The Application of Heterogeneous Information Fusion in Misalignment Fault Diagnosis of Wind Turbines


Abstract
:1. Introduction
2. The Related Theory
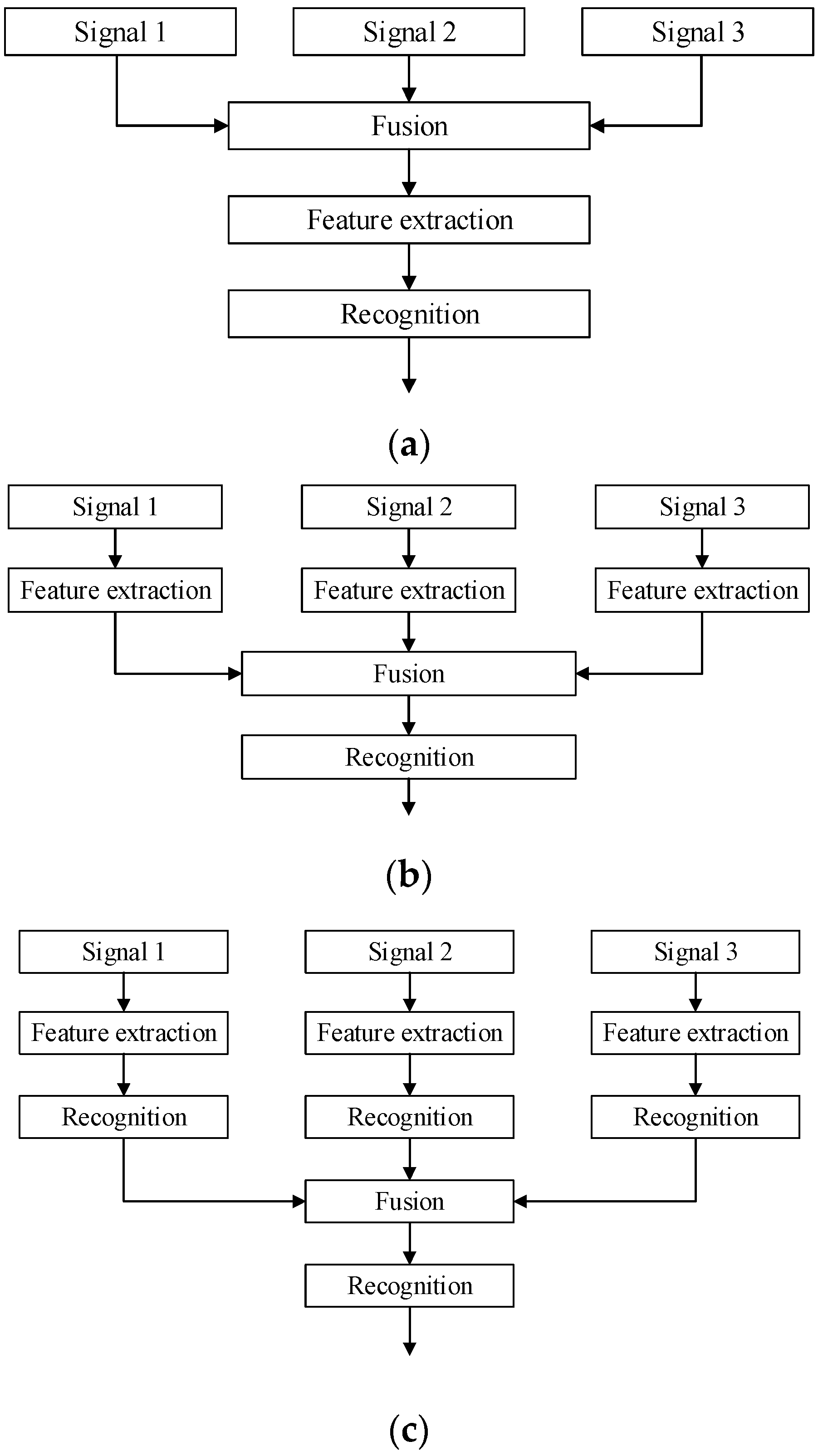
2.1. The Concept of Information Fusion
- Data Level Fusion. Also called pixel level fusion. It is a comprehensive analysis of raw information. In this level of fusion, information loss is small, but the calculation is large. Real-time and fault tolerance are poor, and the level of integration is low. Because of the presence of redundant information, it may affect the diagnostic accuracy. Data level fusion is generally limited to the same type of sensor information.
- Feature Level Fusion. The data from multiple sensors must be preprocessed, forming feature vectors, which were fused to get the joint feature vector. Feature level fusion is more real-time than data level fusion. If the selected algorithm is reasonable, the elimination of redundant information will improve the accuracy of diagnosis.
- Decision Level Fusion. Each sensor’s processing system has completed its decision-making or classification tasks before fusion. Optimal decisions are made based on certain criteria and the credibility of decisions through fusion. Decision level fusion is the highest level of fusion. Its real-time performance and fault tolerance are good, but information loss is large and more complicated algorithms are needed.
2.2. Dimension Reduced Feature Fusion Algorithm
- (1)
- Define a high-dimensional data set:
- (2)
- Compute the complexity parameter of the value equation :where, is the conditional probability of data points (other than ) with respect to , is the conditional probability of high-dimensional data, is the joint probability density in the high-dimensional space, and is the joint probability density in the low-dimensional mapping space.
- (3)
- Define the optimization parameters: the number of iterations T, the learning rate η, the momentum factor at the tth (t ≤ T) iteration . The value equation c is learned by the gradient descent method, and the low-dimensional mapping of the high-dimensional data is finally obtained:where, and are the mapping of the high-dimensional data and in the low-dimensional space.
2.3. Fault Diagnosis Method and Parameters Optimization
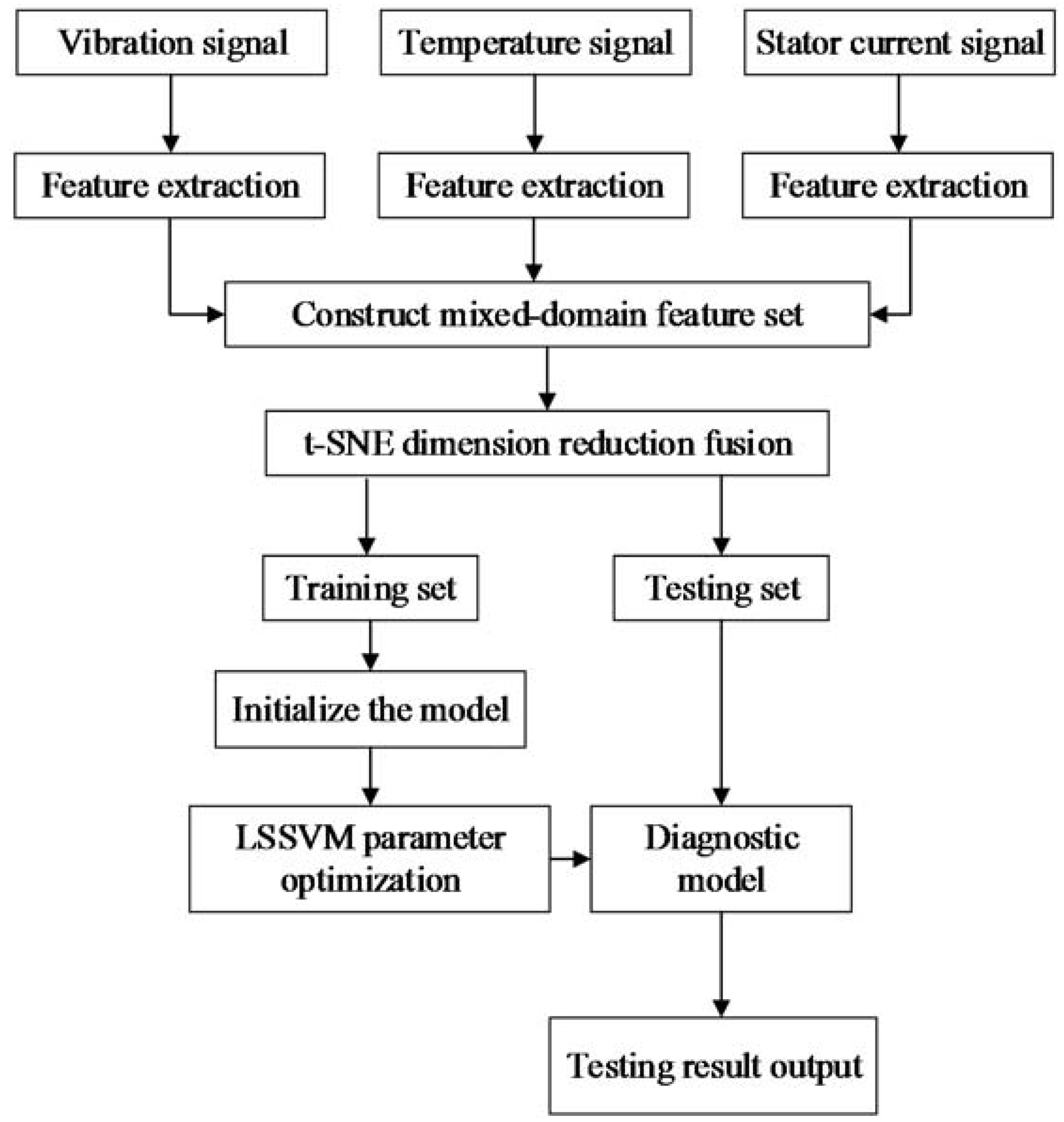
3. Signal Acquisition and Feature Extraction
3.1. Signal Acquisition
3.2. Feature Extraction
3.2.1. Time Domain Feature Extraction
3.2.2. Frequency Domain Feature Extraction
3.2.3. Time-Frequency Feature Extraction
3.2.4. Three Signals Feature Extraction
4. The Fault Diagnosis Implementation and Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- National Energy Administration. 12th Five-Year Plan of Energy Development; National Energy Administration: Beijing, China, 2013.
- Wind Energy Professional Committee of China Renewable Energy Society. 2016 China Wind Power Capacity Statistics; Wind Energy Professional Committee of China Renewable Energy Society: Beijing, China, 2017. [Google Scholar]
- Global Wind Energy Council. Global Wind Market Development Report 2012. Wind Energy 2013, 4, 32–36. [Google Scholar]
- Zhang, S.; Zhao, Q.; Guo, Y. The Status, Trends and Opportunities of Megawatt Wind Power Generation Technology. Aviat. Power Technol. 2008, 29, 9–13. [Google Scholar]
- Jackon, C. Successful shaft hot-alignment. Hydrocarb. Process. 1999, 6, 28–40. [Google Scholar]
- Shen, D. Fault diagnosis of misalignment of large-scale units. Facil. Manag. Maint. 2010, 5, 52–53. [Google Scholar]
- Sun, Z. Research on Equipment Monitoring and Fault Diagnosis Methods Based on Oil Analysis Technology; Taiyuan University of Technology: Taiyuan, China, 2012. [Google Scholar]
- Cao, L.; Li, A.; Deng, Y.; Ding, Y. Application of acoustic emission and wavelet packet analysis in damage condition monitoring. Vib. Test Diagn. 2012, 32, 591–595. [Google Scholar]
- Xu, Z. Research on Condition Monitoring and Fault Diagnosis of Wind Turbine Drive Train Based on Vibration Method; Zhejiang University: Hangzhou, China, 2012. [Google Scholar]
- Hou, J. Research on Fault Diagnosis Method of Rotor Bearing System Based on Motor Current; Taiyuan University of Technology: Taiyuan, China, 2015. [Google Scholar]
- Shen, C. Research on Fault Diagnosis and Prediction of Key Components of Rotating Machinery and Equipment; University of Science and Technology of China: Hefei, China, 2014. [Google Scholar]
- Long, J.; Wu, J. Rotor Misalignment of Wind Turbine Generator. Noise Vib. Control 2013, 3, 222–225. [Google Scholar]
- Zhang, T. Fault Diagnosis of Gear Transmission Based on Bispectrum Analysis of Motor Current Signal. J. Mech. Eng. 2012, 21, 84–90. [Google Scholar] [CrossRef]
- Hou, J.; Ding, H.; Yang, Z. Fault Diagnosis of Rotor Bearing System Based on Stator Current. Coal Technol. 2015, 34, 268–271. [Google Scholar]
- Zhang, X.; Ruan, S.; Zhou, X.; Zhao, H. Prediction method for early failure of main bearing of wind turbine based on condition monitoring. Guangdong Electr. Power 2012, 11, 7–50. [Google Scholar]
- Fang, R.; Jiang, S.; Shang, R.; Wang, L. On-line evaluation cloud model of wind turbine gearbox using trend state analysis. J. Huaqiao Univ. 2016, 37, 32–37. [Google Scholar]
- Li, H.; Li, X.; Hu, Y.; Yang, C.; Zhao, B. Unequally spaced grey prediction of operating parameters of wind turbines. Autom. Electr. Power Syst. 2012, 9, 29–33. [Google Scholar]
- An, B.; Zhai, Y.; Zhao, J.; Li, H.; Hou, Y. Fault diagnosis of wind turbine gearbox based on KPCA-RVM. Comput. Eng. Appl. 2017, 53, 207–211. [Google Scholar]
- Zhen, L. Gearbox Fault Diagnosis Based on Feature Fusion of Different Information; North China Electric Power University: Beijing, China, 2014. [Google Scholar]
- Hong, Y. Fault Diagnosis of Misalignment for Transmission System of Doubly-Fed Wind Turbines Based on Stator Current; Beijing Jiaotong University: Beijing, China, 2018. [Google Scholar]
- Kang, N. Research on Misalignment Fault Diagnosis of Double-Fed Wind Turbine Transmission System; Beijing Jiaotong University: Beijing, China, 2017. [Google Scholar]
- Guo, P.; Infield, D.; Yang, X. Monitoring and analysis of temperature trend of wind turbine gearbox. Proc. CSEE 2011, 31, 129–136. [Google Scholar]
- Fu, Q. Research on Rotor Vibration Fault Diagnosis Method Based on Information Fusion; Shenyang Aerospace University: Shenyang, China, 2012. [Google Scholar]
- Jin, J.; Wu, F. Development and Prospect of Information Fusion Technology. Comput. Dev. Appl. 2006, 19, 50–53. [Google Scholar]
- Liang, J.; Yang, W.; Cai, X. Fuzzy Integration Method for Decision Fusion. J. Xidian Univ. 1998, 29, 86–90. [Google Scholar]
- Li, L. Research on Rotor Dual-Section Information Fusion and Fault Diagnosis; Zhengzhou University: Zhengzhou, China, 2009. [Google Scholar]
- Shao, R.; Hu, W.; Wang, Y.; Qi, X. The fault feature extraction and classification of gear using principal component analysis and kernel principal component analysis based on the wavelet packet transform. Measurement 2014, 54, 118–132. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, P.; Li, B.; Liu, C.; Zhang, A. Feature extraction method based on morphological spectrum of abrasive grain image. Lubr. Seal. 2011, 36, 30–32. [Google Scholar]
- Liu, H.; Yang, J.; Wang, Y. Research on acoustic target feature extraction method based on manifold learning. Acta Phys. Sin. 2011, 60, 444–450. [Google Scholar]
- Li, F.; Tang, B.; Dong, S. Fault diagnosis model based on feature reduction with orthogonal neighborhood retention. Chin. J. Sci. Instrum. 2011, 3, 621–627. [Google Scholar]
- Xia, L.; Hu, N.; Qin, G. Turbine Pump Mass Data Anomaly Recognition Algorithm Based on Manifold Learning. J. Aerosp. Power 2011, 26, 698–703. [Google Scholar]
- Gu, Y. Research on Early Fault Diagnosis Technology and System of Large Wind Turbine Gearbox; Institute of Machinery Science: Beijing, China, 2016. [Google Scholar]
- Li, Y.; Zhang, Y.; Xu, Y.; Wang, J.; Miao, Z. Image Data Set Visualization Method Based on Depth Features and Nonlinear Dimension Reduction. Appl. Res. Comput. 2017, 34, 621–625. [Google Scholar]
- Fei, C.; Ai, Y.; Wang, L.; Li, C. Research on Vibration Fault Diagnosis Technology of Aeroengine Based on Support Vector Machine. J. Shenyang Univ. Aeronaut. Astronaut. 2010, 27, 29–32. [Google Scholar]
- He, X.; Zhao, H. Support vector machine and its application in mechanical fault diagnosis. Cent. South Univ. 2005, 36, 97–101. [Google Scholar]
- Jia, R.; Xu, Q.; Li, H.; Liu, W.; Yang, K. Transformer fault diagnosis using least squares support vector machine multi-classification method. High Volt. Technol. 2007, 33, 110–132. [Google Scholar]
- Zhang, J.; Yan, Y.; Wang, S. Fault Diagnosis of Fan Gearbox Based on Wavelet Decomposition and Least Squares Support Vector Machine. Trans. Microsyst. Technol. 2011, 30, 41–43. [Google Scholar]
- Guo, H.; Liu, H.; Wang, L. Least Squares Support Vector Machine parameter selection method and its application. J. Syst. Simul. 2006, 18, 2033–2036. [Google Scholar]
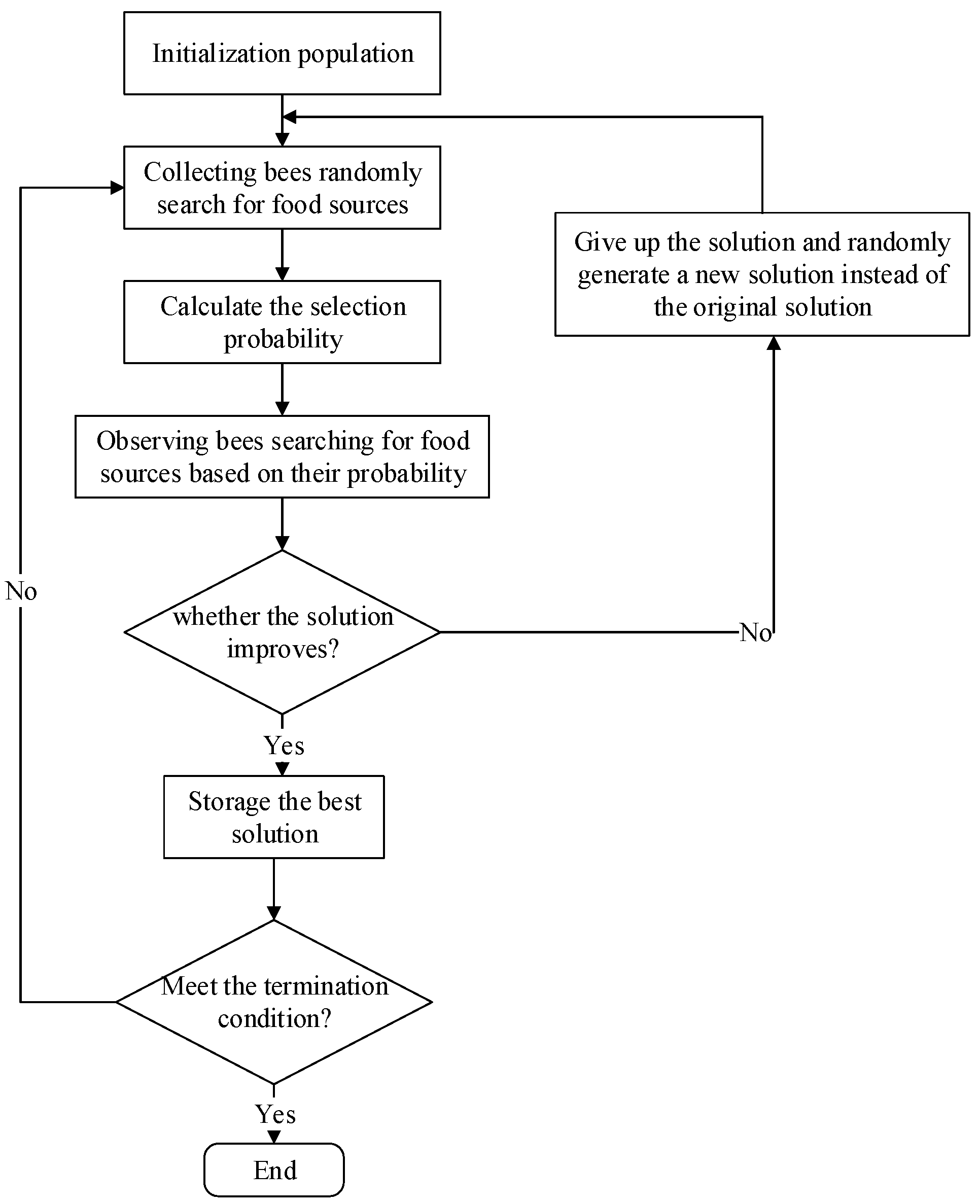
- Zhao, J. Research and Application of Swarm Intelligence Algorithm; Jiangnan University: Wuxi, China, 2010. [Google Scholar]
- Karaboga, D.; Akay, B. A Comparative Study of Artificial Bee Colony Algorithm. Appl. Math. Comput. 2009, 214, 108–132. [Google Scholar] [CrossRef]
- Yu, M.; Ai, Y. Optimization and Application of Support Vector Machine Parameters Based on Artificial Bee Colony Algorithm. Optoelectron.·Laser 2012, 23, 374–378. [Google Scholar]
- Karaboga, D. An Idea Based on HoneyBee Swarm for Numerical Optimization; Technical Report-TR06; Erciyes University: Kayseri, Turkey, 2005. [Google Scholar]
- Wang, D. Analysis and Diagnosis Technique of Misalignment Failure. Equip. Manag. Maint. 2005, 10, 29–31. [Google Scholar]
- Long, J.; Wu, J. Fault Diagnosis of Rotor Misalignment for Windmill Generators. Noise Vib. Control 2013, 33, 222–225. [Google Scholar]
- Liu, R.; Hu, S. Simulation of Misalignment of Gear Coupling Based on Virtual Prototype. Fan Technol. 2009, 2, 49–52. [Google Scholar]
- Xiao, Y.; Kang, N.; Hong, Y.; Zhang, G. Misalignment Fault Diagnosis of DFWT Based on IEMD Energy Entropy and PSO-SVM. Entropy 2017, 19, 6. [Google Scholar] [CrossRef]
- Xiao, Y.; Hong, Y.; Chen, X.; Chen, W. The Application of Dual-Tree Complex Wavelet Transform (DTCWT) Energy Entropy in Misalignment Fault Diagnosis of Doubly-Fed Wind Turbine (DFWT). Entropy 2017, 19, 587. [Google Scholar] [CrossRef]
- Zhang, G. Thermal Characteristics Analysis of High Speed Transmission System of Wind Turbines; Beijing Jiaotong University: Beijing, China, 2017. [Google Scholar]
- Kang, Y.; Wang, C.C.; Chang, Y.P. Gear Fault Diagnosis in Time Domains by Using Bayesian Networks. Adv. Soft Comput. 2007, 37, 741–751. [Google Scholar]
- Wu, S.; Liu, C.; Gao, L. Research on Fault Sensitivity Experiment of Frequency Domain Feature. Mach. Tools Hydraul. 2012, 40, 169–172. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Feature Library | Feature | Index |
|---|---|---|
| Mixed-domain feature library | Time Domain | root mean square, square root amplitude, variance, standard deviation, kurtosis, waveform index, peak index, pulse index, margin index, kurtosis index |
| Frequency domain | center of gravity frequency, mean square frequency, frequency variance | |
| Time-frequency domain | the first eight energy entropy of the IMF (intrinsic mode function) component of IEMD decomposition |
| Feature Library | Feature | Index |
|---|---|---|
| Mixed-domain feature library | Time Domain | root mean square, square root amplitude, variance, standard deviation, kurtosis, waveform index, peak index, pulse index ,margin index, kurtosis index |
| Frequency domain | center of gravity frequency, mean square frequency, root mean square frequency, frequency variance | |
| Time-frequency domain | sample entropy 1–5, energy entropy H1, H2, H3, H4, H5, spectral kurtosis a1, a2, a3, a4, a5 |
| Method | Running Time (s) | Training Set Classification Accuracy | Testing Set Classification Accuracy |
|---|---|---|---|
| LSSVM_ABC | 42.9409 | 100% (240/240) | 96.25% (154/160) |
| LSSVM_trial | 13.2171 | 97.0833% (233/240) | 93.125% (149/160) |
| LSSVM_Grid Search | 39.0374 | 100% (240/240) | 27.5% (44/160) |
| LSSVM_TUNE | 17.4725 | 95.4167% (229/240) | 93.75% (150/160) |
| LSSVM_PSO | 196.5356 | 99.1667% (238/240) | 94.375% (151/160) |
| LSSVM_GA | 66.7908 | 92.5% (222/240) | 91.875% (147/160) |
| SVM_ABC | 44.1836 | 99.1667% (238/240) | 95.625% (153/160) |
| SVM_trial | 7.5427 | 93.3333% (224/240) | 91.875% (147/160) |
| SVM_Grid Search | 38.1483 | 98.3333% (236/240) | 94.375% (151/160) |
| SVM_TUNE | 23.7067 | 98.3333% (236/240) | 93.75% (150/160) |
| SVM_PSO | 43.4475 | 95.8333% (230/240) | 93.75% (150/160) |
| SVM_GA | 40.9686 | 100% (240/240) | 72.5% (116/160) |
| BP (Back Propagation) neural network | 33.1814 | 82.5% (198/240) | 81.875% (131/160) |
| Method | C | σ |
|---|---|---|
| LSSVM_ABC | 3.1355 | 4.4392 |
| LSSVM_trial | 10 | 1 |
| LSSVM_Grid Search | 0.7071 | 0.0884 |
| LSSVM_TUNE | 1.0143 | 232.1482 |
| LSSVM_PSO | 58.2596 | 99.6819 |
| LSSVM_GA | 9.1064 | 479.2951 |
| SVM_ABC | 3.14 | 4.4384 |
| SVM_trial | 1 | 0.01 |
| SVM_Grid Search | 1.4142 | 0.0884 |
| SVM_TUNE | 2.639 | 0.0544 |
| SVM_PSO | 5.4266 | 0.01 |
| SVM_GA | 15.8506 | 82.3615 |
| Signal Selection | Running Time (s) | Training Set Classification Accuracy | Testing Set Classification Accuracy |
|---|---|---|---|
| Vibration signal | 43.6846 | 100% (240/240) | 85.625% (137/160) |
| Temperature signal | 43.0802 | 90.8333% (218/240) | 81.25% (130/160) |
| Electrical signal | 43.1965 | 99.5833% (239/240) | 84.375% (135/160) |
| Vibration signal + temperature signal | 43.1038 | 100% (240/240) | 93.75% (150/160) |
| Vibration Signal + Electrical Signal | 43.5408 | 100% (240/240) | 88.75% (142/160) |
| Temperature signal + electrical signal | 43.0321 | 100% (240/240) | 95% (152/160) |
| Three signals | 42.9409 | 100% (240/240) | 96.25% (154/160) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Wang, Y.; Ding, Z. The Application of Heterogeneous Information Fusion in Misalignment Fault Diagnosis of Wind Turbines. Energies 2018, 11, 1655. https://doi.org/10.3390/en11071655
Xiao Y, Wang Y, Ding Z. The Application of Heterogeneous Information Fusion in Misalignment Fault Diagnosis of Wind Turbines. Energies. 2018; 11(7):1655. https://doi.org/10.3390/en11071655
Chicago/Turabian StyleXiao, Yancai, Yujia Wang, and Zhengtao Ding. 2018. "The Application of Heterogeneous Information Fusion in Misalignment Fault Diagnosis of Wind Turbines" Energies 11, no. 7: 1655. https://doi.org/10.3390/en11071655
APA StyleXiao, Y., Wang, Y., & Ding, Z. (2018). The Application of Heterogeneous Information Fusion in Misalignment Fault Diagnosis of Wind Turbines. Energies, 11(7), 1655. https://doi.org/10.3390/en11071655