
Soundscape Characterization Using Autoencoders and Unsupervised Learning
 , , , , and
, , , , and
Abstract
:1. Introduction
2. Related Work
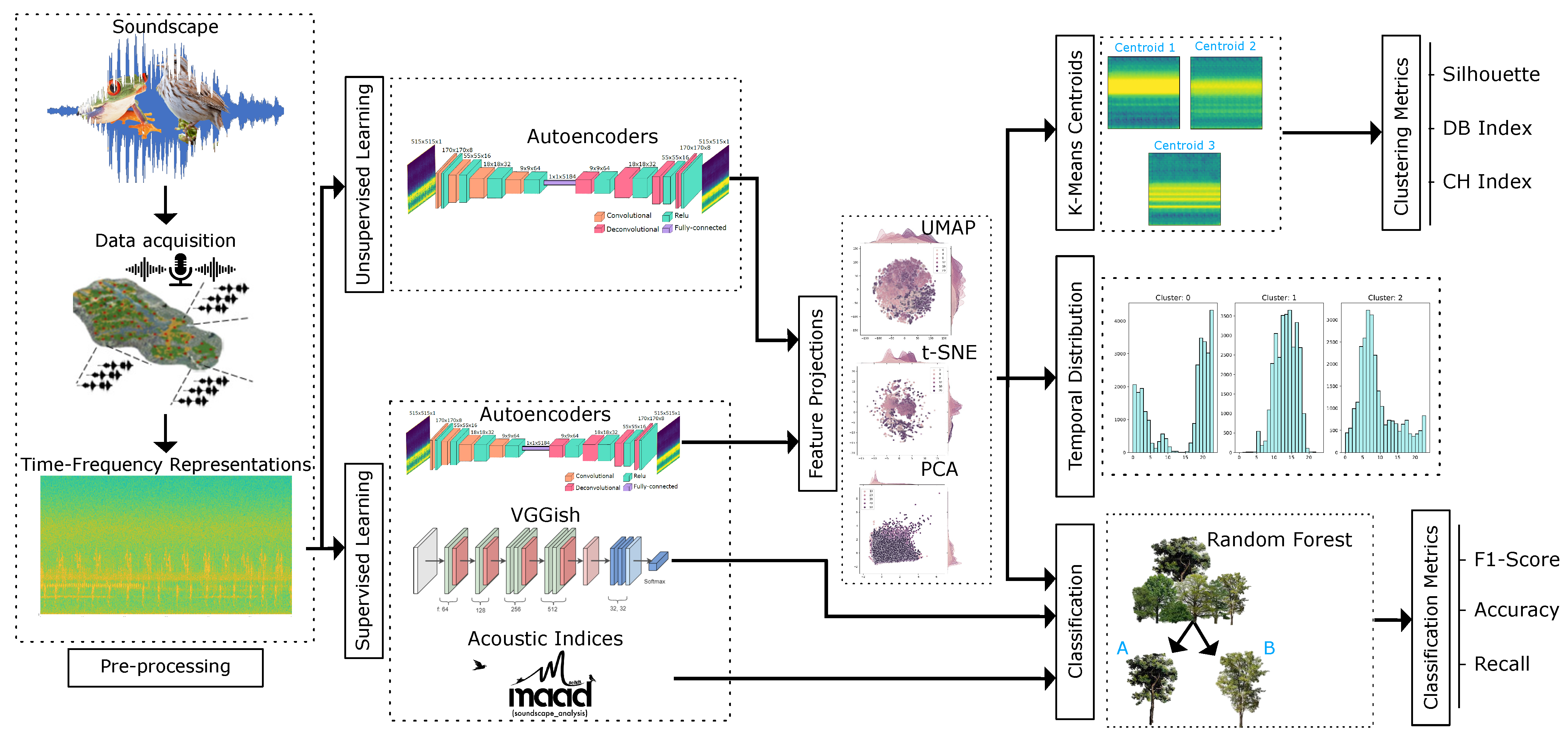
3. Materials and Methods
3.1. Study Site

3.2. Pre-Processing
3.3. Spectrograms Computation and Parameterization
3.4. Autoencoders
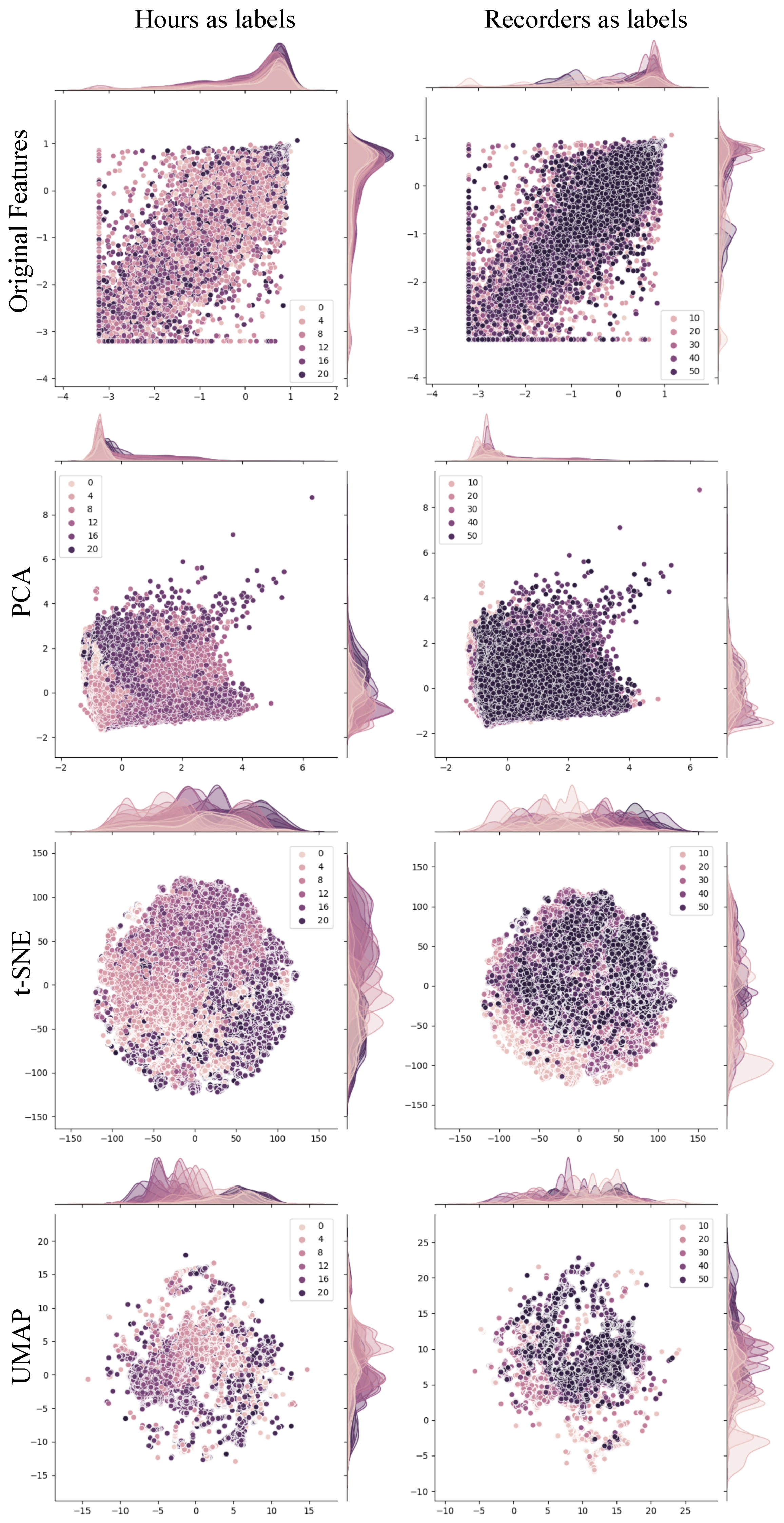
3.5. Feature Projection
3.5.1. Principal Component Analysis (PCA)
3.5.2. t-Distributed Stochastic Neighbor Embedding (t-SNE)
3.5.3. Uniform Manifold Approximation and Projection (UMAP)
3.6. K-Means Clustering
3.7. Performance Metrics
- Accuracy: provides a global assessment of the model’s correctness by quantifying the ratio of correctly predicted instances to the total number of instances. Accuracy is defined in Equation (8).
- Recall: also known as sensitivity, or the true positive rate, recall measures the model’s capability to accurately identify positive instances from the entire pool of actual positive instances, as depicted in Equation (9).
- F1-score: the F1-score is obtained as the harmonic mean of precision and recall, offering a balanced measure that considers both false positives and false negatives, as described in Equation (10).
- Silhouette Coefficient: provides a measure of cluster cohesion and separation, as described in Equation (11). Cohesion is assessed based on the similarity of data instances within a single cluster, while separation is determined by the dissimilarity between instances from different clusters.where is the average distance from the i-th data point to other data points in the same cluster (cohesion) and is the smallest average distance from the i-th data point to data points in a different cluster, minimized over clusters (separation).The silhouette score for the entire dataset is the average of the silhouette score for each instance. The overall silhouette score can be calculated as in Equation (12).
- Calinski–Harabasz (CH) index: measures the ratio of between-cluster variance to within-cluster variance. It helps in assessing how well-separated the clusters are from each other. This index is calculated using Equation (13).where is the between-cluster scatter matrix, is the within-cluster scatter matrix, N is the total number of data points, and k is the number of clusters.
- Davies–Bouldin (DB) index: computes the average similarity between each cluster and its most similar cluster. It provides insights into the compactness and separability of the clusters. The DB index is computed as in Equation (14).where n is the number of clusters, is the average distance from the centroid of cluster i to the points in cluster i, is the centroid of cluster i, and is the distance between centroids and .
4. Experiments
4.1. Autoencoder Architecture and Training
4.2. Supervised Learning Approach
- The autoencoder features, extracted from our trained autoencoder architecture.
- Feature vectors comprising sixty distinct acoustic indices computed using the scikit-maad Python module [50].
- The VGGish feature embedding, obtained from a pre-trained Convolutional Neural Network (17 layers) inspired by the VGG networks typically used for sound classification.
4.3. Unsupervised Learning Approach
5. Results
5.1. Autoencoder Training
5.2. Feature Projections
5.3. Classification of Landscape Type Using Supervised Learning
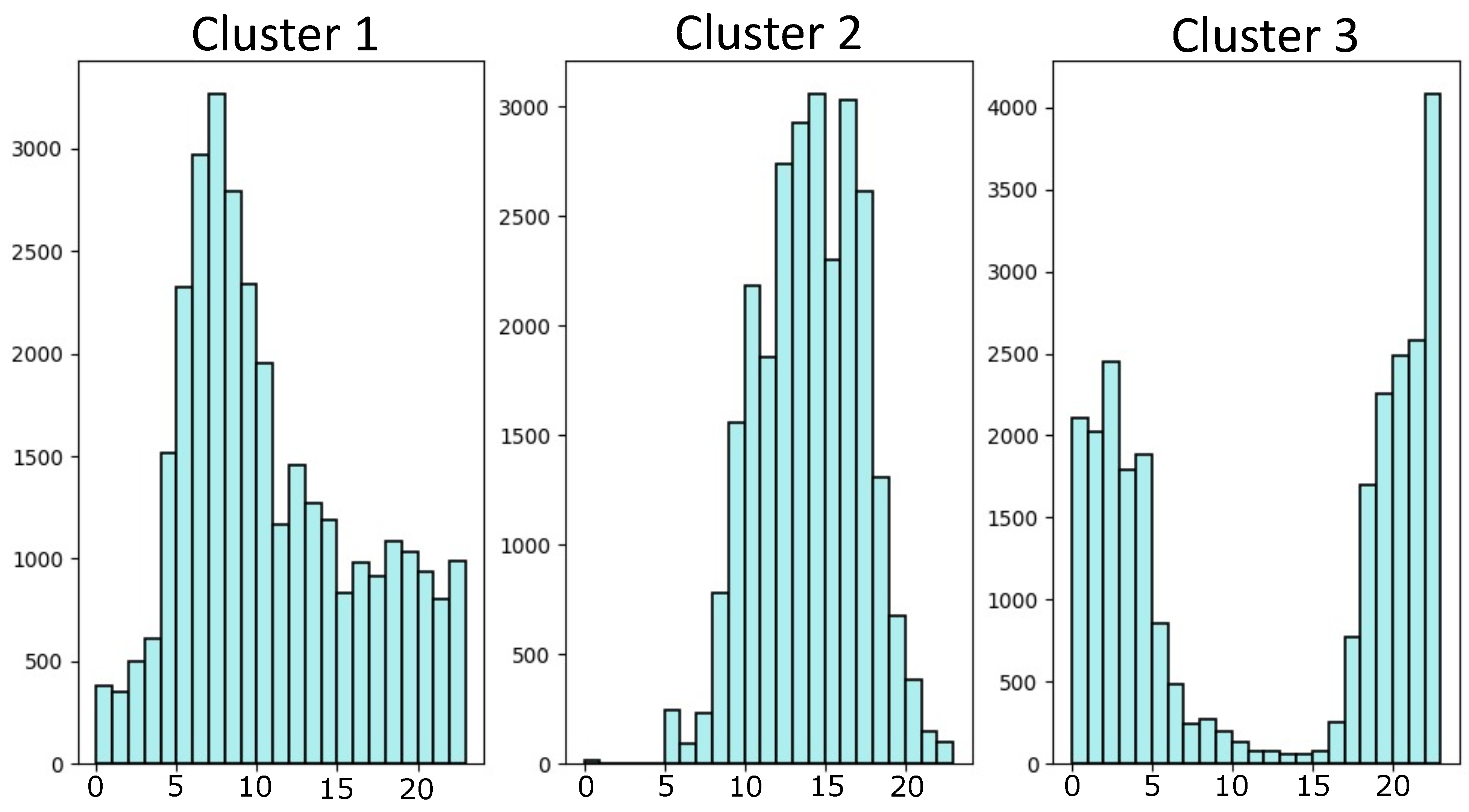
5.4. Unsupervised Learning Results
6. Discussion and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Quinn, C.A.; Burns, P.; Gill, G.; Baligar, S.; Snyder, R.L.; Salas, L.; Goetz, S.J.; Clark, M.L. Soundscape classification with convolutional neural networks reveals temporal and geographic patterns in ecoacoustic data. Ecol. Indic. 2022, 138, 108831. [Google Scholar] [CrossRef]
- Gan, H.; Zhang, J.; Towsey, M.; Truskinger, A.; Stark, D.; van Rensburg, B.J.; Li, Y.; Roe, P. Data selection in frog chorusing recognition with acoustic indices. Ecol. Inform. 2020, 60, 101160. [Google Scholar] [CrossRef]
- Siddagangaiah, S.; Chen, C.F.; Hu, W.C.; Akamatsu, T.; McElligott, M.; Lammers, M.O.; Pieretti, N. Automatic detection of dolphin whistles and clicks based on entropy approach. Ecol. Indic. 2020, 117, 106559. [Google Scholar] [CrossRef]
- Fink, D.; Auer, T.; Johnston, A.; Ruiz-Gutierrez, V.; Hochachka, W.M.; Kelling, S. Modeling avian full annual cycle distribution and population trends with citizen science data. Ecol. Appl. 2020, 30, e02056. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, S.L.; Bicknell, J.E.; Edwards, D.P.; Deere, N.J.; Bernard, H.; Davies, Z.G.; Struebig, M.J. Spatial replication and habitat context matters for assessments of tropical biodiversity using acoustic indices. Ecol. Indic. 2020, 119, 106717. [Google Scholar] [CrossRef]
- Lahoz-Monfort, J.J.; Magrath, M.J. A Comprehensive Overview of Technologies for Species and Habitat Monitoring and Conservation. BioScience 2021, 71, 1038–1062. [Google Scholar] [CrossRef] [PubMed]
- Gibb, R.; Browning, E.; Glover-Kapfer, P.; Jones, K.E. Emerging opportunities and challenges for passive acoustics in ecological assessment and monitoring. Methods Ecol. Evol. 2019, 10, 169–185. [Google Scholar] [CrossRef]
- Irfan, M.; Mushtaq, Z.; Khan, N.A.; Althobiani, F.; Mursal, S.N.F.; Rahman, S.; Magzoub, M.A.; Latif, M.A.; Yousufzai, I.K. Improving Bearing Fault Identification by Using Novel Hybrid Involution-Convolution Feature Extraction With Adversarial Noise Injection in Conditional GANs. IEEE Access 2023, 11, 118253–118267. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A Review of Machine Learning and Deep Learning Applications. In Proceedings of the 2018 4th International Conference on Computing, Communication Control and Automation, ICCUBEA 2018, Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Keen, S.C.; Odom, K.J.; Webster, M.S.; Kohn, G.M.; Wright, T.F.; Araya-Salas, M. A machine learning approach for classifying and quantifying acoustic diversity. Methods Ecol. Evol. 2021, 12, 1213–1225. [Google Scholar] [CrossRef]
- Brodie, S.; Allen-Ankins, S.; Towsey, M.; Roe, P.; Schwarzkopf, L. Automated species identification of frog choruses in environmental recordings using acoustic indices. Ecol. Indic. 2020, 119, 106852. [Google Scholar] [CrossRef]
- Lauha, P.; Panu, S.; Petteri, L.; Lisa, G.; Tobias, R.; Sebastian, S.; Ovaskainen, O. Domain-specific neural networks improve automated bird sound recognition already with small amount of local data. Methods Ecol. Evol. 2022, 13, 2799–2810. [Google Scholar] [CrossRef]
- Dufourq, E.; Batist, C.; Foquet, R.; Durbach, I. Passive acoustic monitoring of animal populations with transfer learning. Ecol. Inform. 2022, 70, 101688. [Google Scholar] [CrossRef]
- Zhang, C.; Zhan, H.; Hao, Z.; Gao, X. Classification of Complicated Urban Forest Acoustic Scenes with Deep Learning Models. Forests 2023, 14, 206. [Google Scholar] [CrossRef]
- Gibb, K.A.; Eldridge, A. Towards Interpretable Learned Representations for Ecoacoustics Using Variational Auto-Encoding. Ecol. Inform. 2024, 80, 102449. [Google Scholar] [CrossRef]
- Hilasaca, L.H.; Ribeiro, M.C.; Minghim, R. Visual active learning for labeling: A case for soundscape ecology data. Information 2021, 12, 265. [Google Scholar] [CrossRef]
- Sun, Y.J.; Yen, S.C.; Lin, T.H. soundscape IR: A source separation toolbox for exploring acoustic diversity in soundscapes. Methods Ecol. Evol. 2022, 13, 2347–2355. [Google Scholar] [CrossRef]
- Ulloa, J.S.; Aubin, T.; Llusia, D.; Bouveyron, C.; Sueur, J. Estimating animal acoustic diversity in tropical environments using unsupervised multiresolution analysis. Ecol. Indic. 2018, 90, 346–355. [Google Scholar] [CrossRef]
- Rowe, B.; Eichinski, P.; Zhang, J.; Roe, P. Acoustic auto-encoders for biodiversity assessment. Ecol. Inform. 2021, 62, 101237. [Google Scholar] [CrossRef]
- Dias, F.F.; Pedrini, H.; Minghim, R. Soundscape segregation based on visual analysis and discriminating features. Ecol. Inform. 2021, 61, 101184. [Google Scholar] [CrossRef]
- Best, P.; Paris, S.; Glotin, H.; Marxer, R. Deep audio embeddings for vocalisation clustering. PLoS ONE 2023, 18, e0283396. [Google Scholar] [CrossRef]
- Akbal, E.; Barua, P.D.; Dogan, S.; Tuncer, T.; Acharya, U.R. Explainable automated anuran sound classification using improved one-dimensional local binary pattern and Tunable Q Wavelet Transform techniques. Expert Syst. Appl. 2023, 225, 120089. [Google Scholar] [CrossRef]
- Rendon, N.; Giraldo, J.H.; Bouwmans, T.; Rodríguez-Buritica, S.; Ramirez, E.; Isaza, C. Uncertainty clustering internal validity assessment using Fréchet distance for unsupervised learning. Eng. Appl. Artif. Intell. 2023, 124, 106635. [Google Scholar] [CrossRef]
- Allaoui, M.; Kherfi, M.L.; Cheriet, A.; Bouchachia, A. Unified embedding and clustering. Expert Syst. Appl. 2024, 238, 121923. [Google Scholar] [CrossRef]
- Nieto-Mora, D.A.; Rodríguez-Buritica, S.; Rodríguez-Marín, P.; Martínez-Vargaz, J.D.; Isaza-Narváez, C. Systematic review of machine learning methods applied to ecoacoustics and soundscape monitoring. Heliyon 2023, 9, e20275. [Google Scholar] [CrossRef] [PubMed]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar] [CrossRef]
- Cano Rojas, E.; Sanchez Giraldo, C.; Bedoya, C.; Daza, J.M. Hábitat y espectro acústico como factores determinantes de la ocupación de anuros neotropicales. Biota Colomb. 2022, 23, e-910. [Google Scholar] [CrossRef]
- Sánchez-Giraldo, C.; Correa Ayram, C.; Daza, J.M. Environmental sound as a mirror of landscape ecological integrity in monitoring programs. Perspect. Ecol. Conserv. 2021, 19, 319–328. [Google Scholar] [CrossRef]
- Bedoya, C.; Isaza, C.; Daza, J.M.; López, J.D. Automatic identification of rainfall in acoustic recordings. Ecol. Indic. 2017, 75, 95–100. [Google Scholar] [CrossRef]
- Pahuja, R.; Kumar, A. Sound-spectrogram based automatic bird species recognition using MLP classifier. Appl. Acoust. 2021, 180, 108077. [Google Scholar] [CrossRef]
- Zhong, M.; LeBien, J.; Campos-Cerqueira, M.; Dodhia, R.; Lavista Ferres, J.; Velev, J.P.; Aide, T.M. Multispecies bioacoustic classification using transfer learning of deep convolutional neural networks with pseudo-labeling. Appl. Acoust. 2020, 166, 107375. [Google Scholar] [CrossRef]
- Steinfath, E.; Palacios-Muñoz, A.; Rottschäfer, J.R.; Yuezak, D.; Clemens, J. Fast and accurate annotation of acoustic signals with deep neural networks. eLife 2021, 10, e68837. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.F. Efficient classification of environmental sounds through multiple features aggregation and data enhancement techniques for spectrogram images. Symmetry 2020, 12, 1822. [Google Scholar] [CrossRef]
- Ventura, T.M.; De Oliveira, A.G.; Ganchev, T.D.; De Figueiredo, J.M.; Jahn, O.; Marques, M.I.; Schuchmann, K.L. Audio parameterization with robust frame selection for improved bird identification. Expert Syst. Appl. 2015, 42, 8463–8471. [Google Scholar] [CrossRef]
- Hinton, G.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Int. Encycl. Educ. 2006, 313, 468–474. [Google Scholar] [CrossRef] [PubMed]
- Tan, W.G.Y.; Xiao, M.; Wu, Z. Robust reduced-order machine learning modeling of high-dimensional nonlinear processes using noisy data. Digit. Chem. Eng. 2024, 11, 100145. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H. (Denoising AE) Extracting and Composing Robust Features with Denoising. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Dong, G.; Liao, G.; Liu, H.; Kuang, G. A Review of the Autoencoder and Its Variants: A Comparative Perspective from Target Recognition in Synthetic-Aperture Radar Images. IEEE Geosci. Remote Sens. Mag. 2018, 6, 44–68. [Google Scholar] [CrossRef]
- Kammoun, A.; Ravier, P.; Buttelli, O. Impact of PCA Pre-Normalization Methods on Ground Reaction Force Estimation Accuracy. Sensors 2024, 24, 1137. [Google Scholar] [CrossRef]
- Siddique, M.F.; Ahmad, Z.; Ullah, N.; Kim, J. A Hybrid Deep Learning Approach: Integrating Short-Time Fourier Transform and Continuous Wavelet Transform for Improved Pipeline Leak Detection. Sensors 2023, 23, 8079. [Google Scholar] [CrossRef] [PubMed]
- Van der Maaten, L.; Geoffrey, H. Visualizing Data using t-SNE Laurens. Ann. Oper. Res. 2008, 219, 187–202. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- Urrutia, R.; Espejo, D.; Evens, N.; Sühn, T.; Boese, A.; Hansen, C.; Fuentealba, P.; Illanes, A.; Poblete, V. Clustering Methods for Vibro-Acoustic Sensing Features as a Potential Approach to Tissue Characterisation in Robot-Assisted Interventions. Sensors 2023, 23, 9297. [Google Scholar] [CrossRef]
- Morissette, L.; Chartier, S. The k-means clustering technique: General considerations and implementation in Mathematica. Tutor. Quant. Methods Psychol. 2013, 9, 15–24. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.S. Unsupervised K-means clustering algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Khan, A.; Hao, J.; Dong, Z.; Li, J. Adaptive Deep Clustering Network for Retinal Blood Vessel and Foveal Avascular Zone Segmentation. Appl. Sci. 2023, 13, 11259. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 322, 178–210. [Google Scholar] [CrossRef]
- Yang, H.; Wang, J.; Wang, J. Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning. Remote Sens. 2023, 15, 5527. [Google Scholar] [CrossRef]
- Abu Abbas, O. Comparisons Between Data Clustering Algorithms. Int. Arab. J. Inf. Technol. 2008, 5, 320–325. [Google Scholar]
- Ulloa, J.S.; Haupert, S.; Latorre, J.F.; Aubin, T.; Sueur, J. scikit-maad: An open-source and modular toolbox for quantitative soundscape analysis in Python. Methods Ecol. Evol. 2021, 12, 2334–2340. [Google Scholar] [CrossRef]
- Sánchez-Giraldo, C.; Bedoya, C.L.; Morán-Vásquez, R.A.; Isaza, C.V.; Daza, J.M. Ecoacoustics in the rain: Understanding acoustic indices under the most common geophonic source in tropical rainforests. Remote Sens. Ecol. Conserv. 2020, 6, 248–261. [Google Scholar] [CrossRef]
- Zhou, H.B.; Gao, J.T. Automatic method for determining cluster number based on silhouette coefficient. Adv. Mater. Res. 2014, 951, 227–230. [Google Scholar] [CrossRef]
- Sousa-Lima, R.S.; Ferreira, L.M.; Oliveira, E.G.; Lopes, L.C.; Brito, M.R.; Baumgarten, J.; Rodrigues, F.H. What do insects, anurans, birds, and mammals have to say about soundscape indices in a tropical savanna. J. Ecoacoust. 2018, 2, 2. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Methods | Dataset | Reference | Year |
|---|---|---|---|---|
| Unsupervised | UEC, GMMs, NMI, K-means | IRIS, Spiral, CIFAR10, ATOM, EngyTime, USPS, MNIST, Reuters 10K | [24] | 2024 |
| Supervised | VGG, UMAP, HDBSCAN | 8 datasets of timestamped and type labeled vocalizations of birds and marine mammals | [21] | 2023 |
| Supervised | Q Wavelets, 1D-LBP, KNN | New anuran dataset with 1536 sounds of 26 species | [22] | 2023 |
| Supervised and Unsupervised | Variational Autoencoders, UMAP, Binomial classification | Datasets from Equador and United Kingdom about habitat degradation | [15] | 2023 |
| Unsupervised | GMMs, Uncertainty Fréchet | 36 Synthetic and 5 real datasets (including a PAM dataset) | [23] | 2023 |
| Unsupervised | Acoustic indices, Autoencoders, Hierarchical clustering | SERF Dataset | [19] | 2021 |
| Unsupervised | Acoustic indices, Image descriptors, Autoencoders, PCA, t-SNE, LAMP | More than 4000 files from terrestrial and marine ecosystems from Costa Rica and Brazil | [20] | 2021 |
| Rec | NSS | RD (S) | SR (KHz) | SS (KHz) | dB Gain | RP | MU (GB) | AL | ||
|---|---|---|---|---|---|---|---|---|---|---|
| SM4 | 31 | 60 | 44.1 | 22.05 | 16 | 1 min every | 212.4 | Forest | Non-forest | |
| 15 min | 14,637 | 5431 | ||||||||
| Total | 20,068 | |||||||||
| NC | Full Embedded Space | UMAP | t-SNE | PCA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SLT | DB | CH | SLT | DB | CH | SLT | DB | CH | SLT | DB | CH | |
| 3 | 0.2131 | 1.7692 | 29,185 | 0.4123 | 0.8589 | 86,427 | 0.3783 | 0.8565 | 66,293 | 0.2493 | 1.5490 | 37,770 |
| 5 | 0.1368 | 2.0666 | 20,519 | 0.3872 | 0.8167 | 85,305 | 0.3411 | 0.9031 | 70,358 | 0.1773 | 1.7393 | 27,896 |
| 7 | 0.1304 | 1.9938 | 16,484 | 0.3503 | 0.8709 | 81,715 | 0.3646 | 0.7740 | 74,417 | 0.1755 | 1.6660 | 23,248 |
| 10 | 0.128 | 2.0494 | 12,910 | 0.3420 | 0.8665 | 78,940 | 0.3431 | 0.8495 | 72,635 | 0.1753 | 1.6801 | 18,927 |
| 15 | 0.1032 | 2.0458 | 9707 | 0.3373 | 0.8312 | 78,438 | 0.3412 | 0.8137 | 73,335 | 0.1537 | 1.6943 | 14,755 |
| 20 | 0.1000 | 2.1764 | 7766 | 0.3294 | 0.8284 | 77,257 | 0.3406 | 0.7807 | 73,952 | 0.1483 | 1.7404 | 12,251 |
| 25 | 0.0839 | 2.2417 | 6556 | 0.3262 | 0.8287 | 76,505 | 0.3406 | 0.7826 | 74,813 | 0.1428 | 1.7605 | 10,572 |
| 30 | 0.0826 | 2.259 | 5719 | 0.3254 | 0.8194 | 76,092 | 0.3425 | 0.7883 | 74,835 | 0.1321 | 1.7655 | 9361 |
| 35 | 0.0786 | 2.2819 | 5092 | 0.3309 | 0.8145 | 76,371 | 0.3403 | 0.7956 | 74,798 | 0.1304 | 1.7801 | 8490 |
| Mean | 0.1174 | 2.0982 | 12,660 | 0.3490 | 0.8372 | 79,672 | 0.3480 | 0.8160 | 72,826 | 0.1649 | 1.7083 | 18,141 |
| STD | 0.03 | 0.15 | 7637 | 0.02 | 0.02 | 3699 | 0.01 | 0.04 | 2682 | 0.03 | 0.06 | 9314 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nieto-Mora, D.A.; Ferreira de Oliveira, M.C.; Sanchez-Giraldo, C.; Duque-Muñoz, L.; Isaza-Narváez, C.; Martínez-Vargas, J.D. Soundscape Characterization Using Autoencoders and Unsupervised Learning. Sensors 2024, 24, 2597. https://doi.org/10.3390/s24082597
Nieto-Mora DA, Ferreira de Oliveira MC, Sanchez-Giraldo C, Duque-Muñoz L, Isaza-Narváez C, Martínez-Vargas JD. Soundscape Characterization Using Autoencoders and Unsupervised Learning. Sensors. 2024; 24(8):2597. https://doi.org/10.3390/s24082597
Chicago/Turabian StyleNieto-Mora, Daniel Alexis, Maria Cristina Ferreira de Oliveira, Camilo Sanchez-Giraldo, Leonardo Duque-Muñoz, Claudia Isaza-Narváez, and Juan David Martínez-Vargas. 2024. "Soundscape Characterization Using Autoencoders and Unsupervised Learning" Sensors 24, no. 8: 2597. https://doi.org/10.3390/s24082597