
CTSF: An Intrusion Detection Framework for Industrial Internet Based on Enhanced Feature Extraction and Decision Optimization Approach


Abstract
:1. Introduction
- Introduces a novel network framework, CTSF, tailored for intrusion detection in the Industrial Internet. This framework is rooted in the actual conditions of the Industrial Internet environment and modifies the traditional Transformer model’s decoder structure to better handle abnormal traffic.
- The CTSF framework leverages the advantage of CNN in extracting local features, compensating for the traditional Transformer’s shortcomings in this aspect, and effectively applying to intrusion detection in the Industrial Internet.
- This paper conducts simulation experiments on the Industrial Internet dataset X-IIOTID with CTSF, and the results demonstrate CTSF’s ability to accurately recognize small-sample categories, achieving an overall accuracy of 0.98875.
2. Related Work
2.1. SVM
2.2. CNN
2.3. Transformer
2.4. CNN-Transformer
3. Framework Analysis
3.1. Pre-Training Part
3.1.1. CNN in the Pre-Training Part
3.1.2. Transformer in the Pre-Training Part
3.2. Decision-Making Part
3.3. The Training Process of the CTSF
4. Experimental Setup and Discussion
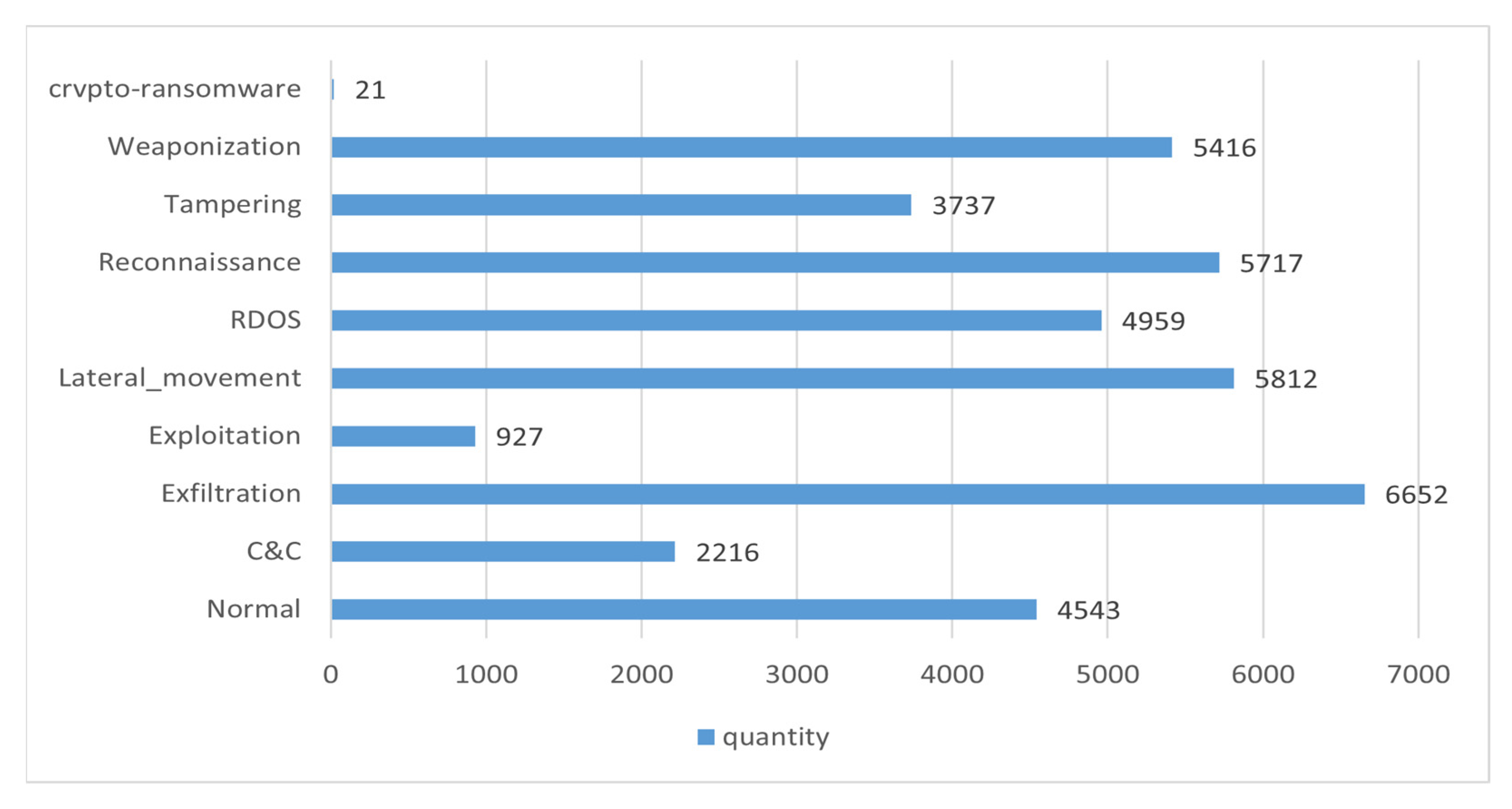
4.1. Dataset Description and Preprocessing
4.2. Parameter Settings of CTSF and Control Models
4.2.1. Parameter Settings of CTSF
- The parameter d_model in the positional encoder was set to 200, representing the extension of each feature of the input data to 200 dimensions. The dropout parameter was set to the default value of 0.1, and the max_len parameter limited the maximum number of features in the input data, which was set to the default value of 5000 in this study.
- The parameter d_model in the encoder was set to 200, consistent with the d_model parameter in the positional encoder; the nhead parameter was set to 2, indicating that there were 2 parallel heads in the multi-head attention layer to concurrently extract features from the input data; the nhid parameter was set to 2, indicating that the entire encoder consists of two encoder layers; the dropout parameter was set to 0.2 to ensure that the overall framework did not overfit as much as possible. The shape of the input data changed to (batch_size, 128, 200) after passing through the encoder section.
- The improved decoder consisted of a meticulously designed fully connected layer with an input feature dimension of 200 and an output feature dimension of 128, denoted as in_features and out_features, respectively. After passing through the decoder section, the shape of the input data changed to (batch_size, 128, 128).
- The section of fully connected layers consisted of a total of five layers. The parameters for the first fully connected layer: in_features with a value of 128 × 128 and out_features with a value of 1000. The second layer had 1000 as in_features and 500 as out_features. In the third layer, the in_features parameter was set to 500, and the out_features parameter was set to 200. For the fourth layer, in_features was 200 and out_features was 50. Finally, in the fifth layer, in_features was 50 and out_features was 10; here, 10 represents the number of classes for initialization classification. The activation functions employed were ReLU for the first four layers and softmax for the final layer.
4.2.2. Parameter Settings of CNN-Transformer (Improved)
4.2.3. Parameter Settings of CNN-RNN
4.2.4. Parameter Settings of CNN
4.2.5. Parameter Settings of RNN
4.3. Model Evaluation Metrics
- Accuracy is used to measure the prediction accuracy of a classification model, which is the ratio of correctly predicted samples to the total number of samples.
- Precision measures the model’s ability to correctly predict positive instances among the predicted positives, i.e., the ratio of true positive instances to the total number of predicted positive samples.
- Recall measures the model’s ability to identify positive samples, i.e., the ratio of true positive instances to the total number of actual positive samples.
- F1 Score: an evaluation metric that comprehensively considers both precision and recall, calculated as the harmonic mean of precision and recall.
4.4. Analysis and Discussion of Experimental Results
5. Conclusions and Future Work
- In CTSF, local and global features of data are extracted using CNN and an enhanced Transformer. While this paper has improved and optimized the traditional Transformer decoder for the characteristics of Industrial Internet traffic data, making it more lightweight, CTSF as a whole is still not sufficiently lightweight. Next, we plan to explore optimization algorithms to further enhance the pre-training phase of CTSF, aiming to reduce its resource consumption while maintaining its accuracy and detection rate.
- In the pretraining phase, we can achieve parallel computing by adopting parallel training and parameter asynchronous updating methods. Distributing computational tasks to edge devices or within a distributed computing environment alleviates the burden on individual devices and reduces latency. Parallel and distributed computing can decompose the training tasks of large-scale models into multiple smaller tasks which are executed concurrently across various computing nodes, significantly reducing training time and enhancing training efficiency. It is worth noting that ensuring load balance among different nodes is a challenge in distributed computing. Some nodes may become busier than others, leading to performance imbalances. By taking into account both the benefits and challenges, and implementing appropriate optimization strategies, such as employing more efficient communication protocols and using suitable load balancing algorithms, the scalability and performance of the CTSF framework can be improved.
- Utilizing pruning algorithms to reduce the CTSF’s size. These algorithms can identify and remove connections or layers that contribute minimally to the CTSF’s accuracy.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.Q.; Yu, F.R.; Deng, G.; Luo, C.; Ming, Z.; Yan, Q. Industrial internet: A survey on the enabling technologies, applications, and challenges. IEEE Commun. Surv. Tutor. 2017, 19, 1504–1526. [Google Scholar] [CrossRef]
- Qin, W.; Chen, S.; Peng, M. Recent advances in Industrial Internet: Insights and challenges. Digit. Commun. Netw. 2020, 6, 1–13. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. A survey on intrusion detection system: Feature selection, model, performance measures, application perspective, challenges, and future research directions. Artif. Intell. Rev. 2022, 55, 453–563. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 20. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar] [CrossRef]
- Saranya, T.; Sridevi, S.; Deisy, C.; Chung, T.D.; Khan, M.A. Performance analysis of machine learning algorithms in intrusion detection system: A review. Procedia Comput. Sci. 2020, 171, 1251–1260. [Google Scholar] [CrossRef]
- Maseer, Z.K.; Yusof, R.; Bahaman, N.; Mostafa, S.A.; Foozy, C.F.M. Benchmarking of machine learning for anomaly based intrusion detection systems in the CICIDS2017 dataset. IEEE Access 2021, 9, 22351–22370. [Google Scholar] [CrossRef]
- Almomani, O.; Almaiah, M.A.; Alsaaidah, A.; Smadi, S.; Mohammad, A.H.; Althunibat, A. Machine learning classifiers for network intrusion detection system: Comparative study. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; pp. 440–445. [Google Scholar]
- Halimaa, A.; Sundarakantham, K. Machine learning based intrusion detection system. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 916–920. [Google Scholar]
- Mohammadi, M.; Rashid, T.A.; Karim, S.H.T.; Aldalwie, A.H.M.; Tho, Q.T.; Bidaki, M.; Rahmani, A.M.; Hosseinzadeh, M. A comprehensive survey and taxonomy of the SVM-based intrusion detection systems. J. Netw. Comput. Appl. 2021, 178, 102983. [Google Scholar] [CrossRef]
- Ngueajio, M.K.; Washington, G.; Rawat, D.B.; Ngueabou, Y. Intrusion Detection Systems Using Support Vector Machines on the KDDCUP’99 and NSL-KDD Datasets: A Comprehensive Survey. In Intelligent Systems and Applications, Proceedings of the 2022 Intelligent Systems Conference (IntelliSys), Amsterdam, The Netherlands, 1–2 September 2022; Springer International Publishing: Cham, Switzerland, 2022; Volume 2, pp. 609–629. [Google Scholar]
- Kocher, G.; Kumar, G. Machine learning and deep learning methods for intrusion detection systems: Recent developments and challenges. Soft Comput. 2021, 25, 9731–9763. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Aleesa, A.M.; Zaidan, B.B.; Zaidan, A.A.; Sahar, N.M. Review of intrusion detection systems based on deep learning techniques: Coherent taxonomy, challenges, motivations, recommendations, substantial analysis and future directions. Neural Comput. Appl. 2020, 32, 9827–9858. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN variants for computer vision: History, architecture, application, challenges and future scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef] [PubMed]
- Yuan, F.; Zhang, Z.; Fang, Z. An effective CNN and Transformer complementary network for medical image segmentation. Pattern Recognit. 2023, 136, 109228. [Google Scholar] [CrossRef]
- Mirlekar, S.; Kanojia, K.P. A Comprehensive Study on Machine Learning Algorithms for Intrusion Detection System. In Proceedings of the 2022 10th International Conference on Emerging Trends in Engineering and Technology-Signal and Information Processing (ICETET-SIP-22), Nagpur, India, 29–30 April 2022; pp. 1–6. [Google Scholar]
- Almaiah, M.A.; Almomani, O.; Alsaaidah, A.; Al-Otaibi, S.; Bani-Hani, N.; Hwaitat, A.K.A.; Al-Zahrani, A.; Lutfi, A.; Awad, A.B.; Aldhyani, T.H. Performance Investigation of Principal Component Analysis for Intrusion Detection System Using Different Support Vector Machine Kernels. Electronics 2022, 11, 3571. [Google Scholar] [CrossRef]
- Saheed, Y.K.; Arowolo, M.O.; Tosho, A.U. An Efficient Hybridization of K-Means and Genetic Algorithm Based on Support Vector Machine for Cyber Intrusion Detection System. Int. J. Electr. Eng. Inform. 2022, 14, 426–442. [Google Scholar] [CrossRef]
- Khairandish, M.O.; Sharma, M.; Jain, V.; Chatterjee, J.M.; Jhanjhi, N.Z. A hybrid CNN-SVM threshold segmentation approach for tumor detection and classification of MRI brain images. IRBM 2022, 43, 290–299. [Google Scholar] [CrossRef]
- Tao, T.; Wei, X. A hybrid CNN–SVM classifier for weed recognition in winter rape field. Plant Methods 2022, 18, 29. [Google Scholar] [CrossRef]
- Krichen, M. Convolutional neural networks: A survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Alahmari, F.; Naim, A.; Alqahtani, H. E-Learning Modeling Technique and Convolution Neural Networks in Online Education. In IoT-Enabled Convolutional Neural Networks: Techniques and Applications; River Publishers: Aalborg, Denmark, 2023; pp. 261–295. [Google Scholar]
- Pingale, S.V.; Sutar, S.R. Remora whale optimization-based hybrid deep learning for network intrusion detection using CNN features. Expert Syst. Appl. 2022, 210, 118476. [Google Scholar] [CrossRef]
- El-Ghamry, A.; Darwish, A.; Hassanien, A.E. An optimized CNN-based intrusion detection system for reducing risks in smart farming. Internet Things 2023, 22, 100709. [Google Scholar] [CrossRef]
- Qazi, E.U.H.; Almorjan, A.; Zia, T. A One-Dimensional Convolutional Neural Network (1D-CNN) Based Deep Learning System for Network Intrusion Detection. Appl. Sci. 2022, 12, 7986. [Google Scholar] [CrossRef]
- Halbouni, A.H.; Gunawan, T.S.; Halbouni, M.; Assaig, F.A.A.; Effendi, M.R.; Ismail, N. CNN-IDS: Convolutional Neural Network for Network Intrusion Detection System. In Proceedings of the 2022 8th International Conference on Wireless and Telematics (ICWT), Yogyakarta, Indonesia, 21–22 July 2022; pp. 1–4. [Google Scholar]
- Xia, L.; Mi, S.; Zhang, J.; Luo, J.; Shen, Z.; Cheng, Y. Dual-Stream Feature Extraction Network Based on CNN and Transformer for Building Extraction. Remote Sens. 2023, 15, 2689. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, H.; Wang, P.; Sun, Z. RTIDS: A robust transformer-based approach for intrusion detection system. IEEE Access 2022, 10, 64375–64387. [Google Scholar] [CrossRef]
- Wang, M.; Yang, N.; Weng, N. Securing a Smart Home with a Transformer-Based IoT Intrusion Detection System. Electronics 2023, 12, 2100. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, L. Intrusion Detection Model Based on Improved Transformer. Appl. Sci. 2023, 13, 6251. [Google Scholar] [CrossRef]
- Tan, M.; Iacovazzi, A.; Cheung, N.M.M.; Elovici, Y. A neural attention model for real-time network intrusion detection. In Proceedings of the 2019 IEEE 44th Conference on Local Computer Networks (LCN), Osnabrueck, Germany, 14–17 October 2019; pp. 291–299. [Google Scholar]
- Khan, A.; Rauf, Z.; Sohail, A.; Rehman, A.; Asif, H.; Asif, A.; Farooq, U. A survey of the Vision Transformers and its CNN-Transformer based Variants. arXiv 2023, arXiv:2305.09880. [Google Scholar]
- Yao, R.; Wang, N.; Chen, P.; Ma, D.; Sheng, X. A CNN-transformer hybrid approach for an intrusion detection system in advanced metering infrastructure. Multimed. Tools Appl. 2023, 82, 19463–19486. [Google Scholar] [CrossRef]
- Luo, S.; Zhao, Z.; Hu, Q.; Liu, Y. A hierarchical CNN-transformer model for network intrusion detection. In Proceedings of the 2nd International Conference on Applied Mathematics, Modelling, and Intelligent Computing (CAMMIC 2022), Kunming, China, 25–27 March 2022; Volume 12259, pp. 853–860. [Google Scholar]
- Al-Hawawreh, M.; Sitnikova, E.; Aboutorab, N. X-IIoTID: A connectivity-agnostic and device-agnostic intrusion data set for industrial Internet of Things. IEEE Internet Things J. 2021, 9, 3962–3977. [Google Scholar] [CrossRef]
- Alanazi, R.; Aljuhani, A. Anomaly Detection for Industrial Internet of Things Cyberattacks. Comput. Syst. Sci. Eng. 2023, 44, 2361–2378. [Google Scholar] [CrossRef]
- Aftab, S.; Shah, Z.S.; Memon, S.A.; Shaikh, Q. A machine-learning-based Intrusion detection for IIoT infrastructure. In Proceedings of the 2023 7th International Multi-Topic ICT Conference (IMTIC), Jamshoro, Pakistan, 10–12 May 2023; pp. 1–6. [Google Scholar]
- Alenezi, N.; Aljuhani, A. Intelligent Intrusion Detection for Industrial Internet of Things Using Clustering Techniques. Comput. Syst. Sci. Eng. 2023, 46, 2899–2915. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Parameters | Meaning |
|---|---|---|
| 1 | n | The number of features a piece of network traffic data has |
| 2 | A feature vector corresponding to a network traffic event | |
| 3 | The “length” of the convolution kernel | |
| 4 | The moving step of the convolution kernel | |
| 5 | The initial eigenvector of each step is convolved to obtain the process value | |
| 6 | The weight parameters of the convolution kernel | |
| 7 | The bias vector of the convolution kernel | |
| 8 | The feature vector obtained after each convolution kernel of CTSF executes all steps | |
| 9 | The “length” of , it is numerically equal to n | |
| 10 | The “length” of the max pooling kernel | |
| 11 | The moving step size of the pooling kernel | |
| 12 | The feature vector is obtained by through the maximum pooling layer | |
| 13 | The feature vector obtained after undergoes all convolution operations and pooling operations of CTSF | |
| 14 | The feature vector obtained after passes through the position encoder part of the CTSF | |
| 15 | Represents the vector corresponding to position , containing pairs of sine and cosine for each frequency. | |
| 16 | Represents an integer value that controls the odd and even conditions in . | |
| 17 | frequency | |
| 18 | The function that generates the position vector | |
| 19 | Represents the dimension of each feature deepening | |
| 20 | Numerically equal to the feature dimension of | |
| 21 | , , | Corresponds to the weight matrix of the query matrix, the weight matrix of the key matrix, and the weight matrix of the value matrix |
| 22 | The query vector for the i-th header in the CTSF pre-training part | |
| 23 | The number of heads in the multi-head attention mechanism | |
| 24 | The key vector for the i-th header in the CTSF pre-training section | |
| 25 | The value vector for the i-th header in the CTSF pre-training section | |
| 26 | The output of the self-attention mechanism of the i-th head | |
| 27 | The results obtained by the self-attention mechanism of all heads are combined to obtain | |
| 28 | represent the mean and standard deviation of , respectively | |
| 29 | The vector obtained after passes through the standard layer | |
| 30 | Represents the process of mapping to | |
| 31 | CTSF establishes a residual connection at the multi-head attention mechanism layer, and this value represents the result of the residual connection | |
| 32 | Represents through the mapping process of the fully connected layer and the normalized layer | |
| 33 | CTSF establishes a residual connection in the feedforward fully connected layer, and this value represents the result of the residual connection | |
| 34 | Represents through the mapping process of the fully connected layer | |
| 35 | Represents the result of the original feature vector after sufficient pre-training | |
| 36 | The weight parameter matrix of the feed-forward fully connected layer of the CTSF pre-training part | |
| 37 | The bias value vector of the feed-forward fully connected layer of the CTSF pre-training part | |
| 38 | The weight parameter matrix of the decoder layer of the CTSF pre-training part | |
| 39 | The bias value vector of the decoder layer of the CTSF pre-training part | |
| 40 | Represents the weight parameters of the SVM | |
| 41 | Represents the bias value of the SVM |
| Input: train_data_iterator: It stores all the and the attack types corresponding to that are needed to train the model. |
| Matrix of weight parameters and bias values. |
| num_epochs: Total training epochs. |
| num_batches: The number of batches included in an epoch. |
| train_features: SVM training data (excluding categories), the type is an array. |
| train_labels: Corresponding to train_features, representing the category of training data, the type is also an array. |
| Process: |
| preprocess_data() # Preprocess the dataset. |
| initialize_parameters () # Initialize weight parameters. |
| for epoch in range(num_epochs): |
| total_loss = 0 |
| for batch_data, batch_labels in train_data_iterator: |
| predictions = pretraining_CTSF (batch_data) |
| loss = compute_loss(predictions, batch_labels) |
| total_loss += loss |
| backpropagation(loss) |
| update_parameters() |
| end for |
| average_loss = total_loss/num_batches |
| end for |
| for batch_data, batch_labels in train_data_iterator: |
| batch_features = pretraining_CTSF.extract_features(batch_data) # Obtain data from the pre-training part. |
| train_features.append(batch_features) |
| train_labels.append(batch_labels) |
| end for |
| svm_CTSF (train_features, train_labels) # update and |
| Output: |
| predictions = svm_CTSF.predict(test_features) |
| Model | Batch Size | Optimizer | Epochs | Learning Rate | Gamma | Step_Size | SVM C | SVM Degree |
|---|---|---|---|---|---|---|---|---|
| CTSF | 32 | Adadelta | 500 | 0.01 | 0.65 | 50 | 1 | 3 |
| CNN-Transformer (improved) | 32 | Adadelta | 500 | 0.01 | 0.65 | 50 | NULL | NULL |
| CNN-RNN | 32 | Adadelta | 500 | 0.01 | 0.65 | 50 | NULL | NULL |
| CNN | 32 | Adadelta | 500 | 0.01 | 0.65 | 50 | NULL | NULL |
| RNN | 32 | Adadelta | 500 | 0.01 | 0.65 | 50 | NULL | NULL |
| Total (P + N) | Predicted Condition | ||
|---|---|---|---|
| Postive (PP) | Negative (PN) | ||
| Actual condition | Postive (P) | True positive (TP) | False negative (FN) |
| Negative (N) | False positive (FP) | True negative (TN) | |
| Linear | rbf | Sigmoid | Poly | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PRE | RC | F1 | PRE | RC | F1 | PRE | RC | F1 | PRE | RC | F1 | |
| Normal | 0.951 | 0.968 | 0.959 | 0.950 | 0.970 | 0.960 | 0.848 | 0.822 | 0.835 | 0.913 | 0.942 | 0.927 |
| C and C | 1 | 0.995 | 0.997 | 0.981 | 1 | 0.990 | 0.985 | 0.958 | 0.972 | 0.995 | 1 | 0.997 |
| Exfiltration | 1 | 0.998 | 0.999 | 1 | 0.997 | 0.998 | 0.929 | 0.988 | 0.958 | 0.997 | 0.997 | 0.997 |
| Exploitation | 0.980 | 0.980 | 0.980 | 1 | 0.943 | 0.970 | 0.962 | 0.777 | 0.860 | 0.989 | 0.913 | 0.95 |
| Lateral_movement | 0.996 | 0.991 | 0.993 | 0.994 | 0.994 | 0.994 | 0.882 | 0.891 | 0.887 | 0.989 | 0.994 | 0.991 |
| RDOS | 0.994 | 0.998 | 0.996 | 1 | 0.996 | 0.997 | 0.998 | 1 | 0.999 | 1 | 0.983 | 0.991 |
| Reconnaissance | 0.977 | 0.966 | 0.972 | 0.976 | 0.973 | 0.974 | 0.935 | 0.933 | 0.934 | 0.958 | 0.942 | 0.950 |
| Tampering | 0.992 | 0.994 | 0.993 | 0.994 | 0.994 | 0.994 | 0.952 | 0.948 | 0.950 | 0.994 | 0.997 | 0.995 |
| Weaponization | 0.996 | 0.994 | 0.995 | 0.998 | 1 | 0.999 | 0.986 | 0.972 | 0.979 | 0.989 | 0.996 | 0.992 |
| crypto-ransomware | 0.667 | 1 | 0.800 | 1 | 1 | 1 | 0 | 0 | 0 | 0.5 | 1 | 0.667 |
| macro avg | 0.960 | 0.990 | 0.970 | 0.990 | 0.990 | 0.99 | 0.85 | 0.83 | 0.84 | 0.93 | 0.98 | 0.95 |
| weighted avg | 0.990 | 0.990 | 0.990 | 0.990 | 0.990 | 0.99 | 0.93 | 0.93 | 0.93 | 0.98 | 0.98 | 0.98 |
| Accuracy | 0.98825 | 0.9885 | 0.9365 | 0.97925 | ||||||||
| Training Time(s) | 55,755.99 | 55,753.90 | 55,752.77 | 55,751.52 | ||||||||
| CNN-Transformer (Improved) | CNN-RNN | CNN | RNN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PRE | RC | F1 | PRE | RC | F1 | PRE | RC | F1 | PRE | RC | F1 | |
| Normal | 0.947 | 0.938 | 0.943 | 0.877 | 0.941 | 0.908 | 0.816 | 0.901 | 0.856 | 0.930 | 0.962 | 0.946 |
| C and C | 0.990 | 1 | 0.995 | 0.995 | 0.991 | 0.993 | 0.972 | 1 | 0.986 | 0.987 | 1 | 0.993 |
| Exfiltration | 1 | 1 | 1 | 0.998 | 0.996 | 0.997 | 0.994 | 0.998 | 0.996 | 1 | 1 | 1 |
| Exploitation | 0.964 | 0.987 | 0.976 | 0.962 | 0.793 | 0.870 | 0.915 | 0.606 | 0.729 | 0.962 | 0.906 | 0.934 |
| Lateral_movement | 0.994 | 0.991 | 0.993 | 0.994 | 0.989 | 0.992 | 0.976 | 0.976 | 0.976 | 0.988 | 0.996 | 0.992 |
| RDOS | 1 | 0.997 | 0.998 | 0.995 | 0.991 | 0.993 | 1 | 0.993 | 0.996 | 1 | 0.991 | 0.995 |
| Reconnaissance | 0.959 | 0.964 | 0.962 | 0.935 | 0.924 | 0.929 | 0.920 | 0.824 | 0.869 | 0.969 | 0.944 | 0.957 |
| Tampering | 1 | 0.997 | 0.998 | 0.997 | 0.991 | 0.994 | 0.977 | 0.991 | 0.984 | 1 | 1 | 1 |
| Weaponization | 0.996 | 0.998 | 0.997 | 0.998 | 1 | 0.999 | 0.934 | 0.998 | 0.965 | 1 | 1 | 1 |
| crypto-ransomware | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| macro avg | 0.99 | 0.99 | 0.99 | 0.88 | 0.86 | 0.87 | 0.85 | 0.83 | 0.84 | 0.98 | 0.98 | 0.98 |
| weighted avg | 0.99 | 0.99 | 0.99 | 0.97 | 0.97 | 0.97 | 0.95 | 0.95 | 0.95 | 0.98 | 0.98 | 0.98 |
| Accuracy | 0.9858 | 0.9728 | 0.9475 | 0.9847 | ||||||||
| Training Time(s) | 55,750 | 25,805 | 17,515 | 17,915 | ||||||||
| Model | C and C | Exfiltration | Exploitation | Lateral_Movement | RDOS | Reconnaissance | Tampering | Weaponization | Crypto-Ransomware |
|---|---|---|---|---|---|---|---|---|---|
| DT | 0.8966 | 0.8976 | 0.9852 | 0.9948 | 0.9999 | 0.9922 | 0.9947 | 0.9997 | 0.9986 |
| NB | 1 | 0.9823 | 0.5267 | 0.0834 | 0.9906 | 0.0150 | 0.9912 | 0.9867 | 0.9962 |
| KNN | 0.8096 | 0.7140 | 0.9128 | 0.9862 | 0.9999 | 0.9688 | 0.7868 | 0.9985 | 0.9960 |
| SVM | 0.8194 | 0.8394 | 0.8987 | 0.9983 | 0.9996 | 0.9170 | 0.9891 | 0.9996 | 0.9992 |
| LR | 0.5801 | 0.4634 | 0.7842 | 0.9809 | 0.9983 | 0.8666 | 0.7407 | 0.9907 | 0.9986 |
| DNN | 0.7716 | 0.9991 | 0.8129 | 0.9769 | 0.9996 | 0.9585 | 0.9815 | 0.9994 | 0.8188 |
| GRU | 0.8826 | 0.9993 | 0.8623 | 0.9789 | 0.9998 | 0.9886 | 0.9918 | 0.9997 | 0.9694 |
| CTSF (with rbf) | 1 | 0.997 | 0.943 | 0.994 | 0.996 | 0.973 | 0.994 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, G.; Li, S.; Yang, Y.; Zhou, G.; Wang, Y. CTSF: An Intrusion Detection Framework for Industrial Internet Based on Enhanced Feature Extraction and Decision Optimization Approach. Sensors 2023, 23, 8793. https://doi.org/10.3390/s23218793
Chai G, Li S, Yang Y, Zhou G, Wang Y. CTSF: An Intrusion Detection Framework for Industrial Internet Based on Enhanced Feature Extraction and Decision Optimization Approach. Sensors. 2023; 23(21):8793. https://doi.org/10.3390/s23218793
Chicago/Turabian StyleChai, Guangzhao, Shiming Li, Yu Yang, Guohui Zhou, and Yuhe Wang. 2023. "CTSF: An Intrusion Detection Framework for Industrial Internet Based on Enhanced Feature Extraction and Decision Optimization Approach" Sensors 23, no. 21: 8793. https://doi.org/10.3390/s23218793