Direct Probabilistic Load Flow in Radial Distribution Systems Including Wind Farms: An Approach Based on Data Clustering


 ,
, 
Abstract
1. Introduction
2. Wind Farm Modeling
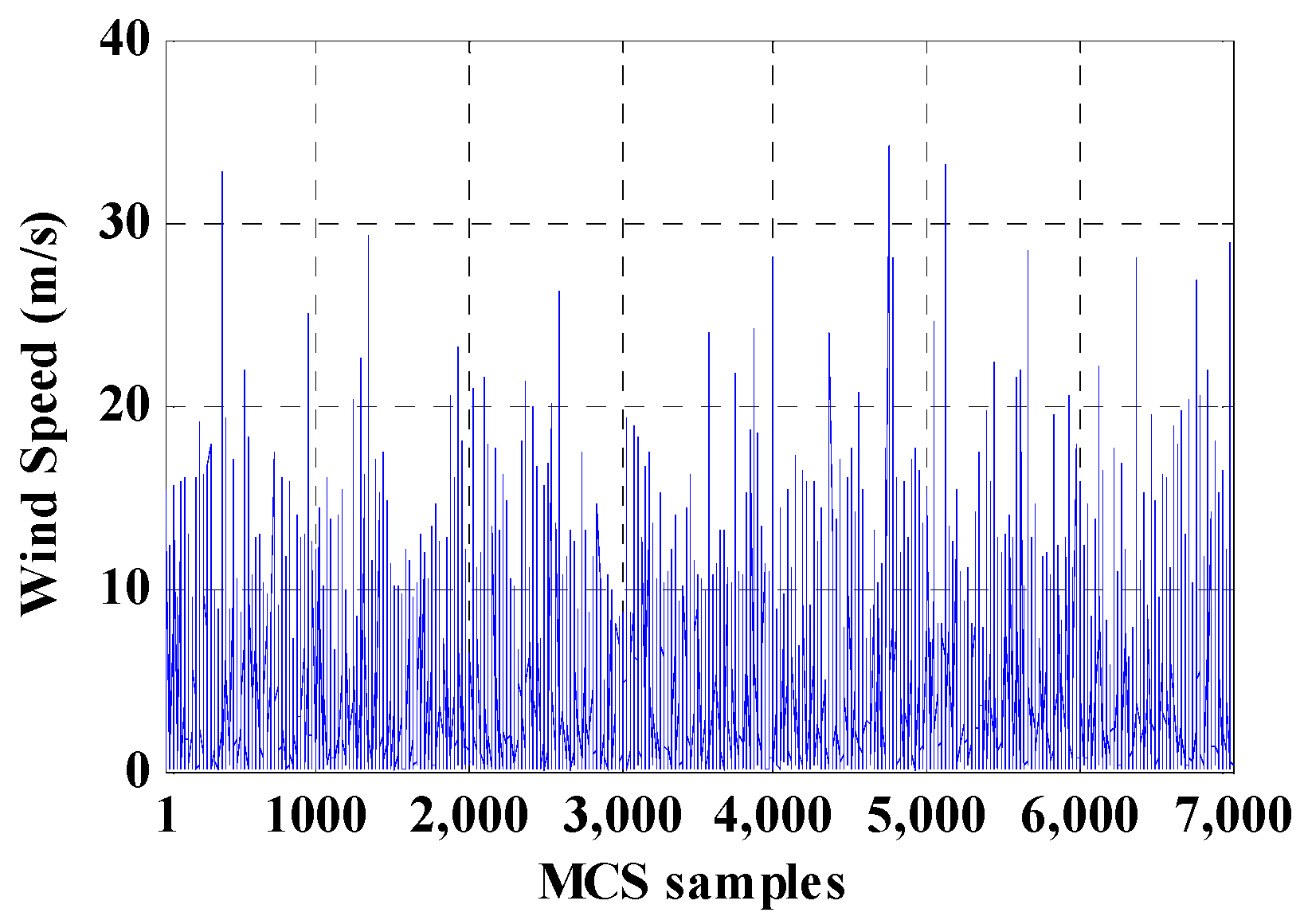
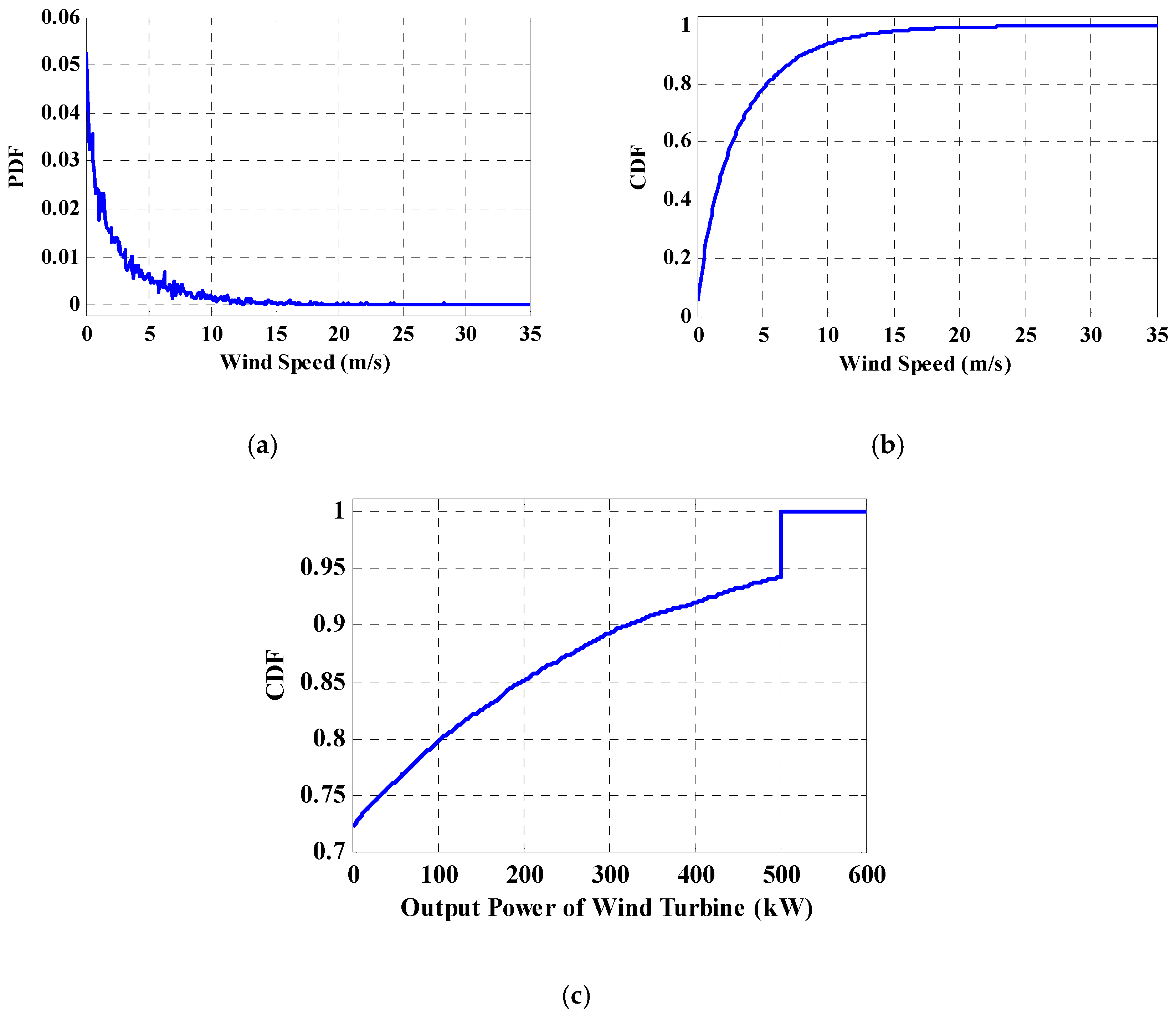
2.1. Wind Speed Model
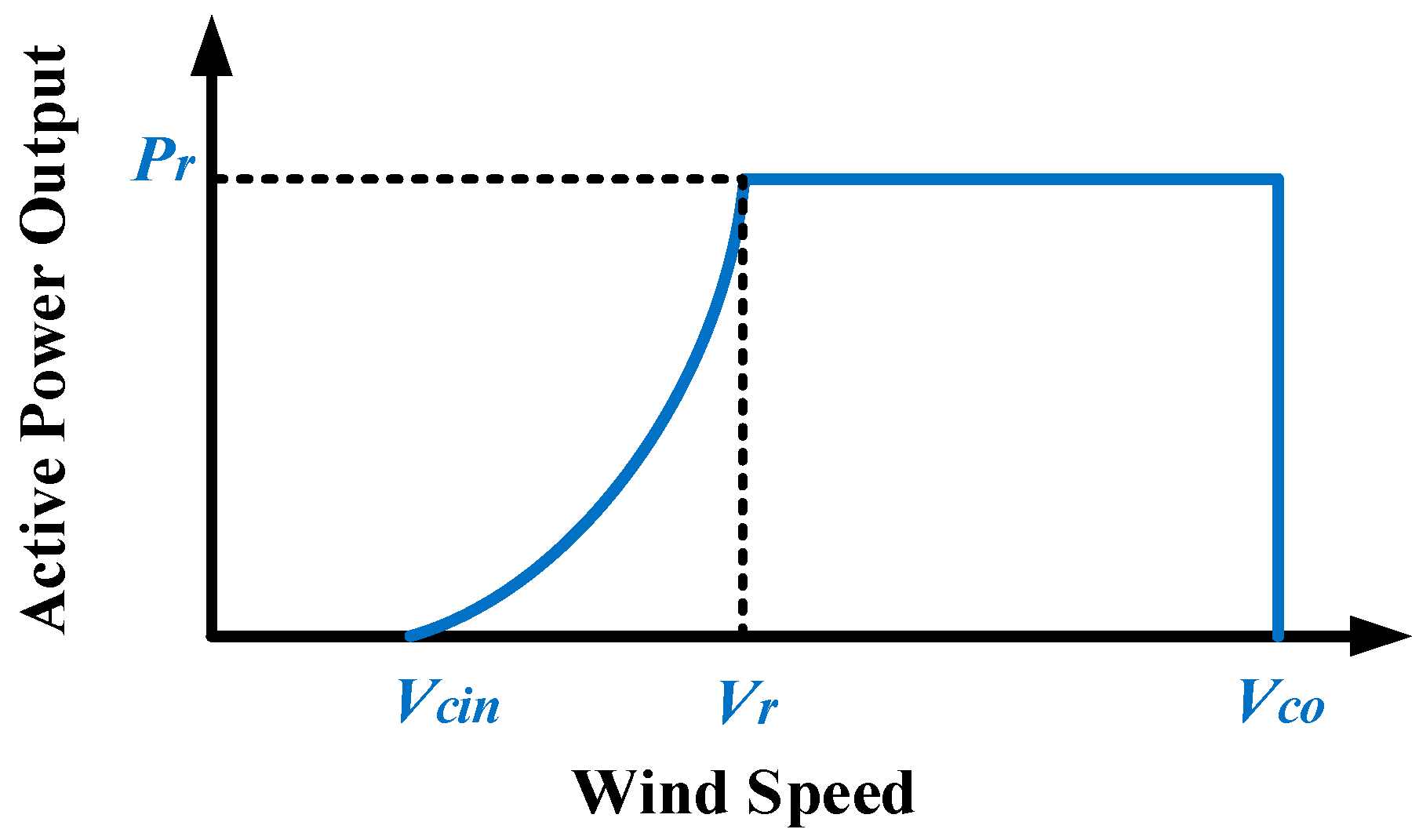
2.2. Wind Turbine Model
2.3. Wind Farm Output Power
3. Direct Probabilistic Load Flow Formulation
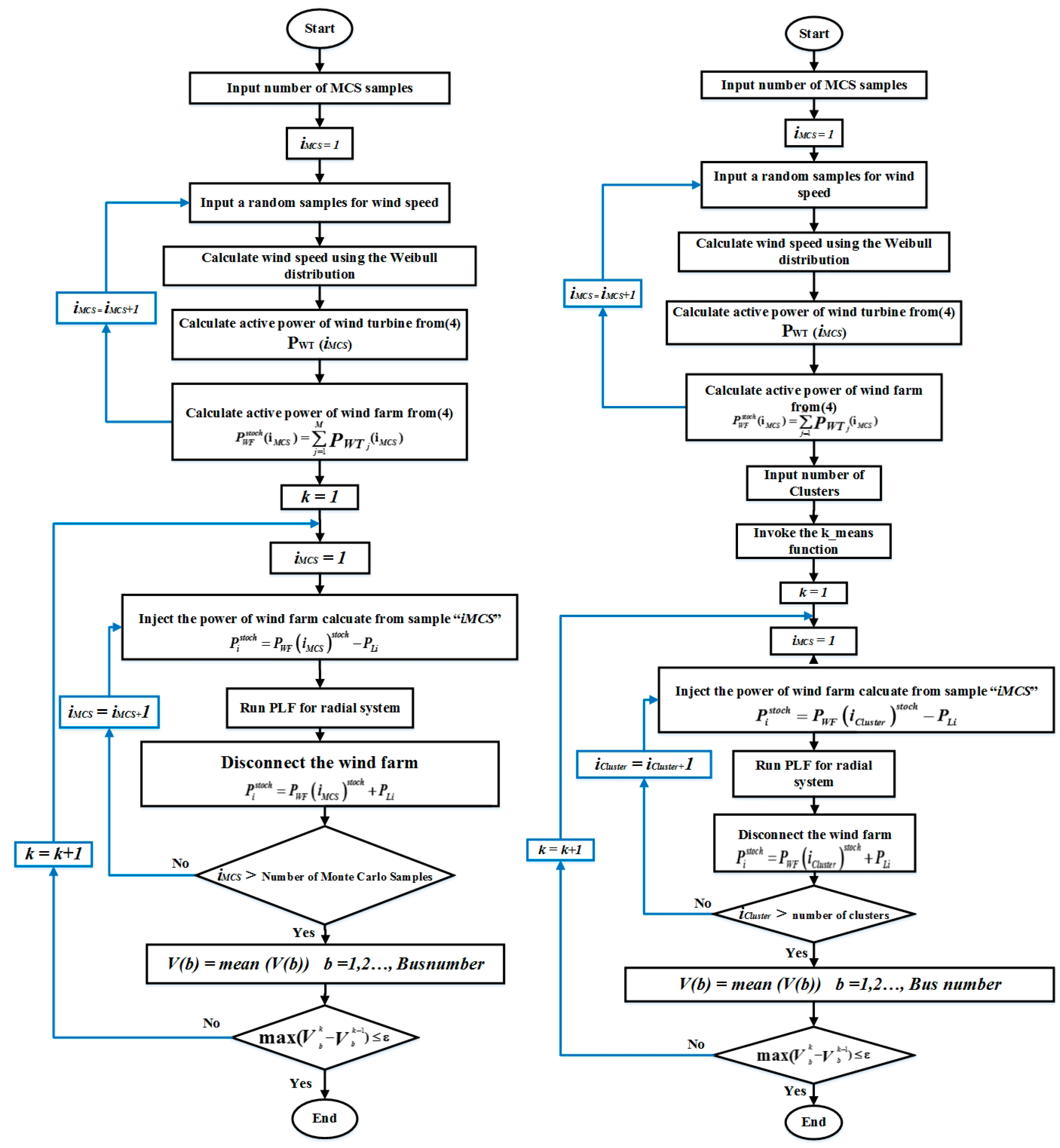
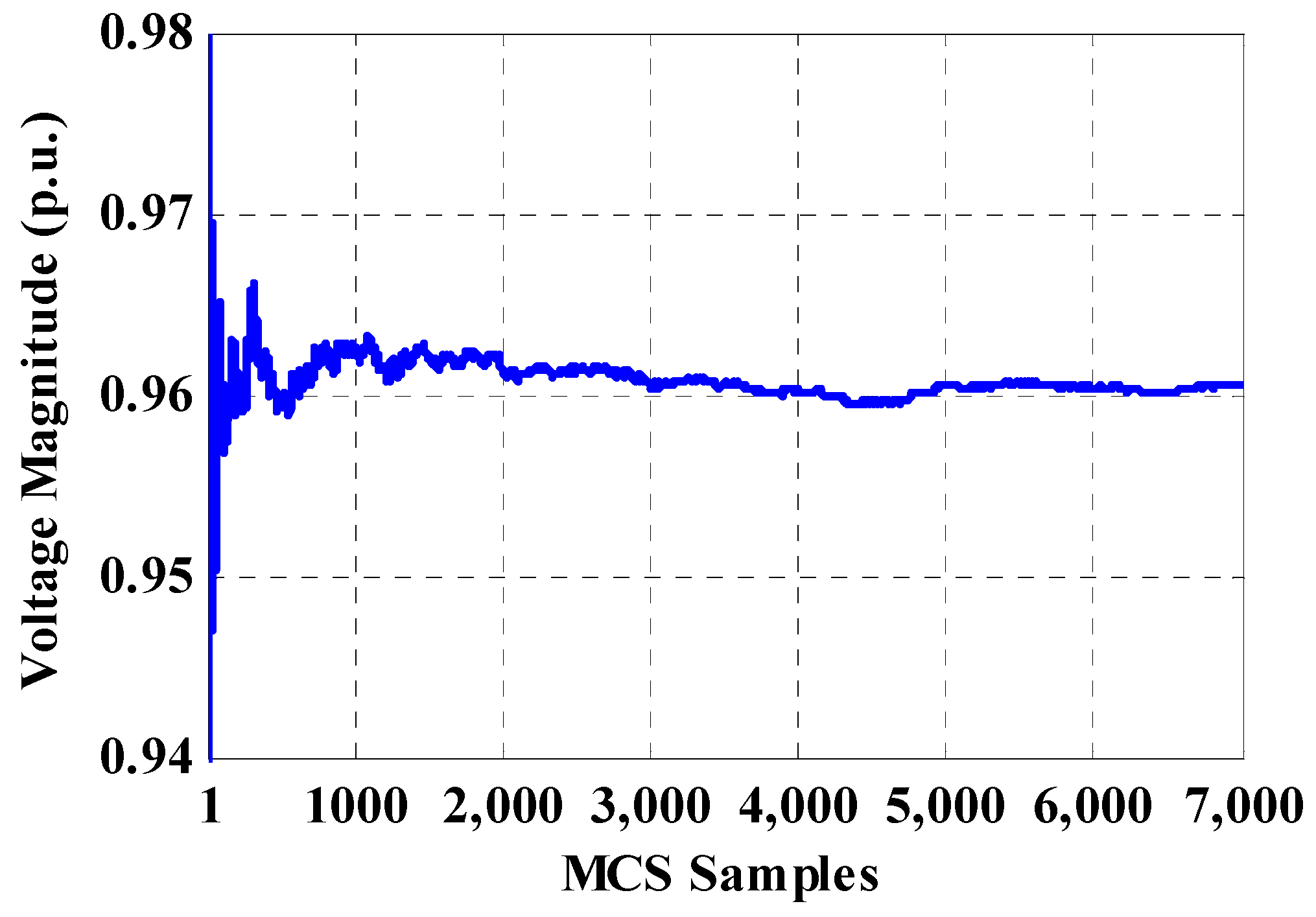
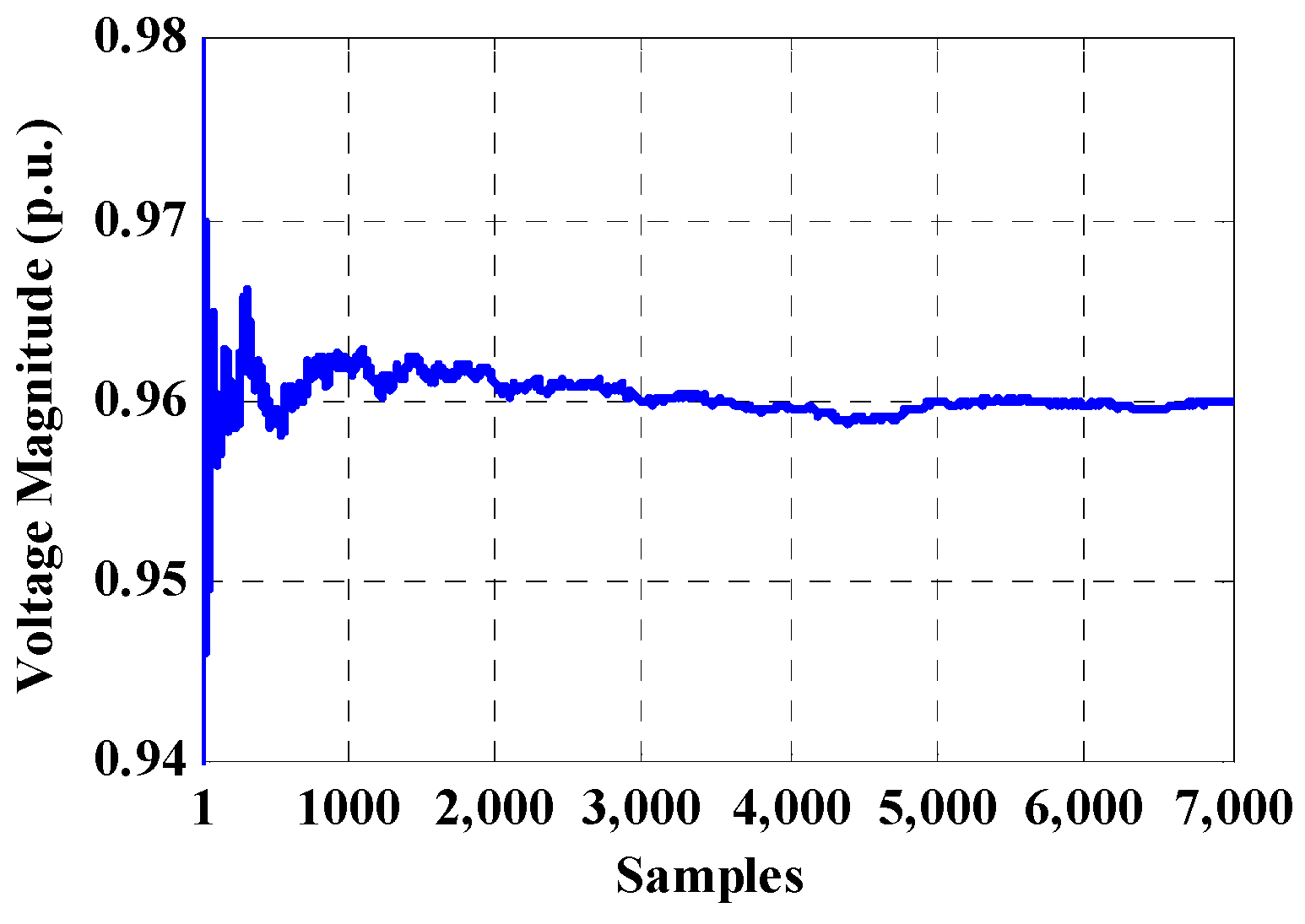
4. Probabilistic Load Flow Evaluation Based on Monte Carlo Simulation
5. Data Clustering Approach
5.1. K-Means Algorithm
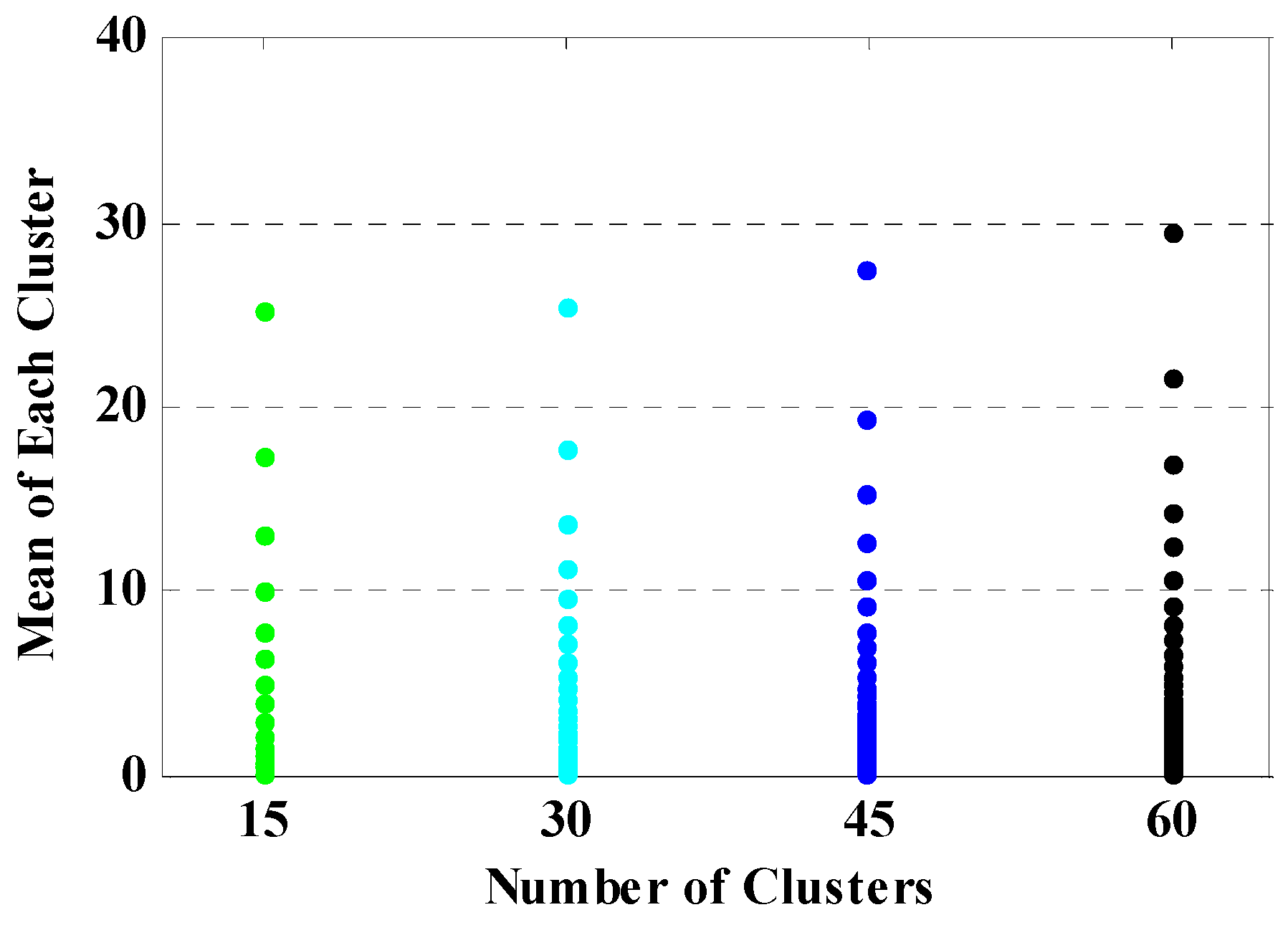
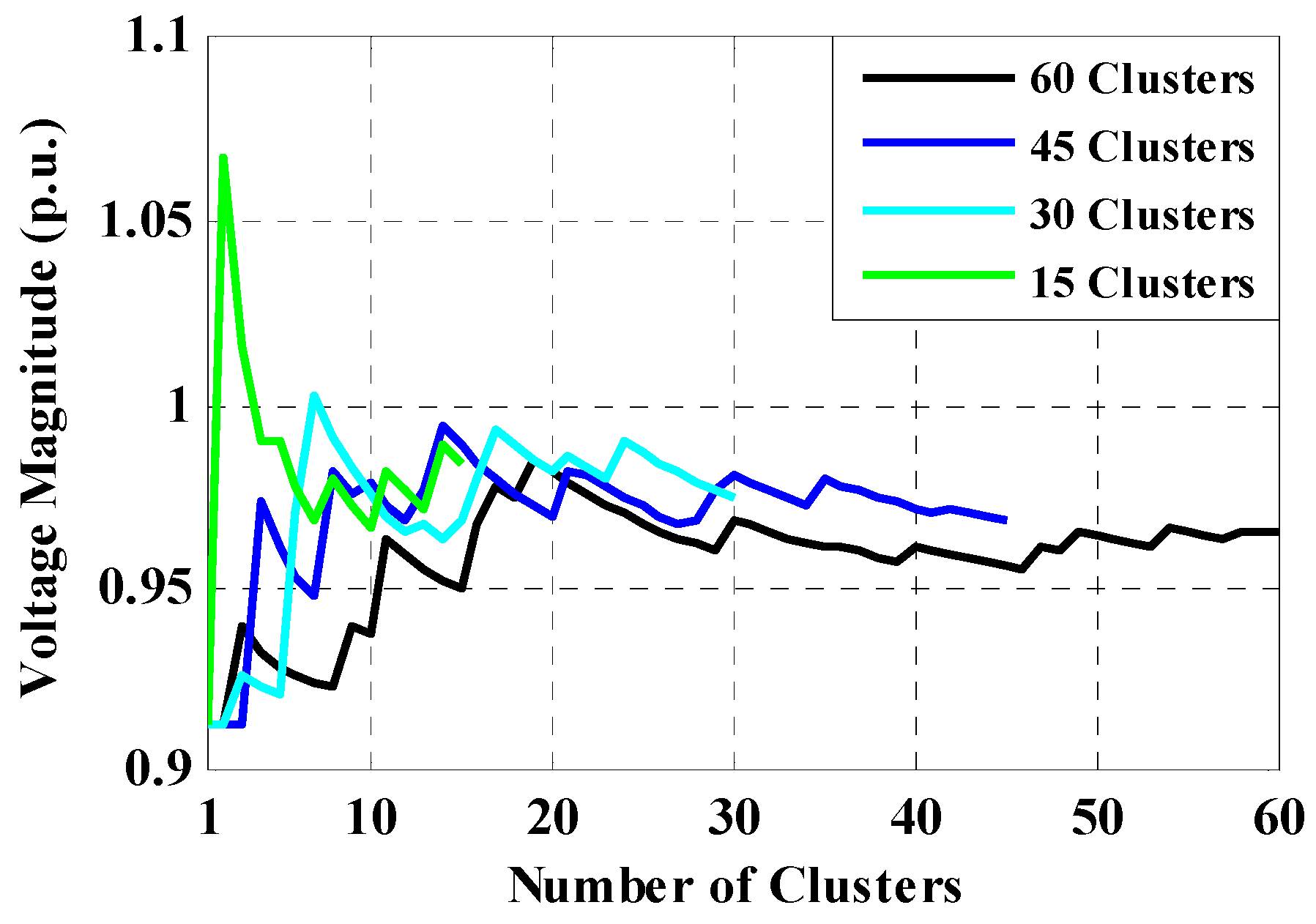
5.2. Clustering Application in MCS for Probabilistic Load Flow
6. Numerical Studies
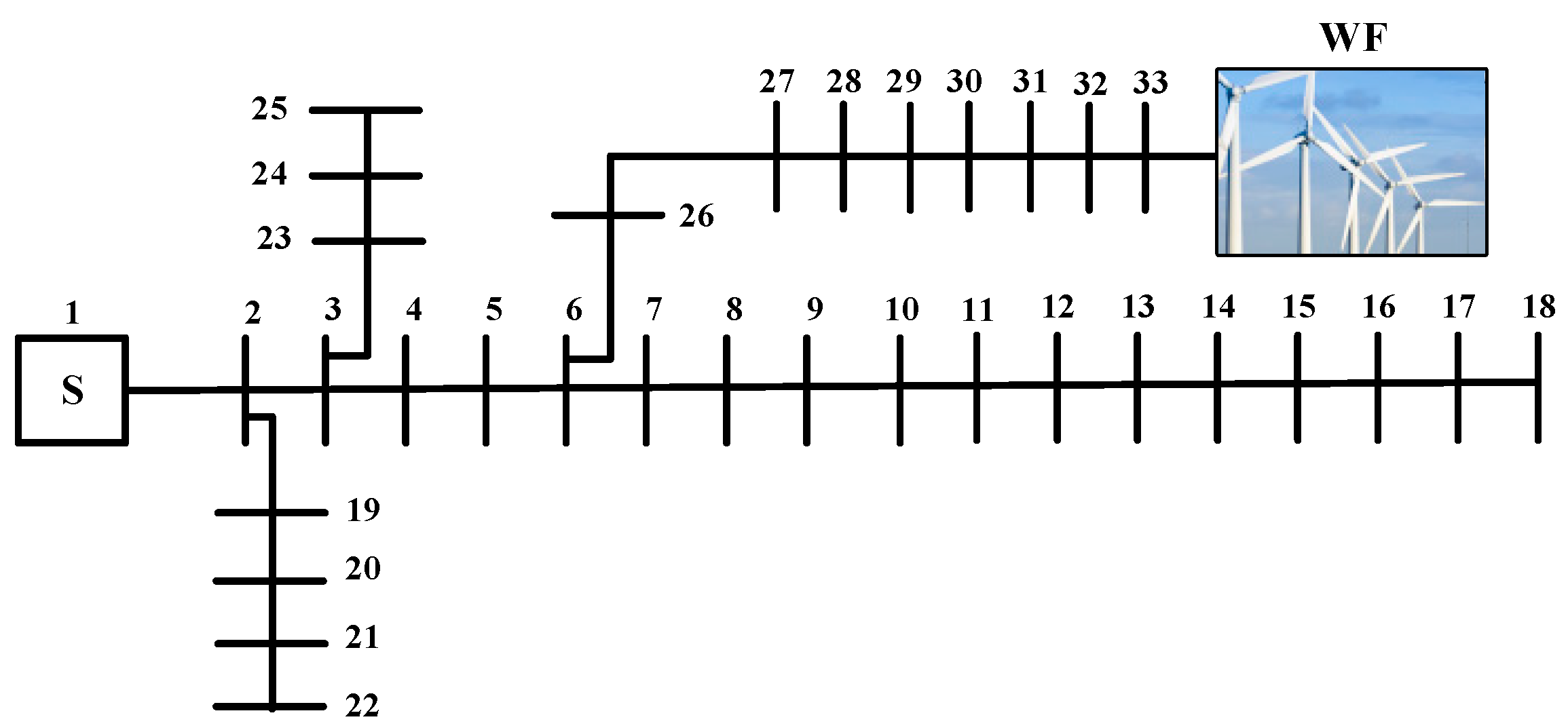
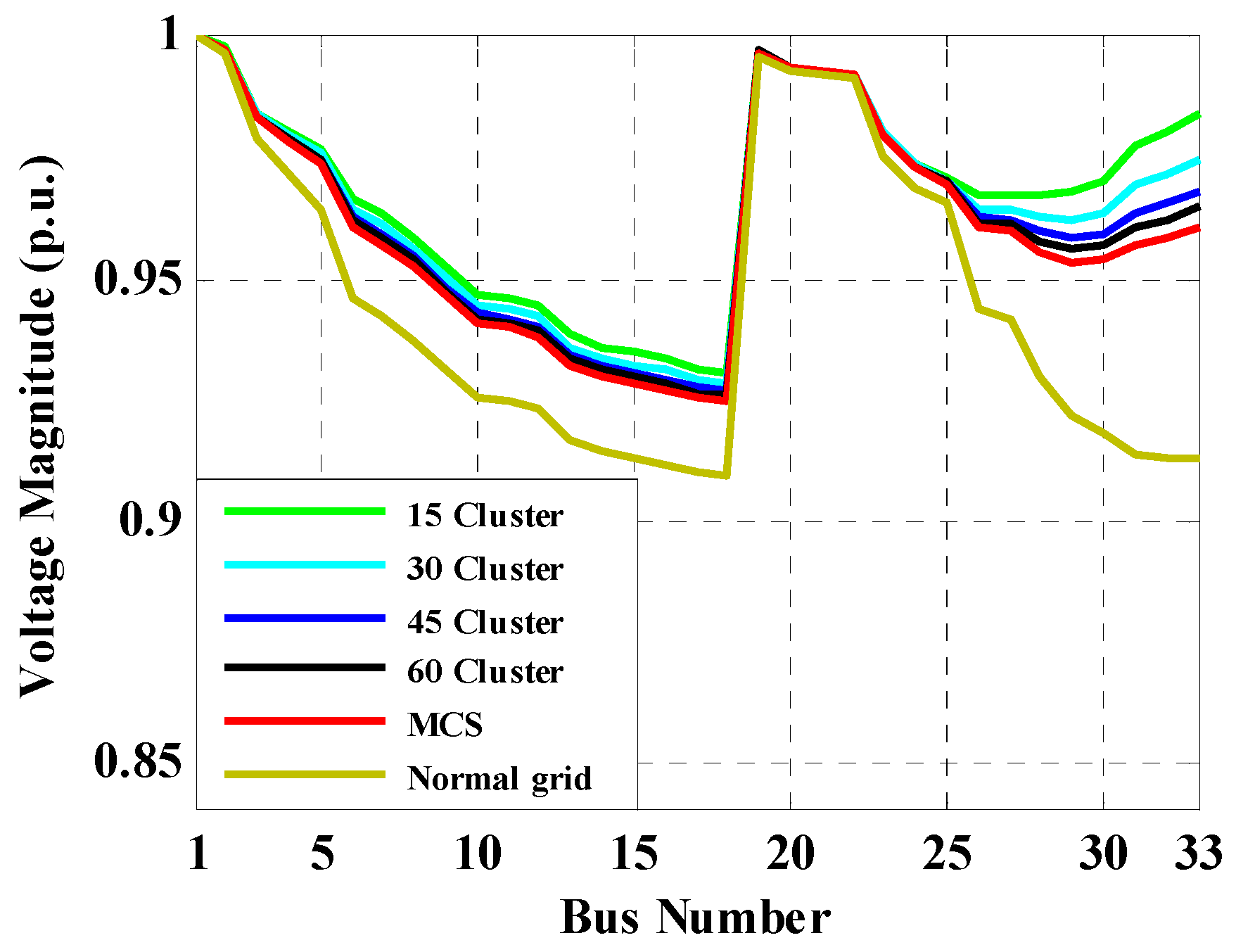
6.1. IEEE 33-Bus Case Study
6.1.1. System Description
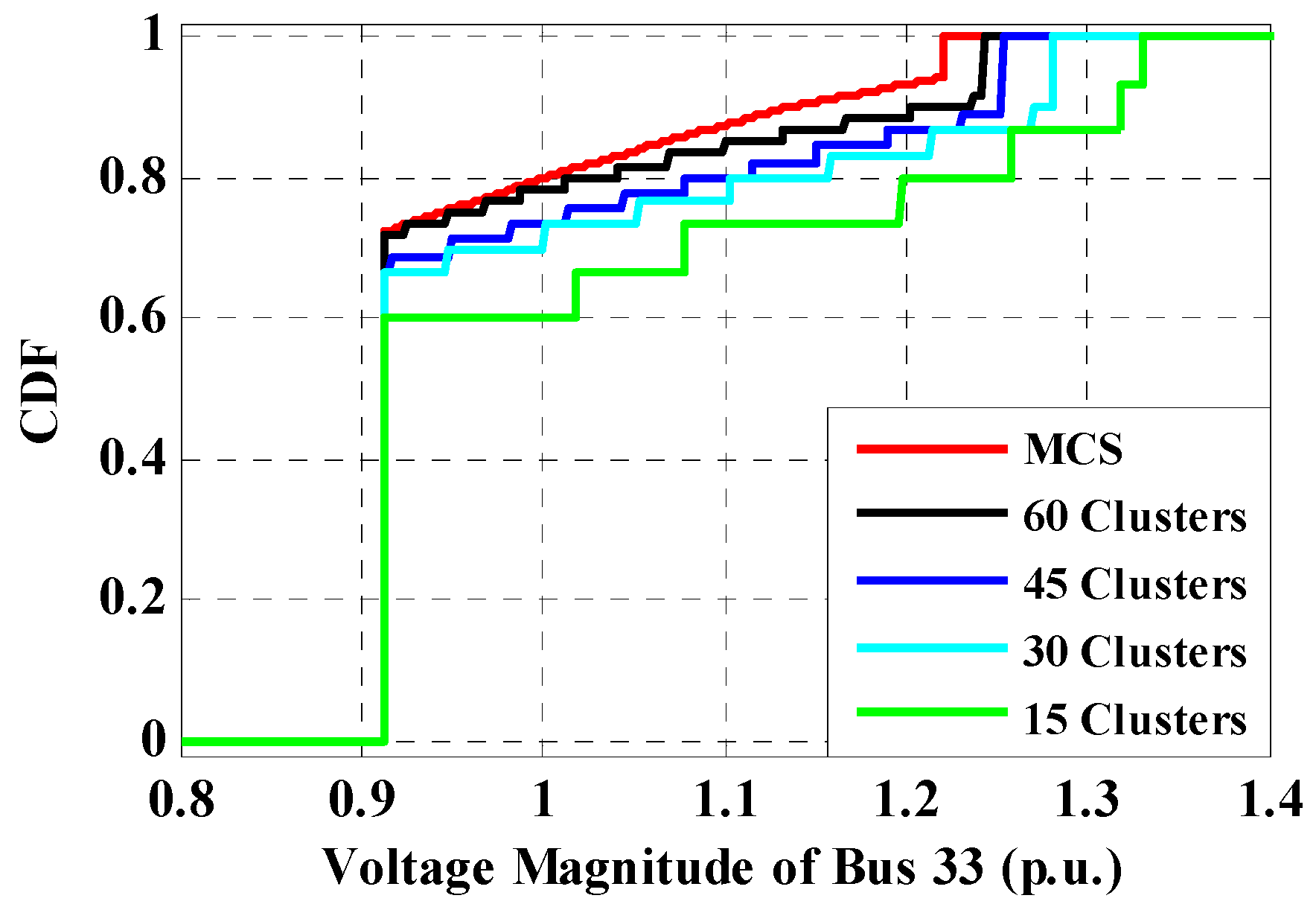
6.1.2. Proposed Direct Probabilistic Load Flow Evaluation
6.1.3. Indirect Probabilistic Forward/Backward Sweep Method Evaluation
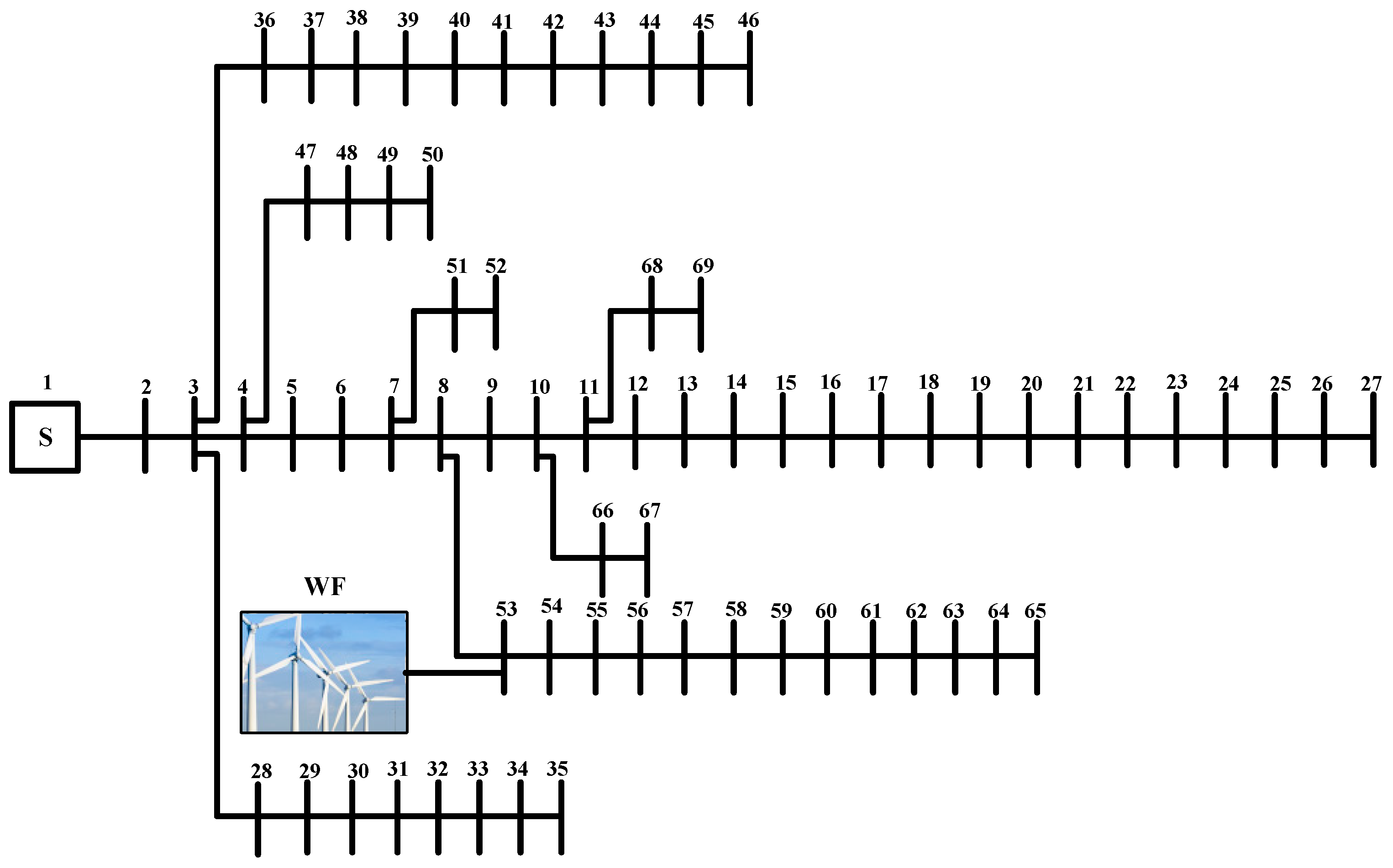
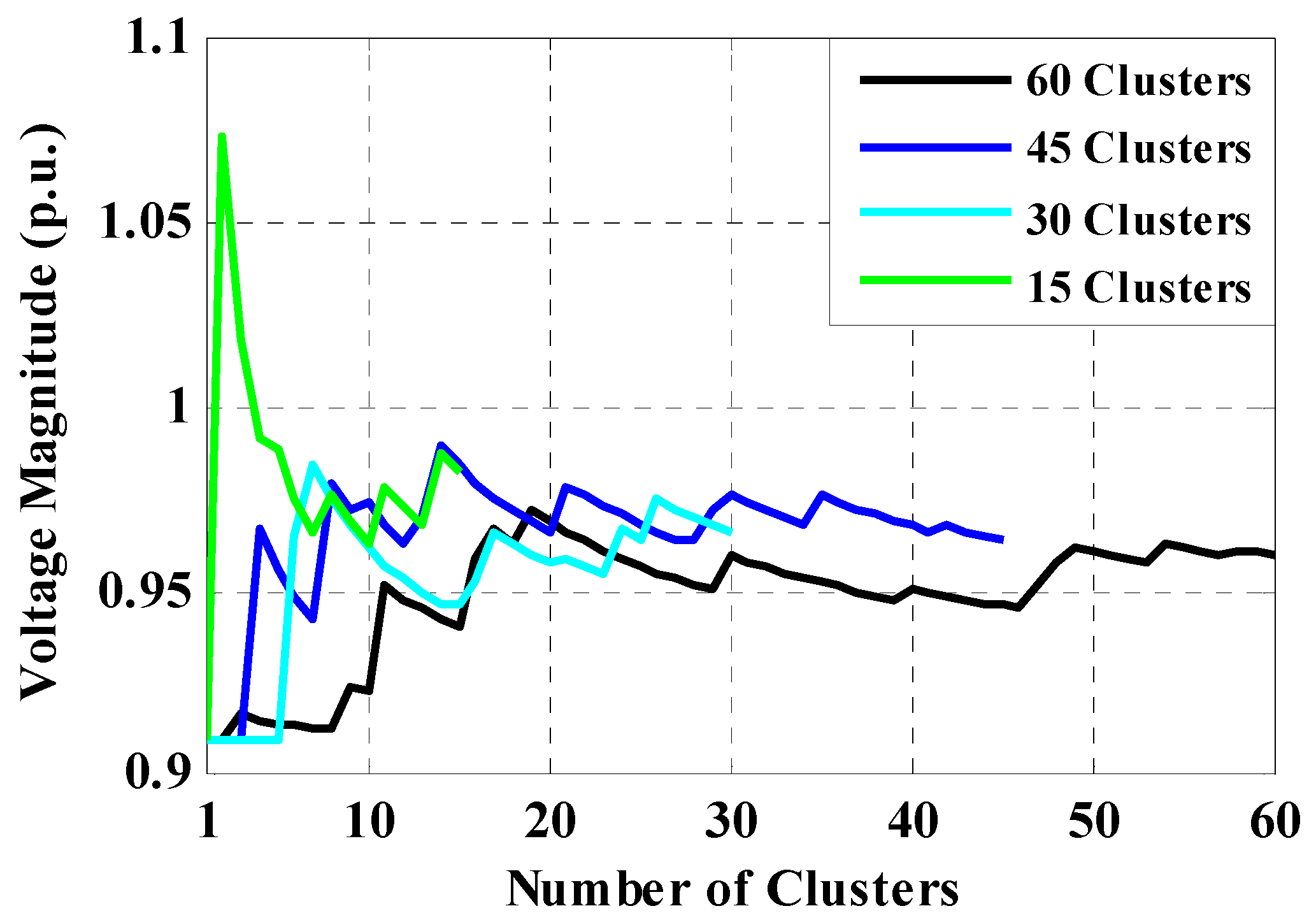
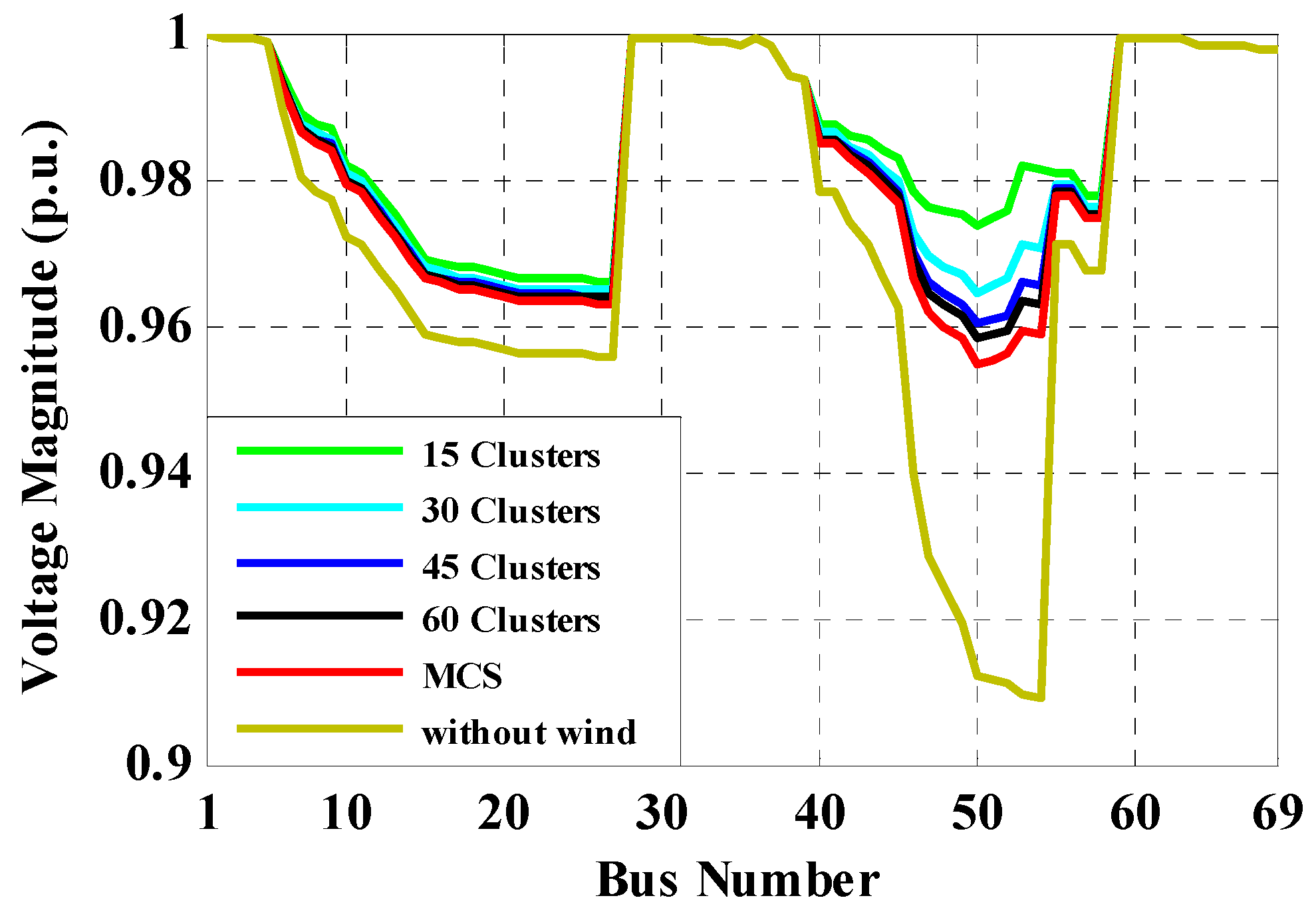
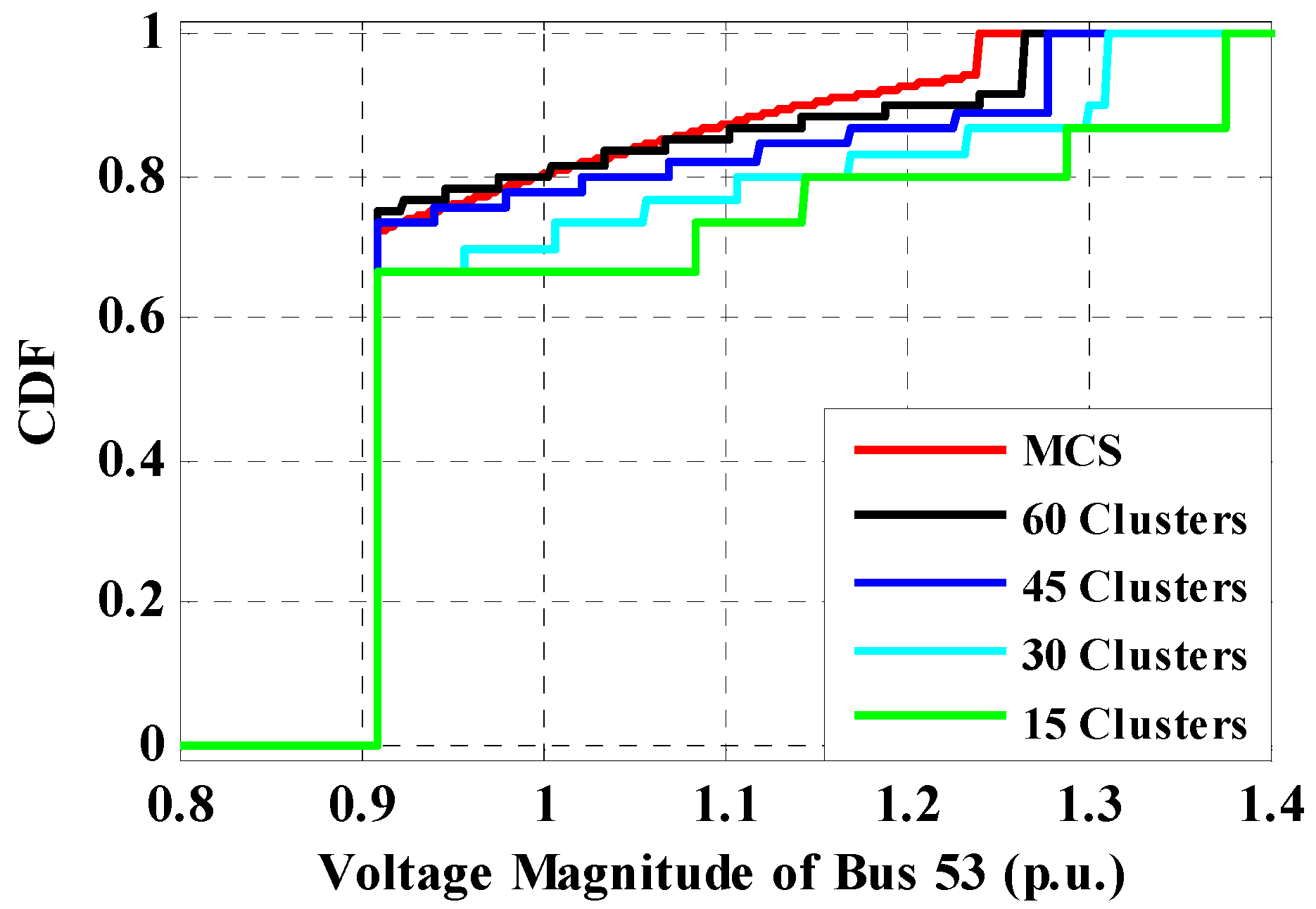
6.2. IEEE 69-Bus Case Study
7. Discussion
8. Conclusions
Author Contributions
Conflicts of Interest
References
- Gatta, F.M.; Iliceto, F.; Lauria, S.; Masato, P. Modeling and Computer Simulation of in Dispersed Generation in Distribution Networks: Measures to prevent disconnection during system disturbances. In Proceedings of the 2003 IEEE Power Tech Conference, Bologna, Italy, 23–26 June 2003. [Google Scholar]
- Teng, J.H. A Direct Approach for Distribution System Load Flow Solutions. IEEE Trans. Power Deliv. 2003, 18, 882–887. [Google Scholar] [CrossRef]
- Tarafdar-Hagh, M.; Ahamadzadeh, T.; Muttaqi, K.M.; Sutanto, D. Load flow analysis of radial and weakly meshed distribution systems including distributed generations. In Proceedings of the 2014 Australasian Universities Power Engineering Conference (AUPEC), Perth, WA, Australia, 28 September–1 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–6. [Google Scholar]
- Piccolo, A.; Siano, P. Evaluating the impact of network investment deferral on distributed generation expansion. IEEE Trans. Power Syst. 2009, 24, 1559–1567. [Google Scholar] [CrossRef]
- Borkowska, B. Probabilistic Load Flow. IEEE Trans. Power Appar. Syst. 1974, PAS-93, 752–759. [Google Scholar]
- Tao, C.; Franchetti, F. A Quasi-Monte Carlo approach for radial distribution system probabilistic load flow. In Proceedings of the IEEE PES Innovative Smart Grid Technologies (ISGT), Washington, DC, USA, 24–27 February 2013; pp. 1–6. [Google Scholar]
- Yu, H.; Chung, C.Y.; Wong, K.P.; Lee, H.W.; Zhang, J.H. Probabilistic load flow evaluation with hybrid latin hypercube sampling and cholesky decomposition. IEEE Trans. Power Syst. 2009, 24, 661–667. [Google Scholar] [CrossRef]
- Singhee, A.; Rutenbar, R.A. Why quasi-Monte Carlo is better than Monte Carlo or Latin hypercube sampling for statistical circuit analysis. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2010, 29, 1763–1776. [Google Scholar] [CrossRef]
- Penuela, C.A.; Granda, M.; Mantovani, J.R.S. Probabilistic Analysis of the Distributed Power Generation in Weakly Meshed Distribution Systems. In Proceedings of the IEEE/IPES Transmission and Distribution Conference and Exposition: Latin America, Sao Paulo, Brazil, 8–10 November 2010; pp. 171–177. [Google Scholar]
- Dimitrovski, A.; Melhorn, A.C. Three-phase probabilistic load flow in radial and meshed distribution networks. IET Gener. Transm. Distrib. 2015, 9, 2743–2750. [Google Scholar]
- Liu, S.; Zhou, X.; Fan, M.; Zhang, Z. Probabilistic Power Flow Calculation Using Sigma-Point Transform Algorithm. In Proceedings of the International Conference on Power System Technology, Chongqing, China, 22–26 October 2006. [Google Scholar]
- Wu, H.; Zhou, Y.; Dong, S.; Song, Y. Probabilistic load flow based on generalized polynomial chaos. IEEE Trans. Power Syst. 2017, 32, 820–821. [Google Scholar] [CrossRef]
- Xiu, D.; Karniadakis, G.E. The Wiener-Askey polynomial chaos for stochastic differential equations. SIAM J. Sci. Comput. 2002, 24, 614–644. [Google Scholar] [CrossRef]
- Mohammadi, M.; Basirat, H.; Kargarian, A. Nonparametric Probabilistic Load Flow with Saddle Point Approximation. IEEE Trans. Smart Grid 2017, PP. [Google Scholar] [CrossRef]
- Morales, J.M.; Pérez-Ruiz, J. Point estimate schemes to solve the probabilistic power flow. IEEE Trans. Power Syst. 2007, 22, 1594–1601. [Google Scholar] [CrossRef]
- Ruiz-Rodríguez, F.J.; Hernández, J.C.; Jurado, F. Probabilistic Load-Flow Analysis of Biomass-Fuelled Gas Engines with Electrical Vehicles in Distribution Systems. Energies 2017, 10, 1536. [Google Scholar] [CrossRef]
- Xu, X.; Yan, Z. Probabilistic load flow evaluation with hybrid Latin Hypercube Sampling and multiple linear regression. In Proceedings of the Power & Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; pp. 1–12. [Google Scholar]
- Cai, D.; Shi, D.; Chen, J. Probabilistic load flow with correlated input random variables using uniform design sampling. Int. J. Electr. Power Energy Syst. 2014, 63, 105–112. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, S.; Cui, H.; Yu, L. Probabilistic load flow considering correlations of input variables following arbitrary distributions. Electr. Power Syst. Res. 2016, 140, 354–362. [Google Scholar] [CrossRef]
- Mohammadi, M.; Shayegani, A.; Adaminejad, H. A new approach of point estimate method for probabilistic load flow. Int. J. Electr. Power Energy Syst. 2013, 51, 54–60. [Google Scholar] [CrossRef]
- Usaola, J. Probabilistic load flow in systems with wind generation. IET Gener. Transm. Distrib. 2009, 3, 1031–1041. [Google Scholar] [CrossRef]
- Cao, J.; Yan, Z. Probabilistic optimal power flow considering dependences of wind speed among wind farms by pair-copula method. Int. J. Electr. Power Energy Syst. 2017, 84, 296–307. [Google Scholar] [CrossRef]
- Ramezani, M.; Falaghi, H.; Singh, C. A Deterministic Approach for Probabilistic TTC Evaluation of Power Systems Including Wind Farm Based on Data Clustering. IEEE Trans. Sustain. Energy 2013, 4, 643–651. [Google Scholar] [CrossRef]
- Vita, V. Development of a decision-making algorithm for the optimum size and placement of distributed generation units in distribution networks. Energies 2017, 10, 1433. [Google Scholar] [CrossRef]
- Ameri, A.; Ounissa, A.; Nichita, C.; Djamal, A. Power Loss Analysis for Wind Power Grid Integration Based on Weibull Distribution. Energies 2017, 10, 463. [Google Scholar] [CrossRef]
- Shirmohammadi, D.; Hong, H.W.; Semlyen, A.; Luo, G.X. A compensation-based power flow method for weakly meshed distribution and transmission networks. IEEE Trans. Power Syst. 1988, 3, 753–762. [Google Scholar] [CrossRef]
- Bie, Z.; Li, G.; Liu, H.; Wang, X.; Wang, X. Studies on voltage fluctuation in the integration of wind power plants using probabilistic load flow. In Proceedings of the 2008 IEEE Power and Energy Society General Meeting Conversion and Delivery of Electrical Energy in the 21st Century, Pittsburgh, PA, USA, 20–24 July 2008; pp. 1–7. [Google Scholar]
- Feijóo, A.; Villanueva, D. Four-Parameter Models for Wind Farm Power Curves and Power Probability Density Functions. IEEE Trans. Sustain. Energy 2017, 8, 1783–1784. [Google Scholar] [CrossRef]
- Aien, M.; Fotuhi-Firuzabad, M.; Aminifar, F. Probabilistic load flow in correlated uncertain environment using unscented transformation. IEEE Trans. Power Syst. 2012, 27, 2233–2241. [Google Scholar] [CrossRef]
- Xu, R. Survey of clustering algorithms for MANET. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Statistical Laboratory of the University of California, Berkeley, CA, USA, 21 June–18 July 1965, 27 December 1965–7 January 1966; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Ruiz-Rodriguez, F.J.; Hernandez, C.; Jurado, F. Probabilistic load flow for radial distribution networks with photovoltaic generators. IET Renew. Power Gener. 2012, 6, 110–121. [Google Scholar] [CrossRef]
- Chakravorty, M.; Das, D. Voltage stability analysis of radial distribution networks. Elect. Power Energy Syst. 2001, 23, 129–135. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Power Factor | Vcin (m/s) | Vr (m/s) | Vco (m/s) | Pr (kW) |
|---|---|---|---|---|
| 0.92 | 4 | 10 | 22 | 500 |
| Method | Cluster | Bus-2 | Bus-10 | Bus-18 | Bus-19 | Bus-25 | Bus-33 | |
|---|---|---|---|---|---|---|---|---|
| Case 1: Direct PLF | Case 1.1 (Clustered Data) | 15 | 0.9978 | 0.9467 | 0.9308 | 0.9973 | 0.9709 | 0.9843 |
| 30 | 0.9977 | 0.9444 | 0.9285 | 0.9972 | 0.9705 | 0.9746 | ||
| 45 | 0.9976 | 0.9428 | 0.9268 | 0.9971 | 0.9701 | 0.9683 | ||
| 60 | 0.9976 | 0.9419 | 0.9259 | 0.9971 | 0.9699 | 0.9649 | ||
| Case 1.2 (Unsorted Data) | - | 0.9975 | 0.9407 | 0.9247 | 0.9970 | 0.9697 | 0.9607 | |
| Case 2: Indirect PFBS | Case 2.1 (Clustered Data) | 15 | 0.9978 | 0.9467 | 0.9307 | 0.9973 | 0.9709 | 0.9843 |
| 30 | 0.9977 | 0.9444 | 0.9279 | 0.9972 | 0.9705 | 0.9845 | ||
| 45 | 0.9976 | 0.9427 | 0.9266 | 0.9972 | 0.9701 | 0.9683 | ||
| 60 | 0.9976 | 0.9418 | 0.9259 | 0.9971 | 0.9700 | 0.9649 | ||
| Case 2.2 (Unsorted Data) | - | 0.9975 | 0.9407 | 0.9247 | 0.9970 | 0.9696 | 0.9607 | |
| Approach | Time (s) (Proposed Direct PLF Approach) | Time (s) (Backward-Forward Approach) | |
|---|---|---|---|
| Data Clustering-Based MCS | Clusters = 15 | 0.0091 | 0.0182 |
| Clusters = 30 | 0.0186 | 0.0370 | |
| Clusters = 45 | 0.0278 | 0.0552 | |
| Clusters = 60 | 0.0370 | 0.0735 | |
| Unsorted Data-Based MCS | 2.9129 | 5.7728 | |
| Number of Bus | Data Clustering-Based MCS | Unsorted Data-Based MCS | |||
|---|---|---|---|---|---|
| 15 Clusters | 30 Clusters | 45 Clusters | 60 Clusters | ||
| 1 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 2 | 0.9978 | 0.9977 | 0.9976 | 0.9976 | 0.9975 |
| 3 | 0.9845 | 0.9841 | 0.9837 | 0.9835 | 0.9833 |
| 4 | 0.9807 | 0.9798 | 0.9792 | 0.9788 | 0.9783 |
| 5 | 0.9772 | 0.9759 | 0.9749 | 0.9744 | 0.9736 |
| 6 | 0.9668 | 0.9645 | 0.9629 | 0.9620 | 0.9609 |
| 7 | 0.9633 | 0.9611 | 0.9595 | 0.9586 | 0.9574 |
| 8 | 0.9586 | 0.9563 | 0.9547 | 0.9538 | 0.9526 |
| 9 | 0.9524 | 0.9502 | 0.9485 | 0.9476 | 0.9464 |
| 10 | 0.9467 | 0.9444 | 0.9428 | 0.9419 | 0.9407 |
| 11 | 0.9459 | 0.9436 | 0.9419 | 0.9410 | 0.9398 |
| 12 | 0.9444 | 0.9421 | 0.9404 | 0.9395 | 0.9383 |
| 13 | 0.9384 | 0.9361 | 0.9344 | 0.9335 | 0.9323 |
| 14 | 0.9361 | 0.9338 | 0.9322 | 0.9312 | 0.9300 |
| 15 | 0.9348 | 0.9324 | 0.9308 | 0.9299 | 0.9287 |
| 16 | 0.9334 | 0.9311 | 0.9294 | 0.9285 | 0.9273 |
| 17 | 0.9314 | 0.9291 | 0.9274 | 0.9265 | 0.9253 |
| 18 | 0.9308 | 0.9285 | 0.9268 | 0.9259 | 0.9247 |
| 19 | 0.9973 | 0.9972 | 0.9971 | 0.9971 | 0.9970 |
| 20 | 0.9937 | 0.9936 | 0.9935 | 0.9935 | 0.9934 |
| 21 | 0.9930 | 0.9929 | 0.9928 | 0.9928 | 0.9927 |
| 22 | 0.9924 | 0.9923 | 0.9922 | 0.9922 | 0.9921 |
| 23 | 0.9809 | 0.9805 | 0.9801 | 0.9799 | 0.9797 |
| 24 | 0.9742 | 0.9738 | 0.9735 | 0.9733 | 0.9730 |
| 25 | 0.9709 | 0.9705 | 0.9701 | 0.9699 | 0.9697 |
| 26 | 0.9670 | 0.9645 | 0.9627 | 0.9617 | 0.9604 |
| 27 | 0.9676 | 0.9646 | 0.9625 | 0.9613 | 0.9599 |
| 28 | 0.9672 | 0.9628 | 0.9597 | 0.9581 | 0.9559 |
| 29 | 0.9680 | 0.9623 | 0.9584 | 0.9563 | 0.9536 |
| 30 | 0.9705 | 0.9638 | 0.9593 | 0.9569 | 0.9539 |
| 31 | 0.9777 | 0.9692 | 0.9637 | 0.9607 | 0.9570 |
| 32 | 0.9805 | 0.9714 | 0.9655 | 0.9624 | 0.9584 |
| 33 | 0.9843 | 0.9746 | 0.9683 | 0.9649 | 0.9607 |
| Method | Cluster | Bus-2 | Bus-10 | Bus-18 | Bus-19 | Bus-25 | Bus-33 | |
|---|---|---|---|---|---|---|---|---|
| Case 1: Direct PLF | Case 1.1 (Clustered Data) | 15 | 0.9881 | 0.9671 | 0.9880 | 0.9756 | 0.9823 | 0.9984 |
| 30 | 0.9868 | 0.9656 | 0.9867 | 0.9675 | 0.9716 | 0.9984 | ||
| 45 | 0.9861 | 0.9649 | 0.9860 | 0.9634 | 0.9663 | 0.9984 | ||
| 60 | 0.9858 | 0.9646 | 0.9858 | 0.9616 | 0.9639 | 0.9984 | ||
| Case 1.2 (Unsorted Data) | - | 0.9853 | 0.9641 | 0.9852 | 0.9586 | 0.9600 | 0.9984 | |
| Case 2: Indirect PFBS | Case 2.1 (Clustered Data) | 15 | 0.9881 | 0.9670 | 0.9880 | 0.9756 | 0.9825 | 0.9984 |
| 30 | 0.9866 | 0.9656 | 0.9866 | 0.9675 | 0.9716 | 0.9984 | ||
| 45 | 0.9861 | 0.9650 | 0.9860 | 0.9635 | 0.9663 | 0.9984 | ||
| 60 | 0.9858 | 0.9646 | 0.9856 | 0.9618 | 0.9640 | 0.9984 | ||
| Case 2.2 (Unsorted Data) | - | 0.9854 | 0.9641 | 0.9852 | 0.9585 | 0.9601 | 0.9984 | |
| Approach | Time (s) (Proposed Direct PLF Approach) | Time (s) (Backward-Forward Approach) | |
|---|---|---|---|
| Data Clustering-Based MCS | Clusters = 15 | 0.0127 | 0.0297 |
| Clusters = 30 | 0.0248 | 0.0581 | |
| Clusters = 45 | 0.0383 | 0.0896 | |
| Clusters = 60 | 0.0488 | 0.1141 | |
| Unsorted Data-Based MCS | 4.7185 | 11.0109 | |
| Number of Bus | Data Clustering-Based MCS | Unsorted Data-Based MCS | |||
|---|---|---|---|---|---|
| 15 Clusters | 30 Clusters | 45 Clusters | 60 Clusters | ||
| 1 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 2 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 3 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 4 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 5 | 0.9993 | 0.9993 | 0.9992 | 0.9992 | 0.9992 |
| 6 | 0.9944 | 0.9938 | 0.9935 | 0.9933 | 0.9931 |
| 7 | 0.9893 | 0.9881 | 0.9875 | 0.9872 | 0.9868 |
| 8 | 0.9881 | 0.9868 | 0.9861 | 0.9858 | 0.9853 |
| 9 | 0.9875 | 0.9861 | 0.9854 | 0.9851 | 0.9845 |
| 10 | 0.9825 | 0.9811 | 0.9804 | 0.9801 | 0.9796 |
| 11 | 0.9815 | 0.9800 | 0.9793 | 0.9790 | 0.9785 |
| 12 | 0.9783 | 0.9769 | 0.9762 | 0.9759 | 0.9753 |
| 13 | 0.9754 | 0.9740 | 0.9733 | 0.9730 | 0.9724 |
| 14 | 0.9726 | 0.9711 | 0.9704 | 0.9701 | 0.9695 |
| 15 | 0.9697 | 0.9683 | 0.9676 | 0.9672 | 0.9667 |
| 16 | 0.9692 | 0.9678 | 0.9670 | 0.9667 | 0.9662 |
| 17 | 0.9683 | 0.9669 | 0.9662 | 0.9658 | 0.9653 |
| 18 | 0.9683 | 0.9669 | 0.9662 | 0.9658 | 0.9653 |
| 19 | 0.9678 | 0.9664 | 0.9657 | 0.9654 | 0.9648 |
| 20 | 0.9676 | 0.9661 | 0.9654 | 0.9651 | 0.9645 |
| 21 | 0.9671 | 0.9656 | 0.9649 | 0.9646 | 0.9641 |
| 22 | 0.9671 | 0.9656 | 0.9649 | 0.9646 | 0.9640 |
| 23 | 0.9670 | 0.9656 | 0.9648 | 0.9645 | 0.9640 |
| 24 | 0.9668 | 0.9654 | 0.9647 | 0.9644 | 0.9638 |
| 25 | 0.9667 | 0.9652 | 0.9645 | 0.9642 | 0.9636 |
| 26 | 0.9666 | 0.9652 | 0.9644 | 0.9641 | 0.9636 |
| 27 | 0.9666 | 0.9652 | 0.9644 | 0.9641 | 0.9636 |
| 28 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 29 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 30 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9997 |
| 31 | 0.9997 | 0.9997 | 0.9997 | 0.9997 | 0.9997 |
| 32 | 0.9996 | 0.9996 | 0.9996 | 0.9996 | 0.9996 |
| 33 | 0.9994 | 0.9994 | 0.9994 | 0.9994 | 0.9994 |
| 34 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | 0.9990 |
| 35 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | 0.9990 |
| 36 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 |
| 37 | 0.9986 | 0.9986 | 0.9986 | 0.9986 | 0.9986 |
| 38 | 0.9947 | 0.9947 | 0.9947 | 0.9947 | 0.9947 |
| 39 | 0.9942 | 0.9942 | 0.9942 | 0.9942 | 0.9942 |
| 40 | 0.9880 | 0.9867 | 0.9860 | 0.9858 | 0.9852 |
| 41 | 0.9880 | 0.9867 | 0.9860 | 0.9857 | 0.9852 |
| 42 | 0.9866 | 0.9850 | 0.9841 | 0.9837 | 0.9831 |
| 43 | 0.9856 | 0.9836 | 0.9826 | 0.9822 | 0.9814 |
| 44 | 0.9843 | 0.9819 | 0.9807 | 0.9801 | 0.9792 |
| 45 | 0.9831 | 0.9802 | 0.9788 | 0.9781 | 0.9770 |
| 46 | 0.9789 | 0.9733 | 0.9705 | 0.9692 | 0.9671 |
| 47 | 0.9769 | 0.9699 | 0.9665 | 0.9649 | 0.9623 |
| 48 | 0.9762 | 0.9687 | 0.9649 | 0.9633 | 0.9605 |
| 49 | 0.9756 | 0.9675 | 0.9634 | 0.9616 | 0.9586 |
| 50 | 0.9742 | 0.9651 | 0.9606 | 0.9586 | 0.9553 |
| 51 | 0.9750 | 0.9657 | 0.9612 | 0.9591 | 0.9557 |
| 52 | 0.9762 | 0.9667 | 0.9620 | 0.9600 | 0.9564 |
| 53 | 0.9823 | 0.9716 | 0.9663 | 0.9639 | 0.9600 |
| 54 | 0.9817 | 0.9710 | 0.9657 | 0.9634 | 0.9594 |
| 55 | 0.9814 | 0.9800 | 0.9793 | 0.9790 | 0.9784 |
| 56 | 0.9814 | 0.9800 | 0.9793 | 0.9790 | 0.9784 |
| 57 | 0.9780 | 0.9766 | 0.9759 | 0.9755 | 0.9750 |
| 58 | 0.9780 | 0.9766 | 0.9759 | 0.9755 | 0.9750 |
| 59 | 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 60 | 0.9998 | 0.9998 | 0.9998 | 0.9998 | 0.9998 |
| 61 | 0.9996 | 0.9996 | 0.9996 | 0.9996 | 0.9996 |
| 62 | 0.9996 | 0.9996 | 0.9996 | 0.9996 | 0.9996 |
| 63 | 0.9995 | 0.9995 | 0.9995 | 0.9995 | 0.9995 |
| 64 | 0.9989 | 0.9989 | 0.9989 | 0.9989 | 0.9989 |
| 65 | 0.9986 | 0.9986 | 0.9986 | 0.9986 | 0.9986 |
| 66 | 0.9985 | 0.9985 | 0.9985 | 0.9985 | 0.9985 |
| 67 | 0.9985 | 0.9985 | 0.9985 | 0.9985 | 0.9985 |
| 68 | 0.9984 | 0.9984 | 0.9984 | 0.9984 | 0.9984 |
| 69 | 0.9984 | 0.9984 | 0.9984 | 0.9984 | 0.9984 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oshnoei, A.; Khezri, R.; Tarafdar Hagh, M.; Techato, K.; Muyeen, S.; Sadeghian, O. Direct Probabilistic Load Flow in Radial Distribution Systems Including Wind Farms: An Approach Based on Data Clustering. Energies 2018, 11, 310. https://doi.org/10.3390/en11020310
Oshnoei A, Khezri R, Tarafdar Hagh M, Techato K, Muyeen S, Sadeghian O. Direct Probabilistic Load Flow in Radial Distribution Systems Including Wind Farms: An Approach Based on Data Clustering. Energies. 2018; 11(2):310. https://doi.org/10.3390/en11020310
Chicago/Turabian StyleOshnoei, Arman, Rahmat Khezri, Mehrdad Tarafdar Hagh, Kuaanan Techato, SM Muyeen, and Omid Sadeghian. 2018. "Direct Probabilistic Load Flow in Radial Distribution Systems Including Wind Farms: An Approach Based on Data Clustering" Energies 11, no. 2: 310. https://doi.org/10.3390/en11020310
APA StyleOshnoei, A., Khezri, R., Tarafdar Hagh, M., Techato, K., Muyeen, S., & Sadeghian, O. (2018). Direct Probabilistic Load Flow in Radial Distribution Systems Including Wind Farms: An Approach Based on Data Clustering. Energies, 11(2), 310. https://doi.org/10.3390/en11020310