
Fish Segmentation in Sonar Images by Mask R-CNN on Feature Maps of Conditional Random Fields †

Abstract
:1. Introduction
- Decoupling learning of fish instances from learning of fish-cultured environments: PreCNN learns a mapping from sonar images to a semantic feature map. Mask R-CNN is fine-tuned on the semantic feature map. Thus, learning of fish instances and learning of fish-cultured environments can be separated.
- Utilizing temporal information in successive sonar-image frames: In noisy sonar images, fish identification is usually more accurate by multiple frames than by a single frame;
- Semi-supervised learning: To reduce annotation costs, ambiguous pixels and pixels similar to annotated background pixels are not required to annotate. Images with partial or no pixel-level annotations can be used to train PreCNN in a semi-supervised learning manner.
2. Related Work
3. Materials and Methods
3.1. Problem Formulation
3.2. The Mean-Field Approximation to
3.3. Semi-Supervised Learning
3.4. The Neural Network Architecture
- : a deep CNN;
- : an RNN;
- : a CNN comprising a sequence of convolutional operations;
- : a convolutional operation.
3.5. Segmentation of Overlapping Fish with Mask R-CNN
4. Results
4.1. Test Environments
- E-A:The first environment is an indoor land-based fish farm with a concrete bottom. The species of the fish in this fish farm is Cyprinus carpio haematopterus.
- E-B: The second environment is the same as the first one except that the gain setting on the sonar system was higher to show more details.
- E-C: The third environment is an outdoor land-based fish farm with a mud bottom. The species of the fish in this fish farm is Pampus argenteus.
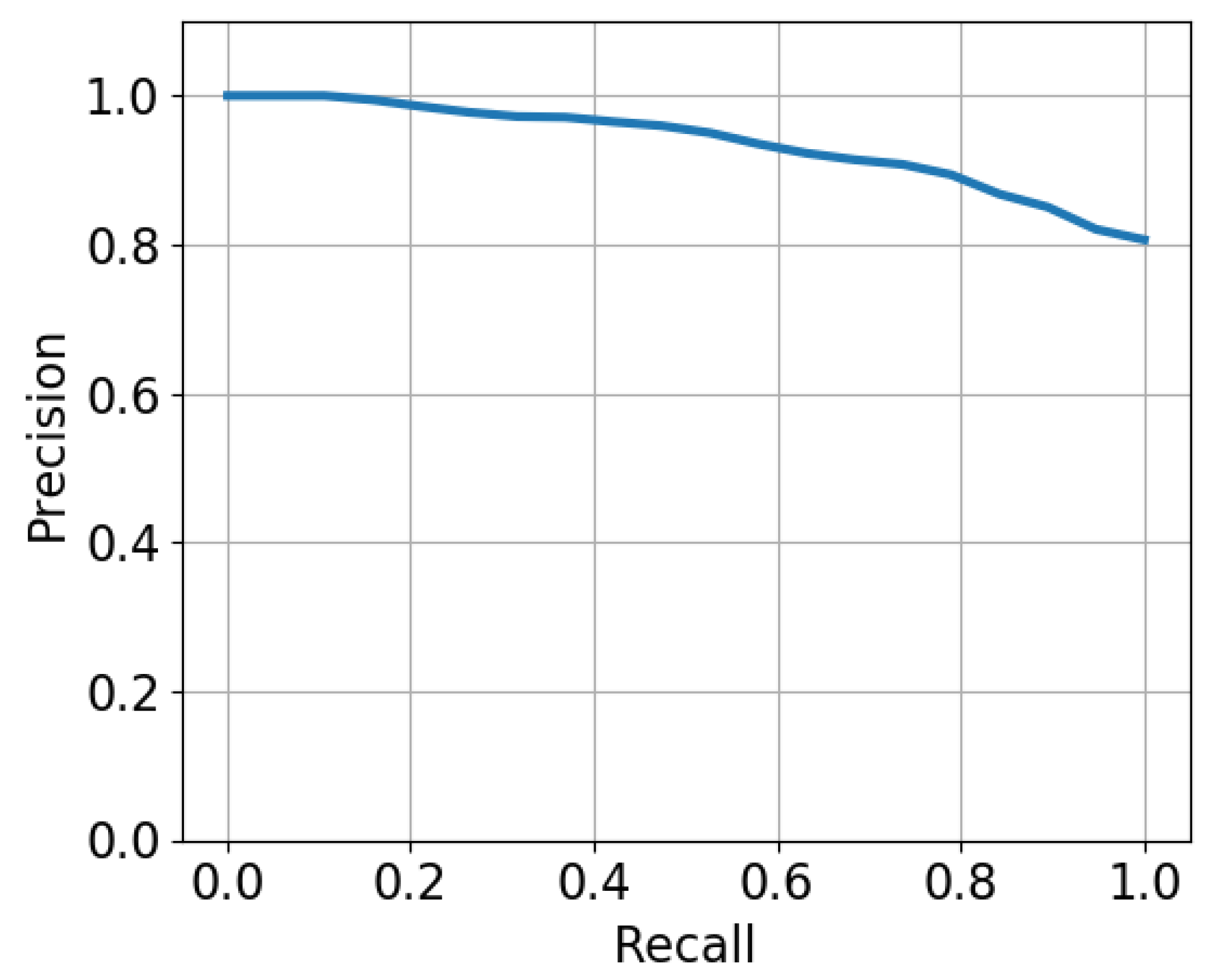
4.2. Performance Evaluation
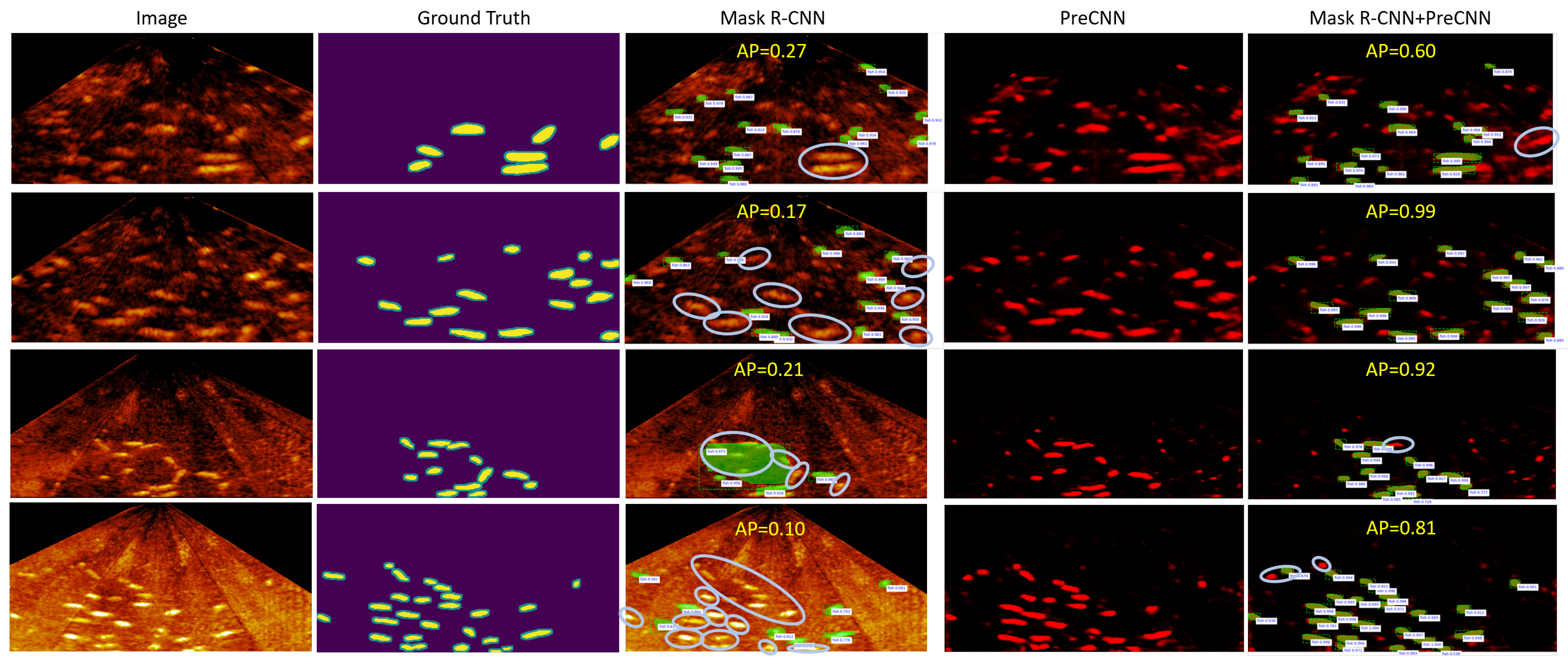
4.2.1. Mask R-CNN vs. Mask R-CNN+PreCNN
- The AP of Mask R-CNN is high when the training and the test example are of the same environment.
- The AP of Mask R-CNN is degenerate when applying Mask R-CNN trained for one test environment to the other two test environments.
- The AP of Mask R-CNN across environments E-A and E-B is acceptable. Mask R-CNN trained for one test environment can apply to the same environment with a different but proper gain setting on the imaging sonar system.
- The AP of Mask R-CNN across environments E-A and E-C or across environments E-B and E-C is low. This is because the echoes reflected from the different fish species and the bottom of different materials show different patterns.
- The overall AP of Mask R-CNN can be improved if the training examples are from the three test environments.
- When the training and test examples are of different environments, Mask R-CNN+ PreCNN is more accurate than Mask R-CNN. Besides, even though Mask R-CNN is fine-tuned on the examples of the three test environments, Mask R-CNN+PreCNN learned on the training example of one single test environment is at least as accurate as Mask R-CNN. That experimental result shows that Mask R-CNN based on the semantic feature map outputted by PreCNN is less dependent on the environment and supports the feasibility of the proposed approach.
- Because the AP of Mask R-CNN+PreCNN is better, Mask R-CNN+PreCNN can segment fish in a way more consistent with human annotations.
4.2.2. Mask R-CNN+Image Preprocessing vs. Mask R-CNN+PreCNN
4.2.3. PreCNN vs. PreCNN with CNN Only
4.2.4. Experimental Results of YOLOv4
4.3. Segmentation of Overlapping Fish with Mask R-CNN+PreCNN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saberioon, M.; Gholizadeh, A.; Cisar, P.; Pautsina, A.; Urban, J. Application of machine viion systems in aquaculture with emphasis on fish: State-of-the-art and key issues. Rev. Aquac. 2017, 9, 369–387. [Google Scholar] [CrossRef]
- Zhou, Y.; Yu, H.; Wu, J.; Cui, Z.; Zhang, F. Fish Behavior Analysis Based on Computer Vision: A Survey. In Data Science; Mao, R., Wang, H., Xie, X., Lu, Z., Eds.; Springer: Singapore, 2019; pp. 130–141. [Google Scholar]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, Z.; Tong, L.; Liu, Z.; Zhao, A.; Zhang, Q.; Dong, J.H.; Zhou, H. Perceptual underwater image enhancement with deep learning and physical priors. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3078–3092. [Google Scholar] [CrossRef]
- Jun, H.; Asada, A. Acoustic counting method of upstream juvenile ayu plecoglossus altivelis by using DIDSON. In Proceedings of the 2007 Symposium on Underwater Technology and Workshop on Scientific Use of Submarine Cables and Related Technologies, Tokyo, Japan, 17–20 April 2007; pp. 459–462. [Google Scholar]
- Rakowitz, G.; Tušer, M.; Říha, M.; Jůza, T.; Balk, H.; Kubečka, J. Use of high-frequency imaging sonar (DIDSON) to observe fish behavior towards a surface trawl. Fish. Res. 2012, 123–124, 37–48. [Google Scholar] [CrossRef]
- Handegard, N.O. An overview of underwater acoustics applied to observe fish behaviour at the institute of marine research. In Proceedings of the 2013 MTS/IEEE OCEANS, Bergen, Norway, 10–14 June 2013; pp. 1–7. [Google Scholar]
- Wolff, L.M.; Badri-Hoeher, S. Imaging sonar-based fish detection in shallow waters. In Proceedings of the 2014 Oceans, St. John’s, NL, Canada, 14–19 September 2014; pp. 1–6. [Google Scholar]
- Martignac, F.; Daroux, A.; Bagliniere, J.-L.; Ombredane, D.; Guillard, J. The use of acoustic cameras in shallow waters: New hydroacoustic tools for monitoring migratory fish population. a review of DIDSON technology. Fish Fish. 2015, 16, 486–510. [Google Scholar] [CrossRef]
- Christ, R.D.; Wernli, R.L. Chapter 15—Sonar. In The ROV Manual, 2nd ed.; Christ, R.D., Wernli, R.L., Eds.; Butterworth-Heinemann: Oxford, UK, 2014; pp. 387–424. [Google Scholar]
- Liu, S.; Jia, J.; Fidler, S.; Urtasun, R. SGN: Sequential grouping networks for instance segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3516–3524. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Venice, Italy, 22–29 October 2017; pp. 4438–4446. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Girshick, R.; He, K.; Dollar, P. TensorMask: A foundation for dense object segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2061–2069. [Google Scholar]
- Guo, L.X.; Griffiths, J.W.R. Sonar modelling in fish abundance measurement. In Proceedings of the IEE Colloquium on Simulation Techniques Applied to Sonar, London, UK, 19 May 1988; pp. 3/1–3/3. [Google Scholar]
- Han, C.-H.; Uye, S.-I. Quantification of the abundance and distribution of the common jellyfish aurelia aurita s.l. with a dual-frequency identification sonar (DIDSON). J. Plankton Res. 2009, 31, 805–814. [Google Scholar] [CrossRef] [Green Version]
- Jing, D.; Han, J.; Wang, X.; Wang, G.; Tong, J.; Shen, W.; Zhang, J. A method to estimate the abundance of fish based on dual-frequency identification sonar (DIDSON) imaging. Fish. Sci. 2017, 83, 685–697. [Google Scholar] [CrossRef]
- Liu, L.; Lu, H.; Cao, Z.; Xiao, Y. Counting fish in sonar images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3189–3193. [Google Scholar]
- Liu, L.; Lu, H.; Xiong, H.; Xian, K.; Cao, Z.; Shen, C. Counting objects by blockwise classification. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3513–3527. [Google Scholar] [CrossRef]
- Misund, O.A.; Coetzee, J. Recording fish schools by multi-beam sonar: Potential for validating and supplementing echo integration recordings of schooling fish. Fish. Res. 2000, 47, 149–159. [Google Scholar] [CrossRef]
- Jing, D.; Han, J.; Wang, G.; Wang, X.; Wu, J.; Chen, G. Dense multiple-target tracking based on dual frequency identification sonar (DIDSON) image. In Proceedings of the OCEANS 2016, Shanghai, China, 10–13 April 2016; pp. 1–5. [Google Scholar]
- Farmer, D.; Trevorrow, M.; Pedersen, B. Intermediate range fish detection with a 12-kHz sidescan sonar. J. Acoust. Soc. Am. 1999, 106, 2481–2491. [Google Scholar] [CrossRef]
- Acker, T.; Burczynski, J.; Hedgepeth, J.M.; Ebrahim, A. Digital Scanning Sonar for Fish Feeding Monitoring in Aquaculture; Tech. Rep.; Biosonics Inc.: Seattle, WA, USA, 2002. [Google Scholar]
- Llorens, S.; Pérez-Arjona, I.; Soliveres, E.; Espinosa, V. Detection and target strength measurements of uneaten feed pellets with a single beam echosounder. Aquac. Eng. 2017, 78 Pt B, 216–220. [Google Scholar] [CrossRef]
- Teixeira, P.V.; Hover, F.S.; Leonard, J.J.; Kaess, M. Multibeam data processing for underwater mapping. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1877–1884. [Google Scholar]
- Abu, A.; Diamant, R. A statistically-based method for the detection of underwater objects in sonar imagery. IEEE Sens. J. 2019, 19, 6858–6871. [Google Scholar] [CrossRef]
- Abu, A.; Diamant, R. Unsupervised local spatial mixture segmentation of underwater objects in sonar images. IEEE J. Ocean. Eng. 2019, 44, 1179–1197. [Google Scholar] [CrossRef]
- Abu, A.; Diamant, R. Enhanced fuzzy-based local information algorithm for sonar image segmentation. IEEE Trans. Image Process. 2020, 29, 445–460. [Google Scholar] [CrossRef]
- Valdenegro-Toro, M. End-to-end object detection and recognition in forward-looking sonar images with convolutional neural networks. In Proceedings of the 2016 IEEE/OES Autonomous Underwater Vehicles (AUV), Tokyo, Japan, 6–9 November 2016; pp. 144–150. [Google Scholar]
- Arvind, C.S.; Prajwal, R.; Bhat, P.N.; Sreedevi, A.; Prabhudeva, K.N. Fish detection and tracking in pisciculture environment using deep instance segmentation. In Proceedings of the TENCON 2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 778–783. [Google Scholar]
- Nie, S.; Jiang, Z.; Zhang, H.; Cai, B.; Yao, Y. Inshore ship detection based on mask r-cnn. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 693–696. [Google Scholar]
- Hafiz, A.M.; Bhat, G.M. A survey on instance segmentation: State of the art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2018. [Google Scholar] [CrossRef]
- Wang, G.; Zuluaga, M.; Li, W.; Pratt, R.; Patel, P.; Aertsen, M.; Doel, T.; David, A.; Deprest, J.; Ourselin, S.; et al. DeepIGeoS: A deep interactive geodesic framework for medical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1559–1573. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Gao, H.; Yuan, H.; Wang, Z.; Ji, S. Pixel transposed convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1218–1227. [Google Scholar] [CrossRef] [PubMed]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H.S. Conditional random fields as recurrent neural networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Vemulapalli, R.; Tuzel, O.; Liu, M.; Chellappa, R. Gaussian conditional random field network for semantic segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3224–3233. [Google Scholar]
- Lin, G.; Shen, C.; van den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3194–3203. [Google Scholar]
- Chen, L.-C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Papandreou, G.; Chen, L.; Murphy, K.P.; Yuille, A.L. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1742–1750. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. From image-level to pixel-level labeling with convolutional networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1713–1721. [Google Scholar]
- Yao, Q.; Gong, X. Saliency guided self-attention network for weakly and semi-supervised semantic segmentation. IEEE Access 2020, 8, 413–414. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. arXiv 2019, arXiv:1908.06391. [Google Scholar]
- Liu, B.; Jiao, J.; Ye, Q. Harmonic feature activation for few-shot semantic segmentation. IEEE Trans. Image Process. 2021, 30, 3142–3153. [Google Scholar] [CrossRef] [PubMed]
- Zoph, B.; Ghiasi, G.; Lin, T.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q.V. Rethinking pre-training and self-training. arXiv 2020, arXiv:2006.06882. [Google Scholar]
- Clausen, S.; Greiner, K.; Andersen, O.; Lie, K.-A.; Schulerud, H.; Kavli, T. Automatic Segmentation of Overlapping Fish Using Shape Priors. In Image Analysis; Ersbøll, B.K., Pedersen, K.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 11–20. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13029–13038. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Environment | E-A | E-B | E-C |
|---|---|---|---|
| Total number of sonar images | 50 | 60 | 35 |
| Total number of annotated fish | 522 | 794 | 360 |
| Test (AP) | ||||||
|---|---|---|---|---|---|---|
| Mask R-CNN | Mask R-CNN+PreCNN | |||||
| Training | E-A | E-B | E-C | E-A | E-B | E-C |
| E-A | 0.86 ± 0.06 | 0.71 ± 0.07 | 0.37 ± 0.07 | 0.97 ± 0.01 | 0.96 ± 0.03 | 0.75 ± 0.07 |
| E-B | 0.66 ± 0.11 | 0.84 ± 0.06 | 0.17 ± 0.07 | 0.92 ± 0.04 | 0.99 ± 0.01 | 0.80 ± 0.02 |
| E-C | 0.41 ± 0.04 | 0.17 ± 0.05 | 0.96 ± 0.01 | 0.85 ± 0.05 | 0.91 ± 0.03 | 0.95 ± 0.02 |
| E-AB | 0.84 ± 0.04 | 0.84 ± 0.06 | 0.45 ± 0.08 | |||
| E-BC | 0.71 ± 0.09 | 0.83 ± 0.06 | 0.86 ± 0.06 | |||
| E-AC | 0.80 ± 0.06 | 0.61 ± 0.13 | 0.83 ± 0.04 | |||
| E-ABC | 0.81 ± 0.08 | 0.79 ± 0.04 | 0.76 ± 0.03 | |||
| Test (AP) | ||||||
| Mask R-CNN | Mask R-CNN+PreCNN | |||||
| Training | E-A | E-B | E-C | E-A | E-B | E-C |
| E-A | 0.47 ± 0.14 | 0.13 ± 0.03 | 0.04 ± 0.03 | 0.88 ± 0.05 | 0.84 ± 0.04 | 0.57 ± 0.10 |
| E-B | 0.11 ± 0.07 | 0.47 ± 0.04 | 0.01 ± 0.01 | 0.75 ± 0.07 | 0.89 ± 0.05 | 0.60 ± 0.08 |
| E-C | 0.10 ± 0.03 | 0.01 ± 0.01 | 0.71 ± 0.12 | 0.53 ± 0.06 | 0.70 ± 0.07 | 0.84 ± 0.03 |
| Test (AP) | ||||||
|---|---|---|---|---|---|---|
| Mask R-CNN+Contrast Stretching | Mask R-CNN+Bilateral Filtering | |||||
| Training | E-A | E-B | E-C | E-A | E-B | E-C |
| E-A | 0.86 ± 0.06 | 0.67 ± 0.04 | 0.36 ± 0.05 | 0.86 ± 0.03 | 0.68 ± 0.04 | 0.38 ± 0.04 |
| E-B | 0.61 ± 0.04 | 0.84 ± 0.06 | 0.15 ± 0.06 | 0.55 ± 0.13 | 0.84 ± 0.03 | 0.09 ± 0.08 |
| E-C | 0.40 ± 0.06 | 0.08 ± 0.04 | 0.96 ± 0.01 | 0.41 ± 0.02 | 0.11 ± 0.03 | 0.89 ± 0.06 |
| Test (AP) | |||
|---|---|---|---|
| Mask R-CNN+PreCNN | |||
| Training | E-A | E-B | E-C |
| E-A | 0.90 ± 0.04 | 0.73 ± 0.06 | 0.62 ± 0.06 |
| E-B | 0.85 ± 0.02 | 0.79 ± 0.03 | 0.60 ± 0.05 |
| E-C | 0.79 ± 0.02 | 0.71 ± 0.07 | 0.57 ± 0.03 |
| Test (AP) | |||
|---|---|---|---|
| Training | E-A | E-B | E-C |
| E-A | 0.57 ± 0.04 | 0.56 ± 0.01 | 0.45 ± 0.02 |
| E-B | 0.47 ± 0.06 | 0.59 ± 0.04 | 0.28 ± 0.04 |
| E-C | 0.40 ± 0.02 | 0.25 ± 0.02 | 0.47 ± 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, C.-C.; Wang, Y.-P.; Cheng, S.-C. Fish Segmentation in Sonar Images by Mask R-CNN on Feature Maps of Conditional Random Fields. Sensors 2021, 21, 7625. https://doi.org/10.3390/s21227625
Chang C-C, Wang Y-P, Cheng S-C. Fish Segmentation in Sonar Images by Mask R-CNN on Feature Maps of Conditional Random Fields. Sensors. 2021; 21(22):7625. https://doi.org/10.3390/s21227625
Chicago/Turabian StyleChang, Chin-Chun, Yen-Po Wang, and Shyi-Chyi Cheng. 2021. "Fish Segmentation in Sonar Images by Mask R-CNN on Feature Maps of Conditional Random Fields" Sensors 21, no. 22: 7625. https://doi.org/10.3390/s21227625
APA StyleChang, C.-C., Wang, Y.-P., & Cheng, S.-C. (2021). Fish Segmentation in Sonar Images by Mask R-CNN on Feature Maps of Conditional Random Fields. Sensors, 21(22), 7625. https://doi.org/10.3390/s21227625