
Closing the Performance Gap between Siamese Networks for Dissimilarity Image Classification and Convolutional Neural Networks

 ,
, 
 ,
,
Abstract
:1. Introduction
- Two different loss functions are used to train the Siamese networks: the binary cross entropy loss function and the triplet loss function.
- Two different approaches for building the dissimilarity spaces are proposed for extracting features: the first is based on the fully connected layer and the latter on a deeper layer where the size of each channel is reduced by the Discrete Cosine Transform (DCT).
- SNNs are optimized using different variants of Adam, with a new Adam variant proposed in this work.
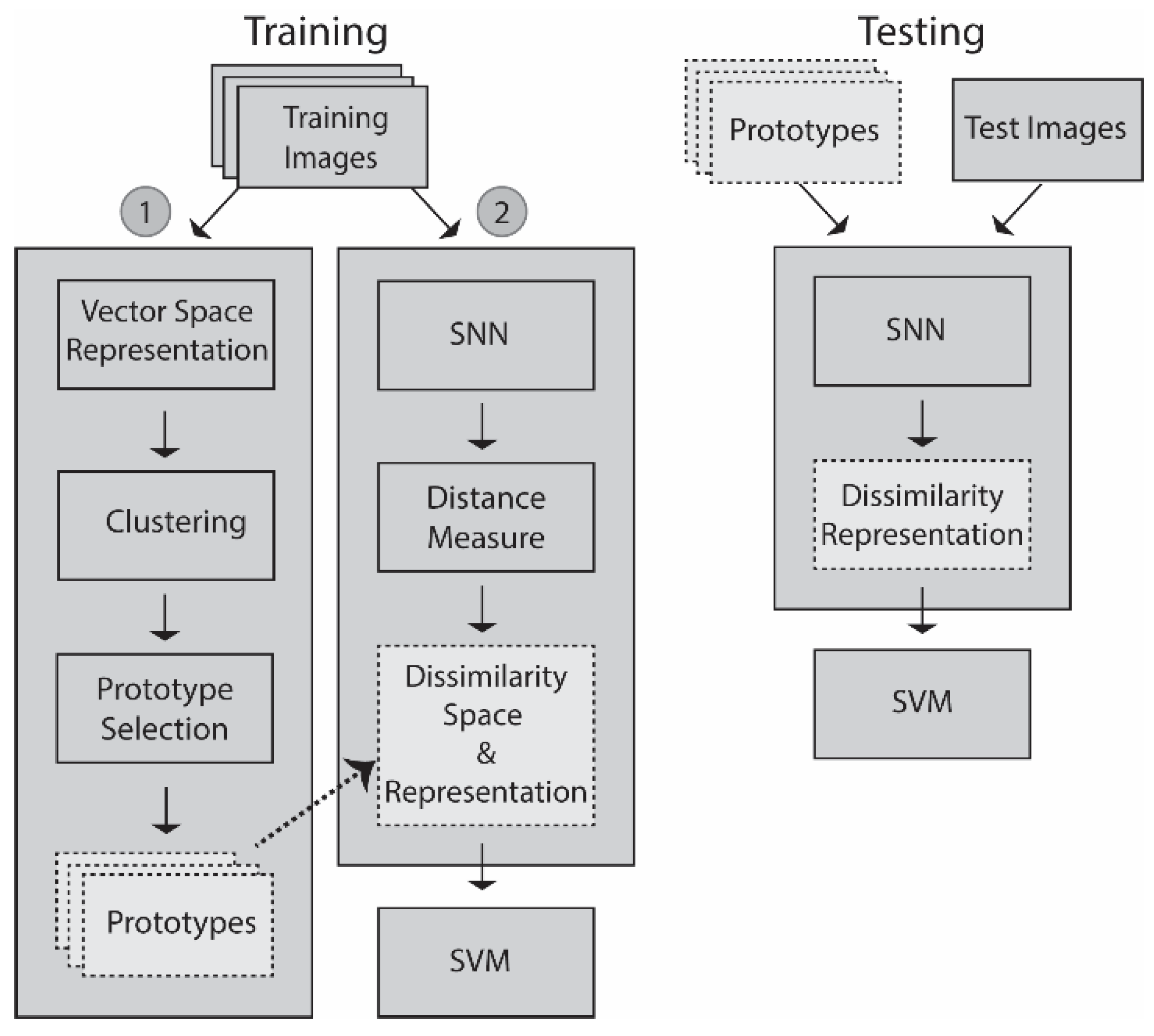
2. Proposed Approach
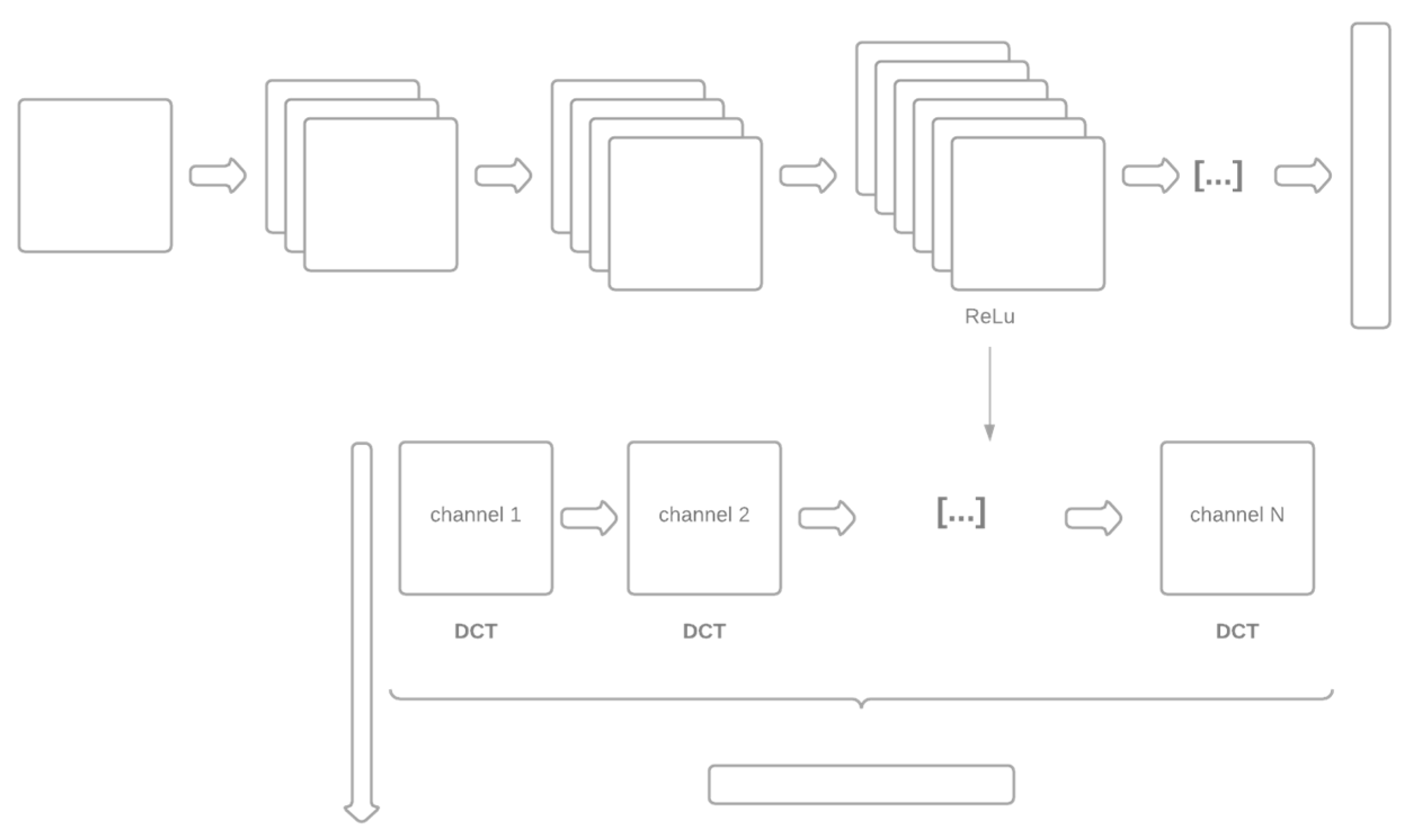
2.1. Methods for Generating the Dissimilarity Spaces
DCT Dimensionality Reduction
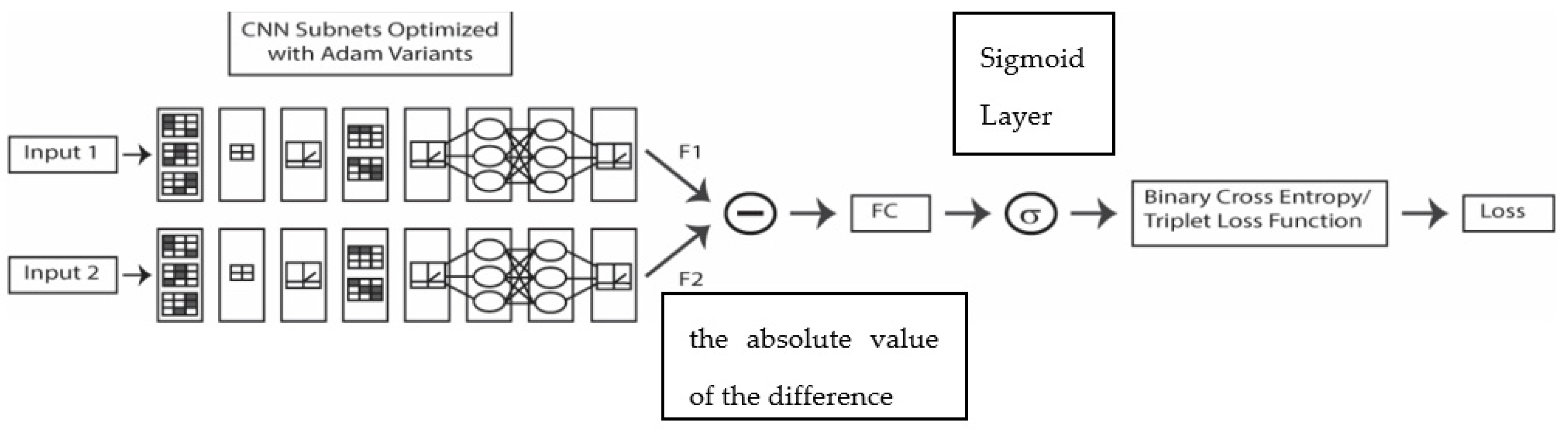
2.2. Loss Functions
2.2.1. Binary Cross Entropy Loss (Cross)
2.2.2. Triplet Loss (Triplet)
2.3. Adam Variants
2.3.1. DGrad
2.3.2. DecayDGrad (New)
3. Data Sets
- BIRDz [25]: This balanced data set is a real-world benchmark for bird species vocalizations. The testing protocol is ten runs using the data split in [25]. The audio tracks were extracted from the Xeno-Canto Archive (http://www.xeno-canto.org/ (accessed on 25 August 2021)). BIRDz contains a total of 2762 acoustic samples from eleven North American bird species, along with 339 unclassified audio samples (consisting of noise and unknown bird vocalizations). The bird classes vary in size from 246 to 259. Each observation is represented by five spectrograms: (1) constant frequency, (2) frequency modulated whistles, (3) broadband pulses, (4) broadband with varying frequency components, and (5) strong harmonics.
- InfLar [28]: This data set contains eighteen Narrow-Band Imaging (NBI) endoscopic videos of eighteen different patients with laryngeal cancer. The videos were retrospectively analyzed and categorized into four classes (informative, blurred, containing saliva or specular reflections, and underexposed). The average video length is 39 s. The videos were acquired with an NBI endoscopic system (Olympus Visera Elite S190 video processor and an ENF-VH rhino-laryngo videoscope) with a frame rate of 25 fps and an image size of 1920 × 1072 pixels. A total of 720 video frames, 180 for each of the four classes, were extracted and labeled. The testing protocol is three-fold cross-validation with data separated at the patient level to ensure that the frames from the same class were classified based on the features characteristic of each class and not due to features linked to the individual patient (e.g., vocal fold anatomy).
- RPE [29]: This is a medical image classification data set that intends to distinguish the maturation of human stem cell-derived retinal pigmented epithelium. RPE is based on 195 images that were divided into sixteen subwindows. These subwindows were then assigned to one of four classes: (1) Fusifors, (2) Epithelioid, (3) Cobblestone, and (4) Mixed. Subwindows that were out of focus or that contained background information exclusively were discarded. This division of images into four and the exclusion process produced a total of 1862 images.
- Port [30]: This data set contains 927 paintings from six different art movements: (1) High Renaissance, (2) Impressionism, (3) Northern Renaissance, (4) Post-Impressionism, (5) Rococo, and (6) Ukiyo-e. Ten-fold cross-validation is the testing protocol.
4. Experimental Results
- Top: The performance obtained using the method named FULLY for SVM input;
- Middle: The performance obtained using the method named DEEPER for SVM input;
- Bottom: The fusion by average rule of the SVMs in 1 and 2.
- The columns of Table 1 report the following approaches:
- Cross: Binary Cross Entropy loss function coupled with base Adam (this is the best approach proposed [14]);
- CrossDD: Binary Cross Entropy loss function coupled with our new Adam variant DecayDGrad;
- Triplet: Triplet loss function coupled with base Adam.
- X + Y (columns 5 and 6): the fusion between X and Y.
- Triplet produces a result that is similar to Cross on three data sets but performs better than Cross in InfLar and worst in CAT;
- The fusion between Cross and Triplet boosts the performance of the base loss functions, except in the case of CAT;
- The fusion among all the different approaches (see bottom cells in the column Triplet+Cross and Triplet+Cross+CrossDD) produces the best average performance.
- Top: Cross function coupled with FULLY for SVM input (the best approach proposed in [14]);
- Upper: Triplet loss function coupled with FULLY for SVM input;
- Lower: Fusion by average rule among Cross coupled with FULLY, Cross coupled with DEEPER, Triplet coupled with FULLY, and Triplet coupled with DEEPER;
- Bottom: This is the fusion by average rule of SVMs 1 and 2 described for the method reported at the bottom of Table 1 but with the addition of CrossDD coupled with both FULLY and DEEPER.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Siamese Network 1 | ||||
| Layers | Activations | Learnable | Filter Size | Num. of Filters |
| Input Layer | 224 × 224 | |||
| 2D Convolution | 215 × 215 × 64 | 6464 | 10 × 10 | 64 |
| ReLU | 215 × 215 × 64 | 0 | ||
| Max Pooling | 107 × 107 × 64 | 0 | 2 × 2 | |
| 2D Convolution | 101 × 101 × 128 | 401,536 | 7 × 7 | 128 |
| ReLU | 101 × 101 × 128 | 0 | ||
| Max Pooling | 50 × 50 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 47 × 47 × 128 | 262,272 | 4 × 4 | 128 |
| ReLU | 47 × 47 × 128 | 0 | ||
| Max Pooling | 23 × 23 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 19 × 19 × 64 | 204,864 | 5 × 5 | 64 |
| ReLU | 19 × 19 × 64 | 0 | ||
| Fully Connected | 4096 | 94,638,080 | ||
| Siamese Network 2 | ||||
| Layers | Activations | Learnable | Filter Size | Num. of Filters |
| Input Layer | 224 × 224 | 0 | ||
| 2D Convolution | 220 × 220 × 64 | 1664 | 5 × 5 | 64 |
| LeakyReLU | 220 × 220 × 64 | 0 | ||
| 2D Convolution | 216 × 216 × 64 | 102,464 | 5 × 5 | 64 |
| LeakyReLU | 216 × 216 × 64 | 0 | ||
| Max Pooling | 108 × 108 × 64 | 0 | 2 × 2 | |
| 2D Convolution | 106 × 106 × 128 | 73,856 | 3 × 3 | 128 |
| LeakyReLU | 106 × 106 × 128 | 0 | ||
| 2D Convolution | 104 × 104 × 128 | 147,584 | 3 × 3 | 128 |
| LeakyReLU | 104 × 104 × 128 | 0 | ||
| Max Pooling | 52 × 52 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 49 × 49 × 128 | 262,272 | 4 × 4 | 128 |
| LeakyReLU | 49 × 49 × 128 | 0 | ||
| Max Pooling | 24 × 24 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 20 × 20 × 64 | 204,864 | 5 × 5 | 64 |
| LeakyReLU | 20 × 20 × 64 | 0 | 5 × 5 | |
| Fully Connected | 2048 | 52,430,848 | ||
| Siamese Network 3 | ||||
| Layers | Activations | Learnable | Filter Size | Num. Filters |
| Input Layer | 224 × 224 | |||
| 2D Convolution | 55 × 55 × 128 | 6400 | 7 × 7 | 128 |
| Max Pooling | 27 × 27 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 23 × 23 × 256 | 819,456 | 5 × 5 | 256 |
| ReLU | 23 × 23 × 256 | 0 | ||
| 2D Convolution | 19 × 19 × 128 | 819,328 | 5 × 5 | 128 |
| Max Pooling | 9 × 9 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 7 × 7 × 64 | 73,792 | 3 × 3 | 64 |
| ReLU | 7 × 7 × 64 | 0 | ||
| Max Pooling | 3 × 3 × 64 | 0 | 2 × 2 | |
| Fully Connected | 4096 | 2,363,392 | ||
| Siamese Network 4 | ||||
| Layers | Activations | Learnable | Filter Size | Num. of Filters |
| Input Layer | 224 × 224 | |||
| 2D Convolution | 218 × 218 × 128 | 6400 | 7 × 7 | 128 |
| Max Pooling | 54 × 54 × 128 | 0 | 4 × 4 | |
| ReLU | 54 × 54 × 128 | 0 | ||
| 2D Convolution | 50 × 50 × 256 | 819,456 | 5 × 5 | 256 |
| ReLU | 50 × 50 × 256 | 0 | ||
| 2D Convolution | 48 × 48 × 64 | 147,520 | 3 × 3 | 64 |
| Max Pooling | 24 × 24 × 64 | 0 | 2 × 2 | |
| 2D Convolution | 22 × 22 × 128 | 73,856 | 3 × 3 | 128 |
| ReLU | 22 × 22 × 128 | 0 | ||
| 2D Convolution | 18 × 18 × 64 | 204,864 | 5 × 5 | 64 |
| Fully Connected | 4096 | 84,938,752 | ||
| Siamese Network 5 | ||||
| Layers | Activations | Learnable | Filter Size | Num. of Filters |
| Input Layer | 224 × 224 | |||
| 2D Convolution | 215 × 215 × 64 | 6464 | 10 × 10 | 64 |
| Max Pooling | 107 × 107 × 64 | 0 | 2 × 2 | |
| ReLU | 107 × 107 × 64 | 0 | ||
| 2D Convolution | 26 × 26 × 128 | 401,536 | 7 × 7 | 128 |
| ReLU | 26 × 26 × 128 | 0 | ||
| 2D Convolution | 9 × 9 × 128 | 409,728 | 5 × 5 | 128 |
| ReLU | 9 × 9 × 128 | 0 | ||
| 2D Convolution | 6 × 6 × 64 | 131,136 | 4 × 4 | 64 |
| ReLU | 6 × 6 × 64 | 0 | ||
| Fully Connected | 4096 | 9,441,280 | ||
| Siamese Network 6 | ||||
| Layers | Activations | Learnable | Filter Size | Num. of Filters |
| Input Layer | 224 × 224 | |||
| 2D Convolution | 218 × 218 × 64 | 3200 | 7 × 7 | 64 |
| Max Pooling | 109 × 109 × 64 | 0 | 2 × 2 | |
| ReLU | 109 × 109 × 64 | 0 | ||
| 2D Convolution | 107 × 107 × 128 | 73,856 | 3 × 3 | 128 |
| Max Pooling | 53 × 53 × 128 | 0 | 2 × 2 | |
| ReLU | 53 × 53 × 128 | 0 | ||
| 2D Convolution | 53 × 53 × 64 | 8256 | 1 × 1 | 64 |
| ReLU | 53 × 53 × 64 | 0 | ||
| 2D Convolution | 51 × 51 × 128 | 73,856 | 3 × 3 | 128 |
| ReLU | 51 × 51 × 128 | 0 | ||
| Max Pooling | 25 × 25 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 25 × 25 × 128 | 16,512 | 1 × 1 | 128 |
| ReLU | 25 × 25 × 128 | 0 | ||
| 2D Convolution | 22 × 22 × 64 | 131,136 | 4 × 4 | 64 |
| Max Pooling | 11 × 11 × 64 | 0 | 2 × 2 | |
| ReLU | 11 × 11 × 64 | 0 | ||
| Fully Connected | 4096 | 31,723,520 | ||
| Siamese Network 7 | ||||
| Layers | Activations | Learnable | Filter Size | Num. of Filters |
| Input Layer | 224 × 224 | |||
| Dropout Layer | 224 × 224 | 0 | ||
| 2D Convolution | 218 × 218 × 64 | 3200 | 7 × 7 | 64 |
| Max Pooling | 109 × 109 × 64 | 0 | 2 × 2 | |
| 2D Convolution | 105 × 105 × 128 | 204,928 | 5 × 5 | 128 |
| Max Pooling | 52 × 52 × 128 | 0 | 2 × 2 | |
| 2D Convolution | 48 × 48 × 64 | 204,864 | 5 × 5 | 64 |
| Max Pooling | 24 × 24 × 64 | 0 | 2 × 2 | |
| 2D Convolution | 22 × 22 × 256 | 147,712 | 3 × 3 | 256 |
| Max Pooling | 11 × 11 × 256 | 0 | 2 × 2 | |
| Fully Connected | 4096 | 16,781,312 | ||
| Siamese Network 8 | ||||
| Layers | Activations | Learnable | Filter Size | Num. of Filters |
| Input Layer | 224 × 224 | |||
| 2D Convolution | 215 × 215 × 32 | 3232 | 10 × 10 | 32 |
| Max Pooling | 107 × 107 × 32 | 0 | 2 × 2 | |
| ReLU | 107 × 107 × 32 | 0 | ||
| 2D Grouped Convolution | 101 × 101 × 64 | 50,240 | 7 × 7 | 64 |
| 2D Convolution | 97 × 97 × 128 | 204,928 | 5 × 5 | 128 |
| Max Pooling | 48 × 48 × 128 | 0 | 2 × 2 | |
| ReLU | 48 × 48 × 128 | 0 | ||
| 2D Grouped Convolution | 46 × 46 × 256 | 147,712 | 3 × 3 | 256 |
| Fully Connected | 4096 | 2,218,790,912 | ||
References
- Pękalska, E.; Duin, R.P. The Dissimilarity Representation for Pattern Recognition—Foundations and Applications; World Scientific: Singapore, 2005. [Google Scholar]
- Cha, S.; Srihari, S. Writer Identification: Statistical Analysis and Dichotomizer. In Proceedings of the SSPR/SPR, Alicante, Spain, 1 September 2000. [Google Scholar]
- Oliveira, L.; Justino, E.; Sabourin, R. Off-line Signature Verification Using Writer-Independent Approach. In Proceedings of the 2007 International Joint Conference on Neural Networks, Orlando, FL, USA, 29 October 2007; pp. 2539–2544. [Google Scholar]
- Hanusiak, R.K.; Oliveira, L.; Justino, E.; Sabourin, R. Writer verification using texture-based features. Int. J. Doc. Anal. Recognit. 2011, 15, 213–226. [Google Scholar] [CrossRef]
- Zottesso, R.H.D.; Costa, Y.M.G.; Bertolini, D.; Oliveira, L.E.S. Bird species identification using spectrogram and dissimilarity approach. Ecol. Inform. 2018, 48, 187–197. [Google Scholar] [CrossRef]
- Souza, V.L.F.; Oliveira, A.; Sabourin, R. A Writer-Independent Approach for Offline Signature Verification using Deep Convolutional Neural Networks Features. In Proceedings of the 2018 7th Brazilian Conference on Intelligent Systems, São Paulo, Brazil, 22–25 October 2018; pp. 212–217. [Google Scholar]
- Pękalska, E.; Duin, R.P. Dissimilarity representations allow for building good classifiers. Pattern Recognit. Lett. 2002, 23, 943–956. [Google Scholar] [CrossRef]
- Nguyen, G.; Worring, M.; Smeulders, A. Similarity learning via dissimilarity space in CBIR. In Proceedings of the MIR’06, Santa Barbara, CA, USA, 26–27 October 2006. [Google Scholar]
- Theodorakopoulos, I.; Kastaniotis, D.; Economou, G.; Fotopoulos, S. HEp-2 cells classification via sparse representation of textural features fused into dissimilarity space. Pattern Recognit. 2014, 47, 2367–2378. [Google Scholar] [CrossRef]
- Hernández-Durán, M.; Calaña, Y.P.; Vazquez, H.M. Low-Resolution Face Recognition with Deep Convolutional Features in the Dissimilarity Space. In Proceedings of the IWAIPR, Chiang Mai, Thailand, 7–10 January 2018. [Google Scholar]
- Mekhazni, D.; Bhuiyan, A.; Ekladious, G.; Granger, É. Unsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification. In Proceedings of the ECCV, Glasgow, Scotland, 23 August 2020. [Google Scholar]
- Nanni, L.; Rigo, A.; Lumini, A.; Brahnam, S. Spectrogram classification using dissimilarity space. Sensors 2020, 10, 4176. [Google Scholar] [CrossRef]
- Nanni, L.; Brahnam, S.; Lumini, A.; Maguolo, G. Animal sound classification using dissimilarity spaces. Appl. Sci. 2020, 10, 8578. [Google Scholar] [CrossRef]
- Nanni, L.; Minchio, G.; Brahnam, S.; Maguolo, G.; Lumini, A. Experiments of image classification using dissimilarity spaces built with siamese networks. Sensors 2021, 21, 1573. [Google Scholar] [CrossRef] [PubMed]
- Costa, Y.M.G.; Bertolini, D.; Britto, A.S.; Cavalcanti, G.D.C.; Oliveira, L. The dissimilarity approach: A review. Artif. Intell. Rev. 2019, 53, 2783–2808. [Google Scholar] [CrossRef]
- Chicco, D. Siamese neural networks: An overview. In Artificial Neural Networks. Methods in Molecular Biology; Cartwright, H., Ed.; Springer Protocols: New York, NY, USA, 2020; pp. 73–94. [Google Scholar]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature Verification Using A “Siamese” Time Delay Neural Network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, A. Dissimilarity learning via Siamese network predicts brain imaging data. arXiv 2019. Available online: https://arxiv.org/ftp/arxiv/papers/1907/1907.02591.pdf (accessed on 25 August 2021).
- San Biagio, M.; Crocco, M.; Cristani, M.; Martelli, S.; Murino, V. Heterogeneous auto-similarities of characteristics (hasc): Exploiting relational information for classification. In Proceedings of the IEEE Computer Vision (ICCV13), Sydney, Australia, 1–8 December 2013; pp. 809–816. [Google Scholar]
- Feig, E.; Winograd, S. Fast algorithms for the discrete cosine transform. IEEE Trans. Signal. Process. 1992, 49, 2174–2193. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. CoRR 2015, 1412, 6980. [Google Scholar]
- Dubey, S.; Chakraborty, S.; Roy, S.K.; Mukherjee, S.; Singh, S.K.; Chaudhuri, B. diffGrad: An Optimization Method for Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4500–4511. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nanni, L.; Maguolo, G.; Lumini, A. Exploiting Adam-like Optimization Algorithms to Improve the Performance of Convolutional Neural Networks. arXiv. 2021. Available online: https://arxiv.org/ftp/arxiv/papers/2103/2103.14689.pdf (accessed on 25 August 2021).
- You, K.; Long, M.; Jordan, M.I. How Does Learning Rate Decay Help Modern Neural Networks. arXiv. 2019. Available online: https://arxiv.org/abs/1908.01878 (accessed on 25 August 2021).
- Zhang, S.-H.; Zhao, Z.; Xu, Z.; Bellisario, K.; Pijanowski, B.C. Automatic Bird Vocalization Identification Based on Fusion of Spectral Pattern and Texture Features. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal, Calgary, AB, Canada, 15–20 April 2018; pp. 271–275. [Google Scholar]
- Pandeya, Y.R.; Kim, D.; Lee, J. Domestic cat sound classification using learned features from deep neural nets. Appl. Sci. 2018, 8, 1949. [Google Scholar] [CrossRef] [Green Version]
- Pandeya, Y.R.; Lee, J. Domestic Cat Sound Classification Using Transfer Learning. Int. J. Fuzzy Logic. Intell. Syst. 2018, 18, 154–160. [Google Scholar] [CrossRef] [Green Version]
- Moccia, S.; Vanone, G.O.; Momi, E.D.; Laborai, A.; Guastini, L.; Peretti, G.; Mattos, L.S. Learning-based classification of informative laryngoscopic frames. Comput. Methods Programs Biomed. 2018, 158, 21–30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nanni, L.; Paci, M.P.; Santos, F.L.C.d.; Skottman, H.; Juuti-Uusitalo, K.; Hyttinen, J. Texture descriptors ensembles enable image-based classification of maturation of human stem cell-derived retinal pigmented epithelium. PLoS ONE 2016, 11, e0149399. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Yang, J.; Agaian, S.S.; Yuan, C. Novel features for art movement classification of portrait paintings. Image Vision Comput. 2021, 108, 104121. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cross | CrossDD | Triplet | Triplet + Cross | Triplet + Cross + CrossDD | |
|---|---|---|---|---|---|
| CAT | 83.05 | 80 | 77.29 | 82.37 | 83.05 |
| 69.15 | 71.19 | 72.2 | 71.53 | 76.27 | |
| 80 | 79.32 | 76.61 | 80 | 80 | |
| InfLar | 86.94 | 93.75 | 90.42 | 91.25 | 93.47 |
| 87.78 | 88.33 | 88.89 | 89.17 | 91.39 | |
| 89.44 | 92.36 | 90.56 | 91.39 | 92.64 | |
| BIRDz | 94.49 | 93.35 | 94.08 | 94.9 | 94.56 |
| 92.92 | 92.53 | 94.02 | 94.36 | 94.16 | |
| 94.52 | 93.91 | 94.84 | 95.21 | 94.88 | |
| RPE | 84.52 | 84.58 | 85.43 | 85.75 | 84.97 |
| 84.15 | 84.49 | 85.1 | 85 | 85.16 | |
| 84.73 | 85.08 | 85.17 | 85.92 | 85.48 | |
| Port | 70.99 | 74.44 | 68.72 | 72.82 | 74.33 |
| 69.57 | 70.54 | 70.96 | 71.83 | 73.22 | |
| 70.55 | 74.53 | 72.59 | 74.11 | 74.65 | |
| Average | 82.85 | 83.89 | 83.12 | 84.37 | 85.21 |
| Topology | InfLar | Port |
|---|---|---|
| Topology 1 | 86.94 | 70.99 |
| 90.42 | 68.72 | |
| 91.39 | 74.11 | |
| 92.64 | 74.65 | |
| Topology 2 | 85.56 | 68.73 |
| 92.78 | 70.02 | |
| 92.08 | 72.49 | |
| 91.67 | 72.92 | |
| Topology 3 | 79.44 | 60.23 |
| 83.75 | 68.17 | |
| 85.42 | 68.41 | |
| 84.03 | 69.17 | |
| Topology 4 | 87.50 | 69.69 |
| 91.25 | 68.29 | |
| 92.22 | 73.58 | |
| 90.97 | 74.65 | |
| Topology 5 | 84.03 | 60.00 |
| 89.44 | 65.03 | |
| 87.64 | 64.95 | |
| 85.14 | 69.69 | |
| Topology 6 | 87.64 | 73.48 |
| 88.61 | 68.07 | |
| 91.25 | 73.25 | |
| 90.56 | 73.24 | |
| Topology 7 | 79.44 | 66.03 |
| 91.39 | 70.85 | |
| 85.00 | 70.85 | |
| 84.72 | 71.85 | |
| Topology 8 | 86.39 | 65.58 |
| 87.22 | 66.55 | |
| 91.11 | 66.55 | |
| 90.56 | 72.16 | |
| Fusion 1–4 | 92.78 | 75.09 |
| Fusion 1–6 | 91.53 | 74.45 |
| Fusion 1–8 | 91.81 | 74.98 |
| Method | InfLar | Port |
|---|---|---|
| [12] | 74.86 | xxx * |
| [13] | 89.86 | 71.42 |
| [14] | 91.10 | 73.05 |
| Fusion 1–4 | 92.78 | 75.09 |
| Fusion 1–6 | 91.53 | 74.45 |
| Fusion 1–8 | 91.81 | 74.98 |
| GoogleNet | 90.42 | 80.38 |
| VGG16 | 91.53 | 86.51 |
| VGG19 | 92.22 | 82.42 |
| GoogleNetP365 | 93.61 | 80.91 |
| eCNN | 94.03 | 86.41 |
| Fusion 1–4 + eCNN | 94.44 | 86.84 |
| Fusion 1–6 + eCNN | 94.44 | 86.84 |
| Fusion 1–8 + eCNN | 94.31 | 86.84 |
| InfLar | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Cross | 1029 | 2009 | 317 | 1179 | 512 | 580 | 679 | 559 |
| Triplet | 1500 | 2721 | 400 | 1620 | 678 | 752 | 885 | 725 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanni, L.; Minchio, G.; Brahnam, S.; Sarraggiotto, D.; Lumini, A. Closing the Performance Gap between Siamese Networks for Dissimilarity Image Classification and Convolutional Neural Networks. Sensors 2021, 21, 5809. https://doi.org/10.3390/s21175809
Nanni L, Minchio G, Brahnam S, Sarraggiotto D, Lumini A. Closing the Performance Gap between Siamese Networks for Dissimilarity Image Classification and Convolutional Neural Networks. Sensors. 2021; 21(17):5809. https://doi.org/10.3390/s21175809
Chicago/Turabian StyleNanni, Loris, Giovanni Minchio, Sheryl Brahnam, Davide Sarraggiotto, and Alessandra Lumini. 2021. "Closing the Performance Gap between Siamese Networks for Dissimilarity Image Classification and Convolutional Neural Networks" Sensors 21, no. 17: 5809. https://doi.org/10.3390/s21175809
APA StyleNanni, L., Minchio, G., Brahnam, S., Sarraggiotto, D., & Lumini, A. (2021). Closing the Performance Gap between Siamese Networks for Dissimilarity Image Classification and Convolutional Neural Networks. Sensors, 21(17), 5809. https://doi.org/10.3390/s21175809