Analyzing and Forecasting Electrical Load Consumption in Healthcare Buildings


 , ,
, , 
Abstract
:1. Introduction
2. Proposed Methodology
2.1. Fundamentals of PCA Forecasting
| Algorithm 1 PCA-based algorithm for electrical load forecast. |
| Input: |
|
| Output: , and . |
2.2. Fundamentals of OPLS Forecasting
| Algorithm 2 OPLS analysis and forecast. |
| Input: , , and Q |
|
| Output: , , and . |
2.3. Convex Combinations
2.4. Performance Evaluation
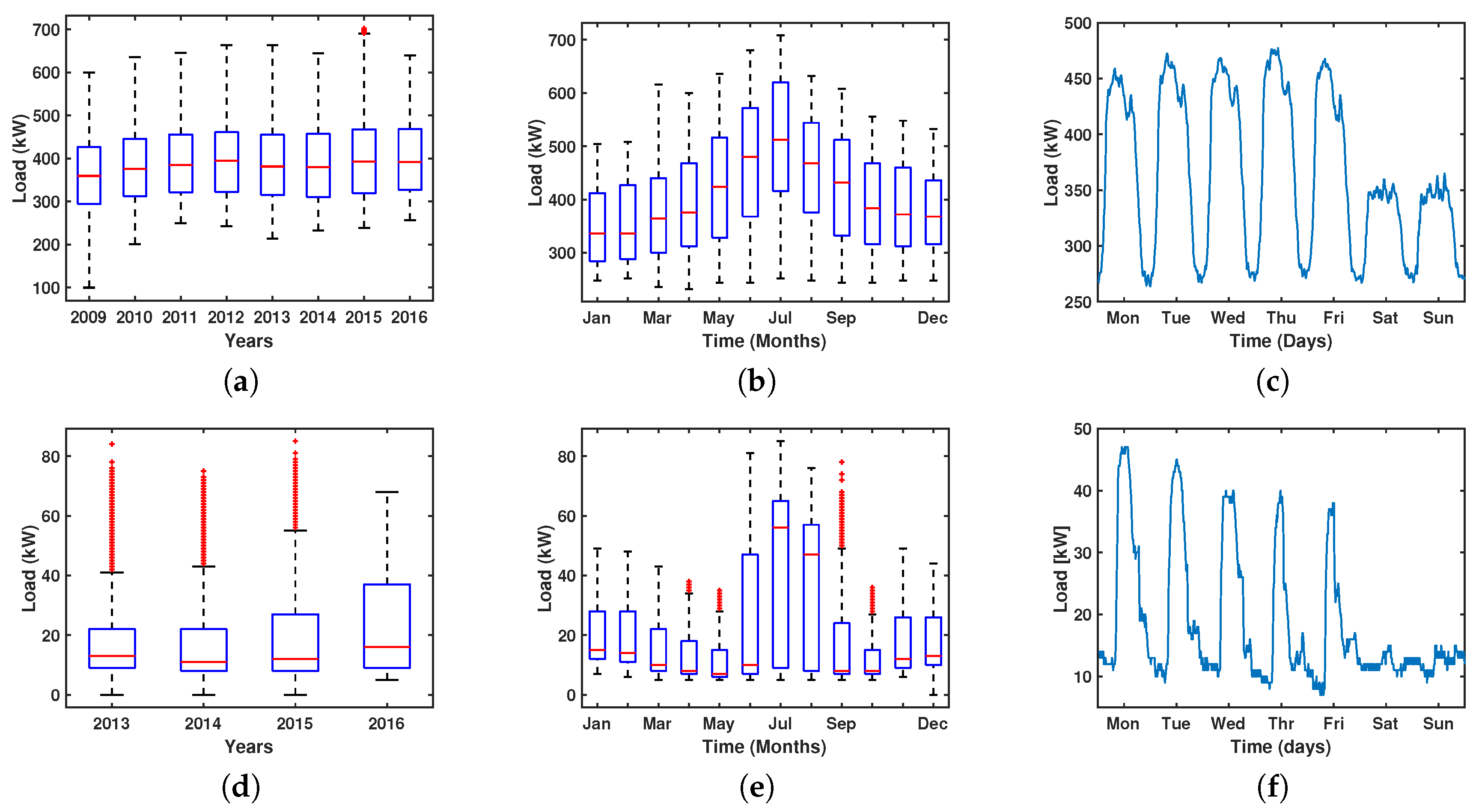
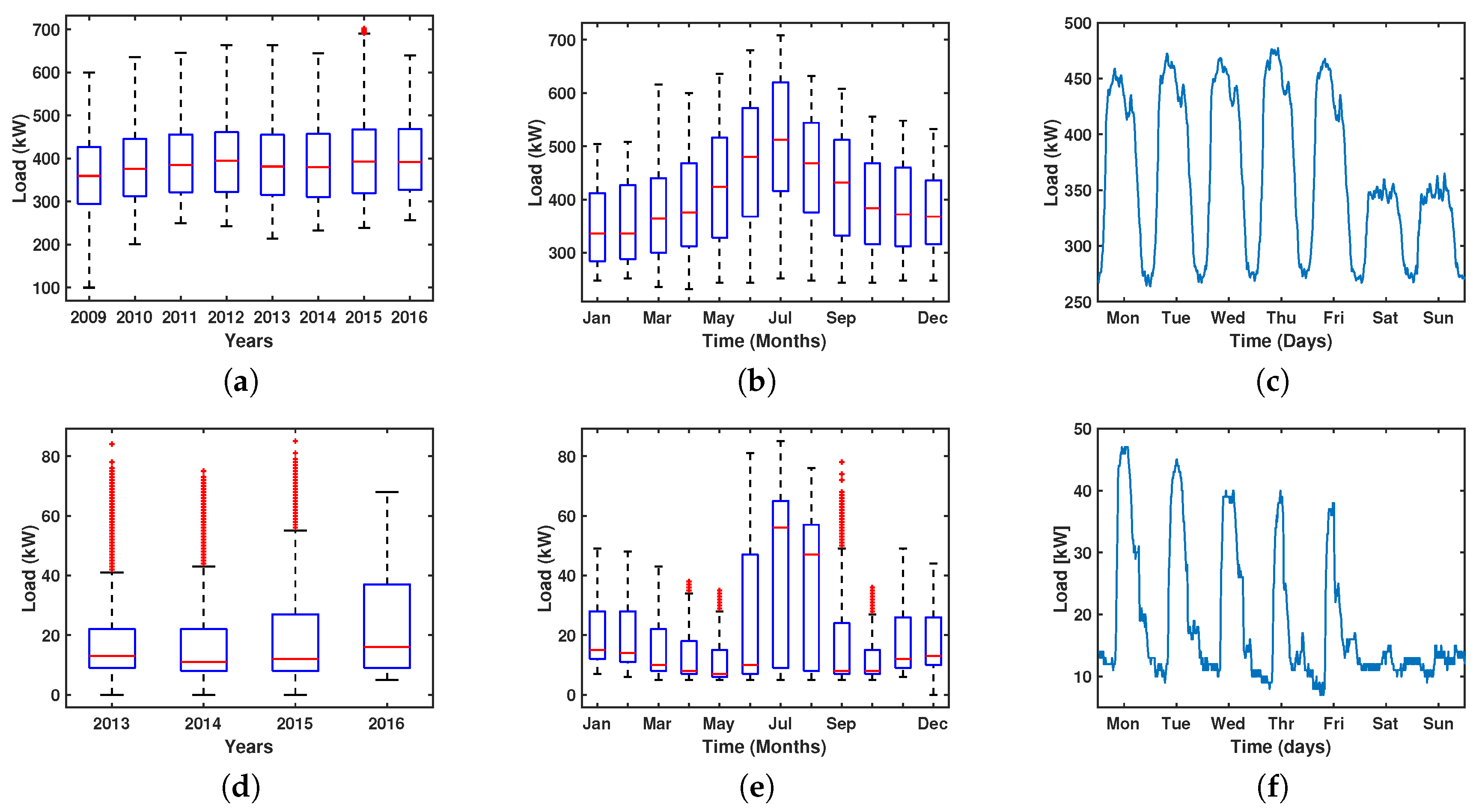
3. Database Description
4. Experiments and Results
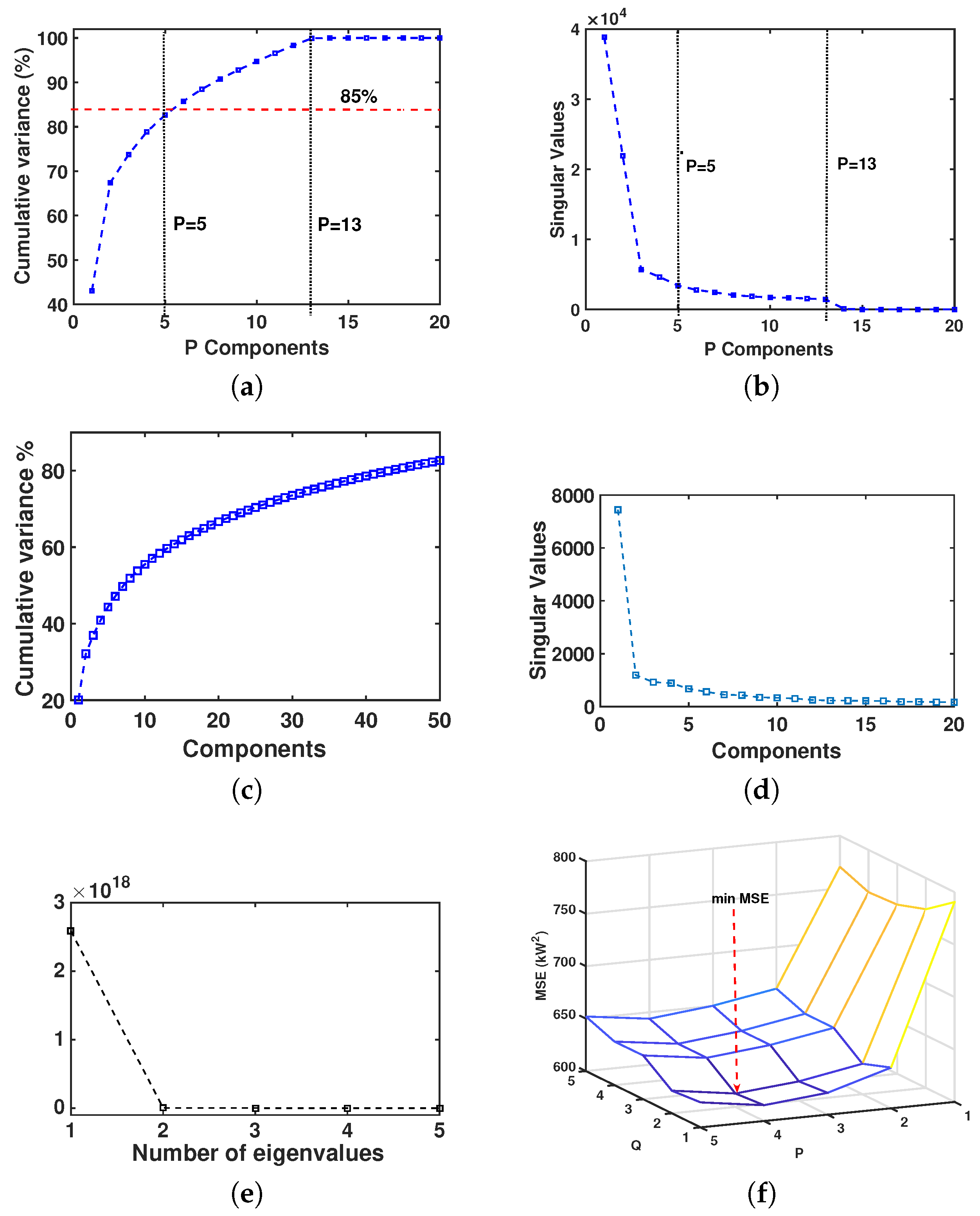
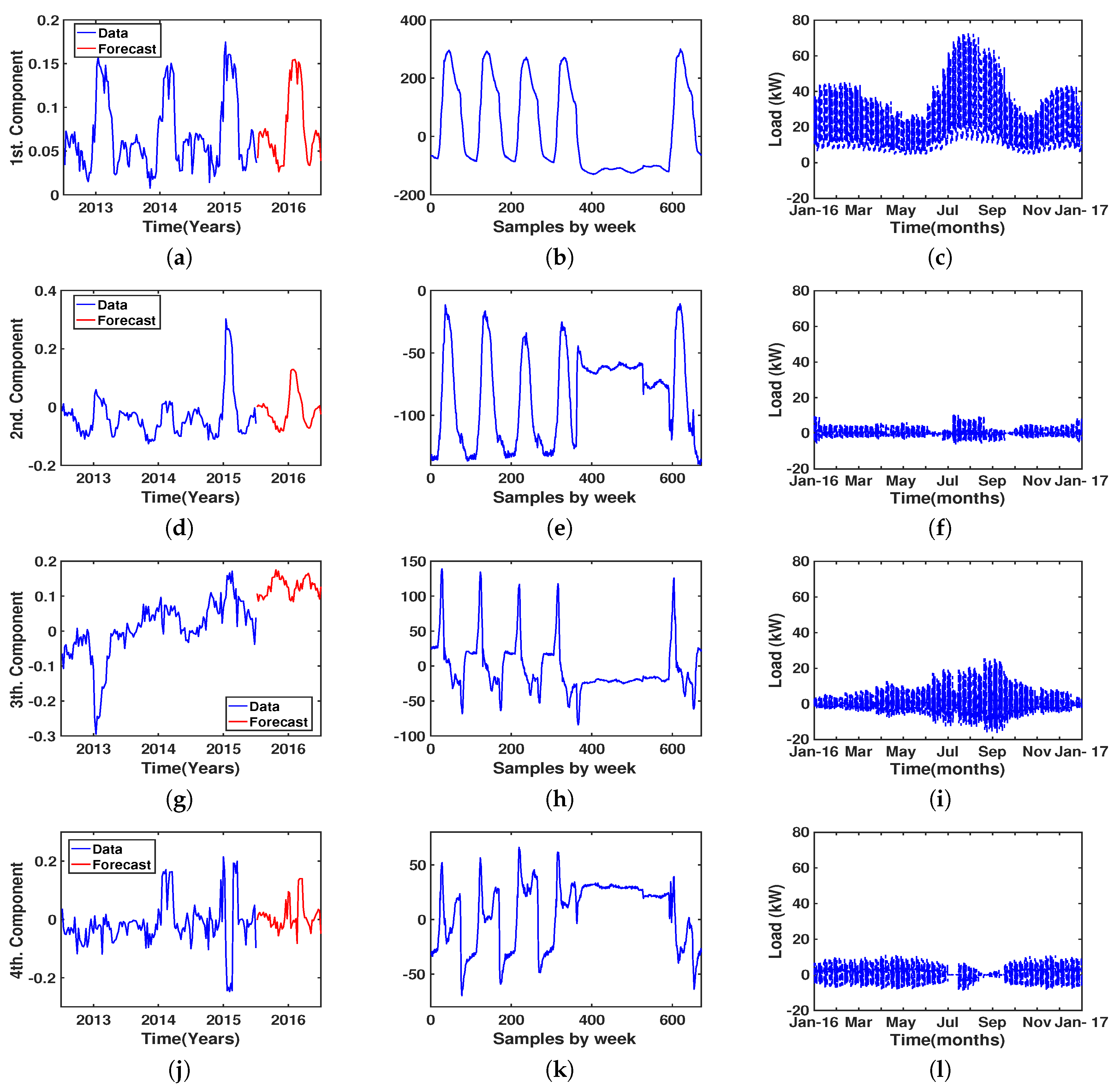
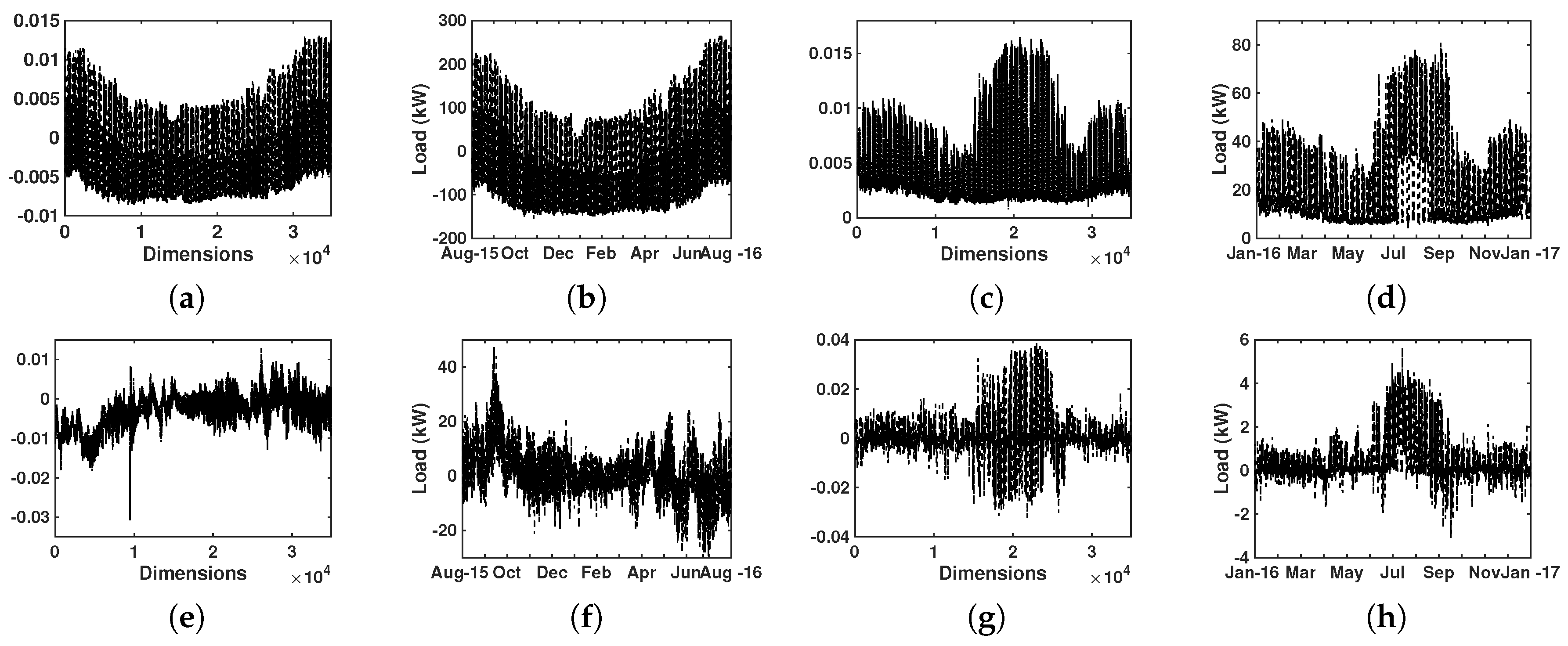
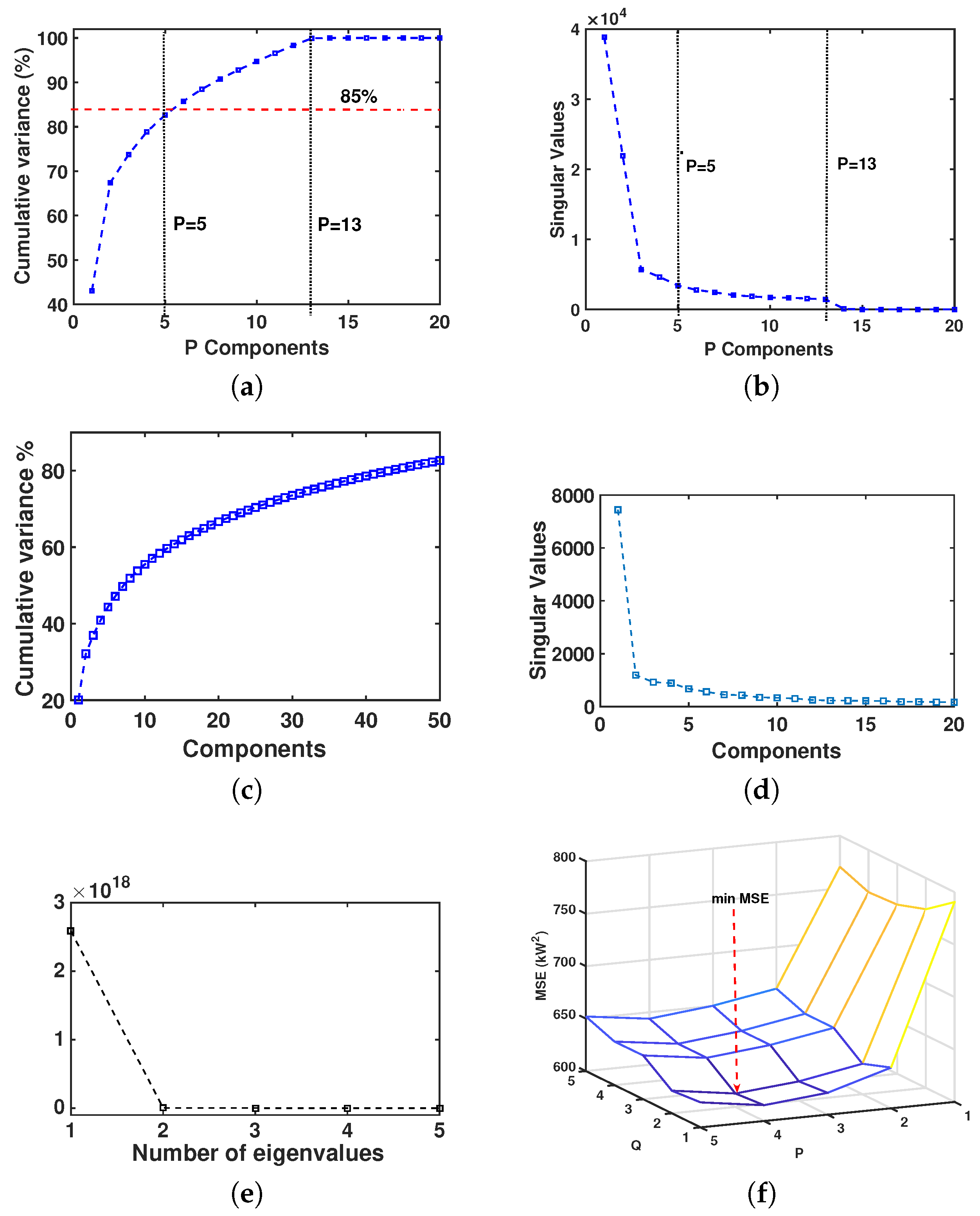
4.1. Results of Model Order Selection
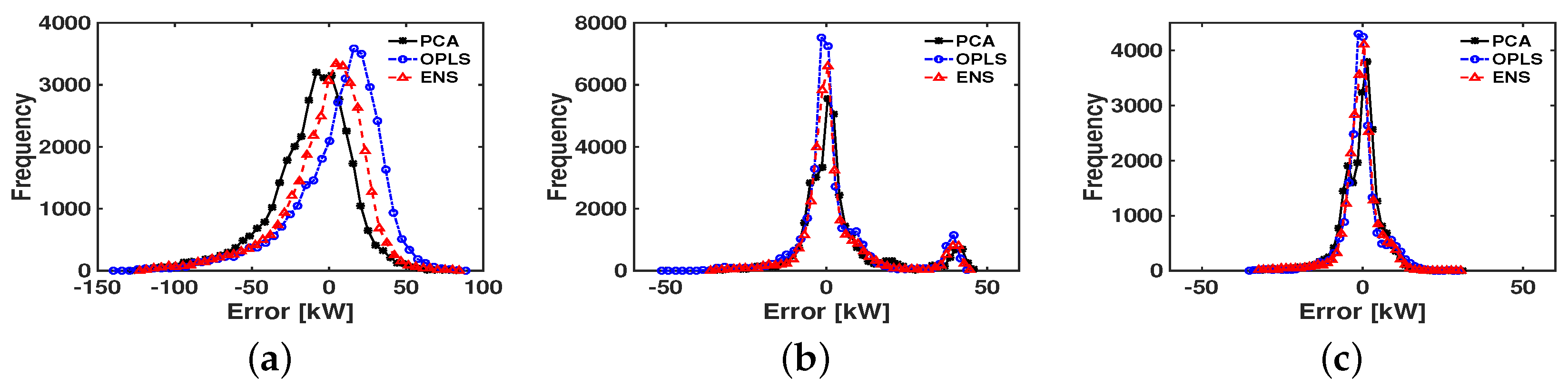
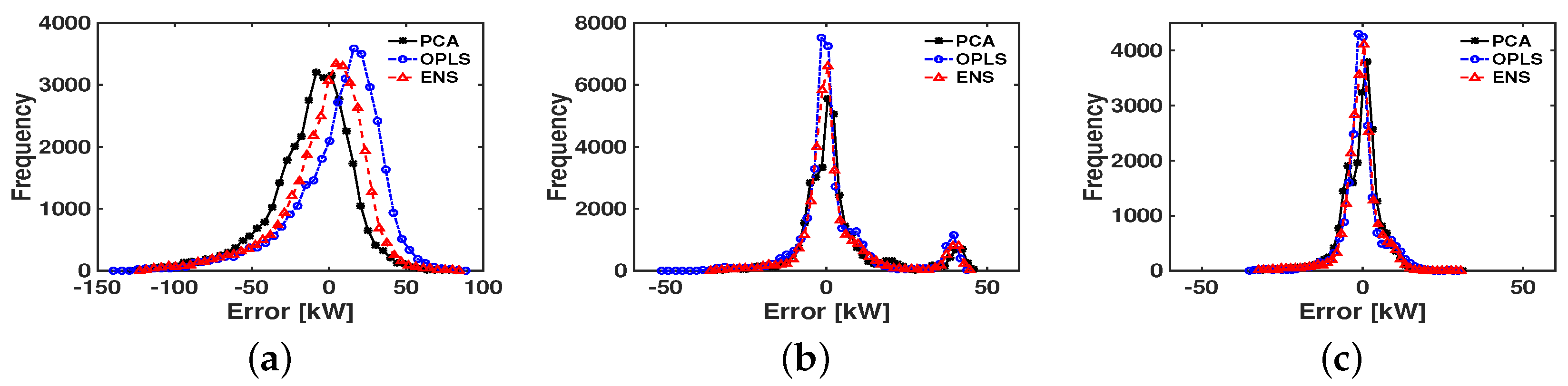
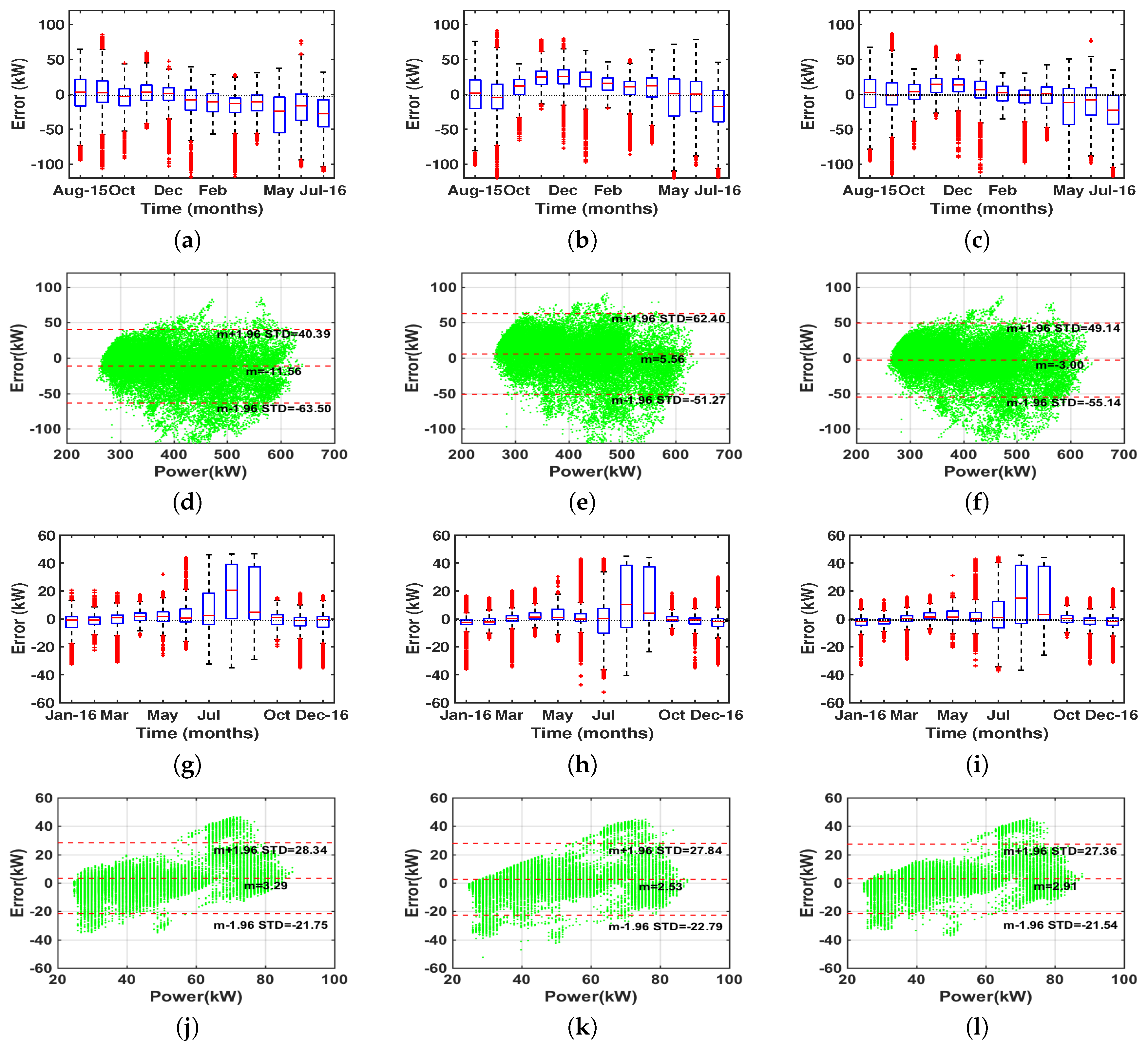
4.2. Performance Results
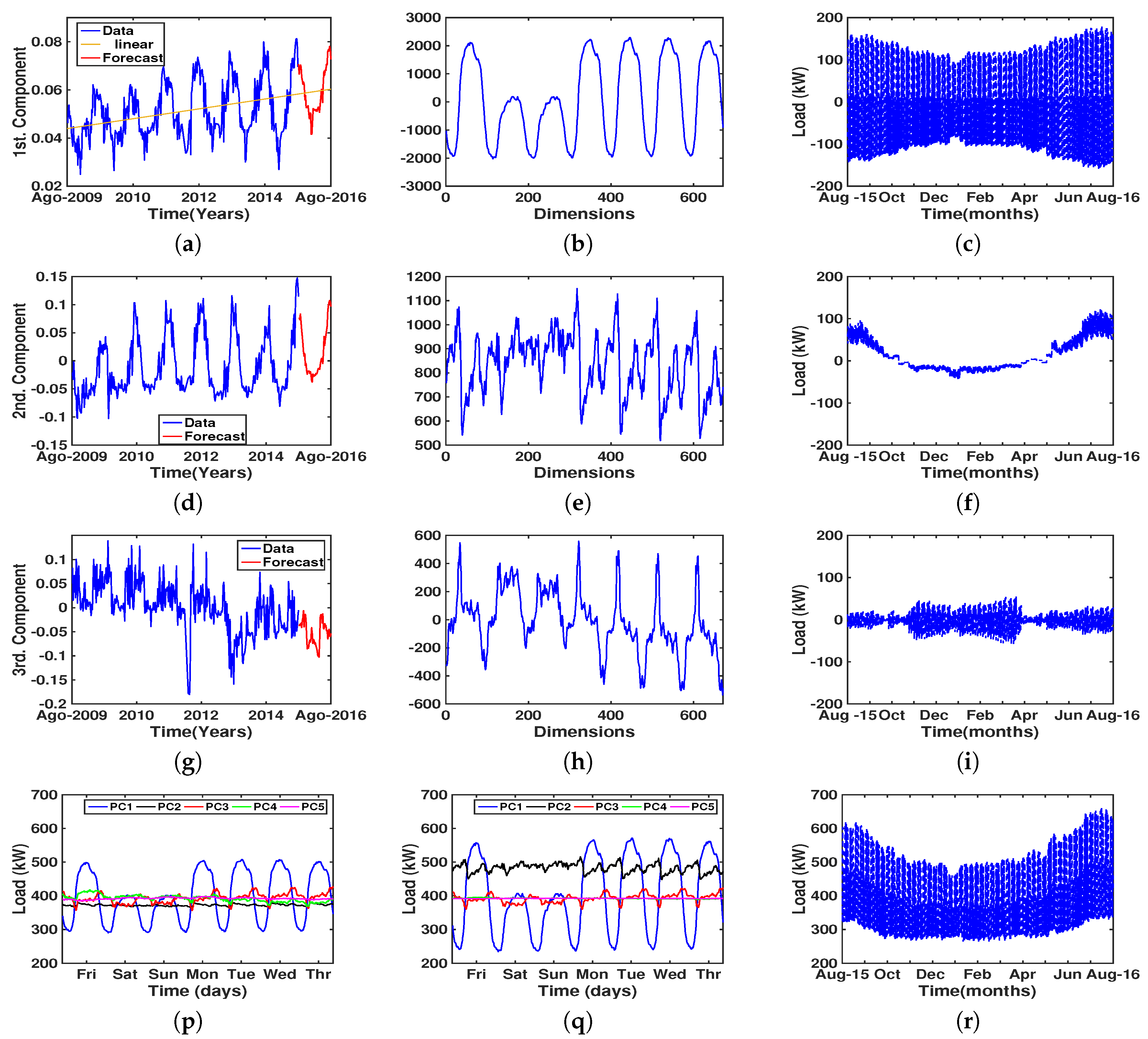
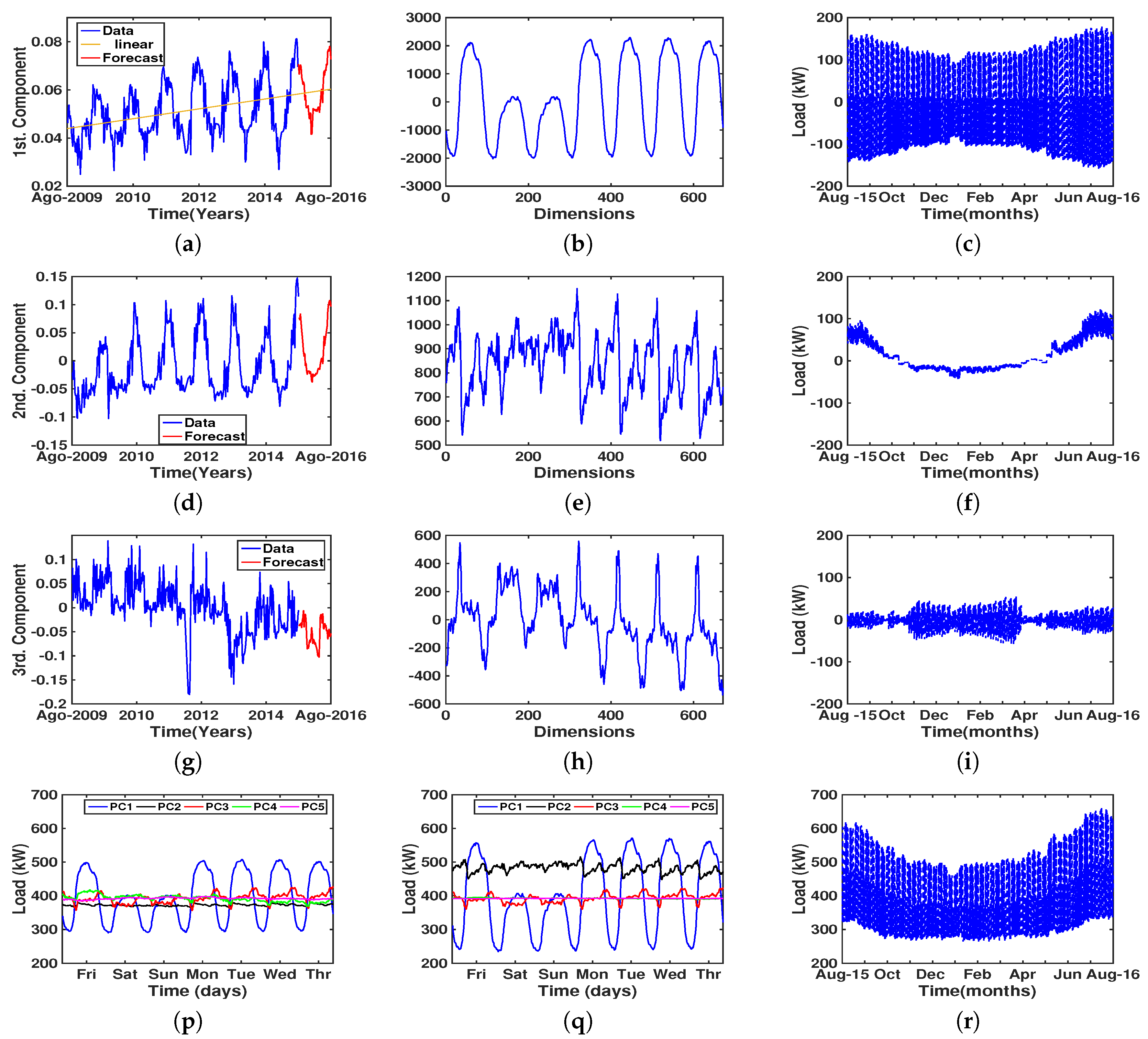
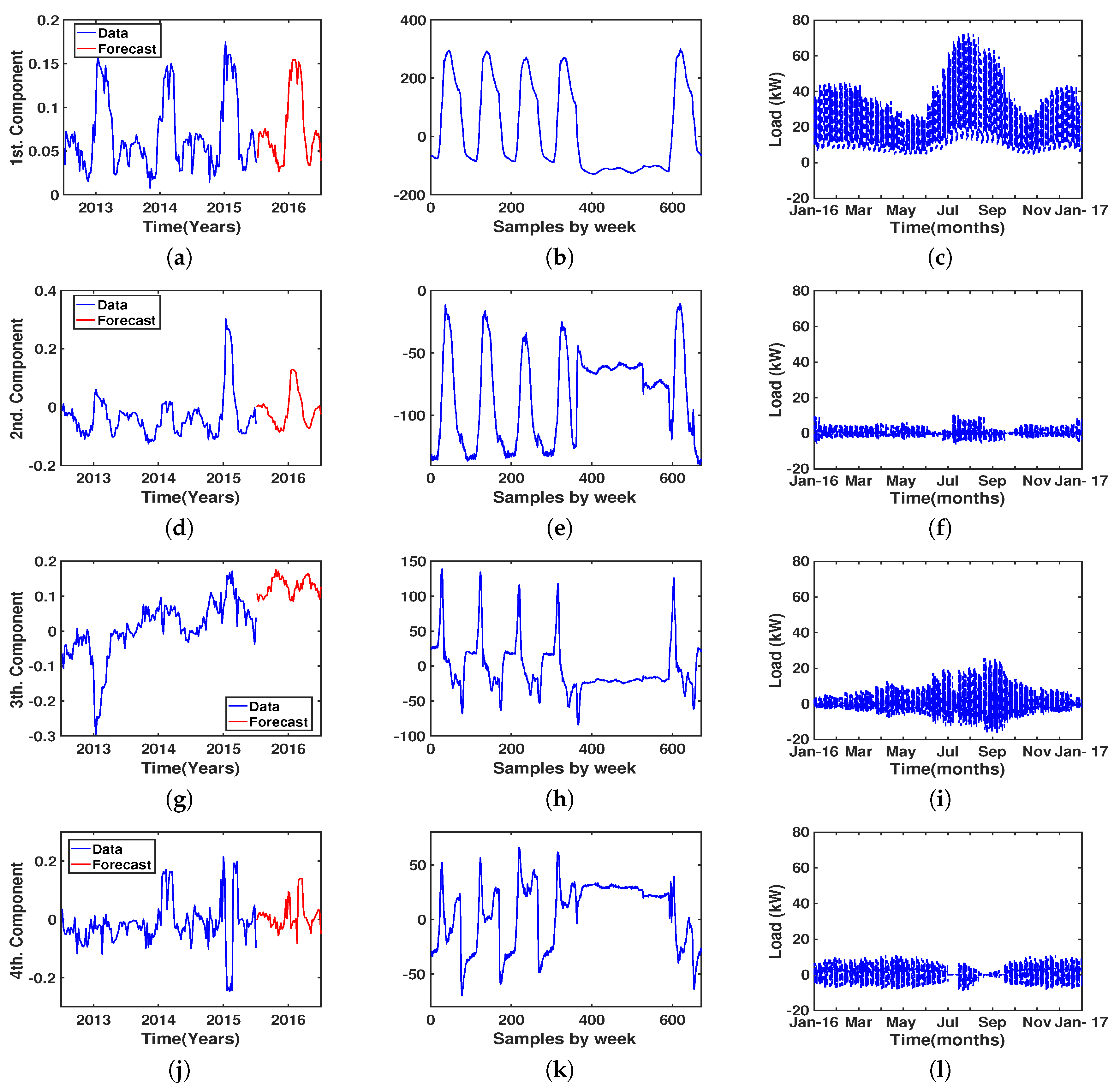
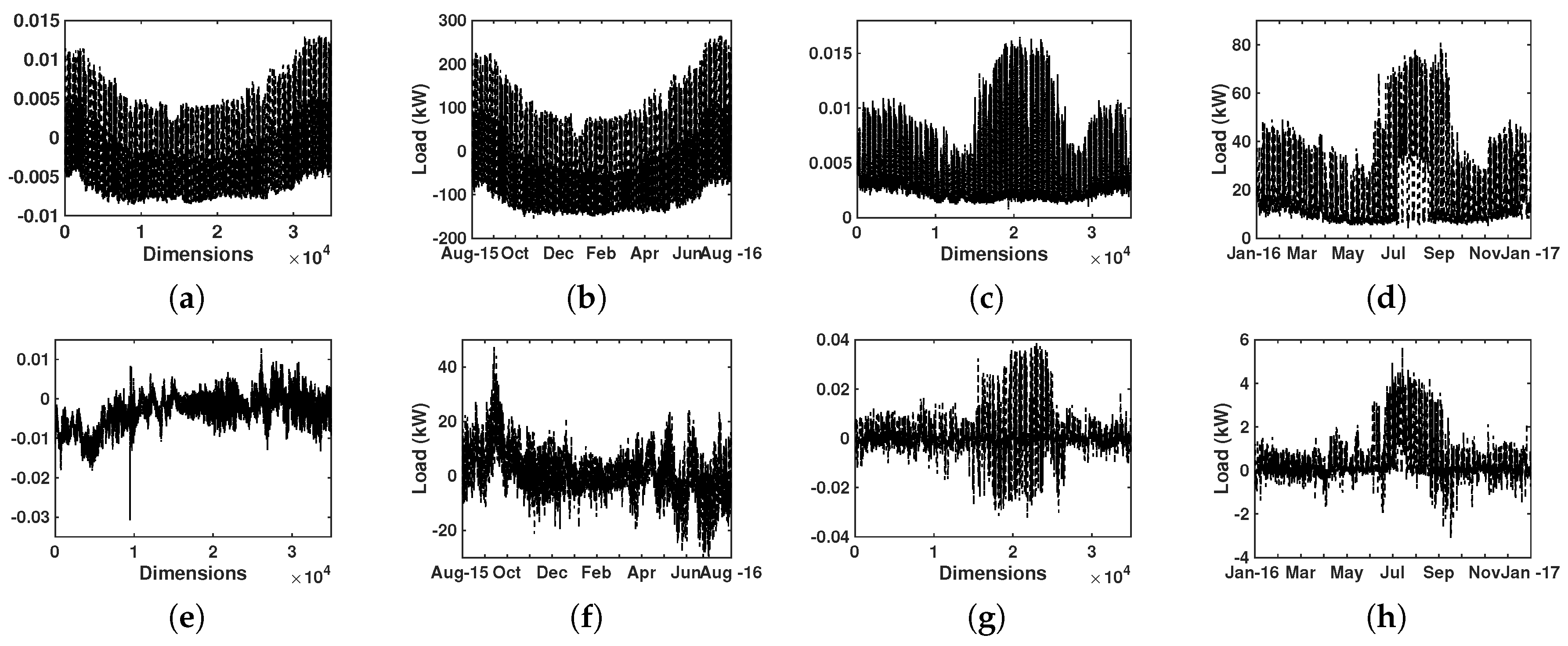
4.3. Results of Eigenvector Analysis
5. Discussion
6. Concluding Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Soliman, S.A.H.; Al-Kandari, A.M. Electrical Load Forecasting: Modeling and Model Construction; Elsevier: Burlington, MA, USA, 2010; ISBN 978-0-12-381543-9. [Google Scholar]
- Abu-Shikhah, N.; Elkarmi, F.; Aloquili, O.M. Medium-term electric load forecasting using multivariable linear and non-linear regression. Smart Grid Renew. Energy 2011, 2, 126–135. [Google Scholar] [CrossRef]
- Ryu, S.; Noh, J.; Kim, H. Deep neural network based demand side short term load forecasting. Energies 2016, 10, 3. [Google Scholar] [CrossRef]
- Khuntia, S.R.; Rueda, J.L.; van der Meijden, M. Forecasting the load of electrical power systems in mid- and long-term horizons: A review. IET Gener. Transm. Distrib. 2016, 10, 3971–3977. [Google Scholar] [CrossRef]
- Hu, S.; Chen, J.; Chuah, Y. Energy cost and consumption in a large acute hospital. Int. J. Archit. Sci. 2004, 5, 11–19. [Google Scholar]
- Hong, T.; Shahidehpour, M. Load Forecasting Case Study; Department of Energy: Chicago, IL, USA, 2015.
- Alhurayess, S.; Darwish, M.K. Analysis of energy management in hospitals. In Proceedings of the 47th International Universities Power Engineering Conference (UPEC), London, UK, 4–7 September 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, D. Medium and long-term load forecasting based on PCA and BP neural network method. In Proceedings of the International Conference on Energy and Environment Technology, Guilin, China, 16–18 October 2009; pp. 389–391. [Google Scholar] [CrossRef]
- Tangirala, A.K. Principles of System Identification: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2015; ISBN 978-1439895993. [Google Scholar]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis; Pearson: London, UK, 2009. [Google Scholar]
- Galbraith, J.W.; Green, C. Inference about trends in global temperature data. Clim. Chang. 1992, 22, 209–221. [Google Scholar] [CrossRef]
- Zheng, X.; Basher, R.E. Structural Time Series Models and Trend Detection in Global and Regional Temperature Series. J. Clim. 1999, 12, 2347–2358. [Google Scholar] [CrossRef]
- Huang, S.C.; Wang, N.Y.; Wu, T.K. High Dimensional Data Mining Systems by Kernel Orthonormalized Partial Least Square Analysis. Int. J. Futur. Comput. Commun. 2015, 4, 364–367. [Google Scholar] [CrossRef]
- Muñoz-Romero, S.; Arenas-García, J.; Gómez-Verdejo, V. Iterative orthonormalized partial least squares with sparsity constraints. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3387–3391. [Google Scholar] [CrossRef]
- Reinsel, G.C.; Velu, R.P. Multivariate Reduced-Rank Regression: Theory and Applications; Lecture Notes in Statistics; Springer: New York, NY, USA, 1998; ISBN 978-0-387-98601-2. [Google Scholar]
- Muñoz-Romero, S.; Arenas-García, J.; Gómez-Verdejo, V. Sparse and kernel OPLS feature extraction based on eigenvalue problem solving. Pattern Recognit. 2015, 48, 1797–1811. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004; ISBN 0521813972. [Google Scholar]
- Wu, Y.K.; Yang, W.W. Optimization of fuzzy relational equations with a linear convex combination of max-min and max-average compositions. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management, Singapore, 2–5 December 2007; pp. 832–836. [Google Scholar] [CrossRef]
- Jia, N.; Yokoyama, R.; Zhou, Y.; Gao, Z. A flexible long-term load forecasting approach based on new dynamic simulation theory—GSIM. Int. J. Electr. Power Energy Syst. 2001, 23, 549–556. [Google Scholar] [CrossRef]
- Chen, Y.H.; Hong, W.C.; Shen, W.; Huang, N.N. Electric load forecasting based on a least squares support vector machine with fuzzy time series and global harmony search algorithm. Energies 2016, 9, 70. [Google Scholar] [CrossRef]
- Hahn, H.; Meyer-Nieberg, S.; Pickl, S. Electric load forecasting methods: Tools for decision making. Eur. J. Oper. Res. 2009, 199, 902–907. [Google Scholar] [CrossRef]
- Bagnasco, A.; Saviozzi, M.; Silvestro, F.; Vinci, A.; Grillo, S.; Zennaro, E. Artificial neural network application to load forecasting in a large hospital facility. In Proceedings of the International Conference on Probabilistic Methods Applied to Power Systems (PMAPS), Durham, UK, 7–10 July 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Stojanović, M.B.; Božić, M.M.; Stanković, M.M. Mid-term load forecasting using recursive time series prediction strategy with support vector machines. Facta Univ.-Ser. Electron. Energ. 2010, 23, 287–298. [Google Scholar] [CrossRef]
- Papaioannou, G.P.; Dikaiakos, C.; Dramountanis, A.; Papaioannou, P.G. Analysis and modeling for short-to medium-term load forecasting using a hybrid manifold learning principal component model and comparison with classical statistical models (SARIMAX, Exponential Smoothing) and artificial intelligence models (ANN, SVM): The case of Greek electricity market. Energies 2016, 9, 635. [Google Scholar] [CrossRef]
- Di Silvio, B.; Cesarotti, V.; Introna, V. Evaluation of electricity rates through characterization and forecasting of energy consumption: A case study of an Italian industrial eligible customer. Int. J. Energy Sect. Manag. 2007, 1, 390–412. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Value |
|---|---|---|
| Sampling time | 15 min | |
| Number of samples by hour | ||
| Day length of samples | ||
| Week length of samples | ||
| Year length of samples | ||
| Year length in days | 364 | |
| Year length in weeks | 52 | |
| L | Database length in years | 8 for Hospital of Fuenlabrada; 4 for Centro Especialidads el Arroyo |
| Dataset | Data Base from Hospital (L = 7) | CEA (L = 3) | ||||
|---|---|---|---|---|---|---|
| Metric/Method | PCA | OPLS | ENS | PCA | OPLS | ENS |
| RMSE (kW) | 28.91 | 29.53 | 26.77 | 13.33 | 13.19 | 12.99 |
| MAPE (%) | 5.06 | 5.96 | 4.83 | 16.21 | 15.14 | 14.63 |
| PBIAS (%) | −2.87 | 1.38 | −0.74 | 7.58 | 5.81 | 6.69 |
| Metric | MAPE (%) | PBIAS (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method/L (Years) | 7 | 6 | 5 | 4 | 3 | 7 | 6 | 5 | 4 | 3 |
| PCA | 5.06 | 4.93 | 5.00 | 5.08 | 5.11 | −2.87 | −1.67 | −0.84 | −0.35 | −3.16 |
| OPLS | 5.96 | 6.11 | 6.01 | 5.951 | 5.57 | 1.38 | 1.34 | 1.39 | 1.87 | 1.15 |
| ENS | 4.83 | 5.13 | 5.28 | 5.32 | 4.85 | −0.74 | −0.16 | 0.27 | 0.75 | −1.00 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gordillo-Orquera , R.; Lopez-Ramos, L.M.; Muñoz-Romero, S.; Iglesias-Casarrubios, P.; Arcos-Avilés, D.; Marques, A.G.; Rojo-Álvarez, J.L. Analyzing and Forecasting Electrical Load Consumption in Healthcare Buildings. Energies 2018, 11, 493. https://doi.org/10.3390/en11030493
Gordillo-Orquera R, Lopez-Ramos LM, Muñoz-Romero S, Iglesias-Casarrubios P, Arcos-Avilés D, Marques AG, Rojo-Álvarez JL. Analyzing and Forecasting Electrical Load Consumption in Healthcare Buildings. Energies. 2018; 11(3):493. https://doi.org/10.3390/en11030493
Chicago/Turabian StyleGordillo-Orquera , Rodolfo, Luis Miguel Lopez-Ramos, Sergio Muñoz-Romero, Paz Iglesias-Casarrubios, Diego Arcos-Avilés, Antonio G. Marques, and José Luis Rojo-Álvarez. 2018. "Analyzing and Forecasting Electrical Load Consumption in Healthcare Buildings" Energies 11, no. 3: 493. https://doi.org/10.3390/en11030493
APA StyleGordillo-Orquera , R., Lopez-Ramos, L. M., Muñoz-Romero, S., Iglesias-Casarrubios, P., Arcos-Avilés, D., Marques, A. G., & Rojo-Álvarez, J. L. (2018). Analyzing and Forecasting Electrical Load Consumption in Healthcare Buildings. Energies, 11(3), 493. https://doi.org/10.3390/en11030493