
Length-Bounded Hybrid CPU/GPU Pattern Matching Algorithm for Deep Packet Inspection


Abstract
:1. Introduction
2. Related Work
3. Length-Bounded Hybrid CPU/GPU Pattern Matching Algorithm
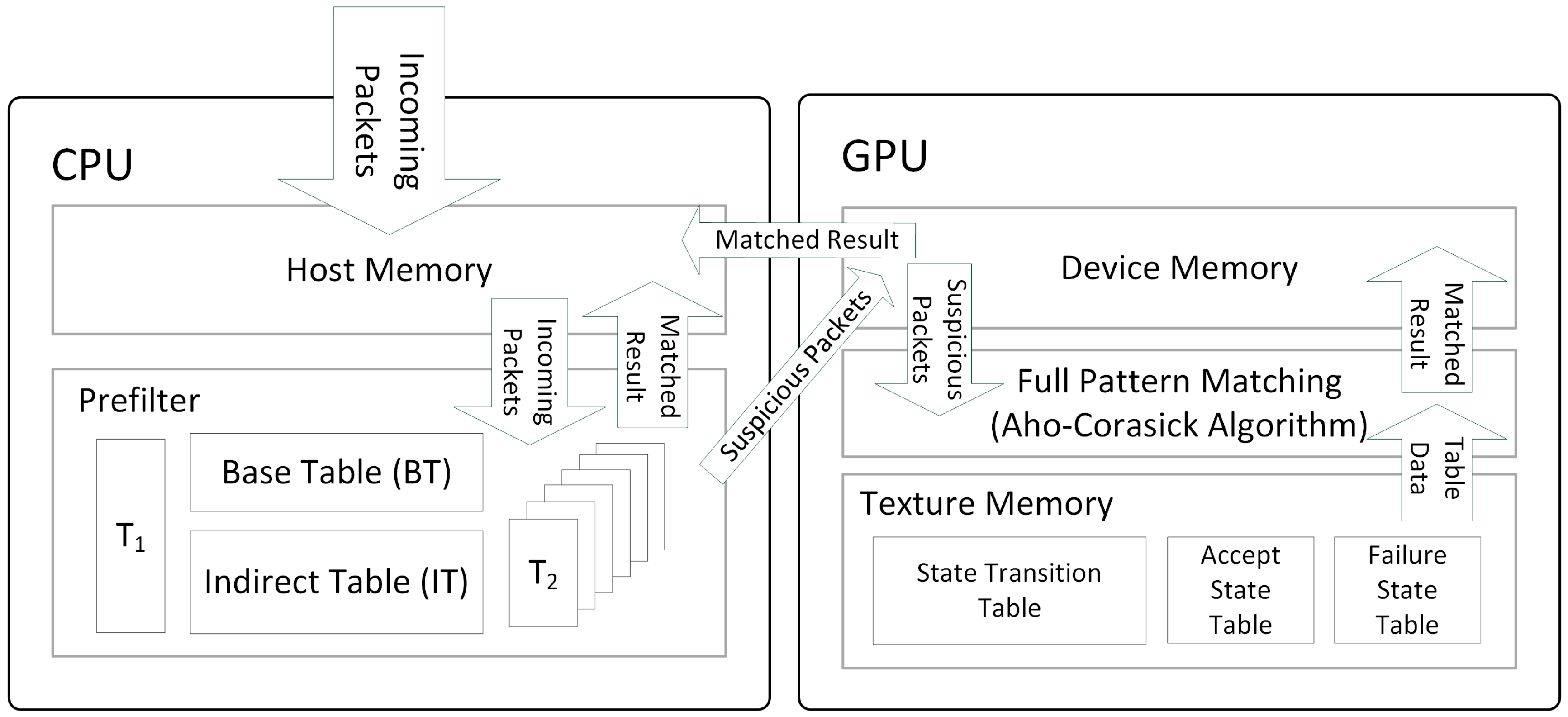
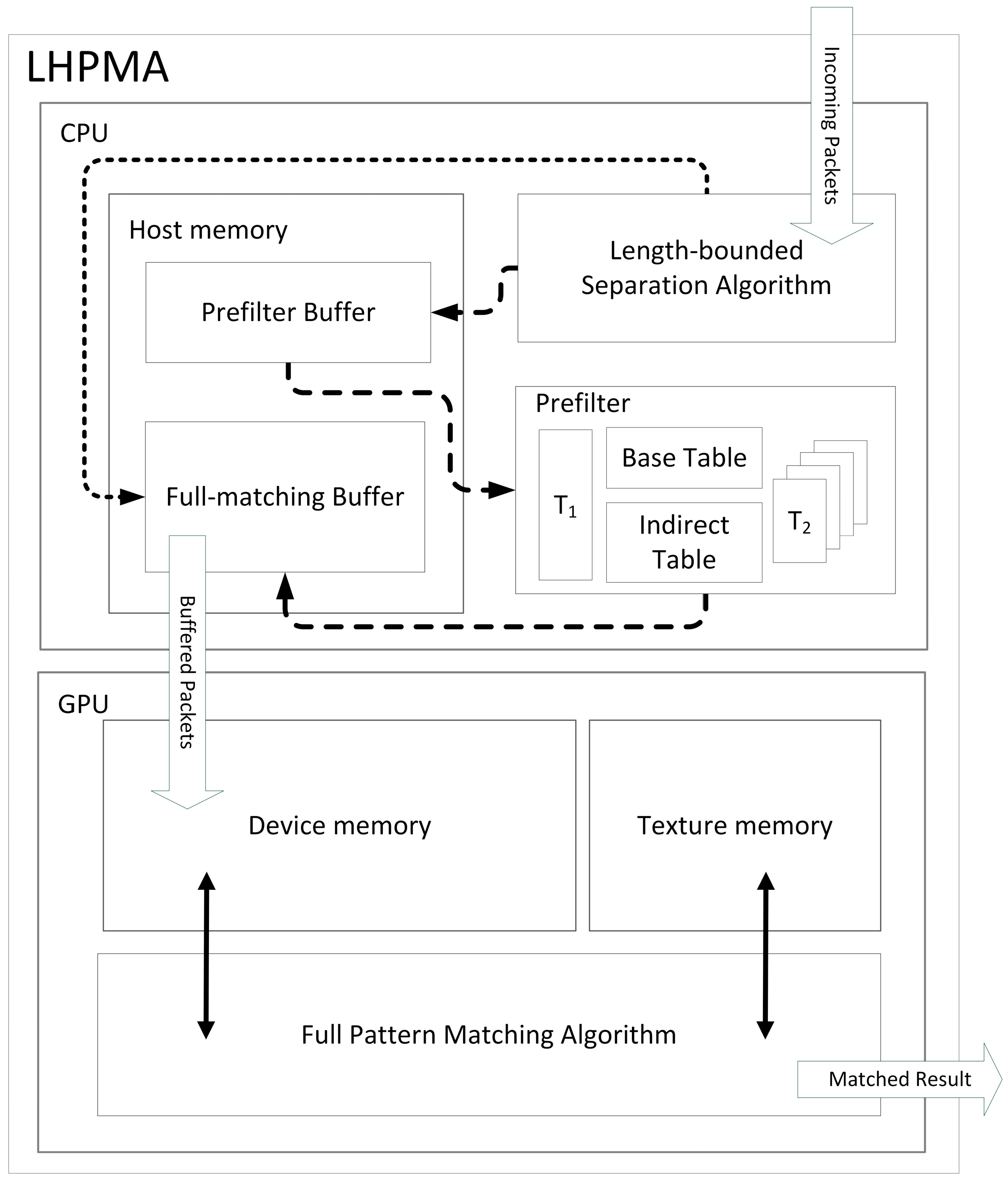
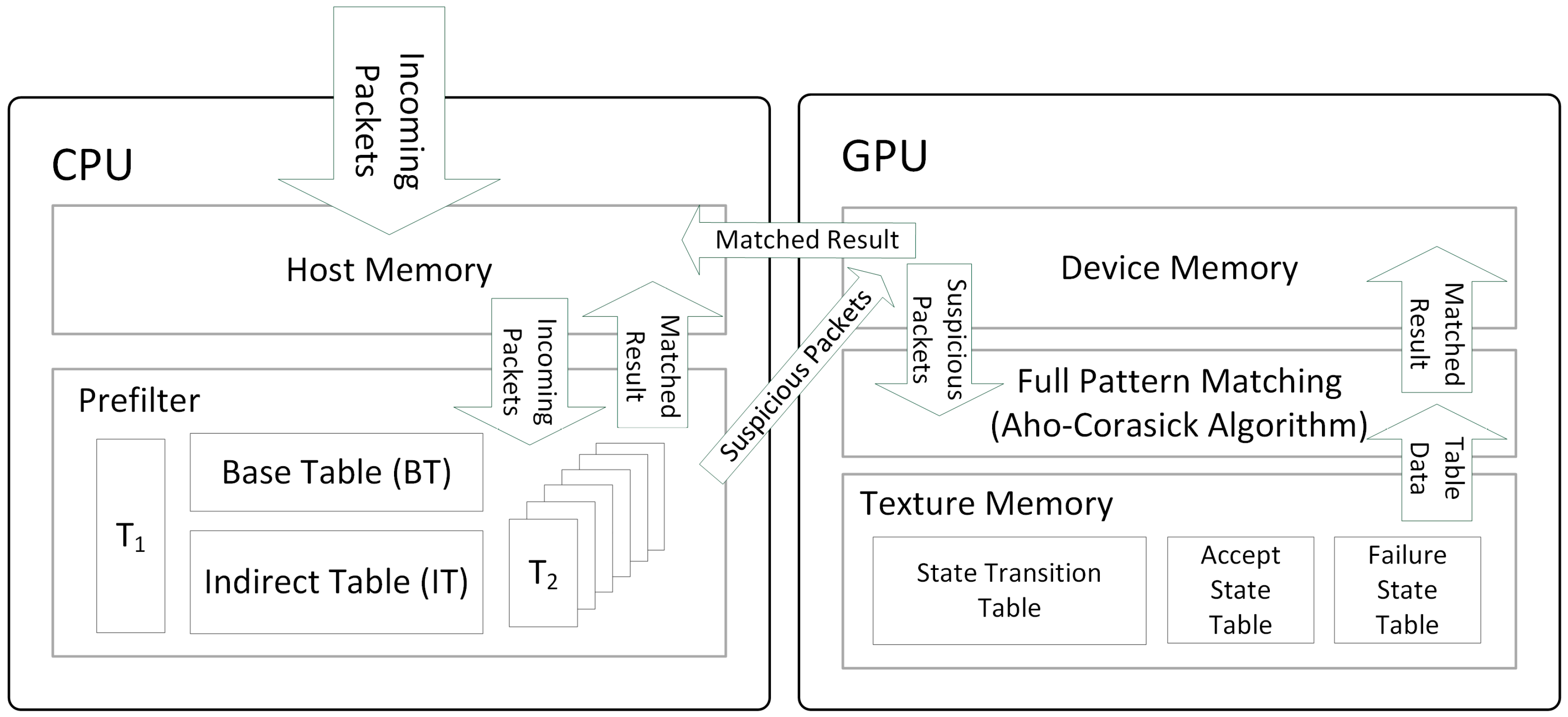
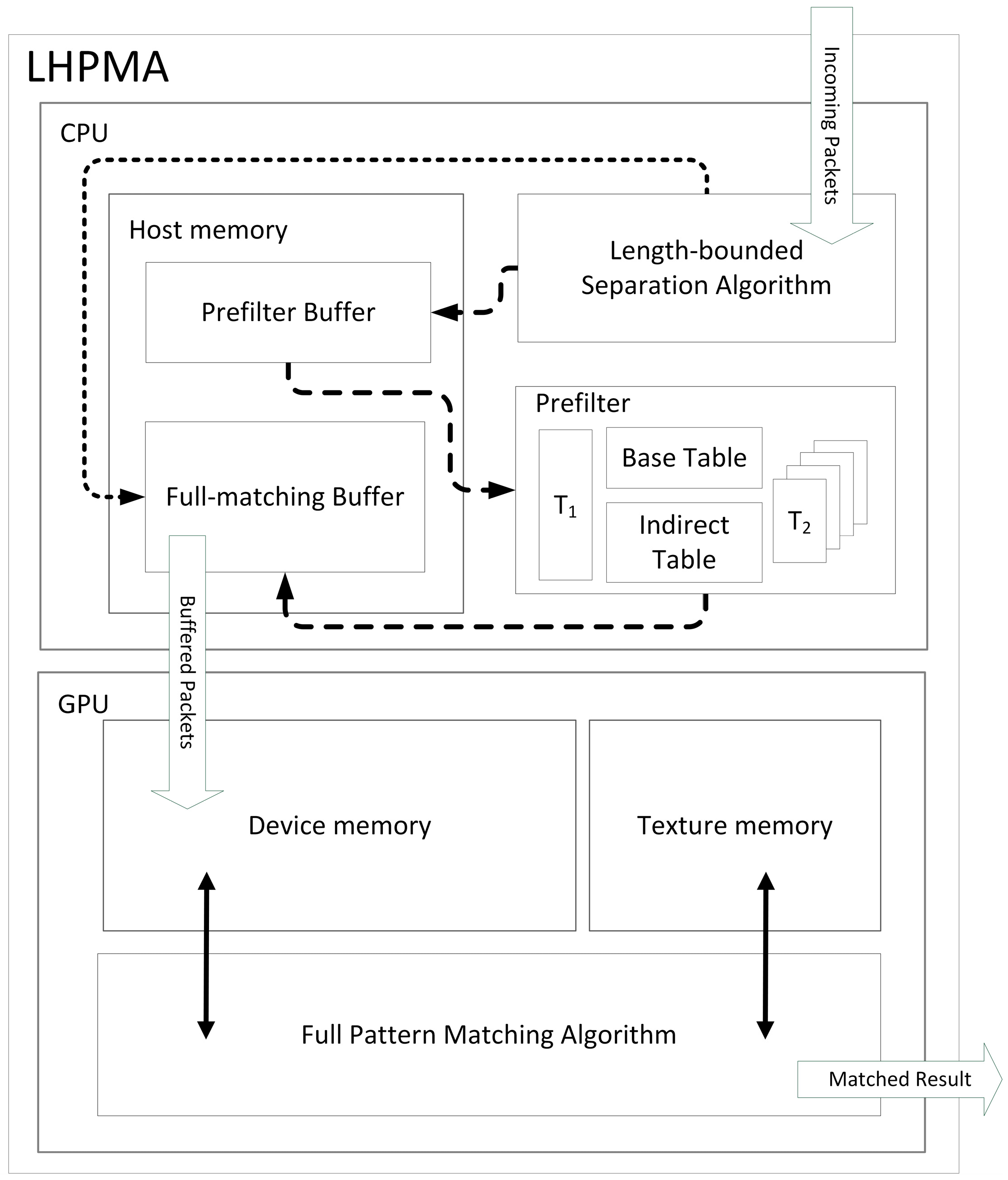
3.1. Overall Architecture and Procedure
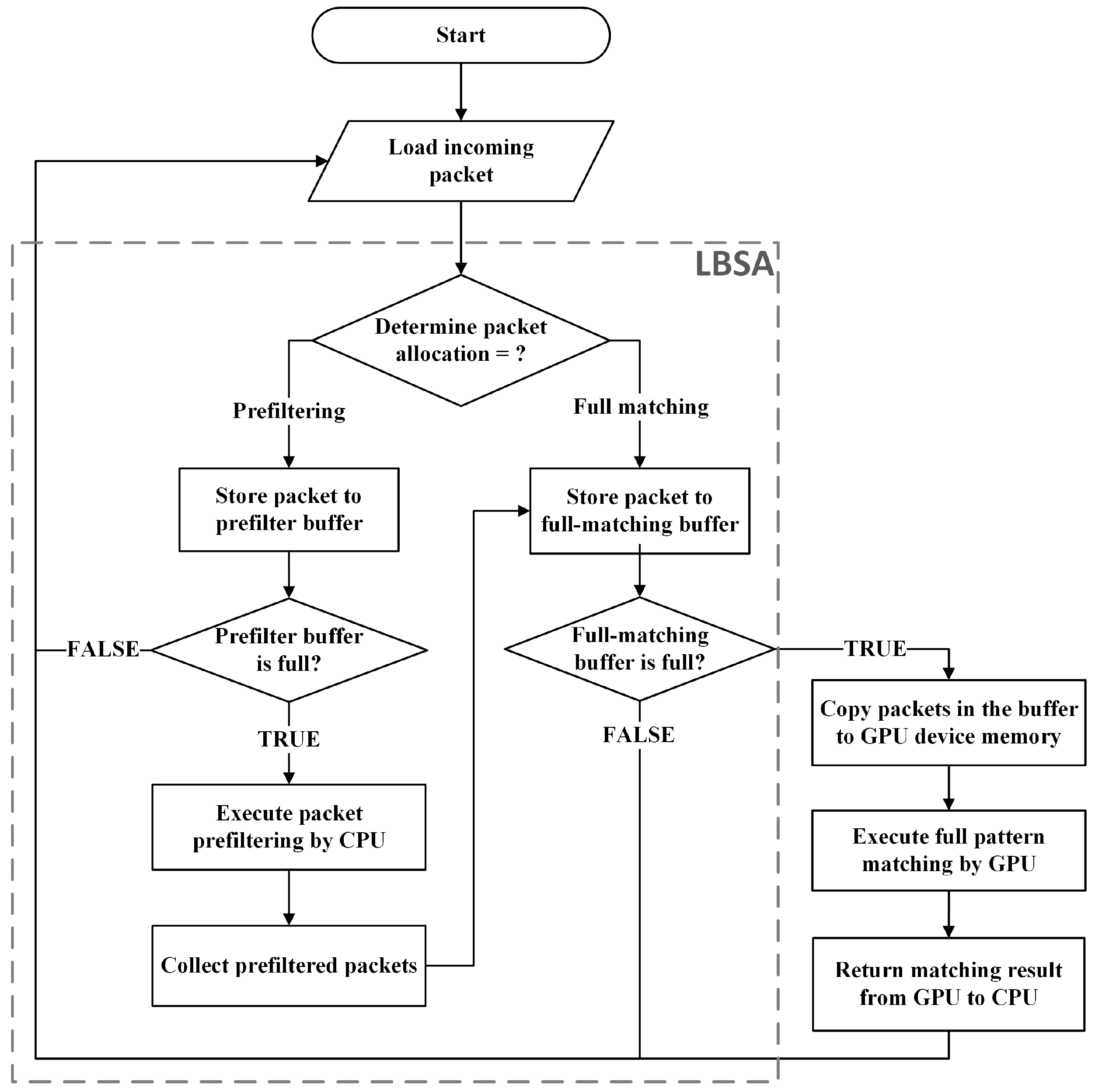
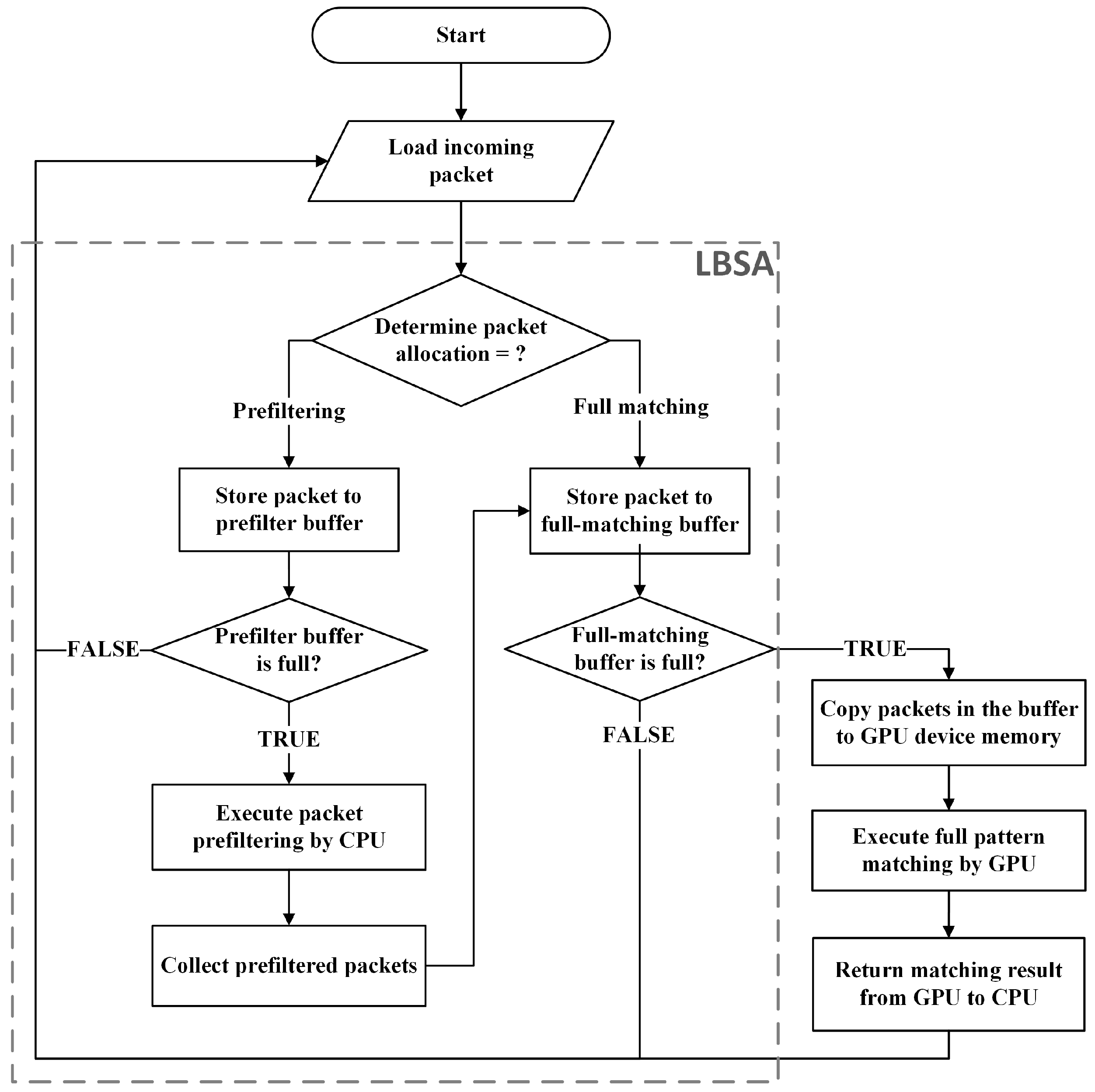
3.2. Length-Bounded Separation Algorithm
| Algorithm 1: Length-Bounded Separation Algorithm (LBSA). | |
| Input: P (packet payload set) and Lb (length boundary). | |
| 1 | TPB ← empty; // Prefilter buffer |
| 2 | TFB ← empty; // Full matching buffer |
| 3 | Pfiltered ← empty; // Prefiltered payloads |
| 4 | idxPB ← 0; // Index of prefilter buffer |
| 5 | foreach Pi do |
| 6 | Li ← payload length of Pi; |
| 7 | if Li > Lb then |
| 8 | TPB [idxPB] ← Pi; // store Pi in prefilter buffer |
| 9 | idxPB ← idxPB + 1; |
| 10 | else |
| 11 | TFB ← TFB ∪ Pi; // store Pi in full matching buffer |
| 12 | end |
| 13 | |
| 14 | if TPB is full then |
| 15 | Pfiltered ← prefiltering(TPB); // execute prefiltering algorithm and |
| 16 | TFB ← TFB ∪ Pfiltered; // store Pfiltered in full matching buffer |
| 17 | Pfiltered ← empty; |
| 18 | TPB ← empty; |
| 19 | idxPB ← 0; |
| 20 | end |
| 21 | |
| 22 | if TFB is full then |
| 23 | result ← fullmatching(TFB); // execute full matching algorithm and |
| 24 | TFB ← empty; // return the matching result |
| 25 | end |
| 26 | end |
4. Experiments
4.1. Experimental Setup
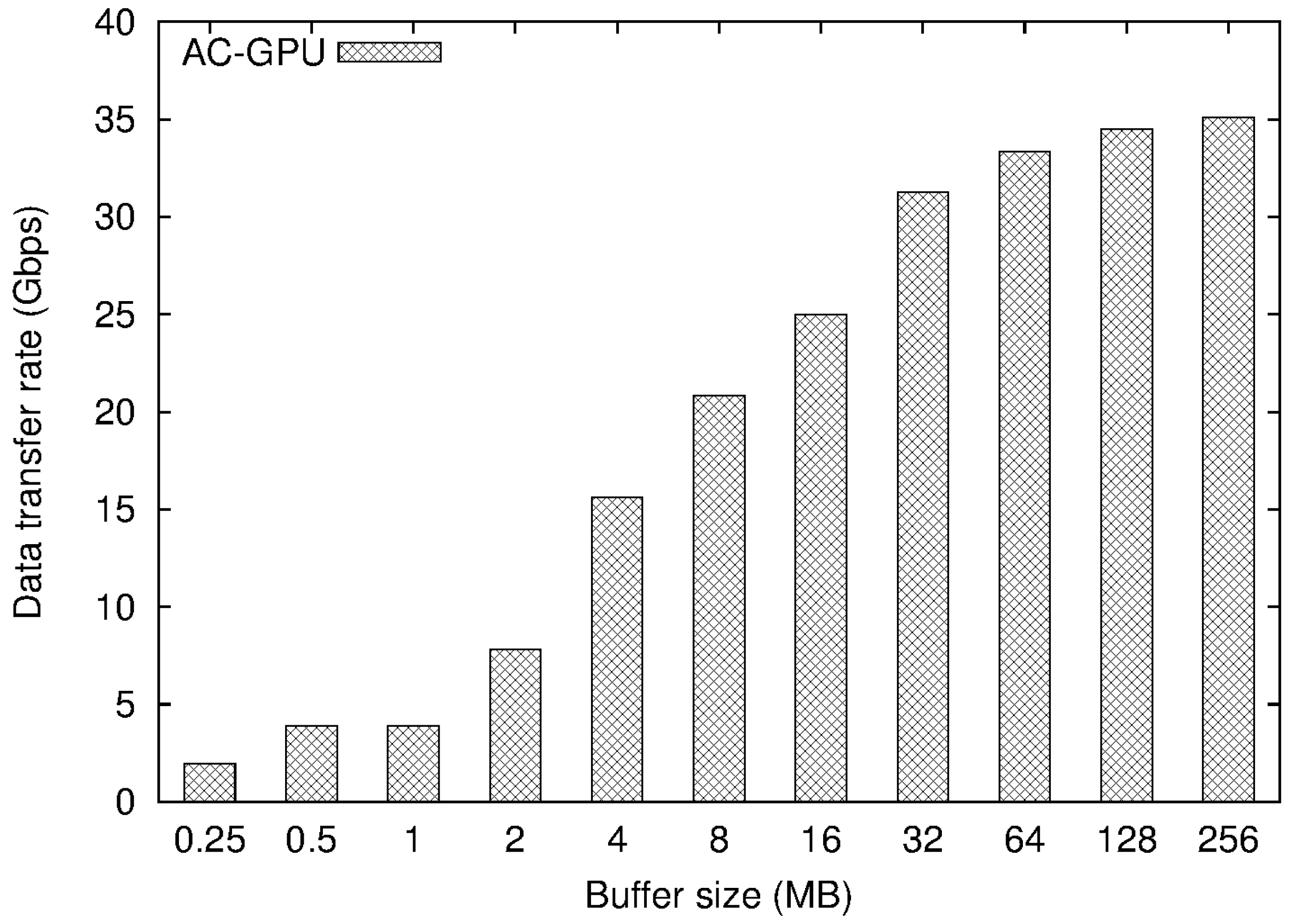
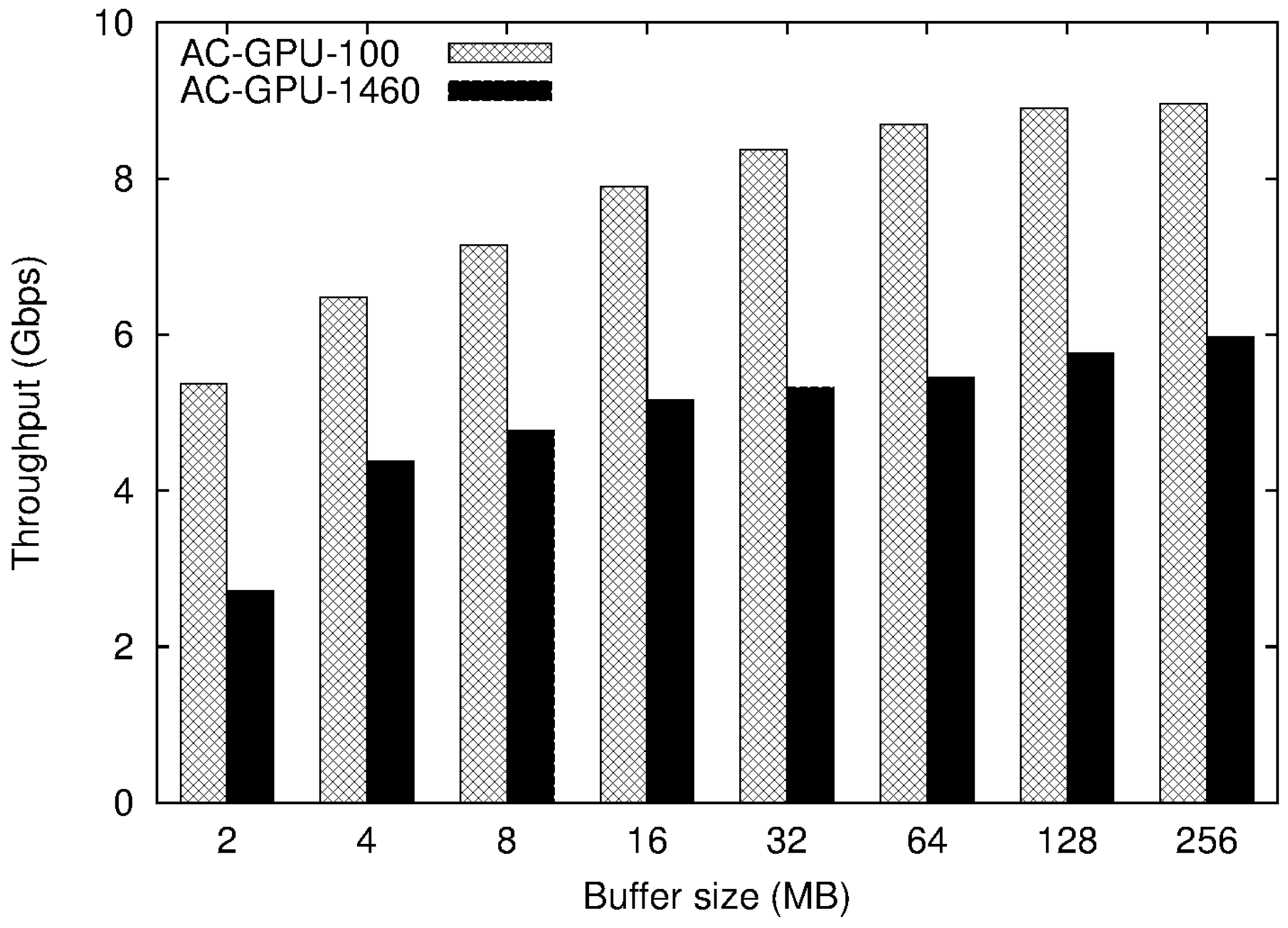
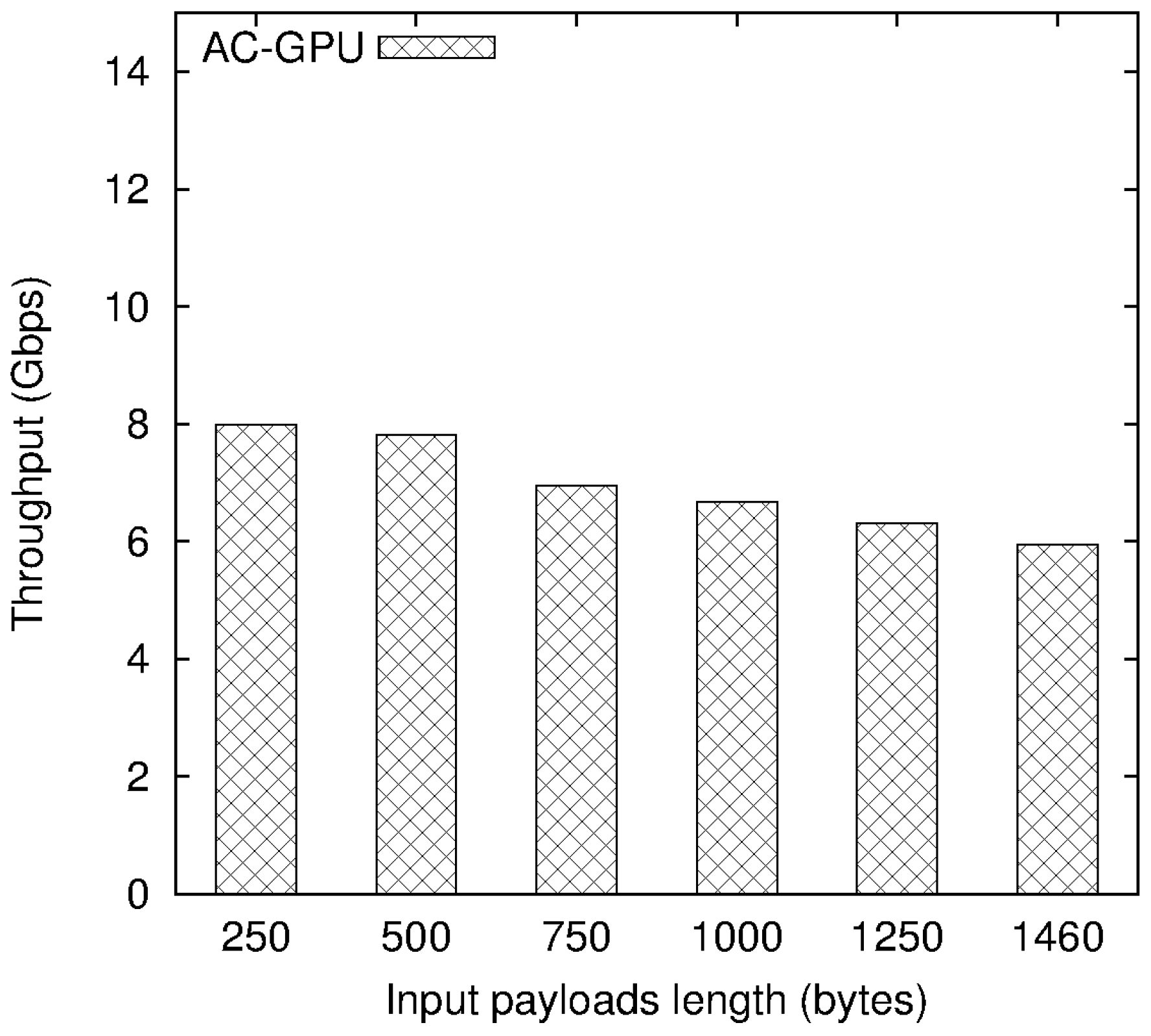
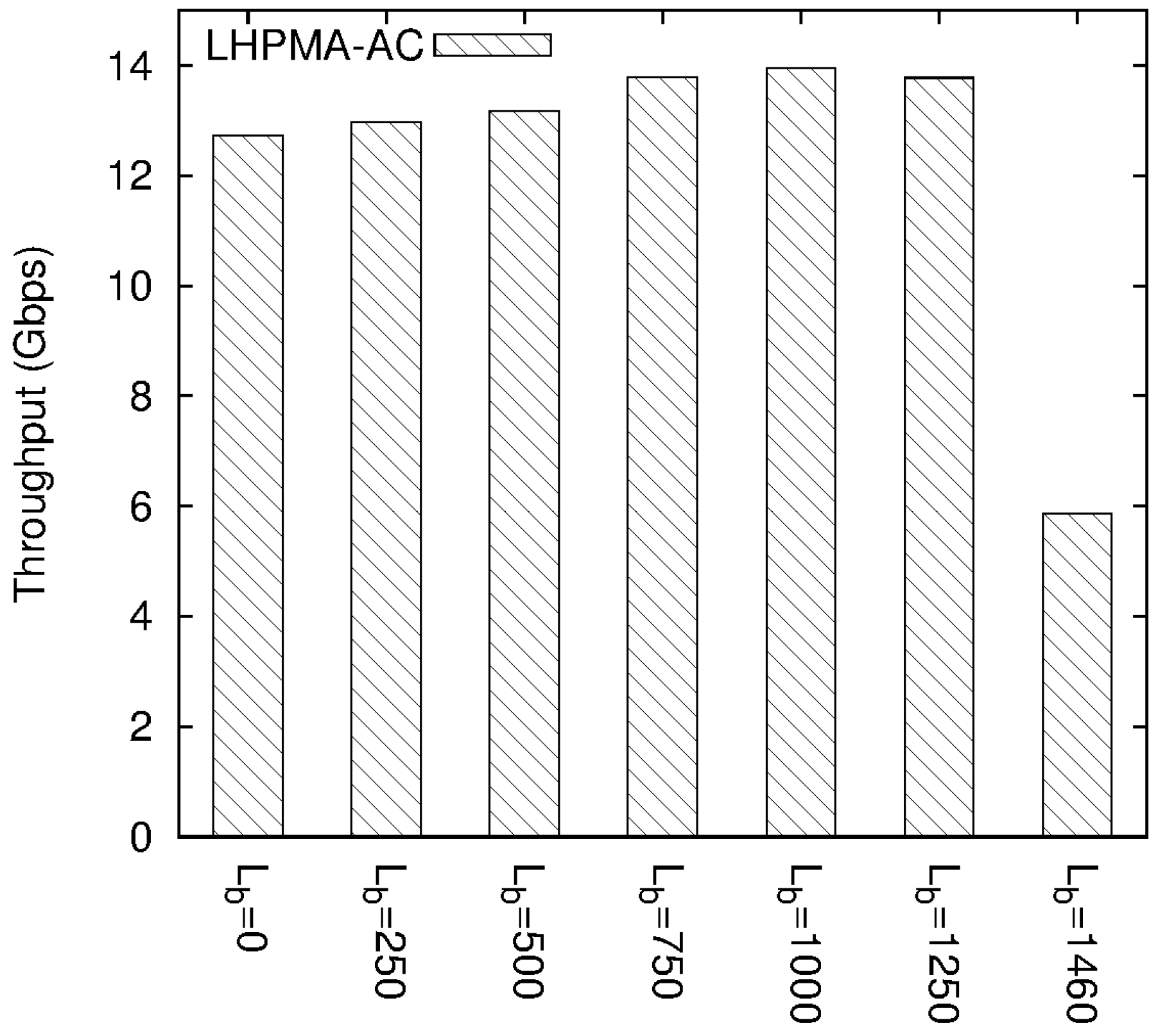
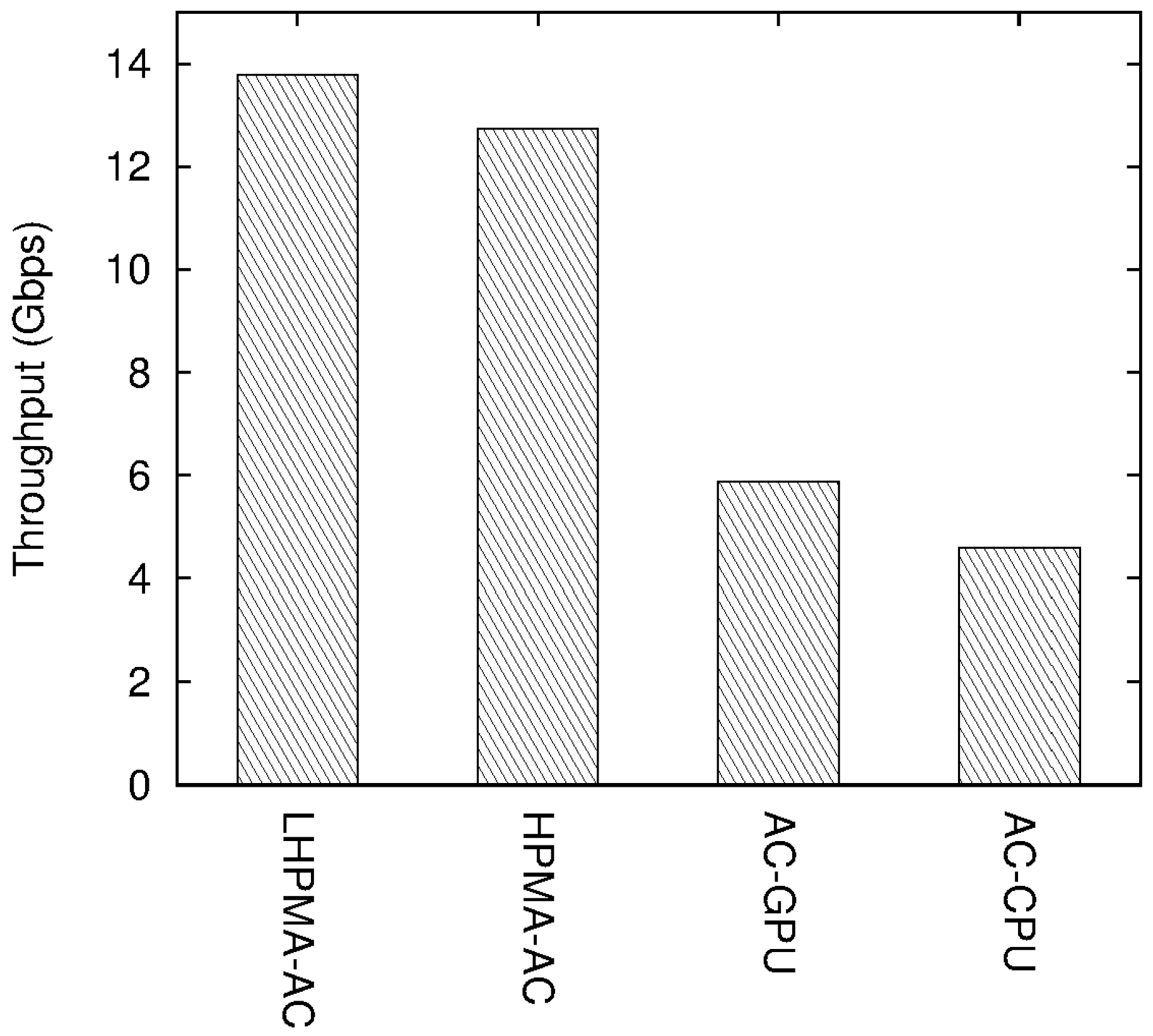
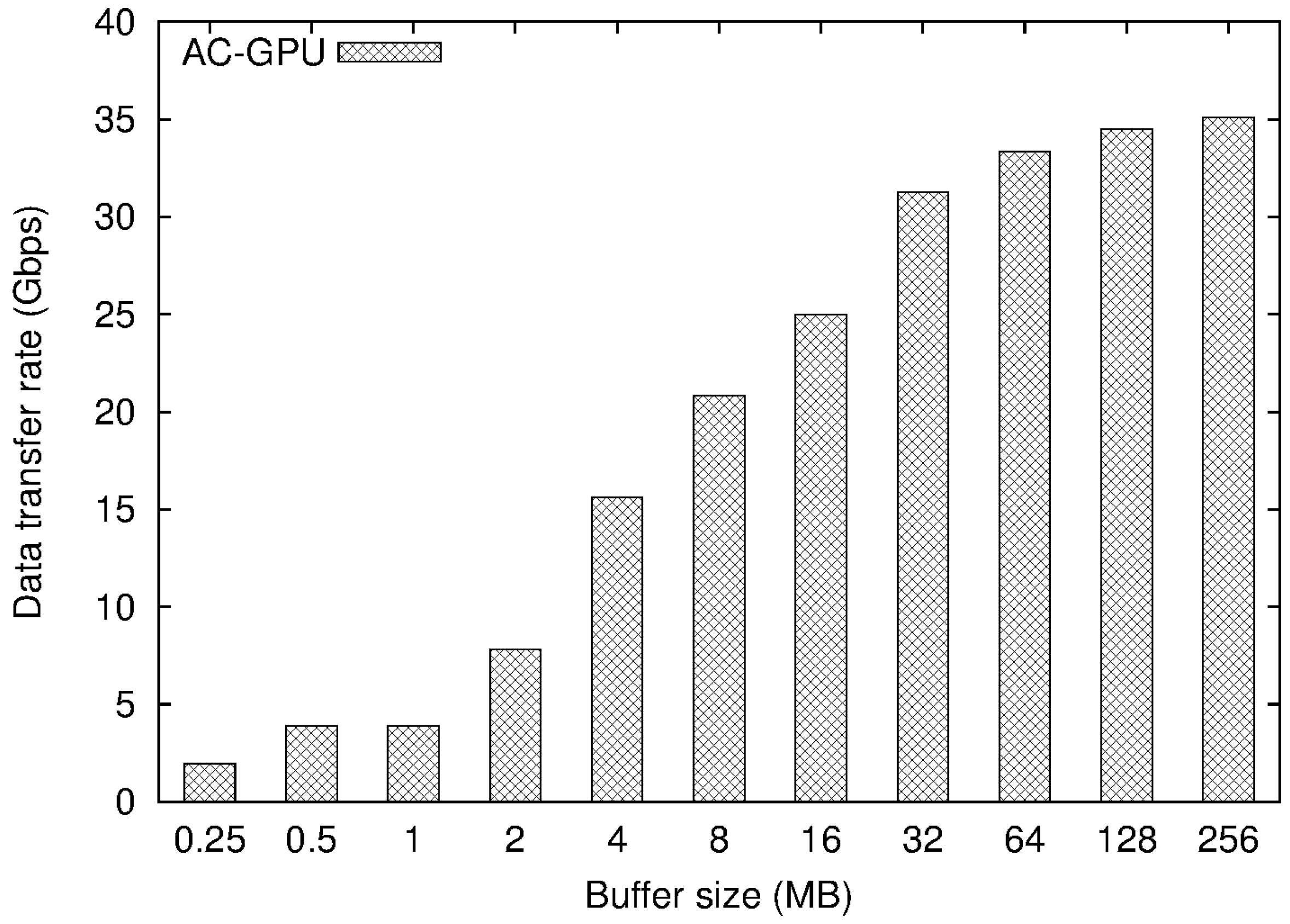
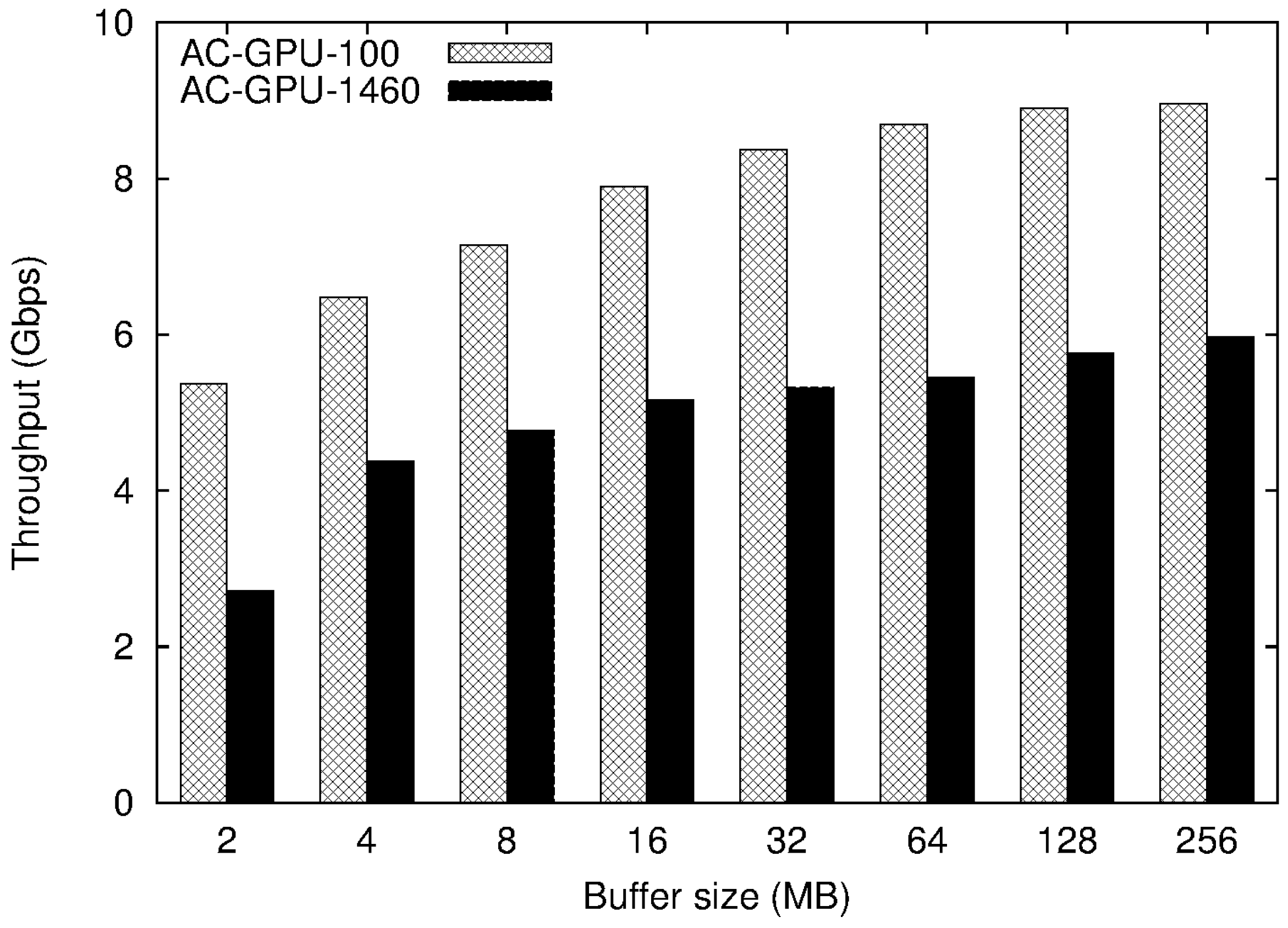
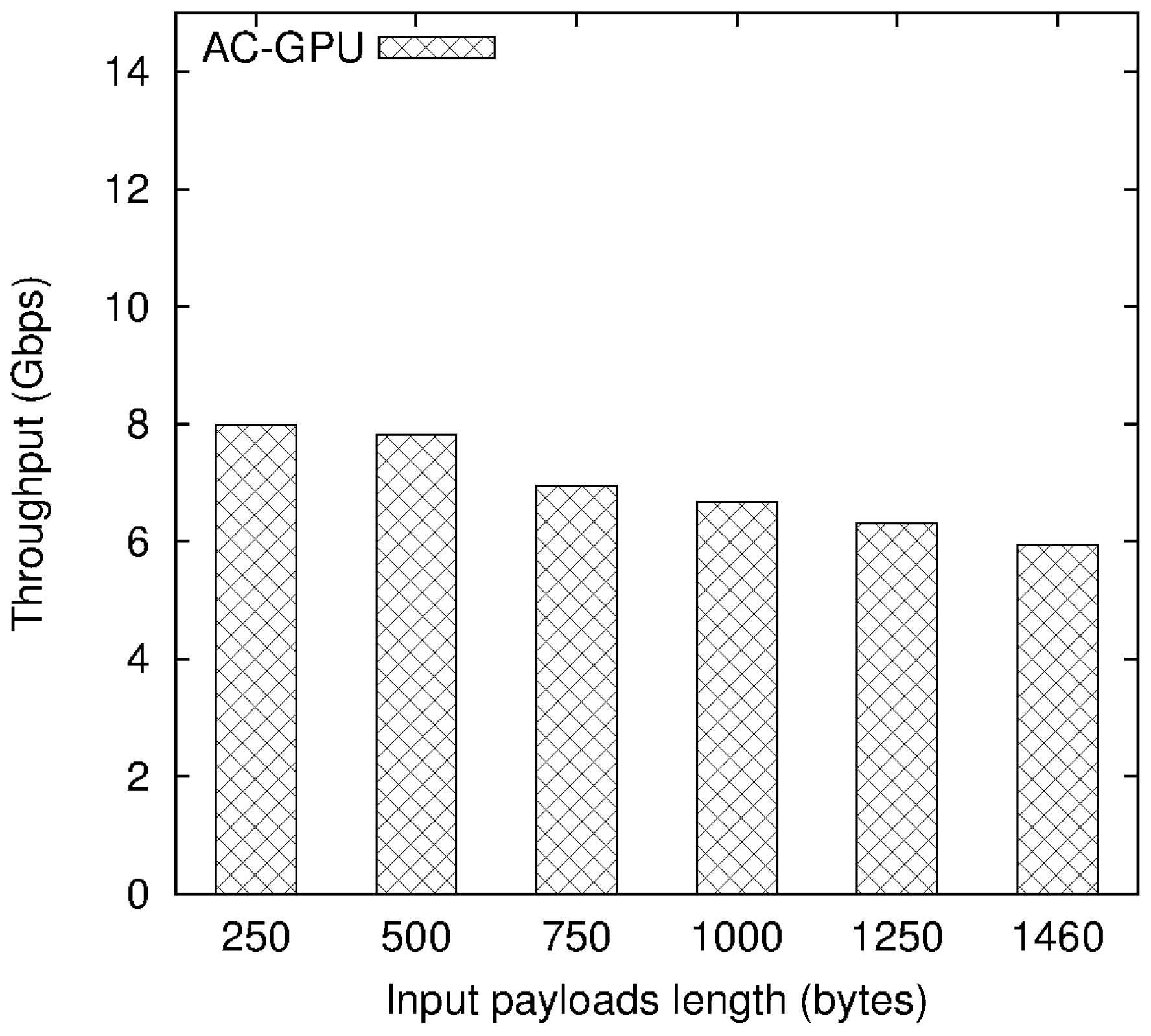
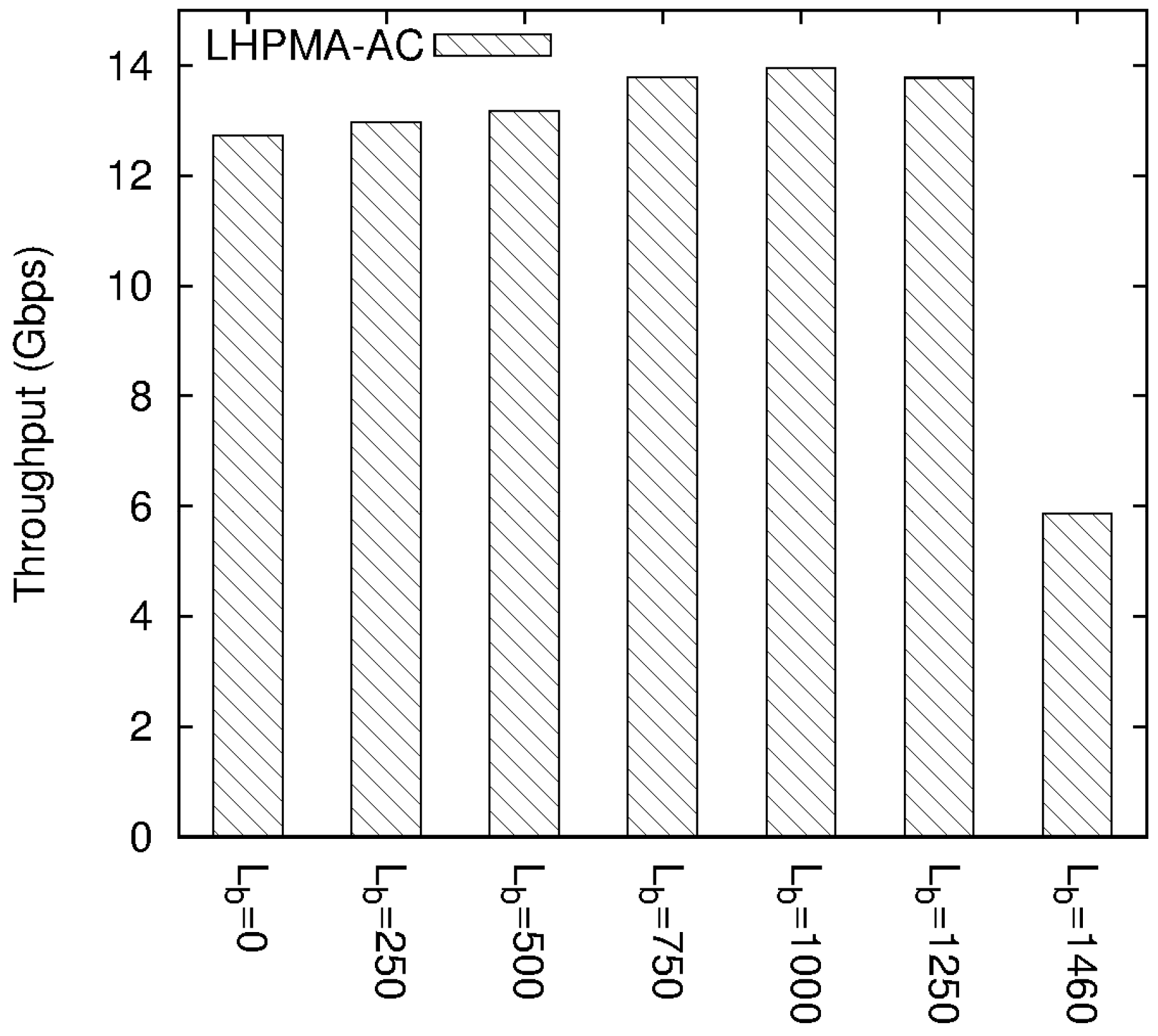
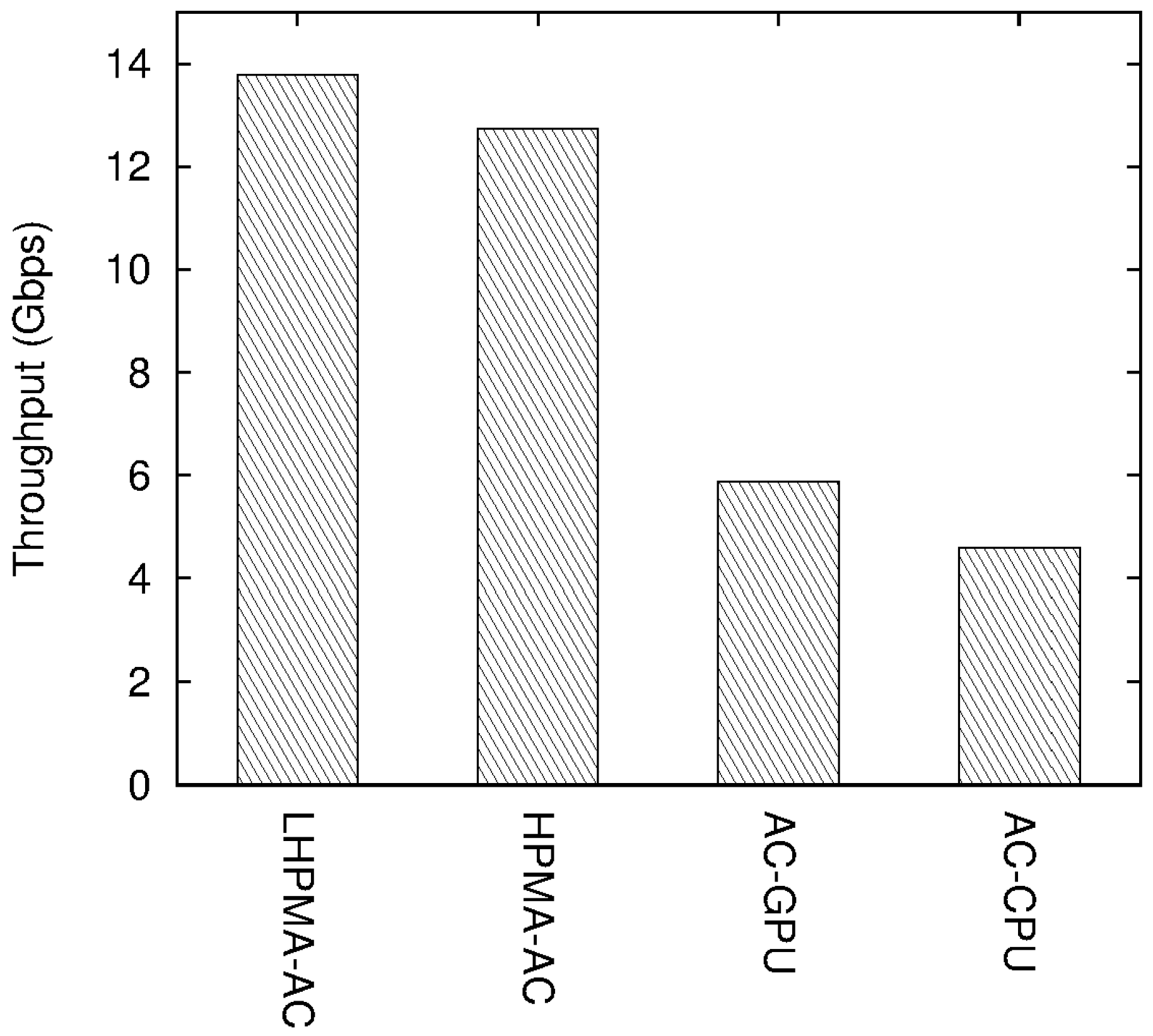
4.2. Experimental Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Handley, M.; Paxson, V.; Kreibich, C. Network intrusion detection: Evasion, traffic normalization, and end-to-end protocol semantics. In Proceedings of the Symposium on USENIX Security, Washington, DC, USA, 13–17 August 2001; pp. 115–131.
- Kruegel, C.; Valeur, F.; Vigna, G.; Kemmerer, R. Stateful intrusion detection for high-speed networks. In Proceedings of Symposium on Security and Privacy, Oakland, CA, USA, 12–15 May 2002; pp. 285–293.
- Paxson, V. Bro: A system for detecting network intruders in real-time. Comput. Netw. 1999, 31, 2435–2463. [Google Scholar] [CrossRef]
- Tian, D.; Liu, Y.H.; Xiang, Y. Large-scale network intrusion detection based on distributed learning algorithm. Int. J. Inf. Secur. 2009, 8, 25–35. [Google Scholar] [CrossRef]
- Beghdad, R. Critical study of neural networks in detecting intrusions. Comput. Secur. 2009, 27, 168–175. [Google Scholar] [CrossRef]
- Wu, J.; Peng, D.; Li, Z.; Zhao, L.; Ling, H. Network intrusion detection based on a general regression neural network optimized by an improved artificial immune algorithm. PLoS ONE 2015, 10, e0120976. [Google Scholar] [CrossRef] [PubMed]
- Antonatos, S.; Anagnostakis, K.G.; Markatos, E.P. Generating realistic workloads for network intrusion detection systems. ACM SIGSOFT Softw. Eng. Notes 2004, 29, 207–215. [Google Scholar] [CrossRef]
- Cabrera, J.B.; Gosar, J.; Lee, W.; Mehra, R.K. On the statistical distribution of processing times in network intrusion detection. In Proceedings of the Conference on Decision and Control, Woburn, MA, USA, 14–17 December 2004; Volume 1, pp. 75–80.
- General-Purpose Computation Using Graphics Hardware. Available online: http://www.gpgpu.org (accessed on 24 November 2016).
- Lee, C.L.; Lin, Y.S.; Chen, Y.C. A hybrid CPU/GPU pattern matching algorithm for deep packet inspection. PLoS ONE 2015, 10, e0139301. Available Online: http://journals. plos.org/plosone/article?id=10.1371/journal.pone.0139301 (accessed on 24 November 2016). [Google Scholar] [CrossRef] [PubMed]
- Knuth, D.E.; Morris, J.; Pratt, V. Fast pattern matching in strings. SIAM J. Comput. 1977, 6, 127–146. [Google Scholar] [CrossRef]
- Boyer, R.S.; Moore, J.S. A fast string searching algorithm. Commun. ACM 1977, 20, 762–772. [Google Scholar] [CrossRef]
- Aho, A.V.; Corasick, M.J. Efficient string matching: An aid to bibliographic search. Commun. ACM 1975, 18, 333–340. [Google Scholar] [CrossRef]
- Wu, S.; Manber, U. A Fast Algorithm for Multi-Pattern Searching; Department of Computer Science, University of Arizona: Tucson, AZ, USA, 1994. [Google Scholar]
- Scarpazza, D.P.; Villa, O.; Petrini, F. Exact multi-pattern string matching on the cell/B.E. processor. In Proceedings of the Conference on Computing Frontiers, Ischia, Italy, 5–7 May 2008; pp. 33–42.
- Schuff, D.L.; Choe, Y.R.; Pai, V.S. Conservative vs. optimistic parallelization of stateful network intrusion detection. In Proceedings of the International Symposium on Performance Analysis of Systems and Software, Philadelphia, PA, USA, 20–22 April 2008; pp. 32–43.
- Vallentin, M.; Sommer, R.; Lee, J.; Leres, C.; Paxson, V.; Tierney, B. The NIDS cluster: Scalable, stateful network intrusion detection on commodity hardware. In Proceedings of the International workshop on Recent Advances in Intrusion Detection, Queensland, Australia, 5–7 September 2007; pp. 107–126.
- Jacob, N.; Brodley, C. Offloading IDS computation to the GPU. In Proceedings of the Computer Security Applications Conference, Miami Beach, FL, USA, 11–15 December 2006; pp. 371–380.
- Snort.Org. Available online: http://www.snort.org (accessed on 24 November 2016).
- Vasiliadis, G.; Antonatos, S.; Polychronakis, M.; Markatos, E.P.; Iasnnidis, S. Gnort: High performance network intrusion detection using graphics processors. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Cambridge, MA, USA, 15–17 September 2008; pp. 116–134.
- Vasiliadis, G.; Polychronakis, M.; Ioannidis, S. MIDeA: A multi-parallel intrusion detection architecture. In Proceedings of the Conference on Computer and Communication Security, Chicago, IL, USA, 17–21 October 2011; pp. 297–308.
- Vespa, L.J.; Weng, N. GPEP: Graphics processing enhanced pattern-matching for high-performance deep packet inspection. In Proceedings of the International Conference on Internet of Things and International Conference on Cyber, Physical and Social Computing, Dalian, China, 19–22 October 2011; pp. 74–81.
- Jamshed, M.A.; Lee, J.; Moon, S.; Yun, I.; Kim, D.; Lee, S.; Yi, Y.; Park, K. Kargus: A highly-scalable software-based intrusion detection system. In Proceedings of the ACM conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 317–328.
- Zu, Y.; Yang, M.; Xu, Z.; Wang, L.; Tian, X.; Peng, K.; Dong, Q. GPU-based NFA implementation for memory efficient high speed regular expression matching. ACM SIGPLAN Not. 2012, 47, 129–140. [Google Scholar] [CrossRef]
- Yu, X.; Becchi, M. GPU acceleration of regular expression matching for large datasets: Exploring the implementation space. In Proceedings of the ACM International Conference on Computing Frontiers, Ischia, Italy, 14–16 May 2013; p. 18.
- Jiang, H.; Zhang, G.; Xie, G.; Salamatian, K.; Mathy, L. Scalable high-performance parallel design for network intrusion detection systems on many-core processors. In Proceedings of the ACM/IEEE Symposium on Architectures for Networking and Communications Systems, San Jose, CA, USA, 21–22 October 2013; pp. 137–146.
- Valgenti, V.C.; Kim, M.S.; Oh, S.I.; Lee, I. REduce: Removing redundancy from regular expression matching in network security. In Proceeding of the International Conference on Computer Communication and Networks, Las Vegas, NV, USA, 3–6 August 2015; pp. 1–10.
- Han, S.; Jang, K.; Park, K.; Moon, S. PacketShader: A GPU-accelerated software router. ACM SIGCOMM Comput. Commun. Rev. 2011, 40, 195–206. [Google Scholar] [CrossRef]
- Lin, Y.S.; Lee, C.L.; Chen, Y.C. A capability-based hybrid CPU/GPU pattern matching algorithm for deep packet inspection. Int. J. Comput. Commun. Eng. 2016, 5, 321–330. [Google Scholar] [CrossRef]
- Douligeris, C.; Serpanos, D.N. Network Security: Current Status and Future Directions; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- OpenMP. Available online: http://openmp.org (accessed on 24 November 2016).
- Fatahalian, K.; Houston, M. A closer look at GPUs. Commun. ACM 2008, 51, 50–57. [Google Scholar] [CrossRef]
- Nickolls, J.; Buck, I.; Garland, M.; Skadron, K. Scalable parallel programming with CUDA. ACM Queue 2008, 6, 40–53. [Google Scholar] [CrossRef]
- NVIDIA. CUDA Architecture Introduction & Overview. Available online: http://developer.download.nvidia.com/compute/cuda/docs/CUDA_Architecture_Overview.pdf (accessed on 24 November 2016).
- NVIDIA. CUDA C Programming Guide. Available online: http://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf (accessed on 24 November 2016).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Specification |
|---|---|
| CPU | Intel Core i7-3770 (3.40 GHz) Number of cores: 4 Host memory: 8 GB DDR3 |
| GPU | NVIDIA GeForce GTX680 (1058 MHz) Number of cores: 1536 Device memory: 2 GB GDDR5 |
| Payload Length (Bytes) | Count | Ratio |
|---|---|---|
| <100 | 3334 | 0.009 |
| 100–300 | 6664 | 0.018 |
| 300–500 | 32,919 | 0.090 |
| 500–700 | 14,670 | 0.040 |
| 700–900 | 4326 | 0.012 |
| 900–1100 | 3946 | 0.011 |
| 1100–1300 | 4441 | 0.012 |
| >1300 | 297,419 | 0.809 |
| Processor Cost ($) | Throughput (Gbps) | Throughput per Dollar (Mbps/$) |
|---|---|---|
| $875 | 13.8 | 16.15 |
| Lb = 750 | Full-Matched/Total Packets | Ratio |
|---|---|---|
| Li ≤ Lb | 54,511/61,929 | 88% |
| Li > Lb | 80,549/328,991 | 24% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.-S.; Lee, C.-L.; Chen, Y.-C. Length-Bounded Hybrid CPU/GPU Pattern Matching Algorithm for Deep Packet Inspection. Algorithms 2017, 10, 16. https://doi.org/10.3390/a10010016
Lin Y-S, Lee C-L, Chen Y-C. Length-Bounded Hybrid CPU/GPU Pattern Matching Algorithm for Deep Packet Inspection. Algorithms. 2017; 10(1):16. https://doi.org/10.3390/a10010016
Chicago/Turabian StyleLin, Yi-Shan, Chun-Liang Lee, and Yaw-Chung Chen. 2017. "Length-Bounded Hybrid CPU/GPU Pattern Matching Algorithm for Deep Packet Inspection" Algorithms 10, no. 1: 16. https://doi.org/10.3390/a10010016
APA StyleLin, Y.-S., Lee, C.-L., & Chen, Y.-C. (2017). Length-Bounded Hybrid CPU/GPU Pattern Matching Algorithm for Deep Packet Inspection. Algorithms, 10(1), 16. https://doi.org/10.3390/a10010016