
Object-Oriented and Visual-Based Localization in Urban Environments


Abstract
1. Introduction
1.1. Background
1.2. Problems and Challenges
- A low-cost localization method using a single camera and mobile CPU/GPU for IoT applications.
- Reusing off-the-shelf object detector features dynamically at appropriate scales for accurate, faster, and robust pose estimation without requiring an additional network or point feature detector.
- Flexibility to handle not only planar pictures but also daily 3D objects without CAD models, suitable for complex urban indoor and outdoor environments.
- Selective pose estimation from either the library or actual scene object models for real-time performance, offering a practical solution for IoT localization.
2. Related Work
2.1. Visual Feature-Matching Based Localization
2.2. Visual Object Based Localization
2.3. Visual Feature Fusion Techniques
3. Model Architecture
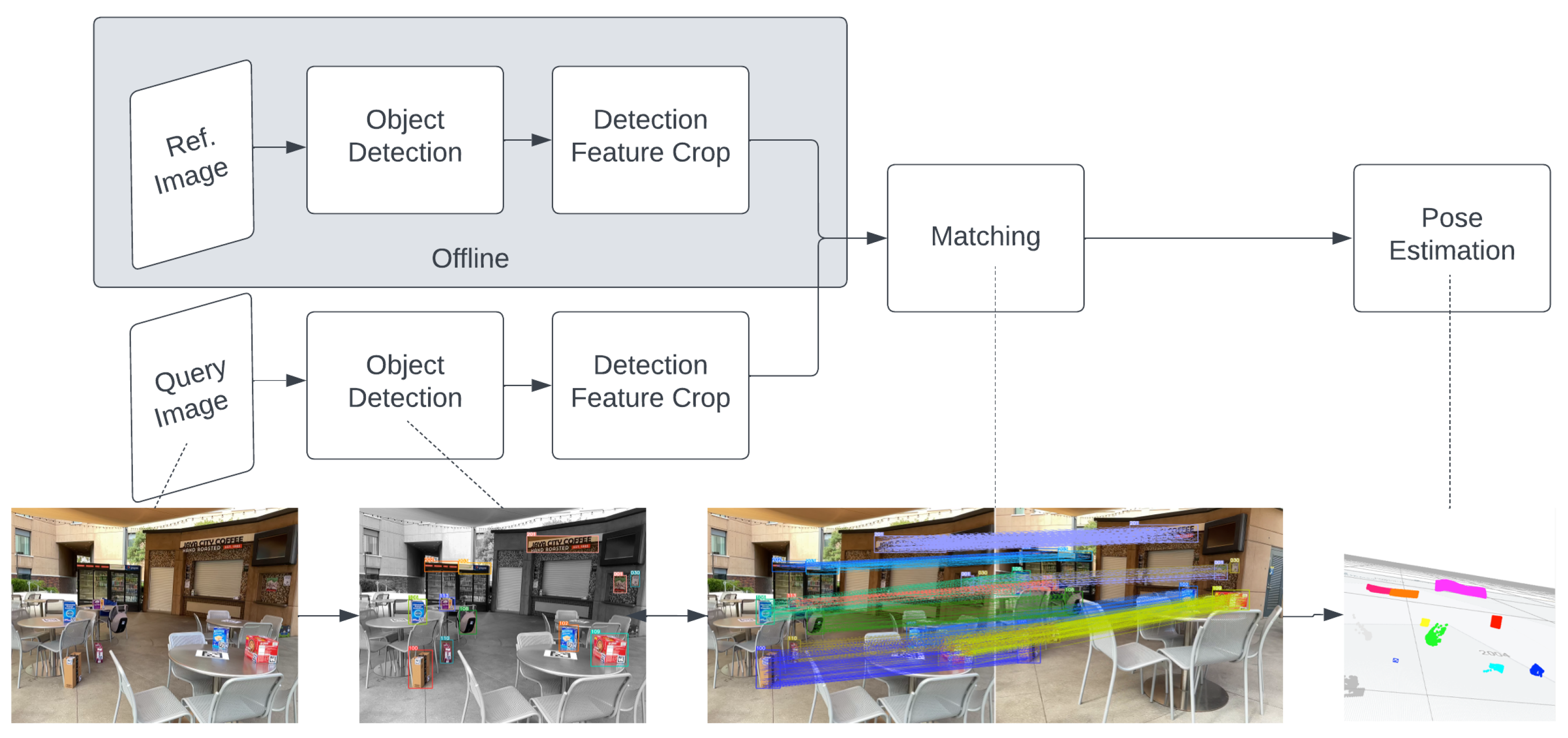
3.1. Object-Oriented Visual-Based Localization
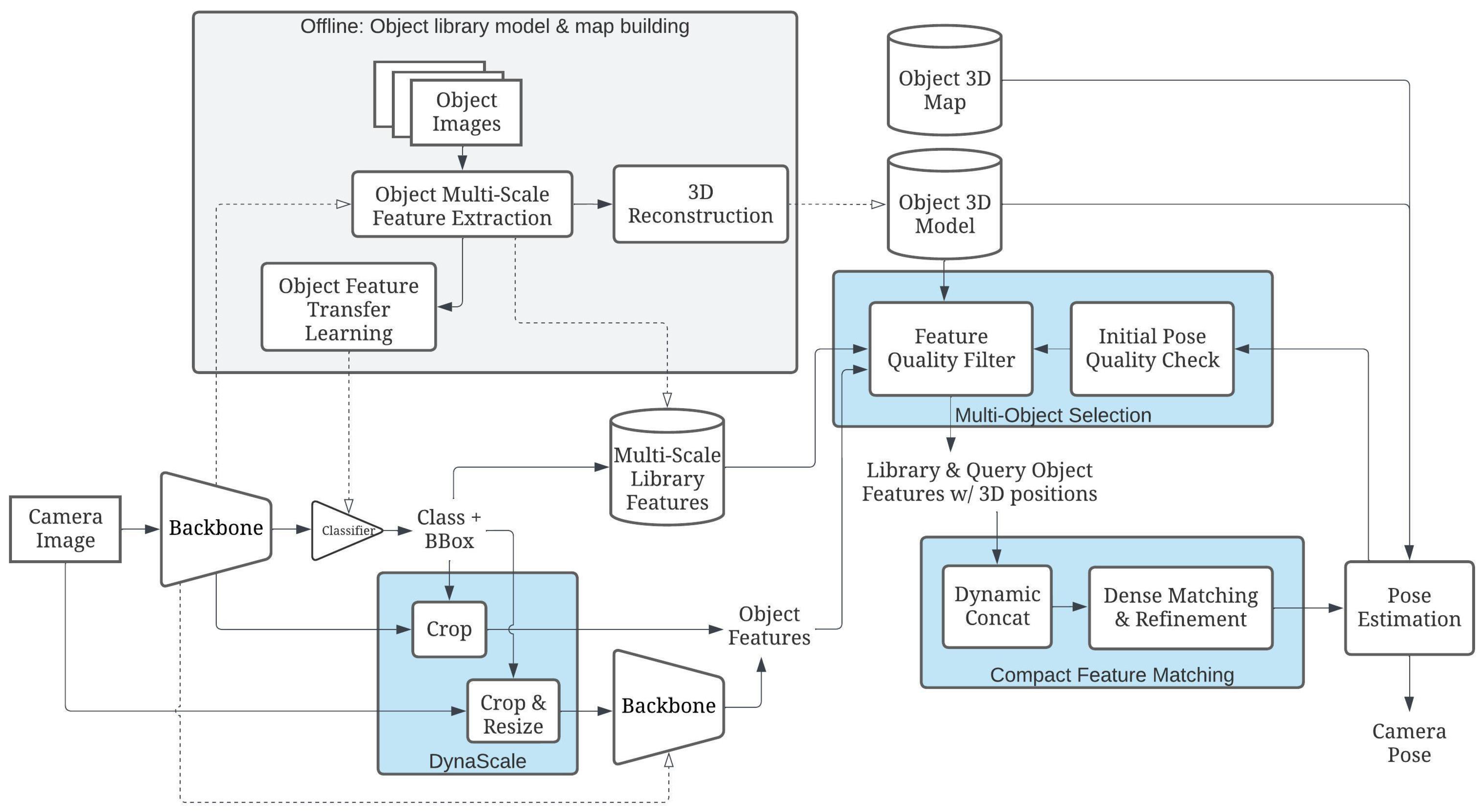
3.2. OOPose Framework Overview
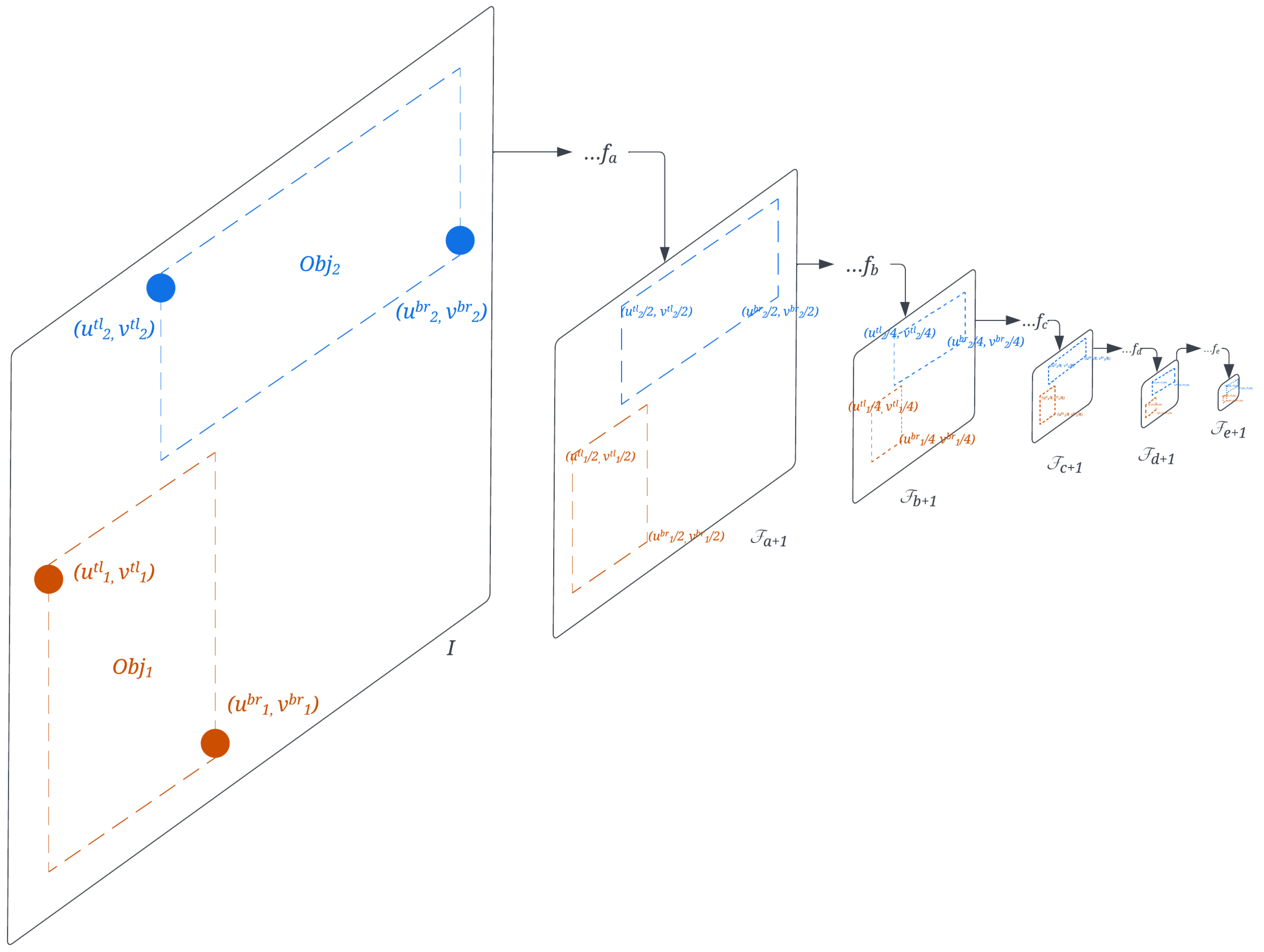
3.2.1. DynaScale2: Image Resolution Selection for Object Matching
3.2.2. Compact Feature Matching
3.2.3. Multi-Object Selection and Pose Estimation
| Algorithm 1 Multi-Object Selection for Matching. |
| Require: ▹ # of Objects to pick, Query img, Library & NN |
| Ensure: ▹ Object query & library features selected for matching |
| 1: ▹ Detect objects & Extract features |
| 2: |
| 3: for do |
| 4: FAST ▹ Get #FAST from RGB of object region |
| 5: |
| 6: |
| 7: |
| 8: end for |
| 9: |
| 10: |
| 11: for do |
| 12: |
| 13: |
| 14: |
| 15: end for |
| Algorithm 2 Initial Object Pose Quality Check. | |
| Require: | ▹ N/A |
| Ensure: | ▹ N/A |
| 1: if is not the first-time detected then | |
| 2: return | |
| 3: end if | |
| 4: | |
| 5: | |
| 6: | |
| 7: while is not empty do | |
| 8: | |
| 9: | |
| 10: | |
| 11: if QUALITYTEST() is not passed then | |
| 12: continue | |
| 13: end if | |
| 14: .add() | |
| 15: | |
| 16: () | |
| 17: project all endpoints of faces in by T | |
| 18: if .size() then | |
| 19: for in neighboring face IDs of do | |
| 20: if in or any of its endpoints in area of then | |
| 21: continue | |
| 22: end if | |
| 23: .add() | |
| 24: mask out the area of in | |
| 25: end for | |
| 26: end if | |
| 27: end while | |
4. Ablation Study
4.1. Metrics
4.2. Backbone for Feature Matching
4.3. Input Scale Change for Real-Time Performance
4.4. Multi-Object Selection
4.5. Execution Time of First-Time Object Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| OOPose | Object-Oriented Pose |
| AR | Augmented Reality |
| IoT | Internet of Things |
| VBL | Visual-Based Localization |
| GPS | Global Positioning System |
| CPU | Central Processing Unit |
| GPU | Graphic Processing Unit |
| CAD | Computer-Aided Design |
| ORB | Oriented FAST and Rotated BRIEF |
| FAST | Features from Accelerated Segment Test |
| CFM | Compact Feature Matching |
| FLOPS | FLoating-point Operations Per Second |
References
- Kyrarini, M.; Lygerakis, F.; Rajavenkatanarayanan, A.; Sevastopoulos, C.; Nambiappan, H.R.; Chaitanya, K.K.; Babu, A.R.; Mathew, J.; Makedon, F. A Survey of Robots in Healthcare. Technologies 2021, 9, 8. [Google Scholar] [CrossRef]
- Valdez, M.; Cook, M.; Potter, S. Humans and robots coping with crisis—Starship, COVID-19 and urban robotics in an unpredictable world. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 2596–2601. [Google Scholar] [CrossRef]
- Parmiggiani, A.; Fiorio, L.; Scalzo, A.; Sureshbabu, A.V.; Randazzo, M.; Maggiali, M.; Pattacini, U.; Lehmann, H.; Tikhanoff, V.; Domenichelli, D.; et al. The design and validation of the R1 personal humanoid. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 674–680. [Google Scholar] [CrossRef]
- Feigl., T.; Porada., A.; Steiner., S.; Löffler., C.; Mutschler., C.; Philippsen., M. Localization Limitations of ARCore, ARKit, and Hololens in Dynamic Large-scale Industry Environments. In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2020)—GRAPP, Valletta, Malta, 27–29 February 2020; pp. 307–318. [Google Scholar] [CrossRef]
- Lee, L.H.; Braud, T.; Zhou, P.; Wang, L.; Xu, D.; Lin, Z.; Kumar, A.; Bermejo, C.; Hui, P. All One Needs to Know about Metaverse: A Complete Survey on Technological Singularity, Virtual Ecosystem, and Research Agenda. arXiv 2021, arXiv:2110.05352. [Google Scholar]
- Piasco, N.; Sidibé, D.; Demonceaux, C.; Gouet-Brunet, V. A survey on Visual-Based Localization: On the benefit of heterogeneous data. Pattern Recognit. 2018, 74, 90–109. [Google Scholar] [CrossRef]
- Masone, C.; Caputo, B. A Survey on Deep Visual Place Recognition. IEEE Access 2021, 9, 19516–19547. [Google Scholar] [CrossRef]
- Sarlin, P.E.; Cadena, C.; Siegwart, R.; Dymczyk, M. From Coarse to Fine: Robust Hierarchical Localization at Large Scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yan, S.; Liu, Y.; Wang, L.; Shen, Z.; Peng, Z.; Liu, H.; Zhang, M.; Zhang, G.; Zhou, X. Long-Term Visual Localization with Mobile Sensors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 17–24 June 2023; pp. 17245–17255. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Meng, Y.; Lin, K.J.; Tsai, B.L.; Chuang, C.C.; Cao, Y.; Zhang, B. Visual-Based Localization Using Pictorial Planar Objects in Indoor Environment. Appl. Sci. 2020, 10, 8583. [Google Scholar] [CrossRef]
- Meng, Y.; Lin, K.J.; Tsai, B.L.; Shih, C.S.; Zhang, B. PicPose: Using Picture Posing for Localization Service on IoT Devices. In Proceedings of the 2019 IEEE 12th Conference on Service-Oriented Computing and Applications (SOCA), Kaohsiung, Taiwan, 18–21 November 2019. [Google Scholar]
- Romero-Ramirez, F.J.; Muñoz-Salinas, R.; Medina-Carnicer, R. Speeded up detection of squared fiducial markers. Image Vis. Comput. 2018, 76, 38–47. [Google Scholar] [CrossRef]
- Tsai, B.L.; Lin, K.J.; Cao, Y.; Meng, Y. DynaScale: An Intelligent Image Scale Selection Framework for Visual Matching in Smart IoT. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Fiji, 14–16 December 2020; pp. 1166–1173. [Google Scholar] [CrossRef]
- Efe, U.; Ince, K.G.; Alatan, A. DFM: A Performance Baseline for Deep Feature Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Virtual, 19–25 June 2021; pp. 4284–4293. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-From-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Arandjelović, R.; Zisserman, A. Three things everyone should know to improve object retrieval. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2911–2918. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and Better: A Machine Learning Approach to Corner Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. LIFT: Learned Invariant Feature Transform. arXiv 2016, arXiv:1603.09114. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint description and detection of local features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8092–8101. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. arXiv 2017, arXiv:1712.07629. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching With Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Choudhary, S.; Narayanan, P.J. Visibility Probability Structure from SfM Datasets and Applications. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; pp. 130–143. [Google Scholar]
- Larsson, V.; Fredriksson, J.; Toft, C.; Kahl, F. Outlier Rejection for Absolute Pose Estimation with Known Orientation. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016; pp. 45.1–45.12. [Google Scholar] [CrossRef]
- Li, Y.; Snavely, N.; Huttenlocher, D.P. Location Recognition Using Prioritized Feature Matching. In Proceedings of the Computer Vision—ECCV 2010, Heraklion, Greece, 5–11 September 2010; pp. 791–804. [Google Scholar]
- Lim, H.; Sinha, S.N.; Cohen, M.F.; Uyttendaele, M. Real-time image-based 6-DOF localization in large-scale environments. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1043–1050. [Google Scholar] [CrossRef]
- Lynen, S.; Zeisl, B.; Aiger, D.; Bosse, M.; Hesch, J.; Pollefeys, M.; Siegwart, R.; Sattler, T. Large-scale, real-time visual-inertial localization revisited. Int. J. Robot. Res. 2019, 39, 1061–1084. [Google Scholar] [CrossRef]
- Sattler, T.; Leibe, B.; Kobbelt, L. Efficient & Effective Prioritized Matching for Large-Scale Image-Based Localization. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1744–1756. [Google Scholar] [CrossRef] [PubMed]
- Donoser, M.; Schmalstieg, D. Discriminative Feature-to-Point Matching in Image-Based Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Heisterklaus, I.; Qian, N.; Miller, A. Image-based pose estimation using a compact 3D model. In Proceedings of the 2014 IEEE Fourth International Conference on Consumer Electronics Berlin (ICCE-Berlin), Berlin, Germany, 7–10 September 2014; pp. 327–330. [Google Scholar] [CrossRef]
- Li, Y.; Snavely, N.; Huttenlocher, D.; Fua, P. Worldwide Pose Estimation Using 3D Point Clouds. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; pp. 15–29. [Google Scholar]
- Sattler, T.; Havlena, M.; Radenovic, F.; Schindler, K.; Pollefeys, M. Hyperpoints and Fine Vocabularies for Large-Scale Location Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Sattler, T.; Havlena, M.; Schindler, K.; Pollefeys, M. Large-Scale Location Recognition and the Geometric Burstiness Problem. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Svärm, L.; Enqvist, O.; Kahl, F.; Oskarsson, M. City-Scale Localization for Cameras with Known Vertical Direction. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1455–1461. [Google Scholar] [CrossRef] [PubMed]
- Svarm, L.; Enqvist, O.; Oskarsson, M.; Kahl, F. Accurate Localization and Pose Estimation for Large 3D Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Zeisl, B.; Sattler, T.; Pollefeys, M. Camera Pose Voting for Large-Scale Image-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Sattler, T.; Maddern, W.; Toft, C.; Torii, A.; Hammarstrand, L.; Stenborg, E.; Safari, D.; Okutomi, M.; Pollefeys, M.; Sivic, J.; et al. Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, C.; Yuen, J.; Torralba, A. SIFT Flow: Dense Correspondence across Scenes and Its Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 978–994. [Google Scholar] [CrossRef] [PubMed]
- Rocco, I.; Cimpoi, M.; Arandjelović, R.; Torii, A.; Pajdla, T.; Sivic, J. Neighbourhood Consensus Networks. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Germain, H.; Bourmaud, G.; Lepetit, V. S2DNet: Learning Image Features for Accurate Sparse-to-Dense Matching. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Sattler, T.; Torii, A.; Sivic, J.; Pollefeys, M.; Taira, H.; Okutomi, M.; Pajdla, T. Are Large-Scale 3D Models Really Necessary for Accurate Visual Localization? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017.
- Arandjelovic, R.; Zisserman, A. All About VLAD. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Arandjelović, R.; Zisserman, A. Visual Vocabulary with a Semantic Twist. In Proceedings of the Computer Vision—ACCV 2014, Singapore, 1–5 November 2015; pp. 178–195. [Google Scholar]
- Kobyshev, N.; Riemenschneider, H.; Gool, L.V. Matching Features Correctly through Semantic Understanding. In Proceedings of the 2014 2nd International Conference on 3D Vision, Tokyo, Japan, 8–11 December 2014; Volume 1, pp. 472–479. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Pollefeys, M.; Geiger, A.; Sattler, T. Semantic Visual Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Singh, G.; Košecká, J. Semantically Guided Geo-location and Modeling in Urban Environments. In Large-Scale Visual Geo-Localization; Zamir, A.R., Hakeem, A., Van Gool, L., Shah, M., Szeliski, R., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 101–120. [Google Scholar] [CrossRef]
- Toft, C.; Stenborg, E.; Hammarstrand, L.; Brynte, L.; Pollefeys, M.; Sattler, T.; Kahl, F. Semantic Match Consistency for Long-Term Visual Localization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Labbé, Y.; Carpentier, J.; Aubry, M.; Sivic, J. CosyPose: Consistent Multi-view Multi-object 6D Pose Estimation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 574–591. [Google Scholar]
- Li, Y.; Wang, G.; Ji, X.; Xiang, Y.; Fox, D. DeepIM: Deep Iterative Matching for 6D Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. arXiv 2018, arXiv:1711.00199. [Google Scholar]
- Oberweger, M.; Rad, M.; Lepetit, V. Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Park, K.; Patten, T.; Vincze, M. Pix2Pose: Pixel-Wise Coordinate Regression of Objects for 6D Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Chan, A.; Derpanis, K.G.; Daniilidis, K. 6-DoF object pose from semantic keypoints. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2011–2018. [Google Scholar] [CrossRef]
- Wang, H.; Sridhar, S.; Huang, J.; Valentin, J.; Song, S.; Guibas, L.J. Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Park, K.; Mousavian, A.; Xiang, Y.; Fox, D. LatentFusion: End-to-End Differentiable Reconstruction and Rendering for Unseen Object Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ahmadyan, A.; Zhang, L.; Ablavatski, A.; Wei, J.; Grundmann, M. Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild With Pose Annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2021; pp. 7822–7831. [Google Scholar]
- Sun, J.; Wang, Z.; Zhang, S.; He, X.; Zhao, H.; Zhang, G.; Zhou, X. OnePose: One-Shot Object Pose Estimation Without CAD Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6825–6834. [Google Scholar]
- Lin, X.; Sun, S.; Huang, W.; Sheng, B.; Li, P.; Feng, D.D. EAPT: Efficient Attention Pyramid Transformer for Image Processing. IEEE Trans. Multimed. 2023, 25, 50–61. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, W.; Li, J.; Zhuang, P.; Sun, H.; Xu, Y.; Li, C. CVANet: Cascaded visual attention network for single image super-resolution. Neural Netw. 2024, 170, 622–634. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Li, Z.; Li, G.; Zhuang, P.; Hou, G.; Zhang, Q.; Li, C. GACNet: Generate Adversarial-Driven Cross-Aware Network for Hyperspectral Wheat Variety Identification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5503314. [Google Scholar] [CrossRef]
- Zhao, W.; Li, C.; Zhang, W.; Yang, L.; Zhuang, P.; Li, L.; Fan, K.; Yang, H. Embedding Global Contrastive and Local Location in Self-Supervised Learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2275–2289. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, L.; Zhuang, P.; Li, G.; Pan, X.; Zhao, W.; Li, C. Underwater Image Enhancement via Weighted Wavelet Visual Perception Fusion. IEEE Trans. Circuits Syst. Video Technol. 2023, 1. [Google Scholar] [CrossRef]
- Chen, Z.; Qiu, G.; Li, P.; Zhu, L.; Yang, X.; Sheng, B. MNGNAS: Distilling Adaptive Combination of Multiple Searched Networks for One-Shot Neural Architecture Search. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13489–13508. [Google Scholar] [CrossRef] [PubMed]
- Jiang, N.; Sheng, B.; Li, P.; Lee, T.Y. PhotoHelper: Portrait Photographing Guidance Via Deep Feature Retrieval and Fusion. IEEE Trans. Multimed. 2023, 25, 2226–2238. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Sheng, B.; Li, P.; Yang, P.; Feng, D.D.; Qi, J. Automatic Detection and Classification System of Domestic Waste via Multimodel Cascaded Convolutional Neural Network. IEEE Trans. Ind. Inform. 2022, 18, 163–173. [Google Scholar] [CrossRef]
- Sheng, B.; Li, P.; Ali, R.; Chen, C.L.P. Improving Video Temporal Consistency via Broad Learning System. IEEE Trans. Cybern. 2022, 52, 6662–6675. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.; et al. ultralytics yolov5: v7.0—YOLOv5 SOTA Realtime Instance Segmentation. Zenodo 2022, 1. [Google Scholar] [CrossRef]
- Muñoz-Salinas, R.; Marín-Jimenez, M.J.; Yeguas-Bolivar, E.; Medina-Carnicer, R. Mapping and localization from planar markers. Pattern Recognit. 2018, 73, 158–171. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Merriaux, P.; Dupuis, Y.; Boutteau, R.; Vasseur, P.; Savatier, X. A Study of Vicon System Positioning Performance. Sensors 2017, 17, 1591. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004; ISBN 0521540518. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Speed | Object Content | Actual Scale | Stages | Dynamic Adjust Input Image Size | Multi-Object Selection For Efficient Matching | Object Type | |
|---|---|---|---|---|---|---|---|---|---|
| Direct Image (VPL [7]) | Low | O(library size) | N/A | No | Local feature detection + description + global clustering | No | No, one global descriptor per image | N/A | |
| Indirect Pixels (mono-ORBSLAM3 [10]) | Med-High | Medium | N/A | No | Local feature detection + description | No | No, Pixel descriptors from whole image | N/A | |
| Object-based | ArUco [13] | High | High | Square-bordered encoded blocks | Yes | Corner detection + cell decoding | No | No, match all squares | 2D |
| Picpose [12] | High | Med-High | Any patterned plannar picture | Yes | Object detection + local feature detection + description | No | No, match all object regions | 2D | |
| OOPose | High | Med-High | Any patterned object | Yes | Object detection + dense feature crop | Yes | Yes | 3D | |
| VGG19 | MNV3-S | MNV3-L | ResNet50 | ResNet101 | |
|---|---|---|---|---|---|
| Pose Error (m) | 0.183 | 0.232 (+26.7%) | 0.206 (+12.5%) | 0.155 (−15.3%) | 0.168 (−8.2%) |
| Valid Frames (%) | 96.0 | 73.6 (−22.4%) | 85.4 (−10.6%) | 39.4 (−56.6%) | 45.4 (−50.6%) |
| Time (s) | 0.219 | 0.034 (−84.5%) | 0.040 (−84.4%) | 0.081 (−63.0%) | 0.156 (−28.7%) |
| CFM-416 | Sparse ORB-2k | |
|---|---|---|
| DynaScale2 | Avg error: 1.06 cm (100%) Min error: 0.5 cm Max error: 2.3 cm Avg Time: 86 ms (100%) | Avg err: 1.4 cm (+32.1%) Min error: 0.3 cm Max error: 4.6 cm Avg Time: 87 ms (+1.16%) |
| Normal Scale | Avg error: 2.56 cm (+141%) Min error: 1.0 cm Max error: 7.3 cm Avg Time: 747 ms (+768%) | 33% frames failed (N/A) Min error: 0.3 cm Max error: 0.7 cm Avg Time: 92 ms (+6.97%) |
| 640x640 | 512x512 | |||
|---|---|---|---|---|
| YOLOv5s | YOLOv5s-mv3 | YOLOv5s | YOLOv5s-mv3 | |
| CPU-pytorch | 103.76 ms (100%) | 63.21 ms (100%) | 77.32 ms (100%) | 45.31 ms (100%) |
| CPU-ONNX | 78.88 ms | 55.41 ms | 52.40 ms | 33.56 ms |
| JN-pytorch | 170 ms (+60%) | 119.6 ms (+20%) | 111.86 ms (+40%) | 80.82 ms (+80%) |
| JN-trt | 120 ms | 85.4 ms | 74.43 ms | 73.79 ms |
| JN-trt-FP16 | 82 ms | 67.4 ms | 54.46 ms | N/A |
| JX-pytorch | 49.61 ms (−53%) | 44.58 ms (−29%) | 47.83 ms (−38%) | 44.74 ms (−1%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, B.-L.; Lin, K.-J. Object-Oriented and Visual-Based Localization in Urban Environments. Sensors 2024, 24, 2014. https://doi.org/10.3390/s24062014
Tsai B-L, Lin K-J. Object-Oriented and Visual-Based Localization in Urban Environments. Sensors. 2024; 24(6):2014. https://doi.org/10.3390/s24062014
Chicago/Turabian StyleTsai, Bo-Lung, and Kwei-Jay Lin. 2024. "Object-Oriented and Visual-Based Localization in Urban Environments" Sensors 24, no. 6: 2014. https://doi.org/10.3390/s24062014
APA StyleTsai, B.-L., & Lin, K.-J. (2024). Object-Oriented and Visual-Based Localization in Urban Environments. Sensors, 24(6), 2014. https://doi.org/10.3390/s24062014