Abstract
A vehicle detection algorithm is an indispensable component of intelligent traffic management and control systems, influencing the efficiency and functionality of the system. In this paper, we propose a lightweight improvement method for the YOLOv5 algorithm based on integrated perceptual attention, with few parameters and high detection accuracy. First, we propose a lightweight module IPA with a Transformer encoder based on integrated perceptual attention, which leads to a reduction in the number of parameters while capturing global dependencies for richer contextual information. Second, we propose a lightweight and efficient multiscale spatial channel reconstruction (MSCCR) module that does not increase parameter and computational complexity and facilitates representative feature learning. Finally, we incorporate the IPA module and the MSCCR module into the YOLOv5s backbone network to reduce model parameters and improve accuracy. The test results show that, compared with the original model, the model parameters decrease by about 9%, the average accuracy (mAP@50) increases by 3.1%, and the FLOPS does not increase.
1. Introduction
Although cars have brought us great convenience, problems such as traffic congestion and traffic accidents have become increasingly serious as the number of vehicles continues to increase. Intelligent traffic management and control systems can effectively solve the above problems [,,]. Vehicle detection algorithms are an important part of intelligent traffic management and working systems. Therefore, vehicle detection algorithms have attracted much attention and become a popular research direction in the field of computer vision.
The traffic environment is complex and varied, including complex backgrounds, diverse vehicles, and changing traffic flows and road conditions. This complexity increases the difficulty of traffic target recognition, which needs to cope with variable scenarios, differences in vehicle shapes, and occlusion situations, as well as real-time availability. Therefore, a good vehicle detection algorithm is essential. At present, the YOLO series is one of the most excellent algorithms in single-stage detection; it has the characteristics of a smaller parameter count, high detection accuracy, and high speed. Therefore, it is widely used in vehicle inspection. Some researchers have chosen to use the original YOLO algorithm [,] for vehicle target detection tasks, which achieves a higher detection accuracy but also incurs high computational costs. Although the YOLOtiny model has relatively small parameters and computational complexity, it has a low detection accuracy and cannot detect vehicles effectively. In [], the model’s ability to capture information about small objects was enhanced by introducing a new feature fusion layer and subsequent attention mechanism into YOLOv5, which improved the accuracy of the target detection. However, improving the model structure made it more complex and did not reduce the number of parameters. In [], they incorporated the small object detection header into YOLOv5 and used a Transformer encoder block instead of some convolutional and CSP blocks to enhance the model’s ability to capture global and contextual information, which significantly improved the model’s performance but increased the model’s computational complexity (FLOPS) by 18.3% compared to the original model. There are also research algorithms [,] that utilise lightweight networks such as MobileNet or EfficientNet instead of YOLO’s entire backbone network. This approach significantly reduces the algorithmic parameters; however, their accuracy is significantly lower compared to the original algorithm.
Despite the importance of the above improved vehicle detection algorithm based on YOLOv5, there are still some problems. The Transformer encoder has multiple layers of self-attentive coding with powerful long-range dependency modelling capabilities. Incorporating it into YOLOv5 can significantly improve the algorithm’s performance. However, due to the stacking of the coding layers and the self-attentive computation, an increase in computational cost comes with embedding it into the model. The backbone network of YOLOv5, which is utilised instead of a lightweight network, is a very effective method for reducing the model parameters. However, lightweight networks are simple in structure and relatively weak in feature extraction. When confronted with some complex scenes, they may have difficulty capturing the detailed features in the scene.
In order to solve these problems, we propose an improved method based on integrated perceptual attention for YOLOv5. The main contributions of this paper are as follows:
- A lightweight module (IPA) with a Transformer encoder is proposed, which uses a parallel two-branch structure, where one branch uses efficient attention to capture global information, while the other branch uses convolutional attention to capture local information. The two-branch structure allows the model to better capture global and local information and obtain richer contextual information.
- A lightweight and efficient multiscale spatial channel reconstruction (MSCCR) module is proposed, which consists of only one efficient convolution and one ordinary attention, without excessive computational redundancy and parametric quantities. And an efficient module was designed by combining the multiscale spatial channel reconstruction (MSCCR) module with the C3 structure in YOLOv5. It is named the C3_MR module.
- The integration of the IPA module and C3_MR module into the YOLOv5s backbone network. Compared to the original model, the mAP@50 increases by 3.1% and the parameters decrease by about 9% with no increase in FLOPS.
2. Related Work
2.1. Vehicle Detection
Vehicle detection methods can usually be classified into two main categories: traditional methods and deep learning-based methods.
In traditional vehicle detection methods, manually designed features such as Scale Invariant Feature Transform (SIFT), Haar features [], and the Histogram of Oriented Gradients (HOG) [] are usually utilised to identify vehicles. These methods rely on manually designed rules to extract features and then use shallow machine learning models to perform vehicle detection tasks []. In [], a new technique for vehicle detection in traffic scenes was proposed, which is based on frame differencing and a colour analysis of the foreground region (moving region). By using different colour channels and segmenting them according to the vehicle colour threshold in the image background, cars can be effectively distinguished from their surroundings. In [], a symmetry-based vehicle detection method was proposed that exploits the symmetry feature of the vertical centreline at the rear of the vehicle. They achieve this by finding regions of interest (ROIs) that contain vehicles, in images with a high level of symmetry. In [], a vision system for brake light detection during the daytime, using a travelling video recorder, was proposed. The operation of the system can be divided into two key steps. First, it uses symmetry verification of the tail lights to determine the presence of a vehicle in front of it. Then, once the position of the vehicle is confirmed, it combines luminance and radial symmetry features to detect the state of the brake lights. In [], an algorithm was proposed to address an innovative technical challenge in visual analytics. The technique employs Hue, Saturation, and Lightness (HSV) colour segmentation combined with support vector machines (SVM) in order to detect moving emergency vehicles in traffic surveillance cameras. However, the above methods usually require the manual selection of features and the design and training of classifiers based on specific detection targets. The manual selection of features and classifier design require a high level of manual processing. Moreover, the maximum processing speed of vehicle detection by traditional methods does not exceed 40 FPS []. Therefore, it is not suitable for roads with fast travelling speeds.
With the continuous development of deep learning, traditional methods are gradually being replaced by deep learning-based target detection methods. These methods are divided into two main types. One is two-stage object detection algorithms such as R-CNN [], Fast R-CNN [], Faster R-CNN [], and Mask R-CNN []. Suggested regions are first selected using a selective search algorithm and then categorised and regressed in the suggested regions. The other is one-stage target detection algorithms, such as SSD [] and YOLO [], which reduce the target detection task to a regression problem by eliminating the generation of suggestion regions and directly predicting the classes and locations of different objects. A two-stage detection algorithm is more accurate compared to a one-stage algorithm, but the model structure is more complex and the model parameters are much higher than the one-stage algorithm. Therefore, vehicle detection algorithms are generally dominated by single-stage target detection algorithms.
2.2. YOLOv5
The YOLO (You-Only-Look-Once) algorithm is the first single-stage detector capable of processing an image in one go and directly predicting the bounding boxes and categories of the objects in the figure. The YOLOv1 is fast but not very effective for objects that are close together and on small targets. The YOLOv2 algorithm adds an anchor mechanism, uses multiscale training, a fusion of shallow features and deep features, adds fine-grained features, and improves the problem of the poor detection of small targets. YOLOv3 further improves its performance by introducing a deeper feature extraction network (Darknet-53) to extract higher-level features []. YOLOv4 uses CSPDarknet53 as its backbone network and introduces a series of optimisations and innovations that reduce the number of parameters and FLOPS values of the model, ensuring accuracy while reducing the model’s size [,]. YOLOv5 has been optimised from YOLOv4; it uses a smaller model size and maintains excellent performance [,].
Depending on the depth of the model and the width of the feature map, YOLOv5 can be divided into four models: the YOLOv5s, the YOLOv5m, the YOLOv5l, and the YOLOv5x. These model sizes are shown in Table 1. From the table, it can be seen that the number of YOLOv5s parameters and the FLOPS are the smallest in these models. In this paper, we propose an approach aimed at achieving a lightweight design for the model, i.e., minimising the number of model parameters without increasing the computational complexity of the model. Therefore, the YOLOv5s is chosen as the benchmark model in this paper. The YOLOv5s network structure is shown in Figure 1, and the YOLOv5 family of models uses a consistent network structure. They consist of the following components: input, backbone, neck, and output.

Table 1.
Comparison of different model sizes of YOLOv5.
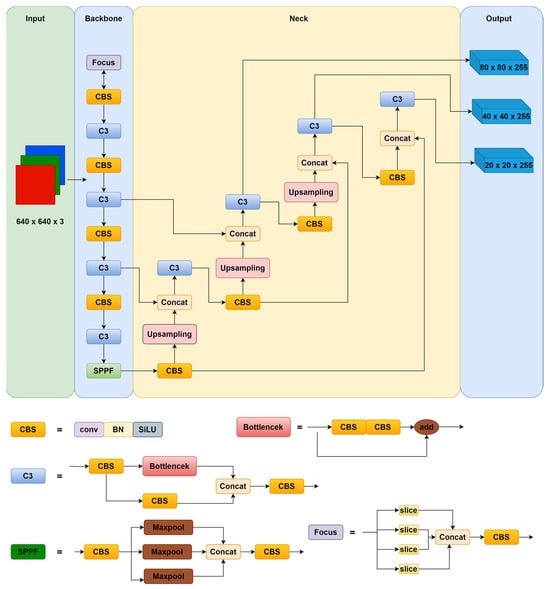
Figure 1.
YOLOv5s network structure.
The inputs include mosaic data enhancement, image size processing, and adaptive anchor frame calculation. The mosaic data enhancement enriches the background of a dataset by randomly selecting four images and randomly stitching, stacking, and scaling them. Image size processing adaptively adds a minimum black border to the images, resizing them to the same standard size. The adaptive anchor frame calculation outputs the bounding box based on the initial anchor frame, and then compares it with the real frame, calculates the gap, and then updates it in reverse, continually iterating the parameters to adaptively calculate the most suitable anchor frame value.
The backbone network consists of the Focus module, the CBS module, the C3 module, and the spatial pyramid pooling layer (SPFF) module. The Focus module divides the input data into four chunks, each of which corresponds to two downsamples. These four pieces of data are merged together in the channel dimension and then subjected to a convolution operation to produce a downsampled feature map without a loss of information. The CBS module consists of three parts: a convolutional layer, a batch normalisation layer, and an activation function, Silu. The C3 module consists of several bottleneck residual structure modules and three CBS modules. The bottleneck residual structure module processes the input through two convolutional layers and then performs an additive operation with the original input while passing residual features without increasing the depth of the output. The SPPF module is a spatial pyramid pooling layer [], which is proposed on the basis of the SPP module to expand the sensory field, fuse local and global features, and enrich feature information [].
The neck uses a combination of the Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) [], which help to enhance feature fusion. The FPN is responsible for passing top feature maps with strong semantic features to bottom feature maps, while PAN passes strong localisation features from bottom feature maps to top feature maps.
The output consists of three detection layers, using the Generalized Intersection over Union (GIOU) as the loss function of the bounding box and NonMaximum Suppression (NMS) [], which employs a multiscale detection approach to detect objects of different sizes. Each output layer outputs corresponding vectors containing object category probabilities, object scores, and bounding box locations, and finally obtains the predicted borders and categories of the target objects and labels them on the original image.
2.3. Attention Mechanism
The method of focusing attention on the critical areas of an image and ignoring the unimportant parts is known as the attentional mechanism. The attentional mechanism is similar to that of the human visual system, through which the object detection model is able to determine which objects in the image are important and obtain their locations []. The attentional mechanism can be viewed as an adaptive weighting process that adjusts the feature weights according to the importance of the inputs. Attentional mechanisms have played an important role in image classification [,], object detection [,], face recognition [,], semantic segmentation [,], and other fields.
Some classical attentions include SE attention, CBAM attention, and CA attention []. The SE attention module is the first channel attention proposed by Momenta, which has at its core a squeeze module and an excitation module. Global information is collected through the squeeze module, channel relationships are captured using the excitation module, and the importance of each channel is learnt to adjust the channels of the input features. The CABM attention is an attention module proposed by Woo et al. It consists of two separate sub-modules, the Channel Attention Module (CAM) and the Spatial Attention Module (SAM). The CAM helps to establish the interdependencies between feature channels, whereas the SAM focuses on the areas of the feature map that are most relevant to the classification task. CA attention creates two one-dimensional average poolings for encoding global information in two spatial dimensions and capturing long-range interactions in different dimensions. Such a design not only preserves precise location information, but also exploits long-range dependencies by encoding inter-channel and spatial information.
Since the introduction of self-attention into computer vision, it has grown rapidly in the field with great success []. A novel type of cross-attention, i.e., row attention and column attention, is used in CCNet [] to collect the contextual information of all pixels on that pixel cross-path and, through further cyclic operations, the global dependencies are made available to each pixel point.
DETR employs a Transformer architecture that applies self-attention to the task of target detection by mapping the objects in an image directly to target frames and categories for prediction, without the need for traditional anchor frames or suggestion regions, in order to achieve end-to-end target detection. The Swin Transformer [] uses a sliding-window based attention that restricts attention computation to a single window while still allowing the model to learn information across windows, saving computation power and enabling its access to global and local information.
3. Materials and Methods
3.1. YOLOV5s Improvements
We redesigned the backbone network of YOLOv5s using integrated perceptual attention and a C3_MR structure. The design principles follow the ideas of MobileViT [], with a combination of convolution and self-attention. Specifically, the C3_MR structure is first used to aggregate shallow features instead of the two C3 structures in the backbone network. The integrated perceptual attention is then used instead of the last two C3 structures to aggregate deep features. This not only reduces the parameters of the model, but also achieves hierarchical feature learning, gradually extracting different levels of information from shallow to deep, making the model more expressive. The improved backbone network is shown in Figure 2.
Figure 2.
Improved backbone network.
3.2. Integrated Perception Attention Module (IPA)
The Transformer encoder mainly consists of multiple layers of self-attentive coding, and its computation also originates from multiple coding layers. The Transformer encoder enhances the model’s ability to capture global information, while at the same time incurring high computational cost. To address this problem, we propose the integrated perceptual attention module (IPA), which employs a parallel two-branch structure, where one branch uses efficient attention to capture global information while the other branch uses convolutional attention to capture local information. The attention used in both branches is lightweight attention, which does not result in a huge increase in the model’s parameters and computational complexity. In addition to this, we have incorporated the idea of grouping into the integrated perceptual attention module. The structure of the integrated perceptual attention module is shown in Figure 3.
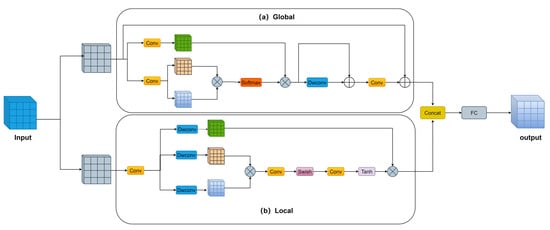
Figure 3.
Integrated perception attention structure (IPA).
Global branching: Global branches use a simple and efficient Inverse Residual Moving Block (IRMB) [] to aggregate global information, and the IRMB structure is shown in Figure 3a. This module is similar to the inverse inverted residual structure (IRB) in lightweight CNNs. IRB uses an extension layer to map feature dimensions to a higher dimensional space and uses depth-separable convolution to obtain more information in that higher dimensional space. IRMB replaces the depth separability in IRB with an efficient operator. The efficient operator consists of improved window attention and depth-separable convolution. Such a design not only incorporates CNN-like local feature modelling efficiency and Transformer-like dynamic modelling capabilities to learn long-distance interactions, but also does not impose unaffordable costs on the model.
Local branch: The local branch uses an attention-style convolution operator (AttnConv) [] to aggregate local information, and the AttnConv structure is shown in Figure 3b. AttnConv, like the standard attention operation, first obtains Q, K, and V using linear transformations. Then, context-aware weights are generated by a nonlinear operator. The difference is that AttnConv obtains Q, K, and V and then aggregates the local information of Q, K, and V using depth-separable convolution, respectively, and the depth-separable convolution weights are shared globally. AttnConv uses Swish too, in addition to introducing Tanh. The use of dual nonlinear operators yields higher-quality context-aware weights to enhance local features.
Specifically, in integrated perceptual attention, we first introduce the idea of grouping into integrated attention, similar to group convolution [,], by dividing the input channels into n groups, which reduces the number of parameters and the computational complexity. Then, the grouped features are fed into the global branch and local branch for information aggregation, respectively. Finally, the outputs of the global and local branches are fused. Specifically, the output of the global branch and the output of the local branch are spliced in the channel dimension. The fully connected layer will then be utilised to increase the interaction between the different channels and reduce the context loss due to grouping.
3.3. MultiScale Spatial Channel Reconstruction Module (MSCCR)
The structure of the multiscale spatial channel reconstruction module is shown in Figure 4. The multiscale spatial channel reconstruction module is centred on Spatial and Channel reconstruction Convolution (SCConv) []. Spatial and Channel reconstruction Convolution (SCConv) is an efficient convolution module that can effectively reduce computational redundancy and facilitate the learning of representative features. As shown in Figure 5, it consists of an SRU (Spatial Reconstruction Unit) and a CRU (Channel Reconstruction Unit). The SRU (Spatial Reconstruction Unit) uses separation and reconstruction to separate information-rich feature maps from information-poor feature maps and reconstruct the feature map weights. The CRU (Channel Reconstruction Unit) uses separation, transformation, and fusion strategies to extract rich feature information using inexpensive operations. The parameters of the standard convolution are calculated as
where and are the number of input and output channels and is the convolution kernel size.

Figure 4.
Multiscale spatial channel reconstruction (MSCCR).
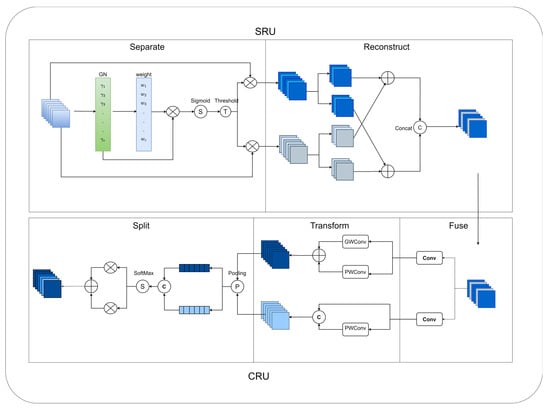
Figure 5.
Spatial and Channel reconstruction Convolution (SCConv).
The parameters of the SCConv (Spatial and Channel reconstruction Convolution) are calculated as follows:
where , , and are the hyperparameters of SCConv and is the size of the convolution kernel, typically = 1/2, = 2, and = 2.
Standard convolution parameters are compared to SCConv parameters with an equal number of input channels, output channels, and the same convolution kernel size:
The SCConv (Spatial and Channel reconstruction Convolution) parameter is a fifth of the standard convolution. So, using the SCConv as the core of the multiscale spatial channel reconstruction module can effectively reduce the number of parameters.
In addition to this, we add a type of efficient multiscale attention (EMA) [] to the multiscale spatial channel reconstruction module. The EMA has a parallel three-branch structure, as shown in Figure 6. Different branches use different scales of convolution in order to facilitate the acquisition of multiscale spatial information and the establishment of long- and short-term dependencies. A richer set of features is then aggregated through the method of cross-spatial information aggregation. It is a lightweight attention; introducing it into the module does not add parameters and compensates for the fact that the convolution is strong locally but not globally.
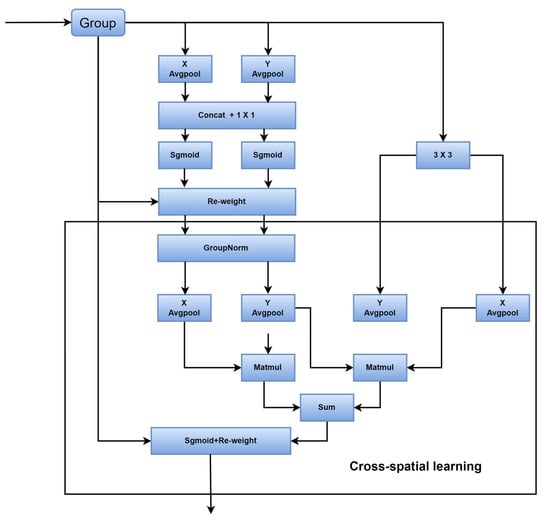
Figure 6.
Efficient multiscale attention (EWA).
3.4. C3_MR Build
The YOLOv5 backbone network is dominated by the C3 structure. The core of the C3 structure is a bottleneck residual structure module. The bottleneck residual structure module reduces the parameters of the backbone network by using the method of mapping features into a low-dimensional space. This reduces the number of parameters but also results in a loss of feature information. Specifically, we utilise the multiscale spatial channel reconstruction module proposed in Section 3.2 to replace the bottleneck residual structure module in the C3 structure, and call it the C3_MR structure. The bottleneck residual structure module parameters are calculated as
where and are the number of input and output channels, is the convolution kernel size, and is the scaling factor, usually 0.5.
The parameters of the multiscale spatial channel reconstruction module are calculated as
where is the parameter of the SCConv, and are the number of input and output channels, and is the convolution kernel size. is the scaling factor, which is usually 0.5.
It is assumed that the bottleneck residual structure module and the multiscale spatial channel reconstruction module have the same number of input and output channels and that their convolution kernel size 3 × 3. The bottleneck residual structure module’s parameters can be compared to the multiscale spatial channel reconstruction module’s parameters:
The multiscale spatial channel reconstruction module is 1.8 times smaller than the bottleneck residual structure module. The parameters of the multiscale spatial channel reconstruction module in relation to the bottleneck residual structure module are shown in Table 2. The structure of C3_MR is shown in Figure 7.
Table 2.
Comparison of bottleneck and MSCCR parameter counts.
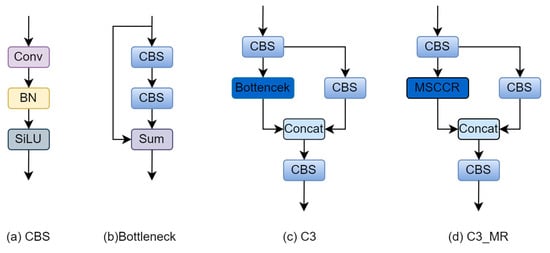
Figure 7.
C3_MR.
4. Results
4.1. Dataset
This paper uses the UA-DETRAC dataset [,,], a large open source resource for vehicle detection and tracking. The UA-DETRAC dataset is composed of road video surveillance from 24 different locations, covering a wide range of weather conditions, including sunny, rainy, and cloudy weather, and nighttime conditions. The types of vehicles in the dataset were divided into four categories, including cars, buses, lorries, and other types of vehicles. A total of 8250 vehicles and 1.21 million target objects were labelled.
We performed a frame extraction operation on the UA-DETRAC dataset, extracting the original video every 10 frames. Doing so, not only reduces the sample size of the dataset and reduces the training time of the model, but also prevents data redundancy. We selected 8639 images from the original training set to create a new training set, and chose 2231 images from the original validation set to create a new dataset.
4.2. Experimental Equipment and Evaluation Indicators
This experiment employs the Ubuntu 20.04 LTS operating system with an Intel Xeon Gold 6330 CPU, 128 GB of RAM, and an RTX 3090 GPU with 24 GB of VRAM. The deep learning framework used is PyTorch 1.10.1 with CUDA 11.8. The batch size for each training batch is 32, and a total of 100 training epochs are conducted.
To assess the performance improvement of YOLOv5s, the primary evaluation metrics used are the mean average precision (mAP@0.5) and the model’s parameter count.
The formula for calculating the average accuracy of n classes is as follows:
In the above equation, P and R represent precision and recall, respectively.
in which TP represents the number of true positives (correctly detected positive samples), FP represents the number of false positives (incorrectly detected negative samples), and FN represents the number of false negatives (incorrectly detected positive samples).
4.3. Comparisons
To validate the improved algorithm’s detection accuracy, we compared the enhanced YOLOv5s with the Faster-RCNN and SSD on the same dataset. The Faster-RCNN utilizes ResNet50 as its backbone network, while SSD uses VGG16 as its backbone network. As shown in Table 3, the parameter count of our improved algorithm is 15.5 of that of Faster-RCNN, with an accuracy 5.7 higher than Faster-RCNN. SSD has a parameter count 3.8 times that of our improved algorithm but has an accuracy 3.3 lower. Therefore, through a comparison with the one-stage detection algorithm SSD and the two-stage detection algorithm Faster-RCNN, our improved algorithm demonstrates a more accurate detection of vehicle targets.
Table 3.
Comparison of the different algorithms.
To validate the performance of the improved backbone network, we compared it with some popular backbone networks such as MobileNetV2, MobileNetV3, and EfficientNet. We conducted experiments by replacing the backbone network of YOLOv5s with the aforementioned backbone networks. The experimental results are shown in Table 4. The improved backbone network achieved a mAP@50 that is 5.6% higher than MobileNetV2, 6.7% higher than MobileNetV3, and 4.1% higher than EfficientNet. The mAP@50:95 is also superior to mainstream backbone networks, and the parameter count is roughly the same. Through this comparison, it can be concluded that under nearly identical parameter counts, our improved backbone network outperforms popular backbone networks in terms of performance.
Table 4.
Comparison of the performance of different backbone networks.
We also compared the improved algorithm with similar algorithms: YOLOv3-tiny, YOLOv4-tiny, and YOLOv5s (the original model). As seen in Table 5, YOLOv3-tiny has 1.4 times the parameter count of the improved model but a 6.7% lower mAP@50. The improved model reduces the parameter count by 9% and increases the mAP@50 by 3.1%. It also performs well compared to YOLOv6s and YOLOv7-tiny. This indicates that the improved algorithm also performs excellently against similar algorithms.
Table 5.
Performance comparison of different lightweight networks.
4.4. Comparison of Test Results
The visual results of vehicle detection in different scenarios for our improved model and YOLOv5 are shown in Figure 8. The left image represents the detection results of YOLOv5s, while the right image displays the detection results of our improved model. From Figure 8, it can be observed that the first and second images depict complex environments with a higher number of vehicles, while the third image represents a simpler environment with fewer vehicles. In both simple and complex environments, the number of vehicles detected in the left panel is less than in the right panel, and the detection accuracy is also generally lower than in the right panel. It can be concluded that the YOLOv5s algorithm has weak adaptability and a poor feature extraction ability in complex scenes, and is prone to low detection accuracy and missed detection problems. Our proposed method can improve the problems of YOLOv5s and better detect vehicles.


Figure 8.
Detection results of YOLOv5s and improved model.
4.5. Grad-CAM Visualisation
To further demonstrate the effectiveness of our method, we conducted Grad-CAM visualizations for YOLOv5s and the improved model, as shown in Figure 9. The left image in each pair represents the Grad-CAM visualization results for YOLOv5s, while the right image represents the Grad-CAM visualization results for the improved model. In the first image, it can be clearly observed that the improved model focuses more accurately on the area in which the object is located than YOLOv5s. In the second image, although both the improved model and YOLOv5s are able to locate the object’s region, the Grad-CAM map of the improved model is darker, which indicates that the improved model pays more attention to the object’s region, emphasising the importance of this region. Therefore, our proposed method can further fine-grain the features, making the model more accurate at locating and recognising objects.
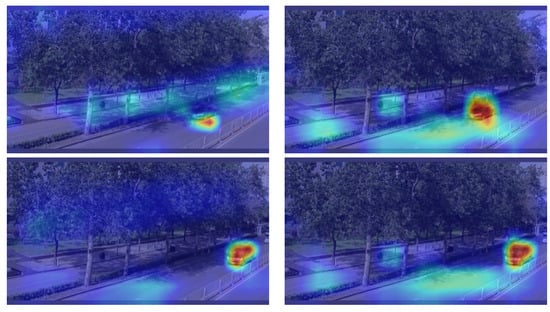
Figure 9.
Grad-CAM visualisation results for YOLOv5s and improved model.
4.6. Ablation Experiment
To demonstrate the impact of the improvements proposed, we conducted ablation experiments, as shown in Table 6. From the table, it can be observed that although C3_MR uses SCConv, a similar 3 × 3 convolution, it does not increase the model’s parameters and it improves detection accuracy. IAT effectively reduces model parameters and enhances model accuracy. When all these improvements are combined with YOLOv5s, they significantly enhance the algorithm’s accuracy while reducing the model’s parameter count.
Table 6.
Results of ablation experiments.
5. Discussion
With the continuous development of automotive technology, vehicle detection algorithms are widely used in autonomous driving to capture images and video data around the vehicle using on-board cameras. Vehicle detection algorithms use this data to identify vehicle targets in images through complex computations and model analysis. Combined with on-board cameras and vehicle detection algorithms, the vehicle system is able to sense vehicle dynamics on the surrounding roads in real time. Moreover, vehicle detection algorithms combined with millimetre wave radar or LiDAR can improve the robustness and reliability of vehicle detection []. Some researchers have chosen to use the original YOLO algorithm in vehicle detection [,]. Although it can accurately detect vehicle targets, when applied to vehicle camera-like mobile terminal devices [] it imposes a huge computational cost on the mobile terminal device and makes it difficult to maintain a high frame rate for real-time detection during runtime. YOLOtiny has smaller parameters and a smaller model size compared to the original YOLO algorithm, but it is less accurate and insufficient at detecting vehicle targets []. The method proposed in this paper can effectively reduce the model’s parameters and improve its accuracy. Therefore, the method can be used as a solution to the above problem. Due to the limitations of mobile terminal devices, we plan to conduct practical experiments in future studies to verify the performance of our proposed method in real applications. In addition, we will further optimise the algorithms to adapt them to the limitations of different hardware platforms and computing resources to ensure that efficient vehicle detection can be achieved on mobile terminal devices.
6. Conclusions
In order to address the issues of the complex structure and large hardware requirements of current vehicle detection algorithms, this paper proposes a lightweight vehicle detection model based on comprehensive perception attention. Two lightweight modules, the integrated perceptual attention module and the multiscale spatial channel reconstruction module, were designed and successfully integrated into the YOLOv5s algorithm.
The experimental results demonstrate that, compared to YOLOv5s, the improved algorithm achieved a 3.1% increase in its average precision on the UA-DETRAC dataset. In comparison to SSD, it outperforms it with a 3.3% higher mAP@50. When compared to Faster-RCNN, it also surpasses that algorithm with a 3.3% higher mAP@50. In comparison to other backbone networks, it achieves a 5.6% higher mAP@50 than MobileNetV2, 6.7% higher than MobileNetV3, and 4.1% higher than EfficientNet. Compared to similar algorithms like YOLOv3-tiny and YOLOv4-tiny, it achieves a 5.7% and 6.7% higher mAP@50, respectively. The improved algorithm exhibits excellent performance in various scenarios. This algorithm not only ensures higher accuracy but also effectively reduces computational costs, decreasing the demand for storage and computing resources. Therefore, it is well-suited for deployment in resource-constrained devices. Future focus can be on successfully deploying the improved model in resource-constrained embedded devices to achieve practical applications in the field of vehicle detection. This initiative will contribute to further enhancing the proposed algorithm and its methods to meet real-world requirements.
Author Contributions
Conceptualization, P.W.; methodology, K.L.; validation, Z.S.; formal analysis, Q.Z.; investigation, Y.L.; resources, Q.H.; data curation, S.X.; writing—original draft preparation, Y.W.; writing—review and editing, S.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Du, Y.; Liu, X.; Yi, Y.; Wei, K. Optimizing Road Safety: Advancements in Lightweight Yolov8 Models and Ghostc2f Design for Real-Time Distracted Driving Detection. Sensors 2023, 23, 8844. [Google Scholar] [CrossRef]
- Rajamoorthy, R.; Arunachalam, G.; Kasinathan, P.; Devendiran, R.; Ahmadi, P.; Pandiyan, S.; Muthusamy, S.; Panchal, H.; Kazem, H.A.; Sharma, P. A Novel Intelligent Transport System Charging Scheduling for Electric Vehicles Using Grey Wolf Optimizer and Sail Fish Optimization Algorithms. Energy Sources Part A Recovery Util. Environ. Eff. 2023, 44, 3555–3575. [Google Scholar] [CrossRef]
- Yu, B.; Zhang, H.; Li, W.; Qian, C.; Li, B.; Wu, C. Ego-Lane Index Estimation Based on Lane-Level Map and Lidar Road Boundary Detection. Sensors 2021, 21, 7118. [Google Scholar] [CrossRef] [PubMed]
- Miao, Y.; Liu, F.; Hou, T.; Liu, L.; Liu, Y. A Nighttime Vehicle Detection Method Based on Yolo V3. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020. [Google Scholar]
- Tajar, A.T.; Ramazani, A.; Mansoorizadeh, M. A Lightweight Tiny-Yolov3 Vehicle Detection Approach. J. Real-Time Image Process. 2021, 18, 2389–2401. [Google Scholar] [CrossRef]
- Zhu, L.; Geng, X.; Li, Z.; Liu, C. Improving Yolov5 with Attention Mechanism for Detecting Boulders from Planetary Images. Remote Sens. 2021, 13, 3776. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. Tph-Yolov5: Improved Yolov5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Huang, S.; He, Y.; Chen, X.-A. M-Yolo: A Nighttime Vehicle Detection Method Combining Mobilenet V2 and Yolo V3. J. Phys. Conf. Ser. 2021, 1883, 012094. [Google Scholar] [CrossRef]
- Li, X.; Qin, Y.; Wang, F.; Guo, F.; Yeow, J.T.W. Pitaya Detection in Orchards Using the Mobilenet-Yolo Model. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020. [Google Scholar]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Zhang, K.; Wang, W.; Lv, Z.; Fan, Y.; Song, Y. Computer Vision Detection of Foreign Objects in Coal Processing Using Attention Cnn. Eng. Appl. Artif. Intell. 2021, 102, 104242. [Google Scholar] [CrossRef]
- Russell, A.; Jia, Z.J. Vehicle Detection Based on Color Analysis. In Proceedings of the 2012 International Symposium on Communications and Information Technologies (ISCIT), Gold Coast, Australia, 2–5 October 2012. [Google Scholar]
- Satzoda, R.K.; Trivedi, M.M. Multipart Vehicle Detection Using Symmetry-Derived Analysis and Active Learning. IEEE Trans. Intell. Transp. Syst. 2016, 17, 926–937. [Google Scholar] [CrossRef]
- Chen, H.T.; Wu, Y.C.; Hsu, C.C. Daytime Preceding Vehicle Brake Light Detection Using Monocular Vision. IEEE Sens. J. 2016, 16, 120–131. [Google Scholar] [CrossRef]
- Razalli, H.; Ramli, R.; Alkawaz, M.H. Emergency Vehicle Recognition and Classification Method Using Hsv Color Segmentation. In Proceedings of the 2020 16th IEEE International Colloquium on Signal Processing & Its Applications (CSPA), Langkawi, Kedah, Malaysia, 28–29 February 2020. [Google Scholar]
- Zhang, Y.; Sun, Y.; Wang, Z.; Jiang, Y. Yolov7-Rar for Urban Vehicle Detection. Sensors 2023, 23, 1801. [Google Scholar] [CrossRef]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J.; Berkeley, U. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation Tech Report. In Proceedings of the IEEE conference on computer vision and pattern recognition, Columbus, OH, USA, 23-28 June 2014; 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-Cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2015; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An Enhanced Cnn-Enabled Learning Method for Promoting Ship Detection in Maritime Surveillance System. Ocean Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Nepal, U.; Eslamiat, H. Comparing Yolov3, Yolov4 and Yolov5 for Autonomous Landing Spot Detection in Faulty Uavs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using Yolov3, Yolov4, and Yolov5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. Dc-Spp-Yolo: Dense Connection and Spatial Pyramid Pooling Based Yolo for Object Detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]
- Bie, M.; Liu, Y.; Li, G.; Hong, J.; Li, J. Real-Time Vehicle Detection Algorithm Based on a Lightweight You-Only-Look-Once (Yolov5n-L) Approach. Expert Syst. Appl. 2023, 213, 119108. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Mnih, V.; Heess, N.M.O.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the Neural Information Processing Systems 2014, Montreal, BC, Canada, 8–13 December 2014. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.-S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, Q.; Wu, T.; Zheng, H.; Guo, G. Hierarchical Pyramid Diverse Attention Networks for Face Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, J.; Ren, P.; Zhang, D.; Chen, D.; Wen, F.; Li, H.; Hua, G. Neural Aggregation Network for Video Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yuan, Y.; Wang, J. Ocnet: Object Context Network for Scene Parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. Ccnet: Criss-Cross Attention for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6896–6908. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-Weight, General-Purpose, Mobile-Friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking Mobile Block for Efficient Attention-Based Models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Fan, Q.; Huang, H.; Guan, J.; He, R. Rethinking Local Perception in Lightweight Vision Transformer. arXiv 2023, arXiv:2303.17803. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and Channel Reconstruction Convolution for Feature Redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2023, Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Lyu, S.; Chang, M.-C.; Du, D.; Li, W.; Wei, Y.; Del Coco, M.; Carcagnì, P.; Schumann, A.; Munjal, B.; Dang, D.-Q.-T.; et al. Ua-Detrac 2018: Report of Avss2018 & Iwt4s Challenge on Advanced Traffic Monitoring. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS) 2018, Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Lyu, S.; Chang, M.-C.; Du, D.; Wen, L.; Qi, H.; Li, Y.; Wei, Y.; Ke, L.; Hu, T.; Del Coco, M. Ua-Detrac 2017: Report of Avss2017 & Iwt4s Challenge on Advanced Traffic Monitoring. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.-C.; Qi, H.; Lim, J.; Yang, M.-H.; Lyu, S. Ua-Detrac: A New Benchmark and Protocol for Multi-Object Detection and Tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef]
- Tang, L.; Yun, L.; Chen, Z.; Cheng, F. Hrynet: A Highly Robust Yolo Network for Complex Road Traffic Object Detection. Sensors 2024, 24, 642. [Google Scholar] [CrossRef]
- Jamiya, S.S.; Rani, P.E. LittleYOLO-SPP: A Delicate Real-Time Vehicle Detection Algorithm. Optik 2021, 225, 165818. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).