Author Contributions
Conceptualization, B.J.; methodology, D.M.; software, B.J.; validation, D.M., A.P.S., M.J. and Y.G.; formal analysis, B.J. and D.M.; investigation, B.J. and D.M.; resources, D.M., P.N.v.N., A.P.S., M.J., Y.G. and A.W.; data curation, B.J.; writing—original draft preparation, B.J. and D.M.; writing—review and editing, B.J., D.M., P.P. and P.N.v.N.; visualization, B.J.; supervision, D.M.; project administration, D.M.; funding acquisition, D.M. All authors have read and agreed to the published version of the manuscript.
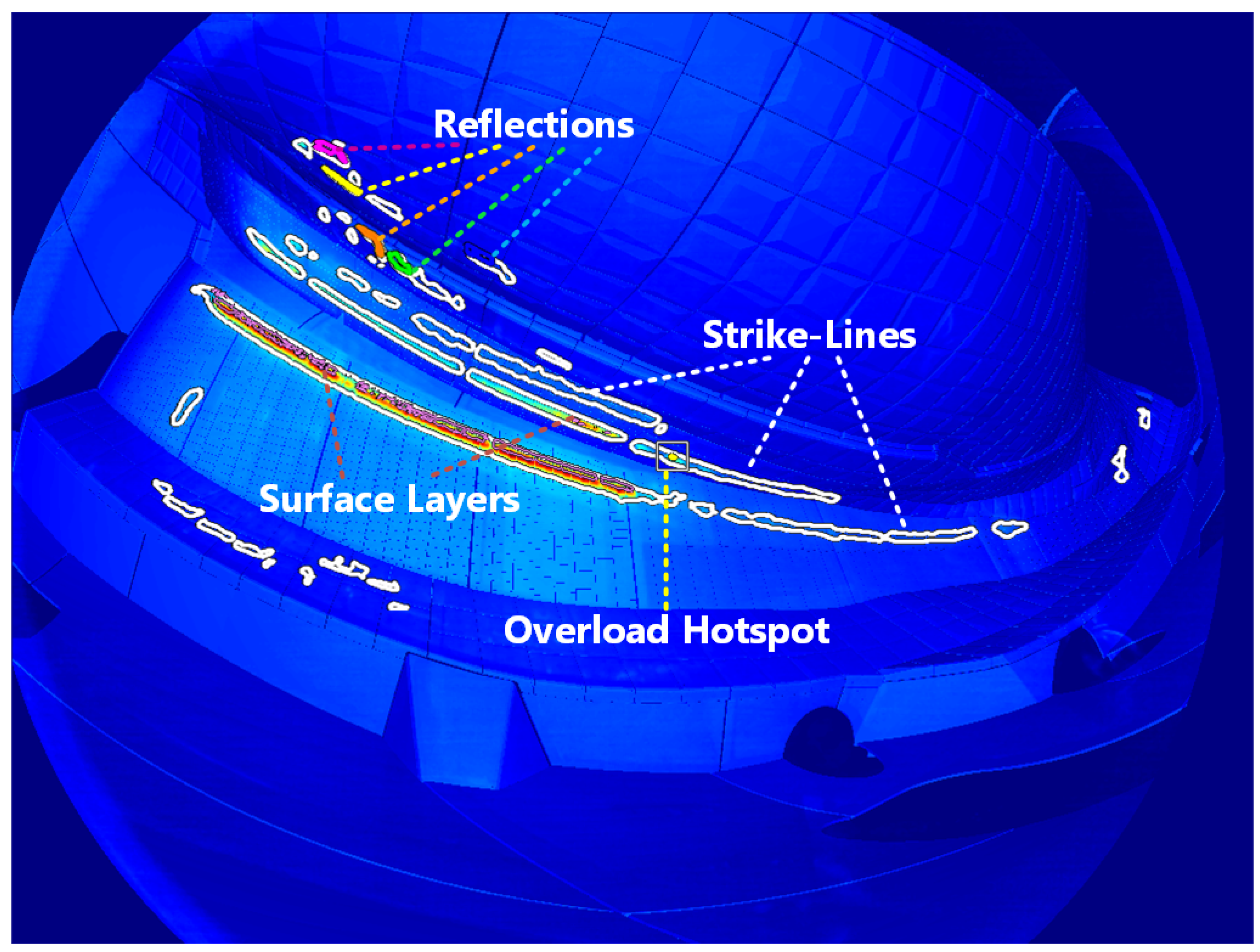
Figure 1.
Detected thermal events in the 20171114.053 (AEF20) dataset. The strike-line visible on the vertical divertor, the top one, is a reflection of the other strike-line, according to simulations conducted by [
3].
Figure 1.
Detected thermal events in the 20171114.053 (AEF20) dataset. The strike-line visible on the vertical divertor, the top one, is a reflection of the other strike-line, according to simulations conducted by [
3].
Figure 2.
Developed image processing pipeline. Algorithms described in the article have bolded edges, i.e., strike-line segmentation, reflection detection and visualisation.
Figure 2.
Developed image processing pipeline. Algorithms described in the article have bolded edges, i.e., strike-line segmentation, reflection detection and visualisation.
Figure 3.
NVIDIA Jetson Xavier NX Developer Kit.
Figure 3.
NVIDIA Jetson Xavier NX Developer Kit.
Figure 4.
Visualisation of data accessibility and caching of pageable and pinned buffers for integrated Graphics Processing Unit (GPU) and Central Processing Unit (CPU) on the System-on-a-Chip (SoC) platform supporting I/O coherency.
Figure 4.
Visualisation of data accessibility and caching of pageable and pinned buffers for integrated Graphics Processing Unit (GPU) and Central Processing Unit (CPU) on the System-on-a-Chip (SoC) platform supporting I/O coherency.
Figure 5.
Max-tree processing pipeline.
Figure 5.
Max-tree processing pipeline.
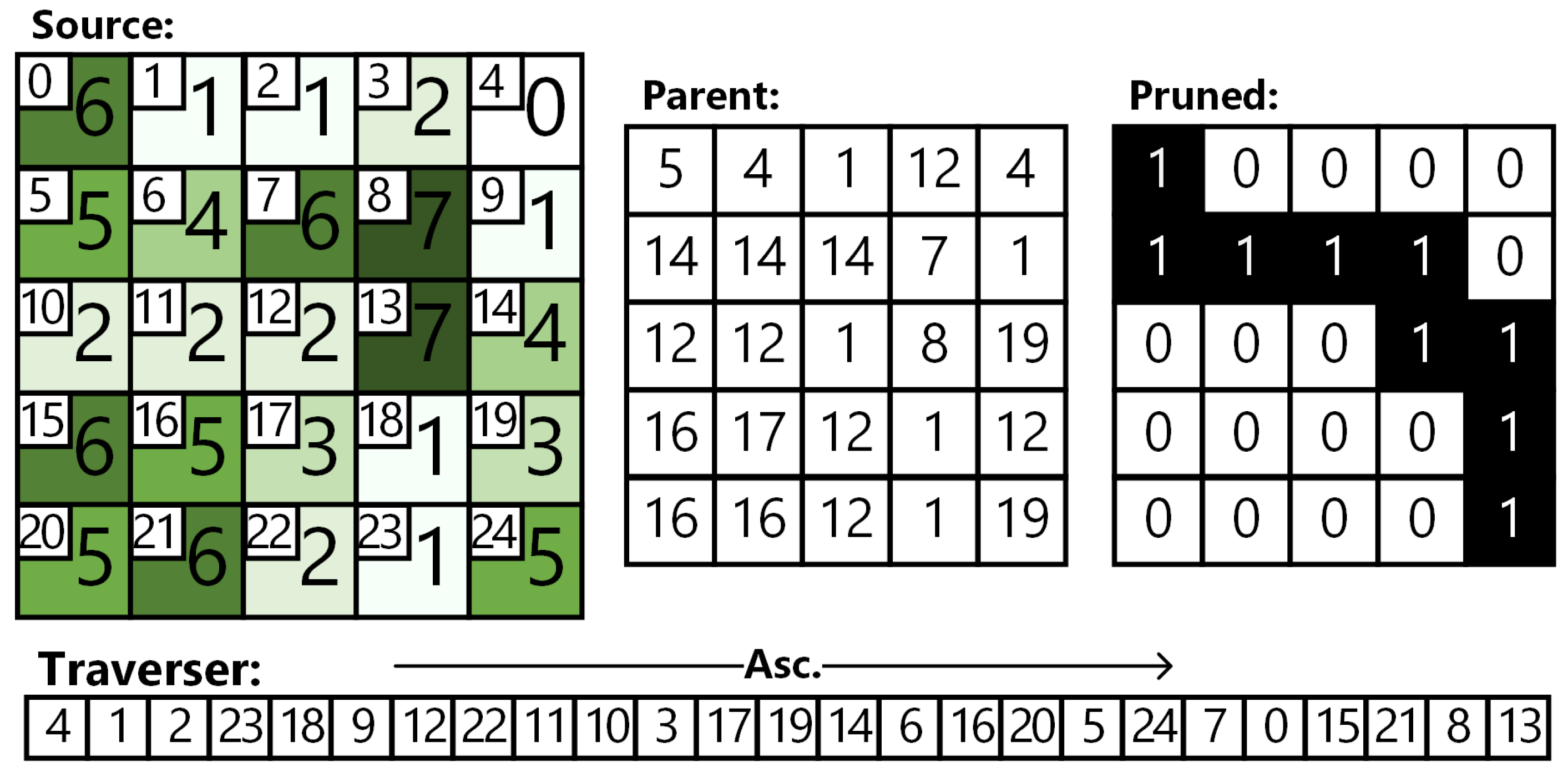
Figure 6.
Resulting max-tree representation (parent, traverser) and the pruning result (pruned) for the exemplary source image (source).
Figure 6.
Resulting max-tree representation (parent, traverser) and the pruning result (pruned) for the exemplary source image (source).
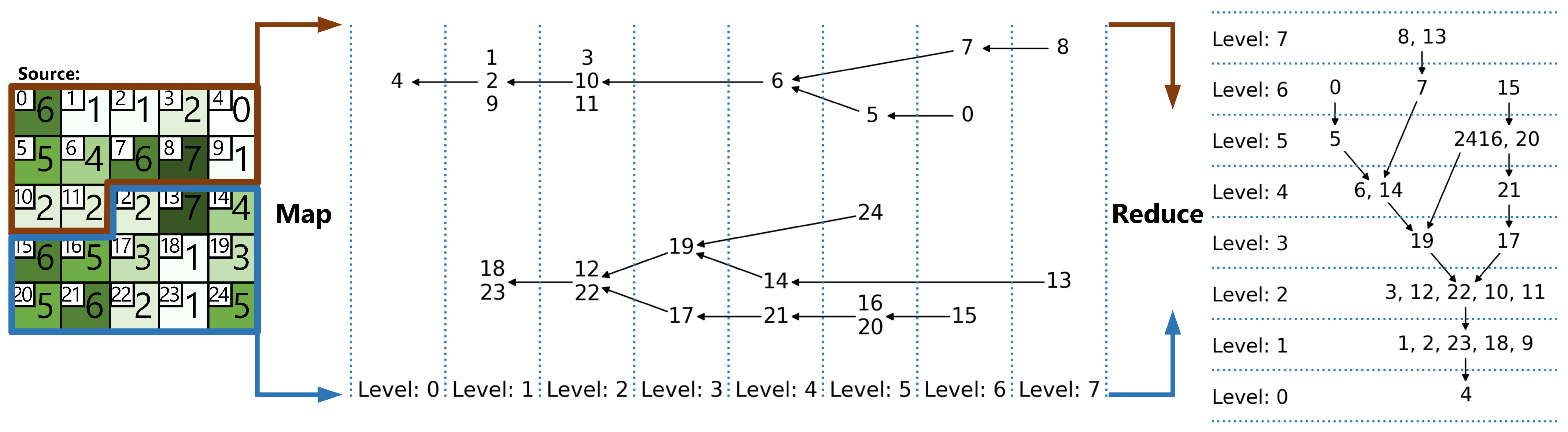
Figure 7.
Example of the parallel max-tree mapping and reduction transformations. A source image is split into two parts of sizes 12 and 13, then two chunks are mapped to two subtrees and merged into the final result. Graph nodes contain image indices.
Figure 7.
Example of the parallel max-tree mapping and reduction transformations. A source image is split into two parts of sizes 12 and 13, then two chunks are mapped to two subtrees and merged into the final result. Graph nodes contain image indices.
Figure 8.
Strike-line segmentation algorithm pipeline. The algorithm returns the mask containing continuous segmented regions of elevated temperature corresponding to strike-lines and hot-spots. Each step is annotated as to whether a CPU or GPU is used for computations.
Figure 8.
Strike-line segmentation algorithm pipeline. The algorithm returns the mask containing continuous segmented regions of elevated temperature corresponding to strike-lines and hot-spots. Each step is annotated as to whether a CPU or GPU is used for computations.
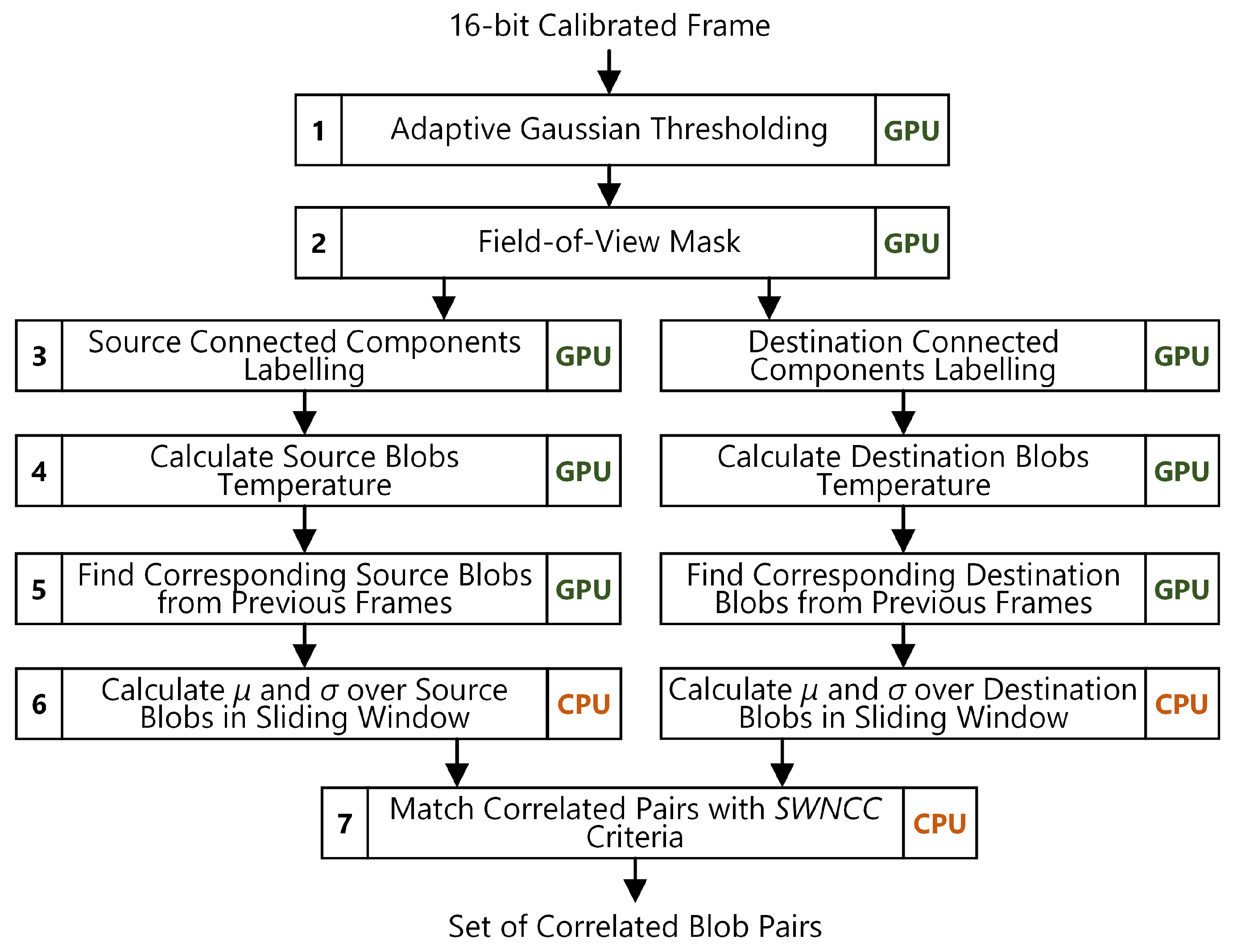
Figure 9.
Reflection detection algorithm pipeline. The algorithm returns correlated blob pairs between two selected Plasma Facing Component (PFC) corresponding to reflections. Each step is annotated as to whether a GPU or GPU is used for computations.
Figure 9.
Reflection detection algorithm pipeline. The algorithm returns correlated blob pairs between two selected Plasma Facing Component (PFC) corresponding to reflections. Each step is annotated as to whether a GPU or GPU is used for computations.
Figure 10.
Detected reflections between the divertors (upper components with red outline) and the wall heat shields (lower components with blue outline) at timestamp 2017.11.14 16:39:49.696,637,440 UTC. The highly correlated blobs are connected by lines.
Figure 10.
Detected reflections between the divertors (upper components with red outline) and the wall heat shields (lower components with blue outline) at timestamp 2017.11.14 16:39:49.696,637,440 UTC. The highly correlated blobs are connected by lines.
Figure 11.
Detected reflections between the divertors and the vertical baffle at timestamp 2017.11.14 16:39:49.696,637,440 UTC.
Figure 11.
Detected reflections between the divertors and the vertical baffle at timestamp 2017.11.14 16:39:49.696,637,440 UTC.
Figure 12.
Normalised Cross Correlations (NCC) on a Sliding Time Window (SWNCC) evolution between blob R on the wall heat shields and blobs A–F on the divertors.
Figure 12.
Normalised Cross Correlations (NCC) on a Sliding Time Window (SWNCC) evolution between blob R on the wall heat shields and blobs A–F on the divertors.
Figure 13.
(a) Source calibrated frame normalised to 8-bits for display purposes. (b) Processed frame in the range 100 °C–700 °C.
Figure 13.
(a) Source calibrated frame normalised to 8-bits for display purposes. (b) Processed frame in the range 100 °C–700 °C.
Figure 14.
Visualisation algorithm pipeline. The algorithm returns a coloured image with improved visibility of heat loads on the PFCs. Each step is annotated as to whether a GPU or GPU is used for computations.
Figure 14.
Visualisation algorithm pipeline. The algorithm returns a coloured image with improved visibility of heat loads on the PFCs. Each step is annotated as to whether a GPU or GPU is used for computations.
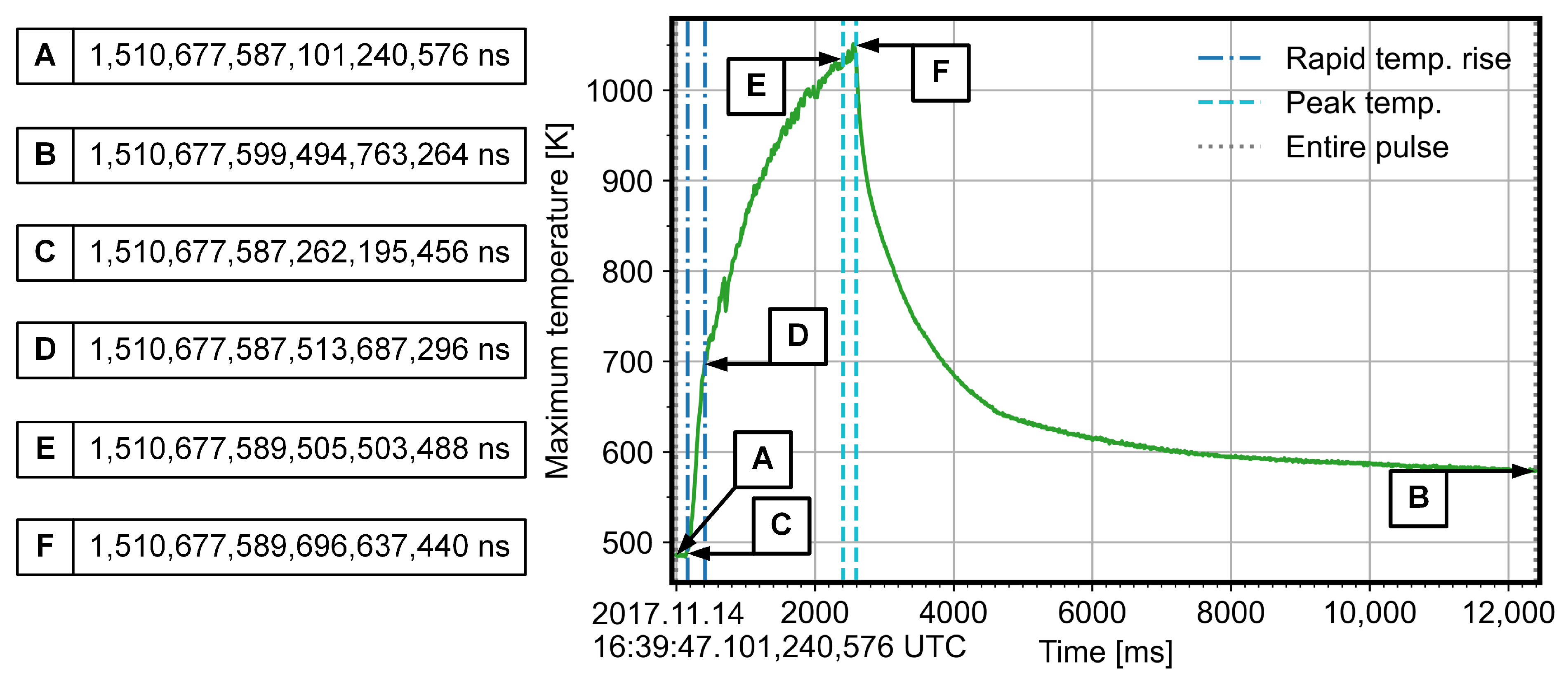
Figure 15.
Evolution of the maximum temperature throughout the pulse 20171114.053 (AEF20) with the signified intervals. The temperature was sampled inside the Field of View (FoV) after applying a 3 × 3 median filter that refers to steps one to three in the visualisation algorithm.
Figure 15.
Evolution of the maximum temperature throughout the pulse 20171114.053 (AEF20) with the signified intervals. The temperature was sampled inside the Field of View (FoV) after applying a 3 × 3 median filter that refers to steps one to three in the visualisation algorithm.
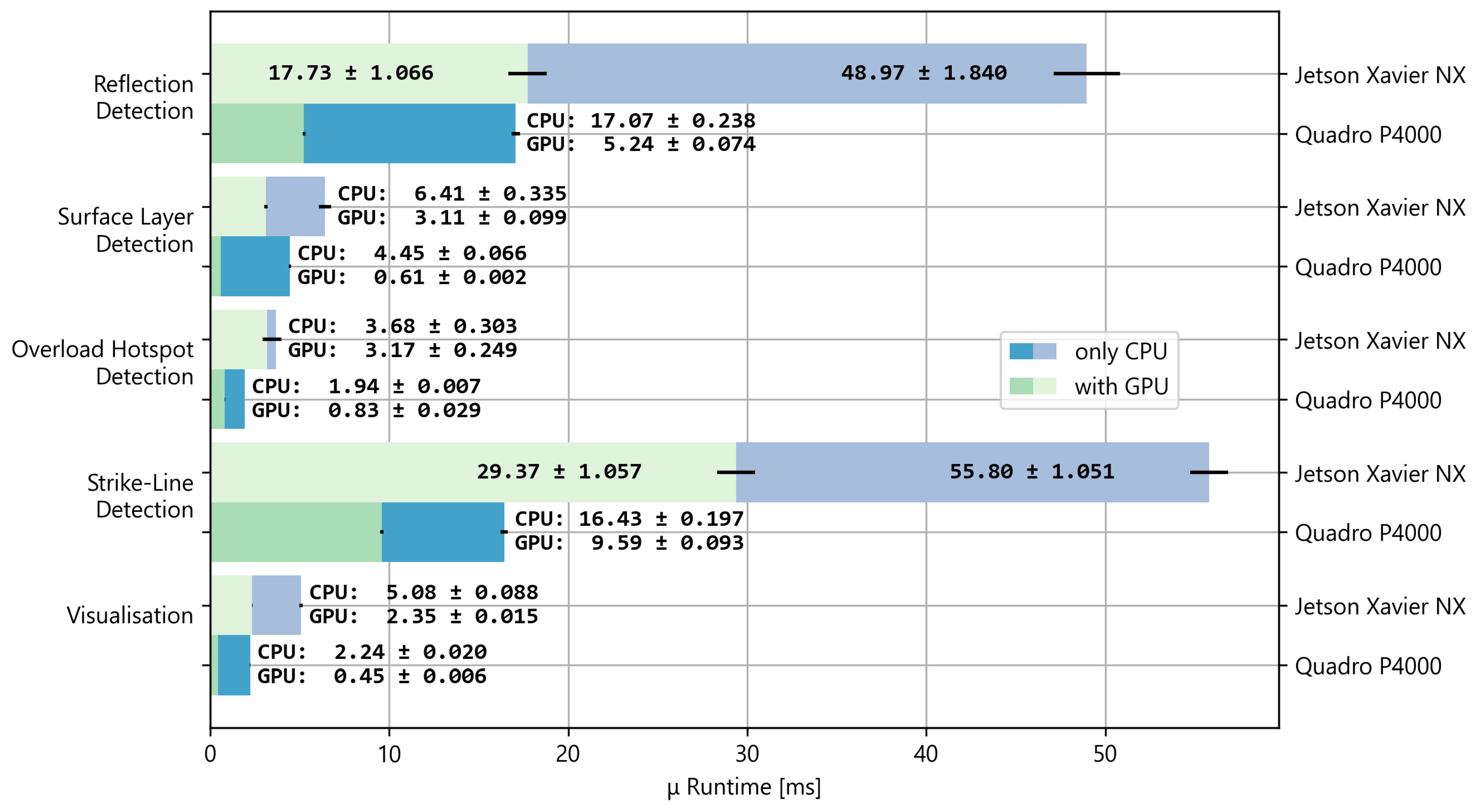
Figure 16.
Average runtime measurements for the implemented Infrared (IR) image-processing algorithms. Black horizontal lines represent a standard deviation of an average runtime.
Figure 16.
Average runtime measurements for the implemented Infrared (IR) image-processing algorithms. Black horizontal lines represent a standard deviation of an average runtime.
Figure 17.
(a) Our results; (b) Results from the literature optimised for F2-score; (c) Ground-truth masks. Images from the 20171114.053 (AEF20) dataset are in the top row, images from the 20180927.025 (AEF20) dataset are in the bottom row. White (1’s) pixels correspond to positive and black (0’s) to negative segmentation labels.
Figure 17.
(a) Our results; (b) Results from the literature optimised for F2-score; (c) Ground-truth masks. Images from the 20171114.053 (AEF20) dataset are in the top row, images from the 20180927.025 (AEF20) dataset are in the bottom row. White (1’s) pixels correspond to positive and black (0’s) to negative segmentation labels.
Table 1.
NVIDIA Jetson Xavier NX technical specification.
Table 1.
NVIDIA Jetson Xavier NX technical specification.
| Feature | Description |
|---|
| GPU | 384-core Volta @ 1.1 GHz (memory shared with RAM) |
| CPU | 6-core NVIDIA Carmel ARM v8.2 @ 2 × 1.9 GHz | 6 × 1.4 GHz (NVPModel) |
| RAM | 8 GB 128-bit LPDDR4x @ 1600 MHz | 51.2 GB/s |
| PCIe | Gen 4 |
| Power | Up to 15 W |
Table 2.
NVIDIA Jetson Xavier NX maximum performance CPU modes.
Table 2.
NVIDIA Jetson Xavier NX maximum performance CPU modes.
| NVPModel ID | Online Cores | Core Frequency [MHZ] |
|---|
| 0 | 2 | 1900 |
| 2 | 6 | 1400 |
Table 3.
Technical specification of the benchmark setup based on the NVIDIA Quadro P4000.
Table 3.
Technical specification of the benchmark setup based on the NVIDIA Quadro P4000.
| Feature | Description |
|---|
| GPU | 1792-core Pascal Quadro P4000 8 GB GDDR5 @ 1.7GHz |
| CPU | 4-core Intel Core i7-4771 @ 3.50 GHz |
| RAM | 2 × 4 GB 64-bit DDR3 @ 1333 MHz |
| PCIe | Gen 3 |
| Power | 105 W (GPU) + 84 W (CPU) |
Table 4.
Performance of the sequential and parallel strike-line segmentation algorithms for different power modes and GPU/CPU implementations on the NVIDIA Jetson Xavier NX.
Table 4.
Performance of the sequential and parallel strike-line segmentation algorithms for different power modes and GPU/CPU implementations on the NVIDIA Jetson Xavier NX.
| | GPU [ms] | CPU [ms] |
|---|
| Implementation | NVPModel 0 | NVPModel 2 | NVPModel 0 | NVPModel 2 |
|---|
| | | | | | | | | |
| Sequential | 29.37 | 1.057 | 36.82 | 0.878 | 55.80 | 1.051 | 71.81 | 0.968 |
| Parallel | 41.34 | 2.526 | 33.12 | 1.458 | 60.26 | 1.473 | 60.73 | 1.515 |
Table 5.
Performance of the top-hat morphological filter for an 8-bit image of a resolution of 1024 ×768 and a structuring element of size of 13 × 13 on the NVIDIA Jetson Xavier NX.
Table 5.
Performance of the top-hat morphological filter for an 8-bit image of a resolution of 1024 ×768 and a structuring element of size of 13 × 13 on the NVIDIA Jetson Xavier NX.
| Implementation | Device | [ms] | [ms] |
|---|
| OpenCV | GPU | 10.48 | 0.065 |
| NPP | GPU | 10.11 | 0.063 |
| vHGW (CUDA kernel) | GPU | 1.33 | 0.057 |
| OpenCV | CPU | 3.60 | 0.993 |
Table 6.
F-score metrics for the result computed with the implemented algorithm and the result from the literature.
Table 6.
F-score metrics for the result computed with the implemented algorithm and the result from the literature.
| Discharge | | |
|---|
| Our implementation |
| 20171114.053 (AEF20) | 0.81 | 0.83 |
| 20180927.025 (AEF20) | 0.56 | 0.52 |
| R. Clemente [7] |
| 20171114.053 (AEF20) | 0.76 | 0.75 |
| 20180927.025 (AEF20) | 0.48 | 0.67 |


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}