

Insights into Batch Selection for Event-Camera Motion Estimation


Abstract
1. Introduction
1.1. Related Work
2. Materials and Methods
2.1. Rotation Estimation Network
2.2. Batch Selection
- 1.
- Number of events;
- 2.
- Temporal period; and
- 3.
- Camera rotation.
2.2.1. Fixed Number of Events (WinT)
2.2.2. Fixed Temporal Period (NK)
2.2.3. Fixed Camera Rotation: Local
2.2.4. Fixed Camera Rotation: Recursive
2.2.5. Fixed Camera Rotation: Trained Network (Net)
2.2.6. Fixed Camera Rotation: Ground-Truth
3. Results
3.1. Datasets
3.2. Training
3.3. Batch Selection Parameters
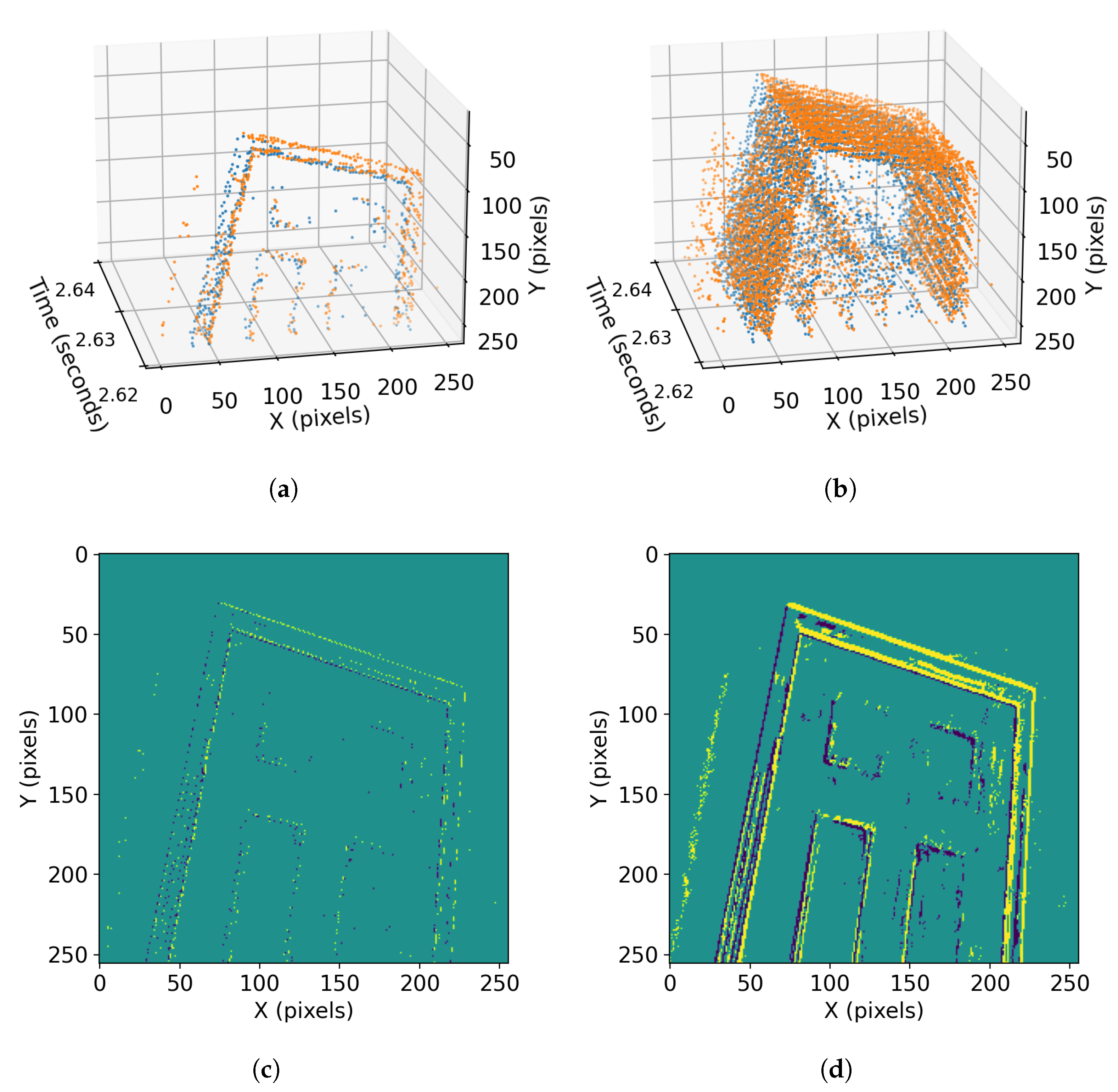
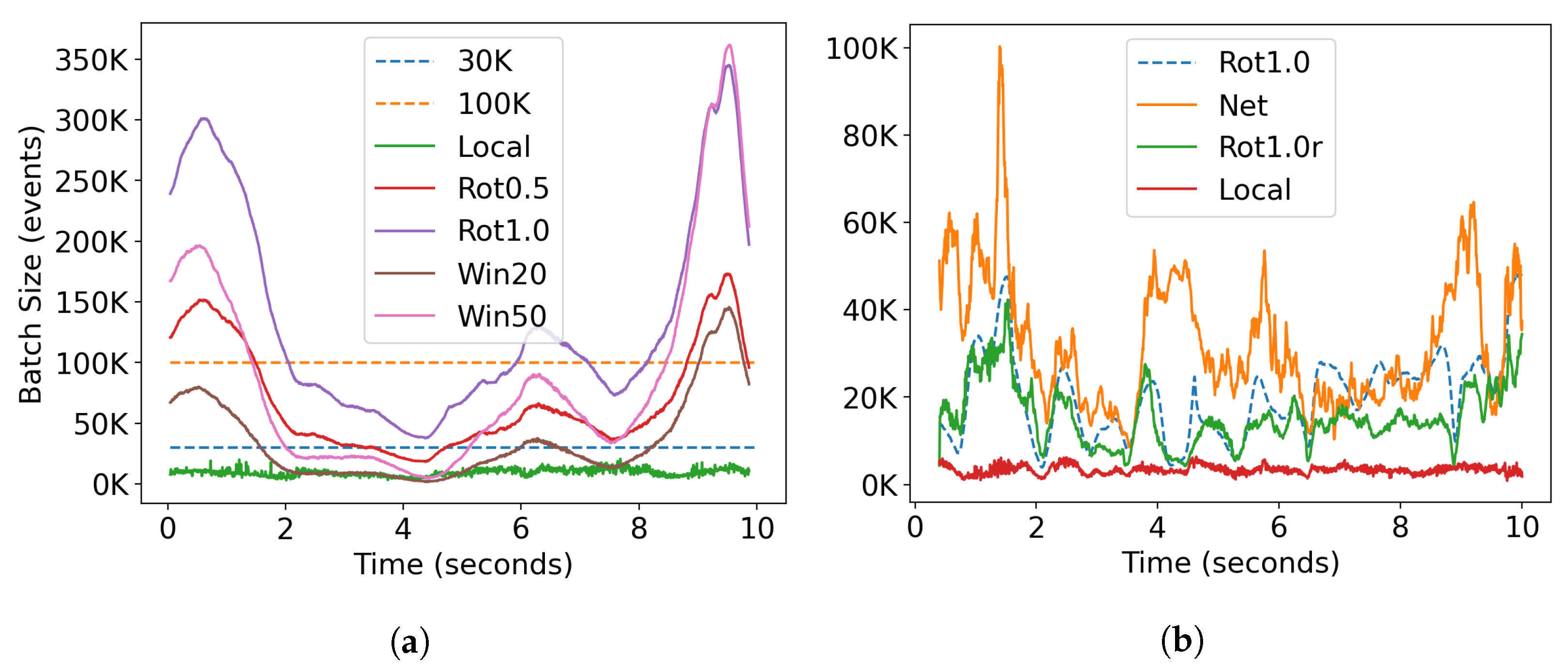
3.4. Batch Size Analysis
3.5. Camera Rotation Estimation
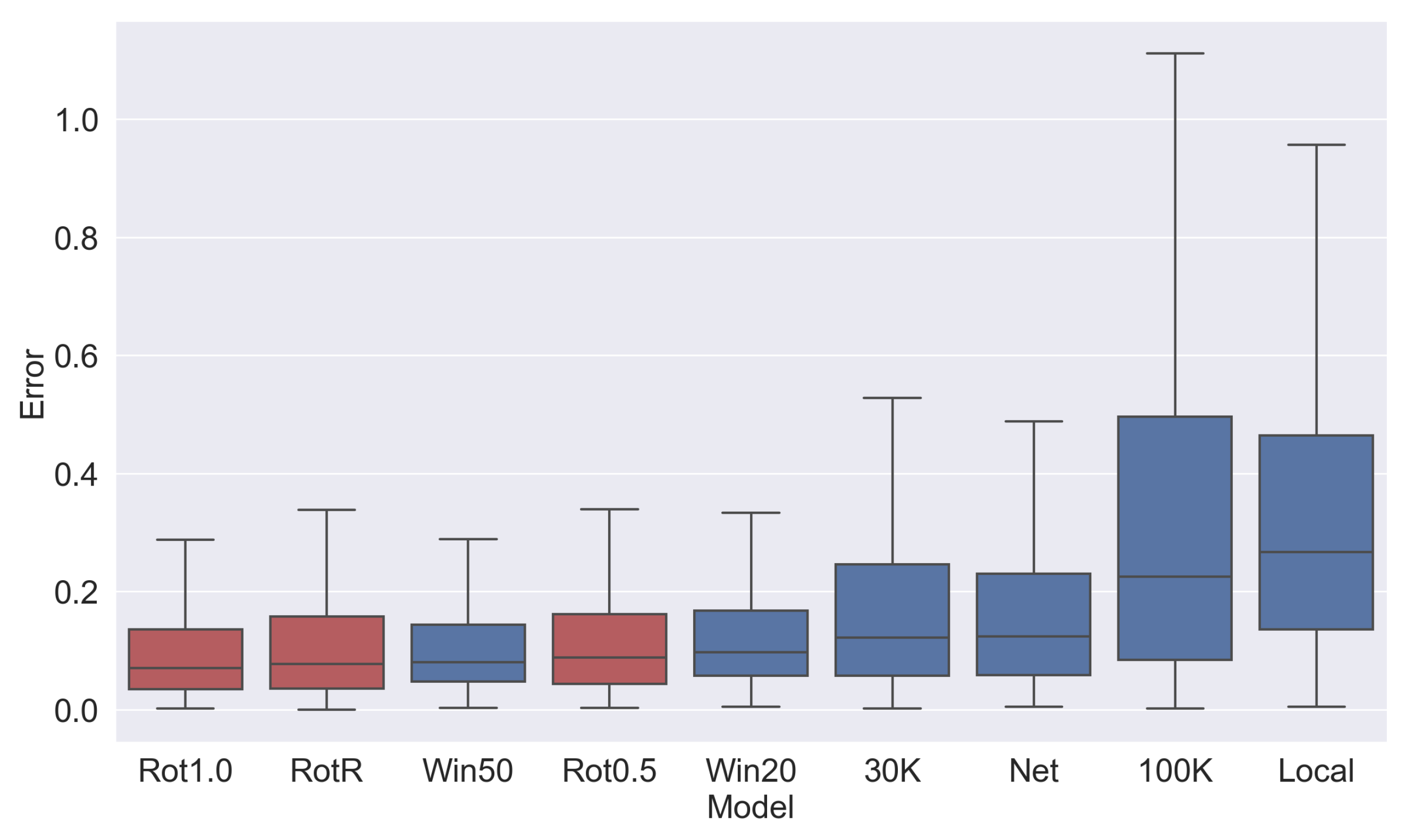
3.5.1. Identical Batch Method for Training and Inference
- Fixed-time networks vastly outperform fixed-count networks.
- The selection network (Net) did not match the performance of fixed rotations, indicating the batching methods are highly sensitive to the precision of the estimator.
- The local window shows the highest average error, which indicates that the algorithm itself did not achieve the desired result of measuring a consistent amount of rotation.
3.5.2. Robustness of the Trained Models (Comparing Figure 10 Columns)
3.5.3. Suitability of Batch Methods for Inference (Comparing Figure 10 Rows)
4. Discussion
4.1. Training with a Large Variety of Batch Sizes Is Important for Model Generalization
4.2. A Minimum Amount of Rotation Is not Necessary for Deep-Learning Techniques
4.3. Inference Choice
4.4. Local Windows
5. Conclusions
- Network training should be performed with the widest variety of batch sizes and velocities to produce a well-generalized network.
- The fixed-time batch is recommended for inference; the exact size of which should depend on the application and typical velocity profiles of the camera. We believe this conclusion may serve as the baseline for any other task that measures velocity or optical flow, but may not be able to be extrapolated to tasks that measure absolute position, for example, object recognition.
- Networks for measuring pose change or velocity possibly have an advantage over contrast maximization techniques for measuring small velocities with a small batch.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Patrick, L.; Posch, C.; Delbruck, T. A 128x 128 120 db 15 μs latency asynchronous temporal contrast vision sensor. IEEE J. Solid-State Circuits 2008, 43, 566–576. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 340–349. [Google Scholar]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: Deep Iterative Matching for 6D Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2043–2050. [Google Scholar] [CrossRef]
- Rebecq, H.; Horstschaefer, T.; Gallego, G.; Scaramuzza, D. EVO: A Geometric Approach to Event-Based 6-DOF Parallel Tracking and Mapping in Real Time. IEEE Robot. Autom. Lett. 2017, 2, 593–600. [Google Scholar] [CrossRef]
- Glover, A.; Bartolozzi, C. Robust visual tracking with a freely-moving event camera. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3769–3776. [Google Scholar] [CrossRef]
- Chen, G.; Liu, P.; Liu, Z.; Tang, H.; Hong, L.; Dong, J.; Conradt, J.; Knoll, A. NeuroAED: Towards Efficient Abnormal Event Detection in Visual Surveillance With Neuromorphic Vision Sensor. IEEE Trans. Inf. Forensics Secur. 2021, 16, 923–936. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; Volume 81. [Google Scholar]
- Portz, T.; Zhang, L.; Jiang, H. Optical flow in the presence of spatially-varying motion blur. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1752–1759. [Google Scholar]
- Gallego, G.; Lund, J.E.; Mueggler, E.; Rebecq, H.; Delbruck, T.; Scaramuzza, D. Event-Based, 6-DOF Camera Tracking from Photometric Depth Maps. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2402–2412. [Google Scholar] [CrossRef] [PubMed]
- Vidal, A.R.; Rebecq, H.; Horstschaefer, T.; Scaramuzza, D. Ultimate SLAM? Combining Events, Images, and IMU for Robust Visual SLAM in HDR and High-Speed Scenarios. IEEE Robot. Autom. Lett. 2018, 3, 994–1001. [Google Scholar] [CrossRef]
- Gallego, G.; Rebecq, H.; Scaramuzza, D. A unifying contrast maximization framework for event cameras, with applications to motion, depth, and optical flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3867–3876. [Google Scholar]
- Gallego, G.; Scaramuzza, D. Accurate angular velocity estimation with an event camera. IEEE Robot. Autom. Lett. 2017, 2, 632–639. [Google Scholar] [CrossRef]
- Kim, H.; Kim, H.J. Real-time rotational motion estimation with contrast maximization over globally aligned events. IEEE Robot. Autom. Lett. 2021, 6, 6016–6023. [Google Scholar] [CrossRef]
- Peng, X.; Gao, L.; Wang, Y.; Kneip, L. Globally-Optimal Contrast Maximisation for Event Cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3479–3495. [Google Scholar] [CrossRef] [PubMed]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 989–997. [Google Scholar]
- Ye, C.; Mitrokhin, A.; Fermüller, C.; Yorke, J.A.; Aloimonos, Y. Unsupervised Learning of Dense Optical Flow, Depth and Egomotion with Event-Based Sensors. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5831–5838. [Google Scholar]
- Henri Rebecq, T.H.; Scaramuzza, D. Real-time Visual-Inertial Odometry for Event Cameras using Keyframe-based Nonlinear Optimization. In Proceedings of the British Machine Vision Conference (BMVC), London, UK; Tae-Kyun, K., Stefanos Zafeiriou, G.B., Mikolajczyk, K., Eds.; BMVA Press: Durham, UK, 2017; pp. 16.1–16.12. [Google Scholar] [CrossRef]
- Kazerouni, I.A.; Fitzgerald, L.; Dooly, G.; Toal, D. A Survey of State-of-the-Art on Visual SLAM. Expert Syst. Appl. 2022, 205, 117734. [Google Scholar] [CrossRef]
- Wagner, D.; Mulloni, A.; Langlotz, T.; Schmalstieg, D. Real-time panoramic mapping and tracking on mobile phones. In Proceedings of the 2010 IEEE Virtual Reality Conference (VR), Boston, MA, USA, 20–24 March 2010; pp. 211–218. [Google Scholar] [CrossRef]
- Scaramuzza, D.; Fraundorfer, F. Visual Odometry [Tutorial]. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Chng, C.K.; Parra, A.; Chin, T.J.; Latif, Y. Monocular Rotational Odometry with Incremental Rotation Averaging and Loop Closure. In Proceedings of the 2020 Digital Image Computing: Techniques and Applications (DICTA), Melbourne, Australia, 9 November–2 December 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar] [CrossRef]
- Xu, J.; Jiang, M.; Yu, L.; Yang, W.; Wang, W. Robust motion compensation for event cameras with smooth constraint. IEEE Trans. Comput. Imaging 2020, 6, 604–614. [Google Scholar] [CrossRef]
- Zihao Zhu, A.; Atanasov, N.; Daniilidis, K. Event-based visual inertial odometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5391–5399. [Google Scholar]
- Liu, D.; Parra, A.; Chin, T.J. Globally optimal contrast maximisation for event-based motion estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6349–6358. [Google Scholar]
- Gallego, G.; Gehrig, M.; Scaramuzza, D. Focus is all you need: Loss functions for event-based vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12280–12289. [Google Scholar]
- Gehrig, D.; Rüegg, M.; Gehrig, M.; Hidalgo-Carrió, J.; Scaramuzza, D. Combining Events and Frames Using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction. IEEE Robot. Autom. Lett. 2021, 6, 2822–2829. [Google Scholar] [CrossRef]
- Hidalgo-Carrió, J.; Gehrig, D.; Scaramuzza, D. Learning monocular dense depth from events. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 534–542. [Google Scholar]
- Mostafavi, M.; Yoon, K.J.; Choi, J. Event-Intensity Stereo: Estimating Depth by the Best of Both Worlds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4258–4267. [Google Scholar]
- Stoffregen, T.; Gallego, G.; Drummond, T.; Kleeman, L.; Scaramuzza, D. Event-based motion segmentation by motion compensation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7244–7253. [Google Scholar]
- Zhu, A.Z.; Yuan, L.; Chaney, K.; Daniilidis, K. EV-FlowNet: Self-supervised optical flow estimation for event-based cameras. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Alonso, I.; Murillo, A.C. EV-SegNet: Semantic segmentation for event-based cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Deng, Y.; Chen, H.; Chen, H.; Li, Y. Learning From Images: A Distillation Learning Framework for Event Cameras. IEEE Trans. Image Process. 2021, 30, 4919–4931. [Google Scholar] [CrossRef] [PubMed]
- Pan, L.; Liu, M.; Hartley, R. Single image optical flow estimation with an event camera. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1669–1678. [Google Scholar]
- Stoffregen, T.; Kleeman, L. Event cameras, contrast maximization and reward functions: An analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12300–12308. [Google Scholar]
- Qiu, W.; Zhong, F.; Zhang, Y.; Qiao, S.; Xiao, Z.; Kim, T.S.; Wang, Y.; Yuille, A. UnrealCV: Virtual Worlds for Computer Vision. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1221–1224. [Google Scholar] [CrossRef]
- Rebecq, H.; Gehrig, D.; Scaramuzza, D. ESIM: An Open Event Camera Simulator. Conf. Robot. Learn. (CoRL) 2018, 87, 969–982. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Selection Method | Application | Parameter | Name |
|---|---|---|---|
| Fixed rotation | Train-only | Rot0.5 | |
| Fixed rotation | Train-only | Rot1.0 | |
| Random rotation | Train-only | – | RotR |
| Fixed count | Train/infer | 30,000 | 30K |
| Fixed count | Train/infer | 100,000 | 100K |
| Fixed time | Train/infer | 20 ms | Win20 |
| Fixed time | Train/infer | 50 ms | Win50 |
| Selection network | Train/infer | target | Net |
| Local estimation | Train/infer | - patches | Local |
| Recursive | Infer-only | (trained Rot1.0) | Rot1.0 |
| Recursive | Infer-only | (trained RotR) | RotR |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valerdi, J.L.; Bartolozzi, C.; Glover, A. Insights into Batch Selection for Event-Camera Motion Estimation. Sensors 2023, 23, 3699. https://doi.org/10.3390/s23073699
Valerdi JL, Bartolozzi C, Glover A. Insights into Batch Selection for Event-Camera Motion Estimation. Sensors. 2023; 23(7):3699. https://doi.org/10.3390/s23073699
Chicago/Turabian StyleValerdi, Juan L., Chiara Bartolozzi, and Arren Glover. 2023. "Insights into Batch Selection for Event-Camera Motion Estimation" Sensors 23, no. 7: 3699. https://doi.org/10.3390/s23073699
APA StyleValerdi, J. L., Bartolozzi, C., & Glover, A. (2023). Insights into Batch Selection for Event-Camera Motion Estimation. Sensors, 23(7), 3699. https://doi.org/10.3390/s23073699