1. Introduction
Deep neural networks have become extremely popular as they achieve state-of-the-art performance on a variety of important applications including image classification, image segmentation, language processing, and computer vision [
1]. Deep neural networks typically have a set of linear components whose parameters are usually learned to fit the data, and a set of nonlinearities, which are pre-specified, typically in the form of a sigmoid, a tanh function, a rectified linear unit, or a max-pooling function. The presence of nonlinear activation functions at each neuron is essential to give the network the ability of approximate arbitrarily complex functions [
2], and its choice affects net accuracy and sometimes the speed of training.
In this paper, we perform a large-scale empirical comparison of different activation functions across a variety of image classification and for an image segmentation problem. Starting from two of the best performing models, i.e. ResNet50 [
3] for the classification task and DeepLabv3+ [
4] for the segmentation task, we compare different approaches for replacing activation layers and different methods for building ensembles of CNNs obtained by varying the activation layers.
After presenting and comparing several activation functions, we propose a new model based on the use of different activation functions at different levels of the graph: to this aim, we propose a method for stochastic selection of activation functions to replace each activation layer of the starting network. The activation functions are randomly selected from a set of nine approaches, including the most effective ones. After training the new models on the target problem, they are fused together to build an ensemble of CNNs. It is well known in the literature [
5] that networks trained using back propagation are unstable; this behavior can be used for building an ensemble of classifiers. These networks are partially independent, and their fusion permits to boost the performance of a stand–alone network.
The proposed framework for ensemble creation is evaluated on two different applications: image classification and image segmentation. In the image classification field, we deal with several medical problems by including in our benchmark 13 image classification datasets. Biomedical image retrieval is a challenging problem due to the varying contrast and size of structures in the images [
6]. CNNs have already been used on several medical datasets reaching very high performance, including keratinocyte carcinomas and malignant melanomas detection [
7], sub-cellular and stem cell image classification [
8], thyroid nodules classification [
9] from ultrasound images, or breast cancer recognition [
10]. Our testing protocol includes a fine-tuning of each model in each dataset and a testing evaluation and comparison: our experiments show that the proposed ensembles work well in all the tested problems gaining state-of-the-art classification performance [
11].
In the image segmentation field, we deal with the skin segmentation problem: the discrimination of skin and non-skin regions in a digital image has a wide range of applications including face detection [
12], body tracking [
13], gesture recognition [
14], and objectionable content filtering [
15]. Skin detection has great relevance also in the medical field, where it is employed as a component of face detection or body tracking: for example, in the remote photoplethysmography (rPPG) problem [
16], it is a component of a system solving the problem of estimating the heart rate of a subject given a video stream of his/her face. In our experiment, we carry out a comparison of several approaches performing a single training on a small dataset including only 2000 labeled images, while testing is performed on 11 different datasets including images from very different applications. The reported results show that the proposed ensembles reach state-of-the-art performance [
17] in most of the benchmark datasets even without ad-hoc tuning.
2. Literature Reviews
In the last years, deep learning has gained increasing attention in several computer vision applications, such as image classification and retrieval, object detection, image segmentation, and many other applications [
18]. CNNs are deep neural networks designed to work similarly to the human brain in visual perception: CNNs are able to distinguish meaningful features in an image in order to classify the image as a whole. They are constituted of several types of layers of neurons: i.e., convolutional layers, activation layers, subsampling layers, and fully connected layers [
19].
Most recent architectures present a substantially higher number of layers and parameters, which gives much more representation learning capability to those models. However, many parameters can produce overfitting. This problem can be solved with the introduction of regularization techniques, data augmentation, and better performing activation functions.
In particular, the purpose of activation layers is to decide if a neuron would fire or not, according to a nonlinear transformation of the input signal. The design of new activation functions in order to improve training speed and network accuracy is an active area of research [
20,
21]. Recently, the sigmoid and hyperbolic tangent, which were the most widely used activations functions, have been replaced by Rectified Linear Units (ReLU) [
22]: ReLU is a piecewise linear function equivalent to the identity for positive inputs and zero for negative ones. Thanks to the good performance of ReLU and the fact that it is fast, effective, and simple to evaluate, several alternatives to the standard ReLU function have been proposed in the literature. The most known “static” activation function are: Leaky ReLU [
23], an activation function equal to ReLU for positive inputs but having a very small slope α > 0 for negative ones; ELU [
21], which exponentially decreases to a limit point α in the negative space; and SELU [
24], a scaled version of ELU (by a constant λ). Moreover, in [
25], a randomized leaky rectified linear unit (RLReLU) is proposed, which uses nonlinear random coefficient instead of linear. The choice of optimal activation functions in a CNN is an important issue because it is directly related to the resulting success rates. Unfortunately, an analytical approach able to select optimal activation functions for a given problem is not available; therefore, several approaches try to determine them by trial and error. “Dynamic” activation functions are a class of function whose parameters, differently from “static” ones, are learned during training. Parametric ReLU (PReLU) [
26] is a Leaky ReLU where the amount of the slope α is learned; Adaptive Piecewise Linear Unit (APLU) [
20] is a piecewise linear activation function with learnable parameters: it calculates piecewise linear function independently for each neuron and learns them during the training process. Another “dynamic” function is proposed in [
27], whose shape is learned by a linear regression model. In [
28], two different variants are proposed: a “linear sigmoidal activation”, which is a fixed structure function whose function coefficients are static, and its “dynamic” variant, named “adaptive linear sigmoidal activation”, which can adapt itself according to the complexity of the given data. Two of the best performing functions are Swish [
29], which is the combination of a sigmoid function and a trainable parameter, and the recent Mexican ReLU (MeLU) [
30], which is a piecewise linear activation function that is the sum of PReLU and multiple Mexican hat functions.
The main difference between “static” and “dynamic” functions is that the first class of activations considers all the neurons and layers as identical, while second class learns parameters independently for each layer or even each neuron. Although the “dynamic” activation functions perform better than “static” in some applications, their parametric nature increases the number of trainable parameters and thus the possibility of overfitting. In this work, we propose a mixture of “static” and “dynamic” activation functions.
3. Activation Functions
This study considers 10 different activation functions (more details, and specific reference for each function, are given in [
30]), namely the widely used ReLU and several variants. The functions used are summarized in
Table 1, while in the following the analytical expression together with their derivatives are given. Several dynamic activation functions depend on a hyperparameter, named
, which is a normalization factor to better deal with input images varying between [0,1] or [0,255].
The well-known ReLU activation function, for the generic couple of points
, is defined as:
and its derivative is easily evaluated as:
This work also considers several variants of the original ReLU function. The first variant is the Leaky ReLU function, defined as:
where the parameter
is a small real number (0.01 in this study). The main advantage of Leaky ReLU is that the gradient is always positive (no point has a zero gradient):
The second variant of the ReLU function considered in this work is the Exponential Linear Unit (ELU) [
21], which is defined as:
where
is a real number (1 in this study). ELU has a gradient that is always positive:
The Parametric ReLU (PReLU) is the third variant that is considered here. It is defined by:
where
is a set of real numbers, one for each input channel. PReLU is similar to Leaky ReLU, the only difference being that the
parameters are learned. The gradient of PReLU is:
S-Shaped ReLU (SReLU) is the fourth variant. It is defined as a piecewise linear function:
In this case, four learnable parameters are used,
and
, expressed as real numbers. They are initialized to
,
, and
. SReLU is highly flexible thanks to the rather large number of tunable parameters. The gradients are given by:
The fifth variant is APLU (Adaptive Piecewise Linear Unit). As the name suggests, it is a linear piecewise function. It is defined as:
where
n is an hyperparameter, set in advance, defining the number of functions (or hinges); and
and
are real numbers, one for each input channel. The gradients are evaluated as:
In our tests, the parameters are initialized to 0, and the points are randomly chosen. We also added an -penalty of 0.001 to the norm of the parameters .
An interesting variant is the Mexican ReLU (MeLU), derived from the Mexican hat functions. These are defined as:
where
and
are real numbers. These functions are used to define the MeLU function, based on the definition of the PReLU detailed above:
The parameter represents the number of learnable parameters for each input channel, are the learnable parameters, is the parameter vector in PReLU, and and are fixed parameters chosen recursively. The MeLU activation function has interesting properties, inherited from the Mexican hat functions, that are continuous and piecewise differentiable. ReLU can be seen as a special case of MeLU, when all the parameters are set to 0. This is important because pre-trained networks based on the ReLU function can be enhanced in a simple way using MeLU. Similar substitutions can be made when the source network is based on Leaky ReLU and PReLU.
As previously observed, MeLU is based on a set of learnable parameters. The number of parameters is sensibly higher with respect to SReLU and APLU, making MeLU more adaptable and with a higher representation power but more likely to overfit. The gradient is given by the Mexican hat functions. The MeLU activation function also has a positive impact on the optimization stage.
In our work, the learnable parameters are initialized to 0, meaning that the MeLU starts as a plain ReLU function; the peculiar properties of the MeLU function come into play at a later stage of the training. The first Mexican hat function has its maximum in and is equal to zero in 0 and . The next two functions are chosen to be zero outside the interval [0, ] and [, ], with the requirement being they have their maximum in and . The parameters and are chosen to fulfill this requirement.
In this work we test two values of k, the standard value is k = 4 for MeLU and a wider version of the function for k = 8 (wMeLU).
The Gaussian ReLU, also called GaLU, is the last activation function considered in our work. Its definition is based on the Gaussian type functions:
where
and
are real numbers. The GaLU activation function is defined as:
which is a formulation similar to the one provided for MeLU, which again depends on the parameters
and
. Again, the function is defined in this way to provide a good approximation of nonlinear functions. We use
for GaLU and
for its “smaller” version sGaLU.
Please note that, to avoid any overfitting, we use the same parameter setting suggested by the original authors for each activation function, as reported in
Table 1.
4. Materials and Methods
In this section, we describe both the starting models and the stochastic method proposed to design new CNN models and create ensembles. In the literature, several CNN architectures have been proposed for image classification (AlexNet [
32], GoogleNet [
33], InceptionV3 [
34], VGGNet [
35], ResNet [
3], and DenseNet [
36]) and segmentation problems (SegNet [
37], U-Net [
38], and Deeplabv3+ [
4]). In our experiments, we selected two of the best performing models: ResNet50 [
3] for image classification and Deeplabv3+ [
4] for segmentation. ResNet50 is a 50-layer network, which introduces a new “network-in-network” architecture using residual layers. ResNet50, which was the winner of ILSVRC 2015, is one of the best performing and most popular architectures used for image classification. In our experiments, all the models for image classification were fine-tuned on the training set of each classification problem according to the model training parameters reported in
Table 2. Data augmentation includes random reflection on both axes and two independent random rescales of both axes by two factors uniformly sampled in [
1,
2].
For image segmentation purposes, we selected Deeplabv3+ [
4], a recent architecture based on atrous convolution, in which the filter is not applied to all adjacent pixels of an image but rather to a spaced-out lattice of pixels. Deeplabv3+ uses four parallel atrous convolutions (each with differing atrous rates) followed by a “Pyramid Pooling” method. Since DeepLabv3+ is based on encoder–decoder structure, and it can be built on top of a powerful pre-trained CNN architecture: in this work, we selected again ResNet50 for this task, although our internal evaluation showed that ResNet101 and ResNet34 gained similar performance. All the models for skin segmentation were trained on a small dataset of 2000 images using class weighting and the same training parameters, as reported in
Table 2.
Given a base model for each task, i.e. ResNet50 for image classification and DeepLabv3+ for skin segmentation, we designed several variants of the initial architecture by replacing all the activation layers (which were ReLU layers in both the starting models used in this work) by a different activation function. The stand-alone methods named leakyReLU, ELU, SReLU, APLU, GaLU, sGaLU, PReLU, MeLU, and wMeLU together with the original model (ReLU) are the 10 models tested in our experiments. Some of them depend on the training parameter , which was set to 1 if not specified (255, otherwise).
After comparing several activation functions, we propose to design a new model based on the use of different activation functions in different layers. According to the pseudo-code in
Figure 1, a
RandAct model is obtained using the function StochasticReplacement, applied to an input CNN and a set of activation functions, by randomly replacing all the activation layers of the input model. In our experiments, we considered ResNet50 as the input model for image classification and DeepLabv3+ for image segmentation. However, this method is general and it could be applied to any other model. The output models
RandAct and
RandAct(255) were obtained from input models using the set of 9 alternative activation functions with the
parameter equal to 1 or 255. To create an ensemble, the function CreateEnsemble is used: first, StochasticReplacement is used to generate N
RandAct models, then the models are fine-tuned on the training set, and finally they were fused together in an ensemble using the sum rule. The fusion of CNNs using the sum rule consists in summing the outputs of the last softmax layer. Then, the final decision is obtained applying an argmax function. In the segmentation task, we evaluated the sum of the output mask, which is equal to a vote rule at pixel level. The ensemble created and tested in the experimental section are the following:
FusRan10 and FusRan10(255) are ensembles obtained by the fusion of 10 RandAct or RandAct (255) models (i.e., fixing = 1 or 255)
FusRan20 = FusRan10 + FusRan10(255)
FusRan3 and FusRan3(255) are the ensembles obtained by the fusion of 3 stochastic models as RandAct or RandAct(255).
Moreover, we also tested the following ensembles obtained by the sum rule of the above stand-alone models:
FusAct10 and FusAct10(255) are the ensembles obtained by the fusion of all the 10 non-random stand-alone models obtained by varying the activation functions: i.e. ReLU, leakyReLU, ELU, SReLU, APLU, GaLU, sGaLU, PReLU, MeLU, and wMeLU (fixing to 1 or 255)
FusAct3 is a lightweight ensemble obtained by the fusion of the best 3 stand-alone models (evaluated on the training set), FusAct3 = wMeLU + MeLU + PReLU for skin classification
FusAct3(255) is a lightweight ensemble obtained by the fusion of the best 3 stand-alone methods for image classification, FusAct3(255) = wMeLu(255) + MeLu(255) + SReLu(255)
Finally, we proposed two ensembles obtained mixing different types of selection for activation functions:
5. Results
To evaluate the stand-alone models based on different activation functions, the stochastic method for model and ensemble creation and the other ensembles described in
Section 4, we performed experiments on 13 well-known medical datasets for image classification and 11 datasets for skin segmentation.
Table 3 summarizes the 13 datasets for image classification including a short abbreviation, the dataset name, the number of samples and classes, the size of the images, and the testing protocol. We used five-fold cross-validation (5CV) in 12 out of 13 datasets, while we maintained a three-fold division for the Laryngeal dataset (the same protocol in [
39]).
Table 4 summarizes the 11 datasets used for skin segmentation. All models were trained only on the first 2000 images of the ECU dataset [
40]; therefore, the other skin datasets were used only for testing (for ECU, only the last 2000 images not included in the training set were used for testing).
The evaluation and comparison of the proposed approaches was performed according to two of the most used performance indicators in image classification and skin segmentation: accuracy and F
1-measure, respectively. Accuracy is the ratio between the number of true predictions and the total number of samples, while the F
1-measure is the harmonic mean of precision and recall and it is calculated according to the following formula F
1 , where
tn, fn, tp, and
fp are the number of true negatives, false negatives, true positives, and false positives evaluated at pixel-level, respectively. According to other works on skin detection, F
1 was calculated at pixel-level (and not at image-level) to be independent on the image size in the different databases. Finally, to validate the experiments, the Wilcoxon signed rank test [
56] was used. For our experiments, all images were resized to the input size of the CNN models (i.e., 224 × 224 for ResNet50 and all our variants) before training and testing, and then the output mask for skin segmentation was resized back to original size.
In the first experiment, we evaluated the proposed methods for image classification on the datasets listed in
Table 3.
Table 5 reports the accuracy obtained by all the tested stand-alone models and ensembles: the last two columns report the average accuracy (Avg) and the rank (evaluated on Avg).
From the results in
Table 5, we can draw the following conclusions:
All ensembles are ranked before the stand-alone methods: this demonstrates that changing the activation function is a viable method for creating diversity among models.
The method named ReLU, which is our baseline since it is the standard implementation of ResNet50, performs very well, but it is not the best performing activation function: many activation functions (with the = 255) perform better than ReLU on average.
It is a very valuable result that methods such as wMeLU(255), MeLU(255), and some other stand-alone approaches strongly outperform ReLU. Starting from a pretrained model and changing its activation layers, we obtained a sensible error reduction. This means that our approaches permit boosting the performance of the original ResNet50 on a large set of problems.
It is difficult to select a function that wins in all problems. Therefore, a good method to improve performance is to create an ensemble of different models: both FusAct10 and FusAct10(255) work better than each of their single components.
Designing the models by means of stochastic activation functions (i.e., RandAct or RandAct(255)) gives valuable results: RandAct is ranked 12th, only two positions worse than the best stand-alone model (wMeLU(255) ranked 10th) and before the baseline ReLU (15th).
Moreover, the selection of stochastic activation functions is very valuable for the creation of ensembles: both FusRan10 and FusRan10(255) perform very well compared to all stand-alone models and other ensembles; their fusion FusRan20 = FusRan10 + FusRan10(255) is the first ranked method tested on these experiments.
The two small ensembles FusAct3(255) and FusRan3(255) perform very well; they strongly outperform stand-alone approaches and reach performance comparable with other heavier ensembles (composed of 10 or 20 models).
In the second experiment, we evaluated the proposed methods for skin segmentation on the 11 datasets listed in
Table 4. In
Table 6, the performance of all the tested stand-alone models and ensembles are reported in terms of F
1-measure; the last two columns report the average F
1-measure (Avg) and the rank (calculated on the average F
1).
From the results in
Table 6 it can be derived that:
ReLU is the standard DeepLabv3+ segmentation CNN based on ResNet50 encoder. This is our baseline, since it has shown state-of-the-art performance for skin segmentation [
17]. Many stand-alone models based on different activation functions outperform
ReLU: in this problem, the activation functions with
= 1 work better than those initialized at 255; therefore, we set to 1 the
for the ensembles with three models (FusAct3 and FusRan3).
Similar to the image classification experiment, all ensembles work better than any stand-alone approach: FusAR20 is the best ranked method in our experiments, but two “lighter” ensembles, namely FusAct3 and FusAct10, offer very good performance.
Similar to the classification problem, the proposed approaches outperform ReLU, i.e. the standard DeepLabv3+ based on ResNet50, a state-of-the-art approach for image segmentation.
The reported results show that all the proposed ensembles reach state of the art performance [
17] in most of the benchmark datasets: all of them outperform our baseline
ReLU.
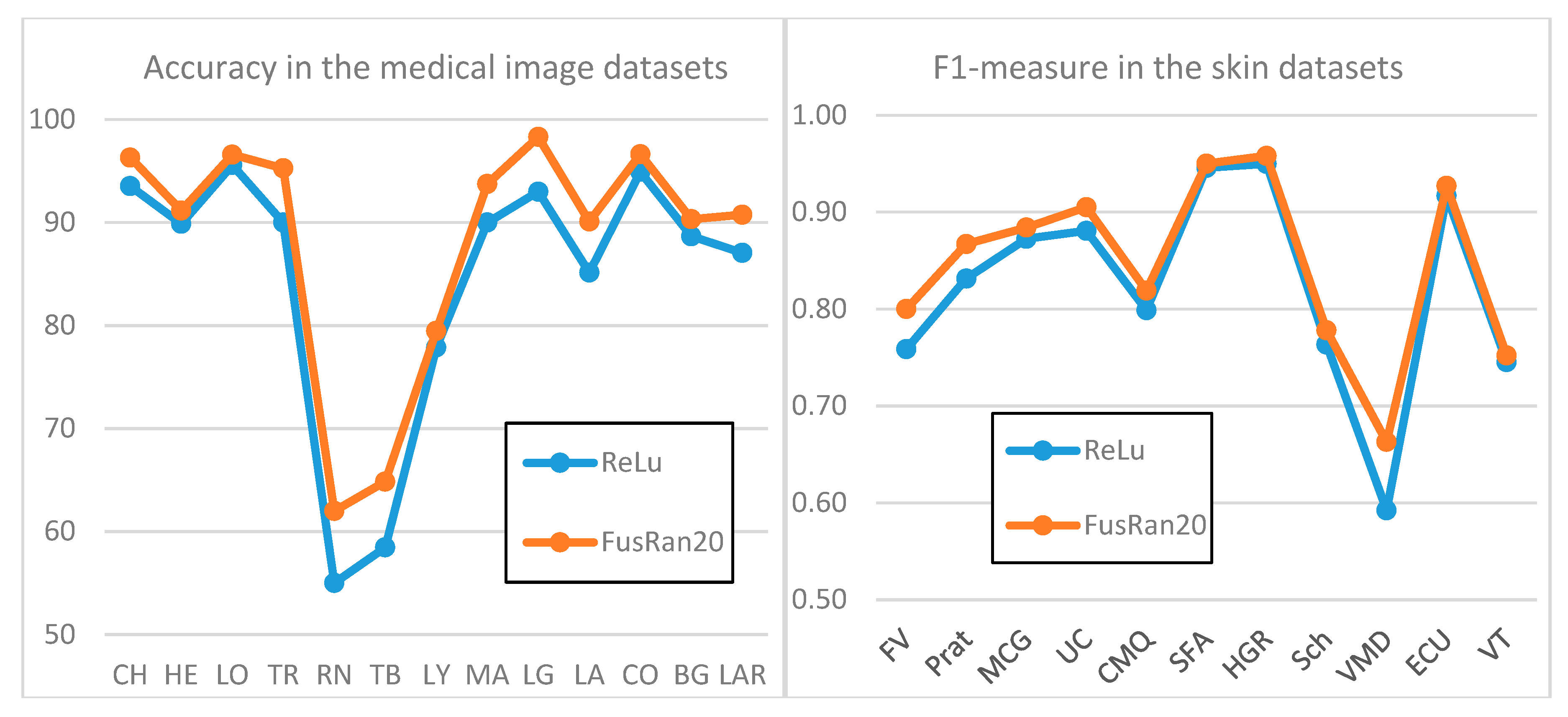
To give a visual evidence of the performance improvement obtained by our ensemble
FusRan20 with respect to the baseline
ReLU, Figure 2 presents two graphics of performance on both datasets. Moreover, in
Figure 3, sample output masks from the Pratheepan dataset obtained by our ensemble
FusAR20 with respect to the baseline
ReLU and the ground truth are shown. In all three sample images, the improvement of the ensemble with respect to our baseline stand-alone method is clearly visible.
Finally, we report some comparisons considering the Wilcoxon signed rank test. In
Table 7 and
Table 8, we compare the performance of some approaches for classification and segmentation: we selected the most interesting approach for each size of ensembles (of course, the approaches can be different in the two problems). The reported p-values confirm the conclusions drawn from
Table 5 and
Table 6. Moreover, the Wilcoxon signed rank test between
FusRan10 and
FusAct10 shows that the stochastic ensemble outperforms the other one with a p-value of 0.0166 on our 13 datasets for image classification. Similarly,
FusRan10(255) outperforms
FusAct10(255) with a p-value of 0.0713 in the image classification problem. This is an experimental demonstration that introducing a stochastic selection is a method to improve diversity of classifiers.
Finally, using a Titan Xp, the classification time of a ResNet50 is 0.018 s per image; this mean that, using an ensemble of 20 CNNs, it is possible to classify more than two images per second using a single Titan Xp.







{kind=link}
{kind=link}
{kind=link}