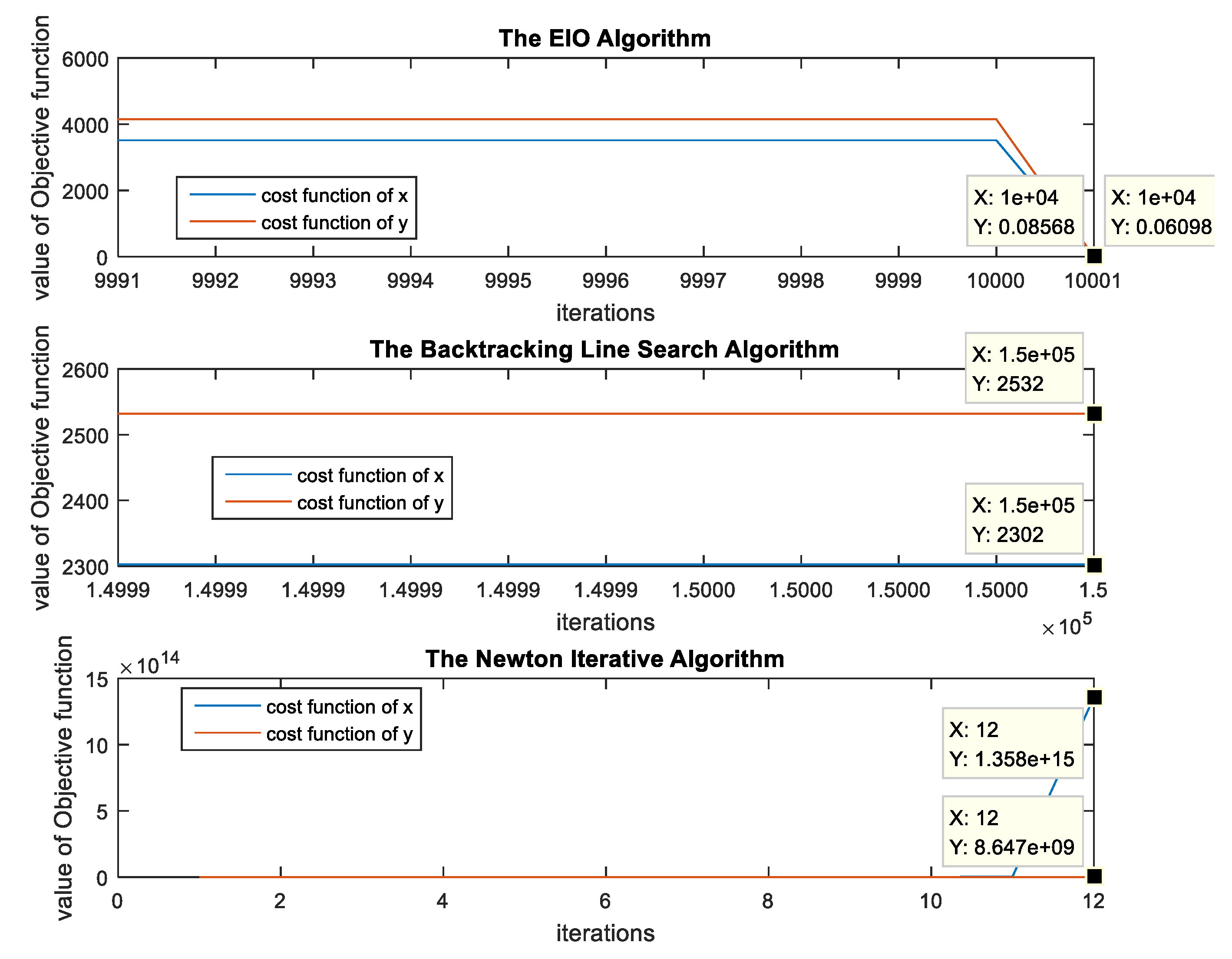
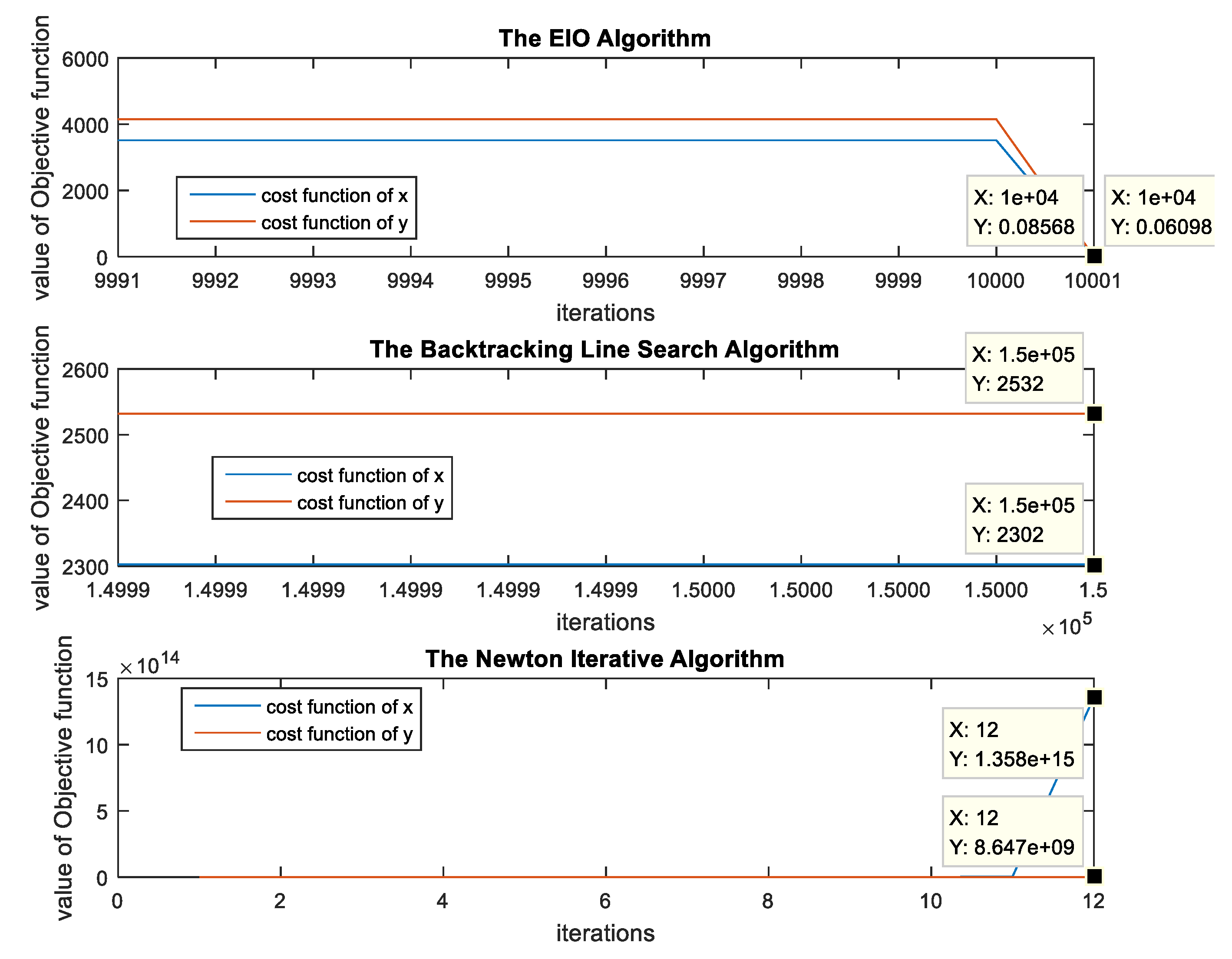
An Efficient Iterative Optimization (EIO) Algorithm
| Algorithm 1: Outline of EIO algorithm |
| 1: let be the initial point 2: let be the number of iterations, do the gradient descent method whose step size is acquired by the backtracking line search, and output . 3: let be the initial point, do Newton iterative algorithm until the algorithm is converged. Output: Obtain the precision |
3.3. Heterogeneous Feature Selection Using L1-Norm Penalty (HFS-LNP)
3.4. Heterogeneous Feature Fusion by Solving Underdetermined Equations (HFF-UE)
3.5. The Relationship between the Proposed Four Learning Models
4. Numerical Analysis and Results
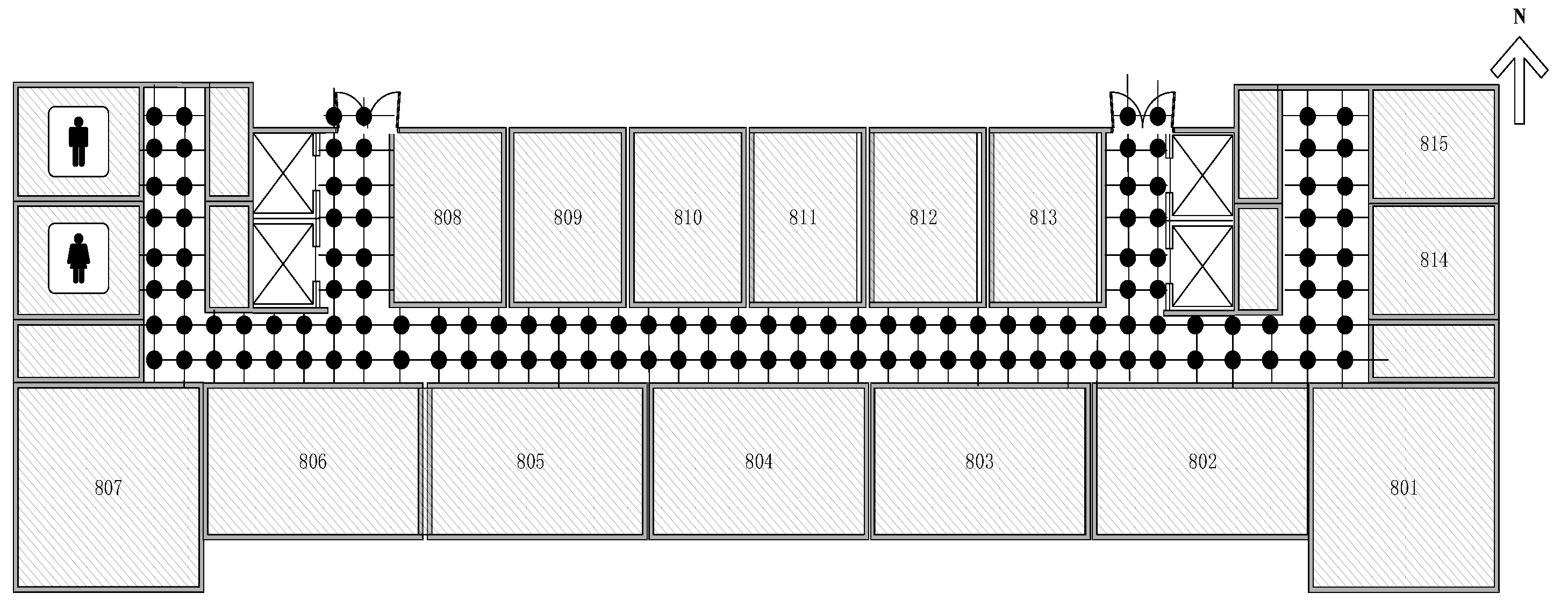
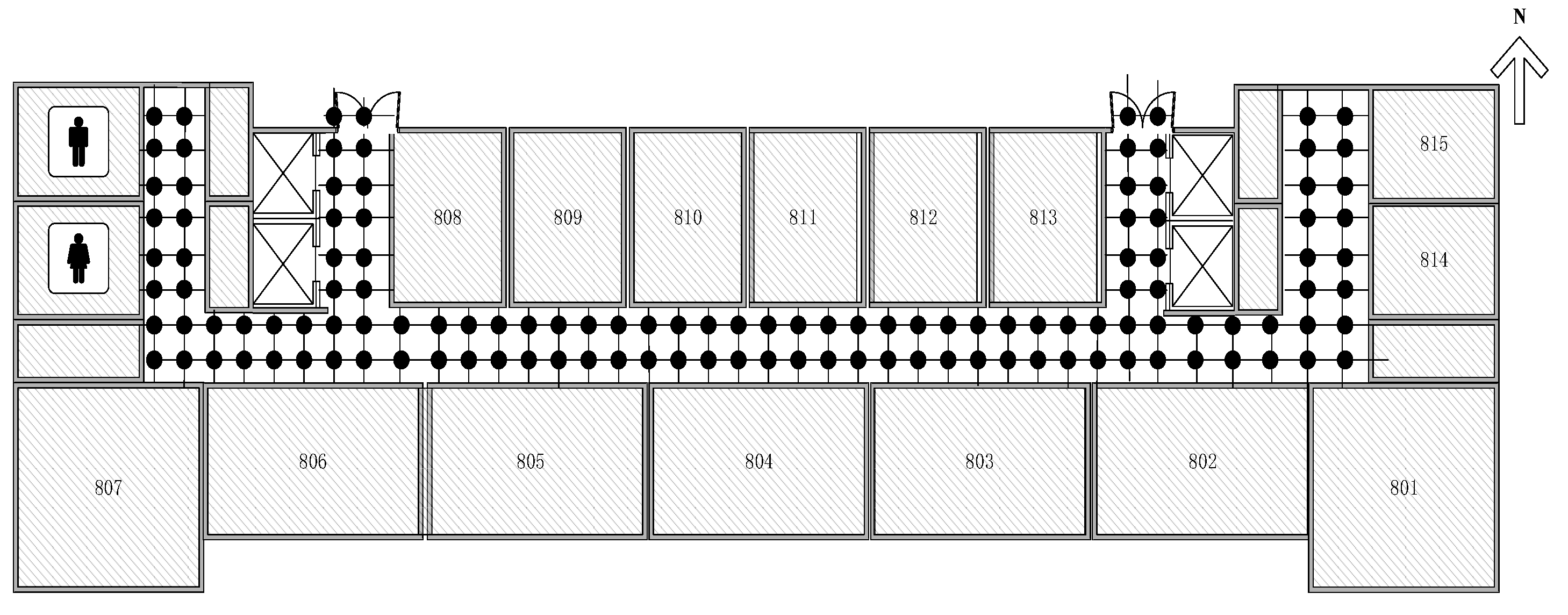
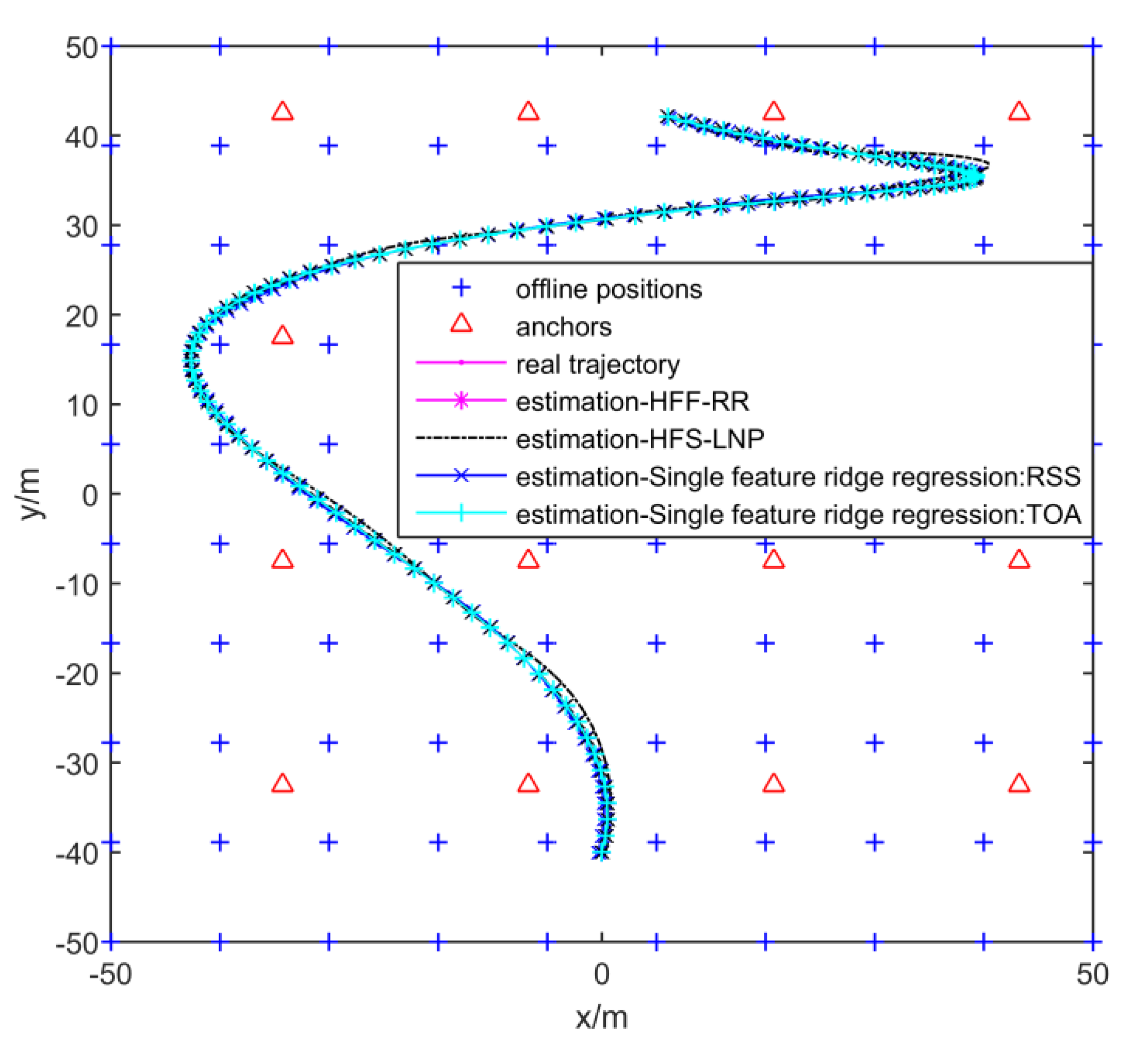
4.1. Real Experiment Setup
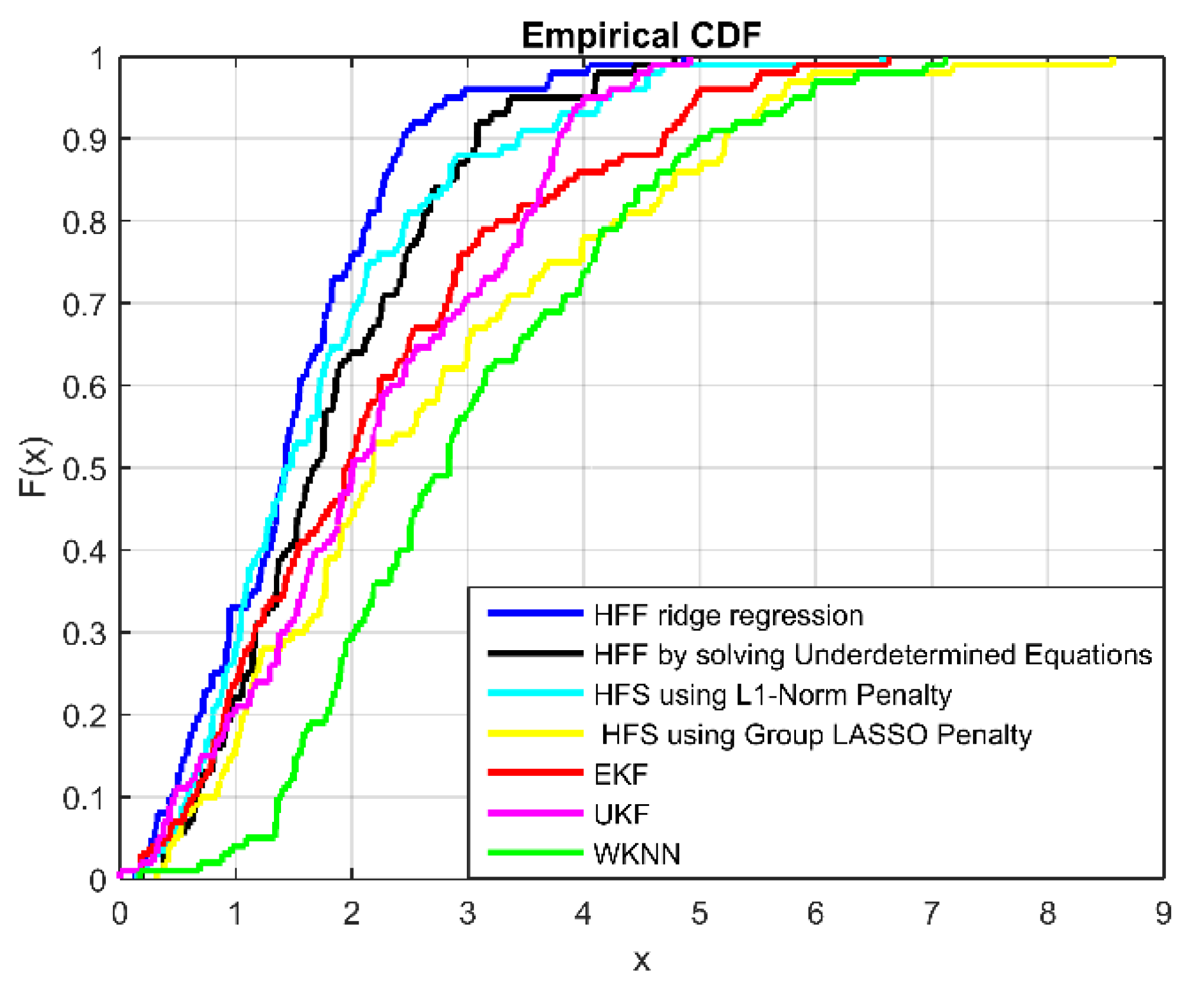
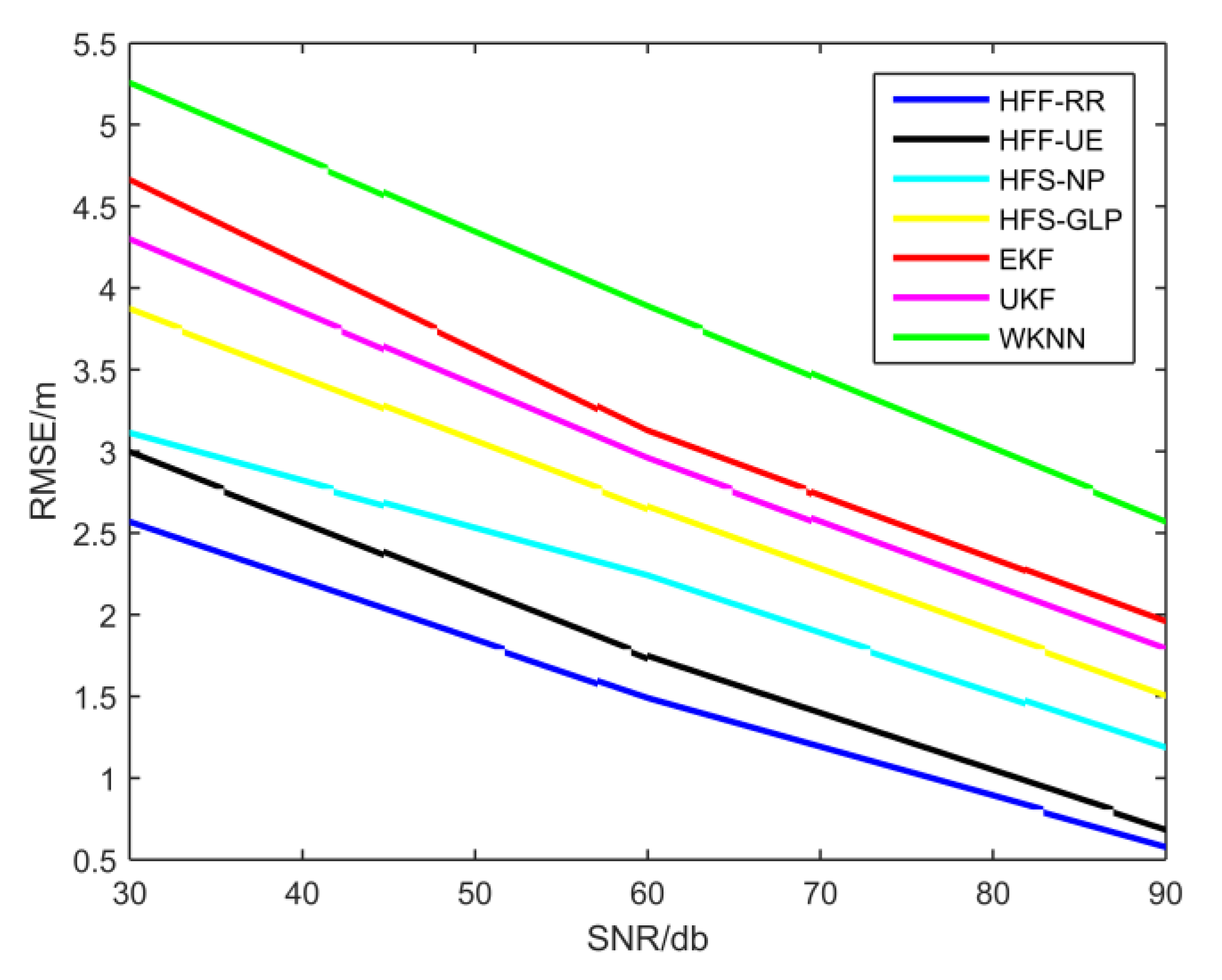
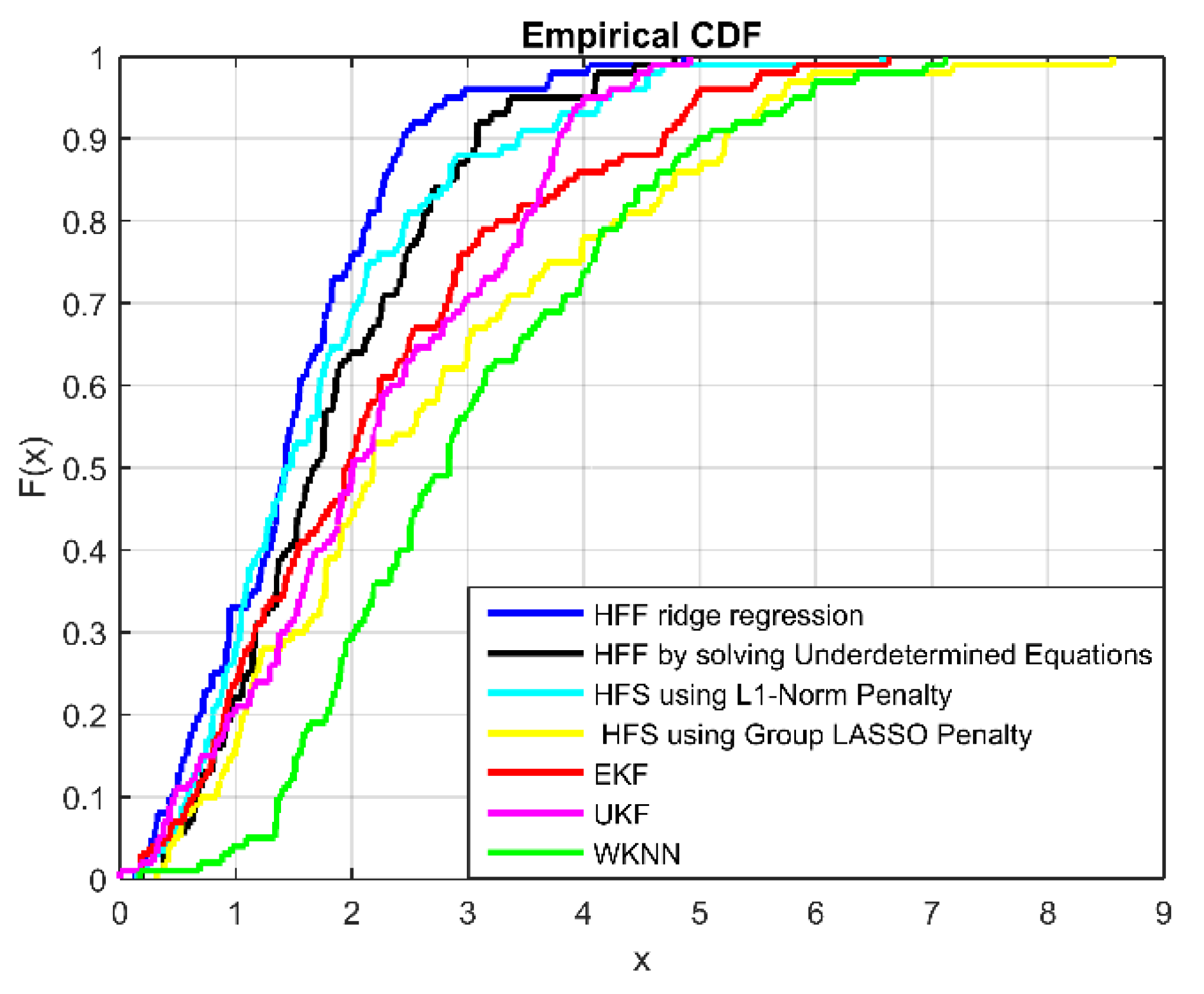
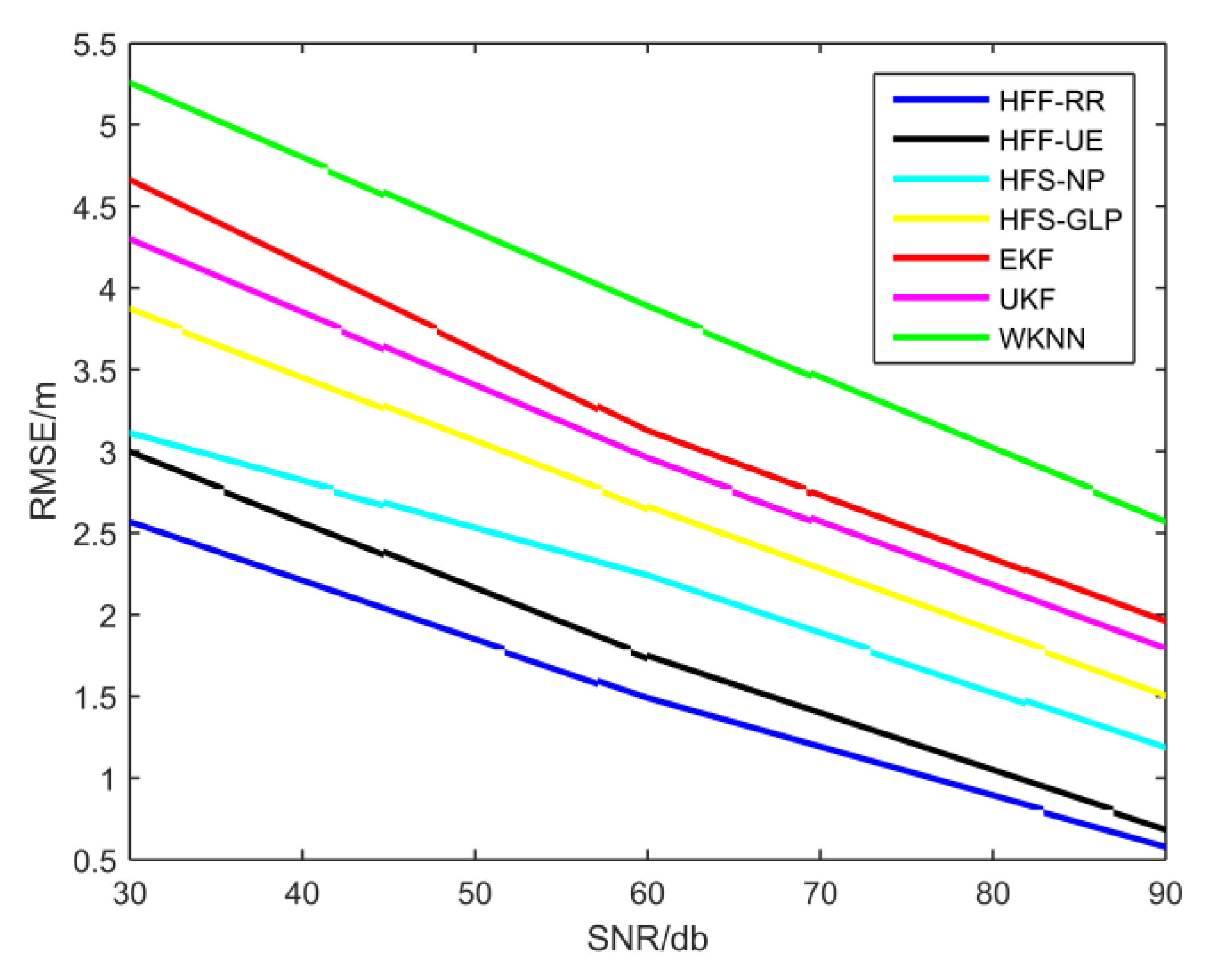
4.2. Localization Accuracy and Computational Cost Evaluation
4.3. Heterogeneous Feature Fusion Machines vs. Single feature machines
- Optimizing the relevant parameters using 10-fold cross-validation method.
- Learning the location model in training set by using current learning algorithm.
- Validating the model learned from the previous step in validation set.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Evans, D. The Internet of Things—How the Next Evolution of the Internet Is Changing Everything doc. Available online: https://www.cisco.com/c/dam/en_us/about/ac79/docs/innov/IoT_IBSG_0411FINAL.pdf (accessed on 27 September 2018).
- Qiu, Z.; Zou, H.; Jiang, H.; Xie, L.; Hong, Y. Consensus-Based Parallel Extreme Learning Machine for Indoor Localization. In Proceedings of the IEEE Global Communications Conference, Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Okello, N.; Fletcher, F.; Musicki, D.; Ristic, B. Comparison of Recursive Algorithms for Emitter Localisation using TDOA Measurements from a Pair of UAVs. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 1723–1732. [Google Scholar] [CrossRef]
- Rong, P.; Sichitiu, M. Angle of arrival localization for wireless sensor networks. In Proceedings of the 3rd Annual IEEE Communications Society on Sensor and Ad Hoc Communications and Networks, SECON, Reston, VA, USA, 28 September 2006; pp. 374–382. [Google Scholar]
- Mahfouz, S.; Mourad-Chehade, F.; Honeine, P.; Farah, J.; Snoussi, H. Kernel-based machine learning using radio-fingerprints for localization in WSNs. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 1324–1336. [Google Scholar] [CrossRef]
- Gholami, M.R.; Vaghefi, R.M.; Ström, E.G. RSS-Based Sensor Localization in the Presence of Unknown Channel Parameters. IEEE Trans. Signal Process. 2013, 61, 3752–3759. [Google Scholar] [CrossRef]
- Jin, Y.; Soh, W.S.; Wong, W.C. Indoor localization with channel impulse response based fingerprint and nonparametric regression. IEEE Trans. Wirel. Commun. 2010, 9, 1120–1127. [Google Scholar] [CrossRef] [Green Version]
- Seow, C.K.; Tan, S.Y. Non-Line-of-Sight Localization in Multipath Environments. IEEE Trans. Mob. Comput. 2008, 7, 647–660. [Google Scholar] [CrossRef]
- Seco, F.; Jimenez, A.R.; Prieto, C.; Roa, J.; Koutsou, K. A survey of mathematical methods for indoor localization. In Proceedings of the IEEE International Symposium on Intelligent Signal Processing, Budapest, Hungary, 26–28 August 2009; pp. 9–14. [Google Scholar]
- Lin, T.N.; Lin, P.C. Performance comparison of indoor positioning techniques based on location fingerprinting in wireless networks. In Proceedings of the International Conference on Wireless Networks, Communications and Mobile Computing, Maui, HI, USA, 13–16 June 2005; Volume 2, pp. 1569–1574. [Google Scholar]
- Lin, T.N.; Fang, S.H.; Tseng, W.H.; Lee, C.W.; Hsieh, J.W. A Group-Discrimination-Based Access Point Selection for WLAN Fingerprinting Localization. IEEE Trans. Veh. Technol. 2014, 63, 3967–3976. [Google Scholar] [CrossRef]
- Gustafsson, F.; Gunnarsson, F. Mobile positioning using wireless networks: Possibilities and fundamental limitations based on available wireless network measurements. IEEE Signal Process. Mag. 2005, 22, 41–53. [Google Scholar] [CrossRef]
- Jiang, Q.; Qiu, F.; Zhou, M.; Tian, Z. Benefits and impact of joint metric of AOA/RSS/TOF on indoor localization error. Appl. Sci. 2016, 6, 296. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, Z.; Liu, Y. From RSSI to CSI: Indoor localization via channel response. ACM Comput. Surv. 2013, 46, 1–32. [Google Scholar] [CrossRef]
- Xiao, J.; Wu, K.; Yi, Y.; Wang, L.; Ni, L.M. Pilot: Passive Device-Free Indoor Localization Using Channel State Information. In Proceedings of the IEEE International Conference on Distributed Computing Systems, Philadelphia, PA, USA, 8–11 July 2013; pp. 236–245. [Google Scholar]
- Zafari, F.; Gkelias, A.; Leung, K. A Survey of Indoor Localization Systems and Technologies. arXiv, 2018; arXiv:1709.01015. [Google Scholar]
- Gazzah, L.; Najjar, L.; Besbes, H. Improved selective hybrid RSS/AOA weighting schemes for NLOS localization. In Proceedings of the IEEE International Conference on Multimedia Computing and Systems, Marrakech, Morocco, 14–16 April 2014; pp. 746–751. [Google Scholar]
- Prieto, J.; Mazuelas, S.; Bahillo, A.; Fernandez, P.; Lorenzo, R.M.; Abril, E.J. Adaptive Data Fusion for Wireless Localization in Harsh Environments. IEEE Trans. Signal Process. 2012, 60, 1585–1596. [Google Scholar] [CrossRef]
- Wang, S.C.; Jackson, B.R.; Inkol, R. Hybrid RSS/AOA emitter location estimation based on least squares and maximum likelihood criteria. In Proceedings of the IEEE Biennial Symposium on Communications, Kingston, ON, Canada, 28–29 May 2012; pp. 24–29. [Google Scholar]
- Chan, F.K.; Wen, C.Y. Adaptive AOA/TOA Localization Using Fuzzy Particle Filter for Mobile WSNs. In Proceedings of the IEEE Vehicular Technology Conference, Yokohama, Japan, 15–18 May 2011; pp. 1–5. [Google Scholar]
- Salman, N.; Khan, M.W.; Kemp, A.H. Enhanced hybrid positioning in wireless networks II: AoA-RSS. In Proceedings of the IEEE International Conference on Telecommunications and Multimedia, Heraklion, Greece, 28–30 July 2014; pp. 92–97. [Google Scholar]
- Xiao, W.; Liu, P.; Soh, W.S.; Huang, G.B. Large scale wireless indoor localization by clustering and Extreme Learning Machine. In Proceedings of the IEEE International Conference on Information Fusion, Singapore, 9–12 July 2012; pp. 1609–1614. [Google Scholar]
- Torteeka, P.; Chundi, X. Indoor positioning based on Wi-Fi Fingerprint Technique using Fuzzy K-Nearest Neighbor. In Proceedings of the IEEE International Bhurban Conference on Applied Sciences and Technology, Islamabad, Pakistan, 14–18 January 2014; pp. 461–465. [Google Scholar]
- Koyuncu, H.; Yang, S.H. A 2D positioning system using WSNs in indoor environment. Int. J. Electr. Comput. Sci. 2011, 11, 70–77. [Google Scholar]
- Yu, F.; Jiang, M.; Liang, J.; Qin, X.; Hu, M.; Peng, T.; Hu, X. Expansion RSS-based Indoor Localization Using 5G WiFi Signal. In Proceedings of the IEEE International Conference on Computational Intelligence and Communication Networks, Bhopal, India, 14–16 November 2014; pp. 510–514. [Google Scholar]
- Chriki, A.; Touati, H.; Snoussi, H. SVM-based indoor localization in Wireless Sensor Networks. In Proceedings of the IEEE Wireless Communications and Mobile Computing Conference, Valencia, Spain, 26–30 June 2017. [Google Scholar]
- Bahl, P.; Padmanabhan, V.N. RADAR: An In-Building RF-based User Location and Tracking System. In Proceedings of the INFOCOM 2000 Conference on Computer Communications and Nineteenth Joint Conference of the IEEE Computer and Communications Societies, Tel Aviv, Israel, 26–30 March 2000; Volume 2, pp. 775–784. [Google Scholar]
- Crouse, R.H.; Jin, C.; Hanumara, R.C. Unbiased ridge estimation with prior information and ridge trace. Commun. Stat. Theory Methods 1995, 24, 2341–2354. [Google Scholar] [CrossRef]
- Wu, Z.L.; Li, C.H.; Ng, J.K.Y.; Leung, K.R. Location Estimation via Support Vector Regression. IEEE Trans. Mob. Comput. 2007, 6, 311–321. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Li, Y.; Gu, Y.; Yang, W. An Efficient Machine Learning Approach for Indoor Localization. China Commun. 2017, 14, 141–150. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Shi, K.; Ma, Z.; Zhang, R.; Hu, W.; Chen, H. Support Vector Regression Based Indoor Location in IEEE 802.11 Environments. Mob. Inf. Syst. 2015, 2015, 295652. [Google Scholar] [CrossRef]
- Berz, E.L.; Tesch, D.A.; Hessel, F.P. RFID indoor localization based on support vector regression and k-means. In Proceedings of the IEEE, International Symposium on Industrial Electronics, Buzios, Brazil, 3–5 June 2015; pp. 1418–1423. [Google Scholar]
- Abdou, A.S.; Aziem, M.A.; Aboshosha, A. An efficient indoor localization system based on Affinity Propagation and Support Vector Regression. In Proceedings of the International Conference on Digital Information Processing & Communications, Beirut, Lebanon, 21–23 April 2016; pp. 1–7. [Google Scholar]
- Wang, X.; Gao, L.; Mao, S.; Pandey, S. CSI-Based Fingerprinting for Indoor Localization: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2017, 66, 763–776. [Google Scholar] [CrossRef]
- Mcdonald, G.C. Ridge regression. Wiley Interdiscip. Rev. Comput. Stat. 2010, 1, 93–100. [Google Scholar] [CrossRef]
- Marquardt, D.; Snee, R. Ridge Regression in Practice. Am. Stat. 1975, 29, 3–20. [Google Scholar]
- He, S.; Chan, S.H.G. Wi-Fi Fingerprint-Based Indoor Positioning: Recent Advances and Comparisons. IEEE Commun. Surv. Tutor. 2017, 18, 466–490. [Google Scholar] [CrossRef]
- Zhang, M.; Wen, Y.; Chen, J.; Yang, X.; Gao, R.; Zhao, H. Pedestrian Dead-Reckoning Indoor Localization Based on OS-ELM. IEEE Access 2018, 6, 6116–6129. [Google Scholar] [CrossRef]
- Li, L.; Lin, X. Apply Pedestrian Dead Reckoning to indoor Wi-Fi positioning based on fingerprinting. In Proceedings of the IEEE International Conference on Communication Technology, Guilin, China, 17–19 November 2013; pp. 206–210. [Google Scholar]
- Zhang, P.; Zhao, Q.; You, L.I.; Niu, X.; Liu, J.; Center, G. PDR/WiFi Fingerprinting/Magnetic Matching-Based Indoor Navigation Method for Smartphones. J. Geomat. 2016, 3, 29–32. [Google Scholar]
- Lee, D.M. W-13 Capstone Design Project: A Hybrid Indoor Positioning Algorithm using PDR and Fingerprint at a Multi-Story Building under Wi-Fi Environment. In Proceedings of the JSEE Conference International Session Proceedings, Tokyo, Japan, 30 August 2017; Japanese Society for Engineering Education: Tokyo, Japan, 2017. [Google Scholar]
- Yang, Q.; Mao, Y.; Ping, X.U. Research on indoor positioning and fusion algorithm based on improved WIFI_PDR. Video Eng. 2017, Z3, 122–128. [Google Scholar]
- Bailey, T.; Nieto, J.; Guivant, J.; Stevens, M.; Nebot, E. Consistency of the EKF-SLAM Algorithm. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 3562–3568. [Google Scholar]
- Pan, Q.; Yang, F.; Ye, L.; Liang, Y.; Cheng, Y.M. Survey of a kind of nonlinear filters-UKF. Control Decis. 2005, 20, 481–489, 494. [Google Scholar]
- Fang, J.; Savransky, D. Automated alignment of a reconfigurable optical system using focal-plane sensing and Kalman filtering. Appl. Opt. 2016, 55, 5967. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Du, G.; Lei, Y.; Shao, H.; Xie, Z.; Zhang, P. A human—Robot interface using particle filter, Kalman filter, and over-damping method. Intell. Serv. Robot. 2016, 9, 323–332. [Google Scholar] [CrossRef]
- Rao, N.S.; Nowak, R.D.; Cox, C.R.; Rogers, T.T. Classification with the Sparse Group Lasso. IEEE Trans. Signal Process. 2015, 64, 448–463. [Google Scholar] [CrossRef]
- Saitoh, S. Theory of Reproducing Kernels. In Analysis and Applications—ISAAC 2001; Springer: Boston, MA, USA, 2003; pp. 135–150. [Google Scholar]
- Reininghaus, J.; Huber, S.; Bauer, U.; Kwitt, R. A stable multi-scale kernel for topological machine learning. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4741–4748. [Google Scholar]
- Lin, Z.; Yan, L. A support vector machine classifier based on a new kernel function model for hyperspectral data. Mapp. Sci. Remote Sens. 2016, 53, 85–101. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. 2006, 68, 49–67. [Google Scholar] [CrossRef] [Green Version]
- Selesnick, I.W. L1-Norm Penalized Least Squares with SALSA. 2014. Available online: http://cnx.org/content/m48933/ (accessed on 5 June 2018).
- Medeisis, A.; Kajackas, A. On the use of the universal Okumura-Hata propagation prediction model in rural areas. In Proceedings of the Vehicular Technology Conference Proceedings, VTC 2000-Spring, Tokyo, Japan, 15–18 May 2000; Volume 3, pp. 1815–1818. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Learning Model | Error (m) | Time (ms) | Sparsity |
|---|---|---|---|
| 0.57 ± 0.55 | 1.0 105 | No sparsity | |
| 1.43 ± 1.23 | 4.27 2.0 | Sample-level sparsity which can denoise at the sample level | |
| 1.36 ± 0.88 | 5.21 | Feature-level sparsity which can denoise at the feature level | |
| 1.04 ± 0.71 | 5.01 | No sparsity |
| Learning Model and Algorithm | Average Running Time of Parameters Optimization (s) | Error (m) | ||||
|---|---|---|---|---|---|---|
| HFF-RR | 2−5 | 26 | 29 | — | 102.59 | 1.5238 |
| HFF-UE | — | 26 | 29 | — | 4.35 | 1.8756 |
| HFS-LNP | 24 | 26 | 29 | — | 56,635.99 | 2.2409 |
| HFS-GLP | 2−24 | 220 | 210 | — | 407,395.65 | 2.6627 |
| EKF | — | — | — | 5 | 1.35 | 3.1274 |
| UKF | — | — | — | 5 | 1.78 | 2.9601 |
| WKNN | — | — | — | 5 | 0.99 | 3.8901 |
| Learning Model and Algorithm | Prediction Model | Error (m) | |||
|---|---|---|---|---|---|
| Single feature ridge regression | RSS-based kernel machine | 2−32 | 27 | — | 0.1995 |
| TOA-based kernel machine | 2−35 | — | 210 | 0.0258 | |
| HFF-RR | heterogeneous feature machine | 2−34 | 213 | 210 | 0.0215 |
| HFS-LNP | heterogeneous feature machine | 23 | 26 | 210 | 0.6698 |
| Noise Conditions | Prediction Model | Error (m) | |||
|---|---|---|---|---|---|
| Noisy RSS and True TOA | RSS-based kernel machine | 2−5 | 26 | — | 1.8756 |
| heterogeneous feature machine | 2−34 | 223 | 210 | 0.0137 | |
| Noisy TOA and True RSS | TOA-based kernel machine | 2−7 | — | 29 | 2.0300 |
| heterogeneous feature machine | 2−22 | 26 | 233 | 0.2288 | |
| Noisy TOA and Noisy RSS | heterogeneous feature machine | 2−5 | 26 | 29 | 1.2569 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Xiao, N.; Yang, W.; Li, J. Advanced Heterogeneous Feature Fusion Machine Learning Models and Algorithms for Improving Indoor Localization. Sensors 2019, 19, 125. https://doi.org/10.3390/s19010125
Zhang L, Xiao N, Yang W, Li J. Advanced Heterogeneous Feature Fusion Machine Learning Models and Algorithms for Improving Indoor Localization. Sensors. 2019; 19(1):125. https://doi.org/10.3390/s19010125
Chicago/Turabian StyleZhang, Lingwen, Ning Xiao, Wenkao Yang, and Jun Li. 2019. "Advanced Heterogeneous Feature Fusion Machine Learning Models and Algorithms for Improving Indoor Localization" Sensors 19, no. 1: 125. https://doi.org/10.3390/s19010125
APA StyleZhang, L., Xiao, N., Yang, W., & Li, J. (2019). Advanced Heterogeneous Feature Fusion Machine Learning Models and Algorithms for Improving Indoor Localization. Sensors, 19(1), 125. https://doi.org/10.3390/s19010125