1. Introduction
Uncertainty in engineering has been considered as a critical problem as it could result in serious financial losses or catastrophic accidents. Specifically, if a machine in a production line suddenly malfunctions, the line will stop, which leads to significant financial losses. Therefore, it is critical to predict malfunctions or the life of manufacturing machines. This requirement has resulted in active research regarding the prognostics and health management of machinery with the benefit of the fourth industrial revolution from the significant progress in data science, computer performance, and communication.
For the health monitoring or diagnosis of a machine, we need sensors to measure the status of the machine, including sensors to measure temperature [
1], pressure [
2], volume pressure [
3,
4], and acceleration [
5,
6,
7]. Among these sensors, acoustic emission sensors and accelerometers are the most commonly used for monitoring machines as they can provide instantaneously the status of a machine with high data sampling frequencies, which is not possible with temperature or pressure sensors. In other words, we can obtain large amounts of information over a relatively short measurement time. Accelerometer signals that measure structural vibration are especially useful in monitoring rotary machines, such as gear sets and bearings, as their frequencies are closely related to the frequency of the mechanical mesh and the machine structure [
8,
9]. In this study, we investigate the techniques for monitoring machinery with the acceleration signals.
The approaches for the fault diagnosis are categorized into model-based, signal-based, knowledge-based, hybrid-based [
10], and active approaches [
11,
12]. Among the five approaches, model-based, signal-based and knowledge-based approaches are mostly applied in the machine fault diagnosis. Model-based methods employ specific dynamic models or theories which simulate the real condition. Luo [
13] proposed a shape-independent method to model different kinds of tooth spalls and validated by finite element analyses. Endo [
14] diagnosed spalls and cracks on the gear tooth based on simulated signals. Park [
15] diagnosed gear faults in planetary gears using transmission errors simulated from a dynamic model.
Signal-based methods use the aforementioned signals with prior knowledge. Lebold [
16] reported a signal processing procedure to extract features from the vibration signal for monitoring a gear set. The first step in this method was extracting statistical parameters, such as root mean square, kurtosis, and skewness, from raw vibrational signal that could include important information regarding mechanical faults. The second step was extracting features from the cyclic signal from which noise is removed by the time synchronous averaging (TSA) technique [
8]. Additional signal features could be obtained from the residual signal remaining after removing the gear mesh frequency, the difference signal obtained by further removing the sideband of the mesh frequency, or the band-pass mesh signal, which is the band frequency signal extracted from the TSA signal. He et al. [
17] employed bearing characteristic frequencies as the representative features for the analysis of bearing faults. The bearing characteristic frequencies are the metrics of frequency densities related to a specific part of a bearing. Statistical parameters, such as kurtosis, are also used to measure degradation and the degree of bearing defects.
The model-based and signal-based methods are commonly employed for the diagnosis of gear sets and bearings. However, these approaches are available only when the signal is measured in a stationary status. It is also virtually impossible for engineers to apply the approaches to a system of which structure is complex and dynamic characteristics, such as operational frequency of the gear sets and bearings, is not sufficient. In order to overcome these limitations and meet the demands of diagnoses of various system types, knowledge-based methods, also called data-driven methods, have been proposed. A considerable number of research works [
18,
19,
20,
21] based on the approach have been carried out recently. In the knowledge-based methods, professional information or knowledge of the systems are not necessary. Instead, a machine-learning algorithm recognizes patterns of each class and diagnoses the systems by themselves. However, it requires a large amount of historical data to find important information for the fault diagnoses [
22]. In order to overcome the limitations of the three different methods, we propose a new fault diagnosis method called a critical information map (CIM), that works with (1) relatively small amounts of data, (2) non-stationary signals, and (3) unknown system structures and dynamics as discussed in this study.
The details of our idea are presented in the following sections:
Section 2 explains pre-processing processes, which apply to the raw signals, include data synchronization, time frequency representation (TFR) transformation, and spectral subtraction.
Section 3 includes an optimization process that addresses the important parameters to achieve critical information map. A case study of data acquiring from manipulator is introduced and the CIM method is validated in
Section 4. Another case study based on the data from the National Aeronautics and Space Administration (NASA) repository has been employed to validate the usefulness of the CIM, comparing performance with other methods in
Section 5. Finally, in
Section 6, we discuss the validation results and the usefulness of this technique in a prognostics and health management (PHM) problem.
2. Critical Information Map (CIM): Pre-Processing
In this study, we propose a TFR-based CIM that includes the information of the locations within the TFR spectrograms that shows clear (or large) difference between normal and fault conditions. An engineer can diagnose the system fault by identifying differences of the parameters at the specific regions of the CIM of a system of interest. Using this approach, we believe that detailed structural or dynamic knowledge of a system is not necessary since we employ TFR-based spectrograms. In addition, the proposed approach is applicable to the non-stationary signal-based diagnoses as we preserve and make use of the domain of the TFRs. Finally, this approach requires relatively small amounts of training data compared to that required by the TFR and convolutional neural network (CNN) approaches.
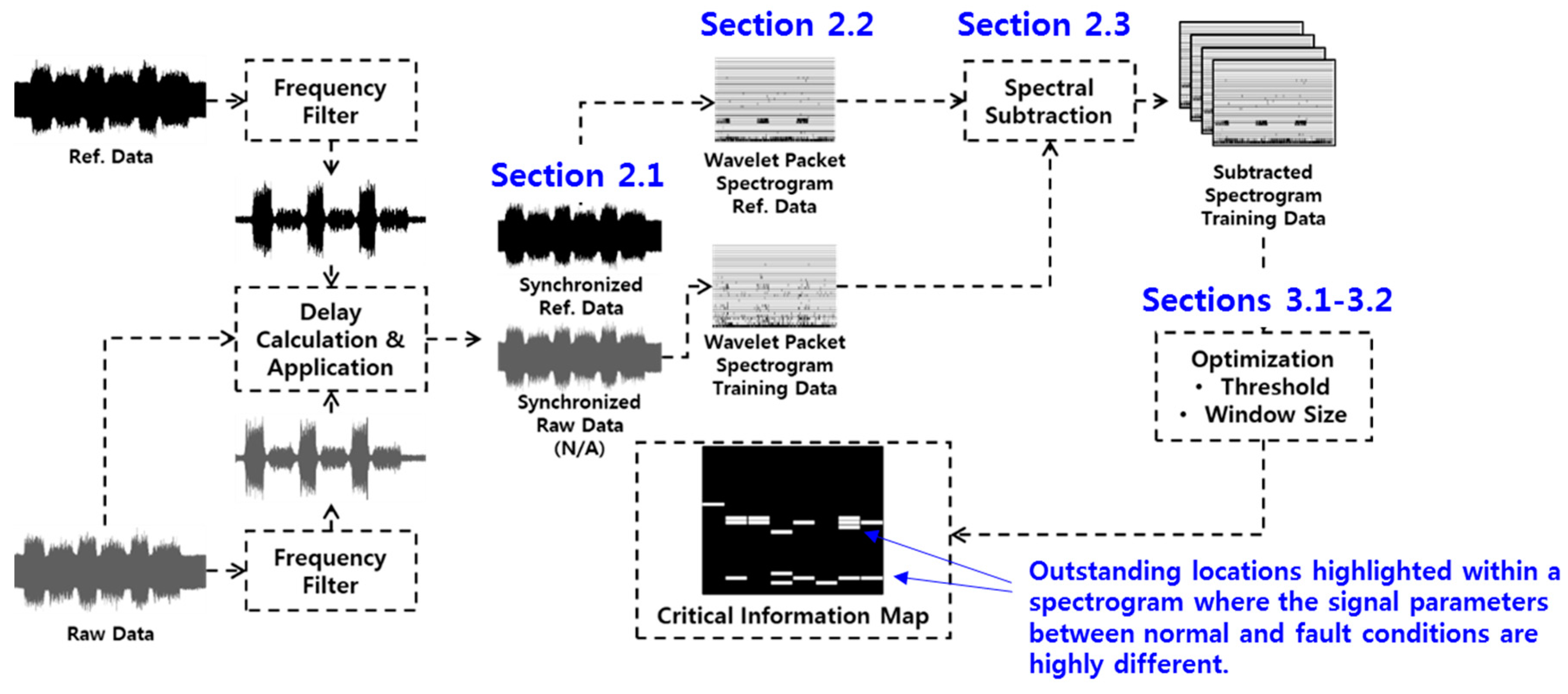
The overall procedure of creating a CIM with raw measured vibrational signals is illustrated in
Figure 1. It comprises three pre-processes: data synchronization that is discussed in
Section 2.1, wavelet packet transformation discussed in
Section 2.2, and spectral subtraction explained in
Section 2.3. Without the pre-processing steps, the following step (i.e., optimization process) cannot be converged. The final optimization process for creating CIMs is discussed in
Section 3.
2.1. Data Synchronization
Measured data typically includes a time delay that needs to be eliminated by synchronization. In this study, we employ cross-correlation for the time synchronization. Before the synchronization, we first extract non-stationary movement signals of interest using a band-pass filter as other unrelated signals become noise and hinder the time synchronization.
Cross-correlation is typically used to synchronize two different time-series signals. The conformity degree between the two signals is defined as
where
f is the original function,
is the filtering function, and τ is the time delay between the two signals [
23]. We determine the time delay (
that maximizes the cross-correlation,
, which is
. The raw signal is then synchronized with the original signal for comparison by applying the
.
2.2. Time Frequency Representation (TFR) Transformation
For developing CIM, we convert raw signals to TFRs (i.e., two-dimensional data plots) for the effective representation of the signal information for humans as well as computers. Short-time Fourier transform (STFT), wavelet transform (WT), and wavelet packet decomposition (WPD) are the linear methods commonly used for the transformation [
24]. The primary differences between the three methods are the form of the filter and the shapes of the spectrum tile (i.e., window) delivered from the filter.
In the STFT method, the size of the windows is pre-determined and identical for all frequency and time domains, as shown in
Figure 2a. In addition, one frequency density value is assigned for each window. The pre-determination of the window size can, at times, increase the degree of uncertainty in the high- and low-frequency domains of the transformed diagrams [
25]. Verstraete [
26] reported that CNN models that were trained based on the two-dimensional image data transformed using the STFT method exhibited low algorithm reliability. The WT method overcomes this limitation by varying the size of the window of each time and frequency domain, as shown in
Figure 2b. However, in WT method, the resolution of the time and frequency domains are determined by the number of windows, which makes the window sizes uneven in the domain. Additionally, WT decomposes only the low frequency component at subsequent levels where as WPD decomposes both low- and high-frequency components at each level. WT is not desirable for creating a CIM for fault identification where signal contains high frequency information. The WPD method addresses the limitations of the two methods.
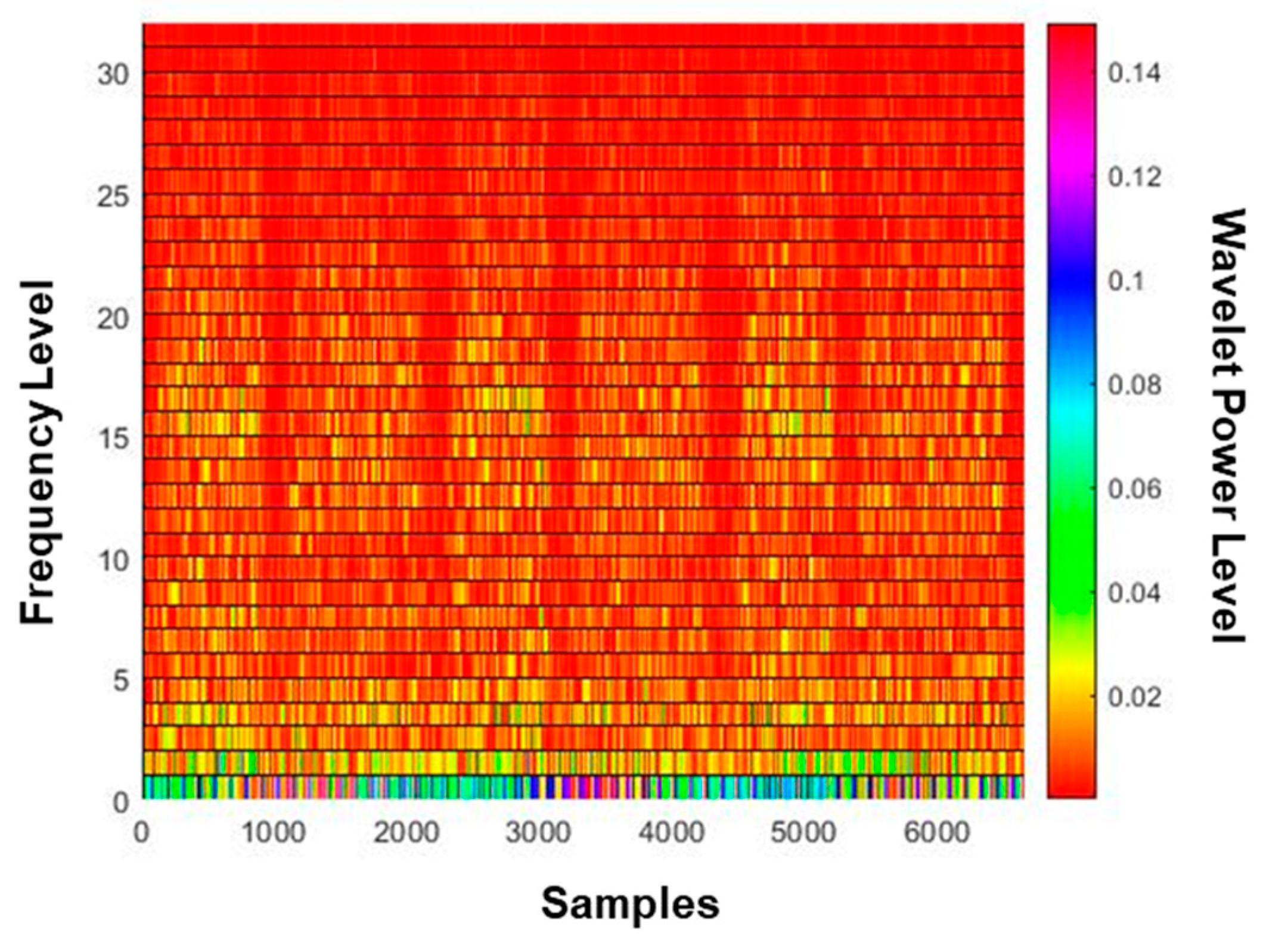
As can be seen in
Figure 2c, the WPD method assigns a different filter at each divided domain, which provides a high degree of freedom in setting the size of tiles. Compared to the STFT method that uses only one filter, we can obtain more reliable frequency density values with the WPD method. In this study, we employ WPD as the TFR method for creating the CIM. In WPD, the kernel function of the wavelet packet to decompose the signal to several frequencies is:
Equation (1) includes three positive integer constants: j is the index scale, k is the translation operation, and n is the modulation parameter or oscillation parameter. The first and second wavelet packet functions need to be predefined, as shown in Equations (2) and (3), which are known as the usual scaling function and mother function, respectively.
additional functions may be created as follows:
where
and
are the quadrature mirror filters, which are orthogonal to each other. The wavelet packet coefficient in a
j, n, k state that represents the density of a filter is:
where
is the time signal that will be analyzed. The values of the wavelet packet coefficients that will be used for developing the CIMs are displayed in the WPD spectrogram in
Figure 2c. The details of the WPD are beyond the scope of this study, and can be found in [
27]
2.3. Spectral Subtraction
In this study, we use the spectral subtraction technique to determine the critical area on the WPD by which we can screen fault conditions from the samples. The spectral subtraction technique has been employed by acoustics engineers to filter out unwanted noise. The basic principle is to extract signals in the domain where speech signals do not exist, and then using the extracted signal to enhance the voices.
In the spectral subtraction, the modified signal spectrum is as follows:
where
is the spectrum with speech and noise, and
is the noise spectrum without speech. Berouti et al. [
28] obtained speech signals without noise by the Fourier inversion of
. Denda [
29] employed spectral subtraction based on a wavelet transformed spectrum, which is represented as follows:
where
is the wavelet spectrum of enhanced speech,
is the wavelet spectrum of the observed signal, and
the wavelet spectrum of noise. In addition,
is the reduction factor, and
a and
b are the filter location and scale parameters in the wavelet transformation spectrum, respectively. El Bouchikhi [
30] assumed the spectrum domain without speech as the signal from normal bearings and the spectrum domain with speech as the signal from faulty bearings. After the spectral subtraction, El Bouchikhi obtained improved diagnosis results.
In this study, we performed the spectral subtraction in Equation (8) based on the spectrogram obtained by WPD to identify the critical region of the spectrogram for fault identification. We subtracted the signal spectrum of the normal condition from that of the abnormal condition, which indicates that specific features of the normal condition data are removed. In this study, normal-reference (N-R) indicates the spectrogram obtained by subtracting the reference signal from the normal condition signal. A normal dataset is randomly selected as the reference signal for this spectral subtraction to fix a ground value of the spectral coefficient. Abnormal-reference (A-R) is then the spectrogram derived by subtracting the reference signal from the abnormal one. We mutually subtract between the spectrums of N-R and A-R to obtain the degree of random error, such as measurement error. We discuss the technique to deal with the random error for robust decision-making in diagnosis in
Section 3.
6. Discussion and Closure
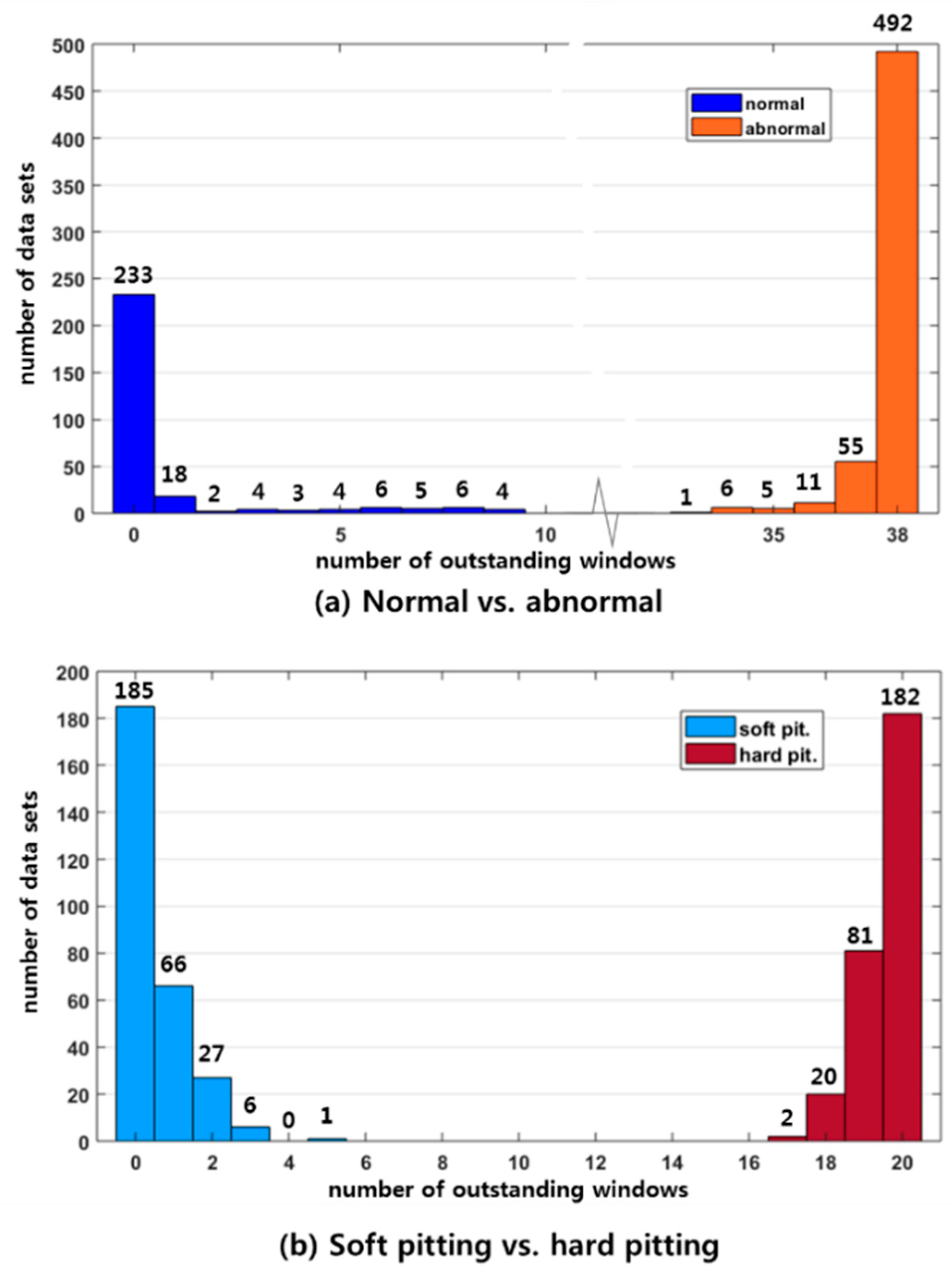
We identified the following observations from the two examples for the validation of the proposed method. Firstly, the proposed CIM approach requires the smaller amount of training data. In the first case study, we used only 45 datasets out of 900 samples, which is only 5% of the data, for developing the CIM. The classification results with the two developed (or trained) CIMs exhibited 100% prediction accuracy, which is an outstanding result. In the second case study, the number of training data sets are 60 out of 560 in total. The results of the case study are also 100% of prediction accuracy, which cannot be achieved by other methods with much large training data.
In addition, the CIM approach for identifying the mechanical faults could be fully automated without expert knowledge of the system being required, which is similar to the current methods, however, they need a large amount of training data. Once a signal is observed, we could accurately identify the status of a system by pre-processing (i.e., time-synchronization, TFR transformation, and spectral subtraction) and make a decision based on optimized CIM in an automated and timely manner.
The validation examples are both for non-stationary and stationary systems. As the robot arm moves upward and downward, two different types of signals, with a time gap, are obtained from the sensor. Moreover, the operating frequencies of the two movements are different as their velocities differ. In this case, the extracted signals of a frequency would be mixed with redundant data, which will increase the signal-to-noise ratio. However, the CIM approach uses TFRs and searches for OWs, which is uniquely beneficial among many different signal frequencies and time domains. This method will efficiently capture the critical information of the two completely different robot arm movements. The second case study, the rotating machine supported by the NASA repository, is a stationary system, of which classification result using the CIM approach is also very accurate with 100%.
From the above observations, we believe that the CIM-based diagnosis approach proposed in this study is functional with a small amount of training data for the diagnosis of non-stationary and stationary systems in an automated manner without expert knowledge for extracting important signal features. However, the proposed CIM approach is designed for the diagnosis of fast dynamic systems. It may not suit slow dynamic systems, such as reactors. In addition, we need further research, such as a hybrid approach using CIM and dynamic analyses, to apply this technique to prognostics.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}