1. Introduction
Tactile sensing is a key sense for humans when carrying out manipulation tasks. It helps us to overcome problems such as finding objects in the dark, distinguishing materials or textures as well as keeping a stable grip when holding objects, among many other possibilities. The interest in the application of tactile sensors is consequently very desirable for humanoids [
1] and its use is growing in the field of robotic manipulation [
2]. These sensors can provide a wide range of information like surface features, material properties and acting forces during the contact experienced by the sensor, which are potentially useful for dealing with manipulation tasks [
3].
One area in which tactile sensors are applied is object recognition [
4]. For example, in Ref. [
5], a robotic hand with tactile sensors in the fingers and the palm was trained to recognise 20 different objects using only the tactile information. More recently, a set of novel tactile descriptors for object recognition were proposed [
6]. These descriptors were learnt using machine learning and showed their potential to be transferred in order to recognise new objects. Furthermore, the classification of materials is also being researched. In Ref. [
7], the authors worked on the recognition of six identical objects made of six different materials using tactile sensors as the only source of information. In other works, such as that of [
8], deep learning strategies were used to recognise 15 objects from tactile images obtained from a flexible tactile sensor mounted in an adaptive gripper.
In this work, we focus on another problem in which tactile sensing is a cornerstone: slip detection. Whenever a robotic hand grasps an object, it is fundamental for the robot to recognise whether the object is firmly grasped or is slipping from the hand. However, recognising this grasp state is generally not sufficient in robotic manipulation tasks. It is of greater value to obtain more information such as recognising the type of slippage and its direction, that is, whether the slip is translational (north, east, south, west) or rotational (clockwise, anti-clockwise). If the robot were able to obtain these details regarding the slip event, it could react accordingly to correct it, by either re-adjusting its fingers or moving the wrist or arm, among other strategies. Therefore, in this paper we work on the detection of these slip directions with tactile sensors. This is achieved using spatio-temporal tactile features and deep learning methods in order to learn them.
Our main contribution is an extensive evaluation of the usefulness of spatio-temporal tactile features when employed to detect the direction of slip. This evaluation is made by applying a new type of recurrent neural network (ConvLSTM [
9]), which is highly specialised in modelling spatio-temporal data. We chose to learn both spatial and temporal tactile features for this task because it seems reasonable to believe that the direction of slip has characteristics that belong to both components: slips occur in time (temporal aspect) and take place on a particular area of the hand (spatial aspect).
2. Related Work
Literature has approached the task of slip detection with tactile sensing from different levels of complexity. The objective of most of the previous works has been to detect two basic grasp states: stable and slipping. Some approaches have focused on the detection of these states by analysing the signals emitted by the tactile sensor. In Ref. [
10], the authors presented an approach in which the Break-Away Friction Ratio was used in order to predict slip. Although the method predicted slips in 4.2 ms, it required a previous exploration of the surface (5–7 s) in order to model its friction coefficients and it was only tested on three scenarios. Later, in Ref. [
11], the authors proposed a three-stage method that amplified an input force signal, which was then rectified and passed through a threshold, in order to return a binary slip signal (slip/stable). Similarly, in Ref. [
12], three different methods for detecting these states were compared. The first exploited friction cones, the second processed the tactile sensor with a bandwidth filter and the third consisted of a random decision tree that correlated tactile readings with grasp states. A similar work was carried out later in Ref. [
13], which showed that machine learning algorithms, and more specifically neural networks, could not only learn to detect these two grasp states but could also distinguish between two types of slips (translational/rotational), without hand-picked features for processing the tactile data as happens with classic methods. Although these works showed interesting approaches for slip detection, the slip types that they were able to recognise had a low degree of complexity. Identifying complex slip types is of greater value for a robotic controller since it allows the system to perform re-grasping strategies based on that knowledge, as demonstrated in Ref. [
14].
In the recent work described in Ref. [
15], six slip types were learnt using a neural network. The authors specifically worked on the task of learning to classify slippage in four directions (west, east, north, south) and two touching states (touch, no touch). Nevertheless, the proposed methodology continued with the trend of processing tactile readings as signals using a classical neural network, in which tactile values were concatenated in arrays, thus losing the spatial information encoded in the distribution of the sensor taxels. In contrast, some authors have been working on a different approach: rather than interpreting tactile readings as classical signals, they process them as if they were images. For example, in Ref. [
16], a Convolutional Neural Network (CNN) was trained to distinguish slippery grasps from stable ones. The authors used matrix-like tactile sensors (sensors in which taxels are arranged in a matrix-like distribution) and their readings were fed to the CNN as if they were images. This method has been also applied to non-matrix tactile sensors (sensors in which measuring points are not arranged as in a matrix) and also showed promising results for slip detection [
17].
CNNs have proved to have an outstanding performance as regards solving computer vision problems thanks to their ability to learn spatial features [
18]. However, they do not encode temporal characteristics explicitly. An approach to overcome this was presented recently [
19]. The authors used CNNs to extract spatial features from single tactile readings, which were arranged in a matrix-like structure. In parallel, sequences of these tactile images were also arranged in 3D images, in which the third channel corresponded to different tactile images in time, and then fed to the CNN in an attempt to learn temporal features. Despite this, the system was only tested for the object recognition task, which does not appear to require an explicit temporal aspect. Moreover, there are machine learning techniques that are more suitable than a CNN as regards learning temporal features.
One example of a machine learning technique that learns temporal features is a Long Short-Term Memory Network (LSTM) [
20]. Some authors have combined these networks with CNNs in order to learn temporal and spatial features [
21]. In the cited work, a tactile sensor with an internal camera, in combination with an external camera pointing to the gripper, was used to detect slips. The authors proposed to calculate spatial features from the sensor camera and the external camera using a CNN that had already been trained in a computer vision task, and then concatenated the features to create a mixed feature vector that was passed in sequences to a LSTM. The LSTM was, therefore, in charge of learning temporal features from the stream of spatial features. Although, in this case, the system learnt temporal features, it required the combination of tactile sensing with a vision system, something that is not always possible. Moreover, the learning of spatial and temporal features was not coupled to this task.
One of the firsts works on the use of spatio-temporal tactile features for slip detection was presented in Ref. [
22]. The authors proposed a descriptor that encoded sequences of tactile readings by extracting features from the raw tactile data and then pooling them over time, repeating the process at various scales. As a result, the system returned a descriptor that simultaneously encoded spatial and temporal features. In experimentation, this approach proved to be robust for both spatial and temporal variations. Later, [
23] presented one of the first applications for slip detection using Convolutional LSTM (ConvLSTM) [
9], a special case of LSTM with internal convolutions which were designed to learn spatio-temporal features. As in Ref. [
21], a tactile sensor with an internal camera was used in order to capture tactile readings. The recorded images were fed to the ConvLSTM in sequences, thus enabling it to learn spatio-temporal features. These two approaches showed great performance on the slip detection task. However, they could only differentiate between two states: slippery or stable grasp.
Given the promising performance of spatio-temporal tactile features in the aforementioned works, we propose their use to learn the task of detecting the direction of slip. Our work is close to that of [
23]. We also use a ConvLSTM but we analyse its performance in a more complex task: detecting the direction of slip, which requires learning to recognise more types of slips and not only slip/stable grips. In addition, we utilise a pure tactile sensor with just 24 sensing points rather than a camera-based sensor with a 30 × 30 image resolution. In these terms, our work is also close to that of [
15] because we aim to solve a similar problem using the same tactile sensor. Nevertheless, we overcome their limitations by covering more slip states, including rotational slippage (both clockwise and anti-clockwise). Moreover, we carry out a more in-depth study of the input data, in addition to use a different learning structure, that is more suitable as regards learning spatio-temporal features.
4. Experimentation
During experimentation, we first analysed the performance of the ConvLSTM learning spatio-temporal features from the recorded tactile data. Afterwards, we compared the generalisation capabilities of this algorithm with the LSTM network by training with the Basic set and testing on each of the other three sets. All of the experiments in this section were run on Ubuntu 16.04, Python 3.5.2, CUDA 8.0 and PyTorch 0.4.1 on a computer equipped with an Intel i5-4690K CPU at 3.5 GHz (4 cores), 16 GiB DDR3 RAM at 1867 MHz and a GeForce GTX 960 GPU.
4.1. ConvLSTM Parameters
In this first set of experiments, we exhaustively studied how the performance of the ConvLSTM changes depending on a number of parameters: number of ConvLSTM layers, the size of the convolutional filters and the number of filters inside each ConvLSTM layer. All of these experiments were carried out following a 5-fold cross validation methodology with the Basic set. The performance metric used to report results in this section is the accuracy. All of the trained networks used the cross-entropy loss and the Adam optimizer with a learning rate equal to 0.001.
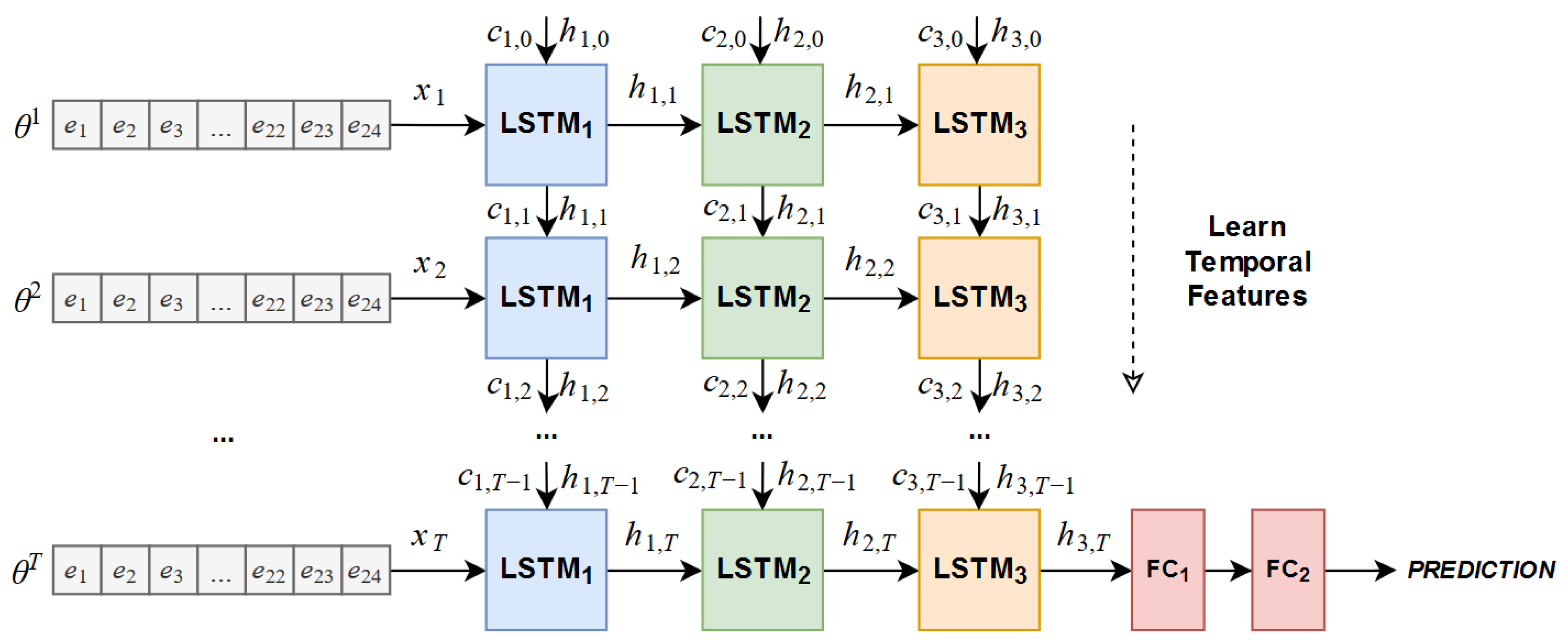
We defined an architecture similar to that previously shown in
Figure 3. The number of ConvLSTM layers was tuned on the first test, after which we changed the size of the convolutional filters and eventually tuned the number of filters in the ConvLSTM layers in order to choose that which provided the best performance. However, the rest of the network was fixed during the experiments: the last ConvLSTM layer was connected to a pooling layer, which was connected to two fully-connected layers with 32 units and ReLU activations. We also fixed the length of the sequence of the training samples to 10 consecutive tactile readings, the batch size to 32 and the number of epochs to 30.
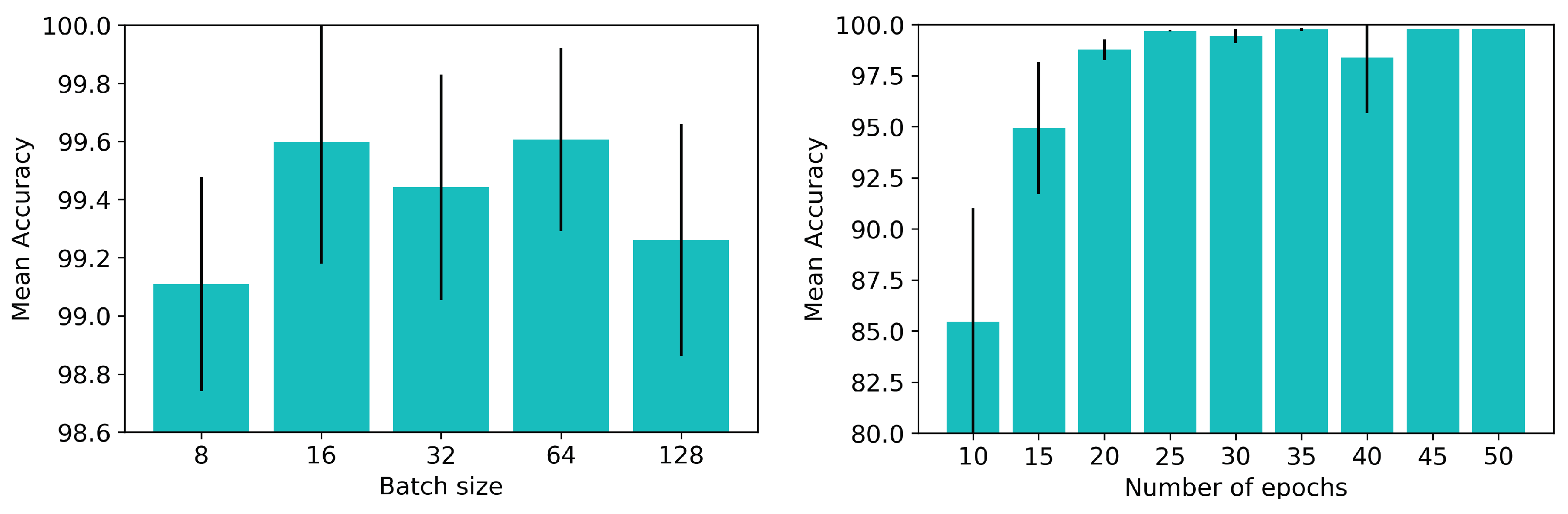
Figure 7 shows the results obtained from these experiments concerning the tuning of these parameters.
As can be seen in
Figure 7 (left), as the number of ConvLSTM layers in the network increased from 1 to 5, the system performed better in the same amount of training iterations. Nevertheless, increasing the number of ConvLSTM layers any further was detrimental to the performance. The system achieved an accuracy of 97.23% with 5 layers, but this rate decreased to 76.48% when the network had 10 ConvLSTM layers. As more layers were added, the network became more complex and it was more difficult to converge in the same amount of epochs. Given the results, we chose to keep using 5 ConvLSTM layers for the following experiments since this configuration had the best accuracy rate, with a low standard deviation (
).
We performed three experiments with three different sizes for the convolutional filters in the ConvLSTM layers (
Figure 7 (middle)): 3 × 3, 5 × 5 and 7 × 7. The input samples
had a size equal to
, where
B was the batch size (32),
T was the length of the sequence (10),
C was the number of channels (1, since we were using one sensor),
H was the height of the tactile image (12) and
W was the width of the tactile image (11). As can be seen in
Figure 7 (middle), the performance that was achieved decreased as we increased the size of the filter. Since the input tactile images were 12 × 11 images, bigger filters covered wider areas of the image. The filters were not, therefore, focusing on patches of the image but were rather taking into account almost the whole tactile image. Consequently, in the following experiments we continued to use 3 × 3 filters, thus allowing the network to pay more attention to lower-level details in the tactile images.
Finally, we tested the networks with 8, 16, 32 and 64 filters per ConvLSTM layer (
Figure 7 (right)). As had occurred with the first test in which we changed the number of ConvLSTM layers, as we increased the number of filters in these layers, the complexity of the network increased and it was, therefore, more difficult for it to learn the problem in the same number of epochs. In addition, increasing the number of ConvLSTM layers and the number of filters in them also increased the number of parameters in the network, signifying that these more complex networks were more time and memory consuming. As a result, in the following experiments, we chose to use ConvLSTM layers with 32 filters because they had the best accuracy rates in our experiments (
).
4.2. Temporal Input Sequence
For these experiments, we changed the length of the input samples in order to check how this would affect the performance of the ConvLSTM network. This was done by training network with 5 ConvLSTM layers (32 filters of 3 × 3 per layer), followed by a pooling layer and two fully-connected layers with 32 units and ReLU activations. Again, the experiments were carried out with a 5-fold cross-validation on the Basic set. The cross-entropy loss was used as well as the Adam optimizer with a learning rate equal to 0.001. The batch size was equal to 32 and 30 epochs were run.
Figure 8 shows the performance achieved when varying the input sequence in these experiments.
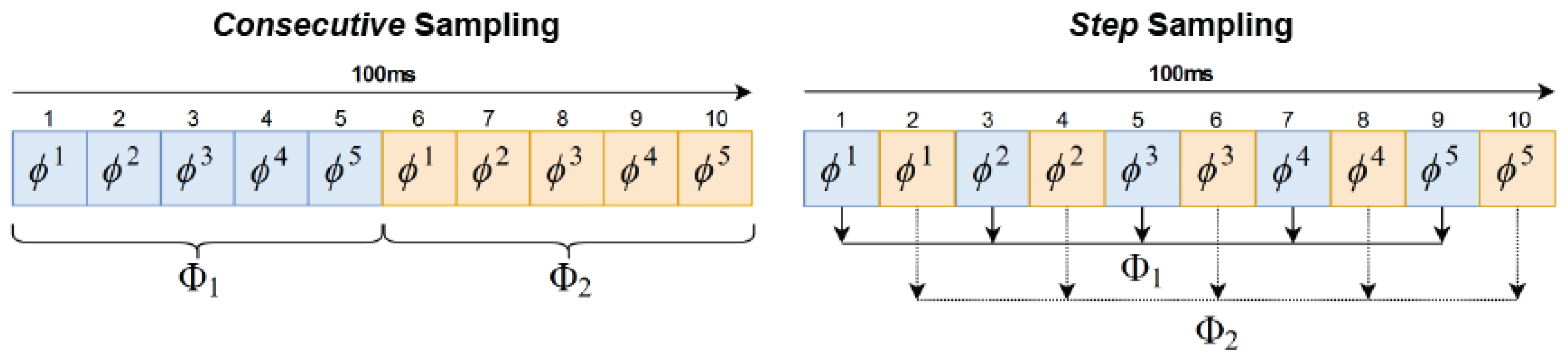
Figure 8 (left) presents the results obtained from the experiments with the
Consecutive sampling method, using
. Since the BioTac SP sensor has a peak publishing frequency of 100 Hz, these tests checked the performance of the ConvLSTM with approximately 30 ms, 50 ms, 100 ms, 300 ms and 500 ms of consecutive readings. Using 3 and 5 consecutive readings yielded accuracy rates of
and
, respectively. However, further increasing the number of tactile images in the samples reduced the accuracy rate achieved by the system.
Noise could be the reason for this decrease in the performance of the system with an increase in the consecutive tactile images included in each sample. In experimentation, we found that the BioTac SP sensor does not maintain the values of the readings at a constant number, but instead they fluctuate continuously (up to 197 points in its range ). The ConvLSTM memory could be affected by this noise and might require more training epochs in order to learn it. With just 3 or 5 consecutive readings there is less fluctuation, so the network can accurately learn to detect the direction of slip.
Regarding the
Step sampling experiments, we tested
and
. Since the peak recording frequency was 100 Hz, this value of
s meant an approximate time gap of 50 ms between a tactile reading
and the next
.
Figure 8 (right) presents the results obtained after running these experiments. In all of these tests, the performance of the system was above 99% accuracy, the standard deviation being the major difference between them. The ConvLSTM network managed to learn samples better when using the
Step method than when using the
Consecutive method. Since tactile readings
were more distant in time from each other, noise was not a big issue for the network and the direction of slip was more clearly identified in these samples.
Although these results suggested that using the Step sampling method would be better, we had to take into account the drawback of this method: time. A Step sampling with and meant that in order to create a sample we had to wait 250 ms until enough tactile readings were published by the BioTac SP sensor. The accuracy rate achieved by this configuration was . The best result achieved by the tests made with the Consecutive method was obtained using , which yielded . However, creating a sample with the Consecutive method only required 25 ms: the Consecutive method gave us a similar result in terms of accuracy in a tenth part of the time required to create a sample with the Step method. We found that this was of paramount importance for the problem in hand. Due to the fact that we want to detect the direction of slip, the earlier we can detect it, the faster we can react and avoid a complete loss of grip on the object. We consequently continued to use the Consecutive sampling method with in the following experiments.
4.3. Convergence
We checked how batch size and the number of epochs would affect the convergence of the ConvLSTM network. In detail, we used the same network as in the previous section, trained with input samples whose length was 5 consecutive tactile readings. Again, the experiments were carried out with a 5-fold cross-validation on the Basic set. The cross-entropy loss was used as well as the Adam optimizer with a learning rate equal to 0.001. We present the obtained results in
Figure 9.
Regarding the batch size, there were no significant differences in the accuracy rate depending on this parameter. All of the configurations tested achieved rates above 99% with similar standard deviations. Literature states [
29] that using larger batches results in models with lower generalisation capabilities. We, therefore, chose to use a batch size of 32 training samples for the rest of the experiments in order to keep a good balance between the training speed and the quality of the resulting model. Finally, the tests carried out with the number of epochs showed that at around 30 epochs the ConvLSTM network converged, and that training further did not lead to an improvement in the accuracy rate. The remaining experiments carried out were consequently run until 30 epochs.
4.4. Robustness Test
In these experiments, we verified how the ConvLSTM, trained with the Basic set, managed to generalise in order to detect the direction of slip in samples recorded from the other three sets: the Solids set, the Small set and the Textures set. In addition, we compared its performance with a tuned LSTM network, since it computes temporal features while the ConvLSTM computes spatio-temporal features, which should be more useful for the problem tackled in this work.
Two ConvLSTM networks were used to carry out these experiments: the
Tuned ConvLSTM, which is the best performing network from the previous experiments with the Basic set; and the
Regularised ConvLSTM, which is a simpler network with higher generalisation capabilities. In detail, the
Tuned ConvLSTM consists of a network with 5 ConvLSTM layers (32 filters of 3 × 3) followed by a pooling layer and two fully-connected layers with 32 units and ReLU activations. With regard to
Regularised ConvLSTM, it has 3 ConvLSTM layers (32 filters of 3 × 3) followed directly by two fully-connected layers with 32 units and ReLU activations, so there is no pooling after the ConvLSTM layers. In addition, this network is regularised with batch normalisation, dropout in the fully-connected layers (30% probability of a unit to be zeroed) and L2 regularisation (0.001). Finally, the
Tuned LSTM has a similar configuration to the
Regularised ConvLSTM, but instead of the ConvLSTM layers it has 3 LSTM layers with 32 units. All of these networks were trained with a batch size of 32 samples during 30 epochs, using cross-entropy loss and the Adam optimizer with a learning rate equal to 0.001. The results were obtained after training the networks 5 times, shuffling the training set (Basic set) and testing them each time with the Solids, Small and Textures set.
Figure 10 presents the accuracy rates achieved by each of the networks for each test set.
Figure 10 shows that the network that performed worst in this robustness test was the Tuned ConvLSTM. This network was configured by choosing the parameters that performed best in previous sections. However, those tests were performed on the Basic set, which did not guarantee that the resulting network could properly generalise to new objects and textures. As a result, the Tuned ConvLSTM overfitted to the Basic set. In contrast, the Regularised ConvLSTM was prepared in order to avoid overfitting with regularisation techniques, in addition to reducing the network complexity. As a result, this ConvLSTM performed much better than the tuned version.
The Regularised ConvLSTM achieved a greater mean accuracy on the Solids set than on the other two sets: it yielded an accuracy rate of 82.56% for this set, while it achieved accuracy rates of 70.94% and 73.54% for the Small and Textures sets, respectively. This trend was also visible in the results obtained for the Tuned ConvLSMT and the Tuned LSTM. The Solids and the Basic sets are similar in that both sets contain objects with similar features: the bottle and the cardboard in the Solids set have a similar stiffness and size to the hard drive and the metal pen holder in the Basic set. As a result, the Solids set produced contact patterns that were similar to the ones already seen by the networks in the Basic set. In contrast, the Small set and the Textures set contain objects that are far more unlike the objects in the Basic set. The features learnt from the Basic set with these networks were consequently not as good at classifying samples from these two sets as they were at classifying samples from the Solids set.
Table 2 shows further details of the performance of the networks trained on the test sets.
Since the problem we approach in this work is a multi-class classification, the arithmetic mean of the precision, recall and F1-score among all of the classes is reported, along with the mean accuracy, in
Table 2. With regard to the performance of the Tuned LSTM, it yielded similar results to the Regularised ConvLSTM. Generally speaking, the Tuned LSTM obtained greater values in most of the sets and metrics than the Regularised ConvLSTM, particularly for the Small set tests. Nevertheless, the differences were not significant. Moreover, the standard deviations of its results were also greater for all the metrics, showing that the Tuned LSTM had a less robust performance. The Regularised ConvLSTM had a more constant performance during the 5 iterations of training and testing carried out. It was less sensitive to the training so its spatio-temporal features were stable. That is, the training iterations of the Regularised ConvLSTM resulted in similar spatio-temporal features that performed similarly. The temporal features calculated for the different training iterations of the Tuned LSTM were more dissimilar to each other, and it was for this reason that its performance varied more from training iteration to training iteration. The most significant difference between the LSTM and the two ConvLSTM approximations was the input data type. In contrast to the LSTM, which received the values of the 24 electrodes, the ConvLSTM received a created tactile image whose size might have been small for this type of neural network. In deep learning, in order to learn better spatial features, images with higher resolution than our tactile images are frequently used for training. Despite this fact, the Regularised ConvLSTM achieved a robust performance on the generalisation tests.
Figure 11 shows the confusion matrices of the best performing configurations of each network for each test set. Note that distinguishing the four translational directions of slip was not as hard as distinguishing clockwise rotational slip, anti-clockwise rotational slip and touch (labelled
cw,
aw,
t in the matrices). Samples belonging to the four translational slips were, in general, correctly classified but samples belonging to the rotational slips and touch were frequently confused. More specifically, these three classes were confused with each other. In the rotational slips, there was no translational movement over the entire surface of the sensor. Hence, the tactile readings were localised in an area of it but there was some fluctuation in values around the centre of the rotation. Touch samples were produced by placing the object at a certain point on the surface of the sensor without moving it. Given that the readings from the BioTac SP sensor are constantly wavering owing to its inherent noise, it could be possible that a touch sample had a similar fluctuating pattern as regards the values of the electrodes to that produced by a rotational slip. This would be confirmed by the fact that rotational slips were mainly confused with touch and not significantly with each other.
5. Conclusions
The task of detecting the direction of slip using tactile sensors is still an open issue in robotic dexterous manipulation. Previous works approach this problem by simplifying it to the classification of grasps in two states: stable or slippery. However, it is of greater use if a robotic controller gets to know not only whether or not a grip is stable, but also the direction towards which a grasped object could be slipping. In this work we, therefore, propose the use of spatio-temporal features learnt using a specialised neural network: a Convolutional Long Short-Term Memory (ConvLSTM).
In order to check the performance of this type of networks in the task of detecting the direction of slip, we used a BioTac SP sensor. This sensor has 24 sensing points or taxels, which are electrodes that are distributed over the entire surface of the sensor. Since the ConvLSTM uses a matrix-like structure to learn spatio-temporal features, we converted the tactile readings from the BioTac SP sensor into tactile images. Four object sets, containing a total of 11 different objects, were used to capture a new tactile dataset, available at
https://github.com/yayaneath/BioTacSP-DoS. Samples recorded were classified in slip north, slip south, slip east, slip west, slip clockwise, slip anti-clockwise or touch.
After training in experimentation with these datasets, we have proved that ConvLSTM can learn useful spatio-temporal features in order to detect the direction of slip effectively. In the task of detecting these seven states on already seen objects, the system achieved an accuracy rate of 99%. To do so, the system required only an input with five consecutive tactile readings, which were recorded in just 50 ms of wall time. In addition, a forward-pass of a batch took only 3 ms. As a result, the proposed approach proved to be fast and accurate for this task.
However, the ConvLSTM network was sensitive to new objects. During the robustness experiments, its performance dropped to an accuracy rate of 82.56% in the case of new objects with familiar properties (Solids set), but continued to decrease to 73.54% and 70.94% for stranger sets like the Textures and Small sets. In comparison, a tuned LSTM attained similar results with these tests, though with a greater sensitivity to the training convergence. In addition, the problem in hand proved to be challenging and the networks struggled to distinguish rotational slips from stable contacts (touch).
In the future, we would like to implement the proposed system in the control loop of a multi-fingered hand, thus enabling it to use this information to manage re-grasping strategies. Moreover, we would like to integrate more tactile sensors in the detection of the direction of slip. It seems reasonable to believe that doing so should increase the generalisation capabilities of the system since more sensing points would reduce the entropy of slips, like the rotational ones recorded.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}