


Comparative Analysis of Anomaly Detection Approaches in Firewall Logs: Integrating Light-Weight Synthesis of Security Logs and Artificially Generated Attack Detection †


Abstract
:1. Introduction
- Inputting previously recorded network traffic from a dataset into a security control to generate logs [14]. It can be noted that similar methods have also seen frequent use in the evaluation of various alert correlation approaches. For instance, Ning et al. [15] used the RealSecure Network Sensor to generate IDS alert logs based on an existing public dataset.

- A novel method for generating logs containing attack-related records that eliminates the need for a dedicated testbed or installed security controls.
- The ability to generate anomalies that closely resemble real-world attacker behavior, enabling seamless integration with existing firewall logs for realistic testing.
- A comparative evaluation of unsupervised and supervised machine learning algorithms in detecting injected anomalies using various feature construction, scaling, and aggregation techniques.
2. Related Work
3. Firewall Logs
4. Generating Synthetic Logs
4.1. Methodology
- Domain knowledge describing target attacks and security controls. This input includes various information, including: (i) reports of attacks and their consequences, such as threat or malware reports and pre-recorded network traffic samples, (ii) knowledge of the security control for which the logs are synthesized, and (iii) knowledge of the medium through which the artifacts are manifested. For example, when creating artifacts originating from network scans for firewall logs, knowledge of the network scanning tools used, such as nmap [75], knowledge of the firewalls used, and familiarity with network protocols are required.
- Security control configuration information. This information can be obtained in a variety of ways, such as by consulting documentation, talking to the relevant security administrators, or directly accessing the configuration of the security control in question. This paper assumes that the security control is configured according to the reports provided and its equivalence is not questioned. For example, in the case of a network firewall, this information could include policy descriptions in unstructured text obtained from discussions with administrators, firewall policy documentation, or a set of configured firewall rules. Depending on the level of detail desired, this information can even be gathered verbally through interviews with the appropriate personnel.
- Pre-existing logs. These logs represent authentic data collected by security controls within the organization. Most organizations already maintain logs for audit purposes, so they are readily available in practice.

4.2. Generated Anomalies
- SYN scans of a machine and a target range of machines using nmap. These network scans were created by scanning our local network server and local IP range with the nmap [75] tool installed on a Kali Linux [76] virtual machine (VM). Both tests were run with the nmap flags . Since the firewall only logged initial packets for individual ports and did not log return packets, it was not necessary to set up listeners for real applications.
- Connect scans of a machine and a target range of machines using nmap. This was done similarly to the first scan, except that the flags were used.
- UDP scans of a machine and a target range of machines using nmap. This was done similarly to the first scan, except that the flags were used.
- SYN scan for characteristic VPN services using nmap. This scan was performed in a similar way as the first scan, but only with the entire IP range and ports 102, 6001, and 13,777.
- Connect scan for characteristic VPN services using nmap. This was done similarly to the fourth scan, except that the flags were used.
- Establishment of an RDP session, with several unsucessful atempts. This was simulated by setting up a Windows 10 VM and making several attempts to establish an RDP connection. The first connections were made with an incorrect password, the last with the correct password.
5. Feature Construction
- The first method used one-hot encoding exclusively for “important ports”, which are defined as ports that occur in more than 1% of all connections. For all other ports, an additional feature called other was introduced, resulting in a significantly reduced zero–one vector.
- The second approach categorized ports into ephemeral and non-ephemeral categories. Ports with numbers lower than 1024 were encoded with the one-hot encoding, while ports with higher numbers were represented with the other feature. This approach resulted in a 1024-bit zero-one vector.
6. Unsupervised Learning
6.1. Performance Measures
6.2. Methodology
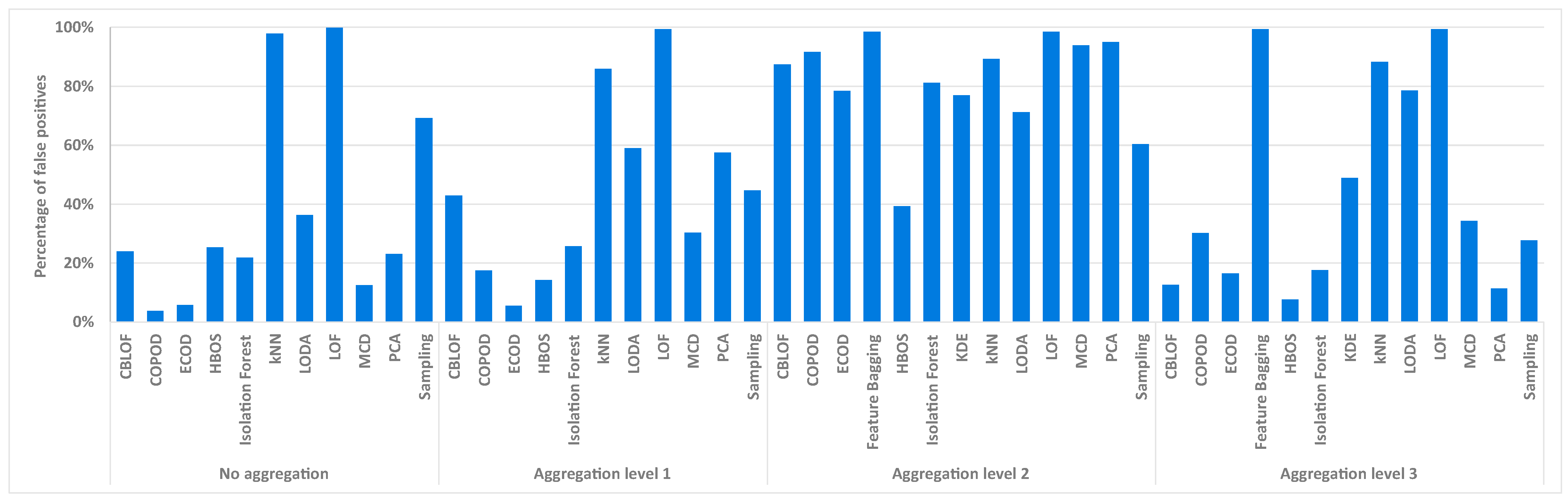
6.3. Results
6.3.1. Comparison of Unsupervised Models
6.3.2. Comparison of Feature Construction Methods
6.3.3. Comparison of Feature Subsets
6.3.4. Comparison of Scaling Methods
7. Supervised Learning
7.1. Methodology
7.2. Results
8. Discussion
8.1. Log Generation
8.2. Anomaly Detection
- The dataset used should not come from the simulated network environment, but should be generated from real network activities.
- The size of the dataset must be large enough to replicate real-world scenarios (often more than one million connections per day), as the size of the dataset strongly influences the selection of machine learning algorithms to be used.
- The proportion of anomalous records in the dataset is an important factor and should be very low (less than 1%), as anomalies in real network traffic are very rare and well hidden.
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Komadina, A.; Kovačević, I.; Štengl, B.; Groš, S. Detecting Anomalies in Firewall Logs Using Artificially Generated Attacks. In Proceedings of the 2023 17th International Conference on Telecommunications (ConTEL), Graz, Austria, 11–13 July 2023; pp. 1–8. [Google Scholar]
- Kovačević, I.; Komadina, A.; Štengl, B.; Groš, S. Light-Weight Synthesis of Security Logs for Evaluation of Anomaly Detection and Security Related Experiments. In Proceedings of the 16th European Workshop on System Security, Rome, Italy, 8–12 May 2023; pp. 30–36. [Google Scholar]
- Ferragut, E.M.; Laska, J.; Bridges, R.A. A new, principled approach to anomaly detection. In Proceedings of the 2012 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 12–15 December 2012; Volume 2, pp. 210–215. [Google Scholar]
- Bezerra, F.; Wainer, J.; van der Aalst, W.M. Anomaly detection using process mining. In Enterprise, Business-Process and Information Systems Modeling, Proceedings of the 10th International Workshop, BPMDS 2009, and 14th International Conference, EMMSAD 2009, Amsterdam, The Netherlands, 8–9 June 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 149–161. [Google Scholar]
- Wu, H.S. A survey of research on anomaly detection for time series. In Proceedings of the 2016 13th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 16–18 December 2016; pp. 426–431. [Google Scholar]
- Hawkins, D.M. Identification of Outliers; Springer: Berlin/Heidelberg, Germany, 1980; Volume 11. [Google Scholar]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate anomaly detection for time series data with generative adversarial networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Springer: Cham, Switzerland, 2019; pp. 703–716. [Google Scholar]
- Nassif, A.B.; Talib, M.A.; Nasir, Q.; Dakalbab, F.M. Machine learning for anomaly detection: A systematic review. IEEE Access 2021, 9, 78658–78700. [Google Scholar] [CrossRef]
- Kovačević, I.; Groš, S.; Slovenec, K. Systematic review and quantitative comparison of cyberattack scenario detection and projection. Electronics 2020, 9, 1722. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Gharib, A.; Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. An evaluation framework for intrusion detection dataset. In Proceedings of the 2016 International Conference on Information Science and Security (ICISS), Pattaya, Thailand, 19–22 December 2016; pp. 1–6. [Google Scholar]
- Salazar, Z.; Nguyen, H.N.; Mallouli, W.; Cavalli, A.R.; Montes de Oca, E. 5greplay: A 5g network traffic fuzzer-application to attack injection. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–8. [Google Scholar]
- Cordero, C.G.; Vasilomanolakis, E.; Wainakh, A.; Mühlhäuser, M.; Nadjm-Tehrani, S. On generating network traffic datasets with synthetic attacks for intrusion detection. ACM Trans. Priv. Secur. (TOPS) 2021, 24, 8. [Google Scholar] [CrossRef]
- Brown, C.; Cowperthwaite, A.; Hijazi, A.; Somayaji, A. Analysis of the 1999 darpa/lincoln laboratory ids evaluation data with netadhict. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–7. [Google Scholar]
- Ning, P.; Cui, Y.; Reeves, D.S. Constructing attack scenarios through correlation of intrusion alerts. In Proceedings of the 9th ACM Conference on Computer and Communications Security, Washington, DC, USA, 18–22 November 2002; pp. 245–254. [Google Scholar]
- Myneni, S.; Chowdhary, A.; Sabur, A.; Sengupta, S.; Agrawal, G.; Huang, D.; Kang, M. DAPT 2020-constructing a benchmark dataset for advanced persistent threats. In Proceedings of the International Workshop on Deployable Machine Learning for Security Defense, San Diego, CA, USA, 24 August 2020; Springer: Cham, Switzerland, 2020; pp. 138–163. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Skopik, F.; Settanni, G.; Fiedler, R.; Friedberg, I. Semi-synthetic data set generation for security software evaluation. In Proceedings of the 2014 Twelfth Annual International Conference on Privacy, Security and Trust, Toronto, ON, Canada, 23–24 July 2014; pp. 156–163. [Google Scholar]
- Haider, W.; Hu, J.; Slay, J.; Turnbull, B.P.; Xie, Y. Generating realistic intrusion detection system dataset based on fuzzy qualitative modeling. J. Netw. Comput. Appl. 2017, 87, 185–192. [Google Scholar] [CrossRef]
- Zuech, R.; Khoshgoftaar, T.M.; Seliya, N.; Najafabadi, M.M.; Kemp, C. A new intrusion detection benchmarking system. In Proceedings of the The Twenty-Eighth International Flairs Conference, Hollywood, FL, USA, 18–20 May 2015. [Google Scholar]
- O’Shaughnessy, S.; Gray, G. Development and evaluation of a dataset generator tool for generating synthetic log files containing computer attack signatures. Int. J. Ambient Comput. Intell. (IJACI) 2011, 3, 64–76. [Google Scholar] [CrossRef]
- Göbel, T.; Schäfer, T.; Hachenberger, J.; Türr, J.; Baier, H. A Novel approach for generating synthetic datasets for digital forensics. In Proceedings of the IFIP International Conference on Digital Forensics, New Delhi, India, 6–8 January 2020; Springer: Cham, Switzerland, 2020; pp. 73–93. [Google Scholar]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Towards Generating Real-life Datasets for Network Intrusion Detection. Int. J. Netw. Secur. 2015, 17, 683–701. [Google Scholar]
- Boggs, N.; Zhao, H.; Du, S.; Stolfo, S.J. Synthetic data generation and defense in depth measurement of web applications. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Gothenburg, Sweden, 17–19 September 2014; Springer: Cham, Switzerland, 2014; pp. 234–254. [Google Scholar]
- Wurzenberger, M.; Skopik, F.; Settanni, G.; Scherrer, W. Complex log file synthesis for rapid sandbox-benchmarking of security-and computer network analysis tools. Inf. Syst. 2016, 60, 13–33. [Google Scholar] [CrossRef]
- Rao, C.M.; Naidu, M. A model for generating synthetic network flows and accuracy index for evaluation of anomaly network intrusion detection systems. Indian J. Sci. Technol. 2017, 10, 1–16. [Google Scholar] [CrossRef]
- Mozo, A.; González-Prieto, Á.; Pastor, A.; Gómez-Canaval, S.; Talavera, E. Synthetic flow-based cryptomining attack generation through Generative Adversarial Networks. Sci. Rep. 2022, 12, 2091. [Google Scholar] [CrossRef]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Toward developing a systematic approach to generate benchmark datasets for intrusion detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Lu, J.; Lv, F.; Zhuo, Z.; Zhang, X.; Liu, X.; Hu, T.; Deng, W. Integrating traffics with network device logs for anomaly detection. Secur. Commun. Netw. 2019, 2019, 5695021. [Google Scholar] [CrossRef]
- Roschke, S.; Cheng, F.; Meinel, C. A new alert correlation algorithm based on attack graph. In Proceedings of the Computational Intelligence in Security for Information Systems: 4th International Conference, CISIS 2011, Torremolinos-Málaga, Spain, 8–10 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 58–67. [Google Scholar]
- Maciá-Fernández, G.; Camacho, J.; Magán-Carrión, R.; García-Teodoro, P.; Therón, R. UGR ‘16: A new dataset for the evaluation of cyclostationarity-based network IDSs. Comput. Secur. 2018, 73, 411–424. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in outlier detection techniques: A survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Sawant, A.A.; Game, P.S. Approaches for Anomaly Detection in Network: A Survey. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar]
- Patcha, A.; Park, J.M. An overview of anomaly detection techniques: Existing solutions and latest technological trends. Comput. Netw. 2007, 51, 3448–3470. [Google Scholar] [CrossRef]
- Gogoi, P.; Bhattacharyya, D.K.; Borah, B.; Kalita, J.K. A survey of outlier detection methods in network anomaly identification. Comput. J. 2011, 54, 570–588. [Google Scholar] [CrossRef]
- White, J.; Legg, P. Unsupervised one-class learning for anomaly detection on home IoT network devices. In Proceedings of the 2021 International Conference on Cyber Situational Awareness, Data Analytics and Assessment (CyberSA), Dublin, Ireland, 14–18 June 2021; pp. 1–8. [Google Scholar]
- Radford, B.J.; Apolonio, L.M.; Trias, A.J.; Simpson, J.A. Network traffic anomaly detection using recurrent neural networks. arXiv 2018, arXiv:1803.10769. [Google Scholar]
- Idrissi, I.; Boukabous, M.; Azizi, M.; Moussaoui, O.; El Fadili, H. Toward a deep learning-based intrusion detection system for IoT against botnet attacks. IAES Int. J. Artif. Intell. 2021, 10, 110. [Google Scholar] [CrossRef]
- Kulyadi, S.P.; Mohandas, P.; Kumar, S.K.S.; Raman, M.S.; Vasan, V. Anomaly Detection using Generative Adversarial Networks on Firewall Log Message Data. In Proceedings of the 2021 13th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Pitesti, Romania, 1–3 July 2021; pp. 1–6. [Google Scholar]
- Vartouni, A.M.; Kashi, S.S.; Teshnehlab, M. An anomaly detection method to detect web attacks using stacked auto-encoder. In Proceedings of the 2018 6th Iranian Joint Congress on Fuzzy and Intelligent Systems (CFIS), Kerman, Iran, 28 February–2 March 2018; pp. 131–134. [Google Scholar]
- Chapple, M.J.; Chawla, N.; Striegel, A. Authentication anomaly detection: A case study on a virtual private network. In Proceedings of the 3rd Annual ACM Workshop on Mining Network Data, San Diego, CA, USA, 12 June 2007; pp. 17–22. [Google Scholar]
- Nguyen, T.Q.; Laborde, R.; Benzekri, A.; Qu’hen, B. Detecting abnormal DNS traffic using unsupervised machine learning. In Proceedings of the 2020 4th Cyber Security in Networking Conference (CSNet), Lausanne, Switzerland, 21–23 October 2020; pp. 1–8. [Google Scholar]
- Tuor, A.; Kaplan, S.; Hutchinson, B.; Nichols, N.; Robinson, S. Deep learning for unsupervised insider threat detection in structured cybersecurity data streams. arXiv 2017, arXiv:1710.00811. [Google Scholar]
- Clark, J.; Liu, Z.; Japkowicz, N. Adaptive threshold for outlier detection on data streams. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 41–49. [Google Scholar]
- Chae, Y.; Katenka, N.; Dipippo, L. Adaptive threshold selection for trust-based detection systems. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 281–287. [Google Scholar]
- Zhao, Y.; Hryniewicki, M.K. DCSO: Dynamic combination of detector scores for outlier ensembles. arXiv 2019, arXiv:1911.10418. [Google Scholar]
- Allagi, S.; Rachh, R. Analysis of Network log data using Machine Learning. In Proceedings of the 2019 IEEE 5th International Conference for Convergence in Technology (I2CT), Bombay, India, 29–31 March 2019; pp. 1–3. [Google Scholar]
- As-Suhbani, H.E.; Khamitkar, S. Classification of firewall logs using supervised machine learning algorithms. Int. J. Comput. Sci. Eng. 2019, 7, 301–304. [Google Scholar] [CrossRef]
- Aljabri, M.; Alahmadi, A.A.; Mohammad, R.M.A.; Aboulnour, M.; Alomari, D.M.; Almotiri, S.H. Classification of firewall log data using multiclass machine learning models. Electronics 2022, 11, 1851. [Google Scholar] [CrossRef]
- Ucar, E.; Ozhan, E. The analysis of firewall policy through machine learning and data mining. Wirel. Pers. Commun. 2017, 96, 2891–2909. [Google Scholar] [CrossRef]
- Shetty, N.P.; Shetty, J.; Narula, R.; Tandona, K. Comparison study of machine learning classifiers to detect anomalies. Int. J. Electr. Comput. Eng. 2020, 10, 5445. [Google Scholar] [CrossRef]
- Al-Haijaa, Q.A.; Ishtaiwia, A. Machine learning based model to identify firewall decisions to improve cyber-defense. Int. J. Adv. Sci. Eng. Inf. Technol. 2021, 11, 1688–1695. [Google Scholar] [CrossRef]
- Fotiadou, K.; Velivassaki, T.H.; Voulkidis, A.; Skias, D.; Tsekeridou, S.; Zahariadis, T. Network traffic anomaly detection via deep learning. Information 2021, 12, 215. [Google Scholar] [CrossRef]
- Le, D.C.; Zincir-Heywood, N. Exploring anomalous behaviour detection and classification for insider threat identification. Int. J. Netw. Manag. 2021, 31, e2109. [Google Scholar] [CrossRef]
- Harshaw, C.R.; Bridges, R.A.; Iannacone, M.D.; Reed, J.W.; Goodall, J.R. Graphprints: Towards a graph analytic method for network anomaly detection. In Proceedings of the 11th Annual Cyber and Information Security Research Conference, Oak Ridge, TN, USA, 5–7 April 2016; pp. 1–4. [Google Scholar]
- Zhang, X.; Wu, T.; Zheng, Q.; Zhai, L.; Hu, H.; Yin, W.; Zeng, Y.; Cheng, C. Multi-Step Attack Detection Based on Pre-Trained Hidden Markov Models. Sensors 2022, 22, 2874. [Google Scholar] [CrossRef] [PubMed]
- Hommes, S.; State, R.; Engel, T. A distance-based method to detect anomalous attributes in log files. In Proceedings of the 2012 IEEE Network Operations and Management Symposium, Maui, HI, USA, 16–20 April 2012; pp. 498–501. [Google Scholar]
- Gutierrez, R.J.; Bauer, K.W.; Boehmke, B.C.; Saie, C.M.; Bihl, T.J. Cyber anomaly detection: Using tabulated vectors and embedded analytics for efficient data mining. J. Algorithms Comput. Technol. 2018, 12, 293–310. [Google Scholar] [CrossRef]
- Winding, R.; Wright, T.; Chapple, M. System anomaly detection: Mining firewall logs. In Proceedings of the 2006 Securecomm and Workshops, Baltimore, MD, USA, 28 August–1 September 2006; pp. 1–5. [Google Scholar]
- Khamitkar, S.; As-Suhbani, H. Discovering Anomalous Rules In Firewall Logs Using Data Mining And Machine Learning Classifiers. Int. J. Sci. Technol. Res. 2020, 9, 2491–2497. [Google Scholar]
- As-Suhbani, H.E.; Khamitkar, S. Using Data Mining for Discovering Anomalies from Firewall Logs: A comprehensive Review. Int. Res. J. Eng. Technol. (IRJET) 2017, 4, 419–423. [Google Scholar]
- Ceci, M.; Appice, A.; Caruso, C.; Malerba, D. Discovering emerging patterns for anomaly detection in network connection data. In Proceedings of the International Symposium on Methodologies for Intelligent Systems, Toronto, ON, Canada, 20–23 May 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 179–188. [Google Scholar]
- Caruso, C.; Malerba, D. A data mining methodology for anomaly detection in network data. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Vietri sul Mare, Italy, 12–14 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 109–116. [Google Scholar]
- Depren, O.; Topallar, M.; Anarim, E.; Ciliz, M.K. An intelligent intrusion detection system (IDS) for anomaly and misuse detection in computer networks. Expert Syst. Appl. 2005, 29, 713–722. [Google Scholar] [CrossRef]
- Anil, S.; Remya, R. A hybrid method based on genetic algorithm, self-organised feature map, and support vector machine for better network anomaly detection. In Proceedings of the 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–5. [Google Scholar]
- Chen, X.; Li, B.; Proietti, R.; Zhu, Z.; Yoo, S.B. Self-taught anomaly detection with hybrid unsupervised/supervised machine learning in optical networks. J. Light. Technol. 2019, 37, 1742–1749. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L. A hybrid network anomaly and intrusion detection approach based on evolving spiking neural network classification. In E-Democracy, Security, Privacy and Trust in a Digital World, Proceedings of the 5th International Conference, E-Democracy 2013, Athens, Greece, 5–6 December 2013; Revised Selected Papers 5; Springer: Berlin/Heidelberg, Germany, 2014; pp. 11–23. [Google Scholar]
- Van, N.T.; Thinh, T.N. An anomaly-based network intrusion detection system using deep learning. In Proceedings of the 2017 International Conference on System Science and Engineering (ICSSE), Ho Chi Minh City, Vietnam, 21–23 July 2017; pp. 210–214. [Google Scholar]
- Liu, D.; Lung, C.H.; Lambadaris, I.; Seddigh, N. Network traffic anomaly detection using clustering techniques and performance comparison. In Proceedings of the 2013 26th IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Regina, SK, Canada, 5–8 May 2013; pp. 1–4. [Google Scholar]
- Mulinka, P.; Casas, P. Stream-based machine learning for network security and anomaly detection. In Proceedings of the 2018 Workshop on Big Data Analytics and Machine Learning for Data Communication Networks, Budapest, Hungary, 20 August 2018; pp. 1–7. [Google Scholar]
- Abdulhammed, R.; Faezipour, M.; Abuzneid, A.; AbuMallouh, A. Deep and machine learning approaches for anomaly-based intrusion detection of imbalanced network traffic. IEEE Sens. Lett. 2018, 3, 7101404. [Google Scholar] [CrossRef]
- Meng, Y.X. The practice on using machine learning for network anomaly intrusion detection. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics, Guilin, China, 10–13 July 2011; Volume 2, pp. 576–581. [Google Scholar]
- He, S.; Zhu, J.; He, P.; Lyu, M.R. Experience report: System log analysis for anomaly detection. In Proceedings of the 2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), Ottawa, ON, Canada, 23–27 October 2016; pp. 207–218. [Google Scholar]
- Ramakrishnan, J.; Shaabani, E.; Li, C.; Sustik, M.A. Anomaly detection for an e-commerce pricing system. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1917–1926. [Google Scholar]
- Lyon, G.F. Nmap Network Scanning: The Official Nmap Project Guide to Network Discovery and Security Scanning; Insecure.Com LLC (US): Seattle, WA, USA, 2008. [Google Scholar]
- OffSec Services Limited. Kali Docs. 2022. Available online: https://www.kali.org/docs/ (accessed on 16 December 2022).
- Kovačević, I. Firewall log PCAP Injection. 2023. Available online: https://zenodo.org/records/7782521 (accessed on 10 March 2024).
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]
- Bewick, V.; Cheek, L.; Ball, J. Statistics review 13: Receiver operating characteristic curves. Crit. Care 2004, 8, 508. [Google Scholar] [CrossRef] [PubMed]
- Soule, A.; Salamatian, K.; Taft, N. Combining filtering and statistical methods for anomaly detection. In Proceedings of the 5th ACM SIGCOMM Conference on Internet Measurement, Berkeley, CA, USA, 19–21 October 2005; p. 31. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]
- Cook, J.; Ramadas, V. When to consult precision-recall curves. Stata J. 2020, 20, 131–148. [Google Scholar] [CrossRef]
- Tang, J.; Chen, Z.; Fu, A.W.C.; Cheung, D.W. Enhancing effectiveness of outlier detections for low density patterns. In Advances in Knowledge Discovery and Data Mining, Proceedings of the 6th Pacific-Asia Conference, PAKDD 2002 Taipei, Taiwan, 6–8 May 2002; Proceedings 6; Springer: Berlin/Heidelberg, Germany, 2002; pp. 535–548. [Google Scholar]
- Papadimitriou, S.; Kitagawa, H.; Gibbons, P.B.; Faloutsos, C. Loci: Fast outlier detection using the local correlation integral. In Proceedings of the Proceedings 19th International Conference on Data Engineering (Cat. No. 03CH37405), Bangalore, India, 5–8 March 2003; pp. 315–326. [Google Scholar]
- Janssens, J.; Huszár, F.; Postma, E.; van den Herik, H. Stochastic outlier selection. Tilburg Cent. Creat. Comput. Techreport 2012, 1, 2012. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Mining: The Textbook; Springer: Cham, Switzerland, 2015; Volume 1, pp. 75–79. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Liu, Y.; Li, Z.; Zhou, C.; Jiang, Y.; Sun, J.; Wang, M.; He, X. Generative adversarial active learning for unsupervised outlier detection. IEEE Trans. Knowl. Data Eng. 2019, 32, 1517–1528. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Hu, X.; Botta, N.; Ionescu, C.; Chen, G. Ecod: Unsupervised outlier detection using empirical cumulative distribution functions. IEEE Trans. Knowl. Data Eng. 2022, 35, 12181–12193. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Botta, N.; Ionescu, C.; Hu, X. COPOD: Copula-based outlier detection. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 1118–1123. [Google Scholar]
- Sugiyama, M.; Borgwardt, K. Rapid distance-based outlier detection via sampling. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Shyu, M.L.; Chen, S.C.; Sarinnapakorn, K.; Chang, L. A Novel Anomaly Detection Scheme Based on Principal Component Classifier. In Proceedings of the IEEE Foundations and New Directions of Data Mining Workshop, in Conjunction with the Third IEEE International Conference on Data Mining (ICDM’03) Computer Engineering, Melbourne, FL, USA, 19–22 November 2003. [Google Scholar]
- Hardin, J.; Rocke, D.M. Outlier detection in the multiple cluster setting using the minimum covariance determinant estimator. Comput. Stat. Data Anal. 2004, 44, 625–638. [Google Scholar] [CrossRef]
- He, Z.; Xu, X.; Deng, S. Discovering cluster-based local outliers. Pattern Recognit. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Angiulli, F.; Pizzuti, C. Fast outlier detection in high dimensional spaces. In Principles of Data Mining and Knowledge Discovery, Proceedings of the 6th European Conference (PKDD 2002), Helsinki, Finland, 19–23 August 2002; Proceedings 6; Springer: Berlin/Heidelberg, Germany, 2002; pp. 15–27. [Google Scholar]
- Goldstein, M.; Dengel, A. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. KI-2012 Poster Demo Track 2012, 1, 59–63. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Pevnỳ, T. Loda: Lightweight on-line detector of anomalies. Mach. Learn. 2016, 102, 275–304. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Latecki, L.J.; Lazarevic, A.; Pokrajac, D. Outlier detection with kernel density functions. In Proceedings of the MLDM, Leipzig, Germany, 18–20 July 2007; Volume 7, pp. 61–75. [Google Scholar]
- Lazarevic, A.; Kumar, V. Feature bagging for outlier detection. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 157–166. [Google Scholar]
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. J. Mach. Learn. Res. 2019, 20, 1–7. [Google Scholar]
- Cohen, I.; Huang, Y.; Chen, J.; Benesty, J.; Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; Volume 112. [Google Scholar]
- Axelsson, S. The base-rate fallacy and the difficulty of intrusion detection. ACM Trans. Inf. Syst. Secur. (TISSEC) 2000, 3, 186–205. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source IP | Source Port | Destination IP | Destination Port | Protocol | |
|---|---|---|---|---|---|
| Day 1 Count | 7,972,381 | 7,972,381 | 7,972,381 | 7,972,381 | 7,972,381 |
| Day 1 Unique | 1931 | 63,629 | 987 | 1578 | 3 |
| Day 1 Top | 143.198.132.18 | 99,999 | 143.239.7.57 | 53 | tcp |
| Day 1 Freq | 1,403,074 | 586,498 | 629,729 | 1,694,203 | 4,639,076 |
| Day 2 Count | 8,422,174 | 8,422,174 | 8,422,174 | 8,422,174 | 8,422,174 |
| Day 2 Unique | 1991 | 64,167 | 1308 | 1606 | 3 |
| Day 2 Top | 143.198.132.18 | 99,999 | 143.239.7.58 | 53 | tcp |
| Day 2 Freq | 1,660,695 | 579,462 | 758,855 | 1,756,672 | 5,035,476 |
| Day 1 | Day 2 | |||||
|---|---|---|---|---|---|---|
| Aggregation Level | Normal | Anomalous | Total | Normal | Anomalous | Total |
| Unaggregated | 7,972,381 | 2327 | 7,974,708 | 8,422,174 | 2327 | 8,424,501 |
| First level | 3,141,435 | 2054 | 3,143,489 | 3,372,934 | 2054 | 3,374,988 |
| Second level | 114,104 | 1411 | 115,515 | 116,395 | 1411 | 117,806 |
| Third level | 90,091 | 513 | 90,604 | 91,617 | 513 | 92,130 |
| Second Level of Aggregation | Third Level of Aggregation | |||||||
|---|---|---|---|---|---|---|---|---|
| Model Name | Recall | Precision | F1-Score | F2-Score | Recall | Precision | F1-Score | F2-Score |
| Naive Bayes | 0.9986 | 0.0052 | 0.0104 | 0.0256 | 1 | 0.0206 | 0.0403 | 0.0950 |
| Kernel Naive Bayes | 1 | 0.9331 | 0.9654 | 0.9859 | 1 | 0.6905 | 0.8169 | 0.9177 |
| Logistic Regression | 0.9008 | 0.8826 | 0.8916 | 0.8971 | 0.61 | 0.9973 | 0.757 | 0.6614 |
| Random Forest | 0.8689 | 0.9983 | 0.9291 | 0.8920 | 0.6413 | 1.0000 | 0.7815 | 0.6909 |
| Decision Tree | 0.8696 | 0.9943 | 0.9278 | 0.8920 | 0.1423 | 0.9985 | 0.2491 | 0.1718 |
| Gradient Boosted Trees | 0.8696 | 0.9895 | 0.9257 | 0.8912 | 0.6608 | 1.0000 | 0.7958 | 0.7089 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komadina, A.; Kovačević, I.; Štengl, B.; Groš, S. Comparative Analysis of Anomaly Detection Approaches in Firewall Logs: Integrating Light-Weight Synthesis of Security Logs and Artificially Generated Attack Detection. Sensors 2024, 24, 2636. https://doi.org/10.3390/s24082636
Komadina A, Kovačević I, Štengl B, Groš S. Comparative Analysis of Anomaly Detection Approaches in Firewall Logs: Integrating Light-Weight Synthesis of Security Logs and Artificially Generated Attack Detection. Sensors. 2024; 24(8):2636. https://doi.org/10.3390/s24082636
Chicago/Turabian StyleKomadina, Adrian, Ivan Kovačević, Bruno Štengl, and Stjepan Groš. 2024. "Comparative Analysis of Anomaly Detection Approaches in Firewall Logs: Integrating Light-Weight Synthesis of Security Logs and Artificially Generated Attack Detection" Sensors 24, no. 8: 2636. https://doi.org/10.3390/s24082636