
Advancing Hyperspectral Image Analysis with CTNet: An Approach with the Fusion of Spatial and Spectral Features

 , and
, and
Abstract
:1. Introduction
- We demonstrate the effectiveness of improving spatial features through synthetic RGB images using a pre-trained ResNeXt to classify the land covers.
- We develop and optimize a multiscale attention module of the transformer block to provide long-range dependency of the spectral features.
- We designed a fusion module to generate enhanced spatial and spectral features obtained through convolution and transformer modules.
- We conducted extensive experiments to evaluate the performance of the proposed method on four benchmark datasets.
2. Materials and Methods
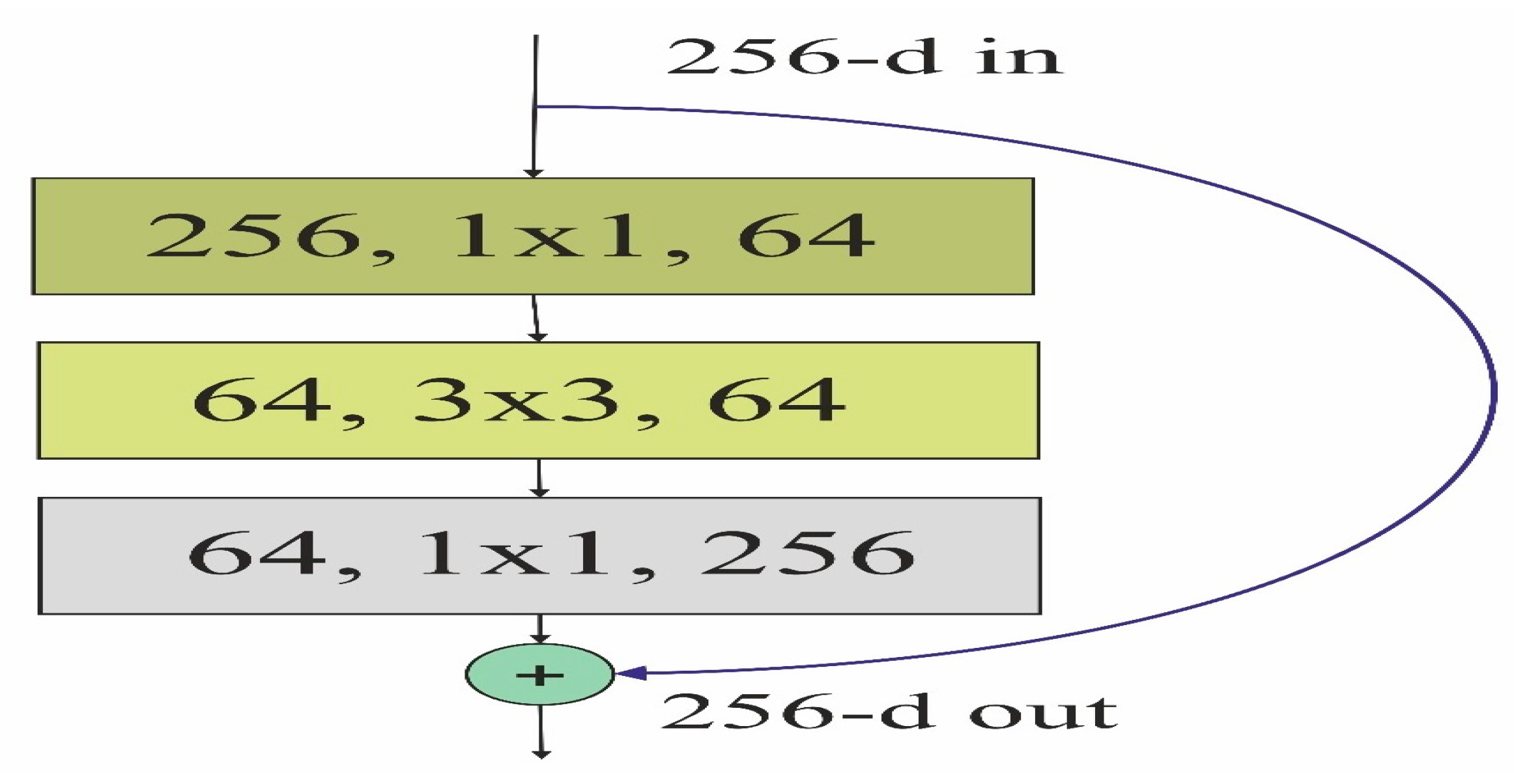
2.1. Enhanced Attention-Based Vision Transformer (EAVT)
2.2. Synthetic RGB Image Formation
| Algorithm 1: Steps to generate synthetic RGB image |
| Input: Hyperspectral image cube H, with dimensions M × N × P and Weight matrix (W) |
| (1) For each channel (Red, Green, Blue) and each spectral band (P), calculate the intensity of the spectral band as follows. where = intensity of k-th spectral band for channel c at spatial position (i, j). = intensity of the hyperspectral image at position (i, j) in the k-th band. = weight of the k-th spectral band for c-th RGB channel. (2) Calculate the intensity of the R, G, and B channels for the synthetic image using Equation (6), Equation (7) and Equation (8), respectively. (3) For each channel (R, G, B) at spatial position (i, j), populate the channel with calculated intensities using Equation (9), Equation (10) and Equation (11), respectively. (4) Normalize each pixel value in the R, G, and B channels by calculating minimum and maximum values using Equation (12), Equation (13) and Equation (14), respectively. (5) Round each pixel value to the nearest integer in each channel as follows. where = Normalized pixel value rounded to the nearest integer and ) = normalized intensity value of the pixel at position (i, j) in channel c. (6) Construct the final RGB image using the normalized and rounded values in each channel as follows. where = pixel value in the final RGB image at position (i, j) in channel c and = normalized and round intensity value of pixel value at position (i, j) in channel c. Output: RGB image |
2.3. Enhanced Spatial Features Using Virtual RGB Images
2.4. Spectral–Spatial Feature Fusion for HSI Classification
| Algorithm 2: The proposed method’s algorithm |
| INPUT: Hyperspectral image and ground truth label . |
| 1. Apply PCA and set dimension D = 30, and pass it to the transformer block. |
| 2. Generate RGB image from using spectral weighting. |
| 3. For I = 1 to 200, do |
| (a) Train the ResNeXT using synthesize image. |
| (b) Apply spectral linear projection to generate Q, K, and V and pass to EAVT. |
| (c) Train the EAVT. end |
| 4. Apply Equations (19) and (20) to generate enhanced features. |
| 5. Test the model for classification of land covers. |
| 6. Plot the training loss curve. |
| OUTPUT: Classified label of the test dataset () |
3. Experimental Results and Discussion
3.1. Datasets Description
3.2. Performance Metrics
3.3. Experimental Setup
3.4. Comparative Analysis with Baseline Methods
3.4.1. Quantitative Results
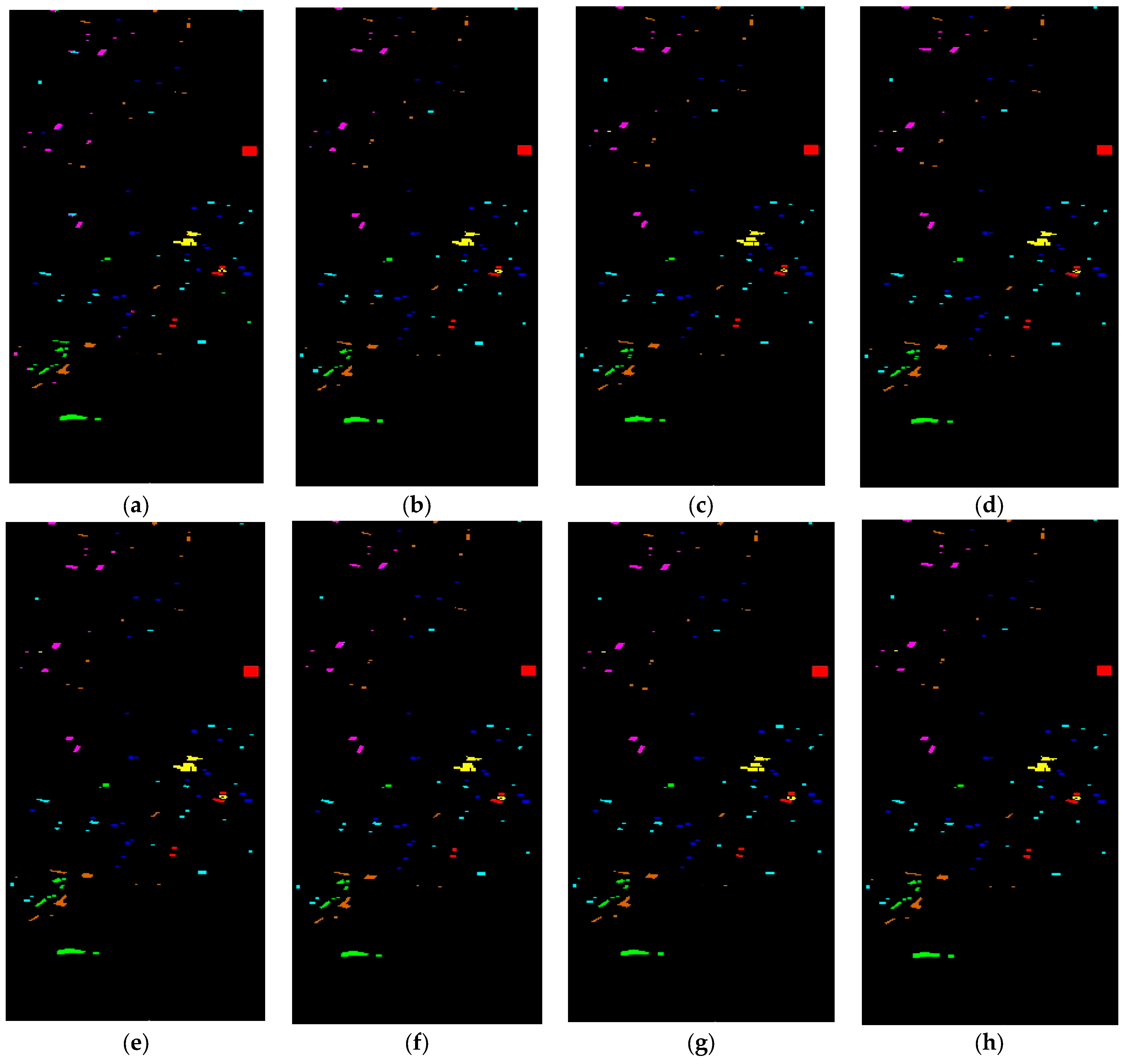
3.4.2. Visual Results Analysis
4. Discussion
4.1. Patch Size Effect on Model Performance
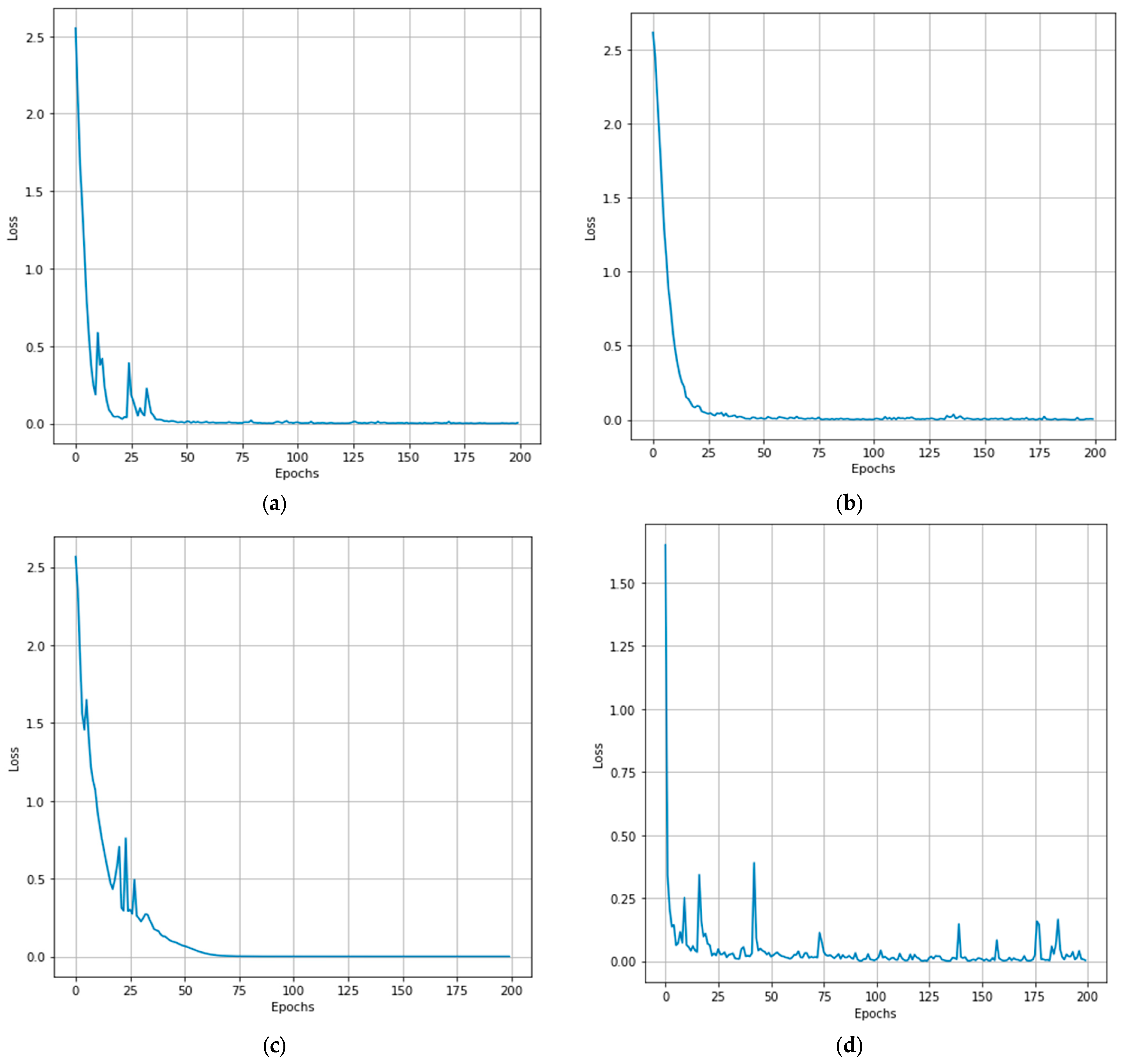
4.2. Training Loss of the Proposed Model
4.3. Computation of the Training and Validation Time
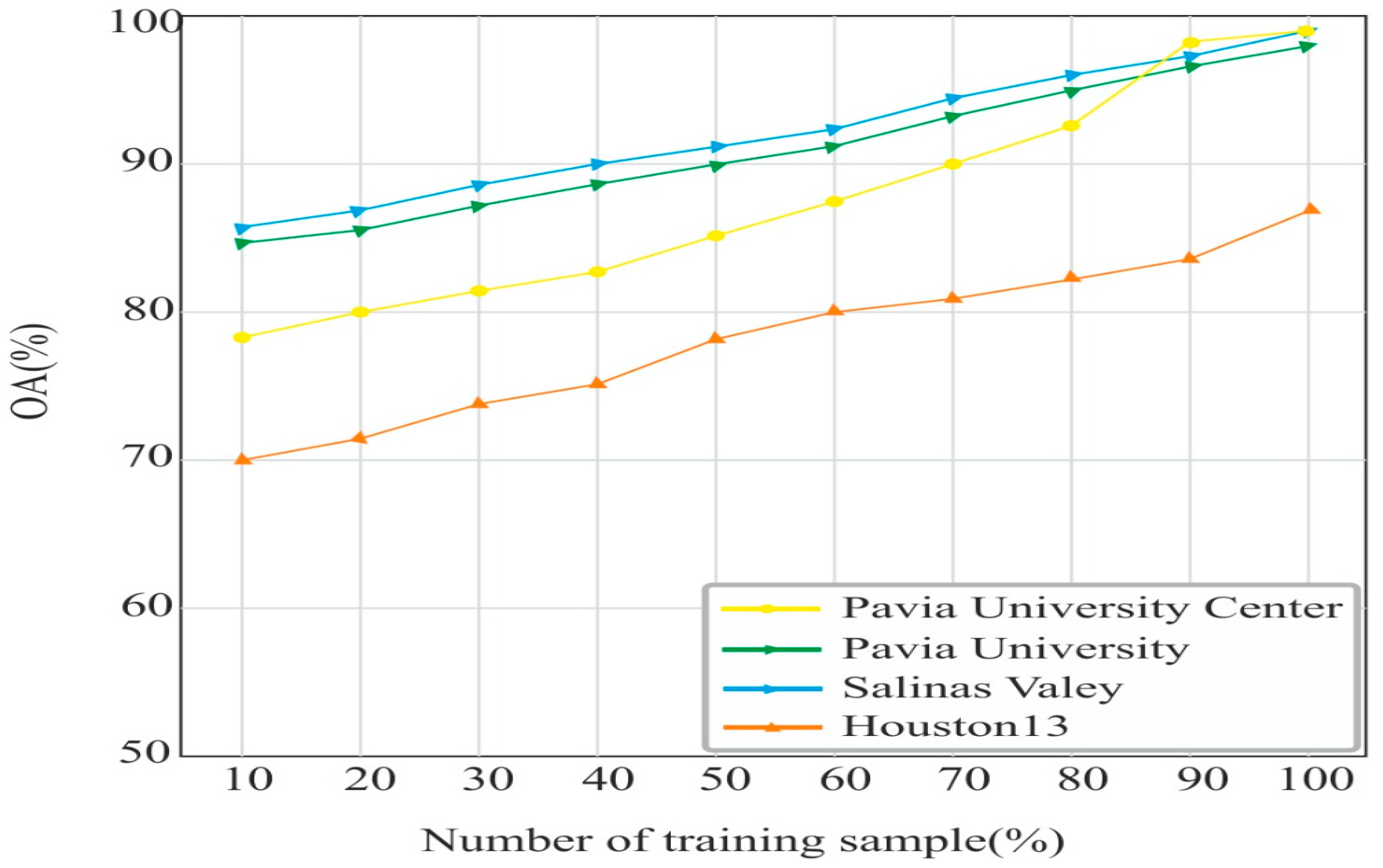
4.4. Effects of Training Samples (%) on OA Accuracy
4.5. Bar Plot Based Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| HSI | Hyperspectral imaging |
| CTNet | Convolutional transformer network |
| RGB | Red blue green |
| PCA | Principal component analysis |
| EAVT | Enhanced attention-based vision transformer |
| AA | Average accuracy |
| OA | Overall accuracy |
| PU | Pavia university |
| PUC | Pavia university Centre scene |
| SV | Salina velley |
| ML | Machine learning |
| DL | Deep learning |
| CNN | Convolution neural network |
| SVM | Support vector machine |
| MNF | Minimum noise fraction |
| NMF | Non-negative matrix factorization |
| BN | Batch normalization |
| ReLU | Rectified linear unit |
| FCN | Fully convolution network |
| ROSIS | Reflective Optics System Imaging Spectrometer |
| CM | Confusion matrix |
| GT | Ground truth |
| NLP | Natural language processing |
| ViT | Vision transformer |
| AI | Artificial intelligence |
| TMOE-CNN | Tree-shaped multi objective evolutionary CN |
| F-GCN | Fuzzy graph convolutional network |
| KSC | Kennedy space Centre |
| AIAF-Defense | Attack-invariant attention feature-based defense |
| DCTransformer | Discrete cosine transform |
| RPDAL | Reinforced pool-based deep active learning |
References
- Datta, D.; Mallick, P.K.; Bhoi, A.K.; Ijaz, M.F.; Shafi, J.; Choi, J. Hyperspectral image classification: Potentials, challenges, and future directions. Comput. Intell. Neurosci. 2022, 2022, 1–36. [Google Scholar] [CrossRef]
- Li, X.; Liu, B.; Zhang, K.; Chen, H.; Cao, W.; Liu, W.; Tao, D. Multi-view learning for hyperspectral image classification: An overview. Neurocomputing 2022, 500, 499–517. [Google Scholar] [CrossRef]
- Jia, S.; Jiang, S.; Lin, Z.; Li, N.; Xu, M.; Yu, S. A survey: Deep learning for hyperspectral image classification with few labeled samples. Neurocomputing 2021, 448, 179–204. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. An overview on spectral and spatial information fusion for hyperspectral image classification: Current trends and challenges. Inf. Fusion 2020, 59, 59–83. [Google Scholar] [CrossRef]
- Gao, H.; Zhu, M.; Wang, X.; Li, C.; Xu, S. Lightweight Spatial-Spectral Network Based on 3D-2D Multi-Group Feature Extraction Module for Hyperspectral Image Classification. Int. J. Remote Sens. 2023, 44, 3607–3634. [Google Scholar] [CrossRef]
- Tinega, H.C.; Chen, E.; Ma, L.; Nyasaka, D.O.; Mariita, R.M. HybridGBN-SR: A Deep 3D/2D Genome Graph-Based Network for Hyperspectral Image Classification. Remote Sens. 2022, 14, 1332. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Xia, J.; Ghamisi, P.; Yokoya, N.; Iwasaki, A. Random forest ensembles and extended multiextinction profiles for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 202–216. [Google Scholar] [CrossRef]
- Ahmad, M.; Shabbir, S.; Raza, R.A.; Mazzara, M.; Distefano, S.; Khan, A.M. Artifacts of different dimension reduction methods on hybrid CNN feature hierarchy for hyperspectral image classification. Optik 2021, 246, 167757. [Google Scholar] [CrossRef]
- Luo, G.; Chen, G.; Tian, L.; Qin, K.; Qian, S.-E. Minimum noise fraction versus principal component analysis as a preprocessing step for hyperspectral imagery denoising. Can. J. Remote Sens. 2016, 42, 106–116. [Google Scholar] [CrossRef]
- He, W.; Zhang, H.; Zhang, L. Sparsity-regularized robust non-negative matrix factorization for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4267–4279. [Google Scholar] [CrossRef]
- Gao, L.; Gu, D.; Zhuang, L.; Ren, J.; Yang, D.; Zhang, B. Combining t-distributed stochastic neighbor embedding with convolutional neural networks for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1368–1372. [Google Scholar] [CrossRef]
- Sun, C.; Zhang, X.; Meng, H.; Cao, X.; Zhang, J.; Jiao, L. Dual-Branch Spectral–Spatial Adversarial Representation Learning for Hyperspectral Image Classification with Few Labeled Samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1–15. [Google Scholar] [CrossRef]
- Cao, F.; Guo, W. Deep hybrid dilated residual networks for hyperspectral image classification. Neurocomputing 2020, 384, 170–181. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual spectral–spatial attention network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Xing, C.; Cong, Y.; Duan, C.; Wang, Z.; Wang, M. Deep network with irregular convolutional kernels and self-expressive property for classification of hyperspectral images. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 10747–10761. [Google Scholar] [CrossRef]
- Pu, C.; Huang, H.; Yang, L. An attention-driven convolutional neural network-based multi-level spectral–spatial feature learning for hyperspectral image classification. Expert Syst. Appl. 2021, 185, 115663. [Google Scholar] [CrossRef]
- Vivone, G. Multispectral and hyperspectral image fusion in remote sensing: A survey. Inf. Fusion 2023, 89, 405–417. [Google Scholar] [CrossRef]
- Zhou, F.; Hang, R.; Liu, Q.; Yuan, X. Pyramid fully convolutional network for hyperspectral and multispectral image fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1549–1558. [Google Scholar] [CrossRef]
- Li, Y.; Fu, M.; Zhang, H.; Xu, H.; Zhang, Q. Hyperspectral Image Fusion Algorithm Based on Improved Deep Residual Network. Signal Process. 2023, 210, 109058. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Song, R.; Zhao, X.; Zhao, K. MCT-Net: Multi-hierarchical cross transformer for hyperspectral and multispectral image fusion. Knowl. Based Syst. 2023, 264, 110362. [Google Scholar] [CrossRef]
- Li, S.; Dian, R.; Liu, H. Learning the external and internal priors for multispectral and hyperspectral image fusion. Sci. China Inf. Sci. 2023, 66, 140303. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Spectral–spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Li, M.; Liu, J.; Fu, Y.; Zhang, Y.; Dou, D. Spectral Enhanced Rectangle Transformer for Hyperspectral Image Denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5805–5814. [Google Scholar]
- Zhang, M.; Liu, L.; Jin, Y.; Lei, Z.; Wang, Z.; Jiao, L. Tree-shaped multiobjective evolutionary CNN for hyperspectral image classification. Appl. Soft Comput. 2024, 152, 111176. [Google Scholar] [CrossRef]
- Ahmad, M.; Ghous, U.; Usama, M.; Mazzara, M. WaveFormer: Spectral–spatial wavelet transformer for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5502405. [Google Scholar] [CrossRef]
- Xu, J.; Li, K.; Li, Z.; Chong, Q.; Xing, H.; Xing, Q.; Ni, M. Fuzzy graph convolutional network for hyperspectral image classification. Eng. Appl. Artif. Intell. 2024, 127, 107280. [Google Scholar] [CrossRef]
- Shi, C.; Liu, Y.; Zhao, M.; Pun, C.-M.; Miao, Q. Attack-invariant attention feature for adversarial defense in hyperspectral image classification. Pattern Recognit. 2024, 145, 109955. [Google Scholar] [CrossRef]
- Ranjan, P.; Girdhar, A. Deep Siamese network with handcrafted feature extraction for hyperspectral image classification. Multimed. Tools Appl. 2024, 83, 2501–2526. [Google Scholar] [CrossRef]
- Gao, Q.; Wu, T.; Wang, S. SSC-SFN: Spectral-spatial non-local segment federated network for hyperspectral image classification with limited labeled samples. Int. J. Digit. Earth 2024, 17, 2300319. [Google Scholar] [CrossRef]
- Dang, Y.; Zhang, X.; Zhao, H.; Liu, B. DCTransformer: A Channel Attention Combined Discrete Cosine Transform to Extract Spatial–Spectral Feature for Hyperspectral Image Classification. Appl. Sci. 2024, 14, 1701. [Google Scholar] [CrossRef]
- Tejasree, G.; Agilandeeswari, L. Land use/land cover (LULC) classification using deep-LSTM for hyperspectral images. Egypt. J. Remote Sens. Space Sci. 2024, 27, 52–68. [Google Scholar] [CrossRef]
- Patel, U.; Patel, V. Active learning-based hyperspectral image classification: A reinforcement learning approach. J. Supercomput. 2024, 80, 2461–2486. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef]
- Koundal, D.; Gupta, S.; Singh, S. Computer aided thyroid nodule detection system using medical ultrasound images. Biomed. Signal Process. Control 2018, 40, 117–130. [Google Scholar] [CrossRef]
- Kaushal, C.; Bhat, S.; Koundal, D.; Singla, A. Recent trends in computer assisted diagnosis (CAD) system for breast cancer diagnosis using histopathological images. IRBM 2019, 40, 211–227. [Google Scholar] [CrossRef]
- Cai, W.; Ning, X.; Zhou, G.; Bai, X.; Jiang, Y.; Li, W.; Qian, P. A Novel hyperspectral image classification model using bole convolution with three-direction attention mechanism: Small sample and unbalanced learning. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5500917. [Google Scholar] [CrossRef]
- Huang, X.; Dong, M.; Li, J.; Guo, X. A 3-D-swin transformer-based hierarchical contrastive learning method for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5411415. [Google Scholar] [CrossRef]
- Wang, X.; Tan, K.; Du, P.; Pan, C.; Ding, J. A unified multiscale learning framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4508319. [Google Scholar] [CrossRef]
- Atito, S.; Awais, M.; Kittler, J. Sit: Self-supervised vision transformer. arXiv 2021, arXiv:2104.03602. [Google Scholar]
- Yuan, D.; Shu, X.; Liu, Q.; Zhang, X.; He, Z. Robust thermal infrared tracking via an adaptively multi-feature fusion model. Neural Comput. Appl. 2023, 35, 3423–3434. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Model | Dataset | OA |
|---|---|---|---|
| Zhang et al. [26] | TMOE-CNN | IP | 96.70% |
| PU | 95.97% | ||
| Houston13 | 89.36% | ||
| Ahmad et al. [27] | WaveFormer | PU | 95.66% |
| Houston | 96.54% | ||
| Xu et al. [28] | F-GCN | IP | 95.30% |
| PU | 97.68% | ||
| KSC | 99.94% | ||
| Shi et al. [29] | AIAF-Defense | PU | 95.17% |
| Houston 18 | 71.94% | ||
| SV | 96.56% | ||
| Ranjan et al. [30] | Siamese network | PU | 95.17% |
| IP | 93.25% | ||
| Gao et al. [31] | SSC-SFN | SV | 99.48% |
| WHU-HI-HanChuan | 91.82% | ||
| WHU-HI-HongHu | 92.94% | ||
| Dang et al. [32] | DCTransformer | IP | 94.40% |
| Houston | 94.89% | ||
| Tajasaree et al. [33] | deep-LSTM | PU | 93.99% |
| IP | 99.01% | ||
| KSC | 96.72% | ||
| Patel et al. [34] | RPDAL | IP | 92.78% |
| PU | 97.85% | ||
| SV | 97.94% |
| University of Pavia (PU) | Pavia University Centre (PUC) | ||||||
|---|---|---|---|---|---|---|---|
| Id | Class | Train | Test | Id | Class | Train | Test |
| 1 | Water | 742 | 82 | 1 | Asphalt | 6299 | 332 |
| 2 | Trees | 738 | 82 | 2 | Meadows | 17,717 | 932 |
| 3 | Asphalt | 735 | 81 | 3 | Gravel | 1994 | 105 |
| 4 | Self-Blocking Bricks | 727 | 81 | 4 | Trees | 2911 | 153 |
| 5 | Bitumen | 727 | 81 | 5 | Painted metal sheets | 1278 | 67 |
| 6 | Tiles | 1134 | 126 | 6 | Bare Soil | 4778 | 251 |
| 7 | Shadows | 428 | 48 | 7 | Bitumen | 1264 | 66 |
| 8 | Meadows | 742 | 82 | 8 | Self-Blocking Bricks | 3498 | 184 |
| 9 | Bare Soil | 738 | 82 | 9 | Shadows | 900 | 47 |
| Salinas Valley (SV) | Houston13 | ||||||
| Id | Class | Train | Test | Id | Class | Train | Test |
| 1 | Brocoli_green_weeds_1 | 1909 | 100 | 1 | Grass healthy | 311 | 14 |
| 2 | Brocoli_green_weeds_2 | 3540 | 186 | 2 | Grass stressed | 329 | 36 |
| 3 | Fallow | 1877 | 99 | 3 | Trees | 329 | 36 |
| 4 | Fallow_rough_plow | 1324 | 70 | 4 | Water | 257 | 28 |
| 5 | Fallow_smooth | 2544 | 134 | 5 | Residential buildings | 288 | 31 |
| 6 | Stubble | 3761 | 198 | 6 | Non-Non-residential buildings | 368 | 40 |
| 7 | Celery | 3400 | 179 | 7 | Road | 399 | 44 |
| 8 | Grapes_untrained | 10,707 | 564 | ||||
| 9 | Soil_vinyard_develop | 5893 | 310 | ||||
| 10 | Corn_senesced_green_weeds | 3114 | 164 | ||||
| 11 | Lettuce_romaine_4wk | 1015 | 53 | ||||
| 12 | Lettuce_romaine_5wk | 1831 | 96 | ||||
| 13 | Lettuce_romaine_6wk | 870 | 46 | ||||
| 14 | Lettuce_romaine_7wk | 1017 | 53 | ||||
| 15 | Vinyard_untrained | 6905 | 363 | ||||
| 16 | Vinyard_vertical_trellis | 1717 | 90 | ||||
| Id. | 2DCNN | 3DCNN | BTA-Net | HybridSN | UML | SiT | 3DSwinT | CTNet |
|---|---|---|---|---|---|---|---|---|
| 1 | 85.35 | 94.17 | 91.80 | 95.16 | 90.53 | 92.17 | 94.15 | 98.65 |
| 2 | 92.18 | 93.54 | 92.71 | 96.47 | 94.81 | 96.43 | 97.63 | 97.18 |
| 3 | 62.57 | 81.34 | 84.05 | 86.57 | 85.17 | 92.62 | 94.35 | 95.37 |
| 4 | 91.71 | 93.18 | 89.16 | 91.26 | 88.62 | 96.53 | 95.67 | 94.94 |
| 5 | 93.87 | 94.87 | 95.98 | 97.53 | 96.57 | 94.76 | 93.75 | 97.49 |
| 6 | 82.58 | 91.57 | 95.36 | 93.89 | 96.42 | 90.85 | 95.38 | 95.92 |
| 7 | 80.65 | 88.94 | 86.54 | 84.52 | 83.53 | 91.74 | 92.14 | 94.17 |
| 8 | 78.64 | 90.67 | 87.28 | 96.76 | 80.27 | 91.17 | 96.81 | 98.76 |
| 9 | 82.16 | 83.67 | 92.79 | 92.89 | 89.15 | 92.04 | 91.59 | 97.58 |
| AA | 83.30 | 90.27 | 90.63 | 92.78 | 89.34 | 93.15 | 94.83 | 96.83 |
| OA | 86.75 | 92.15 | 93.24 | 94.17 | 90.76 | 93.03 | 95.68 | 97.87 |
| Kappa | 82.17 | 88.05 | 87.26 | 90.18 | 87.25 | 92.07 | 94.13 | 96.58 |
| Id. | 2DCNN | 3DCNN | BTA-Net | HybridSN | UML | SiT | 3DSwinT | CTNet |
|---|---|---|---|---|---|---|---|---|
| 1 | 56.38 | 55.34 | 64.52 | 88.28 | 86.62 | 88.92 | 89.25 | 96.72 |
| 2 | 77.53 | 82.28 | 82.38 | 87.58 | 93.32 | 94.65 | 92.53 | 95.48 |
| 3 | 84.18 | 87.68 | 92.32 | 96.74 | 97.82 | 96.16 | 94.46 | 95.19 |
| 4 | 75.32 | 72.27 | 98.12 | 97.36 | 96.32 | 96.25 | 96.34 | 96.87 |
| 5 | 81.96 | 84.54 | 87.54 | 96.32 | 96.92 | 97.98 | 94.54 | 98.57 |
| 6 | 90.28 | 93.26 | 96.87 | 98.66 | 99.25 | 98.84 | 97.73 | 96.45 |
| 7 | 46.25 | 65.78 | 78.42 | 92.26 | 94.87 | 95.28 | 97.64 | 97.82 |
| 8 | 82.78 | 86.14 | 90.63 | 94.86 | 95.74 | 96.26 | 97.57 | 97.14 |
| 9 | 74.92 | 62.89 | 96.18 | 93.68 | 96.85 | 94.45 | 95.25 | 96.27 |
| AA | 74.44 | 76.89 | 86.35 | 94.01 | 95.10 | 94.42 | 95.03 | 96.72 |
| OA | 75.34 | 78.24 | 88.23 | 95.17 | 96.58 | 96.36 | 96.54 | 97.46 |
| Kappa | 73.48 | 75.84 | 85.98 | 93.28 | 94.92 | 94.13 | 94.62 | 96.16 |
| Id. | 2DCNN | 3DCNN | BTA-Net | HybridSN | UML | SiT | 3DSwinT | CTNet |
|---|---|---|---|---|---|---|---|---|
| 1 | 87.52 | 64.25 | 85.27 | 84.32 | 89.25 | 96.72 | 95.36 | 97.85 |
| 2 | 78.63 | 88.76 | 85.64 | 85.48 | 97.53 | 95.42 | 93.42 | 96.15 |
| 3 | 77.81 | 91.24 | 90.52 | 96.37 | 94.46 | 95.84 | 89.25 | 98.24 |
| 4 | 65.27 | 72.28 | 80.62 | 98.56 | 96.34 | 98.38 | 88.12 | 96.52 |
| 5 | 87.78 | 88.67 | 93.25 | 95.62 | 94.54 | 97.56 | 95.78 | 97.21 |
| 6 | 68.46 | 67.89 | 75.48 | 98.46 | 97.73 | 97.94 | 96.92 | 95.54 |
| 7 | 58.35 | 51.48 | 71.34 | 97.82 | 97.64 | 98.52 | 98.64 | 97.12 |
| 8 | 65.28 | 66.78 | 74.94 | 95.25 | 98.28 | 97.38 | 92.36 | 98.67 |
| 9 | 58.92 | 64.96 | 88.36 | 88.28 | 86.62 | 88.92 | 84.52 | 92.25 |
| 10 | 68.84 | 76.43 | 68.74 | 87.58 | 93.32 | 96.65 | 92.38 | 94.52 |
| 11 | 78.65 | 88.75 | 91.82 | 96.74 | 97.82 | 96.16 | 94.32 | 96.15 |
| 12 | 81.52 | 76.38 | 94.76 | 97.36 | 96.32 | 96.25 | 97.12 | 98.52 |
| 13 | 82.42 | 95.57 | 98.15 | 96.32 | 98.12 | 97.98 | 95.54 | 98.17 |
| 14 | 85.57 | 94.32 | 95.21 | 95.66 | 97.25 | 96.14 | 96.87 | 98.86 |
| 15 | 72.64 | 85.65 | 90.18 | 92.26 | 94.87 | 95.28 | 88.42 | 96.24 |
| 16 | 75.85 | 94.36 | 96.34 | 97.82 | 97.13 | 97.48 | 93.87 | 97.94 |
| AA | 74.59 | 79.24 | 86.19 | 93.99 | 95.50 | 96.41 | 93.31 | 96.74 |
| OA | 77.28 | 82.16 | 88.27 | 95.36 | 96.35 | 97.17 | 94.54 | 98.25 |
| Kappa | 72.45 | 78.22 | 84.35 | 92.15 | 93.26 | 95.28 | 91.19 | 96.37 |
| Id. | 2DCNN | 3DCNN | BTA-Net | HybridSN | UML | SiT | 3DSwinT | CTNet |
|---|---|---|---|---|---|---|---|---|
| 1 | 44.53 | 47.37 | 56.38 | 67.82 | 72.43 | 65.28 | 66.78 | 74.94 |
| 2 | 52.67 | 68.72 | 46.86 | 57.28 | 54.85 | 58.92 | 64.96 | 88.36 |
| 3 | 48.14 | 49.85 | 41.58 | 45.84 | 73.76 | 48.84 | 46.43 | 68.74 |
| 4 | 61.34 | 46.86 | 58.93 | 63.76 | 68.78 | 78.65 | 88.75 | 91.82 |
| 5 | 54.53 | 65.67 | 66.37 | 62.94 | 72.13 | 81.52 | 76.38 | 94.76 |
| 6 | 72.72 | 42.92 | 68.92 | 65.87 | 75.52 | 82.42 | 95.57 | 95.10 |
| 7 | 45.48 | 52.94 | 56.38 | 67.82 | 42.32 | 65.28 | 51.48 | 71.34 |
| AA | 54.20 | 53.47 | 56.48 | 61.62 | 61.40 | 68.70 | 70.05 | 83.58 |
| OA | 55.64 | 55.84 | 57.83 | 62.17 | 63.28 | 70.36 | 72.54 | 84.46 |
| Kappa | 53.48 | 52.84 | 55.98 | 60.28 | 60.92 | 67.13 | 68.62 | 83.16 |
| Methods | PU | PUC | SV | Houston13 | ||||
|---|---|---|---|---|---|---|---|---|
| Train (s) | Test (s) | Train (s) | Test (s) | Train (s) | Test (s) | Train (s) | Test (s) | |
| 2DCNN [24] | 247.2 | 3.02 | 214.2 | 1.52 | 387.6 | 3.23 | 92.4 | 1.12 |
| 3DCNN [36] | 788.4 | 8.19 | 435 | 3.46 | 622.2 | 7.54 | 247.2 | 1.28 |
| HybridSN [37] | 561 | 4.51 | 271.2 | 2.17 | 615.6 | 5.47 | 149.4 | 1.53 |
| BTA-Net [40] | 687 | 8.06 | 502.2 | 4.29 | 735.6 | 7.52 | 319.2 | 2.18 |
| 3DSwinT [41] | 508.2 | 5.12 | 513.6 | 3.42 | 812.4 | 7.58 | 292.2 | 2.45 |
| UML [42] | 510.6 | 4.23 | 445.2 | 4.18 | 800.4 | 6.26 | 249.6 | 1.53 |
| SiT [43] | 370.2 | 2.97 | 559.2 | 3.57 | 850.8 | 9.62 | 261 | 2.39 |
| CTNet | 273.6 | 3.52 | 251.4 | 2.16 | 439.2 | 4.16 | 132.6 | 1.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yadav, D.P.; Kumar, D.; Jalal, A.S.; Sharma, B.; Webber, J.L.; Mehbodniya, A. Advancing Hyperspectral Image Analysis with CTNet: An Approach with the Fusion of Spatial and Spectral Features. Sensors 2024, 24, 2016. https://doi.org/10.3390/s24062016
Yadav DP, Kumar D, Jalal AS, Sharma B, Webber JL, Mehbodniya A. Advancing Hyperspectral Image Analysis with CTNet: An Approach with the Fusion of Spatial and Spectral Features. Sensors. 2024; 24(6):2016. https://doi.org/10.3390/s24062016
Chicago/Turabian StyleYadav, Dhirendra Prasad, Deepak Kumar, Anand Singh Jalal, Bhisham Sharma, Julian L. Webber, and Abolfazl Mehbodniya. 2024. "Advancing Hyperspectral Image Analysis with CTNet: An Approach with the Fusion of Spatial and Spectral Features" Sensors 24, no. 6: 2016. https://doi.org/10.3390/s24062016