
BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8

Abstract
:1. Introduction
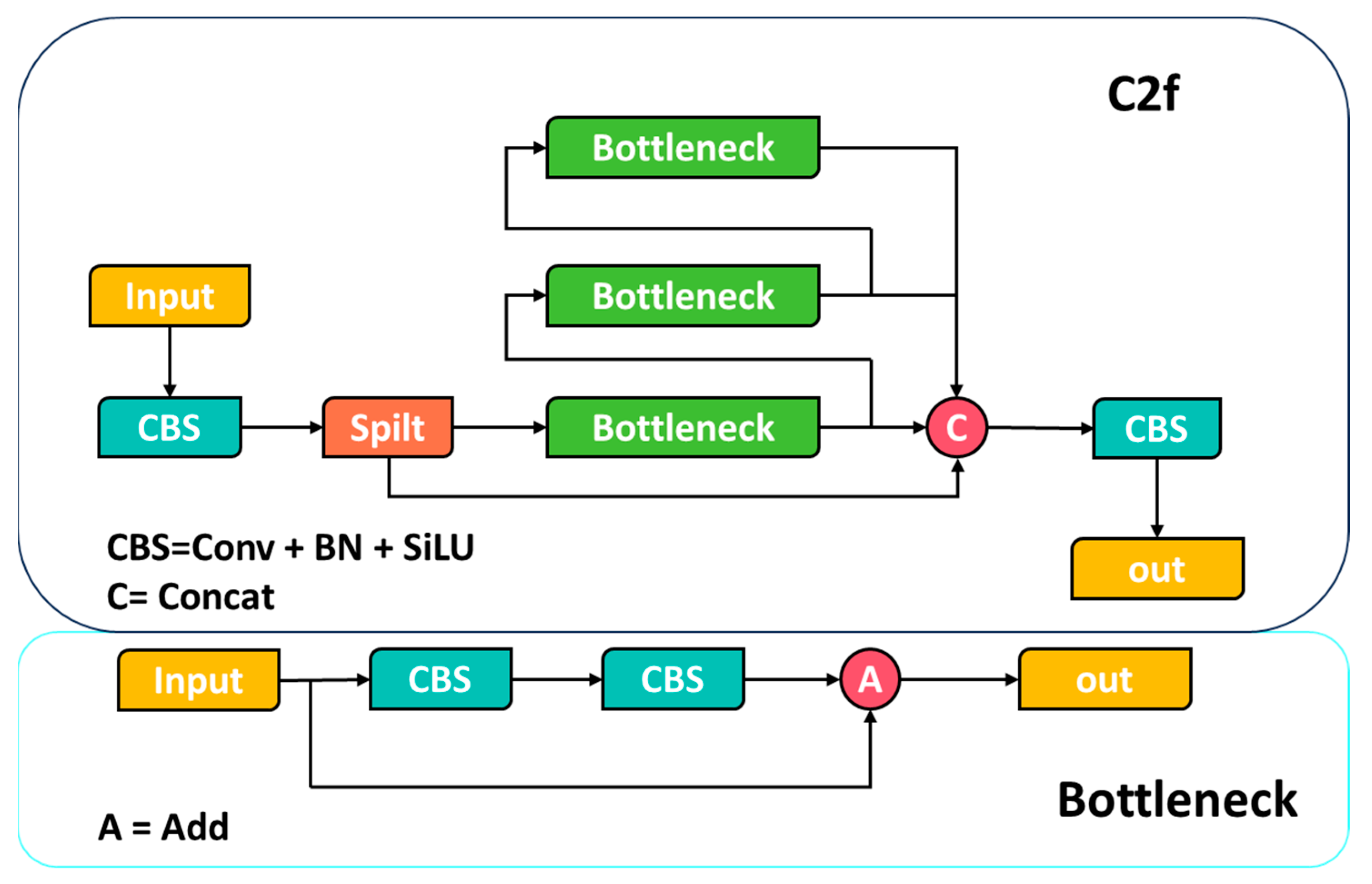
2. YOLOv8 Network Architecture
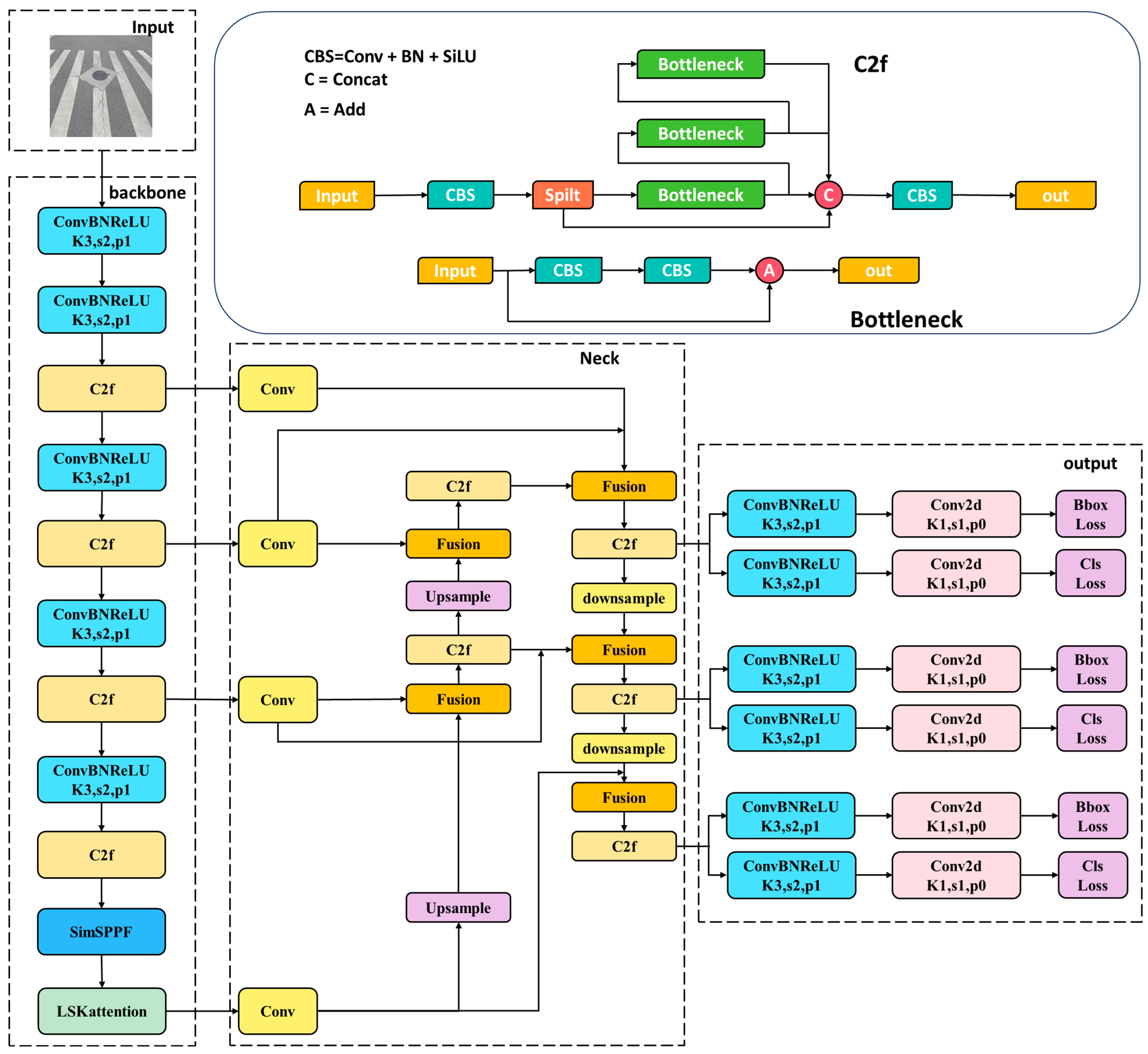
3. Improved YOLOv8 Model
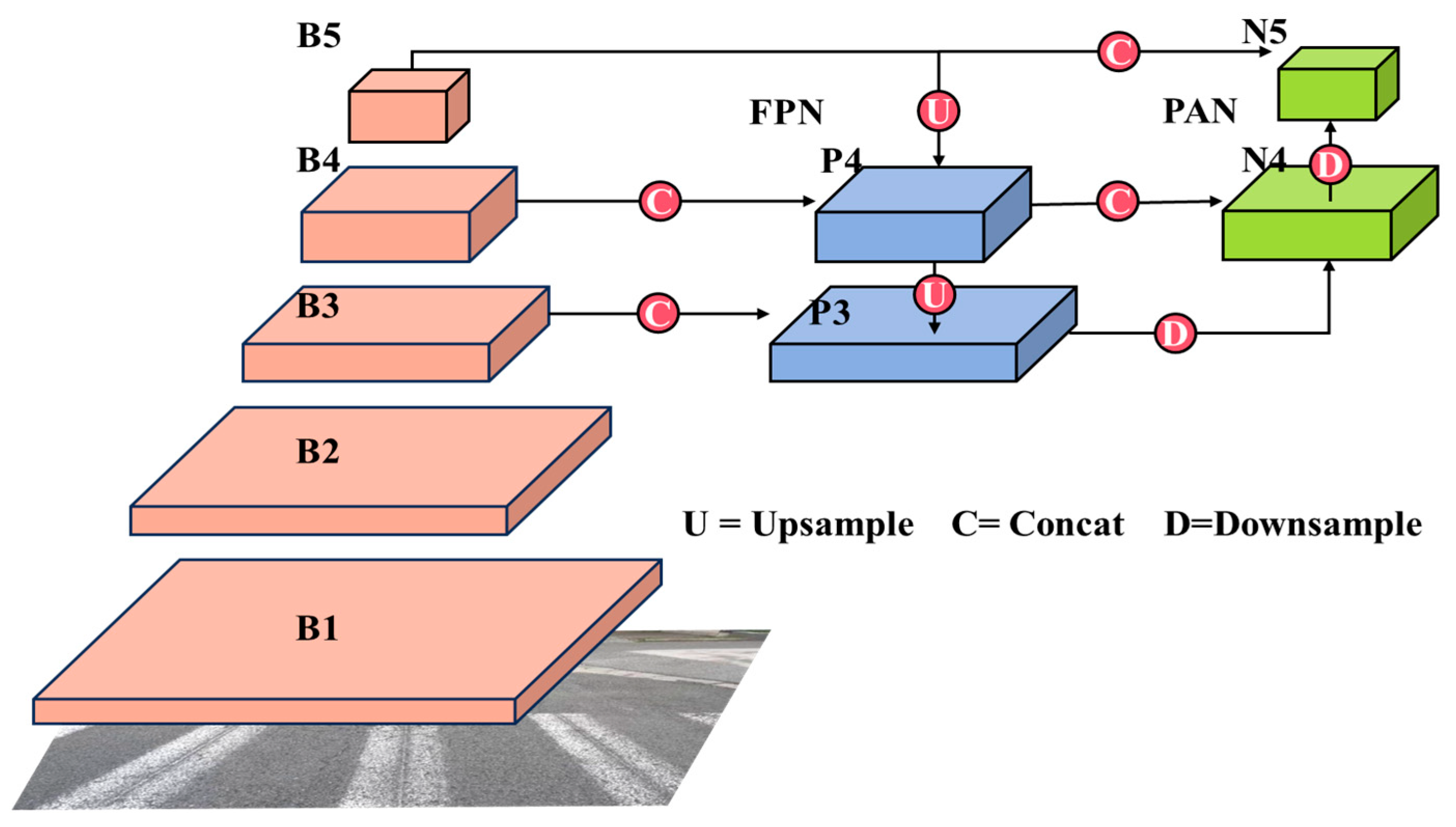
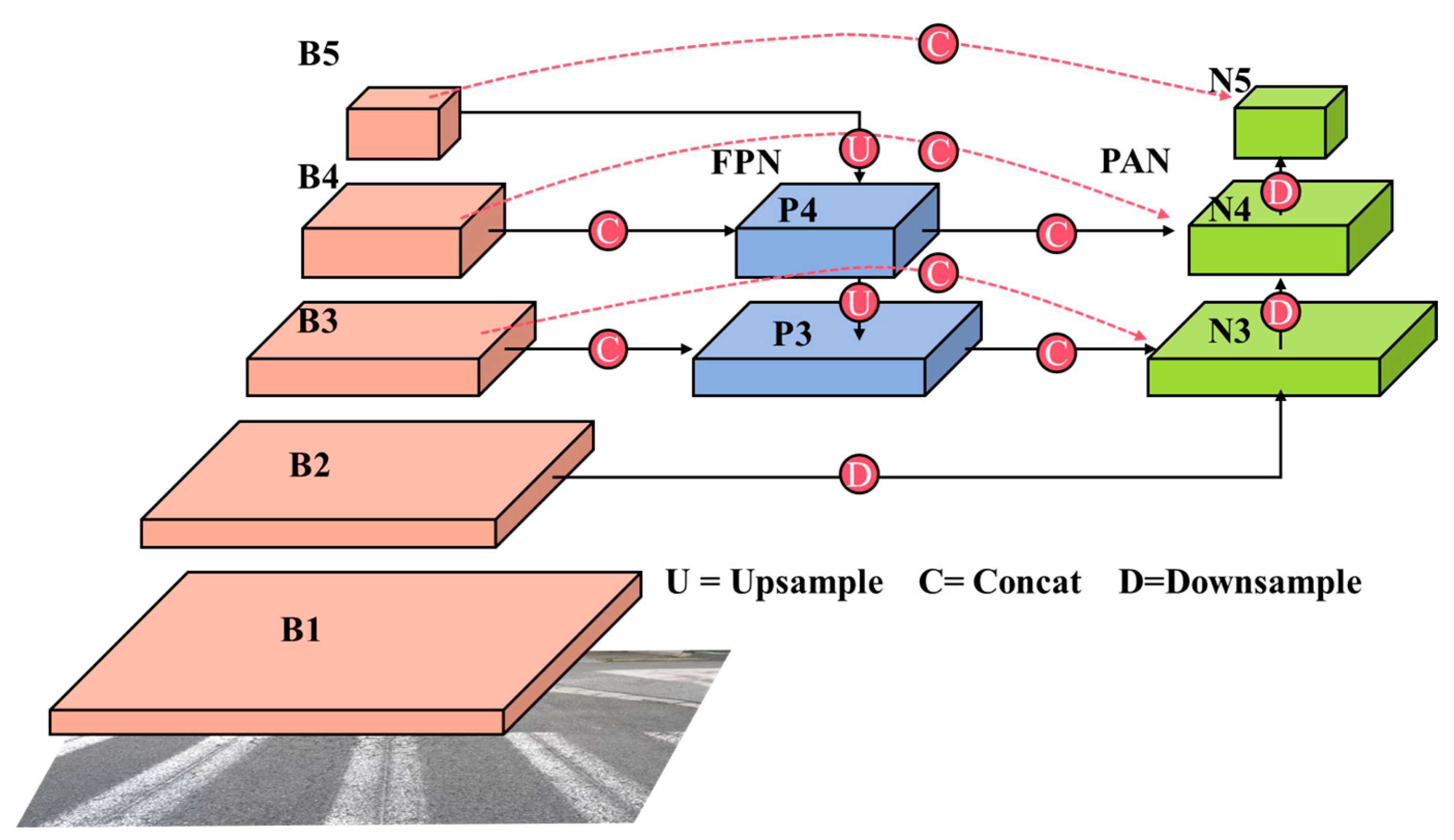
3.1. Feature Pyramid Optimization
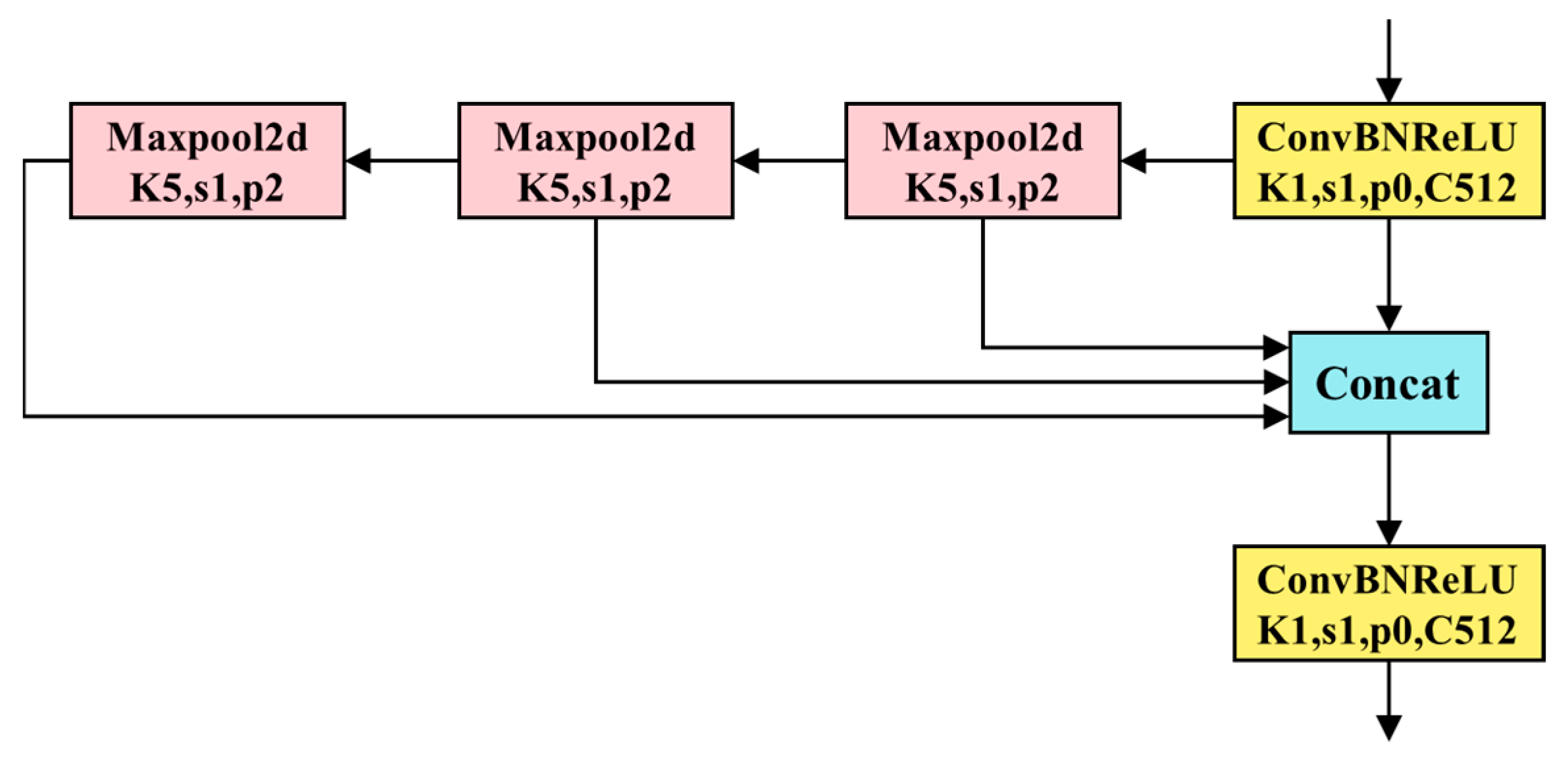
3.2. Optimization of Spatial Pyramid Pooling
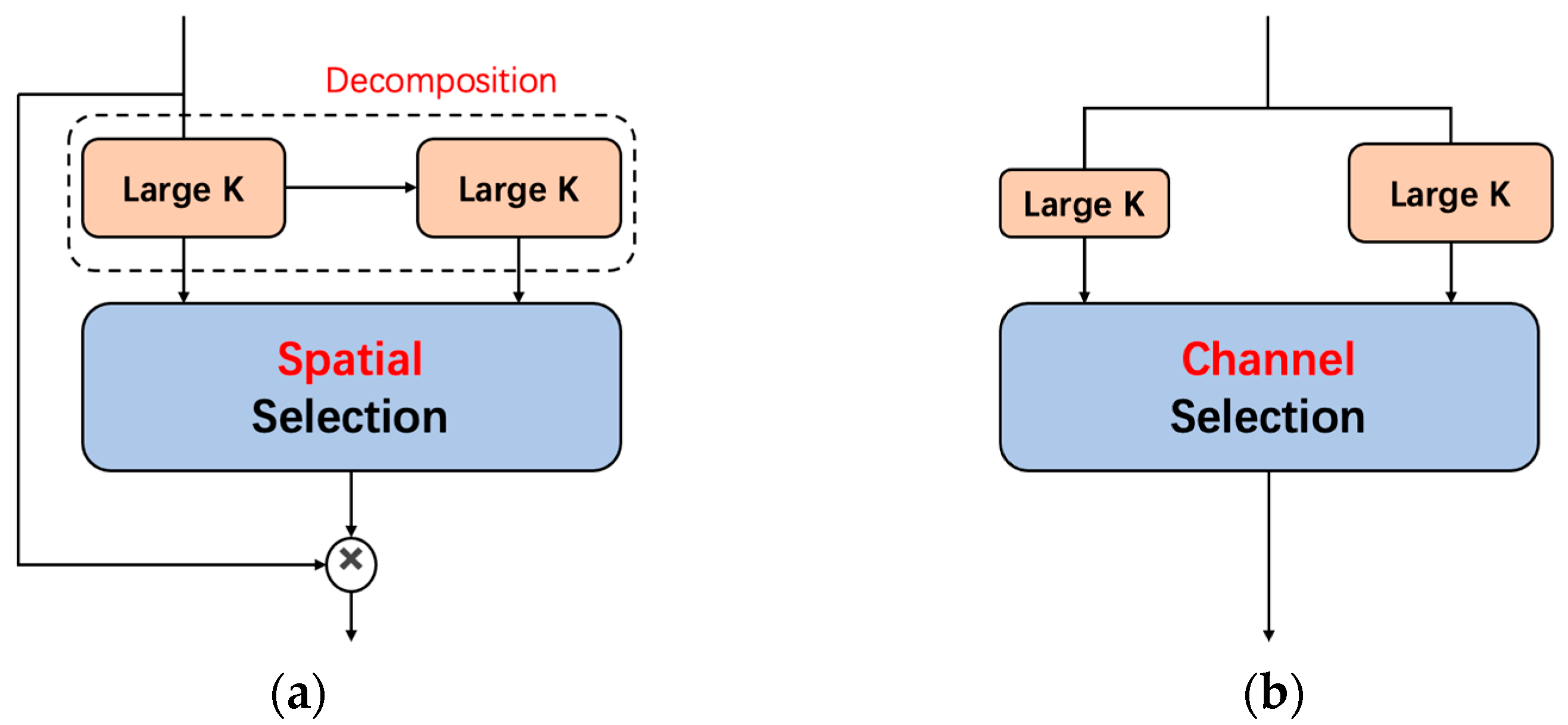
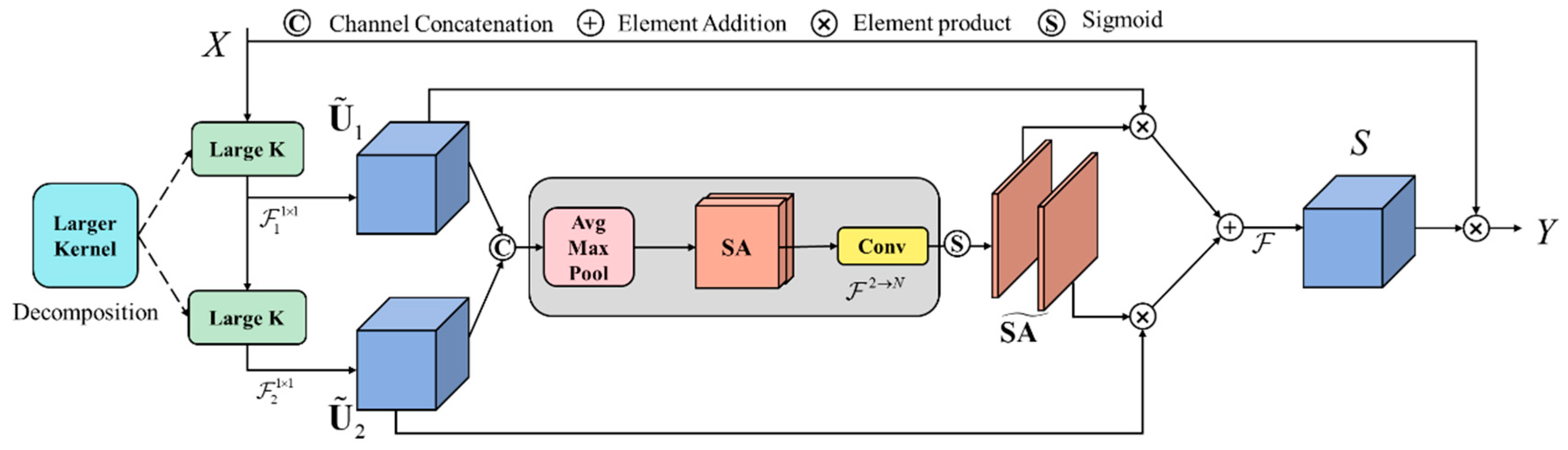
3.3. Dynamic Large Convolutional Kernel Spatial Attention Mechanism
3.4. Network Structure and Parameters
4. Results and Analysis
4.1. Experimental Environment
4.2. Dataset and Evaluation Metrics
4.3. Comparison of Different Spatial Pyramid Pooling Effects
4.4. Comparison of Different Attention Mechanism Effects
4.5. Ablation Experiment
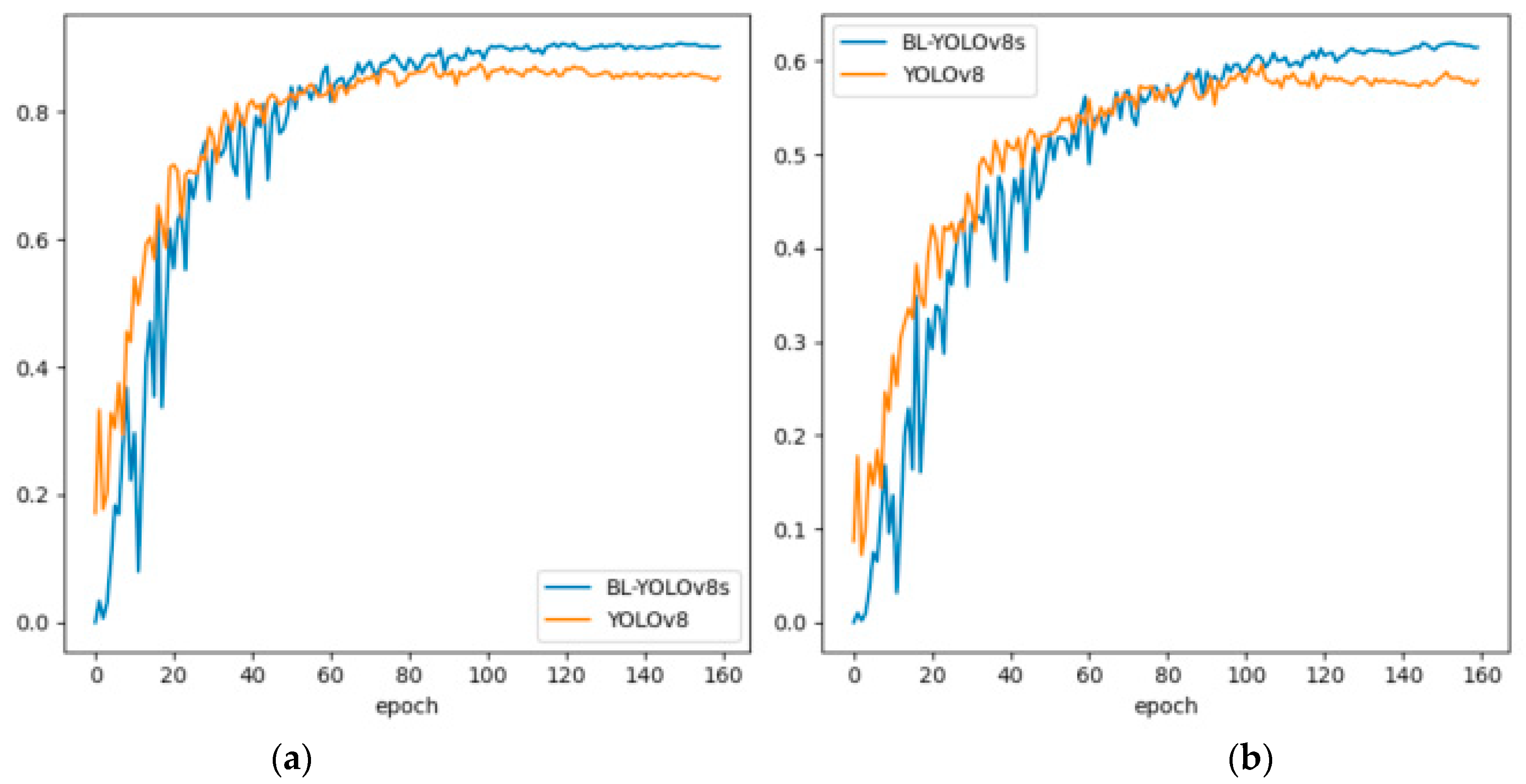
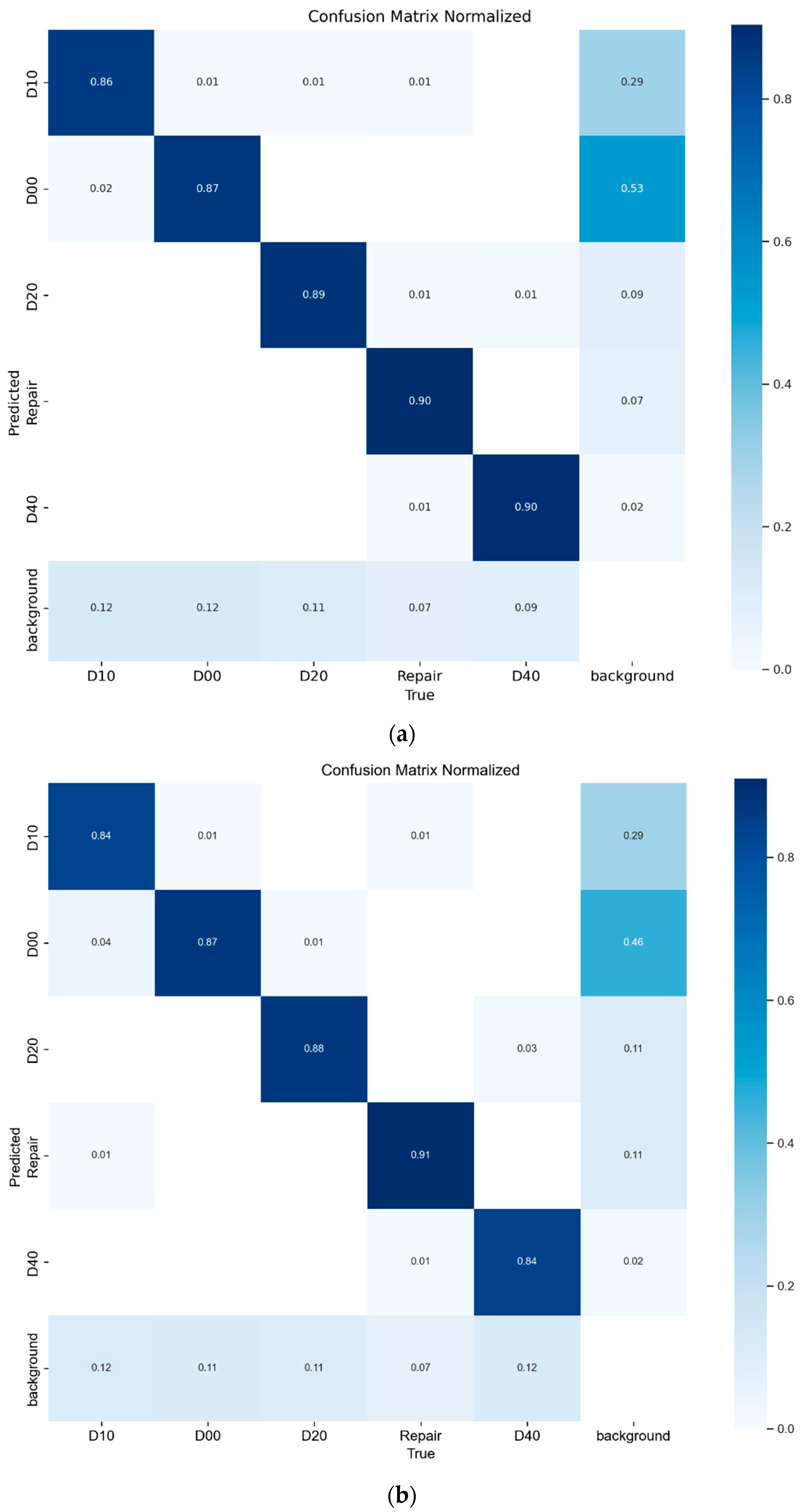
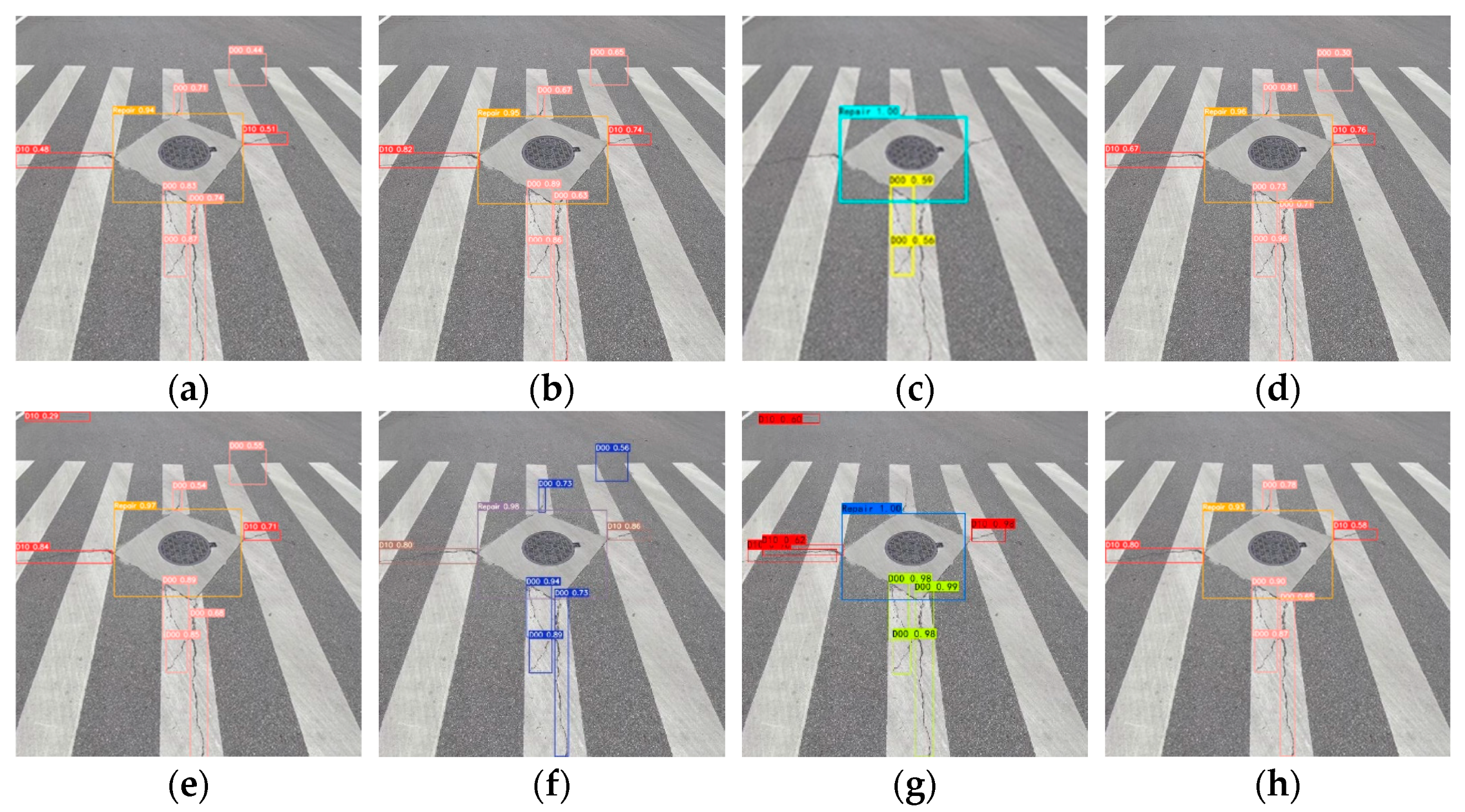
4.6. Interpretability Experiment
4.7. Self-Built Data Performance Experiments
4.8. Comparison of Performance of Different Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Mraz, A.; Kashiyama, T.; Sekimoto, Y.J.A.i.C. Deep learning-based road damage detection and classification for multiple countries. Autom. Constr. 2021, 132, 103935. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Shim, S.; Kim, J.; Lee, S.-W.; Cho, G.-C. Road damage detection using super-resolution and semi-supervised learning with generative adversarial network. Autom. Constr. 2022, 135, 104139. [Google Scholar] [CrossRef]
- Naddaf-Sh, S.; Naddaf-Sh, M.-M.; Kashani, A.R.; Zargarzadeh, H. An efficient and scalable deep learning approach for road damage detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5602–5608. [Google Scholar]
- Wan, F.; Sun, C.; He, H.; Lei, G.; Xu, L.; Xiao, T. YOLO-LRDD: A lightweight method for road damage detection based on improved YOLOv5s. EURASIP J. Adv. Signal Process. 2022, 2022, 98. [Google Scholar] [CrossRef]
- Hacıefendioğlu, K.; Başağa, H.B. Concrete road crack detection using deep learning-based faster R-CNN method. Iran. J. Sci. Technol. Trans. Civ. Eng. 2022, 46, 1621–1633. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Omata, H.; Kashiyama, T.; Sekimoto, Y. Global road damage detection: State-of-the-art solutions. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5533–5539. [Google Scholar]
- Pei, Z.; Lin, R.; Zhang, X.; Shen, H.; Tang, J.; Yang, Y. CFM: A consistency filtering mechanism for road damage detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5584–5591. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Yang, J. Spatial group-wise enhance: Enhancing semantic feature learning in cnn. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 687–702. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. arXiv 2023, arXiv:2303.09030. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W. BiFormer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10323–10333. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef]
- Pham, V.; Nguyen, D.; Donan, C. Road Damage Detection and Classification with YOLOv7. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 6416–6423. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | From | N | Params | Module | Arguments |
|---|---|---|---|---|---|
| 0 | −1 | 1 | 928 | Conv | [3, 32, 3, 2] |
| 1 | −1 | 1 | 18,560 | Conv | [32, 64, 3, 2] |
| 2 | −1 | 1 | 29,056 | C2f | [64, 64, 1, True] |
| 3 | −1 | 1 | 73,984 | Conv | [64, 128, 3, 2] |
| 4 | −1 | 2 | 197,632 | C2f | [128, 128, 2, True] |
| 5 | −1 | 1 | 295,424 | Conv | [128, 256, 3, 2] |
| 6 | −1 | 2 | 788,480 | C2f | [256, 256, 2, True] |
| 7 | −1 | 1 | 1,180,672 | Conv | [256, 512, 3, 2] |
| 8 | −1 | 1 | 1,838,080 | C2f | [512, 512, 1, True] |
| 9 | −1 | 1 | 656,896 | SimSPFF | [512, 512, 5] |
| 10 | −1 | 1 | 433,350 | LSK | [512] |
| 11 | 4 | 1 | 16,640 | Conv | [128, 128] |
| 12 | 6 | 1 | 33,024 | Conv | [256, 128] |
| 13 | 10 | 1 | 65,792 | Conv | [512, 128] |
| 14 | −1 | 1 | 0 | Upsample | [None, 2, ’nearest’] |
| 15 | [−1, 12] | 1 | 2 | Fusion | [[128, 128], ’bifpn’] |
| 16 | −1 | 1 | 115,456 | C2f | [128, 128, 1] |
| 17 | −1 | 1 | 0 | Upsample | [None, 2, ’nearest’] |
| 18 | [−1, 11] | 1 | 2 | Fusion | [[128, 128], ’bifpn’] |
| 19 | −1 | 1 | 115,456 | C2f | [128, 128, 1] |
| 20 | 2 | 1 | 73,984 | Conv | [64, 128, 3, 2] |
| 21 | [−1, 11, 19] | 1 | 3 | Fusion | [[128, 128, 128], ’bifpn’] |
| 22 | −1 | 1 | 115,456 | C2f | [128, 128, 1] |
| 23 | −1 | 1 | 147,712 | Conv | [128, 128, 3, 2] |
| 24 | [−1, 12, 16] | 1 | 3 | Fusion | [[128, 128, 128], ’bifpn’] |
| 25 | −1 | 1 | 115,456 | C2f | [128, 128, 1] |
| 26 | −1 | 1 | 147,712 | Conv | [128, 128, 3, 2] |
| 27 | [−1, 13] | 1 | 2 | Fusion | [[128, 128], ’bifpn’] |
| 28 | −1 | 1 | 115,456 | C2f | [128, 128, 1] |
| 29 | [22, 25, 28] | 1 | 1,262,272 | Detect | [80, [128, 128, 128]] |
| summary (fused): 204 layers, 7829,394 parameters, 7829,378 gradients, 25.5 GFLOPs | |||||
| Environmental Parameter | Value |
|---|---|
| Operating system | Ubuntu18.04 |
| Deep learning framework | Pytorch |
| programming language | Python3.8 |
| CPU | Intel(R) Xeon(R) Platinum 8255C |
| GPU | RTX 3090 (24 GB) |
| RAM | 30 GB |
| Hyperparameters | Value |
|---|---|
| Learning Rate | 0.01 |
| Image Size | 640 × 640 |
| Momentum | 0.937 |
| Optimizer | SGD |
| Batch Size | 64 |
| Epoch | 160 |
| Weight Decay | 0.0005 |
| Pavement Distress | Distress Class | Quantity |
|---|---|---|
| grid cracks | D20 | 756 |
| longitudinal cracks | D00 | 3270 |
| transverse cracks | D10 | 1895 |
| potholes | D40 | 255 |
| road repair | Repair | 821 |
| Models | mAP@0.5/% | Para (M) | GFLOPs | Time (ms) |
|---|---|---|---|---|
| Yolov8s + SPP | 86.9 | 11.16 | 28.8 | 16.40 |
| Yolov8s + SPPF | 87.4 | 11.16 | 28.8 | 6.93 |
| Yolov8s + SimSPPF | 87.4 | 11.16 | 28.8 | 5.73 |
| Yolov8s + ASPP | 86.8 | 14.44 | 31.2 | 11.12 |
| Yolov8s + SPPCSPC | 88.1 | 17.59 | 34.0 | 29.72 |
| Models | mAP@0.5/% | Para (M) | GFLOPs | FPS |
|---|---|---|---|---|
| YOLOv8s + BiFPN | 89.3 | 7.39 | 25.2 | 108 |
| +SE | 89.3 | 13.82 | 30.1 | 83 |
| +Biform [34] | 89.4 | 8.42 | 25.2 | 98 |
| +CBAM | 90.2 | 7.39 | 25.1 | 91 |
| +EMA [35] | 89.3 | 7.40 | 25.3 | 98 |
| +CA | 89.0 | 7.42 | 25.1 | 111 |
| +LSK-attention | 90.5 | 7.83 | 25.7 | 103 |
| BiFPN | SimSPPF | LSK-Net | mAP@0.5/% | Para (M) | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| 87.4 | 11.16 | 28.8 | 128 | |||
| √ | 89.3 | 7.39 | 25.2 | 115 | ||
| √ | 87.4 | 11.16 | 28.8 | 130 | ||
| √ | 88.7 | 11.58 | 29.0 | 120 | ||
| √ | √ | 89.5 | 7.39 | 25.2 | 117 | |
| √ | √ | √ | 90.7 | 7.82 | 25.5 | 98 |
| Models | mAP@0.5/% | Para (M) | GFLOPs | FPS | F1-Score |
|---|---|---|---|---|---|
| Faster R-CNN | 73.2 | 28.31 | 940.97 | 11 | 0.60 |
| SSD | 72.7 | 26.28 | 62.74 | 76 | 0.61 |
| YOLOv3-tiny | 76.1 | 8.68 | 13.0 | 222 | 0.71 |
| YOLOv5s | 85.2 | 7.02 | 15.8 | 156 | 0.83 |
| YOLOv6s | 85.5 | 16.29 | 44.0 | 108 | 0.81 |
| YOLOv5-MobileNetv3 [37] | 87.1 | 7.39 | 9.9 | 82 | 0.84 |
| YOLOX | 89.0 | 5.06 | 15.4 | 77 | 0.86 |
| Efficientdet [10] | 49.8 | 3.87 | 5.2 | 27 | 0.46 |
| YOLOv7-CA [38] | 87.0 | 6.02 | 13.1 | 138 | 0.82 |
| YOLOv7-tiny | 88.3 | 6.02 | 13.2 | 144 | 0.84 |
| YOLOv8s | 87.4 | 11.16 | 28.8 | 120 | 0.83 |
| BL-YOLO8s | 90.7 | 7.82 | 25.5 | 98 | 0.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors 2023, 23, 8361. https://doi.org/10.3390/s23208361
Wang X, Gao H, Jia Z, Li Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors. 2023; 23(20):8361. https://doi.org/10.3390/s23208361
Chicago/Turabian StyleWang, Xueqiu, Huanbing Gao, Zemeng Jia, and Zijian Li. 2023. "BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8" Sensors 23, no. 20: 8361. https://doi.org/10.3390/s23208361
APA StyleWang, X., Gao, H., Jia, Z., & Li, Z. (2023). BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors, 23(20), 8361. https://doi.org/10.3390/s23208361