1. Introduction
Nowadays, electricity trading is liberalized in most countries of the Western world. Due to the particular characteristics of supply and demand, the prediction of electricity prices in this context is complex. Notwithstanding the difficulties, forecasts are necessary for several reasons:
this is a strategic sector of the economy;
there are financial implications due to the trading of forwards and options;
forecasts help optimize and plan consumption and production.
As with other commodities, there are various ways to operate in this market (see [
1] for a detailed market description and a thorough literature review). We focus on prices that result from a pool in which there is a central auction. In this pool, prices could be settled for each hour of the day, or every half hour, depending on the market.
In the first case, the 24 hourly prices for day
t are cleared at the same instant in day t − 1, with the same common information for all of the hours. Therefore, for each day, a 24-dimensional vector is generated
; where
represents the price of hour
at day
t. Consequently, prices can be presented in a
dimensional matrix, where
T is the number of days in the sample, and modeling should be multivariate (as in [
2,
3,
4,
5]).
In several fields, there has been an increasing interest in the development of a methodology to deal with multivariate time series or a high dimensional vector of series. By the end of the 1970s, [
6] (these authors presented a factor model for stationary time series vectors) and [
7] were the first to propose a dynamic factor model. Later, [
8] contributed by extending the idea of principal components to the dynamic case. More recently, dimensionality reduction techniques have gained popularity, in particular since the work by [
9]. For example, [
10,
11] extended [
6]’s model for the non-stationary case.
Regarding applications in electricity markets, [
12] extended [
8,
13] to prices with seasonality. Working with data for the Iberian market for 2007–2009, they propose extracting common factors from the 24-dimensional price vector and modeling such factors as univariate seasonal AutoRegressive Integrated Moving Average (ARIMA) processes. The work in [
5] proposes a technique called Seasonal Dynamic Factor Analysis (SeaDFA), which involves the estimation of a Vector AutoRegressive Integrated Moving Average (VARIMA) model for unobserved common factors having seasonal patterns. The work in [
14] also uses a factor model, including not only hours, but also locations.
In an independent path, forecast combination or model averaging has been developed as a technique to take advantage of the availability of alternative forecasting approaches. This methodology consists of weighting a set of forecasts corresponding to alternative models and combining them to obtain a single forecast. In this way, model selection uncertainty is incorporated. According to [
15], “the idea of combining forecasts implicitly assumed that one could not identify the underlying process, but that different forecasting models were able to capture different aspects of the information available for prediction”. Other justifications for model averaging are: doubts of the existence of a “best model” [
16], “portfolio diversification”, a better adaptation to structural breaks or to average out omitted variables’ bias [
17].
Applications of model averaging in electricity markets are given by [
18] (for the British market) and [
19] (for European and USA markets). Furthermore, [
20] obtain forecasts for the daily average price employing dimensionality reduction techniques, as well as the forecast combination of several models for hourly prices. Other references are [
21], who use averaging to obtain wind speed, solar irradiation and temperature forecasts, which are employed to estimate prices; and [
22], who forecast hourly electricity prices for the Spanish market by weighting seasonal ARIMA (with exogenous variables) and seasonal dynamic factor models of similar performance.
A major drawback of dimensionality reduction techniques is the uncertainty regarding the “correct” model: how many factors to include, and what models they follow. The literature is not definite in regards to the best technique for estimating the number of underlying factors that would contain enough information to make accurate predictions, considering that, as the number of factors included increases, so does estimation complexity and computational burden. As previously indicated, there is no unique model for these factors that outperforms all other models in all circumstances [
1].
In this work, it is hypothesized that the major decisions attached to forecasting by using dimensionality reduction techniques may be resolved in a less arbitrary way if forecast combination is included. In order to follow this course, alternative models, including different numbers of common factors, are estimated. Forecasts are obtained by transforming the factors’ forecasts back to the data units, according to the relations established in the dimensionality technique employed. Subsequently, forecast combination approaches are used to weight each of the forecasts obtained and, thus, to provide a single prediction.
Summing up, factor models extract information ex ante (before any forecast is obtained), while forecast combination works ex post (after forecasts are available). The contribution of this work is to amalgamate both techniques. A reduced number of latent unobserved variables is estimated, and their forecasts are combined in order to obtain a single prediction.
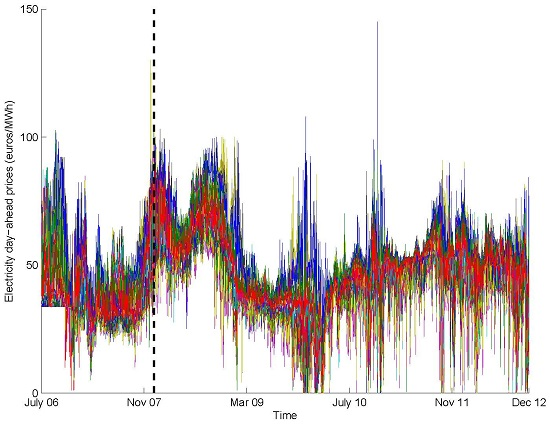
We apply these techniques to one-day-ahead electricity prices for the Iberian spot market for a period of five years. Several ARIMA specifications (for each one of the common factors included in the analysis, 36 choices of parameters are available: , , , , , , ; these pre-defined models are all automatically estimated with the software TRAMO, by its MATLAB interface, intervening outliers.) are estimated for the factors and used to obtain forecasts of the prices for each hour, which makes the task computationally intensive. Next, these forecasts are combined. We study alternative ways to combine forecasts because their performance may vary depending on the dataset. The predictions concern mainly the short- and medium-term (one and two months), but a one-year extension is presented to illustrate the potential accomplishments in long-term forecasting.
The rest of the paper is organized as follows. Fundamentals containing a mathematical description of the proposed methodology are presented in
Section 2, which includes definitions on dynamic factor models, classical techniques for forecasts combination and Bayesian model averaging.
Section 3 describes the methodology for this paper. In
Section 4 , we present the results of the empirical application. This section is divided into sub-sections presenting the data, an analysis of variance (ANOVA) comparing specifications, and forecasting results. Finally,
Section 5 concludes with remarks, limitations and possible extensions.
3. Methodology
Taking into account the limitations of existent approaches in dimensionality reduction, most importantly the issue of selecting a number of common underlying factors r, as well deciding for a “best” model for them, and given the advantages of forecast combination revisited in the previous sections, our methodological proposal consists of averaging the forecasts of alternative models for each factor.
This allows capturing the factors underlying the behavior of large datasets, avoiding the risk of committing to a particularly “bad” specification for them. That is why we consider that this approach improves previously-mentioned solutions to open problems described along
Section 1 and
Section 2.
The complete prediction procedure can be summarized in the following steps, repeated for each window of time in the dataset. Notice that each window of time provides a historical dataset, as well as out of sample data with which the forecasts will be compared.
For each window of time, the factors underlying the data are estimated by means of SVD, as explained in
Section 2.1. There are as many common factors as time series in the dataset,
m. However, the purpose of applying dimensionality reduction techniques is to be able to describe the data by means of a much smaller number of variables, thus
. There are many criteria for estimating the value
r that would best represent the underlying trends in the data. In this regard, a contribution of this work is that, instead of committing to one of them, the possibility of estimating several models is explored. For this reason, two settings are estimated: on the one hand,
, which means that only the underlying factor most representative of the data variability is used to forecast; and on the other hand,
, which means that the first and second most important underlying factors are estimated and employed to obtain forecasts.
As indicated in the flowchart, the next step consists of estimating models for the factors. The literature review performed in this work reveals that it is difficult, if not impossible, to find a model that by all criteria would outperform all others. Even more, a good fit does not guarantee an accurate forecasting performance. To overcome these difficulties, our proposal consists of fitting 36 ARIMA specifications for each estimated factor, in lieu of selecting a “best” set of parameters. These specifications result from the following parameters: , , , , , , . Additional values of the parameters (for example, ) are excluded because they increase the computational burden, but do not provide a relevant improvement in results.
After forecasts are estimated for all of the options of factors (either one or two) and ARIMA models, they are transformed to forecasts for the original variables, by means of a multiplication by the matrix of weights following Equation (
1). This will render many forecasts for the data, which will be combined to present a single forecast for each variable of the original dataset.
Forecast Combinations and Accuracy Metrics
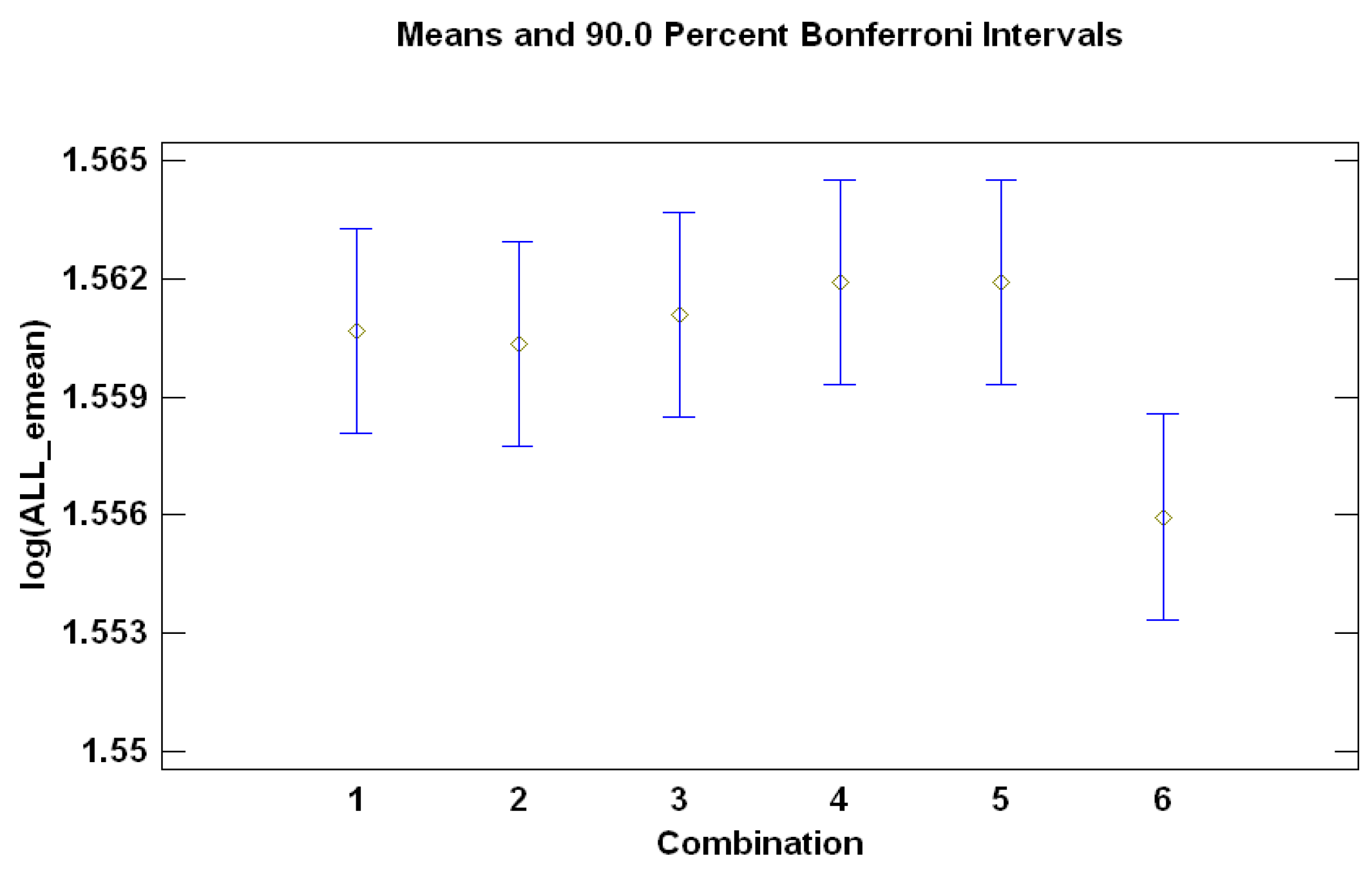
We consider five alternative combinations (2–6 below) and compare them to a benchmark (1 in the next enumeration):
Forecast resulting from the benchmark model (the ‘BIC-selected model’). This is the best model according to the BIC (has the lowest BIC). Selecting only one model is equivalent to assigning it a weight
(Equation (
3); superscript
has been eliminated because weights will not be adaptive to the forecasting horizons, and subscript
t has also been omitted to avoid confusion with time-varying weights), and
for all other models.
Forecast calculated as the median of the forecasts of all of the models (the “median-based combination”). This is also a case of weights , for the model with the median forecast, and for all other models.
Forecast equal to the mean of all forecasts (“mean-based combination”). In this case, Equation (
3)’s weights are all equal
, where
K is the total number of models in the analysis.
Forecast obtained using BIC-based weights as in Equation (
6) (“BIC-based combination”). This approach involves equal a priori probabilities. Other sensible sets of a priori probabilities were considered, and similar results were obtained. For the sake of concreteness, those results are not presented hereby, but are available upon request to the authors.
Forecast obtained with BIC-based weights for the top 50% models (“BIC-50% combination”). In other words, half of the models are included according to their BIC criterion
of Equation (
6), and for the half that has the largest BIC values,
. Let us recall that the BIC evaluates the fit of the model, not how accurate it is when used to forecast.
Forecast calculated as the mean of the forecasts of the top 50% models (“mean BIC-based combination”). Only half of the models are included (the “best” half of the models depending on their BIC), and the forecast combination is simply their average. In other words, the 50% of models with the lowest BIC are assigned weights , and the 50% of models with the greatest BIC are assigned weights .
In order to evaluate forecasts and to assess the most appropriate combination, we need to define a forecasting accuracy metric. We can evaluate the forecasts’ accuracy by means of several alternative metrics (see [
1,
39,
40] for a detailed review). Some of them are the relative forecast error, and the mean (and median) average percentage error (MAPE). However, these measures are not valid when the data have negative and/or positive, but close to zero, values [
40], a frequent occurrence for many electricity prices ([
21,
41] deal with the issue of forecasting extreme prices in the Spanish electricity market).
Therefore, we use the mean absolute error (MAE) and median absolute error (MedAE). They can be obtained as follows:
and:
where
m is the number of days in the out-of-sample period and
τ is the last observation of the rolling window employed to estimate the model used to compute the forecasts.
5. Conclusions and Further Lines of Research
In this paper, dynamic factor models and forecast combination techniques have been jointly employed to obtain predictions of spot market electricity prices in the Iberian market. The main contribution consists, therefore, of combining two streams of literature in order to obtain forecasts that outperform those resulting from the individual models. In this respect, there are three combinations that clearly outperform the benchmark: the median-based combination, the mean-based combination and the mean BIC-based combination. This conclusion is supported by the ANOVA of the combinations for forecast horizons one-day-ahead, seven-days-ahead, 30-days-ahead and 60-days-ahead. For the extended prediction (up to one-year-ahead, taking the case of the year 2012), the results point out that the benefit of forecast combinations is greater for the medium/large forecast horizon than for the short term.
In the process of trying to obtain the best possible results, different aspects of the available models were compared. In this regard, the main conclusions are that longer historic datasets benefit longer forecasting horizons, and the error is reduced by the inclusion of MA terms when modeling the unobserved factors (vs. AR models).
This application reflects how the methodology works for a current dataset. The numerical results for electricity prices, which is a difficult to predict series, are good. An effort has been made to obtain the results for many time horizons ( to ), for every day and hour for 1 January 2008–31 December 2012 and considering several models for the factors, enhancing the validity of our proposal. In other words, forecasts are obtained for the very short (one day) and short term (a few days ahead), like most of other works, as well as for the medium term, which is an extension not customary in the literature. As previously explained, this approach can be employed to obtain long-term forecasts (even up to a year) not experiencing a degradation of accuracy, which is a drawback that most applications suffer from.
Numerous lines of research remain open in relation to this topic. For instance, in this work, few techniques for combining forecasts are employed besides the mean, and weights depend on the overall performance of the particular model to be used in the combination in terms of the BIC information criterion. However, there are several other, Bayesian and classical techniques to determine such weights. In particular, it would be interesting to compare the performance of both types of techniques. Furthermore, in this article, we have mostly worked with fixed weights; however, these could change in a predefined way for different forecasting horizons. Furthermore, weights could be adaptive to the performance of the models (as in [
16]).
The use of ARIMA models for the common factors allows one to maintain the number of parameters to estimate low, but it may also signify a constraint in the improvement that can be achieved from the combinations of forecasts. A future line of work is including other models for the factors, such as the SeaDFA of [
5] (when employing the SeaDFA formulation, it is assumed that
follows a VARIMA model) or the Generalized AutoRegressive Conditionally Heteroscedastic (GARCH)-SeaDFA.
It is also left for future work to incorporate in the forecast combination other forecasting methods (not necessarily involving DFM); for example, the predictions obtained by the mixed model in [
4], which presents extremely accurate short-term predictions for the Iberian market. With weights evolving for different time-horizons, including this model for short-term predictions could improve the results.
A further improvement could consist of employing explanatory variables that drive spot prices in the models. Some examples of these variables are demand, weather conditions, fuel prices, production by technology and excess capacity. Interesting references are [
21,
41]. However, for this, it would be necessary to assess if the uncertainty in the prediction of the explanatory variables does not outweigh the improvement in the forecast of the price. In a similar line of research, regime switching models could be employed to deal with spikes in the price series.
Last, bootstrap procedures could be used to obtain confidence intervals of the predictions and, in this way, assess the uncertainty involved in the forecasts.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







