A Comparison of Exposure Metrics for Traffic-Related Air Pollutants: Application to Epidemiology Studies in Detroit, Michigan

Abstract
:1. Introduction
2. Methods
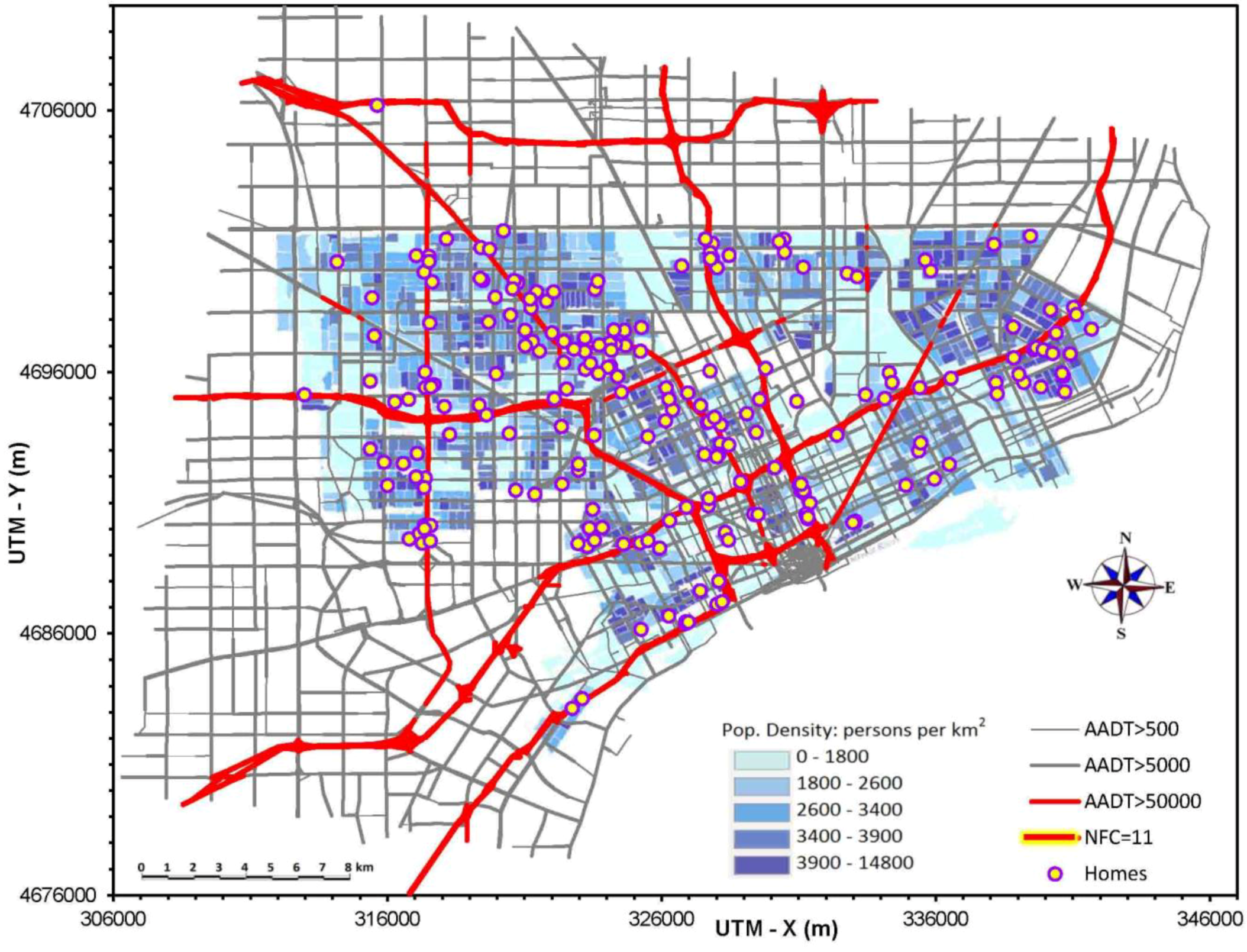
2.1. Study Population
2.2. Residential Proximity to Major Roadways

2.3. Road Network, Traffic Data and Emissions Inventory
2.4. Concentration Estimates and Dispersion Modeling
2.5. Data Analysis
3. Results
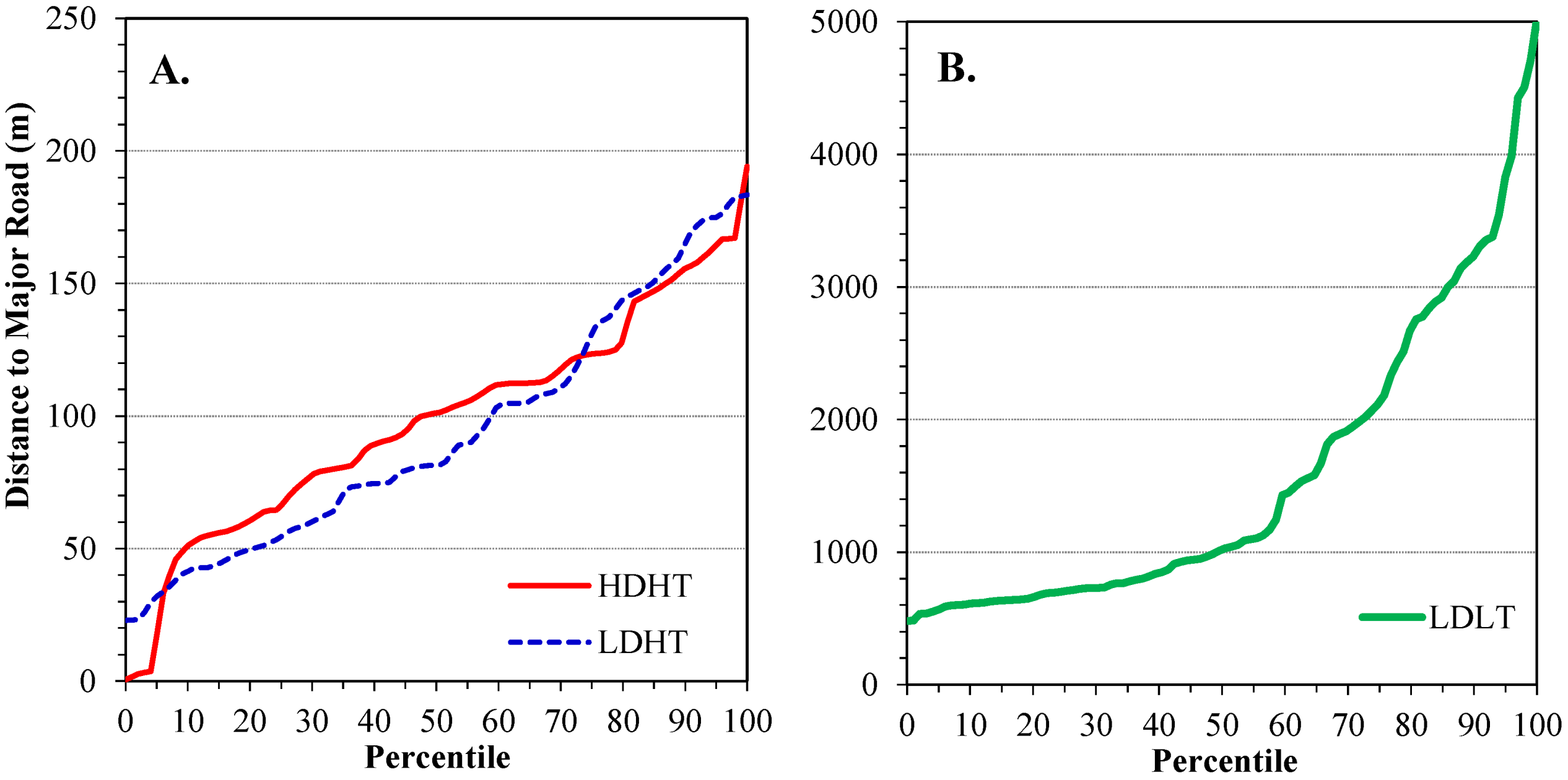
3.1. Grouping of Homes by Distance to Roads

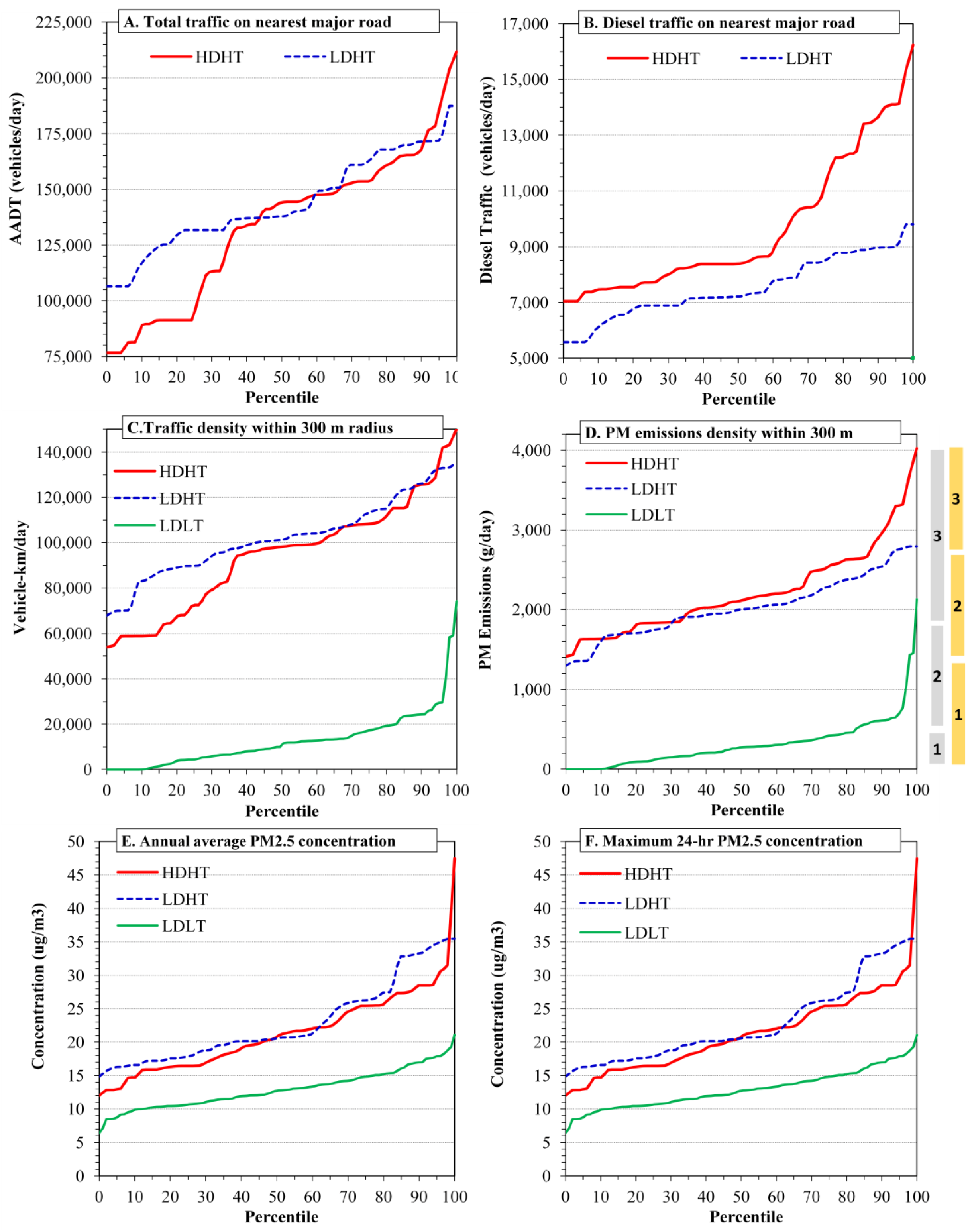
3.2. Total and Diesel Traffic Metrics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistic | All Traffic (Vehicles/Day) | Diesel Traffic (Vehicles/Day) | Number of Lanes | ||||||
|---|---|---|---|---|---|---|---|---|---|
| HDHT | LDHT | All | HDHT | LDHT | All | HDHT | LDHT | All | |
| Average | 133,737 | 143,965 | 138,638 | 9663 | 7529 | 8640 | 7.8 | 6.6 | 7.2 |
| St. Dev. | 34,962 | 21,614 | 29,634 | 2510 | 1130 | 2237 | 1.8 | 1.1 | 1.6 |
| Minimum | 76,723 | 106,508 | 76,723 | 7043 | 5570 | 5570 | 6 | 6 | 6 |
| 25th Percentile | 94,202 | 131,718 | 124,586 | 7716 | 6889 | 7182 | 6 | 6 | 6 |
| Median | 144,013 | 137,845 | 140,722 | 8386 | 7209 | 8218 | 8 | 6 | 6 |
| 75th Percentile | 153,576 | 162,808 | 160,968 | 11,297 | 8515 | 8974 | 9 | 7 | 8 |
| 95th Percentile | 185,442 | 171,849 | 180,417 | 14,098 | 8988 | 13,711 | 11 | 9 | 10 |
| Maximum | 211,750 | 187,373 | 211,750 | 16,235 | 9800 | 16,235 | 14 | 10 | 14 |
| Number | 50 | 46 | 96 | 50 | 46 | 96 | 50 | 46 | 96 |


3.3. Traffic Density Metric
3.4. Emissions Density Metrics
3.5. Concentration Metrics
| Statistic | Onroad, Annual Average | Onroad, 24-hr Peak | Hybrid, Annual Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| HDHT | LDHT | LDLT | HDHT | LDHT | LDLT | HDHT | LDHT | LDLT | |
| Average | 3.3 | 3.2 | 1.5 | 21.4 | 22.8 | 12.9 | 15.6 | 15.6 | 13.9 |
| St. Dev. | 1.2 | 1.0 | 0.4 | 6.3 | 6.2 | 2.9 | 1.4 | 1.5 | 1.3 |
| Minimum | 2.2 | 2.1 | 0.8 | 12.0 | 14.9 | 6.4 | 13.3 | 13.7 | 12.1 |
| 25th Percentile | 2.7 | 2.4 | 1.3 | 16.4 | 17.9 | 10.7 | 14.6 | 14.4 | 13.0 |
| Median | 2.9 | 3.0 | 1.5 | 20.8 | 20.6 | 12.7 | 15.4 | 15.3 | 13.6 |
| 75th Percentile | 3.8 | 3.6 | 1.6 | 25.4 | 26.2 | 14.8 | 16.2 | 16.3 | 14.4 |
| 95th Percentile | 4.8 | 4.8 | 2.4 | 29.6 | 34.7 | 17.9 | 18.2 | 18.6 | 16.5 |
| Maximum | 9.4 | 6.4 | 3.3 | 47.4 | 35.4 | 21.1 | 20.7 | 19.2 | 19.7 |
| Number | 50 | 46 | 102 | 50 | 46 | 102 | 50 | 46 | 102 |
3.6. Comparison of Exposure Metrics
| Type and Metric | Group1 | Group2 | Distance | AADT | Lanes | Diesel | VKT | PMemis | COemis | PMave | PMmax | PMtot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Group) | (Group) | (m) | (veh/day) | (no) | (veh/day) | (km/day) | (g/day) | (g/day) | (ug/m3) | (ug/m3) | (ug/m3) | |
| Spearman correlation coefficients | ||||||||||||
| Group1 | 1.00 | |||||||||||
| Group2 | 0.95 | 1.00 | ||||||||||
| Distance | −0.81 | −0.87 | 1.00 | |||||||||
| AADT | −0.12 | (a) | 0.06 | 1.00 | ||||||||
| Lanes | 0.39 | (a) | 0.31 | −0.08 | 1.00 | |||||||
| Diesel | 0.47 | (a) | −0.02 | 0.66 | 0.12 | 1.00 | ||||||
| VKT | 0.80 | 0.86 | −0.66 | 0.50 | −0.43 | 0.26 | 1.00 | |||||
| PMemis | 0.83 | 0.85 | −0.66 | 0.36 | −0.33 | 0.47 | 0.98 | 1.00 | ||||
| COemis | 0.79 | 0.86 | −0.66 | 0.48 | −0.43 | 0.25 | 1.00 | 0.98 | 1.00 | |||
| PMave | 0.78 | 0.82 | −0.75 | 0.15 | −0.24 | 0.23 | 0.78 | 0.78 | 0.78 | 1.00 | ||
| PMmax | 0.70 | 0.76 | −0.71 | 0.35 | −0.23 | 0.27 | 0.74 | 0.73 | 0.75 | 0.90 | 1.00 | |
| PMtot | 0.56 | 0.59 | −0.57 | 0.13 | −0.08 | 0.17 | 0.55 | 0.54 | 0.55 | 0.74 | 0.71 | 1.00 |
| Kendall Tau-B coefficients matrix | ||||||||||||
| Group1 | 1.00 | |||||||||||
| Group2 | 0.90 | 1.00 | ||||||||||
| Distance | −0.62 | −0.71 | 1.00 | |||||||||
| AADT | −0.10 | (a) | 0.04 | 1.00 | ||||||||
| Lanes | 0.36 | (a) | 0.23 | −0.07 | 1.00 | |||||||
| Diesel | 0.39 | (a) | −0.02 | 0.60 | 0.09 | 1.00 | ||||||
| VKT | 0.61 | 0.71 | −0.42 | 0.42 | −0.34 | 0.19 | 1.00 | |||||
| PMemis | 0.66 | 0.70 | −0.42 | 0.28 | −0.26 | 0.36 | 0.90 | 1.00 | ||||
| COemis | 0.60 | 0.70 | −0.41 | 0.40 | −0.34 | 0.18 | 0.98 | 0.91 | 1.00 | |||
| PMave | 0.62 | 0.67 | −0.58 | 0.12 | −0.18 | 0.16 | 0.55 | 0.56 | 0.55 | 1.00 | ||
| PMmax | 0.54 | 0.62 | −0.52 | 0.27 | −0.18 | 0.19 | 0.53 | 0.52 | 0.53 | 0.74 | 1.00 | |
| PMtot | 0.44 | 0.49 | −0.40 | 0.09 | −0.06 | 0.12 | 0.38 | 0.37 | 0.38 | 0.56 | 0.52 | 1.00 |
| Type and Metric | Group1 | Group2 | Distance | AADT | Lanes | Diesel | VKT | PMemis | COemis | PMave | PMmax | PMtot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (group) | (group) | (m) | (veh/day) | (no) | (veh/day) | (km/day) | (g/day) | (g/day) | (ug/m3) | (ug/m3) | (ug/m3) | |
| Agreement among tertiles (percent) | ||||||||||||
| Group1 | 100 | |||||||||||
| Group2 | 75 | 100 | ||||||||||
| Distance | 58 | 44 | 100 | |||||||||
| AADT | 28 | 36 | 33 | 100 | ||||||||
| Lanes | 24 | 26 | 18 | 38 | 100 | |||||||
| Diesel | 33 | 39 | 27 | 56 | 34 | 100 | ||||||
| VKT | 52 | 45 | 49 | 34 | 19 | 37 | 100 | |||||
| PMemis | 56 | 45 | 49 | 37 | 17 | 43 | 89 | 100 | ||||
| COemis | 53 | 45 | 48 | 33 | 21 | 35 | 96 | 90 | 100 | |||
| PMave | 60 | 51 | 66 | 32 | 20 | 34 | 58 | 61 | 59 | 100 | ||
| PMmax | 54 | 45 | 62 | 41 | 18 | 35 | 58 | 56 | 57 | 75 | 100 | |
| PMtot | 55 | 52 | 58 | 42 | 22 | 36 | 51 | 50 | 50 | 64 | 64 | 100 |
| Agreement with thirds (percent) | ||||||||||||
| Group1 | 100 | |||||||||||
| Group2 | 75 | 100 | ||||||||||
| Distance | 31 | 7 | 100 | |||||||||
| AADT | 45 | 71 | 16 | 100 | ||||||||
| Lanes | 15 | 33 | 15 | 34 | 100 | |||||||
| Diesel | 53 | 76 | 21 | 67 | 40 | 100 | ||||||
| VKT | 70 | 76 | 28 | 35 | 28 | 42 | 100 | |||||
| PMemis | 76 | 90 | 14 | 60 | 31 | 74 | 80 | 100 | ||||
| COemis | 70 | 73 | 30 | 33 | 28 | 38 | 97 | 78 | 100 | |||
| PMave | 64 | 80 | 12 | 47 | 33 | 50 | 70 | 77 | 69 | 100 | ||
| PMmax | 65 | 76 | 15 | 60 | 30 | 48 | 68 | 76 | 66 | 77 | 100 | |
| PMtot | 56 | 68 | 13 | 44 | 39 | 43 | 61 | 62 | 59 | 72 | 67 | 100 |
4. Discussion
| Type | Exposure Metricas Defined for NEXUS | Strengths | Limitations | Results in Detroit |
|---|---|---|---|---|
| 1. Distance to major road | Distance from home to road edge, and distance from home to road centerline, using GPS home location. | Simple to construct. Low data needs. Can potentially distinguish roads with varying traffic volume, vehicle mix, or other characteristics. | Distance limit used as cutoffs for classifying homes/receptors is arbitrary. May not consider traffic volume, vehicle mix, and other factors. Sensitivity to distance calculation, e.g., using road edge or centerline. | HDHT and LDHT roads had comparable distances to homes. LDLT distances considerably exceeded HDHT and LDHT groups, by design and recruitment approach. |
| 2. Total traffic volume on nearby roads | AADT roads within 200 m of homes, using nearest road edge and GPS home location. | Relatively simple to construct. Reasonably good volume estimates on major roads. Can select period of day, e.g., rush-hour. | Traffic volume estimates needed. Distance criterion used to determine road is arbitrary. Does not provide metric for low traffic groups. | HDHT and LDHT groups largely indistinguishable. HDHT group had considerable range. |
| 3. Diesel (or truck or commercial) traffic volume on nearby roads | Roads within 200 m of homes using road edge and GPS home location. | Relatively simple to construct. May relate to PM emissions from diesel traffic. Can select period of day. | Difficult to estimate diesel traffic volume accurately. Does not account for type of diesel vehicles and emissions. Otherwise as 2 above. | HDHT and LDHT groups were largely indistinguish-able. HDHT group had roughly 10%-20% higher diesel volumes than LDHT group, but about 2/3 of the values overlapped. |
| 4. Local traffic density | AADT on road segments with 300 m distance (buffer) around each home, based on distance to road centerline, GPS home location, and traffic-demand model estimates of AADT. | Includes local traffic emissions that might affect receptor. Result (VKT/day) is easily interpretable and possibly generalizable. Large range across sites. Can be applied to irregular shaped sources and receptors. Can select period of day. Relevant to traffic analysis zones used by planners. | Moderately high data needs. Computationally intensive. Sensitive to distance criterion, which is somewhat arbitrary. Uncertainty of traffic estimates on all but major roads. Excludes smaller roads. | LDHT group had slightly greater exposure than the HDHT group. All but a few LDLT homes had low values. |
| 5. Emissions on local roads | As 4 above with addition of annual average road-link emissions estimates for PM2.5, NOx and CO. | Incorporates vehicle emissions of pollutants of interest. Reflects vehicle mix on roads. Also as 4 above. | Results depend on pollutant, to an extent. High data needs. Computationally intensive. Difficult to estimate emissions accurately. | For PM2.5 and NOx, HDHT had slightly higher exposure than LDLT. For CO, results are reversed but very similar All but a few LDLT homes had much lower values. |
| 6. Pollutant concentration predictions | PM2.5 predictions at homes used road-link emissions inventory and RLINE dispersion model; area and point sources using AERMOD and regional sources handled using CMAQ and kriging interpolations of monitoring data. | Incorporates effects of emissions, meteorology, and location in physically-based approach. Quantifies and apportions concentrations due to each sources, e.g., traffic. Can be derived for specific periods of day, season or year, e.g., daily predictions at rush hour periods. Inter-study comparisons are possible and meaningful. | Results depend on pollutant, averaging time, and statistic. High data needs. Computationally intensive. Uncertainty not well characterized. Results potentially sensitive to many factors, including home placement. | For PM2.5, HDHT and LDHT distributions were similar although some dependence on averaging time and statistic. PM2.5 contributions from local traffic at HDHT and LDHT homes were about twice those at LDLT homes. Regional sources provide much (80%) of total PM2.5, but smaller contributions of NOx and CO. |
5. Conclusions
Supplementary Files
Supplementary File 1Acknowledgments
Author Contributions
Conflicts of Interest
References
- Health Effects Institute. Traffic-Related Air Pollution: A Critical Review of the Literature on Emissions, Exposure, and Health Effect; HEI: Boston, MA, 2010. [Google Scholar]
- Zhu, Y.; Kuhn, T.; Mayo, P.; Hinds, W.C. Comparison of daytime and nighttime concentration profiles and size distributions of ultrafine particles near a major highway. Environ. Sci. Technol. 2006, 40, 2531–2536. [Google Scholar] [CrossRef]
- Hitchins, J.; Morawska, L.; Wolff, R.; Gilbert, D. Concentrations of submicrometre particles from vehicle emissions near a major road. Atmos. Environ 2000, 34, 51–59. [Google Scholar] [CrossRef] [Green Version]
- Karner, A.A.; Eisinger, D.S.; Niemeier, D.A. Near-roadway air quality: Synthesizing the findings from real-world data. Environ. Sci. Technol. 2010, 44, 5334–5344. [Google Scholar] [CrossRef]
- Reponen, T.; Grinshpun, S.A.; Trakumas, S.; Martuzevicius, D.; Wang, Z.M.; LeMasters, G.; Lockey, J.E.; Biswas, P. Concentration gradient patterns of aerosol particles near interstate highways in the Greater Cincinnati airshed. J. Environ. Monit. 2003, 5, 557–562. [Google Scholar]
- Baldauf, R.; Thoma, E.; Hays, M.; Shores, R.; Kinsey, J.; Gullett, B.; Kimbrough, S.; Isakov, V.; Long, T.; Snow, R.; et al. Traffic and meteorological impacts on near-road air quality: Summary of methods and trends from the Raleigh near-road study. J. Air Waste Manag. Assoc. 2008, 58, 865–878. [Google Scholar] [CrossRef]
- Barzyk, T.M.; George, B.J.; Vette, A.F.; Williams, R.W.; Croghan, C.W.; Stevens, C.D. Development of a distance-to-roadway proximity metric to compare near-road pollutant levels to a central site monitor. Atmos. Environ. 2009, 43, 787–797. [Google Scholar] [CrossRef]
- Hagler, G.S.W.; Baldauf, R.W.; Thoma, E.D.; Long, T.R.; Snow, R.F.; Kinsey, J.S.; Oudejans., L.; Gullett, B.K. ltrafine particles near a major roadway in Raleigh, north Carolina: Downwind attenuation and correlation with traffic-related pollutants. Atmos. Environ. 2009, 43, 1229–1234. [Google Scholar] [CrossRef]
- Hu, S.S.; Fruin, S.; Kozawa, K.; Mara, S.; Paulson, S.E.; Winer, A.M. A wide area of air pollutant impact downwind of a freeway during pre-sunrise hours. Atmos. Environ. 2009, 43, 2541–2549. [Google Scholar] [CrossRef]
- Huang, Y.L.; Batterman, S. Residence location as a measure of environmental exposure: A review of air pollution epidemiology studies. J. Expo. Anal. Environ. Epidemiol. 2000, 10, 66–85. [Google Scholar]
- Beevers, S.D.; Kitwiroon, N.; Williams, M.L.; Kelly, F.J.; Ross Anderson, H.; Carslaw, D.C. Air pollution dispersion models for human exposure predictions in London. J. Expo. Sci. Environ. Epidemiol. 2013, 23, 647–653. [Google Scholar] [CrossRef]
- Özkaynak, H.; Baxter, L.K.; Dionisio, K.L.; Burke, J. Air pollution exposure prediction approaches used in air pollution epidemiology studies. J. Expo. Sci. Environ. Epidemiol. 2013, 23, 566–572. [Google Scholar] [CrossRef]
- Batterman, S. The near-road ambient monitoring network and exposure estimates for health studies. Environ. Manager. 2013, 24–30. [Google Scholar]
- Brauer, M. How much, how long, what, and where: air pollution exposure assessment for epidemiologic studies of respiratory disease. Proc. Amer. Thor. Soc. 2010, 7, 111. [Google Scholar] [CrossRef]
- Rioux, C.L.; Gute, D.M.; Brugge, D.; Peterson, S.; Parmenter, B. Characterizing urban traffic exposures using transportation planning tools: an illustrated methodology for health researchers. Journal of urban health : bulletin of the New York Academy of Medicine 2010, 87, 167–188. [Google Scholar]
- Jerrett, M.; Arain, A.; Kanaroglou, P.; Beckerman, B.; Potoglou, D.; Sahsuvaroglu, T.; Morrison, J.; Giovis, C. A review and evaluation of intraurban air pollution exposure models. J. Expos. Anal. Environ. Epidem. 2005, 15, 185–204. [Google Scholar]
- Sheppard, L.; Burnett, R.T.; Szpiro, A.A.; Kim, S.-Y.; Jerrett, M.; Pope, C.A., III; Brunekreef, B. Confounding and exposure measurement error in air pollution epidemiology. Air Qual. Atmos. Health. 2012, 5, 203–216. [Google Scholar] [CrossRef]
- Brauer, M.; Reynolds, C.; Hystad, P. Traffic-related air pollution and health in Canada. Can. Med. Assn. J. 2013, 185. [Google Scholar] [CrossRef]
- Kioumourtzoglou, M.-A.; Spiegelman, D.; Szpiro, A.A.; Sheppard, L.; Kaufman, J.D.; Yanosky, J.D.; Williams, R.; Laden, F.; Hong, B.; Suh, H. Exposure measurement error in PM2.5 health effects studies: A pooled analysis of eight personal exposure validation studies. Environ Health 2014, 13. [Google Scholar] [CrossRef]
- Vette, A.; Burke, J.; Norris, G.; Landis, M.; Batterman, S.; Breen, M.; Isakov, V.; Lewis, T.; Gilmour, M.I.; Kamal, A.; et al. The near-road exposures and effects of urban air pollutants study (NEXUS): Study design and methods. Sci. Total Environ. 2013, 448, 38–47. [Google Scholar]
- Bing Maps. Available online: http://www.bing.com/maps (accessed on 1 May 2014).
- Aitchison, A. The Google Maps/Bing Maps Spherical Mercator Projection. Available online: http://alastairawordpresscom/2011/01/23/the-google-maps-bing-maps-spherical-mercator-projection/ (accessed on 14 April 2014).
- ESRI. ESRI Geocoder Information. Available online: http://www.esri.com/software/arcgis/arcgisonline/credits/geocoding (accessed on 21 February 2010).
- Ganguly, R.; Batterman, S. Effect of geocoding errors on traffic-related air pollutant concentration estimates. J. Exp. Sci. Environ. Epid. 2014. under review.
- Michigan Department of Transportation. ADT & CADT Map Archive Lansing, MI: Michigan Department of Transportation. Available online: http://mdotcf.state.mi.us/public/maps_adtmaparchive/ (accessed on 1 April 2014).
- Office of Highway Policy Information, U.S. Federal Highway Administration, Department of Transportation. Highway Statistics Series—Highway Statistics 2010. Available online: https://www.fhwa.dot.gov/policyinformation/statistics/2010/vm4.cfm (accessed on 11 February 2014).
- U.S. Environmental Protection Agency. Technology Transfer Network Clearinghouse for Inventories & Emissions Factors—Emission Inventory Improvement Program 2014. Available online: http://www.epa.gov/ttn/chief/eiip/index.html (accessed on 11 February 2014).
- Cook, R.; Isakov, V.; Touma, J.S.; Benjey, W.; Thurman, J.; Kinnee, E.; Ensley, D. Resolving local-scale emissions for modeling air quality near roadways. J. Air Waste Manage. Assoc. 2008, 58, 451–461. [Google Scholar] [CrossRef]
- Isakov, V.; Touma, J.S.; Burke, J.; Lobdell, D.T.; Palma, T.; Rosenbaum, A.; Ozkaynak, H. Combining regional- and local-scale air quality models with exposure models for use in environmental health studies. J. Air Waste Manage. Assoc. 2009, 59, 461–472. [Google Scholar] [CrossRef]
- Snyder, M.G.; Venkatram, A.; Heist, D.K.; Perry, S.G.; Petersen, W.B.; Isakov, V. RLINE: A line source dispersion model for near-surface releases. Atmos. Environ. 2013, 77, 748–756. [Google Scholar] [CrossRef]
- Venkatram, A.; Snyder, M.G.; Heist, D.K.; Perry, S.G.; Petersen, W.B.; Isakov, V. Re-formulation of plume spread for near-surface dispersion. Atmos. Environ. 2013, 77, 846–855. [Google Scholar] [CrossRef]
- U.S. Environmental Protection Agency. RLINE—A Research LINE-Source Dispersion Model for Near-Surface Releases. Available online: https://www.cmascenter.org/r-line/ (accessed on 1 April 2014).
- Heist, D.; Isakov, V.; Perry, S.; Snyder, M.; Venkatram, A.; Hood, C.; Stocker, J.; Carruthers, D.; Arunachalam, S.; Owen, R.C. Estimating near-road pollutant dispersion: A model inter-comparison. Transp. Res. Pt. D-Transp. Enviro. 2013, 25, 93–105. [Google Scholar]
- Snyder, M.; Arunachalam, S.; Isakov, V.; Heist, D.; Batterman, S.; Talgo, K.; Ganguly, R.; Harbin, P. Sensitivity Analysis of Dispersion Model Results in the NEXUS Health Study due to Uncertainties in Traffic-Related Emissions Inputs. In Air & Waste Management Association Annual Conference & Exhibition, Chicago, IL, USA, 25–28 June 2013.
- Isakov, V.; Arunachalam, S.; Batterman, S.; Bereznicki, S.; Burke, J.; Dionisio, K.; Garcia, V.; Heist, D.; Perry, S.; Snyder, M.G.; et al. Air quality modeling in support of the near-road exposures and effects of urban air pollutants study (NEXUS). Int. J. Environ. Res. Public Health 2014. submitted. [Google Scholar]
- Apte, J.S.; Bombrun, E.; Marshall, J.D.; Nazaroff, W.W. Global intraurban intake fractions for primary air pollutants from vehicles and other distributed sources. Environ. Sci. Technol. 2012, 46, 3415–3423. [Google Scholar]
- Hoek, G.; Beelen, R.; de Hoogh, K.; Vienneau, D.; Gulliver, J.; Fischer, P.; Briggs, D. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos. Environ. 2008, 42. [Google Scholar] [CrossRef]
- Allen, R.W.; Amram, O.; Wheeler, A.J.; Brauer, M. The transferability of NO and NO2 land use regression models between cities and pollutants. Atmos. Environ. 2011, 45. [Google Scholar] [CrossRef]
- Wang, R.; Henderson, S.B.; Sbihi, H.; Allen, R.W.; Brauer, M. Temporal stability of land use regression models for traffic-related air pollution. Atmos. Environ. 2013, 64. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Batterman, S.; Burke, J.; Isakov, V.; Lewis, T.; Mukherjee, B.; Robins, T. A Comparison of Exposure Metrics for Traffic-Related Air Pollutants: Application to Epidemiology Studies in Detroit, Michigan. Int. J. Environ. Res. Public Health 2014, 11, 9553-9577. https://doi.org/10.3390/ijerph110909553
Batterman S, Burke J, Isakov V, Lewis T, Mukherjee B, Robins T. A Comparison of Exposure Metrics for Traffic-Related Air Pollutants: Application to Epidemiology Studies in Detroit, Michigan. International Journal of Environmental Research and Public Health. 2014; 11(9):9553-9577. https://doi.org/10.3390/ijerph110909553
Chicago/Turabian StyleBatterman, Stuart, Janet Burke, Vlad Isakov, Toby Lewis, Bhramar Mukherjee, and Thomas Robins. 2014. "A Comparison of Exposure Metrics for Traffic-Related Air Pollutants: Application to Epidemiology Studies in Detroit, Michigan" International Journal of Environmental Research and Public Health 11, no. 9: 9553-9577. https://doi.org/10.3390/ijerph110909553