Comparison Between Wind Power Prediction Models Based on Wavelet Decomposition with Least-Squares Support Vector Machine (LS-SVM) and Artificial Neural Network (ANN)


Abstract
:1. Introduction
2. Wind Farm Characteristics and Available Time Data
3. Input Data and Performance Evaluation


- -
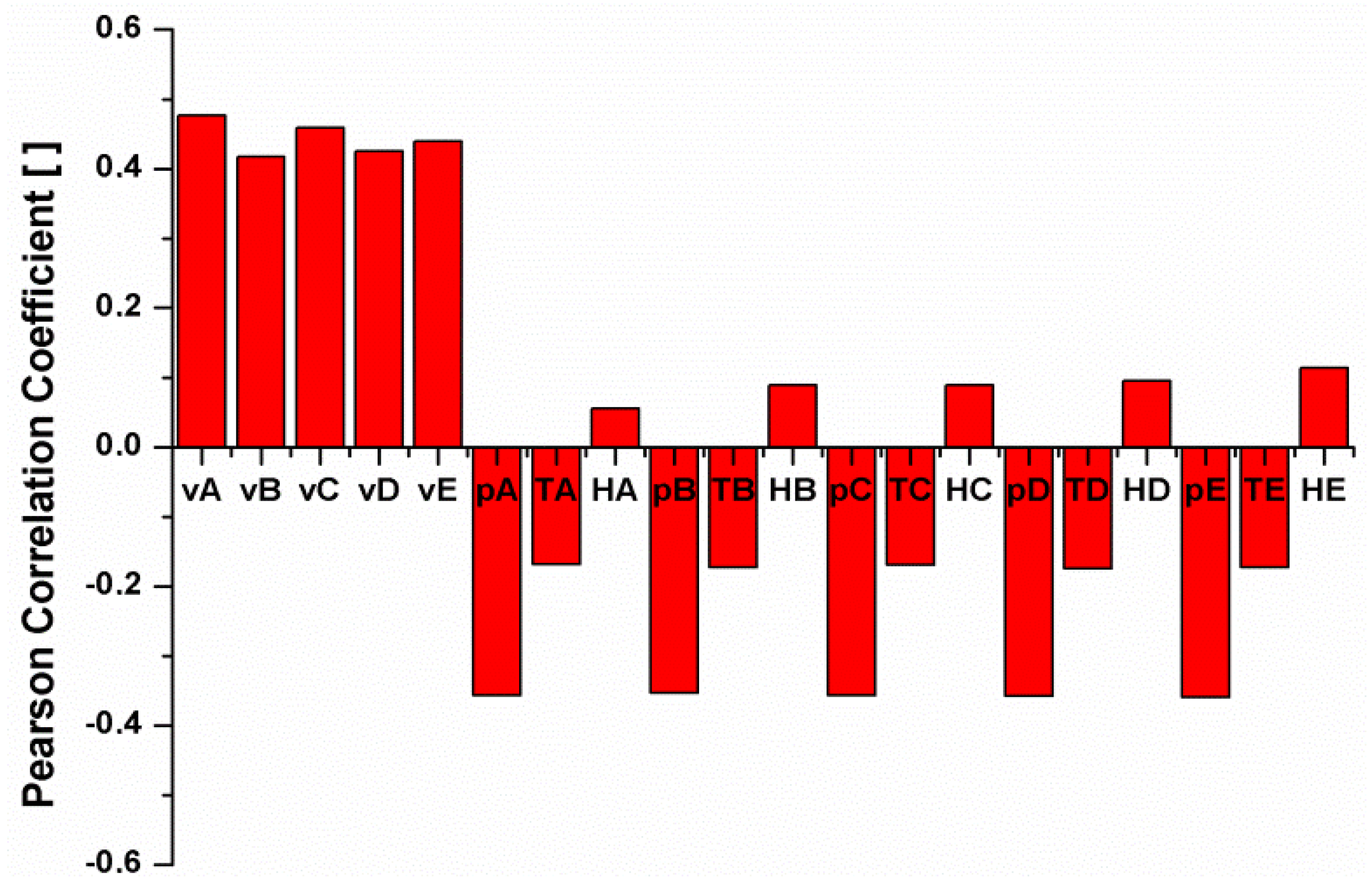
- The hourly wind speed values predicted by the NWP for the five best-correlated sites, as previously described, considers the time horizon of the forecast. For example, when the forecast horizon is 1 h, the 5 predicted wind speeds for each site for the next hour in respect to the beginning of the forecast will be considered; for a prediction using a 24 h forecast horizon, the input vector includes the predicted values for the next 24 h for each site (120 forecasted wind speeds).
- -
- The numerical weather parameters (pressure, temperature and humidity) that are predicted hourly by the NWP, like the predicted wind speed.


| Input Vectors | Numerical Weather Parameters | Measured Data | |||
|---|---|---|---|---|---|
| Site Speed vA, vB, vC, vD, vE | Pressure pA, pB, pC, pD, pE | Temperature TA, TB, TC, TD, TE | Humidity HA, HB, HC, HD, HE | Hourly average power Pm | |
| I | X | X | X | X | X |
| II | X | X | X | - | X |
| Horizon (Hours) | Input | Unit of Measurement | Target (kW) |
|---|---|---|---|
| L | vA, i+1 … vA, i+l vB, i+1 … vB, i+l vC, i+1 … vC, i+l vD, i+1 … vD, i+l vE, i+1 … vE, i+l | m/s | Pt+ 1 + …+ Pt +l |
| pA, i+1 … pA, i+l pB, i+1 … pB, i+l pC, i+1 … pC, i+l pD, i+1 … pD, i+l pE, i+1 … pE, i+l | mmHg | ||
| TA, i+1 … TA, i +l TB, i+1 … TB,i+l TC,i+1 … TC,i+l TD, i+1 … TD, i+l TE, i+1 … TE, i+l | °C | ||
| HA, i+1 … HA, i+l HB,i+1 … HB, i+l HC, i+1 … HC, i+l HD, i+1 … HD, i+l HE, i+1 … HE, i+l | % | ||
| Pmi | kW |





- i = generic hour of the predicted data;
- l = time horizon;
- M = number of predicted data, equal to 1896;
![Energies 07 05251 i007]() , where T(i,l) is the predicted power at hour i for the time horizon l;
, where T(i,l) is the predicted power at hour i for the time horizon l;![Energies 07 05251 i008]() , where Pt(i,l) is defined as Equation (4).
, where Pt(i,l) is defined as Equation (4).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

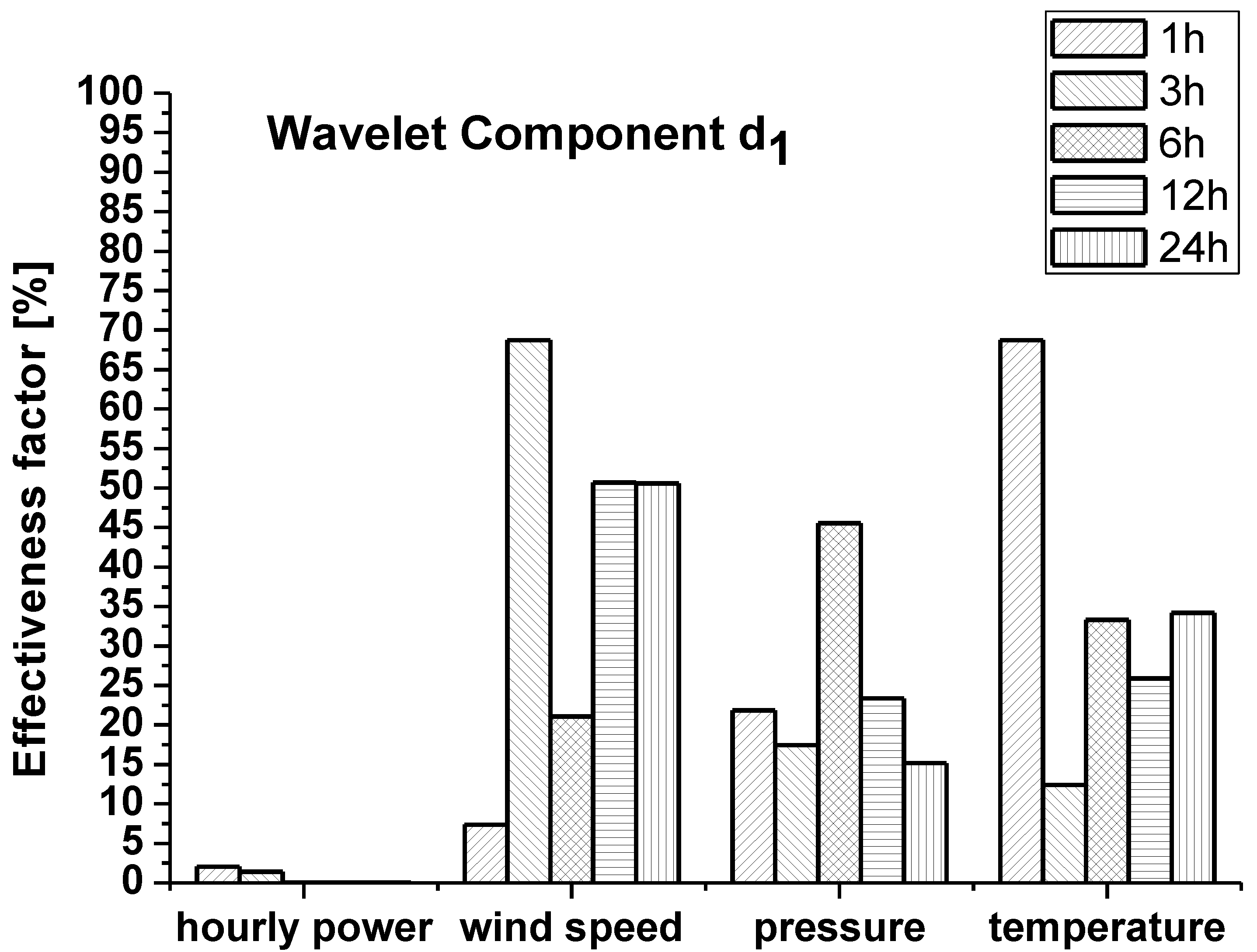
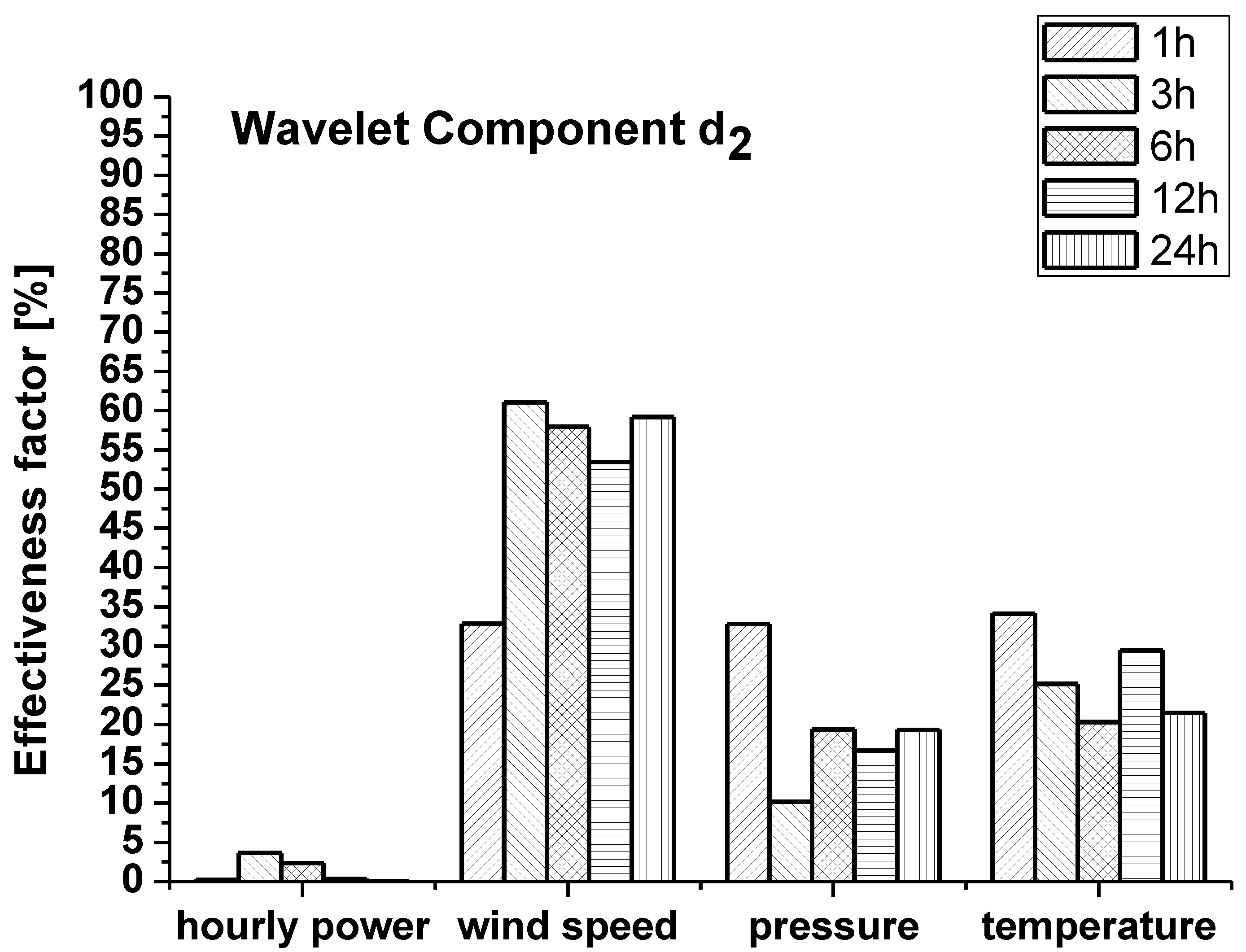
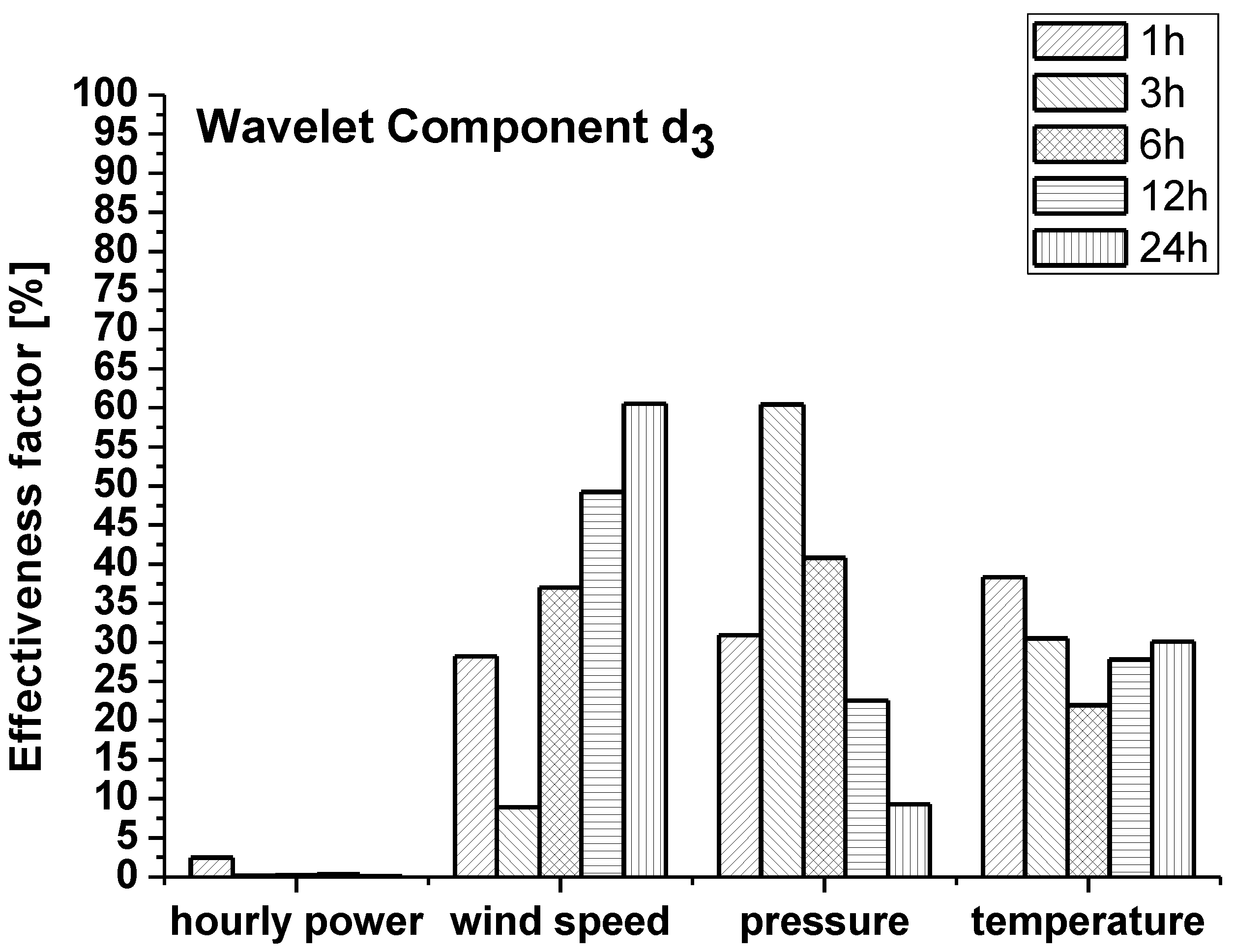
- σT(l) = standard deviation of TN(i,l)
- σP(l) = standard deviation of PN(i,l)
- RTP = the cross-correlation coefficient between TN(i,l) and PN(i,l)
4. The Least Squares Support Vector Machine Model
 , where x(I) is the i-th input data and Pt(i,l) is the i-th output data defined in Equation (4). The following regression model can be constructed by using , ϕ(x(i)) nonlinear function mapping of the input space to a higher dimensional space:
, where x(I) is the i-th input data and Pt(i,l) is the i-th output data defined in Equation (4). The following regression model can be constructed by using , ϕ(x(i)) nonlinear function mapping of the input space to a higher dimensional space:
5. The Artificial Neural Network Method
| Number of layers | Input vector I | Input vector II | |
|---|---|---|---|
| 3 | 3 | ||
| Neurons (layer 1) | l = 1 h | 21 | 16 |
| l = 3 h | 31 | 26 | |
| l = 6 h | 61 | 51 | |
| l = 12 h | 121 | 101 | |
| l = 24 h | 241 | 201 | |
| Neurons (layer 2) | l = 1 h | 11 | 8 |
| l = 3 h | 16 | 13 | |
| l = 6 h | 31 | 26 | |
| l = 12 h | 61 | 51 | |
| l = 24 h | 121 | 101 | |
| Neurons (layer 3)—output | 1 | 1 | |
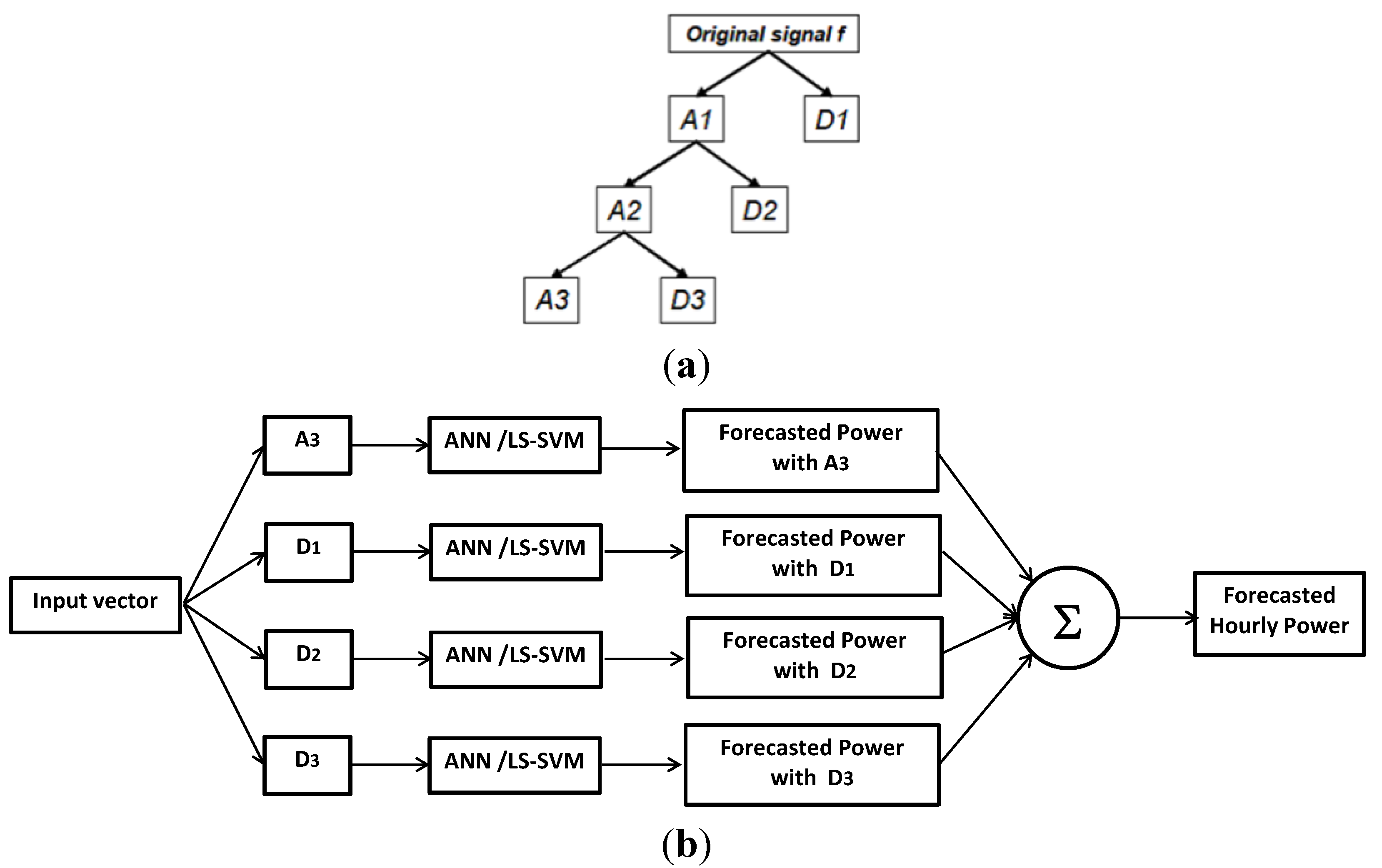
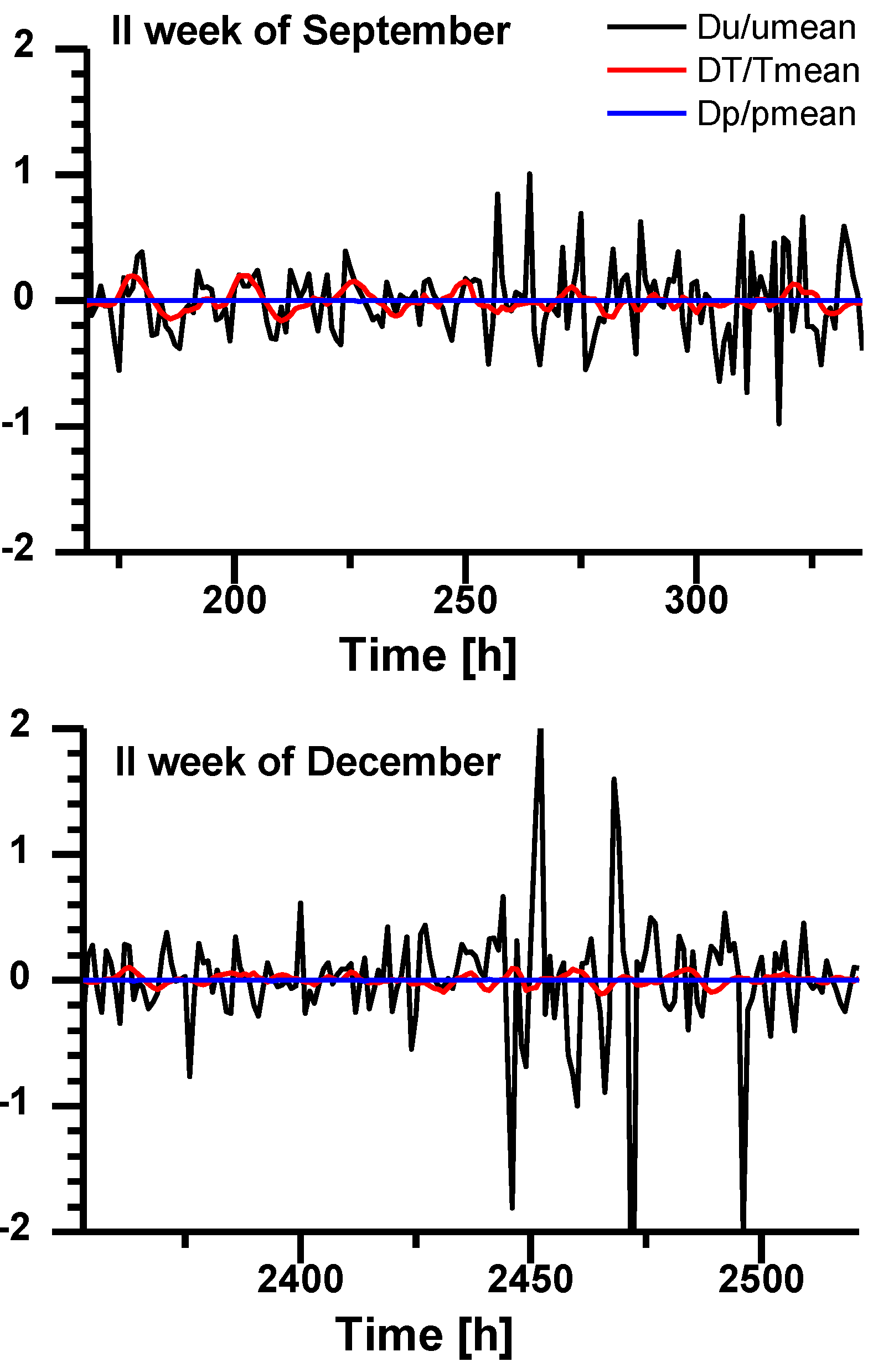
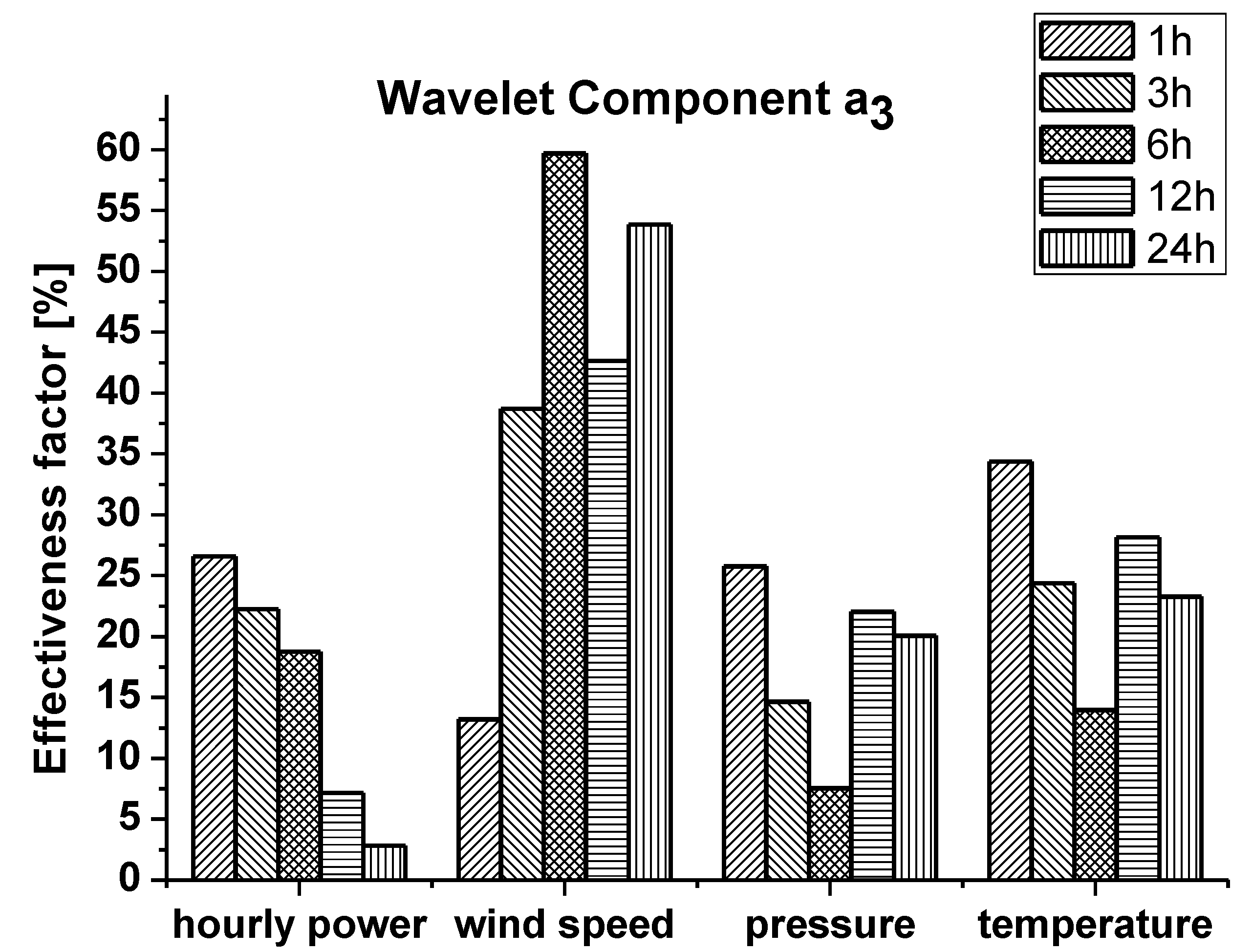
6. Wavelet Decomposition Technique
- -
- Six Daubechies Wavelet Decomposition employed to carry out the 3rd level discrete WD of the original hourly time series; the approximation component A3 and the three detail components D1, D2 and D3 were obtained.
- -
- Training of the forecast model (ANN or LS-SVM), one for each of the four WD components.
- -
- Aggregation of the four partial forecast results for final predicted wind power.

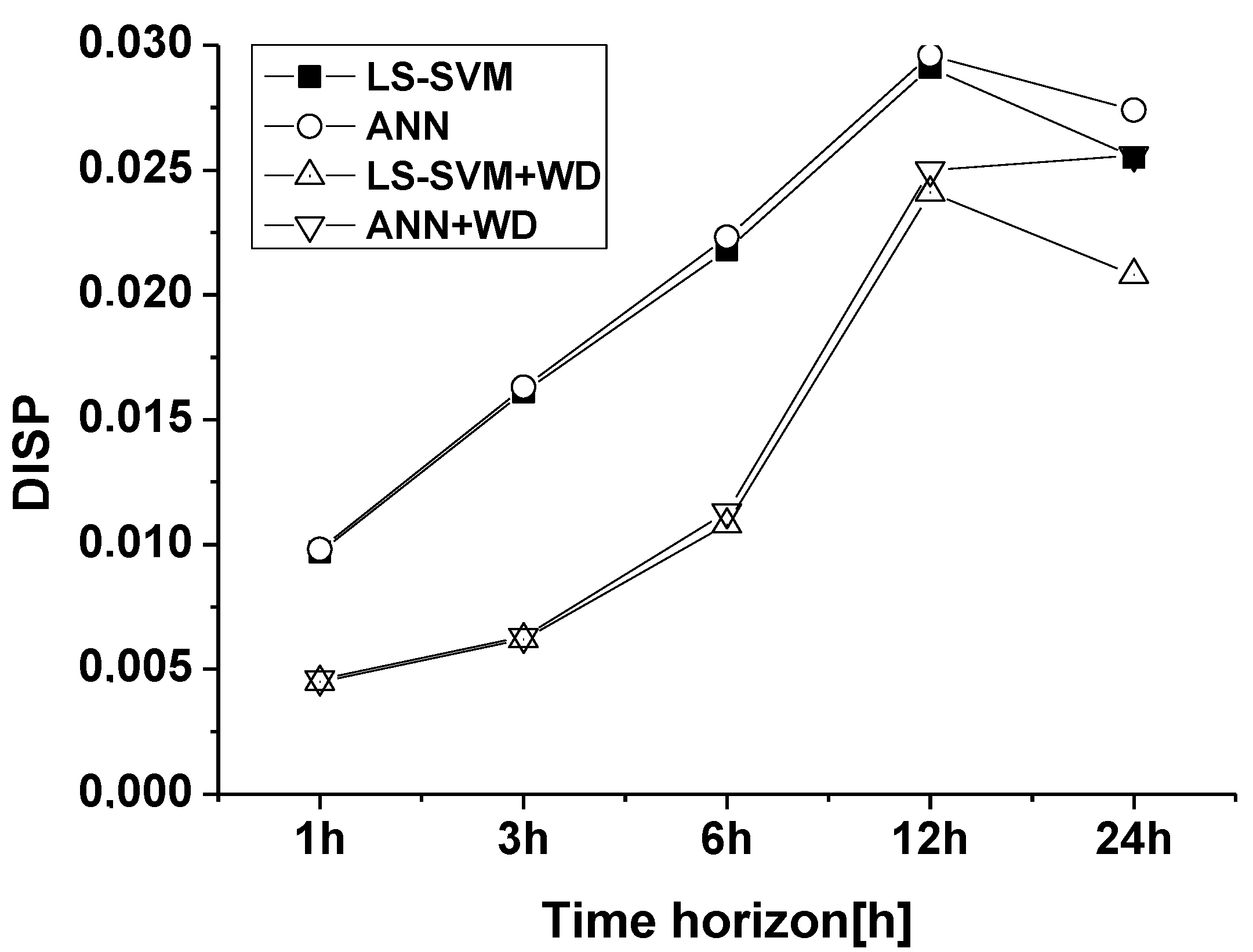
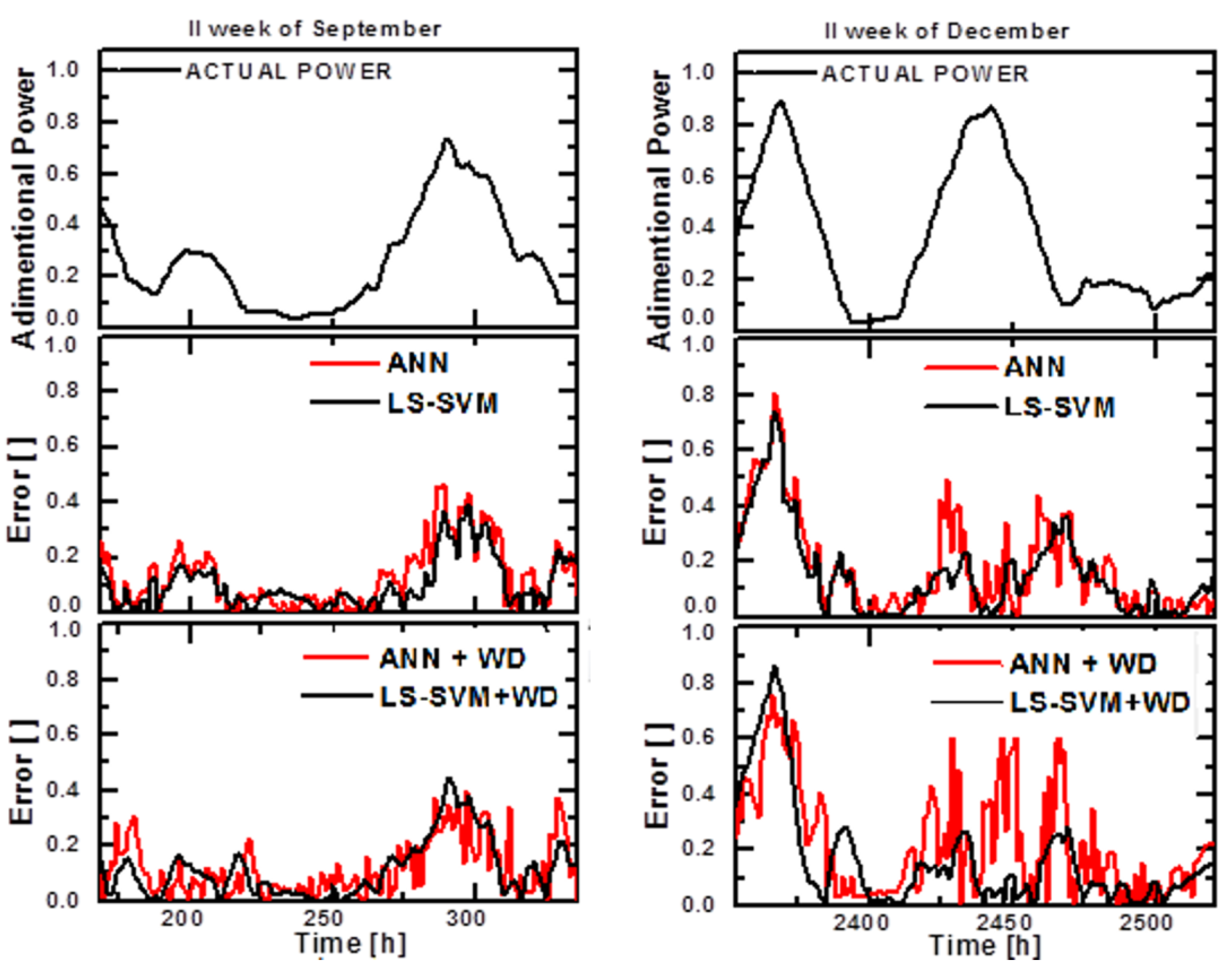
7. Results
7.1. Forecasting Based on Artificial Neural Networks and LS-SVM

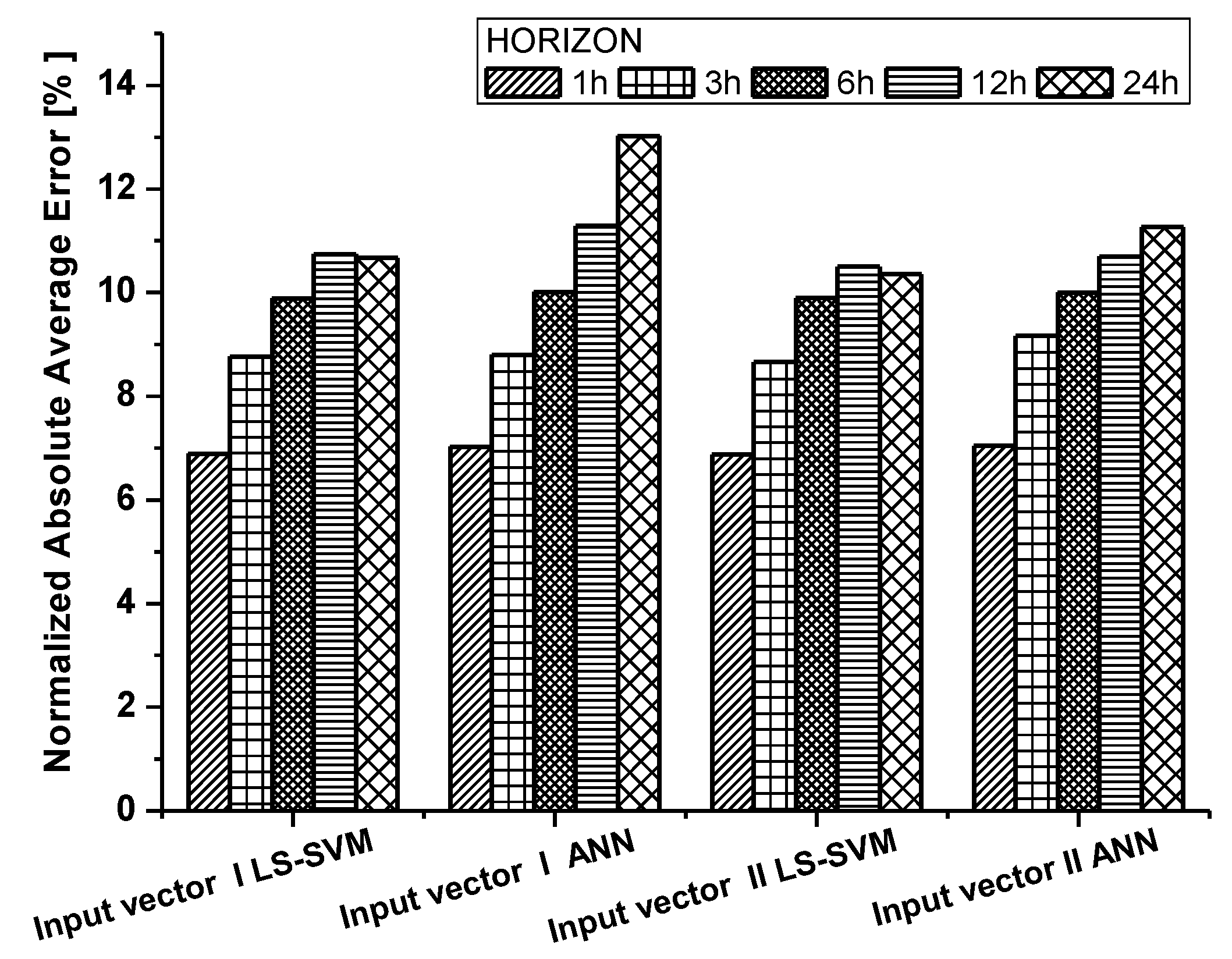
| Time Horizon | Normalized Absolute Average Error | Error Range Probability [−10%; +10%] | Error Range Probability [−20%; +20%] | Prediction Length | Normalized Absolute Average Error | Error Range Probability [−10%; +10%] |
|---|---|---|---|---|---|---|
| Input vector I LS-SVM | Input vector II LS-SVM | Input vector I LS-SVM | Input vector II LS-SVM | Input vector I LS-SVM | Input vector II LS-SVM | |
| 1 h | 6.89% | 6.88% | 78.36% | 78.29% | 91.83% | 91.76% |
| 3 h | 8.76% | 8.67% | 70.50% | 70.67% | 88.40% | 88.51% |
| 6 h | 9.90% | 9.89% | 66.11% | 64.94% | 85.78% | 85.65% |
| 12 h | 10.74% | 10.51% | 63.27% | 63.31% | 82.95% | 84.40% |
| 24 h | 10.67% | 10.36% | 59.73% | 63.34% | 86.16% | 86.65% |
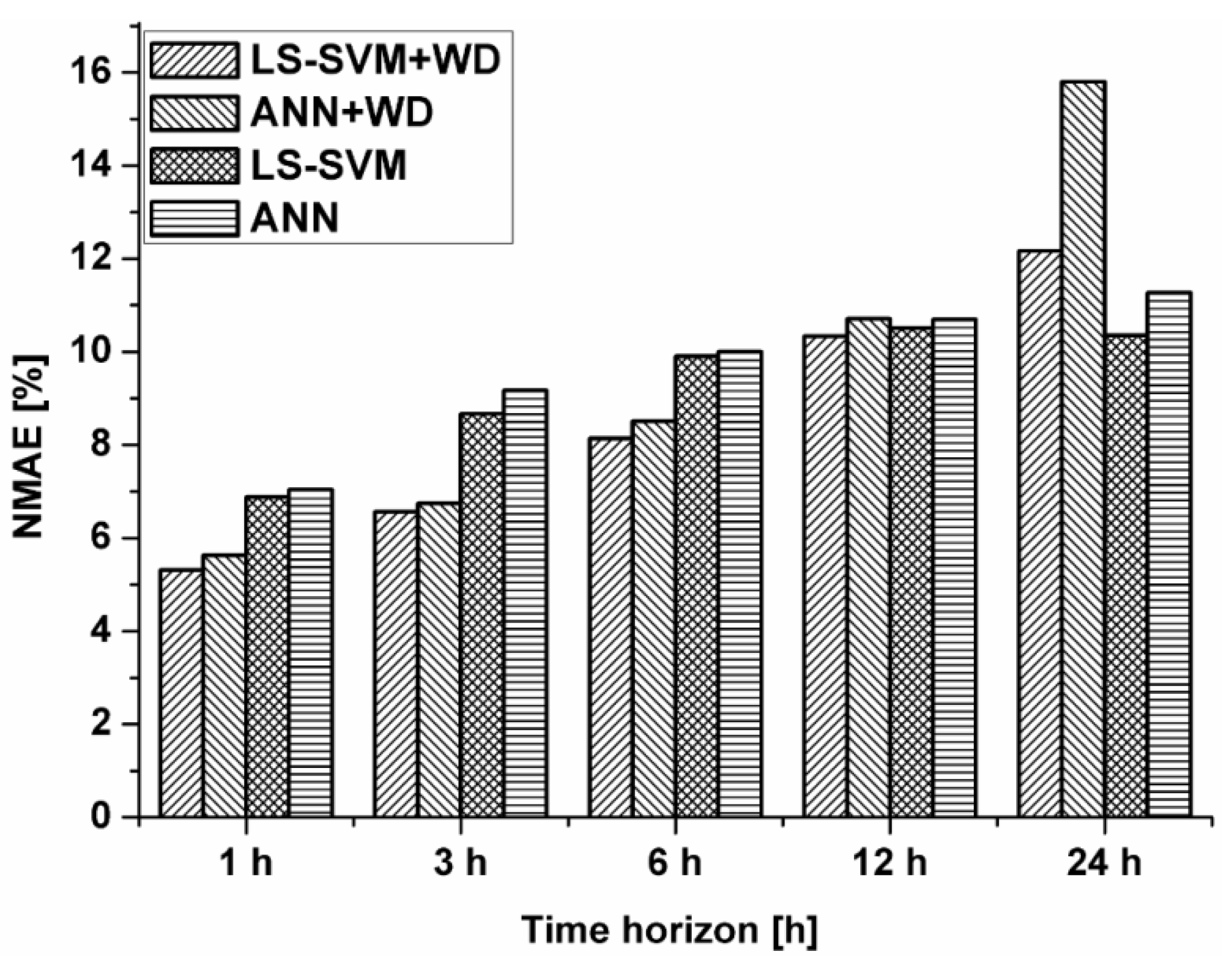
7.2. Wind Power Forecast by Wavelet Based Forecasting Methods
| Normalized Absolute Average Error NMAE | ||||
|---|---|---|---|---|
| Time Horizon | Input Vector IIANN | Input Vector IILS-SVM | Input Vector IIANN with WD | Input Vector IILS-SVM with WD |
| 1 h | 7.04% | 6.88% | 5.67% | 5.31% |
| 3 h | 9.17% | 8.67% | 6.83% | 6.57% |
| 6 h | 9.99% | 9.89% | 8.56% | 8.14% |
| 12 h | 10.70% | 10.51% | 10.92% | 10.33% |
| 24 h | 11.27% | 10.36% | 15.50% | 12.16% |
| Error Range Probability [−10%; +10%] | ||||
| Time Horizon | Input vector IIANN | Input vector IILS-SVM | Input vector IIANN with WD | Input vector IILS-SVM with WD |
| 1 h | 78.19% | 78.29% | 82.84% | 83.56% |
| 3 h | 71.88% | 70.50% | 78.12% | 78.15% |
| 6 h | 67.43% | 64.94% | 71.61% | 71.62% |
| 12 h | 65.11% | 63.27% | 60.95% | 64.02% |
| 24 h | 59.56% | 63.34% | 43.42% | 56.65% |
| Error Range Probability [−20%; +20%] | ||||
| Time Horizon | Input Vector IIANN | Input Vector IILS-SVM | Input Vector IIANN with WD | Input Vector IILS-SVM with WD |
| 1 h | 91.45% | 91.76% | 94.93% | 95.07% |
| 3 h | 88.68% | 88.51% | 92.17% | 92.18% |
| 6 h | 85.55% | 85.65% | 88.66% | 89.63% |
| 12 h | 82.43% | 84.40% | 83.96% | 84.80% |
| 24 h | 84.35% | 86.65% | 72.44% | 81.36% |








 ], where
], where  is the average of xj(i) over the total number of samples M and it is given by:
is the average of xj(i) over the total number of samples M and it is given by:





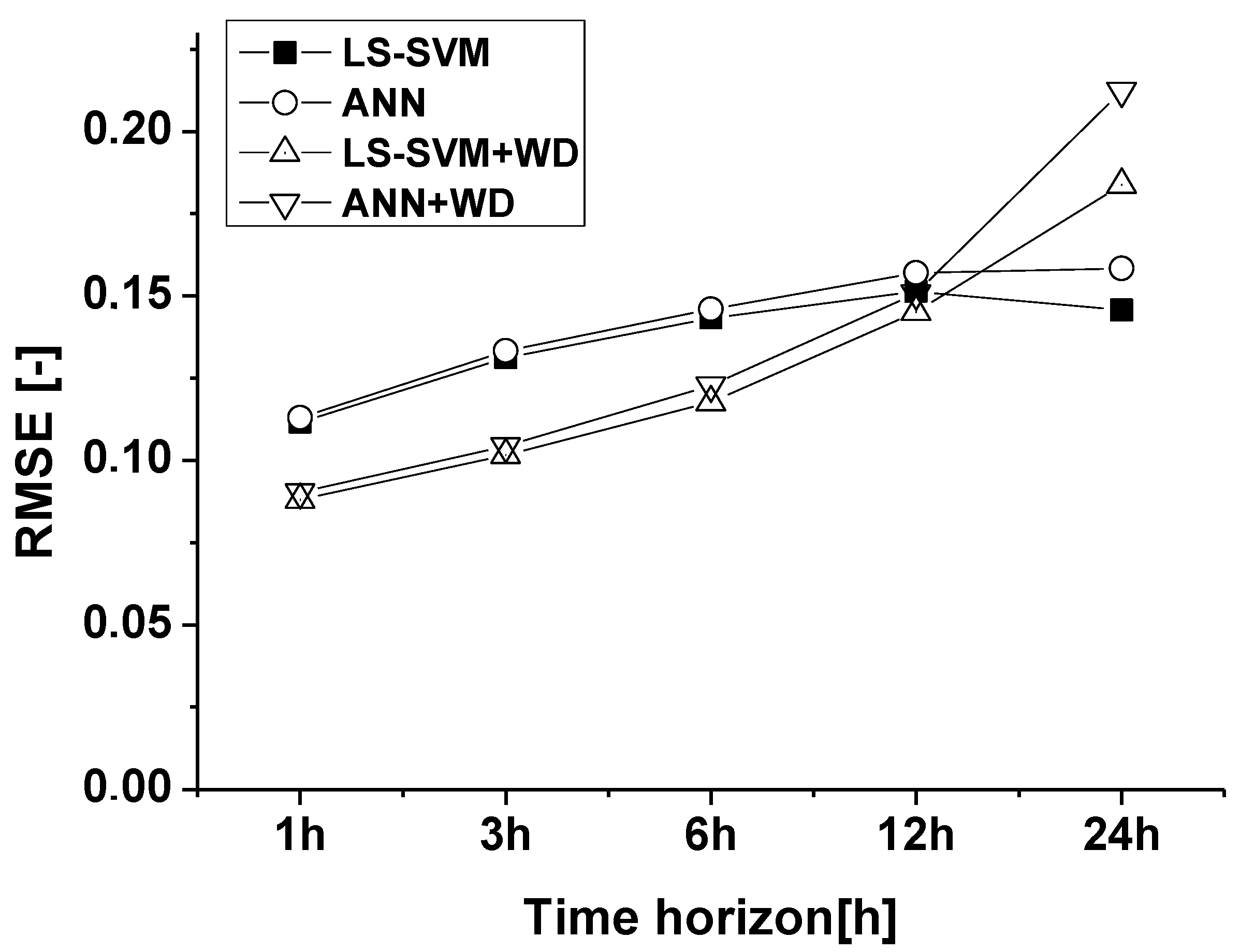
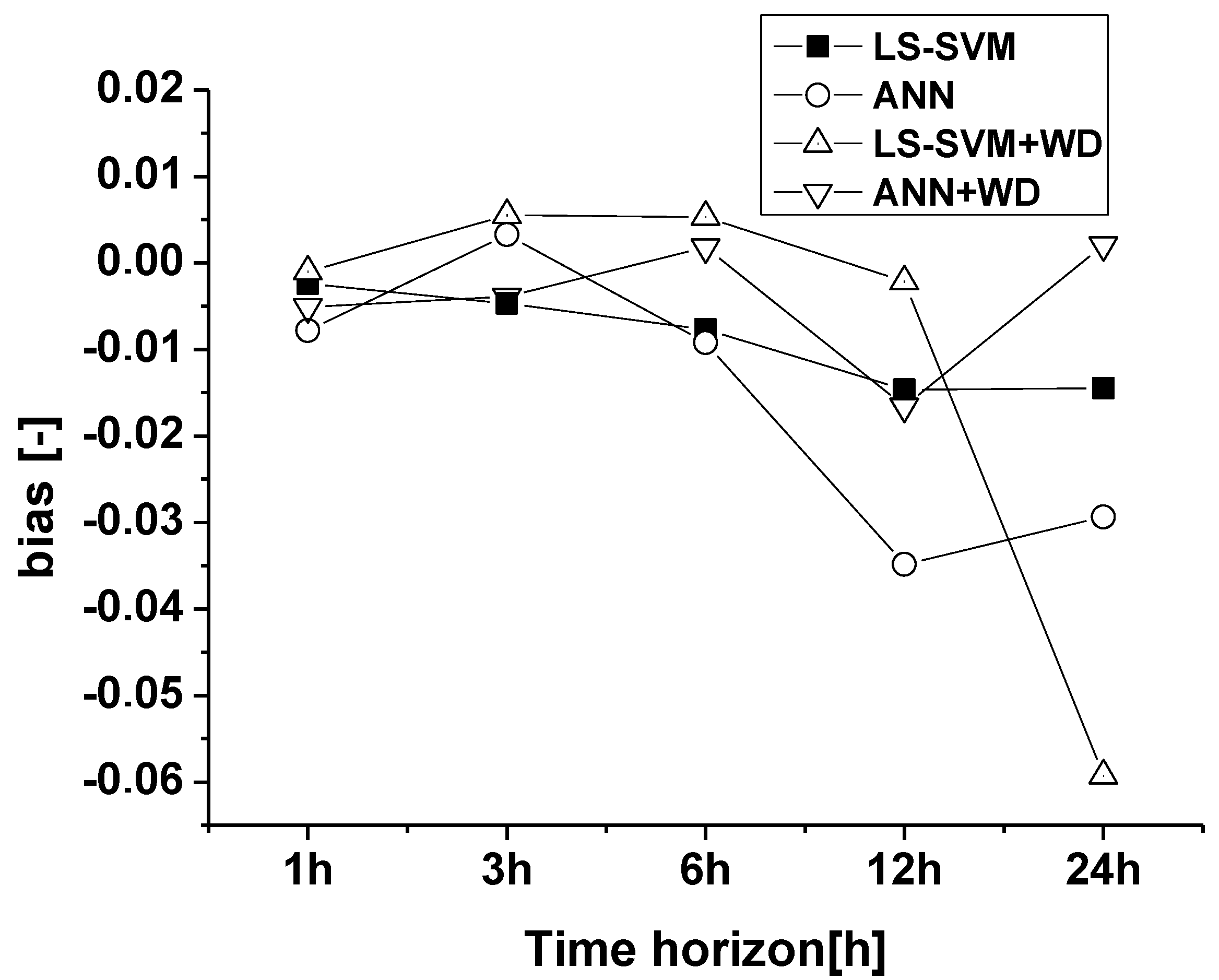
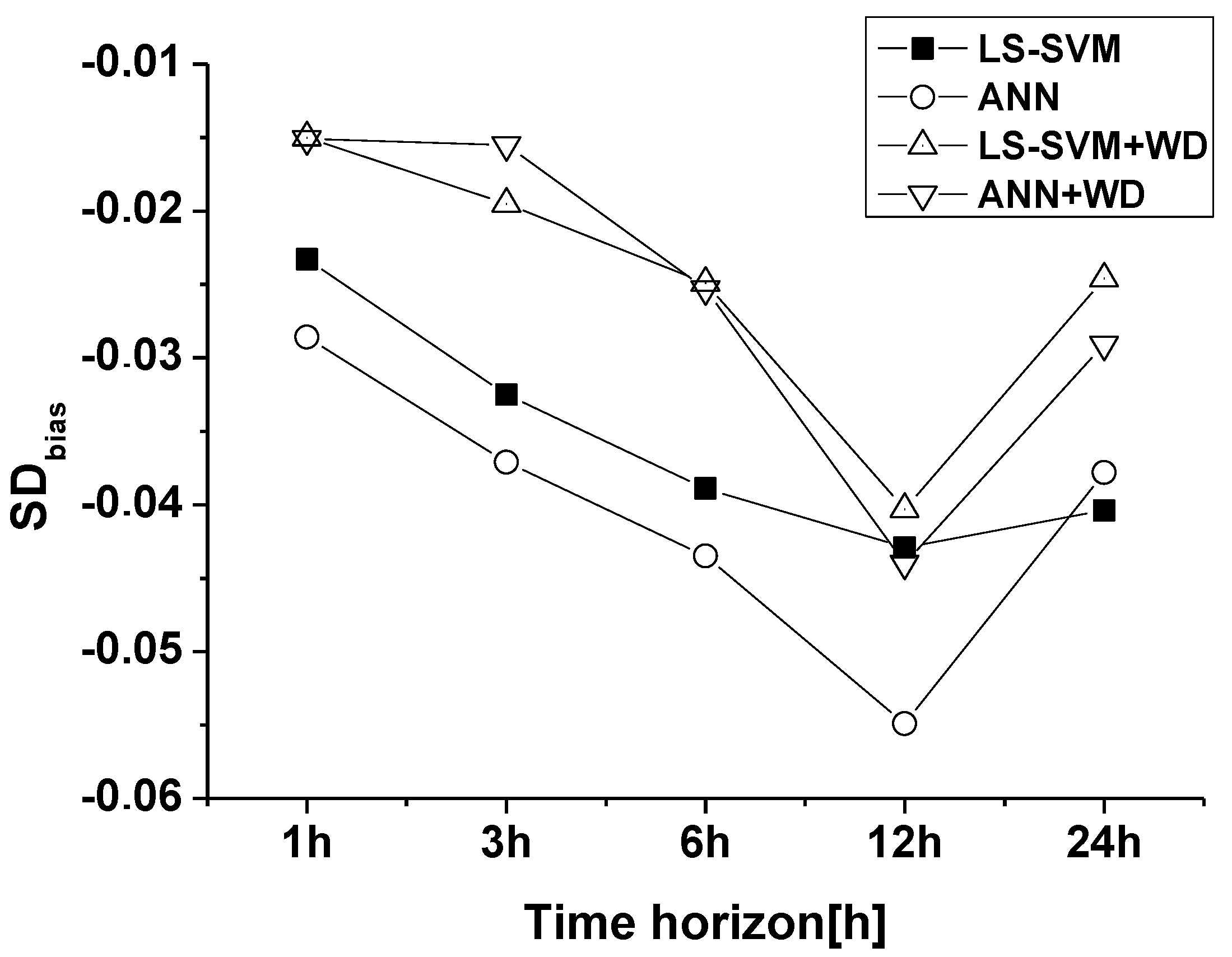
8. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Congedo, P.M.; Malvoni, M.; Mele, M.; de Giorgi, M.G. Performance measurements of monocrystalline silicon PV modules in South-eastern Italy. Energy Convers. Manag. 2013, 68, 1–10. [Google Scholar] [CrossRef]
- Wu, J.; Wang, J.; Lu, H.; Dong, Y.; Lu, X. Short term load forecasting technique based on the seasonal exponential adjustment method and the regression model. Energy Convers. Manag. 2013, 70, 1–9. [Google Scholar] [CrossRef]
- Xydis, G.; Koroneos, C.; Loizidou, M. Exergy analysis in a wind speed prognostic model as a wind farm sitting selection tool: A case study in Southern Greece. Appl. Energy 2009, 86, 2411–2420. [Google Scholar] [CrossRef]
- Foley, A.M.; Leahy, P.G.; Marvuglia, A.; McKeogh, E.J. Current methods and advances in forecasting of wind power generation. Renew. Energy 2012, 37, 1–8. [Google Scholar] [CrossRef] [Green Version]
- De Giorgi, M.G.; Ficarella, A.; Russo, M.G. Short-term wind forecasting using artificial neural networks (ANNs). WIT Trans. Ecol. Environ. 2009, 121, 197–208. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Ficarella, A.; Tarantino, M. Assessment of the benefits of numerical weather predictions in wind power forecasting based on statistical methods. Energy 2011, 36, 3968–3978. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Ficarella, A.; Tarantino, M. Error analysis of short term wind power prediction models. Appl. Energy 2011, 88, 1298–1311. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Tarantino, M.; Ficarella, A. Comparisons of different wind power forecasting systems. In Proceedings of the ASME 2010 10th Biennial Conference on Engineering Systems Design and Analysis, Istanbul, Turkey, 12–14 July 2010; pp. 105–113.
- Flores, A.T.; Tapia, G. Application of a control algorithm for wind speed prediction and active power generation. Renew. Energy 2005, 33, 523–536. [Google Scholar] [CrossRef]
- Beccali, M.; Cirrincione, G.; Marvuglia, A.; Serporta, C. Estimation of wind velocity over a complex terrain using the Generalized Mapping Regressor. Appl. Energy 2010, 87, 884–893. [Google Scholar] [CrossRef] [Green Version]
- Cadenas, E.; Rivera, W. Wind speed forecasting in the South Coast of Oaxaca, Mexico. Renew. Energy 2006, 32, 2116–2128. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. On comparing three artificial neural networks for wind speed forecasting. Appl. Energy 2010, 87, 2313–2320. [Google Scholar] [CrossRef]
- Sfetsos, A. A novel approach for the forecasting of mean hourly wind speed time series. Renew. Energy 2002, 27, 163–174. [Google Scholar] [CrossRef]
- Sideratos, G.; Hatziargyriou, N.D. Probabilistic wind power forecasting using radial basis function neural networks. IEEE Trans. Power Syst. 2012, 27, 1788–1796. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Comprehensive review of neural network-based prediction intervals and new advances. IEEE Trans. Neural Netw. 2011, 22, 1341–1356. [Google Scholar] [CrossRef]
- Taylor, J.W.; Buizza, R. Neural network load forecasting with weather ensemble predictions. IEEE Trans. Power Syst. 2002, 17, 626–632. [Google Scholar] [CrossRef]
- Quan, H.; Srinivasan, D.; Khosravi, A. Short-term load and wind power forecasting using neural network-based prediction intervals. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 303–315. [Google Scholar] [CrossRef]
- Hippert, H.; Pedreira, C.; Souza, R. Neural networks for short-term load forecasting: A review and evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar] [CrossRef]
- Hong, Y.-Y.; Yu, T.-H.; Liu, C.-Y. Hour-ahead wind speed and power forecasting using empirical mode decomposition. Energies 2013, 6, 6137–6152. [Google Scholar] [CrossRef]
- Sideratos, G.; Hatziargyriou, N.D. An advanced statistical method for wind power forecasting. IEEE Trans. Power Syst. 2007, 22, 258–265. [Google Scholar] [CrossRef]
- Chang, W.-Y. Short-term wind power forecasting using the enhanced particle swarm optimization based hybrid method. Energies 2013, 6, 4879–4896. [Google Scholar] [CrossRef]
- Guan, C.; Luh, P.; Michel, L.; Chi, Z. Hybrid Kalman filters for very short-term load forecasting and prediction interval estimation. IEEE Trans. Power Syst. 2013, 28, 3806–3817. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Tarantino, M.; Ficarella, A. A new hybrid method for wind power forecasting based on wavelet decomposition and artificial neural networks. In Proceedings of the ASME Turbo Expo, Turbine Technical Conference and Exposition, GT2011, Vancouver, BC, Canada, 6–10 June 2011; pp. 889–900.
- Mallat, S. A theory for multiresolution signal decomposition and wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- An, X.; Jiang, D.; Liu, C.; Zhao, M. Wind farm power prediction based on wavelet decomposition and chaotic time series. Expert Syst. Appl. 2011, 38, 11280–11285. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F. Short-term load forecasting of power systems by combination of wavelet transform and neuro-evolutionary algorithm. Energy 2009, 34, 46–57. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statiscal Learning Theory; Springer-Verlag: New York, NY, USA, 1999. [Google Scholar]
- Suykens, J.A.K.; van Gestel, T.; Debrebanter, J.; de Moor, B.; Vandewalle, J. Least Squares Support Vector Machines; World Scientific Publishing Co.: Singapore, 2002. [Google Scholar]
- Fan, G.F.; Qing, S.; Wang, H.; Hong, W.C.; Li, H.J. Support vector regression model based on empirical mode decomposition and auto regression for electric load forecasting. Energies 2013, 6, 1887–1901. [Google Scholar] [CrossRef]
- Sreelakshmi, K.; Kumar, P.R. Performance evaluation of short term wind speed prediction techniques. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 162–169. [Google Scholar]
- Mohandes, M.; Halawani, T.O.; Rehman, S.; Hussain, A.A. Support vector machines for wind speed prediction. Renew. Energy 2004, 29, 939–947. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J.; Zeng, G. A hybrid forecasting approach applied to wind speed time series. Renew. Energy 2013, 60, 185–194. [Google Scholar] [CrossRef]
- Li, H.Z.; Guo, S.; Zhao, H.R.; Su, C.B.; Wang, B. Annual electric load forecasting by a least squares support vector machine with a fruit fly optimization algorithm. Energies 2012, 5, 4430–4445. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, J.; Li, G. Fine tuning support vector machines for short-term wind speed forecasting. Energy Conversat. Manag. 2011, 52, 1990–1998. [Google Scholar] [CrossRef]
- Zhang, Q.; Lai, K.K.; Niu, D.X.; Wang, Q.; Zhang, X.B. A fuzzy group forecasting model based on least squares support vector machine (LS-SVM) for short-term wind power. Energies 2012, 5, 3329–3346. [Google Scholar] [CrossRef]
- Blum, A.; Langley, P. Selection of relevant features and examples in machine learning. Artif. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef]
- Vladislavleva, E.; Friedrich, T.; Neumann, F.; Wagner, M. Predicting the energy output of wind farms based on weather data: Important variables and their correlation. Renew. Energy 2013, 50, 236–243. [Google Scholar] [CrossRef] [Green Version]
- Shi, D.; Zhang, H.; Yang, L. Time-delay neural network for the prediction of carbonation tower’s temperature. IEEE Trans. Instrum. Meas. 2003, 52, 1125–1128. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, H. Neural networks approach for prediction of gas-liquid two-phase flow pattern based on frequency domain analysis of vortex flowmeter signals. Meas. Sci. Technol. 2007, 19. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Bello, D.; Ficarella, A. A neural network approach to analyze cavitating flow regime in an internal orifice. In Proceedings of Biennial Conference on Engineering Systems Design and Analysis, ESDA 2012, Nantes, France, 2–4 July 2012.
- Bludszuweit, H.; Dominguez-Navarro, J.A.; Llombart, A. Statistical analysis of wind power forecast error. IEEE Trans. Power Syst. 2008, 23, 983–991. [Google Scholar] [CrossRef]
- Hernández, L.; Baladrón, C.; Aguiar, J.M.; Calavia, L.; Carro, B.; Sánchez-Esguevillas, A.; García, P.; Lloret, J. Experimental Analysis of the input variables’ relevance to forecast next day’s aggregated electric demand using neural networks. Energies 2013, 6, 2927–2948. [Google Scholar] [CrossRef]
- Palomares-Salas, J.C.; Agüera-Pérez, A.; Rosa, J.J.G.; Sierra-Fernández, J.M.; Moreno-Muñoz, A. Exogenous measurements from basic meteorological stations for wind speed forecasting. Energies 2013, 6, 5807–5825. [Google Scholar] [CrossRef]
- Vogl, T.P.; Mangis, J.K.; Rigler, A.K.; Zink, W.T.; Alkon, D.L. Accelerating the convergence of the backpropagation method. Biol. Cybern. 1988, 59, 257–263. [Google Scholar] [CrossRef]
- Demuth, H.; Beale, M.; Hagan, M. Neural Network Toolbox™ 6 User’s Guide; The MathWorks, Inc.: Natick, MA, USA, 2008. [Google Scholar]
- Starzyk, J.; Pang, J. Evolvable binary artificial neural network for data classification. In Proceedings of the 2000 International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA’ 2000), Monte Carlo Resort, Las Vegas, NV, USA, 6–29 June 2000.
- Lange, M. On the Uncertainty of wind power predictions—Analysis of the forecast accuracy and statistical distribution of errors. J. Sol. Energy Eng. 2005, 127, 177–184. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
De Giorgi, M.G.; Campilongo, S.; Ficarella, A.; Congedo, P.M. Comparison Between Wind Power Prediction Models Based on Wavelet Decomposition with Least-Squares Support Vector Machine (LS-SVM) and Artificial Neural Network (ANN). Energies 2014, 7, 5251-5272. https://doi.org/10.3390/en7085251
De Giorgi MG, Campilongo S, Ficarella A, Congedo PM. Comparison Between Wind Power Prediction Models Based on Wavelet Decomposition with Least-Squares Support Vector Machine (LS-SVM) and Artificial Neural Network (ANN). Energies. 2014; 7(8):5251-5272. https://doi.org/10.3390/en7085251
Chicago/Turabian StyleDe Giorgi, Maria Grazia, Stefano Campilongo, Antonio Ficarella, and Paolo Maria Congedo. 2014. "Comparison Between Wind Power Prediction Models Based on Wavelet Decomposition with Least-Squares Support Vector Machine (LS-SVM) and Artificial Neural Network (ANN)" Energies 7, no. 8: 5251-5272. https://doi.org/10.3390/en7085251