
Learnable Leakage and Onset-Spiking Self-Attention in SNNs with Local Error Signals


Abstract
:1. Introduction
- We present the LLC-LIF model with a learnable leakage coefficient, which allows the leakage coefficient of the membrane potential to be a learnable parameter. This design provides automated optimization capabilities, ensuring consistent properties between neurons within the same layer and independent properties across layers.
- To better exploit the temporal sensitivity and efficiency of SNNs, we incorporate the self-attention mechanism at the initial time step of the SNN. By integrating strategies from both neuroscience and deep learning, we further enhance the network’s ability to transform temporal and spatial features.
- To adapt to the unique characteristics of spiking neural networks, we introduce the batch normalization method combined with a learnable leakage coefficient, termed LLC-BN. This method harmonizes the temporal dynamics of SNNs with spike-time encoding and enhances the stability and flexibility of the network through joint optimization.
- To efficiently emulate biological neural networks, we introduce local loss signals within the spiking neural network, allowing certain layers to receive distinct learning feedback independently. Using supervised local learning strategies and auxiliary classifiers, we design a hierarchical loss function that ensures excellent performance of the SNN in various tasks.
2. Related Work
2.1. Basic LIF Neurons in SNNs
2.2. Self-Attention
2.3. Normalization
2.4. Spatiotemporal Backpropagation
3. Materials and Methods
3.1. LIF Model with Learnable Leakage Coefficient (LLC-LIF)
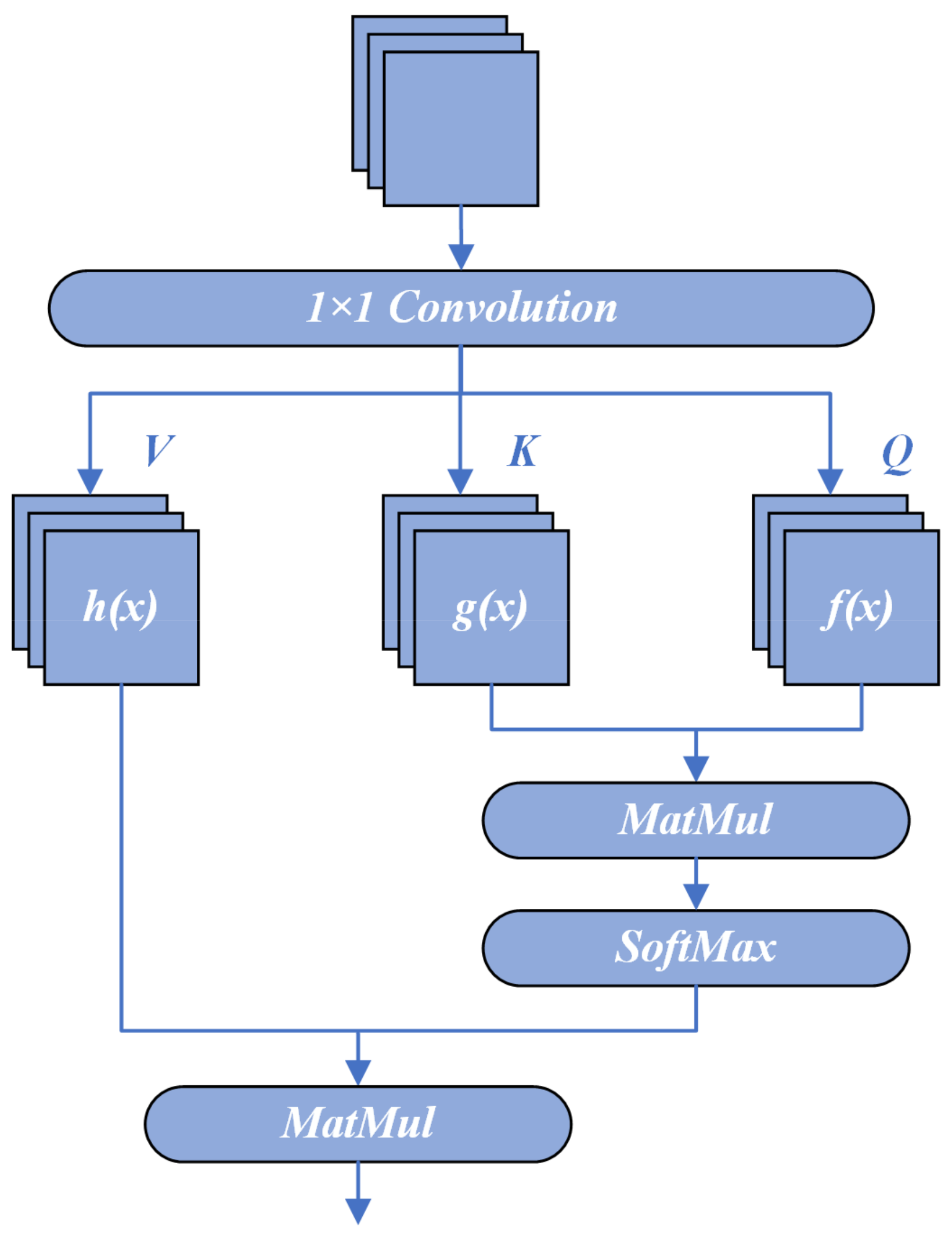
3.2. Onset-Spiking Self-Attention (OSSA)
3.3. Learnable Leakage Coefficient Batch Normalization (LLC-BN)
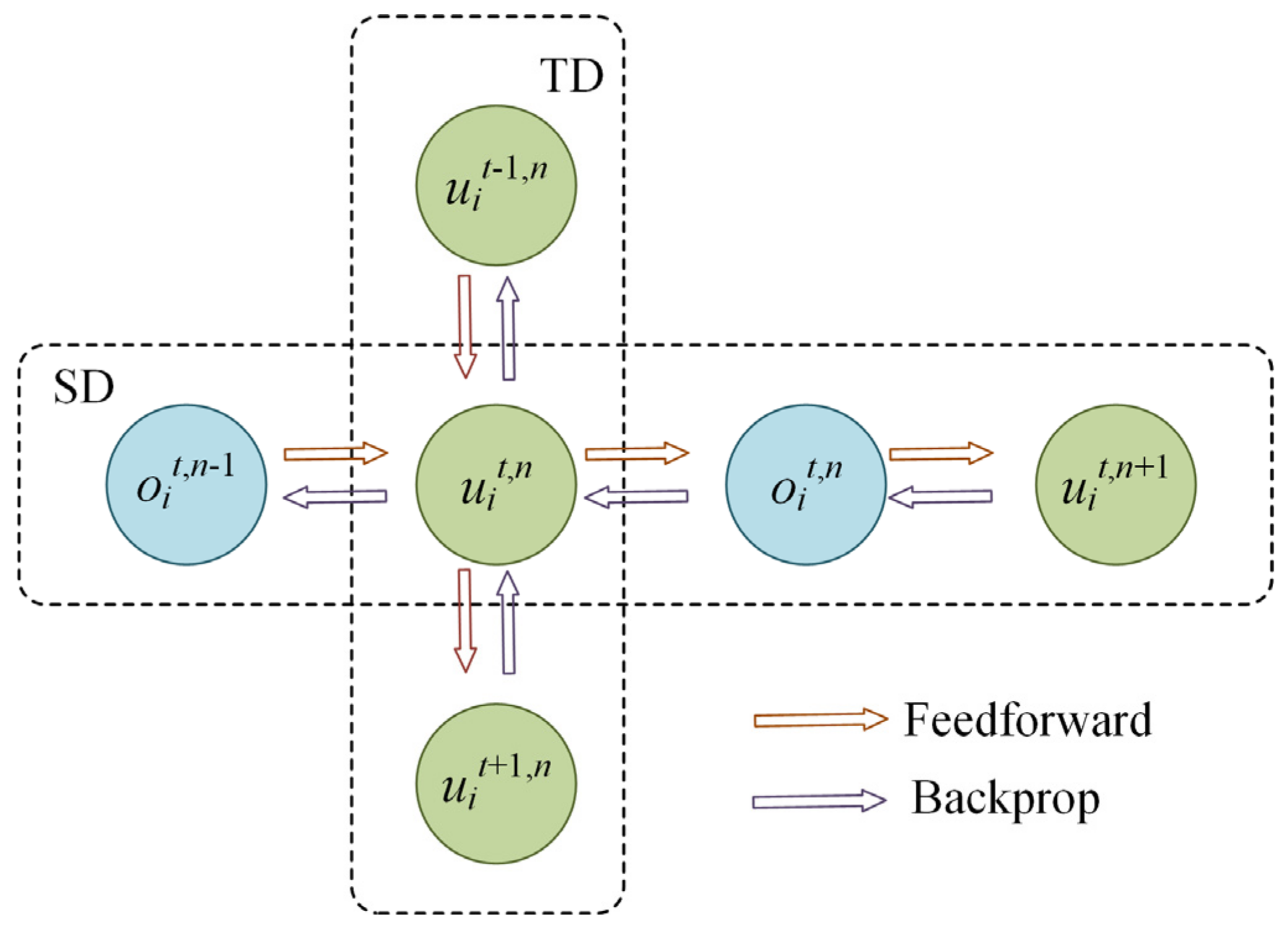
3.4. Spatiotemporal Backpropagation with Local Error Signals
4. Experiments
4.1. Benchmark Datasets
4.2. Network Structure Configuration
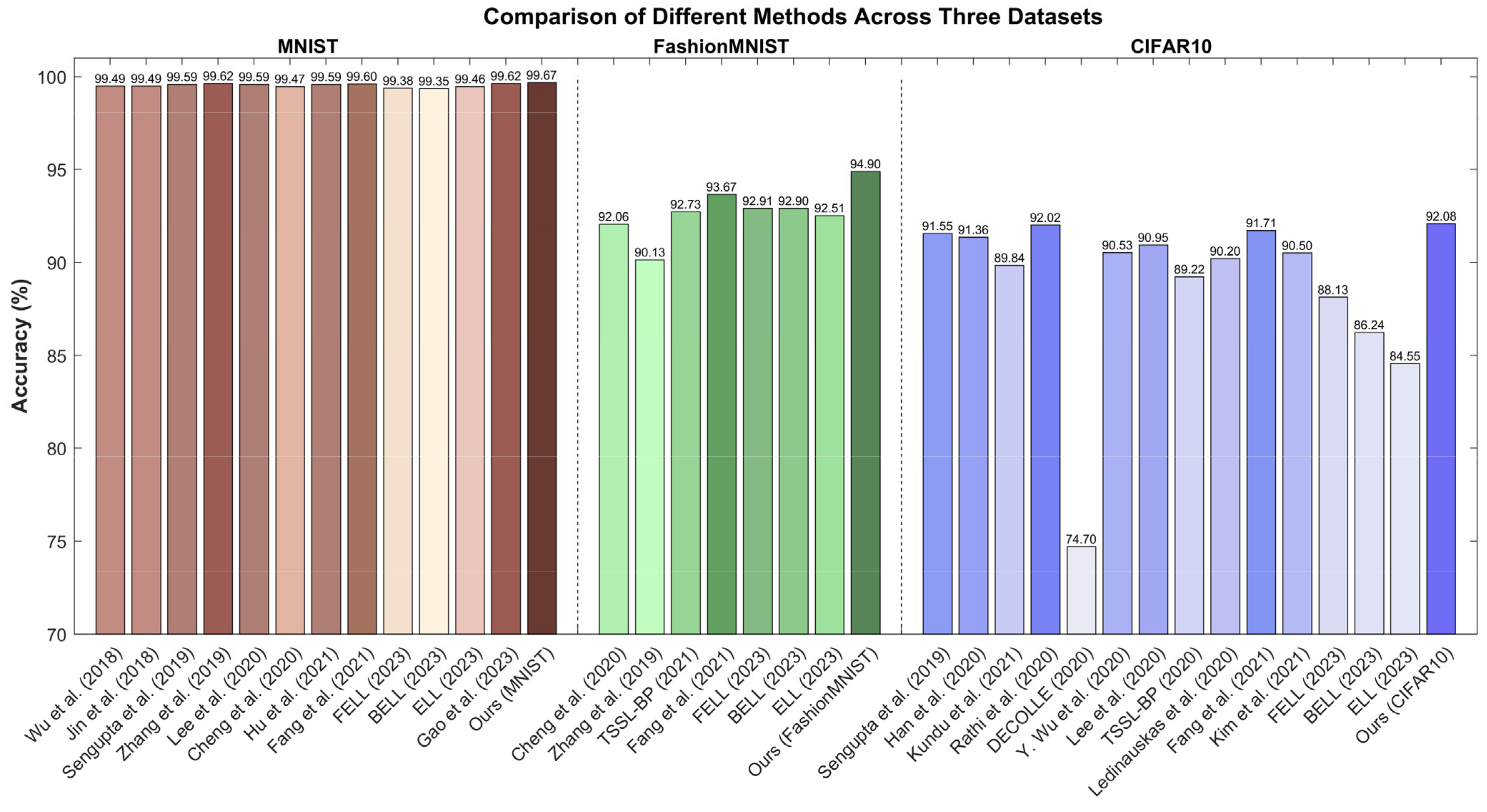
4.3. Work Comparison and Discussion
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Zang, Y.; De Schutter, E. Recent data on the cerebellum require new models and theories. Curr. Opin. Neurobiol. 2023, 82, 102765. [Google Scholar] [CrossRef] [PubMed]
- Wagner, M.J.; Kim, T.H.; Savall, J.; Schnitzer, M.J.; Luo, L. Cerebellar granule cells encode the expectation of reward. Nature 2017, 544, 96–100. [Google Scholar] [CrossRef] [PubMed]
- Spanne, A.; Jörntell, H. Questioning the role of sparse coding in the brain. Trends Neurosci. 2015, 38, 417–427. [Google Scholar] [CrossRef] [PubMed]
- Yamazaki, K.; Vo-Ho, V.-K.; Bulsara, D.; Le, N. Spiking neural networks and their applications: A Review. Brain Sci. 2022, 12, 863. [Google Scholar] [CrossRef] [PubMed]
- Eshraghian, J.K.; Ward, M.; Neftci, E.O.; Wang, X.; Lenz, G.; Dwivedi, G.; Bennamoun, M.; Jeong, D.S.; Lu, W.D. Training spiking neural networks using lessons from deep learning. Proc. IEEE 2023, 111, 1016–1054. [Google Scholar] [CrossRef]
- Demin, V.; Nekhaev, D. Recurrent spiking neural network learning based on a competitive maximization of neuronal activity. Front. Neuroinform. 2018, 12, 79. [Google Scholar] [CrossRef]
- Guo, Y.; Huang, X.; Ma, Z. Direct learning-based deep spiking neural networks: A review. Front. Neurosci. 2023, 17, 1209795. [Google Scholar] [CrossRef]
- Iqbal, B.; Saleem, N.; Iqbal, I.; George, R. Common and Coincidence Fixed-Point Theorems for ℑ-Contractions with Existence Results for Nonlinear Fractional Differential Equations. Fractal Fractional. 2023, 7, 747. [Google Scholar] [CrossRef]
- Bi, G.-Q.; Poo, M.-M. Synaptic modifications in cultured hippocampal neurons: Dependence on spike timing, synaptic strength, and postsynaptic cell type. J. Neurosci. 1998, 18, 10464–10472. [Google Scholar] [CrossRef] [PubMed]
- O’Connor, P.; Neil, D.; Liu, S.-C.; Delbruck, T.; Pfeiffer, M. Real-time classification and sensor fusion with a spiking deep belief network. Front. Neurosci. 2013, 7, 178. [Google Scholar] [CrossRef] [PubMed]
- Hunsberger, E.; Eliasmith, C. Spiking deep networks with LIF neurons. arXiv 2015, arXiv:1510.08829. [Google Scholar]
- Neil, D.; Pfeiffer, M.; Liu, S.C. Phased LSTM: Accelerating recurrent network training for long or event-based sequences. Adv. Neural Inf. Process. Syst. 2016, 29, 3882–3890. [Google Scholar]
- Seth, A.K. Neural coding: Rate and time codes work together. Curr. Biol. 2015, 25, R110–R113. [Google Scholar] [CrossRef] [PubMed]
- Neftci, O.; Mostafa, H.; Zenke, F. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Shrestha, S.B.; Orchard, G. SLAYER: Spike Layer Error Reassignment in Time. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 2–8 December 2018; pp. 1419–1428. [Google Scholar]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-temporal Backpropagation for Training High-performance Spiking Neural Networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef]
- Gu, P.; Xiao, R.; Pan, G.; Tang, H. STCA: Spatio-temporal Credit Assignment with Delayed Feedback in Deep Spiking Neural Networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019; pp. 1366–1372. [Google Scholar]
- Lee, C.; Sarwar, S.S.; Panda, P.; Srinivasan, G.; Roy, K. Enabling Spike-based Backpropagation for Training Deep Neural Network Architectures. Front. Neurosci. 2020, 14, 119. [Google Scholar] [CrossRef]
- Zhang, W.; Li, P. Temporal Spike Sequence Learning via Backpropagation for Deep Spiking Neural Networks. In Proceedings of the International Conference Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 12011–12022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Gidon, A.; Zolnik, T.A.; Fidzinski, P.; Bolduan, F.; Papoutsi, A.; Poirazi, P.; Holtkamp, M.; Vida, I.; Larkum, M.E. Dendritic action potentials and computation in human layer 2/3 cortical neurons. Science 2020, 367, 83–87. [Google Scholar] [CrossRef] [PubMed]
- Larkum, M.E. Are dendrites conceptually useful? Neuroscience 2022, 489, 4–14. [Google Scholar] [CrossRef] [PubMed]
- Lapicque, L.M. Recherches quantitatives sur l’excitation electrique des nerfs. Physiol. Paris 1907, 9, 620–635. [Google Scholar]
- Gerstner, W.; Kistler, W.M.; Naud, R.; Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Fourcaud-Trocmé, N.; Hansel, D.; van Vreeswijk, C.; Brunel, N. How Spike Generation Mechanisms Determine the Neuronal Response to Fluctuating Inputs. J. Neurosci. 2003, 23, 11628–11640. [Google Scholar] [CrossRef] [PubMed]
- Latham, P.E.; Nirenberg, S. Syllable Discrimination for a Population of Auditory Cortical Neurons. J. Neurosci. 2004, 24, 2490–2499. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cheng, J.; Dong, L.; Lapata, M. Long short-term memory-networks for machine reading. arXiv 2016, arXiv:1601.06733. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Parikh, A.; Täckström, O.; Das, D.; Uszkoreit, J. A decomposable attention model for natural language inference. arXiv 2016, arXiv:1606.01933. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. arXiv 2017, arXiv:1705.04304. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Salimans, T.; Kingma, D.P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5–10 December 2016; pp. 901–909. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Direct Training for Spiking Neural Networks: Faster, Larger, Better. arXiv 2018, arXiv:1809.05793. [Google Scholar] [CrossRef]
- Marquez, E.S.; Hare, J.S.; Niranjan, M. Deep Cascade Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5475–5485. [Google Scholar] [CrossRef] [PubMed]
- Mostafa, H.; Ramesh, V.; Cauwenberghs, G. Deep Supervised Learning Using Local Errors. Front. Neurosci. 2018, 12, 608. [Google Scholar] [CrossRef] [PubMed]
- Nøkland, A.; Eidnes, L.H. Training neural networks with local error signals. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4839–4850. [Google Scholar]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500. [Google Scholar] [CrossRef] [PubMed]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Prinz, A.A.; Bucher, D.; Marder, E.M. Similar network activity from disparate circuit parameters. Nat. Neurosci. 2004, 7, 1345–1352. [Google Scholar] [CrossRef]
- Baria, A.T.; Maniscalco, B.; He, B.J. Initial-state-dependent, robust, transient neural dynamics encode conscious visual perception. PLoS Comput. Biol. 2017, 13, e1005806. [Google Scholar] [CrossRef] [PubMed]
- Kaiser, J.; Mostafa, H.; Neftci, E. Synaptic plasticity dynamics for deep continuous local learning (DECOLLE). Front. Neurosci. 2020, 14, 424. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Department of Computer Science, University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Guo, W.; Fouda, M.E.; Eltawil, A.M.; Salama, K.N. Neural coding in spiking neural networks: A comparative study for robust neuromorphic systems. Front. Neurosci. 2021, 15, 638474. [Google Scholar] [CrossRef] [PubMed]
- Fang, W.; Chen, Y.; Ding, J.; Yu, Z.; Masquelier, T.; Chen, D.; Huang, L.; Zhou, H.; Li, G.; Tian, Y. SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence. Sci. Adv. 2023, 9, eadi1480. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jin, Y.; Zhang, W.; Li, P. Hybrid macro/micro level backpropagation for training deep spiking neural networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 7005–7015. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Zhang, W.; Li, P. Spike-train level backpropagation for training deep recurrent spiking neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 1–12. [Google Scholar]
- Cheng, X.; Hao, Y.; Xu, J.; Xu, B. LISNN: Improving spiking neural networks with lateral interactions for robust object recognition. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 11–17 July 2020; pp. 1519–1525. [Google Scholar]
- Hu, Y.; Tang, H.; Pan, G. Spiking deep residual networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 5200–5205. [Google Scholar] [CrossRef]
- Fang, W.; Yu, Z.; Chen, Y.; Masquelier, T.; Huang, T.; Tian, Y. Incorporating learnable membrane time constant to enhance learning of spiking neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2661–2671. [Google Scholar]
- Ma, C.; Yan, R.; Yu, Z.; Yu, Q. Deep spike learning with local classifiers. IEEE Trans. Cybern. 2023, 53, 3363–3375. [Google Scholar] [CrossRef]
- Gao, H.; He, J.; Wang, H.; Wang, T.; Zhong, Z.; Yu, J.; Wang, Y.; Tian, M.; Shi, C. High-accuracy deep ANN-to-SNN conversion using quantization-aware training framework and calcium-gated bipolar leaky integrate and fire neuron. Front. Neurosci. 2023, 17, 1141701. [Google Scholar] [CrossRef]
- Han, B.; Srinivasan, G.; Roy, K. RMP-SNN: Residual membrane potential neuron for enabling deeper high-accuracy and low-latency spiking neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13555–13564. [Google Scholar]
- Kundu, S.; Datta, G.; Pedram, M.; Beerel, P.A. Spike-thrift: Towards energy-efficient deep spiking neural networks by limiting spiking activity via attention-guided compression. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3953–3962. [Google Scholar]
- Rathi, N.; Srinivasan, G.; Panda, P.; Roy, K. Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation. arXiv 2020, arXiv:2005.01807. [Google Scholar]
- Ledinauskas, E.; Ruseckas, J.; Juršėnas, A.; Buračas, G. Training deep spiking neural networks. arXiv 2020, arXiv:2006.04436. [Google Scholar]
- Kim, Y.; Panda, P. Revisiting batch normalization for training low-latency deep spiking neural networks from scratch. Front. Neurosci. 2021, 15, 773954. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Image Size | Categories | Training Samples | Testing Samples |
|---|---|---|---|---|
| MNIST | 28 × 28 | 10 | 50,000 | 10,000 |
| FashionMNIST | 28 × 28 | 10 | 50,000 | 10,000 |
| CIFAR-10 | 32 × 32 | 10 | 50,000 | 10,000 |
| Method | Architecture | Time Steps | Accuracy (%) |
|---|---|---|---|
| Wu et al. (2018) [19] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 99.49 |
| Jin et al. (2018) [57] | 15c5-p2-40c5-p2-300-10 | 400 | 99.49 |
| Sengupta et al. (2019) [58] | LeNet-5 | 2500 | 99.59 |
| Zhang et al. (2019) [59] | 784-400-400r-10 (r represent recurrent layer) | 400 | 99.62 |
| Lee et al. (2020) [21] | LeNet | 100 | 99.59 |
| Cheng et al. (2020) [60] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 99.47 |
| Hu et al. (2021) [61] | ResNet-8 | 350 | 99.59 |
| Fang et al. (2021) [62] | 128c3-p2-128c3-p2-2048-100-10 | 8 | 99.60 |
| FELL (2023) [63] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 99.38 |
| BELL (2023) [63] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 99.35 |
| ELL (2023) [63] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 99.46 |
| Gao et al. (2023) [64] | VGG-9 | 128 | 99.62 |
| Ours | 128c3-p2-128c3-p2-2048-100-10 | 8 | 99.67 |
| Method | Architecture | Time Steps | Accuracy (%) |
|---|---|---|---|
| Cheng et al. (2020) [60] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 92.06 |
| Zhang et al. (2019) [59] | 784-400-400r-10 | 400 | 90.13 |
| TSSL-BP (2021) [22] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 92.73 |
| Fang et al. (2021) [62] | 128c3-p2-128c3-p2-2048-100-10 | 8 | 93.67 |
| FELL (2023) [63] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 92.91 |
| BELL (2023) [63] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 92.90 |
| ELL (2023) [63] | 128c3-p2-128c3-p2-2048-100-10 | 10 | 92.51 |
| Ours | 128c3-p2-128c3-p2-2048-100-10 | 8 | 94.90 |
| Method | Architecture | Time Steps | Accuracy (%) |
|---|---|---|---|
| Sengupta et al. (2019) [58] | VGG-16 | 2500 | 91.55 |
| Han et al. (2020) [65] | ResNet-20 | 2048 | 91.36 |
| Kundu et al. (2021) [66] | VGG-11 | 100 | 89.84 |
| Rathi et al. (2020) [67] | VGG-16 | 200 | 92.02 |
| DECOLLE (2020) [47] | VGG-9 | 10 | 74.70 |
| Y. Wu et al. (2020) [39] | VGG-8 | 12 | 90.53 |
| Lee et al. (2020) [21] | ResNet-11 | 100 | 90.95 |
| TSSL-BP (2020) [22] | AlexNet | 5 | 89.22 |
| Ledinauskas et al. (2020) [68] | ResNet-11 | 20 | 90.20 |
| Fang et al. (2021) [62] | 256c3-256c3-256c3-p2-256c3-256c3-256c3-p2-2048-100-10 | 8 | 91.71 |
| Kim et al. (2021) [69] | VGG-9 | 25 | 90.50 |
| FELL (2023) [63] | 256c3-256c3-256c3-p2-256c3-256c3-256c3-p2-2048-100-10 | 10 | 88.13 |
| BELL (2023) [63] | 256c3-256c3-256c3-p2-256c3-256c3-256c3-p2-2048-100-10 | 10 | 86.24 |
| ELL (2023) [63] | 256c3-256c3-256c3-p2-256c3-256c3-256c3-p2-2048-100-10 | 10 | 84.55 |
| Ours | 256c3-256c3-256c3-p2-256c3-256c3-256c3-p2-2048-100-10 | 8 | 92.08 |
| LLC-LIF | Local Error Signal | LLC-BN | OSSA | Accuracy (%) |
|---|---|---|---|---|
| √ | √ | √ | √ | 94.90 |
| × | √ | √ | √ | 94.58 |
| √ | × | √ | √ | 94.68 |
| √ | √ | × | √ | 94.85 |
| √ | √ | √ | × | 94.87 |
| √ | √ | × | × | 94.72 |
| √ | × | × | × | 94.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Wang, L.; Gao, H.; Tian, M. Learnable Leakage and Onset-Spiking Self-Attention in SNNs with Local Error Signals. Sensors 2023, 23, 9781. https://doi.org/10.3390/s23249781
Shi C, Wang L, Gao H, Tian M. Learnable Leakage and Onset-Spiking Self-Attention in SNNs with Local Error Signals. Sensors. 2023; 23(24):9781. https://doi.org/10.3390/s23249781
Chicago/Turabian StyleShi, Cong, Li Wang, Haoran Gao, and Min Tian. 2023. "Learnable Leakage and Onset-Spiking Self-Attention in SNNs with Local Error Signals" Sensors 23, no. 24: 9781. https://doi.org/10.3390/s23249781
APA StyleShi, C., Wang, L., Gao, H., & Tian, M. (2023). Learnable Leakage and Onset-Spiking Self-Attention in SNNs with Local Error Signals. Sensors, 23(24), 9781. https://doi.org/10.3390/s23249781