2. Materials and Methods
The main motivation and starting point in devising our research methodology consisted of designing, developing, and implementing a new forecasting method for both the produced and consumed electricity of small wind farms situated on quite complex hilly terrain that offers an improved accuracy when compared to the forecasting method that some members of our research team previously developed and implemented in a series of wind farms [
25].
In this previous work [
25], some members of our research team tackled issues regarding the development of a FITNET Artificial Neural Networks solution, useful in forecasting the wind electricity production in the case of small wind farms in Romania, situated on hilly terrain, with the aim to improve the day-ahead hourly prediction accuracy. Therefore, the developed method has been validated using a case study based on a set of historical data, comprising two-year records (since the 1 January 2013 to the 31 December 2014), from a wind power plant comprising two power production groups (one of 5 MW and one of 10 MW) located in the southeastern part of Romania.
The method devised in the previous work [
25] uses the meteorological forecast from a specialized institute and allocates it to the turbine that has proven to have its meteorological parameters recorded by its sensors closest to the ones provided by the institute (named Turbine 1). Afterwards, a FITNET Artificial Neural Network approach is used to forecast the meteorological parameters of the other turbine based on the allocated forecasted weather numerical parameters of the first turbine, both turbines belonging to the same 5 MW production group. This method has provided very good results; the 5 MW production group contains only two turbines, therefore allowing FITNET-type neural networks to be used in order to forecast the meteorological parameters using three inputs representing the meteorological forecasted dataset from the institute (the temperature, the absolute wind direction, and average wind speed) that produces three outputs representing the meteorological datasets of the second turbine (the temperature, the absolute wind direction, and average wind speed).
Therefore, in the case of the 5 MW production group, the developed network managed to forecast the meteorological dataset for the second turbine using a FITNET approach in order to accurately adjust the meteorological parameters. However, in what regards the 10 MW production group containing four turbines, the results of a FITNET forecasting meteorological Artificial Neural Network, trained to predict the meteorological parameters for the turbines 2, 3 and 4, produced considerable errors when the FITNET network received the three inputs related to the meteorological data provided by the specialized institute allocated to the first turbine, and had to produce nine outputs (three datasets, regarding three meteorological parameters: temperature, absolute wind direction, and average wind speed) in order to reconstruct the corresponding meteorological dataset. These considerable errors represent a drawback that arose, on the one hand, from the increased number of turbines, and on the other hand, from the quite complex hilly terrain that rendered the global forecast from the specialized institute useless, even if all of the four turbines are situated within the same weather prediction area. Consequently, in the method of colleagues past work [
25], the research team developed and implemented an upscaling algorithm that forecasts the electricity production of the 10 MW production group, using the forecasted produced electricity of the 5 MW group.
In order to overcome the deficiencies of the previous research study, in this paper, we have developed a forecasting method by incorporating the advantages of both Long Short-Term Memory (LSTM) artificial neural networks and Function Fitting Artificial Neural Networks (FITNET), applying them in different stages and steps of the newly developed forecasting method. The method benefits from the properties of Long Short-Term Memory networks, from their ability to learn and manage long-term dependencies among data, in order to refine the meteorological parameters provided by the specialized institute for a large number of turbines located within the same weather prediction area without having to allocate the forecast of the institute to a certain turbine. Therefore, the forecasting accuracy is refined up to the level of each and every turbine, exceeding the limitations of the initial method [
25,
26] in which case we had to employ, also taking into account the computational constraints, an upscaling technique applied directly to the electricity produced by the 5 MW production group in order to extrapolate the output of the 10 MW group. Details regarding the hardware and software configurations, along with the motivation for using them can be found in the
Appendix A.1.
We have structured our devised forecasting method into five consecutive stages. In the first stage, consisting of five steps, we have acquired and preprocessed the datasets collected from the specialized meteorological institute, from the turbines’ sensors, and from the 10 MW Production Group.
During the six steps of the second stage of the method, we have developed the LSTM artificial neural networks with exogenous variables support in view of refining the meteorological forecast at each turbine’s level, based on the Adaptive Moment Estimation (ADAM), Stochastic Gradient Descent with Momentum (SGDM), and Root Mean Square Propagation (RMSPROP) training algorithms.
Afterwards, in stage three of the method, we elaborated, during five steps, the function fitting ANNs solutions for predicting the produced and consumed electricity, based on the Levenberg–Marquardt (LM), Bayesian Regularization (BR), and Scaled Conjugate Gradient (SCG) training algorithms.
During stage four, over the course of four steps, we have validated the forecasting by obtaining the prediction of the produced and consumed electricity using the best combination of the two components of our approach (LSTM and FITNET ANNs).
In the last stage, the fifth one, we have performed the compilation of the developed method for assuring its integration in a wide range of custom-tailored forecasting applications for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain.
In the following, we briefly present the main concepts that we have made use of when developing our forecasting method in order to familiarize the multidisciplinary reader with the materials and methods used.
2.1. Long Short-Term Memory Artificial Neural Networks
A Long Short-Term Memory (LSTM) Artificial Neural Network (ANN) represents a type of RNN capable of learning long-term dependencies between time steps of sequence data. Unlike traditional ANNs, LSTM ANNs contain loops inside them which allow information to persist, being passed from each step of the network to the next one. This type of RNN was introduced by Hochreiter & Schmidhuber in 1997 [
27], and afterwards was refined and popularized by many authors in other works [
28,
29,
30,
31,
32,
33,
34]. The LSTMs Network architecture includes, as core components, a sequence input layer designed to input time series or sequences into the network and a Long Short-Term Memory layer whose purpose is to learn the long-term dependencies between time steps of sequence data [
27].
The Long Short-Term Memory ANNs are useful in classifying, processing, and forecasting data starting from time series. They were successfully used in applications regarding artificial intelligence, natural language processing [
35], and unconstrained handwriting recognition [
36], being considered as very useful tools by renowned technology and business companies (Microsoft, Google, Apple, and Amazon). For instance, Microsoft used the LSTM approach in speech recognition and declared in 2017 that they have obtained an accuracy of more than 95% on a dataset containing 165,000 words [
37]; Google employed LSTMs in achieving speech recognition on their smartphones, for the Google Translate application, and for the Google Allo smart messaging app assistant [
38], Apple used LSTM in developing their virtual assistant Siri and the QuickType keyboard on iPhone, while Amazon has benefited from the advantages of the LSTM ANNs when it has developed the Amazon Alexa cloud-based voice service [
39].
A LSTM network comprises a series of specific LSTM units, each of these units being composed of a cell that remembers values over time intervals and three gates that manage the information flow through the cell: an input gate, an output gate, and a forget gate. The LSTM’s cell is designed to take input data and store it for a set amount of time. As a mathematical formalism, the identical function
is applied to the input value
. Obviously, the derivative of this function is
, a constant function. This approach has a major advantage, as in this case, if a Long Short-Term Memory Neural Network is trained using the backpropagation, the gradient does not vanish [
40].
The vanishing gradient problem is an issue that appears in the process of training the ANNs using gradient-based learning methods. When this problem arises, the gradient-based method has difficulties in learning and tuning the parameters of the previous layers of the network and the problem gets worse with the increase in the number of network layers. This type of network learns the value of a parameter by integrating the way in which small changes of this value can affect the output of the network. Sometimes, such changes of a certain parameter’s values cause imperceptible changes of the output, affecting it to a very small extent. In these cases, the network has difficulties in learning this parameter, causing the vanishing gradient problem, a case in which the gradients of the output of the network, regarding the above-mentioned parameters, decrease considerably. Therefore, in such situations, even if the values of the parameters from previous layers are subjected to large changes, the output is not affected [
40].
Each component of a LSTM’s cell architecture has a certain role in managing and controlling specific activities: the input gate manages and controls the way in which each new value fills a cell, the output gate manages and controls the way in which the values within a cell are used in computing the output, while the forget gate is responsible for the way in which a value remains in the corresponding LSTM cell. The LSTM gates are connected to each other and a few of these connections are recurrent. During the training process, the weights of the above-mentioned connections should be learned by the LSTM ANN as they determine the operation of the gates.
In order to bring the total training error corresponding to a Long Short-Term Memory network to a minimum, one usually adjusts each of the weights in rapport to the derivative of the error that it is related to by using an iterative gradient descent technique like back-propagation over time. However, an important issue arises when using a gradient descent approach for training RNNs consisting of the vanishing gradient problem that makes the error gradient vanish exponentially the higher the size of the time lag is between different significant events. This issue occurs because of the fact that
when the spectral radius corresponding to
is less than 1 [
41]. Conversely, in the case of Long Short-Term Memory units, the errors are stored in the memory of the units when the back-propagation process generates and propagates the errors back based on the output. The errors keep back-propagating to the gates up to the moment when the gates learn to interrupt the process. Consequently, the main drawback of the back-propagation technique is overcome, and the technique becomes efficient for training Long Short-Term Memory units allowing them to learn and remember values for long periods of time.
In the scientific literature, it has been shown that LSTM ANNs can also be successfully trained using techniques based on evolution strategies, genetic algorithms, policy gradient methods, or by using a mix of artificial evolution techniques applied for the weights to the hidden units and support vector machines (SVM) or pseudo-inverse approaches for the weights to the output LSTM units [
41].
The Gradient Descendent algorithm is among the most popular algorithms useful in training and optimizing ANNs. It is widely used and implemented in many Deep-Learning libraries, for example, lasagna [
42], caffe [
43], and keras [
44]. The Gradient Descent algorithm has three main variants, that are classified by taking into account the amount of data that is used to compute the gradient of the objective function, namely: the Batch gradient descent, the Stochastic gradient descent, and the Mini-batch gradient descent. In each case, the amount of data influences the accuracy obtained in updating the parameter but also the required time for update. The gradient descent targets to minimize an objective function, depending on the model’s parameters, by updating the parameters along with a direction that is opposite to the gradient of the objective function with respect to the involved parameters. The size of the necessary steps that must be followed in order to obtain the minimum of the objective function is determined by the learning rate.
The most frequently used algorithms within the deep learning research community for optimizing the gradient descent algorithm are Adadelta, Adagrad, Momentum, Adam, AdaMax, AMSGrad, Nadam, Nesterov accelerated gradient, and RMSprop. In the following, we present the main properties of the Stochastic Gradient Descent with Momentum (SGDM), Root Mean Square Propagation (RMSPROP), and Adaptive Moment Estimation (ADAM) training algorithms, considering the fact that we will develop our LSTM ANNs with exogenous variables support meteorological forecasting solutions based on these algorithms.
2.1.1. The SGDM Training Algorithm
The Stochastic Gradient Descent with Momentum (SGDM) training algorithm is based on the same approach as the Stochastic Gradient Descent algorithm, attempting to minimize an objective function by adjusting the parameters of the network (weights and biases), by taking small steps in the opposite direction of the gradient of the objective function. In the case of the Stochastic Gradient Descent algorithm, the updating formula is as follows:
where
represents the number of the iteration,
is the parameter under discussion,
is a positive number that represents the learning rate,
is the objective function, and
is the gradient of the computed objective function, based on the entire training dataset. The algorithm evaluates the gradient, and at each step updates the parameters based on the so-called “mini-batch”, a subset of the training set. Each time when the gradient is computed by using the mini-batch, an iteration takes place and during each iteration, a new step in minimizing the objective function is completed. Each time when the training algorithm processes the whole training dataset by using the mini-batch subset, an epoch is completed.
The Stochastic Gradient Descent has a series of drawbacks due to the fact that it might oscillate along the above-mentioned direction when searching the local minimum [
45]. In order to overcome this drawback and solve the issue, the SGDM training algorithm adds a new term in the equation, a “momentum term” [
46]:
where
is a parameter that reflects the contribution of the previous gradient step within the current iteration, while
represents the “momentum term”. By applying this method, the Stochastic Gradient Descent is accelerated along the relevant direction, while the oscillations are diminished because the momentum term increases the updates for the cases in which the gradients are oriented within the same directions, but reduces the updates in the cases when the gradients change their directions.
2.1.2. The RMSPROP Training Algorithm
As mentioned before, the Gradient Descent algorithm updates the weights and biases of the network in order to minimize the objective function by using the same learning rate for all the parameters. In contrast to this approach, a series of optimization algorithms use different learning rates for different parameters. An example of such an optimization algorithm is the Root Mean Square Propagation (RMSPROP) training algorithm. This algorithm has a few similarities with the SGDM training algorithm, it also diminishes the oscillations, but it targets the ones in the vertical direction. Consequently, the learning rate can be increased, and the algorithm is capable of accepting larger steps in the horizontal direction as the convergence is attained faster.
The RMSPROP training algorithm first computes the moving average, based on the relation [
47]:
where
represents the number of the iteration,
is the moving average,
is the parameter under discussion,
is the decay rate of the moving average [
48],
is the objective function, and
is the gradient of the objective function. The usual values of the decay rate are 0.9, 0.99, and 0.999. Based on the moving average, the RMSProp algorithm normalizes the updates of the parameters, using a customized relation for each of them [
47]:
where
represents the number of the iteration,
is the moving average,
is the parameter under discussion,
is a positive number that represents the learning rate,
is the objective function,
is the gradient of the objective function, and
is a small positive constant added to avoid division by zero. Using RMSPROP, the learning rates are reduced for the parameters that have large gradients, while for the parameters having small gradients, the learning rates are increased [
48].
2.1.3. The Adam Training Algorithm
The Adaptive Moment Estimation (ADAM) training algorithm is based on the computation of the adaptive learning rates for all the parameters of the model. In the case of the ADAM training algorithm, the decaying averages of past and past squared gradients
and
are computed [
48]:
where
represents the number of the iteration,
and
are the decaying averages of past and past squared gradients; they are also the estimates of the first moment (the mean) and the second moment (the uncentered variance) of the gradients,
is the parameter under discussion,
is a positive number that represents the learning rate,
is the objective function,
is the gradient of the objective function,
is the decay rate of the moving average, and
is the gradient decay rate. The update rule in this case is based on the averages given by the relations (5) and (6) [
48]:
where
represents the number of the iteration,
is the moving average,
is the parameter under discussion,
is a positive number that represents the learning rate, and
is a small positive constant added to avoid division by zero.
2.2. Function Fitting Artificial Neural Networks
Artificial Neural Networks (ANNs) are systems inspired from the biological natural neural networks within the animals’ and humans’ brains, designed to learn to perform activities starting from certain examples, for example in image recognition, signal processing, pattern classification, social network, speech recognition, machine translation, and medical diagnosis [
49,
50].
An ANN is composed of a collection of interconnected units (or nodes), called neurons (or artificial neurons) which resemble the biological natural neurons from a brain. These units operate in parallel, being connected via weights. Like in the case of the synapses of the biological brain, the connections between neurons transmit a signal from one unit to another. An artificial neuron receives a signal, processes it, and afterwards, passes it to another interconnected unit. For most of the implementations of Artificial Neural Networks, each neuron’s output is computed as a nonlinear function depending on the inputs. The artificial units and their associated connections have a specific weight that is adjusted within the learning process, therefore influencing the strength of the connections’ signals. The neurons are organized into layers, which are structured according to the different tasks that they have to perform on the inputs. Each signal passes through the network’s layers starting from the input layer to the output layer.
A particular case of ANN is the feed-forward neural network, the first developed type of ANNs. In this case, unlike the case of the RNNs, the connections between the neurons do not present cycles or loops, as the information flows unidirectional, forward, starting from the input nodes, to the hidden ones and finally to the output ones [
51]. A particular case of feed-forward neural networks is represented by function fitting ANNs (FITNET ANNs), which are characterized by the fact that they are used in order to fit a relationship between the input and the output. In the literature, it has been proven that a feed-forward network with one hidden layer and enough neurons in the hidden layers can fit any finite input–output mapping problem [
52].
In order to learn perform specific tasks, ANNs are trained using certain training algorithms. The best training algorithm (from the accuracy and the training time points of views) differs from case to case, for each specific problem, and depends on a wide variety of factors, such as the problem’s complexity, the dimension of the training dataset, the structure of the network in what concerns the weights and biases, the network’s architecture and complexity, the accepted error, the accuracy level, and the purpose of the training error.
Due to their incontestable advantages, we have chosen to develop and make use of, in certain stages of our forecasting method, several function fitting ANNs trained using three widely used algorithms: the Levenberg-Marquardt, the Bayesian Regularization, and the Scaled Conjugate Gradient algorithms. In the following, we present the main characteristics of these three training algorithms.
2.2.1. The LM Training Algorithm
The Levenberg-Marquardt (LM) training algorithm uses as an objective function, the sum of squared errors, minimizes the objective function based on the gradient descent and the Gauss-Newton methods, performing training, validation, and testing steps. The LM algorithm is useful in training ANNs and is based on a network training function that updates the values of the weights and biases [
53]. The algorithm is based on an approach consisting in a sequence of steps, targeting the attaining of the minimum of a function that represents a sum of the squares of nonlinear functions of real values [
54].
This algorithm combines the advantages of two methods, namely the Gauss-Newton method and the steepest descendent one. The algorithm has the capability of adjusting its processing in accordance with the obtained forecasting dataset: if the forecasted values are close to the experimental ones then the algorithm processes data based on the Gauss-Newton method, while in the opposite case, based on the steepest descent method [
55]. The detailed mathematical formalism can be found in a past paper [
56].
2.2.2. The BR Training Algorithm
The Bayesian Regularization (BR) training algorithm uses as an objective function a linear combination of squared weights and squared errors, uses the LM algorithm and back-propagation as methods to minimize the objective function, performing training and testing steps. The BR training algorithm is based on a function that updates the values of the weights and biases according to a methodology that targets to minimize a combination of squared errors and weights, in order to obtain a network that has an increased generalization capability [
53].
This process is entitled the Bayesian regularization [
54]. The regularization is based on an adjustment of the objective function by adding to it a term consisting of the squares of the network’s weights. The regularization aims to obtain a very smooth response of the network to the above-mentioned adjustment. The detailed mathematical formalism can be found in two reference papers: McKay [
57] introduced the algorithm for the first time, while Foresee et al. [
58] made further improvements to it.
2.2.3. The SCG Training Algorithm
The SCG training algorithm uses, as an objective function, the sum of squared errors, which uses the conjugate gradient approach and the Levenberg-Marquardt’s approach of model-trust region as methods to minimize the objective function, performing training, validation, and testing steps [
53].
The Scaled Conjugate Gradient (SCG) training algorithm is useful in training networks that have their weights, inputs, and transfer functions modeled as derivative functions. The derivatives of the performance function, with respect to the weighs and biases, are computed based on the backpropagation technique. As with many other training algorithms, SCG is based on the conjugate directions approach, posing the benefit of not being necessary to perform a line search at every iteration. The training process stops if one of the following conditions is met: the maximum number of epochs is reached; a previous established time interval is exceeded; the desired level of performance is attained; the performance gradient attains its minimum value; or the validation performance has increased up to a certain level. The detailed mathematical formalism can be found in the paper of Møller, who first introduced this algorithm in the scientific literature [
59].
In what follows, we describe, in detail, the stages and steps that one must perform in order to reproduce our developed forecasting method.
2.3. Stage I: Acquiring and Preprocessing the Data
We have designed the first stage for data acquiring and preprocessing activities. Consequently, we have designed the first step of this stage in view of acquiring and concatenating the data collected from the specialized meteorological institute, from the turbines’ sensors, and from the 10 MW Production Group of a wind power plant located in the southeastern part of Romania, covering a two-year period, from 1 January 2016 to 31 December 2017.
The measurements have been conducted at a 10 MW production group (connected to the general grid) of a small wind farm comprising four wind turbines of two types manufactured by the Vestas company, namely V90 2 MW/3 MW IEC IA/IIA having a hub with the height of 90 m, devised for medium and high wind sites that are characterized by high turbulences. The V90 3 MW wind turbine has a cut-in wind speed of 3.5 m/s, while the V90 2 MW turbine’s cut-in wind speed is 4 m/s. The four turbines are situated within the same weather prediction area. The 10 MW production group is located at an altitude of 75 m measured from sea level. The terrain has many hills, the highest of them being 22.8 m high measured from the ground (97.8 m from the sea level). This quite complex hilly terrain redirects the wind, which in turn causes turbulences that makes it hard to achieve an accurate forecast of the produced and consumed energy (
Figure 1).
The historical hourly meteorological forecasted data have been acquired from a specialized weather institute by the wind farm operator and consists of the Average Temperature measured in degrees Celsius (ATI), Absolute Wind Direction measured in degrees (AWDI), and Average Wind Speed measured in meters per second (AWSI), for the years 2016 to 2017, corresponding to the Weather Prediction Area (WPA) within which the 10 MW production group, comprising four wind turbines, is located. This dataset consists of three vectors, each of them containing 17,544 records representing the hourly meteorological data for the years 2016 to 2017.
We have retrieved the historical hourly meteorological data from the sensors of the four turbines, therefore obtaining, for each turbine, the Average Temperature measured in degrees Celsius (ATTk), the Absolute Wind Direction measured in degrees (AWDTk), and the Average Wind Speed measured in meters per second (AWSTk), for the years 2016 to 2017, where represents the number of the turbine. Therefore, this dataset contains three vectors for each turbine, resulting in a total of 12 vectors, each of them comprising 17,544 records that represent the hourly meteorological data for the years 2016 to 2017.
We have acquired the historical hourly total produced electricity measured in MWh (TPE) and the historical hourly total consumed electricity measured in MWh (TCE) of the 10 MW production group for the years 2016 to 2017 from the wind farm operator. This dataset consists of two vectors, each of them containing 17,544 records, representing the hourly produced and consumed electricity at the level of the whole 10 MW production group for the years 2016 to 2017. The datasets and detailed information about them can be found in the
Supplementary Materials.
Afterwards, we have concatenated the datasets collected from the specialized meteorological institute, from the turbines’ sensors, and from the 10 MW Production Group into the DS dataset.
In the first stage’s second step, the records that are registered during the maintenance activities are identified and marked as correct values. During this process, the values of the parameters registered by the turbines’ sensors could sometimes appear abnormal, for example, having zero value. Therefore, these values were identified according to the wind farm’s maintenance log, taking into account that, in the respective day, one or more turbines underwent scheduled maintenance activities. Afterwards, these values are marked within the dataset as being correct values.
During the third step of the developed method’s first stage, the dataset from the previous step is filtered and reconstructed in order to solve the problem of missing or erroneous values. These two types of values are identified in the database by the way in which they are displayed, namely: when the data from the sensors is missing (as it has not been registered correctly on the storage device), the value “N/A” is stored and displayed in the database; when the sensors have encountered a measurement error or when an abnormal value that goes beyond the possible range of values has been registered, the value “Err” is stored and displayed in the database. In this purpose, we have applied a technique entitled “gap-filling” that we have developed and applied successfully in our previous works [
60,
61]. This technique employs the linear interpolation, in order to fill in the missing values. As all the involved data are discreet (being collected hourly) and the number of missing values was very small (20 separate values, from different days), we were able to apply, successfully, the “gap-filling” technique. Therefore, we have obtained a dataset (DMR) consisting of 17 vectors, each of them containing 17,544 records. Afterwards, we have created a copy of this dataset, entitled DMC in order to be processed within the upcoming method’s stages.
In the fourth step of the devised forecasting method’s first stage, we have trimmed the DMC dataset from Step 3 by removing the hourly produced and consumed electricity components, therefore obtaining a dataset consisting in 15 vectors, DMCT.
During the fifth step of the first stage of our devised forecasting method, we have reconstructed the DMCT dataset from the previous step by replacing the zero-values corresponding to the maintenance activities, values that have been previously identified and marked in Step 2 with the values obtained by applying the “gap-filling” technique as if the maintenance operations had not been carried out. We have therefore obtained a dataset consisting of 15 vectors, each of them containing 17,544 records (DMCTR).
2.4. Stage II: Developing the LSTM ANNs with Exogenous Variables Support in View of Refining the Meteorological Forecast at the Level of Each Turbine
In stage two we developed the LSTM ANNs with exogenous variables support in view of refining the meteorological forecast at each turbine’s level, based on the ADAM, SGDM, and RMSPROP training algorithms.
Accordingly, in the first step of the developed forecasting method’s second stage, we have extracted two subsets from the DMCTR dataset and divided them into training and validation samples. We have started from the DMCTR dataset from the fifth step of the first stage, consisting of 15 vectors, each of them containing 17,544 records, and we have extracted from it by removing the dataset from the meteorological institute, a subset of 12 vectors, each of them containing 17,375 records (from record 2 up to the record 17,376 of the DMCTR dataset), namely DMCTRS. The remaining 168 records of the 12 vectors were used to construct the validation dataset, entitled DMCTRV.
In the second step of the second stage, we have normalized the DMCTR dataset (by adjusting the data as to have a zero mean and a variance of 1) in order to obtain a better fit and avoid the risk of a divergence occurring in the training process, obtaining the subset DMCTRN. Afterwards, we have chosen, as training inputs, 17,375 records of this dataset (from the first record up to the record 17,375 of the DMCTRN dataset). Secondly, we have normalized the 17,375 records of the DMCTRS dataset, obtaining the subset DMCTRSN. Afterwards, we have chosen this vector for training responses (outputs).
In the second stage’s third step, we have developed 20 LSTM ANNs with exogenous variables support meteorological forecasting solutions based on the ADAM training algorithm. Details regarding the technical parameters for the ADAM training algorithm can be found in
Appendix A.2. In what concerns the number of hidden units, we have tested different values, meaning
in order to obtain the best configuration with regard to the forecasting accuracy. According to our devised method, we have run, for each value of
, 100 training iterations. After having performed all of these training iterations, out of the 100 obtained ANNs in each of the cases, we have saved the LSTM artificial neural network that has registered the best performance metrics and discarded the rest. The 100 chosen training iterations have assured an appropriate division of the training dataset that is performed randomly at each iteration, therefore, minimizing the risk of obtaining an unsatisfactory result due to a poor choice of the minibatches from the big training dataset in the event that the number of hidden units has been appropriately chosen. After several experiments, the chosen value of 100 training iterations has offered a good balance between the required training time and obtaining the best trained network when using a certain number of neurons.
In all the cases, when comparing the forecasting accuracy of the LSTM ANNs, we have used, as a performance metric, the value of the Root Mean Square Error (RMSE) computed based on the forecasted values and the real ones, for 24 h and also for 7 days, along with charts depicting the fit between the forecasted and real data [
62]. Nonetheless, we must point out that the main purpose of the paper is to cover the need of the contractor, who is interested in an as-accurate-as-possible next day hourly prediction for 24 h. However, we wanted to assess how well the method performs on a longer forecasting time horizon, as if the wind farm operator had been asked to provide a forecast in advance for the whole week.
Besides the performance metrics, an important factor that we have also taken into account when choosing the best forecasting LSTM ANN consists of the necessary time for training each of the developed networks. The training time is a very important aspect for the moment when the method is put into practice in a real production environment, taking into account that the neural networks will require subsequent training processes as time passes by and new datasets containing hourly samples are collected. Therefore, we have obtained 20 forecasting LSTM ANNs for the ADAM training algorithm.
In the fourth step of the second stage of the forecasting method, we have developed LSTM ANNs with exogenous variables support meteorological forecasting solutions based on the SGDM training algorithm. Details regarding the technical parameters for the SGDM training algorithm can be found in the
Appendix A.3. We have used the same methodology as in the case of the ADAM training algorithm regarding the number of hidden units, the number of iterations, and the performance assessment in order to develop the forecasting LSTM ANNs for the SGDM training algorithm. Finally, we have obtained 20 forecasting LSTM ANNs for the SGDM training algorithm, corresponding to a number of hidden units
.
In the second stage’s fifth step, we developed ANNs with exogenous variables support meteorological forecasting solutions based on the RMSPROP training algorithm. Details regarding the technical parameters for the RMSPROP training algorithm can be found in
Appendix A.4. We have used the same testing and performance assessment methodology as in the cases of the ADAM and SGDM training algorithms regarding the number of hidden units,
and the number of training iterations, therefore obtaining 20 forecasting LSTM ANNs for the RMSPROP training algorithm.
In the second stage’s sixth step, based on the performance assessment methodology used in the steps three to five, we have chosen the best LSTM ANN with exogenous variables support meteorological forecasting solution. For this purpose, a comparison of the prediction accuracy has been made for identifying the network that has registered the best forecasting results from all the 20 ones developed based on the ADAM training algorithm, namely the LSTM_ADAM ANN. Subsequently, using the same approach for the 20 obtained LSTM ANNs based on the SGDM training algorithm we have obtained the network LSTM_SGDM ANN as having the best forecasting accuracy. Using the same approach, we have selected from the 20 obtained LSTM ANNs for the RMSPROP training algorithm the LSTM_RMSPROP ANN that has provided the best forecasting results. Finally, we have compared the forecasting accuracy of the LSTM_ADAM, LSTM_SGDM, and LSTM_RMSPROP ANNs and obtained the best LSTM forecasting solution.
2.5. Stage III: Developing the FITNET Forecasting Solutions for the Produced and Consumed Electricity
We have designed the third stage of the forecasting method in order to develop the FITNET forecasting solutions for the produced and consumed electricity, trained using the above-mentioned algorithms (LM, BR, and SCG).
Therefore, in the first step of the developed forecasting method’s third stage, we have extracted two subsets from the DMR dataset and divided them into training, validation, and testing samples. We have first extracted two subsets from the DMR dataset, consisting of 12 vectors, each of them containing 17,376 records of the meteorological datasets from the turbines (DMRI) as inputs for the networks and a subset containing the hourly produced and consumed electricity, consisting of two vectors, each of them containing 17,376 records (DMRO) as outputs for the networks. The remaining 168 records of the vectors from the DMRO dataset were used to construct the final validation dataset, entitled DMRV. We have divided the 17,376 records of the DMRI and DMRO datasets by allocating, in each of the two cases, 70% of samples for the training process (12,164 samples), and the remaining percentage was equally divided between the validation process and the testing one, in the case of the LM and SCG training algorithms (2606 samples per each of these two processes). As regards the BR training algorithm, the 2631 samples corresponding to the validation process were set aside, as this process does not take place in this case. In all cases, the data sampling was achieved randomly. We have normalized the errors. Details regarding the normalization process can be found in the
Appendix A.5.
Over the course of the third stage’s second step, we developed 40 FITNET ANNs solutions for predicting the produced and consumed electricity, based on the LM training algorithm. We used the previously obtained inputs and outputs and during the testing process, different architectures were employed, varying the hidden layer’s size, namely
, in order to obtain the best configuration with regard to the forecasting accuracy. For each value of
, we have run 100 training iterations and saved the FITNET ANN that provided the best forecasting accuracy and discarded the remaining networks. The rationale behind the decision to choose 100 training iterations is the same as in the case of developing the LSTM ANNs meteorological forecasting component of the method. In all the cases, when comparing the forecasting accuracy of the FITNET ANNs, we used, as performance metrics, the values of the Mean Squared Error (MSE) and the correlation coefficient R [
62]. Besides the performance metrics, an important factor that we have also taken into account when choosing the best forecasting FITNET ANN consists of the necessary time for training each of the developed networks. When the forecasting method is put into practice in a real production environment, the neural networks will require subsequent training processes due to the new registered datasets containing hourly samples and, therefore, the training time is an aspect of great importance that must be considered in the evaluation process of the developed ANNs’ performance. Therefore, we have obtained 40 forecasting FITNET ANNs for the LM training algorithm.
In the third step of the third stage, we developed 40 FITNET ANNs solutions for predicting the produced and consumed electricity, trained using the BR algorithm along with the previously obtained inputs and outputs using the same methodology as the LM training algorithm, thus obtaining 40 forecasting FITNET ANNs for the BR training algorithm.
In the fourth step, like in the case of the other training algorithms, we developed 40 FITNET forecasting solutions for the produced and consumed electricity, based on the SCG training algorithm.
During the third stage’s fifth step, we chose the best function fitting ANN solution for predicting the produced and consumed electricity. For this purpose, we first analyzed the prediction performance for the 40 function fitting forecasting solutions for the produced and consumed electricity, trained based on the LM algorithm, and obtained the network that has provided the best forecasting accuracy, namely the FITNET_LM ANN. Using the same approach, we identified the artificial neural networks, trained using the BR and SCG algorithms, that have provided the best results within their category, namely the FITNET_BR and the FITNET_SCG ANNs. Finally, by comparing the performance in terms of accuracy of the three selected FITNET ANNs we have obtained the best FITNET forecasting solution for the produced and consumed electricity.
2.6. Stage IV: The Forecasting Solution’s Validation
During this stage, the forecasting solution has been validated by obtaining the prediction of the produced and consumed electricity using the best combination of the two components of our approach (LSTM and FITNET ANNs).
Therefore, in the first step of the fourth stage, we forecasted the meteorological datasets using the best LSTM with exogenous variables support meteorological forecasting solution identified in Step 6 of Stage II. We first initialized the best LSTM meteorological forecasting ANN state based on the first 17,375 records of the DMCTRN dataset.
We inserted, in the last record of the DMCTRSN dataset, the values of the meteorological parameters provided by the specialized weather institute corresponding to the last day of the DMCTRSN dataset in order to pad the 12 existing values that contain the meteorological data for the turbines with the three exogenous values representing the meteorological parameters at the level of the Weather Prediction Area (WPA)—provided by the meteorological institute—in order to obtain the 15 necessary values for the sequence input. Using this devised sequence input and the best LSTM with exogenous variables support meteorological forecasting solution, identified in Step 6 of Stage II, we have forecasted the values for the first hour out of the 168 dataset for the above-mentioned 12 variables.
We have repeated this process in order to forecast the meteorological datasets for all 168 h, one step at a time, by inserting, at each step, the three exogenous values of the meteorological parameters provided by the specialized weather institute in order to pad the 12 forecasted values of the current time step (hour) containing the meteorological data from the turbines in order to obtain the 15 necessary values for the sequences inputs that will be used to forecast the remaining timesteps.
We have denormalized the forecasted dataset, containing the values for all 168 h for the 12 vectors containing the refined meteorological parameters corresponding to the four turbines, namely DSF, in view of validating the LSTM with exogenous variables support forecasting solution.
In the fourth stage’s second step, we have validated the LSTM with exogenous variables support forecasting solution and, implicitly, the refined forecasted meteorological dataset. The forecasted dataset DSF has been compared with the validation dataset DMCTRV, containing the real values. We have computed as a performance metric the root-mean-square error (RMSE) for the next 24 h, which is the purpose of our paper and also for the whole week (168 h), in order to analyze how the devised LSTM with exogenous variables support forecasting solution performs on a longer prediction horizon.
For achieving an appropriate comparison, we have also calculated and represented the plots of the differences for the whole week (168 h) between the forecasted dataset and the real values stored in the validation dataset, as to obtain and analyze the fit that the best LSTM with exogenous variables support meteorological forecasting solution identified in Step 6 of Stage II achieves.
Throughout the fourth stage’s third step, we have forecasted the produced and consumed electricity using the best FITNET ANN forecasting solution identified in Step 5 of Stage III. We have used, as an input, the previously forecasted dataset, containing the refined meteorological parameters at the turbines level and we have obtained as outputs the forecasted values of the produced and consumed electricity dataset DMRF. In the fourth stage’s four step, we have validated the FITNET ANN forecasting solution. The forecasted dataset DMRF has been compared with the final validation dataset DMRV containing the real values. We have computed, as a performance metric, the root-mean-square error (RMSE) for the next 24 h, which is the purpose of our paper and also for the whole week (168 h), in order to analyze how the devised FITNET ANN forecasting solution performs on a longer prediction horizon. For achieving an appropriate comparison, we have also calculated and represented the plots of the differences for the whole week (168 h) between the forecasted dataset and the real values, stored in the final validation dataset, as to obtain and analyze the fit that the best FITNET ANN forecasting solution identified in Step 5 of Stage III achieves.
2.7. Stage V: Compiling the Developed Method
We have designed the fifth stage to perform the compilation of the obtained method for preparing its incorporation into a wide range of custom-tailored forecasting applications for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain.
In the first step of the last stage of the developed forecasting method for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain, the method that benefits from the multiple advantages of both the developed meteorological LSTM with exogenous variables support ANN and the developed function fitting FITNET ANN, has been compiled as a Java package, a Python package, C and C++ software libraries, a.NET assembly, and a Component Object Model add-in in order to assure the developed forecasting method’s integration in a wide range of custom tailored applications.
During the fifth stage’s second step, we have implemented the compiled Java package from Step 1 of Stage V in the existing wind farm’s computer-based information system that has been previously developed by members of our research team during their research project [
26].
By compiling the method in the MATLAB (R2018a) Compiler Software Development Kit and incorporating it into the MATLAB (R2018a) Production Server, we avoid the need to constantly recode, recompile, and recreate custom infrastructure for the application. The contractor, who is also the owner of several wind power plants, will be able to access the latest version of the forecasting method, along with the analytical capabilities from the MATLAB Production server automatically, with minimal effort. Another advantage of the implementation approach is the fact that the MATLAB Production Server can handle multiple and different versions of MATLAB Runtimes in the same time. Consequently, when updates are provided, the whole method will be integrated without any compatibility issues and without having to recode it, therefore reducing the maintenance costs of the developed solution.
The devised forecasting method, described in the above sections for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain, which incorporates both the advantages of LSTM neural networks and the advantages of FITNET neural networks, is synthesized in the following block diagram (
Figure 2).
In the next section, we analyze the results registered after conducting the experimental tests.
3. Results
We used the hardware and software configurations, the acquired datasets, and have carried out the stages and steps specified in detail within the Materials and Methods section in order to design, develop, and implement the forecasting method for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain. In the following, we present a concise and precise description of the main registered experimental results.
3.1. Results Regarding the Developed LSTM ANNs with Exogenous Variables Support in View of Refining the Meteorological Forecast at the Level of Each Turbine
According to the presented methodology, we have developed a long short-term memory artificial neural network with exogenous variables support forecasting solution, in order to refine the meteorological forecast provided by the specialized institute for the Weather Prediction Area (WPA) at each turbine’s level. We have tested various settings concerning the algorithm used for training the neural networks (ADAM, SGDM, and RMSPROP), the dimension of the hidden layer (
), therefore developing 20 LSTM ANNs in each case. In the following, the obtained results were synthesized after having validated the 20 developed LSTM ANNs per each training algorithm, by computing the Root Mean Square Error (RMSE) performance metric, based on the forecasted values and the real ones, for 24 h and also for 7 days. We have also registered the running time in each case.
Table 1 presents a synthesis of the obtained results; the comprehensive results can be found in the
Appendix A.6 (
Table A1).
By analyzing the registered results (
Table 1) and comparing the forecasting accuracy and training time of the 20 LSTMs ANNs developed, based on the ADAM training algorithm, we have identified the network that provided the best forecasting accuracy, denoted LSTM_ADAM ANN, namely the network developed when choosing 100 hidden units. In this situation, the following results were obtained. For the RMSE performance metric, a value of 0.1609 for the next day hourly prediction (24 h), a value of 1.8662 for the next week hourly prediction (168 h), and a time of 170 s for training the network, which is a very good result for the moment when the network has to be retrained, using new datasets acquired after the network is implemented in a production environment.
Afterwards, using the same approach, we have identified the network based on the SGDM training algorithm that has offered the best forecasting accuracy, namely the one having a number of 1000 hidden units, denoting this network by LSTM_SGDM ANN. This network has registered the lowest values for the RMSE performance metric: a value of 3.0185 for the next day hourly prediction (24 h), a value of 14.0831 for the next week hourly prediction (168 h), and a time of 705 s for training the network.
Using the same approach, we have selected, from the 20 obtained LSTM ANNs for the RMSPROP training algorithm, the LSTM_RMSPROP ANN that has provided the best forecasting results. This network was developed using 1000 hidden units and we have obtained a value of 9.5072 for the next day hourly prediction (24 h), a value of 17.8254 for the next week hourly prediction (168 h), and a time of 704 s for training the network.
By analyzing all 60 ANNs developed using the ADAM, SGDM, and RMSPROP algorithms, one can conclude that, due to their very good prediction accuracy, these networks offer the possibility to be employed in a production environment on a daily basis. When we have tried to increase the number of hidden units, we observed a significant increase in the time needed to train the artificial neural networks, while the performance did not register any further improvements in terms of accuracy. Furthermore, when increasing the number of hidden units over 1000, in all the cases, the overfitting process appeared. Therefore, in all cases we had to limit the maximum number of hidden units to 1000 and benchmark the obtained results up to this value.
Finally, according to our devised methodology, we have compared the forecasting accuracy of the three selected ANNs (LSTM_ADAM, LSTM_SGDM, and LSTM_RMSPROP) and we have observed that the best forecasting accuracy was registered in the case of the LSTM_ADAM ANN, therefore, this is the best long short-term memory artificial neural network with exogenous variables support forecasting solution in order to refine the meteorological forecast provided by the specialized institute at the level of each of the turbines. One can find in the
Supplementary Materials file the LSTM ANNs that have registered the best results for each training algorithm, namely: LSTM_ADAM, LSTM_SGDM, and LSTM_RMSPROP.
Next, the results registered after having forecast the produced and consumed electricity using the function fitting artificial neural network developed in this purpose are presented.
3.2. Results Registered when Forecasting the Produced and Consumed Electricity
After having applied the devised methodology for training the function fitting ANNs, we have registered, in each situation, the performance metrics consisting in the Mean Squared Error (MSE) and the correlation coefficient R computed for the entire dataset.
Table 2 presents a synthesis of the obtained results; the comprehensive results can be found in the
Appendix A.6 (
Table A2).
By analyzing the obtained results, one can observe that the best prediction in terms of accuracy is achieved by the following ANNs: in the case of the Levenberg–Marquardt algorithm, the ANN with 33 hidden neurons (entitled FITNET_LM ANN), as in this case the value of the Mean Squared Error is 0.0048263 (the lowest of all the values of MSE for all the networks trained using the LM algorithm), the value of the correlation coefficient is 0.98672 (the highest of all the values of R for all the networks trained using the LM algorithm and very close to 1), and the training time is only 7 s; as regards the Bayesian Regularization training algorithm, the ANN with 35 hidden neurons (entitled FITNET_BR ANN), because, in this situation, the MSE performance metric is 0.0011195 (the lowest of all the values of MSE for all the networks trained using the BR algorithm), the correlation coefficient is 0.99628 (the highest of all the values of R for all the networks trained using the BR algorithm and very close to 1), while attaining a training time of 208 s; in the case of the Scaled Conjugate Gradient algorithm, the ANN with 26 hidden neurons (entitled FITNET_SCG ANN), case in which the value of MSE is 0.010419, the value of R is 0.96417, and the registered training time is only 6 s. One can find in the
Supplementary Materials the FITNET ANNs that have registered the best results for each training algorithm, namely the FITNET_LM, FITNET_BR, FITNET_SCG.
Analyzing the obtained results, one can notice that in all the cases the best results have been registered for a hidden layer size higher than 25 and lower than 40. If one increases the size of the hidden layer, the recorded results are worse than those synthetized in
Table 2, due to data overfitting.
Even if in the case of the SCG training algorithm we have registered the lowest performance metrics, in this case, the necessary training times are considerably lower than in the cases of the LM and BR training algorithms. Therefore, if the ANNs need to be frequently retrained for new datasets, or if issues regarding the required training memory occur for the ANNs, the SCG training algorithm could be a convenient solution due to its low memory requirements and increased computational speed.
Subsequently, by comparing the forecasting accuracy of the FITNET_LM, FITNET_BR and FITNET_SCG ANNs we have identified the best function fitting solution for predicting the produced and consumed electricity: the FITNET_BR ANN.
In the following, we analyze the performance plots of the FITNET_BR artificial neural network, presenting the performance plots that depict the Mean Squared Error (MSE), the error histogram, and the regressions between the network targets and network outputs. We first plotted the training and testing curves in view of analyzing the best training performance that has been recorded when one forecasts the produced and consumed electricity using the FITNET_BR artificial neural network (
Figure 3a).
The plot highlights that the best validation performance has been attained at epoch 1000, when the recorded value of MSE is 0.0011195. By analyzing
Figure 3a, one can notice that the testing curve does not increase significantly before the training curve, in fact both of the curves are almost identically, therefore confirming the high level of performance and prediction accuracy of the FITNET ANN and the fact that the developed solution does not overfit the results. The performance plot (
Figure 3a) also confirms that the data division process has been performed appropriately and that the training process was efficient. This aspect is substantiated by the fact that the training and testing curves do not increase anymore after they have converged, therefore reconfirming the robustness of the function fitting ANN approach that we have developed within Stage III of our forecasting method, and the fact that this solution forecasts with an increased level of accuracy both the produced and consumed electricity of the wind farm’s 10 MW production group.
Afterwards, we have plotted and evaluated the error histogram concerning the case when the FITNET_BR network forecasts the produced and consumed electricity and we have noticed that this plot emphasizes and confirms the excellent prediction accuracy and efficiency of the developed FITNET ANN forecasting solution, because the majority of errors fall between −0.283 and 0.3448, a narrow interval, while in most frequent cases, the difference between the targets and outputs has a value of 0.04374 (
Figure 3b).
Subsequently, we have computed and plotted the regressions regarding the FITNET_BR artificial neural network’s targets and outputs when forecasting the produced and consumed electricity of the wind farm’s 10 MW production group. The plot highlights the fact that the correlation coefficient
R registered a value of 0.99628 for the entire dataset emphasizing the very good fit provided by the FITNET_BR ANN (
Figure 3c).
In the fourth stage of our developed forecasting method, the prediction solution has been validated by obtaining the prediction of the produced and consumed electricity using the LSTM_ADAM and FITNET_BR ANNs. The results of the validation process are presented next.
3.3. Results Registered When Validating the Forecasting Solution
In the fourth stage, the forecasting solution has been validated in view of assessing its prediction accuracy in a real-world environment, by obtaining the forecast of the produced and consumed electricity using the best combination of the two components of our approach (LSTM and FITNET ANNs), and comparing the obtained forecasted results with the real values.
Consequently, in the first step we have forecasted the meteorological datasets using the best LSTM with exogenous variables support meteorological forecasting solution identified in Step 6 of Stage II, for a period of 7 days (168 h). We have computed, as a performance metric, the root-mean-square error (RMSE) for the next 24 h, which is the purpose of our paper and also for the whole week (168 h), in order to analyze how the devised LSTM with exogenous variables support solution performs on a longer prediction horizon. The RMSE values of 0.1609 (for 24 h) and 1.8662 (for 168 h) were considered very good, useful results by the wind farm operator.
For achieving an appropriate comparison, we have also calculated and represented the plots of the
differences for the whole week (168 h) between the forecasted dataset and the real values, stored in the validation dataset (corresponding to the period of 25 to 31 of December 2017) to obtain and analyze the fit of the best LSTM with exogenous variables support meteorological forecasting solution identified in Step 6 of Stage II. The plots show very low values of the
differences for the first day (24 h) and, after that point, the differences start to increase, even if they still remain low. The plotted differences highlight the fact that the forecasting accuracy is excellent for the first 24 h and good for the whole next week, up to the 168th time step. In
Figure 4 is presented an eloquent but nonlimitative case regarding the obtained
differences for the Turbine 1. See the
Supplementary Materials for comprehensive details regarding the obtained results for all the turbines.
After having obtained the meteorological hourly forecast for the next seven days, we used this forecast to obtain the produced and consumed electricity using the best FITNET ANN forecasting solution identified in Step 5 of the Stage III, for the same period, 25 to 31 of December 2017. We have computed, as a performance metric, the root-mean-square error (RMSE) for the next 24 h, which is the purpose of our paper and also for the whole week (168 h), in order to analyze how the devised FITNET ANN forecasting solution performs on a longer prediction horizon. The RMSE values of 0.0080 (for 24 h) and 0.0539 (for 168 h) are considered excellent and useful results by the wind farm operator.
In order to validate the FITNET ANN forecasting solution, we have computed and plotted the
differences for the whole week (168 h) between the forecasted dataset and the real values, which were stored in the final validation dataset to obtain and analyze the fit that the best FITNET ANN forecasting solution identified in Step 5 of the Stage III achieves. The
differences are very low in the first day and even if they increase afterwards, they still remain low for the whole period of one week. The fact that the forecasted results are very close to the real ones confirms the high-degree of accuracy and efficiency of our forecasting method for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain (
Figure 5). See the
Supplementary Materials for comprehensive details regarding the obtained results of the forecasting method.
After having analyzed the results, we can state that we have obtained and validated an accurate forecasting method for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain.
4. Discussion
This paper addresses small-scale wind farms, and has the main purpose to overcome the limitation of lowering the forecasting accuracy arising from wind deflection caused by the quite complex hilly terrain. Our devised forecasting method brings together the advantages of Long Short-Term Memory ANNs and those of feed-forward function fitting neural networks FITNET ANNs.
Analyzing
Figure 4 and
Figure 5 in the above section, representing
differences for the whole week (168 h) between the forecasted dataset and the real values, one can observe that the plots from these figures are characterized by an increasing sinusoid shape with small, nonlinear increasing amplitude over time and a relative symmetric trend with respect to the horizontal axis. The plots depict an excellent day-ahead forecasting accuracy (the purpose of the study); the developed method is also able to register good hourly results in terms of accuracy for up to one whole week. One can notice that the forecasting accuracy begins to decrease starting around day 3, this fact being accounted for due to the errors of the exogenous meteorological dataset that our developed LSTM meteorological forecasting prediction solution uses in order to refine the weather forecast parameters up to the level of each turbine. The relative symmetric trend of the chart, with respect to the horizontal axis, highlights the fact that the forecasting errors are both positive and negative as the forecasted values are sometimes higher and sometimes lower than the real ones, having comparable values during close time moments.
In each of the analyzed cases, the performance metrics were chosen in accordance with the official development environment (MATLAB) enterprise documentation recommendation for each type of the developed artificial neural networks in order to be sure that a relevant metric is computed and used in accordance with the training process implementation resulting from the MATLAB source code [
62]. Therefore, when refining the meteorological forecast at the level of each turbine, for highlighting and analyzing the prediction accuracy of the 60 developed LSTM ANNs in view of achieving an appropriate comparison, we have computed the values of the RMSE performance metric, based on the forecasted values and the real ones, for 24 h and 7 day forecasts, selecting the ANN that has provided the minimum value of the RMSE. We have also synthetized for each of the training algorithms the ANNs that have provided the worst performance, highlighted by the greatest values of the RMSE performance metric (
Table 3).
Therefore, one can notice that the best prediction accuracy regarding the developed LSTM ANNs is attained for the ADAM training algorithm and a hidden layer size of
. The synthetized results from
Table 3 show that, in what concerns the value of the RMSE performance parameter for the hourly day-ahead prediction (for the next 24 h), the improvement registered in the best case compared to the worst varies between 96.62% and 99.82%, while in the case of the RMSE performance parameter for the hourly next week prediction (for the next 168 h), the improvement ranges between 39.37% and 97.53%. With regard to the training time, the difference between the case of the best and the worst ANNs developed using the ADAM training algorithm is only 18 s, during which the above-mentioned performance improvements take place.
Likewise, when predicting the produced and consumed electricity, for evaluating and analyzing the prediction accuracy of the 120 function fitting neural networks, we have computed the values of the performance metrics (MSE and R), based on which, the best ANN has been chosen. As we wanted to gain a deeper insight regarding the performance improvement in terms of forecasting accuracy, we have also synthetized the FITNET ANNs that provided the lowest degree of prediction accuracy, and for each of the training algorithms, the cases in which the highest values of the MSE and the values of R furthest from 1 have been recorded (
Table 4).
Regarding the FITNET ANNs, we have observed that the best prediction accuracy has been obtained for values of N larger than 25 and smaller than 36, while the best forecasting ANN has proven to be the one having a hidden layer size of 35 neurons, trained based on the BR algorithm. Analyzing the results synthetized in
Table 4, one can remark that, in what concerns the MSE performance metric, the improvement registered in the case of the best ANNs, when compared to the worst ones, varies between 64.71% and 96.53%, while concerning the correlation coefficient R, it has been improved by a percentage ranging from 8.71% to 12.19%. Concerning the training time, the difference between the case of the best and the worst ANNs developed using the BR training algorithm is 207 s, but the difference is insignificant considering the huge performance improvements that are achieved.
In both cases of the LSTM and FITNET ANNs, increasing the hidden layer’s size over a certain limit led to, in some situations, a significant increase in training time as well as lower performance; in other cases the overfitting process has occurred.
After having implemented our forecasting method in a real production environment, when forecasting the meteorological parameters for the day after tomorrow, namely the second day, we devised our LSTM ANNs with exogenous variables support solution within the devised forecasting method so that it will use, instead of its own predicted 24 values representing the refined forecasted meteorological parameters of the four turbines corresponding to the 24 h of the first day, the real 24 values that have been recorded at the end of the day by the turbine’s sensors. We have explored this approach, and after having evaluated its performance impact, we have observed that the Long-Short-Term-Memory Network provides better forecasting results as it takes into account the real values from the previous day.
However, in this paper, even if our main purpose was achieving an accurate hourly forecast only for the next day (the main need of the wind farm operator) for the produced and consumed electricity, we have computed the 7-day hourly forecast (even if the wind farm operator only needs an as-accurate-as-possible hourly forecast for the day-ahead, namely the next 24 h) using the previously forecasted values of the LSTM artificial neural network in order to investigate the behavior of our developed forecasting method in the case that the wind farm operator would have had to provide an up to seven-day forecast ahead to the National Dispatch Center. For example, in the case of national holydays, the wind operator has to provide the forecast more than one day in advance.
The accurate forecasting of the produced and consumed electricity brings a series of benefits such as maximizing revenues for the day-ahead electricity market by notifying the amount of electricity to be sold as close as possible to the actual produced quantity, reducing the balancing costs, minimizing the loss of Green Certificates received monthly from the dispatchable units, and facilitating the settlement of bilateral electricity contracts.
Certainly, the accurate forecasting of the produced and consumed electricity for power systems is an essential aspect in order to assure a balance between the electricity generation and the demand, both of which must be constantly fine-tuned and controlled. This aspect is even more important considering the stochastic nature of the wind that determines fluctuations in electricity production. In the situation where the wind farm’s production groups are located on complex hilly terrain, such as the case in the current paper, the challenge to design, develop, and implement an accurate forecasting method for the produced and consumed electricity is even greater, as one has to overcome the additional problems created by the complex hilly terrain that can hinder the accuracy of what could otherwise be a good wind power prediction method.
In our previous researches [
26], along with our research team, we have managed to develop a forecasting method based on a function-fitting ANN approach that is useful in predicting the produced electricity from wind renewable sources in the case of small wind farms located on complex hilly terrain areas from Romania, having as a main target the day-ahead hourly forecasting accuracy. The research conducted within the project targeted a series of such small capacity wind farms situated on complex hilly terrains. As a nonlimitative example of applying the developed method, in the past paper, authored by members of our research team [
25], the team reported the main results of applying the forecasting method to a small wind farm that comprised two production groups, one of 5 MW and the other of 10 MW, located on complex hilly terrain, in the southeastern part of Romania.
The method employed [
25] used numerical weather parameters forecasted by a specialized meteorological institute and allocated these parameters to the wind turbine that had, based on the historical meteorological data recorded by the turbines’ sensors, the weather parameters closest to the ones provided by the meteorological institute, this turbine being considered the initial turbine, or Turbine 1. For the purpose of refining these meteorological parameters for the other turbines, a previously trained FITNET Artificial Neural Network was used to predict the numerical weather parameters for the second turbine, which belonged to the same 5 MW production group, using, as inputs, the allocated meteorological parameters of the first turbine.
In the case of the 5 MW production group that contained two turbines, the method registered very good results, therefore being able to be used in predicting the numerical weather parameters of the second turbine (the temperature, absolute direction of the wind, and average wind speed) using, as inputs, the allocated meteorological dataset of the first turbine that consisted of the forecasted temperature, absolute wind direction and average wind speed from the specialized meteorological institute. However, when trying to refine the forecasting accuracy for the 10 MW production group comprising of four turbines, the results of the FITNET meteorological forecasting Artificial Neural Network trained to forecast the refined numerical weather parameters in the case of turbines 2, 3, and 4, registered substantial errors when using as inputs the allocated forecasted meteorological data of the first turbine and had to produce nine outputs (consisting of three datasets, each dataset comprising values regarding three numerical weather parameters: temperature, absolute wind direction, and average wind speed). These refined parameters were needed for obtaining the forecast of the produced electricity of the production group. As the results were not satisfactory, the research team designed and implemented an upscaling algorithm that estimated the produced electricity of the 10 MW production group based on the forecasted produced electricity of the smaller 5 MW production group.
In rapport with the devised approach [
25], the method that we have proposed in the current article overcomes the limitation of a higher number of turbines (that posed problems to the previous forecasting approach) and offers an improved forecasting accuracy when compared to the upscaling technique. Our developed method also uses the forecasted weather dataset received from the specialized institute consisting of the temperature, absolute wind direction, and average wind speed, but in contrast to the previous method [
25], it does not allocate the data to a certain turbine in order to train a FITNET ANN, using instead a developed long short-term memory artificial neural network with exogenous variables for the purpose of refining the meteorological forecast at the level of each and every wind turbine, the forecasted numerical weather parameters from the meteorological institute being used as an exogenous variable in addition to the historical meteorological data recorded by the sensors of each of the turbines.
Consequently, our developed method benefits from the advantages of long short-term artificial neural networks’ characteristics, the refining of the meteorological parameters can be achieved for a higher number of turbines located in the same weather prediction area at the level of each wind turbine, having the advantage that the LSTM solution is able to learn and manage long-term dependencies among data. In contrast to the previous method [
25], when the production group comprises a higher number of turbines, instead of using the upscaling technique that estimates only the produced electricity based on the production of only a small number of turbines, our devised method uses a FITNET artificial neural network to forecast both the produced and consumed electricity, using, as inputs, the refined accurate meteorological parameters, forecasted at each wind turbine’s level.
Compared to our developed method, López et al. [
5] devised an artificial neural network that uses LSTM memory blocks as units in the hidden layer, within an Echo State Artificial Neural Network architecture, while our proposed method uses a developed long short-term memory artificial neural network with exogenous variables support in view of improving the forecasting accuracy within the weather prediction area up to the wind turbines’ level and subsequently, a function fitting artificial neural network for accurately predicting both the produced and consumed electricity at the whole production group level of the wind farm. In contrast to our paper, even if López et al. [
5] admit the very good forecasting accuracy of the LSTM ANNs, they state that, in their case, the training process has proven to be computationally expensive, as a consequence of its complex architecture. In the case of our research, the LSTM approach has offered advantages from both the perspective of very good forecasting accuracy and also the low computational costs highlighted by the results synthetized in
Table 2 (the required training time of our developed LSTM ANNs varied from a few seconds up to a maximum of 208 s, which are very good computational time costs that allow us to retrain the LSTM ANNs with exogenous variables support meteorological forecasting solution frequently, as the training of the artificial neural network makes use of the parallel processing Compute Unified Device Architecture). Another important difference between the study of López et al. [
5] and ours consists in the fact that López et al. predict up to 48 steps forward, by modeling meteorological variables and historical wind power, while in our approach, we first forecast the improved meteorological parameters in terms of accuracy up to the turbines’ level and in the subsequent stages of the method, both the produced and consumed electricity are forecasted for up to 168 h ahead for the whole production group, overcoming the limitations imposed by the complex hilly terrain.
In contrast to our method, Xu et al. [
6] developed a hybrid approach consisting of a composite Particle Swarm Optimization and Tabu Search combined with an echo state network technique for ultrashort-term and short-term wind power forecasting systems, while our developed hybrid method uses long short-term memory neural networks to adjust the accuracy of the meteorological parameters at the level of each and every wind turbine, subsequently employing a function fitting neural network to forecast both the produced and consumed electricity of the wind farm’s production groups in order to surpass the challenges posed by the complex hilly terrain. Regarding the time interval over which the forecasting is conducted, Xu et al. [
6] address ultrashort-term and short-term wind power forecasting, while our research targets short-term and medium-term predictions.
In rapport to our approach, in which we have incorporated the advantages of LSTM and FITNET neural networks for the purpose of obtaining an accurate forecast of the produced and consumed electricity of small wind farms located on complex hilly terrains, Amjady et al. [
13] used an enhanced Kriging Interpolation approach, an Empirical Mode Decomposition along with a method for the selection of information-theoretic features and a closed-loop form of an ANN forecasting engine useful in forecasting the wind power for a short-term horizon. While Amjady et al. [
13] considered 49 days for the training set, we have used for the training set 724 days consisting of 17,376 hourly records, in order to develop a long short-term memory artificial neural network with exogenous variables and parallel Compute Unified Device Architecture (CUDA) support in view of improving the forecasting accuracy of the meteorological parameters (the temperature, absolute direction of the wind, and average wind speed) up to each of the wind turbines’ level within the production group. Concerning the development of the feed-forward function fitting neural network solution, we have used 12,164 samples for the training process, 2606 samples for the validation one, and 2606 samples for the testing process in the cases of the Levenberg–Marquardt and Scaled Conjugate Gradient training algorithms, while in the case of the Bayesian Regularization training algorithm the 2606 samples corresponding to the validation process are set aside, as this process does not take place in this case.
Compared to our method, Cheng et al. [
7] tackle a less than one-hour-ahead ultra-short-term wind speed forecasting by means of an ensemble model developed in order to devise probabilistic wind speed forecasting, the model was composed of a wavelet threshold denoising, a RNN, and an adaptive neuro fuzzy inference system. Contrasting with their approach, our developed prediction method targets a short-term (24 h ahead) and medium-term (168 h ahead) forecasting horizon of not only the wind speed but of the produced and consumed electricity at the level of the whole production group in the context of complex hilly terrain. Our developed method first improves the accuracy of the numerical weather parameters, namely temperature, average wind speed, and absolute wind direction, at the level of each wind turbine, employing a developed LSTM meteorological forecasting solution using the historical meteorological datasets recorded by each of the turbines’ sensors and, as exogenous variables, the forecasted meteorological parameters for the weather prediction area provided by a specialized meteorological institute in order to be able to forecast subsequently, using a developed FITNET artificial neural network solution, both the produced and consumed electricity at the level of the whole production group.
In contrast to our proposed wind power forecasting method, Wang et al. [
8] develop their forecasting system based on data preprocessing and Extreme Learning Machine feed-forward neural networks optimized by the cuckoo algorithm. With regard to data preprocessing, our developed method has employed a gap-filling technique taking also into account, when training the neural networks, the missing values that were caused due to the maintenance processes, as depicted in the third step of the devised method’s first stage. While the method proposed by Wang et al. [
8] addresses the case of medium-term prediction of the produced wind energy, our proposed approach targets both short-term (one day ahead) and medium-term predictions (one week ahead) for the produced and also the consumed electricity of the wind farm’s whole production group in the context of having to overcome the issues caused by the complex hilly terrain.
Regarding the forecasting horizon, in contrast to our short-term (24 h ahead) and medium-term forecasting (168 h ahead), Niu et al. [
9] developed an ultra-short-term wind-power forecast based on wavelet decomposition and weighted random forest enhanced by applying the niche immune lion algorithm. In rapport to Niu et al. [
9], in our study, the training datasets are larger in size, therefore allowing us to develop a long short-term memory meteorological forecasting solution for fine-tuning the accuracy of the predicted meteorological parameters up to each of the wind turbines, subsequently using the accurate numerical weather parameters as inputs to a function fitting neural network in view of obtaining accurate short-term and medium-term predictions of both the produced and consumed energy, succeeding in dealing with the challenging conditions of complex hilly terrain.
When compared to our approach, Yao et al. [
11] developed a hybrid model in order to obtain the wind speed forecasting for a short-term horizon, while our developed method targets a short-term and medium-term forecasting horizon of the meteorological parameters (the temperature, absolute direction of the wind, and average wind speed) using a developed long short-term artificial neural network approach with exogenous variables support that makes use of the parallel processing capabilities of the CUDA architecture and of both the produced and consumed electricity at the level of the whole production group of the wind farm. In the case of our developed method, the main challenge was to attain an accurate forecast in the context of complex hilly terrain.
In contrast to our paper, Zhao et al. [
12] developed a forecasting algorithm based on the Beveridge–Nelson, the Least Square Support Vector Machine and the Grasshopper Optimization approaches, while our method was designed and developed bearing in mind the advantages of the LSTM and FITNET approaches. Therefore, in our proposed approach, we have developed a long short-term memory artificial neural network with exogenous variables support enhancing the forecasted accuracy of the numerical weather parameters for each of the production group’s wind turbines, the accurate meteorological forecast being used afterwards in a custom tailored developed function fitting neural network that predicts not only the produced, but also the consumed electricity of the whole wind farm’s production group, surpassing the severe limitations of the complex hilly terrain. While Zhao et al. remark that their proposed optimization algorithm has as a main disadvantage the fact that it comprises a series of complicated computation steps, in our case, we have overcome this situation by making use, in our developed method, of the huge computational advantages offered by the parallel processing Compute Unified Device Architecture, therefore, obtaining an efficient and accurate forecasting method for both the produced and consumed electricity of small wind farms situated on quite complex hilly terrain.
Our developed method targets as main beneficiaries the power plant operators, but it can also be successfully applied in order to assess the energy potential of a quite complex hilly terrain. The developed method was compiled in order to assure its integration in a wide range of custom-tailored forecasting applications for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain.
5. Conclusions
Through a thorough analysis of the scientific literature, one can see that many authors have addressed issues regarding the accurate forecasting of the produced and consumed electricity from wind farms, developing a wide variety of forecasting methods that analyze numerous case studies. Trying to devise a comparison among the relevant issues of the different approaches represents a very difficult (or even impossible) task, due to the fact that the purposes of all these studies differ, each of them using different datasets and being validated through different case studies.
Except some of the state-of-art methods and algorithms, even if the datasets from a certain study became available, it would be very difficult for another researcher to adapt his own method so as to be applied to this dataset, as every researcher adjusts his approach according to the specific problem and the available datasets. However, if certain problems are characterized by common features, it is possible to adapt an approach from one case to another, through a generalization process.
The analyzed case is a nonlimitative example of applying the devised method taking into consideration that the examined case is a typical operating situation of a small wind farm located on quite complex hilly terrain. Considering this perspective, our proposed approach based on the presented methodology makes it possible to be applied, and therefore, generalized to other case studies having similarities to our proposed one. Furthermore, our developed forecasting method for the produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain can be called through different Application Programming Interfaces (APIs), therefore assuring also its generalization character from the implementation point of view. This aspect highlights the generalization capability and effectiveness of our forecasting method.
Our research targeted designing, developing, and implementing a forecasting method for the hourly produced and consumed electricity in the case of small wind farms situated on quite complex hilly terrain. The devised solution provides an excellent forecasting accuracy for the first 24 h (the purpose of the study), the developed method being also able to register good hourly results in terms of accuracy for up to one whole week. The very good forecasting accuracy is highlighted by the registered performance metrics. In the case of the LSTM ANN developed based on the ADAM training algorithm, when choosing a number of 100 hidden units, we have registered a value of 0.1609 of the Root Mean Square Error when forecasting data for the next 24 h and a value of 1.8662 when forecasting data for the next week. In the case of the FITNET forecasting ANN developed based on the BR training algorithm, using 35 neurons in the hidden layer, we have registered the values of 0.0011195 for the Mean Square Error and 0.99628 for the correlation coefficient.
Even if the registered results highlight a very good forecasting accuracy, we are aware that, as any other forecasting solution, our method cannot offer a global solution, but, due to our forecasting methodology, we are certain that we have chosen the best combination of the two components of our approach (LSTM and FITNET), taking into account the multitude of tests regarding the varying parameters involved in this study. Moreover, the method’s validation and the comparison between our results and other ones from the literature allow us to state that our developed approach represents an accurate, useful, and viable alternative to the existing ones from the scientific literature.
In the future work, we intend to adapt this method and see how well it performs in improving previously developed methods that targeted the devising of “hourly forecasting solutions regarding electricity consumption in the case of commercial center type consumers” [
60] and the forecasting of “the residential electricity consumption based on sensors recorded data” [
61] from the promoting scheme point of view [
63]. Another research direction that we want to explore further consists in the modeling of the economic decisions in case of information asymmetry [
64] that operators must take into account when operating on the centralized market with double continuous negotiation for electricity bilateral contracts. An aspect of particular focus for our future works consists in applying the Multilayered Structural Data Sectors Switching Algorithm (MSDSSA) [
65] in view of training the networks with encrypted data from multiple wind farms, each wind farm operator obtaining in the end his own decrypted needed predicted data, without having access to the other competitors’ sensible data, but benefitting from each other’s data.




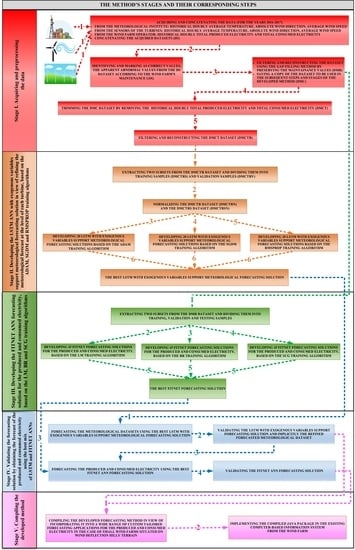

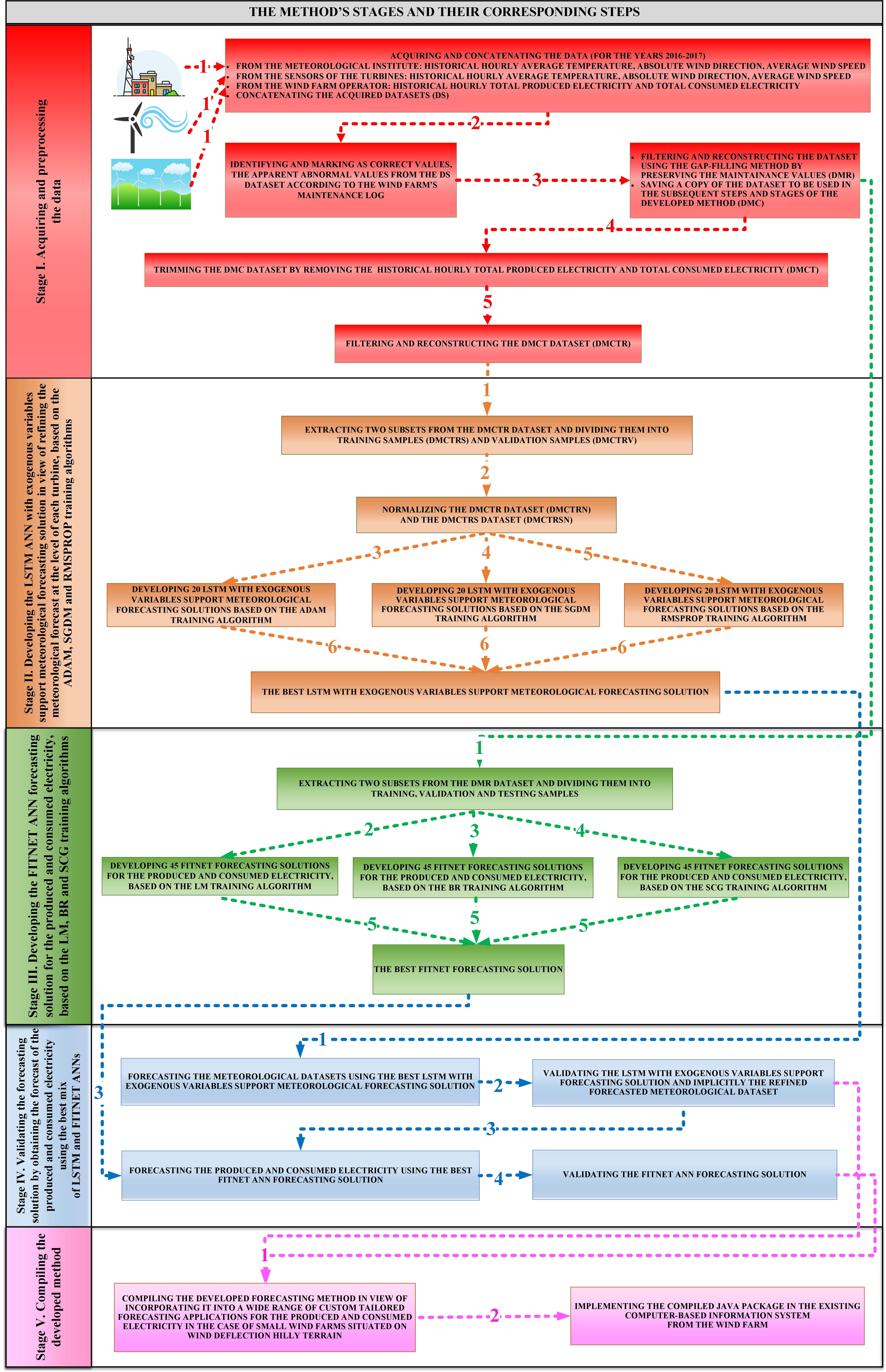{kind=link}
{kind=link}
{kind=link}
{kind=link}
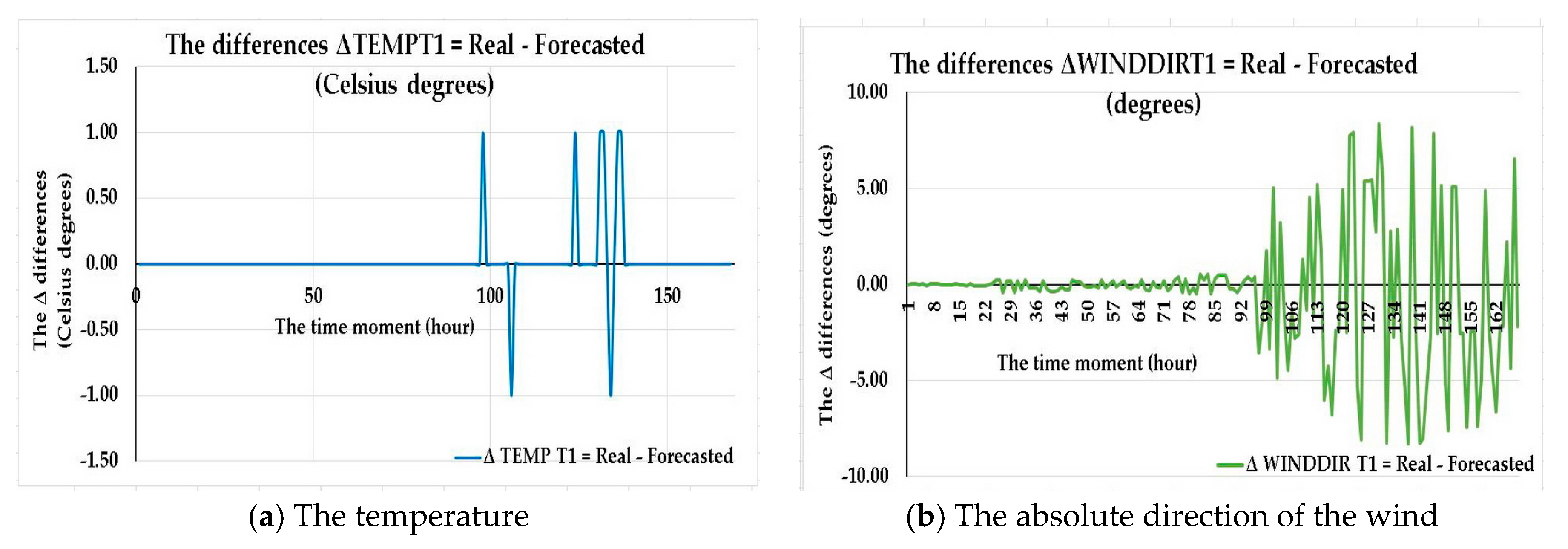{kind=link}
{kind=link}
{kind=link}





