A Fault Detection System for a Geothermal Heat Exchanger Sensor Based on Intelligent Techniques

 , ,
, ,  ,
,  , and
, and
Abstract
:1. Introduction
2. Case of Study
2.1. Sotavento Bioclimatic House
- Generation group: Three different renewable sources are exploited:
- -
- Geothermal system: A horizontal collector consisting of 5 loops of 100 m is placed under the ground at a depth of 2 m. The heat pump is a MAMY Genius—10.3 kW, and it has a nominal electrical power consumption of 1.9 kW and a nominal thermal power of 8.4 kW. The energy is absorbed from the ground and it is used to heat a mixture of water and glycol.
- -
- Solar thermal: Eight solar panels absorb the solar radiation to heat the ethyleneglycol flowing inside them.
- -
- Biomass boiler system: A biomass boiler type Ökofen, model Pallematic 20, with a configurable power of 20 kW, with a yield of pellets of 90%.
- Energy accumulation group: The thermal energy storage is ensured using different accumulators. A solar accumulator of 1000 L receives the thermal energy from the solar system. In series, an inertial accumulator of 800 L stores the heat from the boiler and geothermal systems.
- Consumption group: The thermal system must cover the demand of underfloor heating systems and Domestic Hot Water (DHW). The underfloor heating system is designed to keep the house temperature between 18 C and 22 C. The fluid temperature should remain between 35 C and 40 C. According to the Spanish Technical Building Code, the DHW demands 240 L/day.
2.2. The Geothermal System
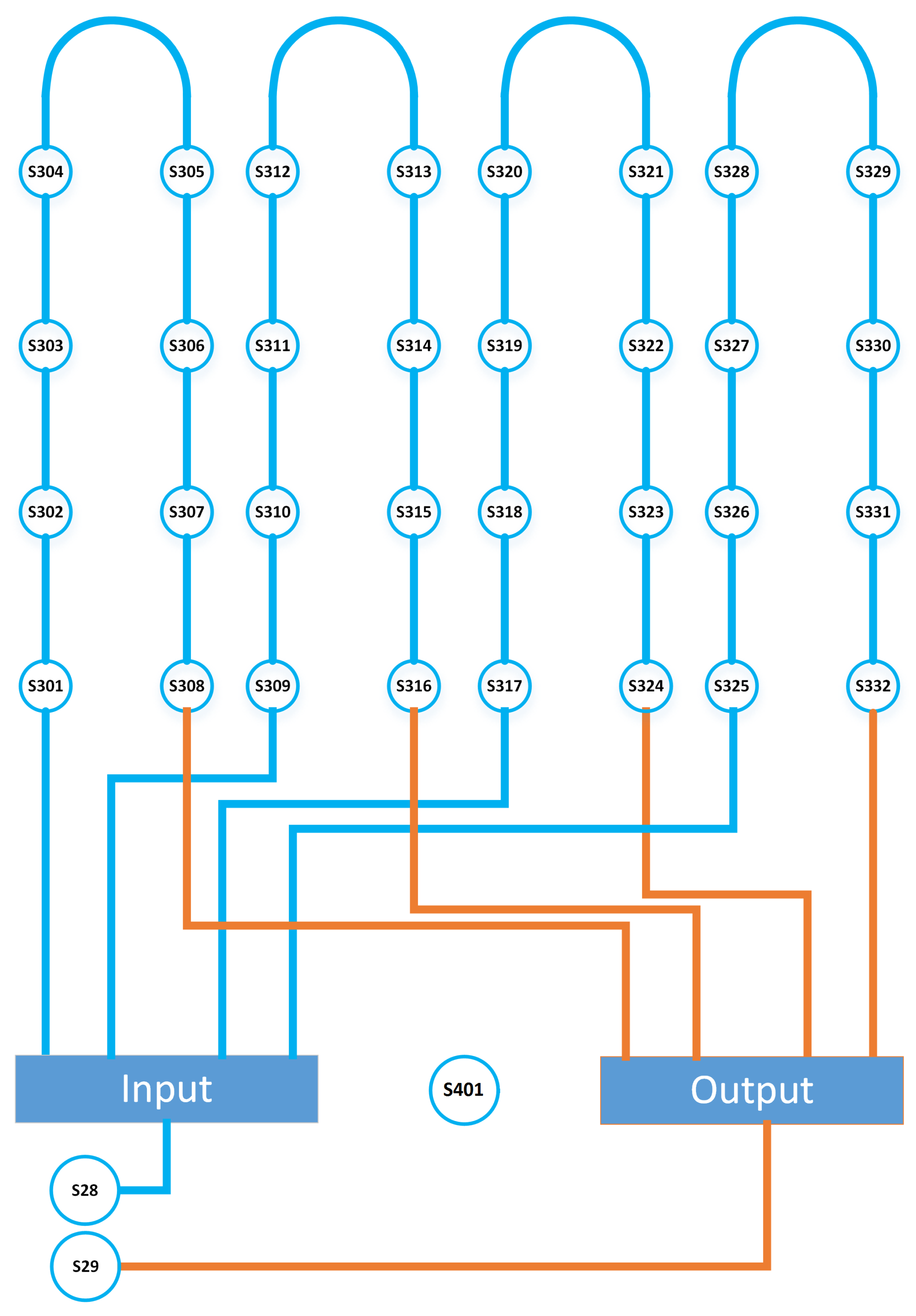
2.3. The Dataset
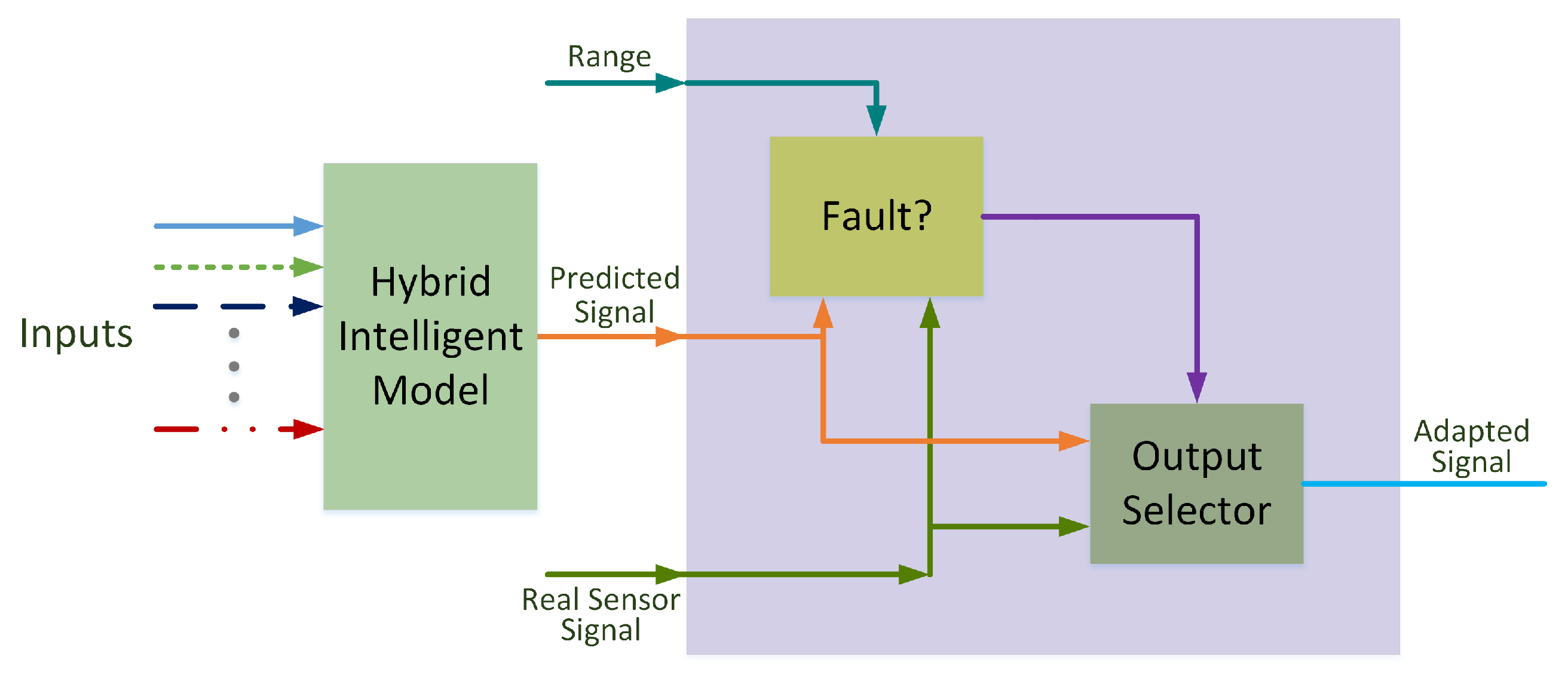
3. Fault Detection and Recovery (FDR) Approach—Used Techniques
3.1. FDR Steps
3.2. Used Techniques
3.2.1. Analysis and Preprocessing
- Day data cases.
- Night data cases.
3.2.2. Regression Techniques
- Shallow Neural Networks. Artificial Neural Networks can be used as universal approximators [35]. For this paper, a three layer Multi Layer Perceptron architecture was chosen: An input layer for capturing the sensor information, a hidden layer with non linear activation functions, and an output layer with one single neuron and a linear activation function to provide the prediction. The most important hyperparameters governing the regressor performance are the hidden layer size, the maximum number of iterations, the early stopping, the activation function, the nesterov momentum and the solver.
- K-Nearest Neighbors. This is a representative of instance based techniques or non generalizing learning. Instead of representing the data via a model, this technique stores instance and uses a voting scheme on the nearest neighbors for obtaining the prediction on new data. This technique is a popular choice for setting a baseline for the prediction error. The most important hyperparameter is the number of neighbors.
- Adaptive Boosting. This technique belongs to the stagewise additive models family. The prediction is based on a weighted sum of the simpler weak estimators it comprises. Each weak estimator is designed to concentrate on those samples that previous estimators found still to be difficult to fit. In this technique, the number of estimators is the most important hyperparameter to tune.
- Random Decision Forests. Being one of the most popular ensemble methods, Random decision forests (RF) comprise a collection of simple decision trees whose results are considered to emit a final collective result. RF basic components can be built by considering a random limited number of features and/or a random limited number of observations. Thus, each component only has access to a fraction of the information and pays attention to specific details in the portion of information assigned to them. The combination of a number of these simple basic trees most frequently outperforms the results from a larger and more complex single tree. The number of estimators is the most important hyperparameter to tune.
- Extremely Randomized Trees. They are similar to Random Forests, as they combine an ensemble of decision trees. Nevertheless, a few important differences are worth noting: Firstly, Extra Trees can provide piece-wise multilinear approximations to the training dataset instead of the piece-wise constants one provides by random forests. Secondly, Extra Trees are based on using random values for the optimal cut point choice, instead of bootstrapping to find the optimal cut point [36]. Similarly to RF, one of the most important hyperparameters to tune is the number of basic estimators.
- Gradient Boosting. This technique builds the model following a stage-wise approach, by adding subsequent basic estimators in order to capture the unexplained information present in the residuals of former weak estimators [37]. The estimators frequently are decision trees and, similarly, the number of basic estimators is among the most important hyperparameters.
4. Experiments and Results
4.1. Experiment Definition
- Experiment A: Prediction of sensor S-315 based on S-309 to S-316 signals
- Experiment B: Prediction of sensor S-315 based on S-309 to S-316 signals and their previous states
- Experiment C: Prediction of sensor S-315 based on S-309 to S-316 signals and S-315 previous state
- Experiment D: Prediction of sensor S-315 based on S-309 to S-316 signals, their previous states, and S-315 previous state
- Global models: In this case the whole data set is used for training a single regressor.
- Hybrid models: In this case, the data set is split into two groups in accordance to day and night criteria. Two different models are fit, one for day usage and another one for the night hours.
4.2. Error Metrics
- MAE: Mean Absolute Error. The goal of this metric is to measure the difference between predicted and real values. This metric has some advantages compared to other error measures [38].where is the observed value and is the foretold value.
4.3. Experiments Setup
4.3.1. Shallow Neural Network
- hidden_layer_sizes=[(n,) for n in ( 5, 6, 7, 8)]
- max_iter=[ 500_000]
- learning_rate_init=[1e-1, 1e-2, 1e-3]
- early_stopping=[True]
- activation=[’relu’]
- nesterovs_momentum=[True]
- warm_start=[False]
- solver=[’lbfgs’]
4.3.2. Extremely Randomized Tree
- n_estimators=range(10, 100, 5)
4.3.3. Random Decision Forests
- n_estimators=range(10, 100, 5)
4.3.4. Gradient Boosting
- n_estimators=range(10, 100, 5)
- learning_rate=np.linspace(1e-3, 1e-1, 5)
- n_iter_no_change=[2]
4.3.5. AdaBoost
- n_estimators=range(10, 100, 5)
4.3.6. K-Neareat Neighbors
- n_neighbors=range(5, 20, 5)
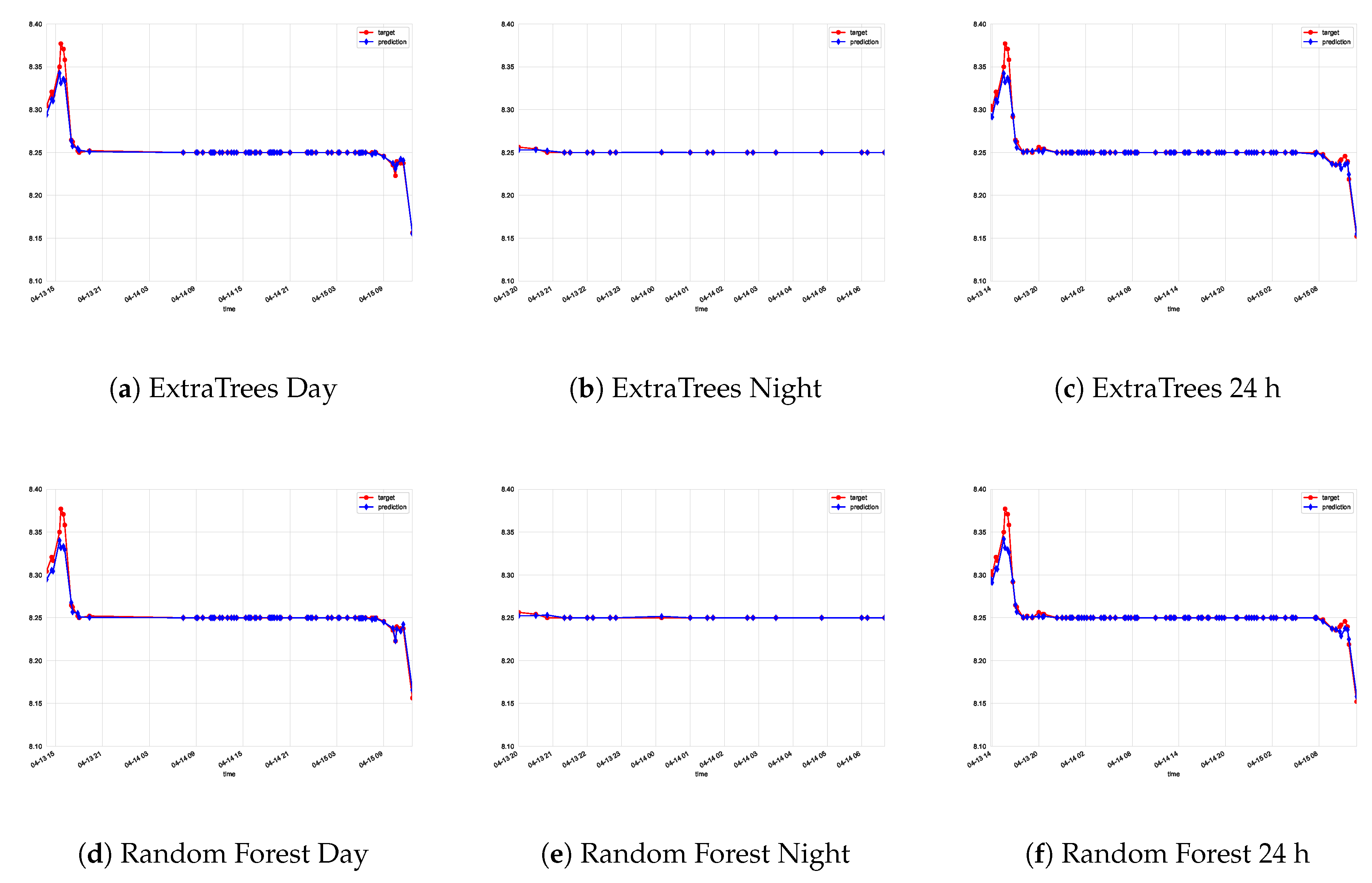
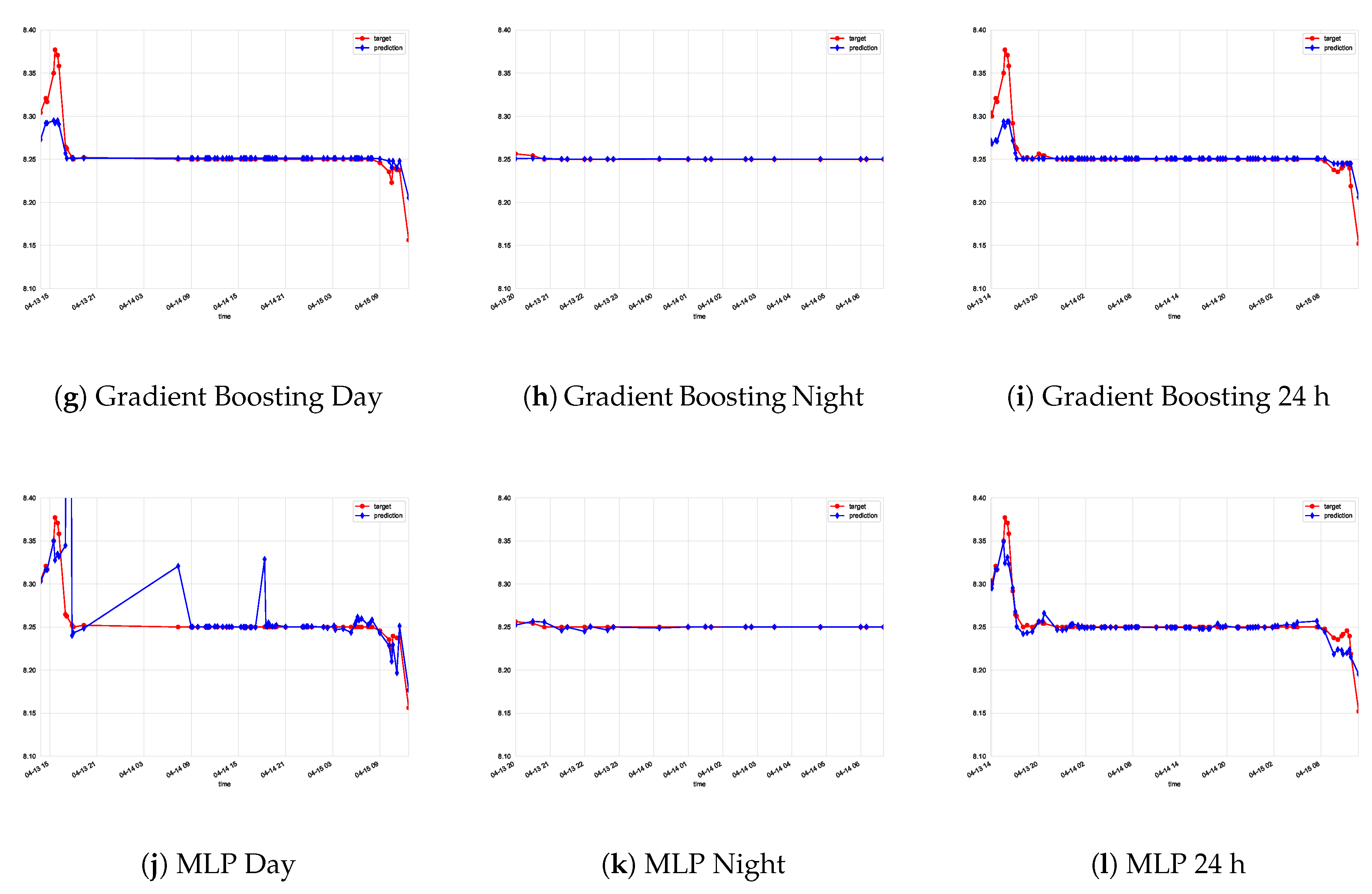
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kaltschmitt, M.; Streicher, W.; Wiese, A. Renewable Energy; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Dickson, M.H.; Fanelli, M. Geothermal Energy: Utilization and Technology; Routledge: Abingdon, UK, 2013. [Google Scholar]
- Ozgener, L.; Ozgener, O. Monitoring of energy exergy efficiencies and exergoeconomic parameters of geothermal district heating systems (GDHSs). Appl. Energy 2009, 86, 1704–1711. [Google Scholar] [CrossRef]
- Kakaç, S.; Liu, H.; Pramuanjaroenkij, A. Heat Exchangers: Selection, Rating, and Thermal Design, 2nd ed.; Designing for Heat Transfer, Taylor & Francis: Abingdon, UK, 2002. [Google Scholar]
- Sauer, H.; Howell, R. Heat Pump Systems; Krieger Publishing Company: Malabar, FL, USA, 1991. [Google Scholar]
- Quintian Pardo, H.; Calvo Rolle, J.L.; Fontenla Romero, O. Application of a low cost commercial robot in tasks of tracking of objects. Dyna 2012, 79, 24–33. [Google Scholar]
- Rolle, J.; Gonzalez, I.; Garcia, H. Neuro-robust controller for non-linear systems. Dyna 2011, 86, 308–317. [Google Scholar] [CrossRef]
- Alaiz Moretón, H.; Calvo Rolle, J.; García, I.; Alonso Alvarez, A. Formalization and practical implementation of a conceptual model for PID controller tuning. Asian J. Control 2011, 13, 773–784. [Google Scholar] [CrossRef]
- Garcia, R.F.; Rolle, J.L.C.; Castelo, J.P.; Gomez, M.R. On the monitoring task of solar thermal fluid transfer systems using NN based models and rule based techniques. Eng. Appl. Artif. Intell. 2014, 27, 129–136. [Google Scholar] [CrossRef]
- González Gutiérrez, C.; Sánchez Rodríguez, M.L.; Fernández Díaz, R.Á.; Calvo Rolle, J.L.; Roqueñí Gutiérrez, N.; Javier de Cos Juez, F. Rapid tomographic reconstruction through GPU-based adaptive optics. Log. J. IGPL 2018, 27, 214–226. [Google Scholar] [CrossRef]
- Baruque, B.; Porras, S.; Jove, E.; Calvo-Rolle, J.L. Geothermal heat exchanger energy prediction based on time series and monitoring sensors optimization. Energy 2019, 171, 49–60. [Google Scholar] [CrossRef]
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Springer Science & Business Media: Berlin, Germany, 2000. [Google Scholar]
- Casteleiro-Roca, J.L.; Pérez, J.A.M.; Piñón-Pazos, A.J.; Calvo-Rolle, J.L.; Corchado, E. Modeling the electromyogram (EMG) of patients undergoing anesthesia during surgery. In Proceedings of the 10th International Conference on Soft Computing Models in Industrial and Environmental Applications, Burgos, Spain, 15–17 June 2015; pp. 273–283. [Google Scholar]
- Vega Vega, R.; Quintián, H.; Calvo-Rolle, J.L.; Herrero, Á.; Corchado, E. Gaining deep knowledge of Android malware families through dimensionality reduction techniques. Log. J. IGPL 2018, 27, 160–176. [Google Scholar] [CrossRef]
- Quintián, H.; Casteleiro-Roca, J.L.; Perez-Castelo, F.J.; Calvo-Rolle, J.L.; Corchado, E. Hybrid intelligent model for fault detection of a lithium iron phosphate power cell used in electric vehicles. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Seville, Spain, 18–20 April 2016; pp. 751–762. [Google Scholar]
- Jove, E.; Gonzalez-Cava, J.M.; Casteleiro-Roca, J.L.; Méndez-Pérez, J.A.; Antonio Reboso-Morales, J.; Javier Pérez-Castelo, F.; Javier de Cos Juez, F.; Luis Calvo-Rolle, J. Modelling the hypnotic patient response in general anaesthesia using intelligent models. Log. J. IGPL 2018, 27, 189–201. [Google Scholar] [CrossRef]
- Gonzalez-Cava, J.M.; Reboso, J.A.; Casteleiro-Roca, J.L.; Calvo-Rolle, J.L.; Méndez Pérez, J.A. A novel fuzzy algorithm to introduce new variables in the drug supply decision-making process in medicine. Complexity 2018, 2018, 9012720. [Google Scholar] [CrossRef]
- Casteleiro-Roca, J.L.; Jove, E.; Gonzalez-Cava, J.M.; Méndez Pérez, J.A.; Calvo-Rolle, J.L.; Blanco Alvarez, F. Hybrid model for the ANI index prediction using Remifentanil drug and EMG signal. Neural Comput. Appl. 2018. [Google Scholar] [CrossRef]
- Casteleiro-Roca, J.L.; Quintián, H.; Calvo-Rolle, J.L.; Corchado, E.; del Carmen Meizoso-López, M.; Piñón-Pazos, A. An intelligent fault detection system for a heat pump installation based on a geothermal heat exchanger. J. Appl. Log. 2016, 17, 36–47. [Google Scholar] [CrossRef] [Green Version]
- Vilar-Martinez, X.M.; Montero-Sousa, J.A.; Calvo-Rolle, J.L.; Casteleiro-Roca, J.L. Expert system development to assist on the verification of “TACAN” system performance. Dyna 2014, 89, 112–121. [Google Scholar]
- Casteleiro-Roca, J.L.; Calvo-Rolle, J.L.; Méndez Pérez, J.A.; Roqueñí Gutiérrez, N.; de Cos Juez, F.J. Hybrid Intelligent System to Perform Fault Detection on BIS Sensor During Surgeries. Sensors 2017, 17, 179. [Google Scholar] [CrossRef] [PubMed]
- Marrero, A.; Méndez, J.; Reboso, J.; Martín, I.; Calvo, J. Adaptive fuzzy modeling of the hypnotic process in anesthesia. J. Clin. Monit. Comput. 2017, 31, 319–330. [Google Scholar] [CrossRef] [PubMed]
- Quintián, H.; Corchado, E. Beta scale invariant map. Eng. Appl. Artif. Intell. 2017, 59, 218–235. [Google Scholar] [CrossRef]
- Jove, E.; López, J.A.V.; Fernández-Ibáñez, I.; Casteleiro-Roca, J.L.; Calvo-Rolle, J.L. Hybrid intelligent system topredict the individual academic performance of engineering students. Int. J. Eng. Educ. 2018, 34, 895–904. [Google Scholar]
- Jove, E.; Casteleiro-Roca, J.L.; Quintián, H.; Méndez-Pérez, J.A.; Calvo-Rolle, J.L. A fault detection system based on unsupervised techniques for industrial control loops. Expert Syst. 2019, e12395. [Google Scholar] [CrossRef]
- Ozgener, L. A review on the experimental and analytical analysis of earth to air heat exchanger (EAHE) systems in Turkey. Renew. Sustain. Energy Rev. 2011, 15, 4483–4490. [Google Scholar] [CrossRef]
- Cabrerizo, J.A.R.; Santos, M. ParaTrough: Modelica-based Simulation Library for Solar Thermal Plants. Revista Iberoamericana de Automática e Informática Industrial RIAI 2017, 14, 412–423. [Google Scholar] [CrossRef]
- Tuv, E. Feature Selection with Ensembles, Artificial Variables, and Redundancy Elimination. J. Mach. Learn. Res. 2009, 10, 1341–1366. [Google Scholar] [CrossRef]
- Developers, S.L. scikit-learn v0.19.1. Available online: https://sklearn.org/modules/classes.html (accessed on 15 January 2019).
- Géron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques for Building Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Jove, E.; Gonzalez-Cava, J.M.; Casteleiro-Roca, J.L.; Pérez, J.A.M.; Calvo-Rolle, J.L.; de Cos Juez, F.J. An Intelligent Model to Predict ANI in Patients Undergoing General Anesthesia. In Proceedings of the International Joint Conference SOCO’17-CISIS’17-ICEUTE’17, León, Spain, 6–8 September 2017; Pérez García, H., Alfonso-Cendón, J., Sánchez González, L., Quintián, H., Corchado, E., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 492–501. [Google Scholar]
- Casteleiro-Roca, J.L.; Jove, E.; Sánchez-Lasheras, F.; Méndez-Pérez, J.A.; Calvo-Rolle, J.L.; de Cos Juez, F.J. Power Cell SOC Modelling for Intelligent Virtual Sensor Implementation. J. Sens. 2017, 2017, 9640546. [Google Scholar] [CrossRef]
- Casteleiro-Roca, J.; Calvo-Rolle, J.; Meizoso-López, M.; Piñón-Pazos, A.; Rodríguez-Gómez, B. Bio-inspired model of ground temperature behavior on the horizontal geothermal exchanger of an installation based on a heat pump. Neurocomputing 2015, 150 Pt A, 90–98. [Google Scholar] [CrossRef] [Green Version]
- Alaiz-Moretón, H.; Casteleiro-Roca, J.L.; Robles, L.F.; Jove, E.; Castejón-Limas, M.; Calvo-Rolle, J.L. Sensor Fault Detection and Recovery Methodology for a Geothermal Heat Exchanger. In Hybrid Artificial Intelligent Systems; de Cos Juez, F.J., Villar, J.R., de la Cal, E.A., Herrero, Á., Quintián, H., Sáez, J.A., Corchado, E., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 171–184. [Google Scholar]
- Hornik, K. Approximation Capabilities of Multilayer Feedforward Network. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Campoy, A.M.; Rodríguez-Ballester, F.; Carot, R.O. Using dynamic, full cache locking and genetic algorithms for cache size minimization in multitasking, preemptive, real-time systems. In Proceedings of the International Conference on Theory and Practice of Natural Computing, Caceres, Spain, 3–5 December 2013; pp. 157–168. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Kim, S.; Kim, H. A new metric of absolute percentage error for intermittent demand forecasts. Int. J. Forecast. 2016, 32, 669–679. [Google Scholar] [CrossRef]
- Poli, A.A.; Cirillo, M.C. On the use of the normalized mean square error in evaluating dispersion model performance. Atmos. Environ. Part A Gen. Top. 1993, 27, 2427–2434. [Google Scholar] [CrossRef]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. In Proceedings of the ECML PKDD Workshop: Languages for Data Mining and Machine Learning, Prague, Czech Republic, 23–27 September 2013; pp. 108–122. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error | Experiment | ET | GB | MLP | RF | AB | K-NN |
|---|---|---|---|---|---|---|---|
| LMLS | A | 2.4 | 24.4 | 6.0 | 3.7 | 2.66 | 4.76 |
| B | 2.4 | 21.2 | 6.7 | 3.5 | 3.16 | 4.76 | |
| C | 2.6 | 21.2 | 4.5 | 3.0 | 2.87 | 4.76 | |
| D | 2.3 | 16.6 | 18.7 | 3.2 | 3.26 | 4.76 | |
| MAE | A | 243.1 | 880.6 | 495.3 | 280.3 | 263.76 | 353.77 |
| B | 240.1 | 868.9 | 620.1 | 300.8 | 317.70 | 353.77 | |
| C | 249.5 | 821.5 | 414.9 | 280.7 | 277.65 | 353.77 | |
| D | 243.5 | 768.2 | 855.9 | 283.5 | 336.57 | 353.77 | |
| MAPE | A | 29.2 | 106.0 | 59.9 | 33.7 | 31.72 | 42.62 |
| B | 28.9 | 104.6 | 74.9 | 36.2 | 38.24 | 42.62 | |
| C | 30.0 | 98.9 | 50.1 | 33.8 | 33.40 | 42.62 | |
| D | 29.3 | 92.5 | 103.2 | 34.1 | 40.52 | 42.62 | |
| MSE | A | 4.8 | 48.8 | 12.0 | 7.4 | 5.32 | 9.53 |
| B | 4.9 | 42.5 | 13.4 | 7.0 | 6.33 | 9.53 | |
| C | 5.2 | 42.5 | 9.0 | 6.1 | 5.75 | 9.53 | |
| D | 4.6 | 33.2 | 37.5 | 6.3 | 6.51 | 9.53 | |
| NMSE | A | 508.4 | 535.7 | 979.6 | 370.6 | 572.03 | 108.90 |
| B | 527.9 | 570.0 | 250.6 | 320.7 | 540.69 | 108.90 | |
| C | 561.2 | 569.8 | 867.9 | 407.3 | 537.47 | 108.90 | |
| D | 658.0 | 257.4 | 1883.6 | 428.9 | 502.79 | 108.90 | |
| SMAPE | A | 29.3 | 106.3 | 59.9 | 33.7 | 31.75 | 42.67 |
| B | 28.9 | 104.9 | 75.0 | 36.2 | 38.28 | 42.67 | |
| C | 30.0 | 99.1 | 50.1 | 33.8 | 33.44 | 42.67 | |
| D | 29.3 | 92.7 | 103.4 | 34.1 | 40.56 | 42.67 |
| Error | Experiment | ET | GB | MLP | RF | AB | K-NN |
|---|---|---|---|---|---|---|---|
| LMLS | A | 2.9 | 15.7 | 1153.2 | 3.3 | 3.56 | 5.81 |
| B | 3.2 | 19.5 | 77.7 | 3.9 | 3.96 | 5.81 | |
| C | 3.2 | 29.5 | 16.3 | 3.9 | 4.15 | 5.81 | |
| D | 3.1 | 34.1 | 304.7 | 4.0 | 3.73 | 5.81 | |
| MAE | A | 232.0 | 689.1 | 3079.4 | 269.9 | 355.44 | 363.79 |
| B | 255.1 | 832.2 | 1515.3 | 318.7 | 332.95 | 363.79 | |
| C | 280.8 | 1102.7 | 727.6 | 321.4 | 483.44 | 363.79 | |
| D | 278.4 | 1136.0 | 1675.1 | 320.7 | 407.91 | 363.79 | |
| MAPE | A | 27.8 | 82.8 | 372.6 | 32.4 | 42.75 | 43.75 |
| B | 30.6 | 100.2 | 183.2 | 38.3 | 40.00 | 43.75 | |
| C | 33.8 | 132.8 | 87.8 | 38.6 | 58.27 | 43.75 | |
| D | 33.5 | 136.8 | 202.6 | 38.5 | 49.10 | 43.75 | |
| MSE | A | 5.9 | 31.5 | 3457.9 | 6.7 | 7.12 | 11.62 |
| B | 6.3 | 39.0 | 157.5 | 7.8 | 7.93 | 11.62 | |
| C | 6.4 | 59.1 | 32.6 | 7.9 | 8.30 | 11.62 | |
| D | 6.2 | 68.3 | 672.6 | 8.0 | 7.45 | 11.62 | |
| NMSE | A | 799.6 | 783.7 | 18418.0 | 544.7 | 724.68 | 98.50 |
| B | 425.2 | 347.0 | 7103.5 | 366.3 | 731.76 | 98.50 | |
| C | 459.0 | 193.2 | 1652.2 | 361.8 | 111.51 | 98.50 | |
| D | 434.8 | 147.3 | 13330.6 | 408. | 733.02 | 98.50 | |
| SMAPE | A | 27.9 | 83.0 | 349.5 | 32.4 | 42.80 | 43.82 |
| B | 30.7 | 100.4 | 184.3 | 38.3 | 40.05 | 43.82 | |
| C | 33.8 | 133.1 | 88.0 | 38.7 | 58.32 | 43.82 | |
| D | 33.5 | 137.1 | 198.0 | 38.6 | 49.15 | 43.82 |
| Error | Experiment | ET | GB | MLP | RF | AB | K-NN |
|---|---|---|---|---|---|---|---|
| LMLS | A | 0.05 | 0.10 | 0.3 | 0.10 | 0.09 | 0.07 |
| B | 0.04 | 0.10 | 3254.6 | 0.08 | 0.10 | 0.06 | |
| C | 0.05 | 0.10 | 0.10 | 0.07 | 0.09 | 0.06 | |
| D | 0.04 | 0.10 | 633.3 | 0.06 | 0.10 | 0.06 | |
| MAE | A | 38.6 | 67.8 | 141.3 | 55.6 | 42.00 | 39.90 |
| B | 33.6 | 57.6 | 14477.5 | 49.5 | 52.50 | 35.70 | |
| C | 35.3 | 65.1 | 110.6 | 48.1 | 42.00 | 37.80 | |
| D | 33.3 | 67.5 | 5595.9 | 45.9 | 52.50 | 37.80 | |
| MAPE | A | 4.7 | 8.2 | 17.1 | 6.7 | 5.09 | 4.83 |
| B | 4.1 | 7.0 | 1754.5 | 6.0 | 6.36 | 4.32 | |
| C | 4.3 | 7.9 | 13.4 | 5.8 | 5.09 | 4.58 | |
| D | 4.0 | 8.2 | 678.2 | 5.6 | 6.36 | 4.58 | |
| MSE | A | 0.11 | 0.21 | 0.55 | 0.20 | 0.18 | 0.13 |
| B | 0.08 | 0.21 | 6996.17 | 0.16 | 0.20 | 0.11 | |
| C | 0.11 | 0.20 | 0.20 | 0.14 | 0.18 | 0.12 | |
| D | 0.08 | 0.23 | 1291.10 | 0.13 | 0.20 | 0.12 | |
| NMSE | A | 4735.4 | 8055.6 | 18847.7 | 7114.2 | 6805.56 | 822.22 |
| B | 2407.6 | 1427.0 | 16796.8 | 5333.3 | 6388.89 | 1355.56 | |
| C | 5349.2 | 6283.4 | 22194.2 | 5732.9 | 6805.56 | 2355.56 | |
| D | 3829.9 | 7114.8 | 64166.1 | 3324.2 | 8055.56 | 2356.56 | |
| SMAPE | A | 4.7 | 8.2 | 17.1 | 6.7 | 5.09 | 4.83 |
| B | 4.1 | 7.0 | 1711.6 | 6.0 | 6.36 | 4.83 | |
| C | 4.3 | 7.9 | 13.4 | 5.8 | 5.09 | 4.83 | |
| D | 4.0 | 8.2 | 687.5 | 5.6 | 6.36 | 4.83 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aláiz-Moretón, H.; Castejón-Limas, M.; Casteleiro-Roca, J.-L.; Jove, E.; Fernández Robles, L.; Calvo-Rolle, J.L. A Fault Detection System for a Geothermal Heat Exchanger Sensor Based on Intelligent Techniques. Sensors 2019, 19, 2740. https://doi.org/10.3390/s19122740
Aláiz-Moretón H, Castejón-Limas M, Casteleiro-Roca J-L, Jove E, Fernández Robles L, Calvo-Rolle JL. A Fault Detection System for a Geothermal Heat Exchanger Sensor Based on Intelligent Techniques. Sensors. 2019; 19(12):2740. https://doi.org/10.3390/s19122740
Chicago/Turabian StyleAláiz-Moretón, Héctor, Manuel Castejón-Limas, José-Luis Casteleiro-Roca, Esteban Jove, Laura Fernández Robles, and José Luis Calvo-Rolle. 2019. "A Fault Detection System for a Geothermal Heat Exchanger Sensor Based on Intelligent Techniques" Sensors 19, no. 12: 2740. https://doi.org/10.3390/s19122740