1. Introduction
Although countries have actively implemented Nationally Determined Contributions (NDCs) to alleviate climate deterioration in recent years, global greenhouse gas emissions are still in the process of continuous growth, and there has not yet been a peak phenomenon. In order to control the future temperature rise within 1.5 °C, the United Nations Environment Programme advocates that countries around the world should reduce the emissions to fill the gap between the current greenhouse gas emissions level and the Paris Agreement provisions [
1]. The transformation of energy structure is regarded as the primary way for emissions reduction by all countries. Many countries have formulated plans to build a high-penetration renewable energy source (RES) system, which fully releases the high environmental and economic value of renewable energy by replacing fossil energy [
2,
3]. There are two main challenges in the RES system construction. One is to solve the time and space uncertainties caused by the intermittency of renewable energy [
4], and the other is to optimize the network structure for large-scale renewable energy integration [
5]. The transmission network expansion planning (TNEP) is the crucial task of power system construction, which determines the basic structure and system characteristic. Therefore, the characteristics of system with high-penetration of RES should be fully considered in the TNEP task on the basis of ensuring system stability and economy.
In a high-penetration RES system, as general generators are gradually replaced by renewable energy, the increase in the penetration rate of renewable energy makes the system operation state more diversified [
6,
7], and the uncertainties of the load-side and the source-side are also amplified. The TNEP task of a high-penetration RES system should first obtain the description of the renewable energy uncertainty. The uncertainty description is mainly obtained through the scenario generation method based on probabilistic power flow and the representative days method based on system operating data. The scenario generation method does not require a large amount of operation data. It abstracts the characteristics of renewable energy and variable load fluctuations, and appropriately estimates operation data according to task requirements. In reference [
8], the uncertainty of renewable energy and demand resources (DR) was decomposed by robust optimization theory according to the robust intervals on multiple timescales, and the modeling method was selected in conformity with the characteristics of each component to form the uncertain model. Furthermore, the relationship between DR and RES was considered in uncertain model to form a multi-energy hub in [
9]. References [
9,
10] established a model based on the uncertain characteristics of renewable energy, and studied the electricity market trading strategy of the RES system. The scenario generation method is intuitive and practical, which can greatly speed up the problem-solving. However, the accuracy of the uncertainty description of regional equipment is extremely important in the TNEP tasks [
11]. Therefore, more and more studies have turned to constructing uncertain models from operation data. Reference [
12] studied the relationship between the system’s renewable energy penetration rate and typical operating conditions based on a data-driven method, and verified that when the penetration rate increases from 20% to 40%, the system typical states will increase 4 times. Reference [
13] improved the K-Means algorithm by taking the maximum and minimum output of renewable energy as the classification condition, and the classified representative days data is more in line with the needs of the TNEP task. In addition, the duration curve of renewable energy was also used to generate the uncertain model, and the multiple typical scenario duration curves were generated according to seasons, times, weather conditions and demand levels in reference [
14]. Therefore, this paper will use the system operation data to construct the uncertain model of renewable energy and variable load to assist the TNEP task solving, and use the data compression method to maintain the efficiency of the calculation while retaining the main characteristics of the uncertain model.
The huge uncertainties of the source-side and the load-side in the system with high-penetration of RES make the power shortage more frequent [
15]. The transmission stability in a wide area cannot be maintained only by the local balance of power generation and load. It is also necessary to build a more compact transmission network structure through TNEP task to release the potential of power support among various renewable energy sources [
16]. The construction of the TNEP model of the system with high-penetration of RES should fully consider the uncertain characteristics of renewable energy and variable loads, and improve the stability of system in the most economical way. Reference [
17] proposed a two-stage model of TNEP and the renewable energy generation expansion planning (REGEP), which can coordinate system stability and renewable energy consumption in complex situations. On this basis, the system outages and post-contingency control were added to construct a five-level model in reference [
18]. For some special scenarios, environmental conditions are also used as part of the TNEP model to assist decision-making. For example, reference [
19] constructed an offshore grid planning model based on the typical connection structure of offshore wind farms. The comprehensive TNEP model can ensure that the planning scheme meets the various requirements of network construction. The solution of traditional TNEP model is a complex and large-scale mixed-integer linear programming (MILP) problem [
18], and many studies have focused on improving the solution efficiency. The Benders decomposition method was adopted to reduce the complexity of model in references [
20,
21]. Furthermore, combining Benders decomposition method with the Column-and-Constraint generation method, reference [
22] proposed a better method to obtain the planning scheme with high reliability and economy for RES system. In addition, the primal cutting planes algorithm was also used to accelerate the TNEP solution in reference [
23]. With the increase in the scale of the system with high-penetration of RES and the nonlinear constraints of the TNEP model, the traditional decomposition method has encountered a bottleneck, which makes the heuristic-learning based method a more convenient way to obtain planning scheme. Reference [
24] used the improved Particle Swarm Optimization (PSO) to solve the multi-objective TNEP model, which contains the security and uncertain constraints of photovoltaic power farms. Reference [
25] separated the cost problem from the investment problem in TNEP model, and solved them by PSO and quadratic programming (QP) methods, respectively. In addition, under the uncertain scenario, the shuffled frog leaping algorithm (SFLA) was adopted to process the TNEP task, which obtained a better scheme than PSO in reference [
26]. Although the heuristic learning-based method can solve TNEP problem more quickly than decomposition methods, the black box characteristic of such methods makes the solution process interpretability extremely low. At the same time, it requires thorough retraining for different tasks, which wastes time. Deep reinforcement learning is currently an advanced technology, and it is widely used in power system load frequency contortion, flow adjustment, and AGC power order optimization in references [
27,
28,
29]. However, the application of deep reinforcement learning to the TNEP tasks is still in the early stage. Reference [
30] adopted Deep Q Network (DQN) to solve the TNEP model based on the static system. Nevertheless, when undertaking the TNEP tasks for the system with high-penetration of RES, the deep reinforcement learning environment should contain more uncertain characters of wind power and variable load. Moreover, the reinforcement learning structure should be redesigned accordingly to satisfy more complex model solving.
The contributions of this paper are listed below:
A K-means algorithm that enhances the extraction quality of variable wind and load power uncertain characteristics is proposed. The proposed method considers the accumulation and change rate of operational data.
A calculation method of wind curtailment and load shedding that reduces the computational complexity while retaining the uncertainty of the system is proposed. The calculation method is based on the typical uncertain scenarios extracted from operation data.
A TNEP bi-level model considering the system stability and economy is constructed, and this model includes the comprehensive cost, wind curtailment, load shedding, and electrical betweenness.
Multi-agent DDQN is proposed based on the bi-level model, which is a high-performance and interpretable machine learning method for the TNEP task.
This paper is organized as follows:
Section 2 constructs the bi-level TNEP model to consider the wind power and load uncertainties.
Section 3 builds the multi-agent DDQN for TNEP task based on deep reinforcement learning.
Section 4 takes multi-agent DDQN to complete TNEP tasks on modified IEEE 24-bus system and New England 39-bus system.
2. TNEP Bi-Level Model Based on Typical Scenarios of Wind Power and Load Uncertainties
This section constructs a TNEP bi-level model considering the system stability and economy based on uncertain scenarios. First, the typical uncertain scenarios of wind power and load data are extracted based on the improved K-Means algorithm. Secondly, based on the extracted results, a TNEP bi-level model is constructed. This model can comprehensively evaluate the economic and stability of transmission network under the scenario of a high-penetration of wind power and variable load.
2.1. Improved K-Means Algorithm Based on Characteristics of Wind power and Load Operation Data
The output power of a wind farm is closely related to the regional weather, and the load-side behavior also makes the input power of the load variable. The system with high-penetration wind farms and variable load injection face high uncertainties at the source-side and load-side, which greatly affects the stability of the RES system. In the system to be expanded, there are many combinations of wind farm output power and load input power recorded in historical operating data, and it is unrealistic to consider each scenario in the TNEP task. Therefore, this paper uses the improved K-Means algorithm to extract typical scenarios, which saves a lot of calculation time for TNEP task while preserving the system uncertainty.
K-Means algorithm is an intuitive and efficient clustering method based on the distance of data samples. Additionally, when applied to the classification task of large data sets, its performance is still excellent.
When the K-Means algorithm is used to extract typical scenarios from operating data, the K value should be given first to determine K cluster centers. Then, through iterative optimization of K cluster centers, the sum of the distances between the classified samples and each cluster center is minimized. The traditional sum of the squared errors (SSE) is
where
x is the operation data;
δ is the operation data set;
Cn is data of cluster center.
However, when traditional SSE is used for clustering task, its morphological-based clustering objective cannot fully reflect the fluctuation characteristics and accumulation of operation data, which are quite critical for the TNEP task. Therefore, this paper proposes to adopt accumulation and change rate as indicators to measure the data uncertainty, and then use these two indicators as clustering objective to improve the quality of clustering data.
The cumulation of operation data
Dcumulative is
where
dh is value of operation data at
h-th hour, and the change rate of operation data
Dchange is
where
drated is the rated value of operation data;
dh−1 is value of operation data at
h − 1-th hour.
Based on (2) and (3), the clustering objective function
SSEnew of improved K-Means algorithm is
where
Dcumulative,x is the cumulation of operation data
x;
Ccumulative,n is the cumulation of clustering center
n;
Dchange,x is the change rate of operation data
x;
Cchange,n is the change rate of clustering center
n.
2.2. Bi-Level Multi-Objective TNEP Model
The TNEP task of the RES system is a multi-objective problem. It needs to coordinate economy and stability. In addition, the uncertainties of the system under large-scale wind power and variable load should also be considered. Therefore, this section constructs a bi-level model based on the nature of the transmission network evaluation index, and each layer model is composed of objective function and constraints.
2.2.1. Upper-Level Objective Function
The upper-level model uses the comprehensive cost to evaluate the economy of the system. The comprehensive cost is composed of construction cost, network loss cost, and operation and maintenance cost. The construction cost
f1 of the TNEP task is formed by the uniform annual investment of transmission lines.
where
rd is the capital discount rate of line;
y is the life expectancy of line;
NL is the total number of lines;
λl is the line construction state;
Xl is the construction investment of line
l.
The transmission network loss refers to the power loss in the form of heat energy during the power transmission, the transmission network loss cost
f2 is
where
Pl is the active power of line
l in AC rectangular;
Ql is the active power of line
l in AC rectangular;
Ul is the voltage of line
l in AC rectangular;
ploss is the unit electricity price of network loss.
The operation and maintenance cost of the transmission network should consider the equipment of line and transformer. However, the transformer operation and maintenance cost is related to the load rate, and the parameters and transmission power of each transformer in the IEEE RTS-24 bus system are almost equal. Therefore, the transformer operation and maintenance cost have little effect on the scheme choice. The system operation and maintenance cost
f3 is
where
ηl is the line operation and maintenance cost coefficient.
The calculation of upper-level objective function is based on the AC power flow method, which can describe power flow characteristics more accurately than the DC power flow method used in traditional TNEP methods. The
fupper(·) is
2.2.2. Upper-Level Constraints
The upper-level constraints are mainly composed of power transmission and equipment operation constraints. The AC power flow balance constraints are
where
is the generator rated active power output of node
j;
is the wind curtailment active power of node
j;
Vj is the voltage of node
j;
Bjk is the susceptance between node
j and node
k;
G is the conductivity between node
j and node
k;
θjk is the phase angle between node
j and node
k;
is the load active power input of node
j;
is the load active power shedding of node
j;
is the generator reactive power output of node
j;
is the reactive power input of node
j;
is the wind curtailment reactive power of node
j;
is the load reactive power of node
j;
is the reactive power of reactive power compensation device of node
j.
The voltage amplitude and phase angle constraints are
where
and
are the maximum and minimum of voltage of node
j;
and
are the maximum and minimum of phase angle of node
j.
Because wind farm has strong reactive power regulation capability, this paper does not make a special constraint. The wind power and general generator output constraints are
where
and
are the maximum and minimum of generator active power output;
and
is the maximum and minimum of generator reactive power output;
and
is the maximum and minimum of wind active power output.
The line transmission capacity constraint is
where the
Fl is the power flow of line
l;
is the power flow transmission maximum line
j.
The wind curtailment constraint is
where
μwind,j is the minimum output ratio;
is the wind active power curtailment of lower-level model.
The load shedding constraint is
where
μload,j is the minimum load ratio;
is the load activate power shedding of lower-level model;
is the wind active power curtailment of lower-level model.
2.2.3. Lower-Level Objective Function
The lower-level model is based on typical uncertain scenarios. It evaluates renewable energy consumption of system through load shedding and wind curtailment calculations, and the system stability is evaluated by the improved electrical betweenness. Based on the bi-level model structure, the upper-level model obtains a Pareto set composed of better economical lines, and the lower-level model only needs to calculate the scheme in this set. Then, the upper-level model further optimizes the TNEP scheme after receiving the calculation results of lower-level model. This mechanism satisfies the constraints between the bi-level models and improves the computational efficiency.
The transmission network is a real-time balance system, but high-penetration wind power and variable load will affect this balance. Hence, when the wind farm output power is greater than the maximum absorbable power of the system or the adjacent lines of the wind farm do not have enough capacity to transmit the power flow, the excess wind power needs to be curtailed to ensure the balance. On the contrary, when the system load power exceeds the sum of the power of wind farm and the general generator set or the adjacent lines of load node are blocked, the excess load will be shed.
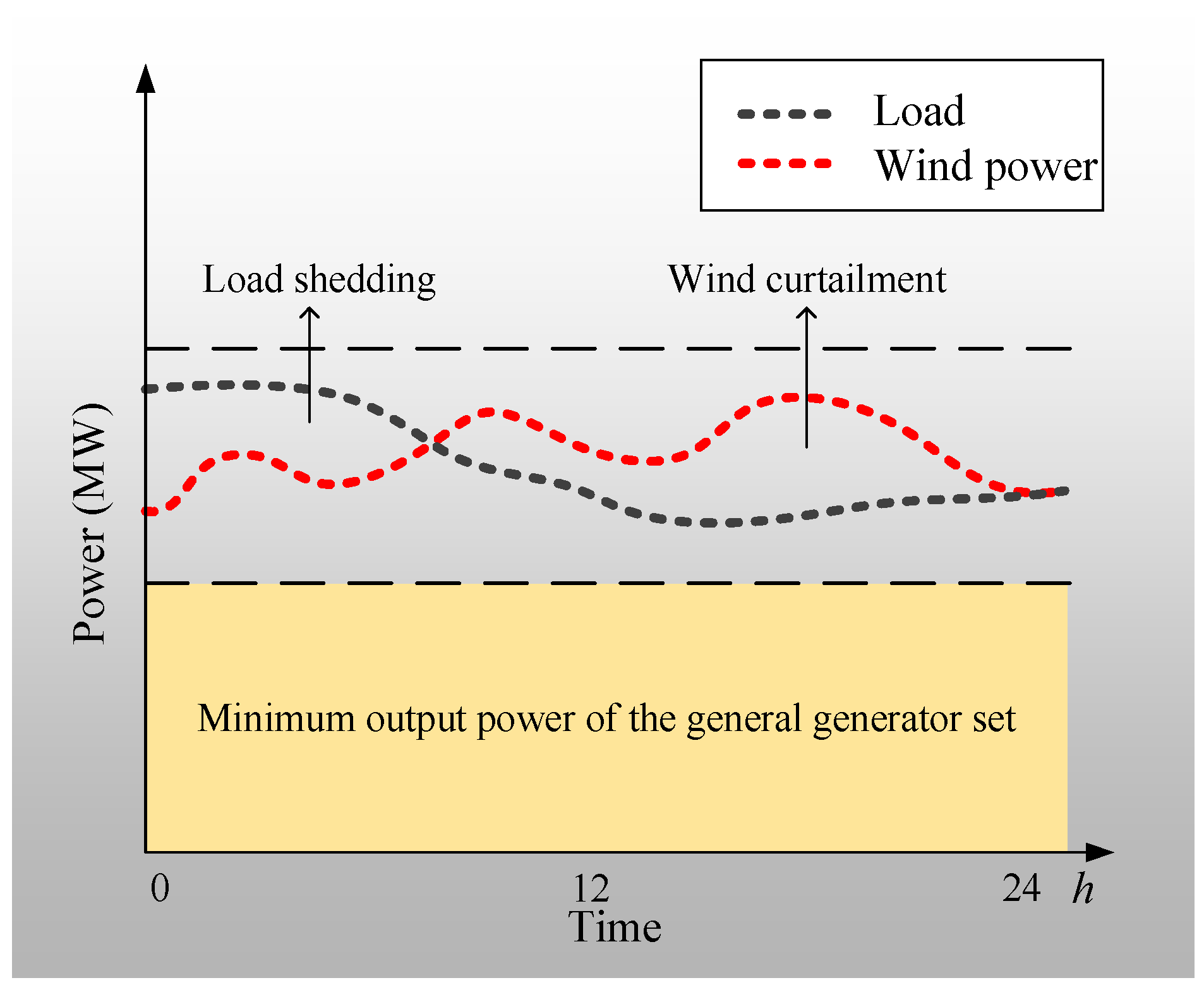
Figure 1 is the schematic diagram of wind curtailment and load shedding.
We set priority wind power output conditions to ensure the maximum wind power consumption. Therefore, the wind curtailment is determined by the load and the minimum output of general generator set. The wind curtailment of each hour
is calculated by
where
Nwind is the total number of wind farms;
is the sum of the output of wind farm at
h-th hour;
is the sum of the minimum output of general generator set at
h-th hour;
is the sum of the input of load at
h-th hour.
The total wind curtailment of each scenario
is
The load shedding of each hour
is
where
is the maximum output of general generator set
j at
h-th hour.
The total load shedding of each scenario
is
The wind curtailment and load shedding can evaluate the operation economy of system structure under uncertain scenarios. However, the high-penetration wind power and variable load may cause the line with excessive power flow to be cut off, which will lead large-scale power flow transfer and even cause a cascading failure. We propose to apply the improved electrical betweenness to measure system power flow balance in uncertain scenarios, and use it to evaluate the system stability.
The stability evaluation of the transmission network based on the electrical betweenness integrates the power flow characteristics into the topology analysis. This method uses electrical betweenness to indicate the transmission power of each line in multiple scenarios, and the large electrical betweenness means that the line is more important in the power flow transmission. When it is forced to be cut off, the system will be severely affected. Therefore, it is necessary to balance the power flow transmission by constructing new lines to improve the system’s ability to withstand uncertainties of wind power and variable load.
The electrical betweenness is based on two assumptions:
Assumption (a): The line power flow is a linear additive model, and the line transmission capacity is shared by each generator set and load.
Assumption (b): The power flow transmission occurs in any line between the generator set and the load.
The calculation of electrical betweenness first requires the system to be divided into a combination of a single generator set and a single load. Then, the combination is required to transmit unit power with the complete line structure. The active power flow
Pl,unit and reactive power flow
Ql,unit of line
l under transmitting unit power are
where
Vj,unit and
Vk,unit are the voltage of node
j and node
k under transmitting unit power;
Gj0 is the conductivity between node
j and ground points;
Bjk is the susceptance between node
j and node
k under transmitting unit power.
Second, the coefficient
ω of unit power flow is determined by the smaller value of the generator set and load in the selected combination. The unit power coefficient is calculated by
where
and
are the power of variable load and constant load.
Third, all combinations in the system should be traversed, and the electrical betweenness of lines can be obtained from the sum of the unit power flow distribution. The electrical betweenness (
EB) is
where Φ is the combination set;
s is a combination of one source and one load.
The (26) can compare the power flow of each line in the system, but it is difficult to intuitively calculate the power flow balance of the system. Therefore, this paper proposes to use the Wasserstein distance to measure the uniformity of electrical betweenness distribution.
The Wasserstein distance measures the similarity of two distributions by calculating the distance between two distributions. In this paper, the Wasserstein distance between the electrical betweenness distribution and the absolute equilibrium power flow
EBbalance distribution is used to evaluate the power flow balance of the transmission network. Additionally, the power flow Wasserstein distance
Wass(
EB) is
where inf means infimum; Π(
EB,
EBbalance) represents the set of all possible joint probability distributions of
EBl,h and
EBbalance; ‖A‖ is any norm of A.
The lower-level objective function needs to improve the system’s renewable energy consumption capacity while ensuring that the system has a small improved electrical betweenness. Therefore, the lower-level objective function
flower(·) is
2.2.4. Lower Constrains
The lower-level constraints are similar to the upper-level constraints, and they are
The solution of this model is to find a transmission network structure that meets various constraints and maximizes the performance of the objective function. The method based on deep reinforcement learning determines the construction value of each line based on Markov decision to realize the TNEP task. The method based on heuristic learning achieves the optimization goal by iterating the overall transmission network structure, while business optimizer such as CPLEX is based on mathematical planning to solve the task model.
4. Simulation and Verification
In this section, we apply the multi-agent DDQN to solve the multi-scenarios TNEP tasks of system with high-penetration of RES. The planning scheme and solution process of multi-agent DDQN are compared with those of DQN, particle swarm optimization (PSO) and branch-and-bound (B&B) in the modified IEEE RTS-24 bus system and the modified New England 39-bus system.
4.1. Modified IEEE RTS-24 Bus System with High-Penetration RES
The IEEE RTS-24 bus system is widely used to evaluate the performance of planning algorithms. This model contains 24 generator or load buses. The initial network consists of 38 lines with two rated voltages, the north area is 220 kV and the south area is 110 kV. The load model contains 17 buses with a maximum of 2850 MW. The generation model contains 32 generator sets, and the range of the output is 12–400 MW.
Based on the IEEE RTS-24 bus system, a modified IEEE RTS-24 bus system is constructed, in which the types of some generator sets and loads are changed to make the system have the characteristics of renewable energy and variable load. The changes are listed in
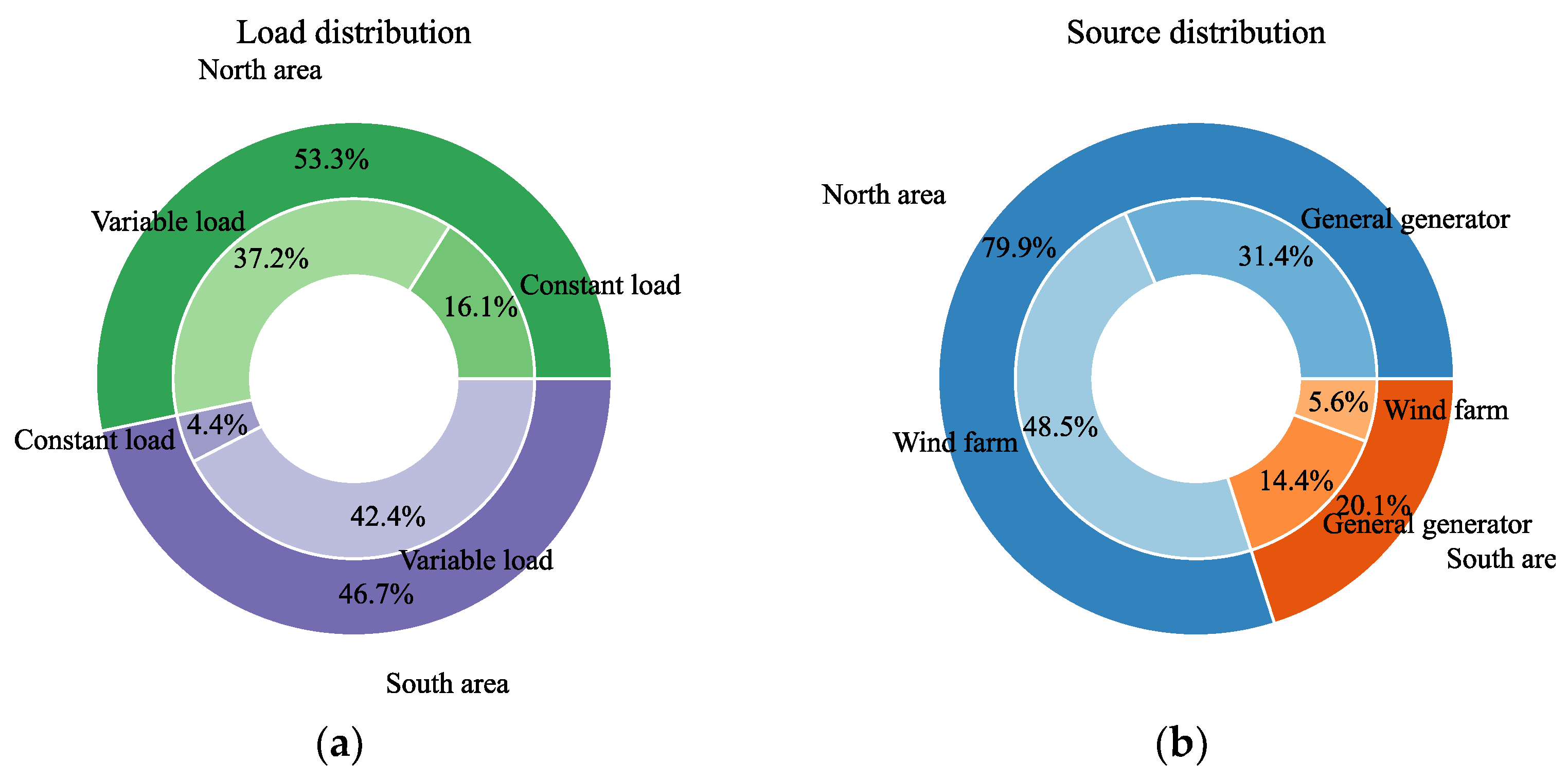
Table 2, and the distribution of generator set and loads is shown in
Figure 5.
It can be seen from
Figure 5 that the modified system contains 54.1% renewable energy and 79.6% variable load, which simulates the high-penetration renewable energy and variable load characteristic of RES system.
Then, we use the improved K-Means algorithm to extract the typical scenarios. Its performance is not only related to the setting of the clustering objective function, but also closely related to the K value. We use the improved K-Means algorithm to cluster the variable wind power and load operation data of HRP-38-test-system in reference [
31], and the best K value is determined from the curve of SSE based on the elbow method. The results are shown in
Figure 6.
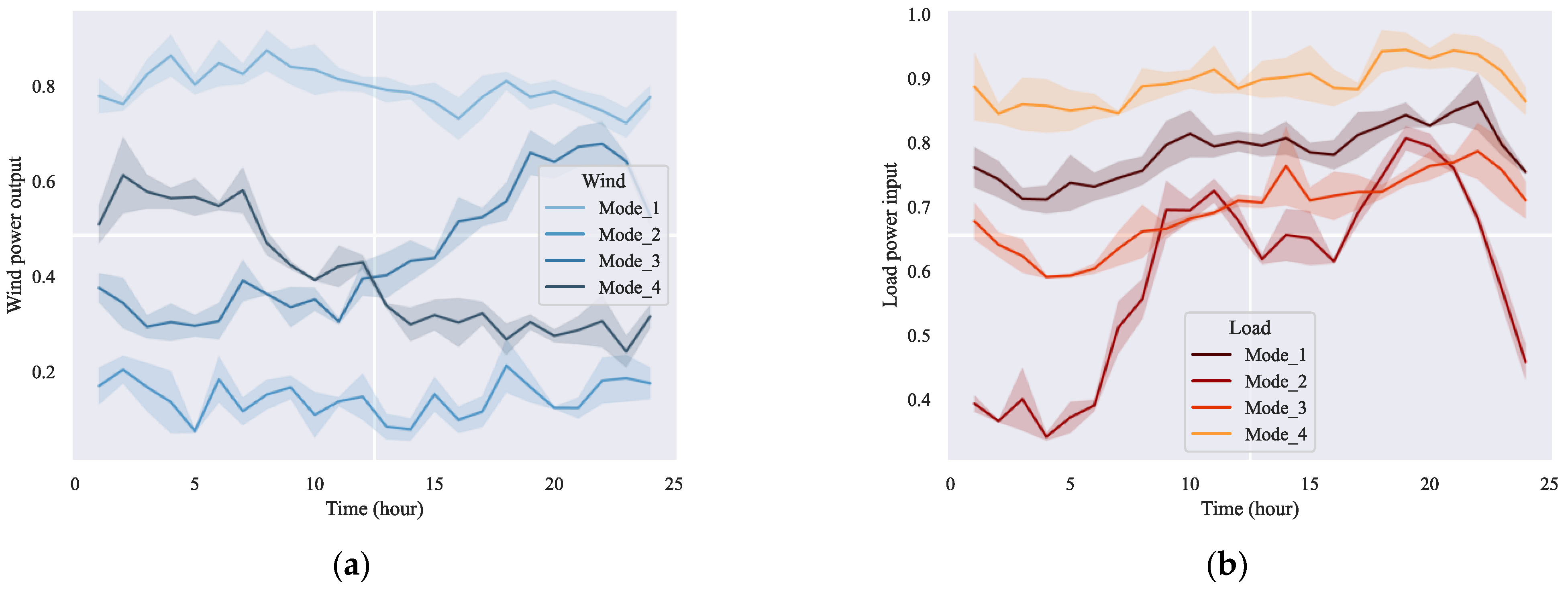
The results show that the SSEs of wind power and variable load decreases faster when K value becomes K = 4. If K continues to increase, the change rate of SSE will decrease, which can be considered as an elbow point. Therefore, this paper adopts K = 4. The clustering results are shown in
Figure 7.
Figure 7a shows the four operating modes of wind power. Mode 1 and mode 2 are distinguished by the difference in cumulative energy. Mode 3 and mode 4 have similar cumulative energy, but the fluctuation characteristics are different. Similarly, in
Figure 7b, the cumulative energy of load 1, 3, and 4 modes are different, and the fluctuation characteristics of mode 2 are more unique. Therefore, the improved K-Means algorithm realizes the operation data compression of wind power and variable load, which greatly improves the efficiency of TNEP task solving.
The scenario generation rule is to randomly select the wind farm and load status in each hour from the extracted mode as the system status and then generate 384 typical scenarios. Some typical scenarios are listed in
Table 3.
The typical scenarios cover the normal and extreme conditions during the system operation. This data-driven scenario generation method reduces computational complexity and ensures the uncertain characteristic.
4.2. TNEP for Multi-Level Renewable Energy Penetration Scenarios in Modified IEEE RTS-24 Bus System
All the programs are developed using TensorFlow 1.14 and python 3.7. The system configuration is i9-9900K with 3.6 GHz, a memory of 32 GB, and graphics card of 2080Ti. DQN and PSO are used for contrast, and the parameters of multi-agent DDQN and DQN are listed in
Table 4. The TNEP schemes of four methods are shown in
Table 5,
Table 6,
Table 7 and
Table 8, and the transmission network structure is in
Figure 8.
Table 5,
Table 6,
Table 7 and
Table 8 show that all four methods optimize the stability and economy of the transmission network by constructing lines. The deep reinforcement learning based methods contain line sequence information, but PSO method only optimizes the structure of the complete transmission network structure. Among the four schemes, the scheme obtained by multi-agent DDQN has the lowest construction cost at USD 6.95 M. Due to the scheme obtained by DQN includes the line 9–12, which contains a set of transformers, the construction cost is the highest at USD 10.58 M. In addition, the four schemes all affect the system structure and the distribution of power flow through new lines construction, which decreases the network loss cost. Finally, the objective function of the upper-level model is to minimize the comprehensive cost. The comprehensive costs of four methods are USD 18.8 M, USD 22.72 M and USD 19.31 M, USD 22.36 M, respectively. The scheme obtained by multi-agent DDQN has the lowest comprehensive cost, which proves that the one set DDQN agent built by the upper-level layer is better than DQN agent in the optimization of comprehensive cost indicators.
The improved electrical betweenness measures the system stability by calculating the power flow balance of each line. The scheme obtained by multi-agent DDQN reduces the improved electrical betweenness from 0.007154 to 0.004457, which reduces the probability of cascading failures than other three methods. In addition, system with high-penetration of RES needs to ensure as little wind curtailment and load shedding as possible under uncertain scenarios. Both multi-agent DDQN and DQN improve the power support capability through building a tighter transmission network structure. However, the scheme obtained by PSO is over-searching for a structure with better comprehensive cost performance, and it ignores the optimization of the improved electrical betweenness, wind curtailment and load shedding. This is because the heuristic learning-based method is easy to fall into the local optima problem in TNEP task solving processing. TNEP is a complex non-convex non-deterministic polynomial (NP) problem. The scheme obtained by B&B still has a certain gap with the other schemes obtained by three methods. The methods based on deep reinforcement learning well coordinates the optimization of the lower-level model indicators, which avoids the impact of the local optima problem to a certain extent, and confirms the superiority of this type of methods in this task.
Although the sum of the wind curtailment and the load shedding are nearly equal for scheme obtained by DQN and multi-agent DDQN, the improved electrical betweenness of multi-agent DDQN is significantly better. The dual DDQN agent structure improves the optimization capability of each layer, and thus forming a better solution method for TNEP task.
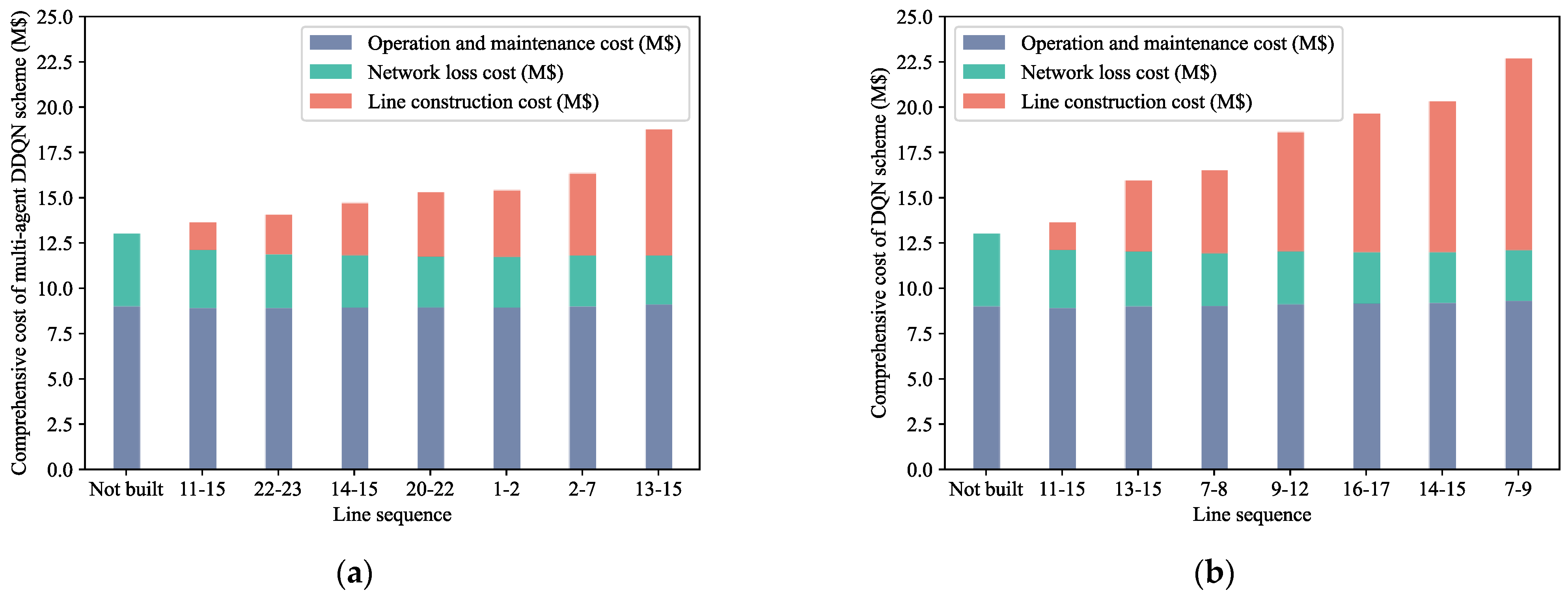
Figure 9 shows the comprehensive cost changes of the schemes obtained by multi-agent DDQN and DQN. The construction cost of lines 13–15, 9–12, and 7–9 in the DQN scheme is relatively high, which makes the construction cost rise rapidly. The scheme obtained by multi-agent DDQN chooses lines with lower construction cost, so that the investment in the scheme implementation can be invested more smoothly. Moreover, the sum of network loss cost and operation and maintenance cost of scheme obtained by multi-agent DDQN are decreasing faster, which makes the transition process more economical.
Figure 10 is the distribution of line power flow for the two methods. It shows that the initial power flow is quite uneven, and the power flow of the initial network contains three lines with more than 300 MW and two lines more than 400 MW. The scheme obtained by multi-agent DDQN transfers part of the power flow to underloading lines, which improves the utilization rate of the underloading lines and reduces the probability of the cascading failures caused by the overloading lines. For the lines with power greater than 200 WM in
Figure 10b, the multi-agent DDQN controls the line power flow close to 250 MW. The scheme obtained by DQN reduces most of the line power flow to below 250 MW, but it contains two lines that are much larger than 250 MW. For the lines with power lower than 200 MW, multi-agent DDQN optimizes the power flow distribution in the range of 150~200 MW better than DQN method. DQN better increases the power flow of underloading lines, and multi-agent DDQN tends to limit the power flow of overloading lines. The lines with high power flow often determine the stability of the system. Therefore, the scheme obtained by multi-agent DDQN has higher system stability.
Figure 11 shows the changes in wind curtailment and load shedding during the construction of the two schemes.
The initial network structure sheds a mass of load under uncertain scenarios. When the output of wind farms is reduced, the regional power balance ability is weakened, and the power support from power generators and wind farms in the other regions of the system is needed to supplement the regional power shortage. However, when the congestion occurs in transmission lines connected to the power shortage area, the power support in the system is difficult to achieve, which forces load shedding. Therefore, it is necessary to build new lines to eliminate the occurrence of congestion. The two schemes obtained by multi-agent DDQN and DQN both reduce the load shedding to the same level through new lines construction, and multi-agent DDQN is decreasing slightly faster than the scheme obtained by DQN. The wind curtailment of the multi-agent is lower than the scheme obtained by DQN, more wind power will be curtailed during the construction process.
Multi-agent DDQN not only controls the sum of wind curtailment and load shedding as DQN, but also obtains a scheme with high power flow balance. This demonstrates that one set DDQN agent built by lower-level model has better performance than DQN agent for lower-level optimization. Therefore, the dual DDQN agent structure realizes the hierarchical prediction value of line. One set is used to search the lines with high economy, and the other set is to search the lines that can improve the renewable energy consumption capacity and stability of the system. This structure improves the accuracy of the line value prediction and contributes to the formation of a better TNEP scheme.
Figure 12 and
Figure 13 are the indicators (such as wind abandonment and load shedding) of 7000 network structures constructed by the multi-agent DDQN agent in 200 episodes of training. Before 1000 steps, the distribution of various indicators in poor areas is more concentrated, or only some indicators of the network perform well. This is because the multi-agent DDQN does not have enough data for neural network training now, and there is a large error in its value prediction. Between 1000 and 2500 steps, the indexes of the transmission network gradually improve. The neural network achieves sufficient training, and the prediction error of the line construction value has gradually decreased. After 2500 steps, the indexes are uniformly distributed between the best and the worst. This is because the multi-agent DDQN adopts a
ε-greedy strategy, which allows the agent to chooses the line randomly without using the prediction result of the neural network under a certain probability. This training mechanism can prevent local optimal problem and obtain more accurate value function.
Figure 14 shows the sum of value prediction of multi-agent DDQN and DQN. The value prediction represents the estimation of the construction value estimation of different lines by the agent, and the sum of value prediction of the multi-agent DDQN is lower than that of the DQN. This is because the agent of multi-agent DDQN adopts a dual neural network structure, which makes the optimal line
Amax independent of the value prediction
Qmax of the optimal line. This structure avoids the influence of accidental overestimation to a certain extent and improves the accuracy of line value prediction, which enhances the ability of multi-agent DDQN to solve TNEP task.
4.3. TNEP under Unavoidable Interference in Modified IEEE RTS-24 Bus System
During the implementation of the TNEP scheme, unavoidable interference or unconsidered factors may cause a certain line to be unable to be constructed. When this happens, the heuristic learning-based method requires retraining due to changes in planning conditions. However, the experience obtained from training based on the reinforcement learning method is to judge the construction value of each line, which is not affected by changes in conditions. Thereby, multi-agent DDQN can solve new TNEP tasks without redundant training. We change the fourth line of the scheme obtained by multi-agent DDQN from 20–22 to line 5–6 to simulate the TNEP task scenario under unavoidable interference. Similarly, the fourth line of the scheme obtained by DQN is changed from 9–12 to line 13–14. The schemes obtained by multi-agent DDQN and DQN are shown in
Table 9 and
Table 10.
After the interference, the improved electrical betweenness of the scheme obtained by multi-agent DDQN immediately deteriorates, and the wind curtailment and load shedding are hardly improved. This shows that the line 5–6 causes the system power flow balance to be destroyed, and the scheme is greatly affected by the interference. On the contrary, although the improved electrical betweenness of the scheme obtained by DQN slightly deteriorates after the interference, the line 13–14 reduces the wind curtailment and load shedding. The continued construction of multi-agent DDQN after unfavorable interference is more positive. The multi-agent DDQN agent reuses training experience to judge the performance of the current transmission network structure and the construction value of each line. Then, three high-value lines are selected to form the new scheme. Although the new scheme obtained by multi-agent DDQN increases the comprehensive cost under unfavorable interference, it still shows great performance in the improved electrical betweenness, wind curtailment and load shedding. The comprehensive cost of scheme obtained by new DQN is USD 0.45 M, which is higher than that of the new scheme obtained by multi-agent DDQN. In addition, the improved electrical betweenness of the new scheme obtained by DQN is also larger than that of the new scheme obtained by multi-agent DDQN, which means the new scheme obtained by DQN has lower reliability of the system. Even the excellent control of wind curtailment and load shedding in the scheme obtained by original DQN is weakened. Finally, both methods can complete planning tasks by reusing the training experience under the unavoidable interference, but the value prediction of multi-agent DDQN is more accurate, which makes the multi-agent DDQN better to solve such TNEP tasks.
4.4. TNEP in Modified New England 39-Bus System
This article extends the application scenario to a more complex modified New England 39-bus system to further evaluate the performance of the proposed methods. Consistent with the changes in the modified IEEE 24-bus system, we increase the load to 1.1 times, the capacity of conventional generator sets to 1.2 times, and the capacity of wind farms to 1.4 times. The node settings of wind farm and variable load are shown in
Table 11, the schemes of the four methods are shown in
Table 12,
Table 13,
Table 14 and
Table 15, and the network structure is shown in
Figure 15.
The generator sets of the modified New England 39-bus system are settled at the edge of the system, but the load nodes are evenly distributed. Under the uncertain scenarios, the initial network structure cannot deliver wind power to the system due to the line blockage, and the system curtails a large amount of wind power. Therefore, the three methods all need to optimize the wind farm adjacent line structure to improve the power transmission capacity under uncertain conditions. The scheme obtained by multi-agent DDQN focuses on optimizing the network structure near node 30 connecting the largest capacity wind farm by adding six new lines (2–30, 1–2, 2–3, 3–4, 3–18, 17–18). In addition, the construction of line 10–32 also raises the upper limit of the transmission capacity of the node 32 wind farm. Although the schemes obtained by DQN and the PSO optimize the node 30 adjacent line structure, their ability to select key lines is still insufficient. The scheme obtained by DQN only optimizes the lines within the distance between two lines near node 30, but it does not further optimize the structure with longer distances. The PSO and CPLEX optimize the node 30 network structure is similar to that of multi-agent DDQN, except that the more influential 1–2 line is ignored. In addition, neither of PSO and DQN optimizes the line structure near other wind farms, which leads to the poor performance in reducing wind curtailment. Although the scheme obtained by B&B optimizes the line structure near the 32-node, it did not choose the 10–32 line that more directly impacts the power transmission of the wind farm. The scheme obtained by multi-agent DDQN has the best improved electrical betweenness and better economy, which proves the advantages of multi-agent DDQN in scheme optimization and multi-objective coordination in complex TNEP tasks.
5. Conclusions
This paper proposes a multi-agent DDQN for the TNEP task considering the uncertainties of wind power and load. In order to extract typical uncertain scenarios for TNEP tasks from system operating data, we improve the K-Means algorithm with the cumulation and the change rate of operation data as the clustering objective function. It improves computational efficiency while retaining the uncertainty of the system. Based on the typical uncertain scenarios, we construct a Bi-level multi-objective TNEP model considering the system renewable energy consumption capacity, economy, stability. Then, we transform the bi-level model into a TNEP reinforcement learning environment based on the Markov Chain model, which can support the interactive way to solve the TNEP task.
Based on the bi-level model structure, the proposed method constructs a dual DDQN agents, which realizes separation of the upper-level and the lower-level objective function optimization. The comparison of the proposed method with other four methods in multi-scenario TNEP tasks shows that the multi-agent DDQN is the most high-performance and flexible method. In addition, it trains by interacting with the reinforcement learning environment, which makes the training process more interpretable and observable than the heuristic-learning based methods. This paper only considers the uncertainties of wind power and load. In future work, we can build a TNEP model that contains more factors such as electric vehicle to expand the application scenarios of this method. Simultaneously, it is necessary to increase the computational efficiency by improving the multi-agent DDQN structure.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}