Automatic Modulation Recognition Using Compressive Cyclic Features


Department of Electronic Engineering, University of Electronic Science and Technology of China, Qingshuihe Campus, No. 2006, Xiyuan Ave, West Hi-Tech Zone, Chengdu 611731, Sichuan, China
*
Author to whom correspondence should be addressed.
Algorithms 2017, 10(3), 92; https://doi.org/10.3390/a10030092
Submission received: 30 June 2017
/
Revised: 10 August 2017
/
Accepted: 10 August 2017
/
Published: 18 August 2017
Abstract
:Higher-order cyclic cumulants (CCs) have been widely adopted for automatic modulation recognition (AMR) in cognitive radio. However, the CC-based AMR suffers greatly from the requirement of high-rate sampling. To overcome this limit, we resort to the theory of compressive sensing (CS). By exploiting the sparsity of CCs, recognition features can be extracted from a small amount of compressive measurements via a rough CS reconstruction algorithm. Accordingly, a CS-based AMR scheme is formulated. Simulation results demonstrate the availability and robustness of the proposed approach.
1. Introduction
Automatic modulation recognition (AMR) always plays a crucial role in spectral monitoring, surveillance, and spectrum sensing in cognitive radios. The concept of AMR is to classify an unknown modulation by comparing it to hypothetical schemes [1]. As shown in previous literature, higher-order cyclic cumulants (CCs)—inheriting the signal selectivity of higher-order cumulants [2]—have been confirmed as suitable discriminating features for AMR [3,4,5,6,7,8,9]. However, to perform a CC-based AMR, a large amount of signal symbols and an extremely higher sampling rate are both required to achieve an acceptable performance, which definitely results in computational complexity and a heavy sampling burden. To address this issue, we investigate the feature extraction in the framework of compressive sensing (CS), which enables the idea that CCs can be estimated from a relatively small number of compressive measurements. In the light of CS, Zhou and Hong [10] explored the sparsity of cyclic spectrum, and extracted features with compressive measurements. However, this method is restricted in the modulation pool consisting of a few lower-order modulations. Lim and Wakin [11] proposed a CS-based AMR algorithm by exploiting the sparsity of cyclic moments (CMs). In this approach, higher-order CC was indirectly derived by initially estimating several lower-order CMs. The drawback appears that one has to repeatedly run the CS reconstruction and peak detection algorithm to obtain the required CMs. It is no doubt a complicated process.
Since the CCs with specific nth-order/q-conjugate are sparse in the cyclic frequency domain, we consider estimating CCs directly in a CS way with the absence of CM estimation. In this paper, we first demonstrate that the CCs can be treated as the sparse representation of the successive temporal higher-order cumulant sequence, such that the relationship between the compressive measurements and CCs is exploited. Then, the feature extraction of AMR can be treated as a CS reconstruction problem, and a simplified reconstruction algorithm is proposed. Simulation results validate the effectiveness of this novel AMR algorithm.
2. Statistical Characterization of Signal of Interest
Assuming an intercepted modulated signal is oversampled at a rate , where is an integer and T is the symbol period, the observed discrete-time sequence can be expressed as [3]
where a is the signal amplitude, denotes the carrier frequency offset, is the phase shift, is the overall shape pulse sequence, is the propagation delay, and is the additive Gaussian noise sequence. The symbol sequence is a zero-mean independently and identically distributed (i.i.d.) sequence, with values drawn from a finite-alphabet constellation. Without loss of generality, the assumption of unit variance constellation is given; i.e. .
Due to the cyclostationarity of the linearly modulated signal, the nth-order/q-conjugate discrete-time CC can be inferred as [3]
where represents cyclic frequency (CF) given by (3), is the delay-vector, denotes the nth-order/q-conjugate cumulant of transmitted constellation, and is the optional minus sign associated with the optional conjugation . Because is assumed to be a stationary, zero-mean Gaussian process, its cumulants are time independent and non-zero only for the second order. Since our work focuses on the higher-order () CCs of , the noise contribution does not appear in (3). Moreover, we also find that the CFs are determined by the (normalized) carrier frequency offset and the (normalized) symbol rate .
It is also worth noting that for the raised cosine pulse shape, the actual set of CFs is essentially limited by the signal bandwidth , where r denotes the roll-off factor, . Thus, to avoid aliasing in the cyclic frequency domain, the oversampling factor should be fixed according to the order n and the roll-off factor r, and a result is given as follows: For n even, if , the necessary and sufficient condition for the oversampling factor is , if , , . Additionally, when n odd, the CCs are zero and the set of CFs is empty. One can refer to [9] for more details.
By inspection of (2), the fact that the CC is directly proportional to the corresponding cumulant of the signal constellation implies the potential as a signature of modulation format. Nevertheless, the rotation caused by , , and considerably restricts its application for AMR. In response, one way is to select the CCs with (i.e., the zero delay vector) [6,7], and the other way is to utilize the magnitudes of CCs [8,9] as discriminating features.
Although the CCs have avoided the effect of carrier frequency offset and is suited for the blind AMR, only limited types of modulations can be recognized. In contrast, based on the prior knowledge of carrier frequency offset and symbol rate, the possible combinations of CC magnitudes are more flexible, and can consequently deal with a wider range of modulations. A typical feature vector formulated by CC magnitudes is given by [9]
where .
Along with this formulation of feature vector, a hierarchical scheme is widely adopted by the AMR [8], with which lower-order CCs are used to make initial classification, followed by higher-order CCs to further refine the decision. The hierarchical scheme not only leads to a more perfect performance but also saves the computational cost of CC-based AMR.
3. CS-based AMR
For a CC-based AMR, the sampling rate for signal acquisition is always several times larger than the Nyquist rate to ensure the absence of the aliasing effect in the area of cyclic frequencies. For instance, to recognize a more extensive number of modulations, many studies appeal to 8th-order CCs [8,9]. According to the result presented before, the oversampling factor reaches up to 11 with roll-off factor. Besides, a large amount of symbols (a large observation interval) is also necessary for better recognition performance in most cases [3]. All of the above yields a heavy computational and storage burden. Fortunately, the development of CS enlightens a way to relieve this burden. By employing the sparsity of CMs, Lim and Wakin [11] estimated CMs from compressive measurements, then derived CC through cyclic moment to cumulant formula [9]. Because of the requirement of all the necessary nth- and lower-order CMs, it seems cumbersome.
3.1. CS-Based Cyclic Characteristic Analysis
In this subsection, we attempt to exploit the sparsity structure of CC function, and investigate the relationship between the compressive measurements and CCs.
Assuming is the set of uniform samples at the oversampling rate , the nth-order/q-conjugate temporal cumulant (TC) can be expressed as [12]
where is the cumulant operator, and . TC is a periodic function for cyclostationary signals, with its Fourier components given by
From (3), when , the expression (6) is the CC at CF . Assuming that the vector represents the quantities , is the Fourier coefficient vector, and is the N-point discrete Fourier transform (DFT) matrix, it holds evidently from (6) that . Equivalently, , where denotes the conjugate transpose operator. Clearly, the nth-order/q-conjugate CCs can be viewed as the set of nonzero elements of vector , and the location of nonzero element implies the corresponding CF. Thus, the calculation of CCs is equivalent to locating the peaks in . Since the CFs belong to a finite set depending on the signal bandwidth and order n [9], the CCs can be treated as sparse in the Fourier domain under the assumption of no cyclic leakage. Sparsity of CCs motivates the application of CS. CS argues that sparse vector can be recovered from compressive measurements , obtained by , where is the so-called measurement matrix. If satisfies the condition known as the restricted isometry property (RIP), the exact recovery of can be achieved by solving an optimization problem, as follows:
where . In previous studies, a variety of greedy iterative algorithms and convex solvers have been adopted for signal recovery [13,14]. However, there still remains the issue that the relationship between TCs and the compressive measurements has not been established. Before proceeding, it should be pointed out that in practical implementations with finite data samples, the estimators of involved statistics are defined on the basis of averaging of the sample values taken through the observation interval.
Assume that the received signal sequence with length L is divided into W frames with length N, where ( denotes floor operation). Then, can be recognized as a mixture of W sequences [15]. We define the estimator of higher-order temporal moment (TM) as
By substituting (8) into the moment-cumulant (M-C) formula [9], we obtain the estimator of TC
where is the set of distinct partitions of , I is the number of subsets in each partition, and correspond to the number of elements and the number of conjugated terms in the ith subset.
For each frame represented by , we acquire the compressive measurements by multiplying it by the same random matrix . is designed as a binary matrix, , containing a single 1 in a random position in each row. When , where s is the sparsity level of , is proved to meet the RIP, and can be reconstructed with high probability [16]. Consequently, the compressive measurements , is actually the subset of indexed by , elements of which are randomly drawn from . It can be easily deduced that
which implies that in (7) can be estimated from nonuniform samples by using (8) and (9).
In practice, based on the strategy of non-uniform sampling (NUS) [17], compressive measurements can be directly acquired from the continuous waveform . Moreover, a novel signal acquisition setup proposed in [11] was available to generate various compressive signal lag products. As a result, we just need to divide into W temporal windows, let them undergo the aforementioned setup, respectively, and then the TMs and TCs can be calculated successively.
3.2. Feature Selection
As a case study of CS-based AMR, we investigate the modulation pool consisting of 4QAM, 32QAM, 16QAM, 16PSK, 8ASK. The theoretical values of constellation cumulants of candidate modulations, are given by Table 1. Accordingly, the feature vector is formatted as
where , corresponding to .
3.3. Feature Extraction
Based on the fact that the carrier frequency offset and the symbol rate can be properly estimated with compressive measurements respectively [18], feature extraction can be implemented by solving the problem expressed by (7). Lim and Wakin [11] proposed a rough estimator as
which can be interpreted as taking the fast Fourier transform (FFT) of the zero-padded vector (a length-N vector containing the M entries of at the nonuniform sample locations). It is easy to find that the estimator expressed by (12) is essentially the simplified Orthogonal Matching Pursuit (OMP) algorithm without further iterations. Moreover, since satisfies the RIP, Lemmas of [19] guarantee this reasonability of the rough estimator theoretically. Thus, the feature extraction can be described as:
where . Although this process is not a full-scale or exact recovery, it is simple and efficient enough for an AMR application. It is worth mentioning that the computation of TC in CS-based AMR is implemented with M compressive measurements, instead of N uniform samples in classical AMR. Then, after zero-padding, the N-point FFT is taken, just as in the classical method, such that a significant reduction of computational burden is achieved.
Support Vector Machine (SVM) Classifier
In previous literature, the CC-based AMR is often realized by comparing the Euclidean distance between the measured feature vector and its counterparts of catalog patterns. In our work, a support vector machine (SVM) classifier is proposed. In SVM, groups of feature vectors are separated by the hyperplane, derived from previously generated training sets. The SVM is more valid than the aforementioned classifier, since it can not only perform the linear separation, but also the nonlinear separation by using a variety of kernel functions [20].
4. Simulation and Performance Analysis
In order to validate the proposed algorithm and evaluate its performance, we consider two modulation pools: for the scenario of intra-class recognition, and for the scenario of inter-class recognition. The transmit and receive filters are square-root raised cosine pulses with roll-off factor. Accordingly, at the receiver, the signal is oversampled by a factor of 16 to eliminate aliasing. For each modulation type, 150 signals are generated for the training phase of the SVM system, and 1000 Monte Carlo trials are run as the testing phase. The number of processed symbols is equal to 4096. Each signal is generated with carrier frequency offset 500 Hz, symbol rate 1000 Hz. This classifier is tested in a variety of channel conditions, with a signal-to-noise ratio (SNR) range of 0 dB to 12 dB. The performance metric is the correct rate of recognition (COR)—the ratio between the number of correctly recognized signals and the total number of testing signals. A key parameter of interest is the compression ratio for sampling rate reduction. It is necessary that its impact on the performance of the proposed AMR algorithm be investigated in our simulations.
Since the utilized estimators of cyclic statistics are biased due to the finite number of symbols (finite observation interval), a relatively large amount of symbols (e.g., 4096) are of great help to enhance the performance of the CC-based classifier [3].
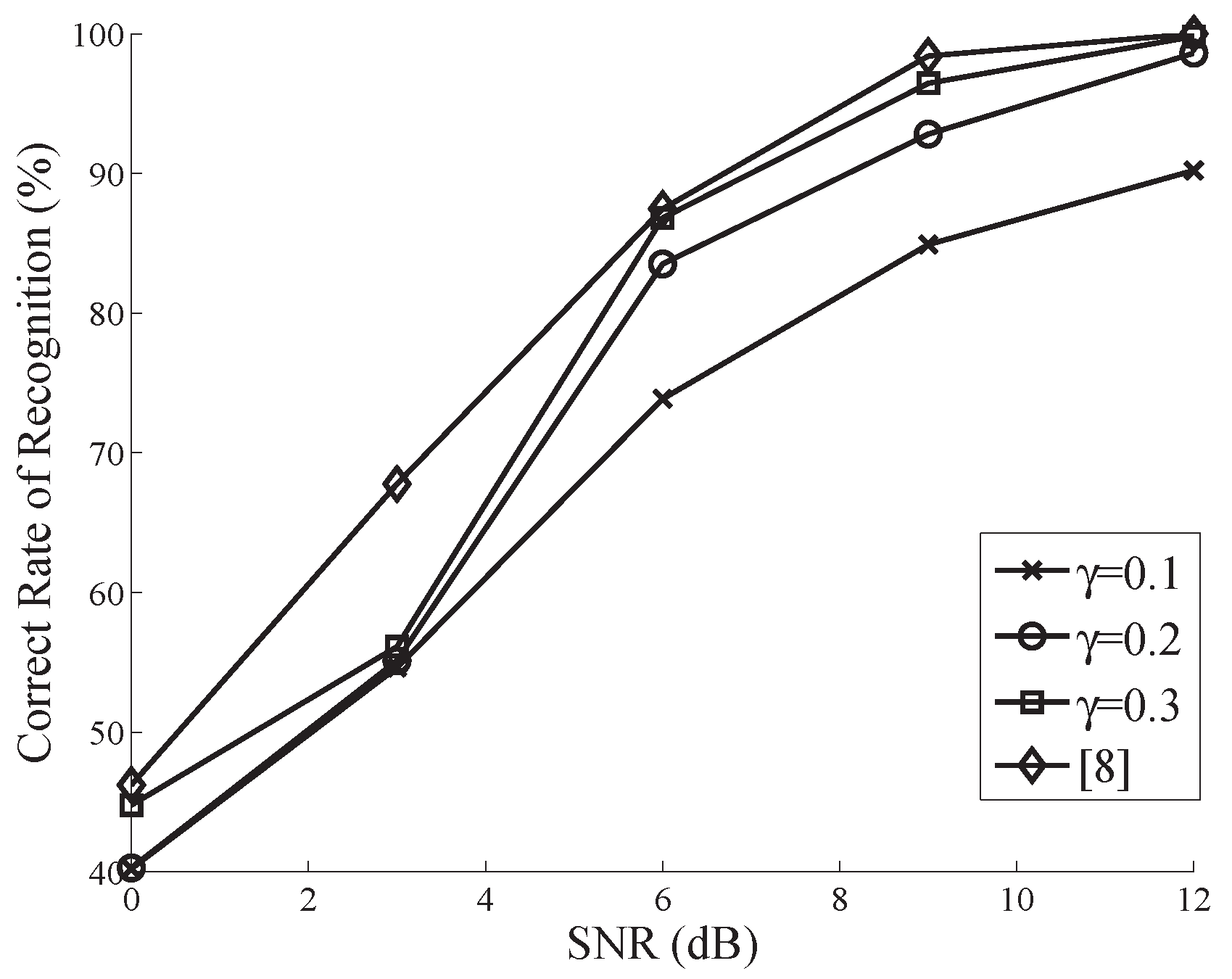
Figure 1 plots the performance of the proposed algorithm (for the modulation pool ) versus SNR, for , and . The performance of the classical CC-based method with uniform samples which was proposed in [8] is also shown in the same figure. As one can easily notice from Figure 1, all the curves degrade when SNR decreases. As is readily seen, when SNR dB, the proposed AMR provides a comparable performance (COR ), with only of samples utilized by the classical counterpart. Moreover, with , the proposed method can achieve a perfect performance (COR ) at 6 dB SNR.
In Figure 2, for the modulation pool , the performance maintains a similar trend as shown in Figure 1. It is noted that the performance for is quite close to that of classical method when SNR dB.
From Figure 1 and Figure 2, we can conclude that regardless of the effect of noise, the more measurements are taken, the more excellent the performance can be. This is because the finite sample effect can be adequately alleviated as the length of measurements increases. Providing a proper tradeoff between SNR and , the CS-based AMR can be totally treated as an alternative of the classical CC-based AMR, and affords dramatic savings of computational complexity and storage requirements.
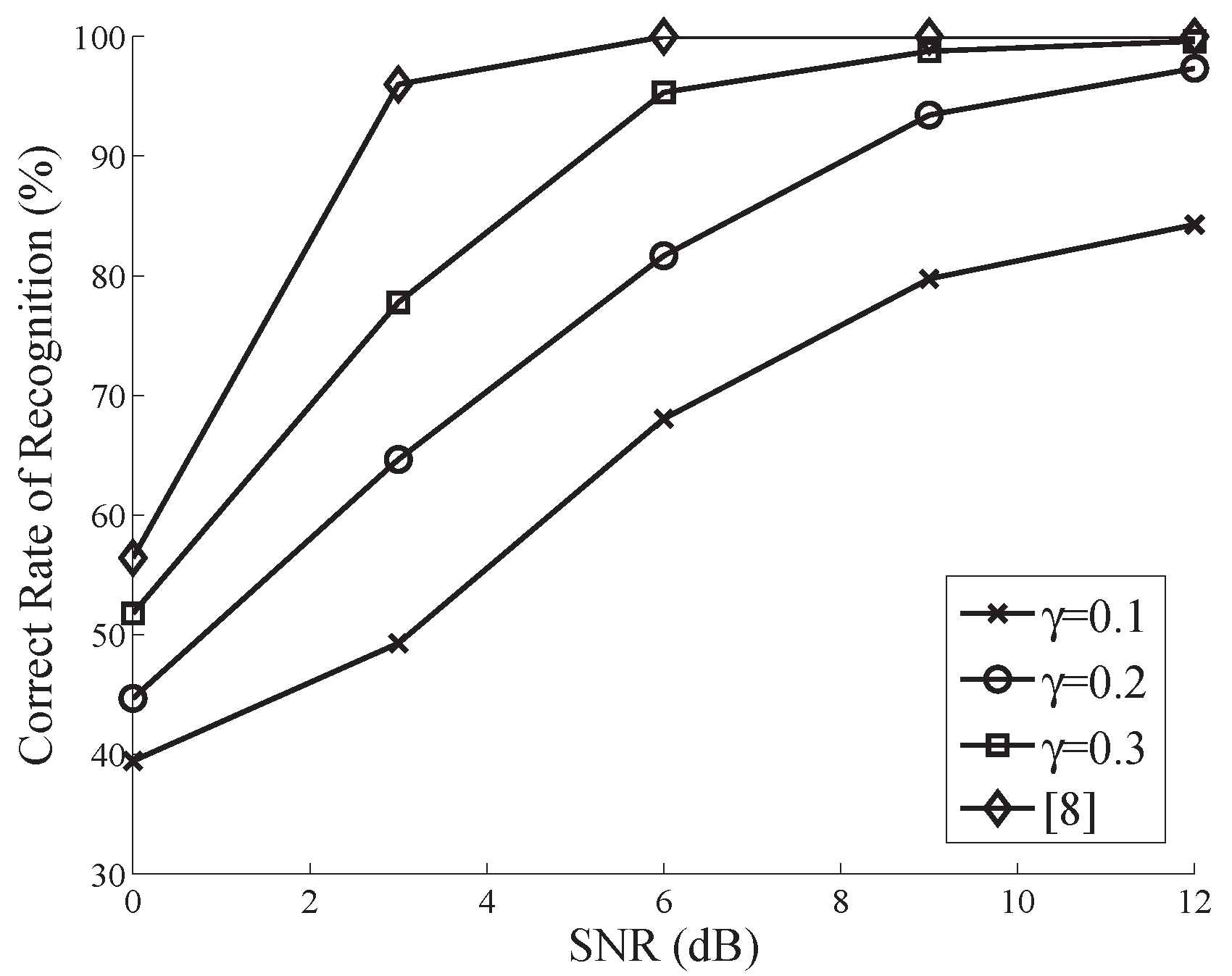
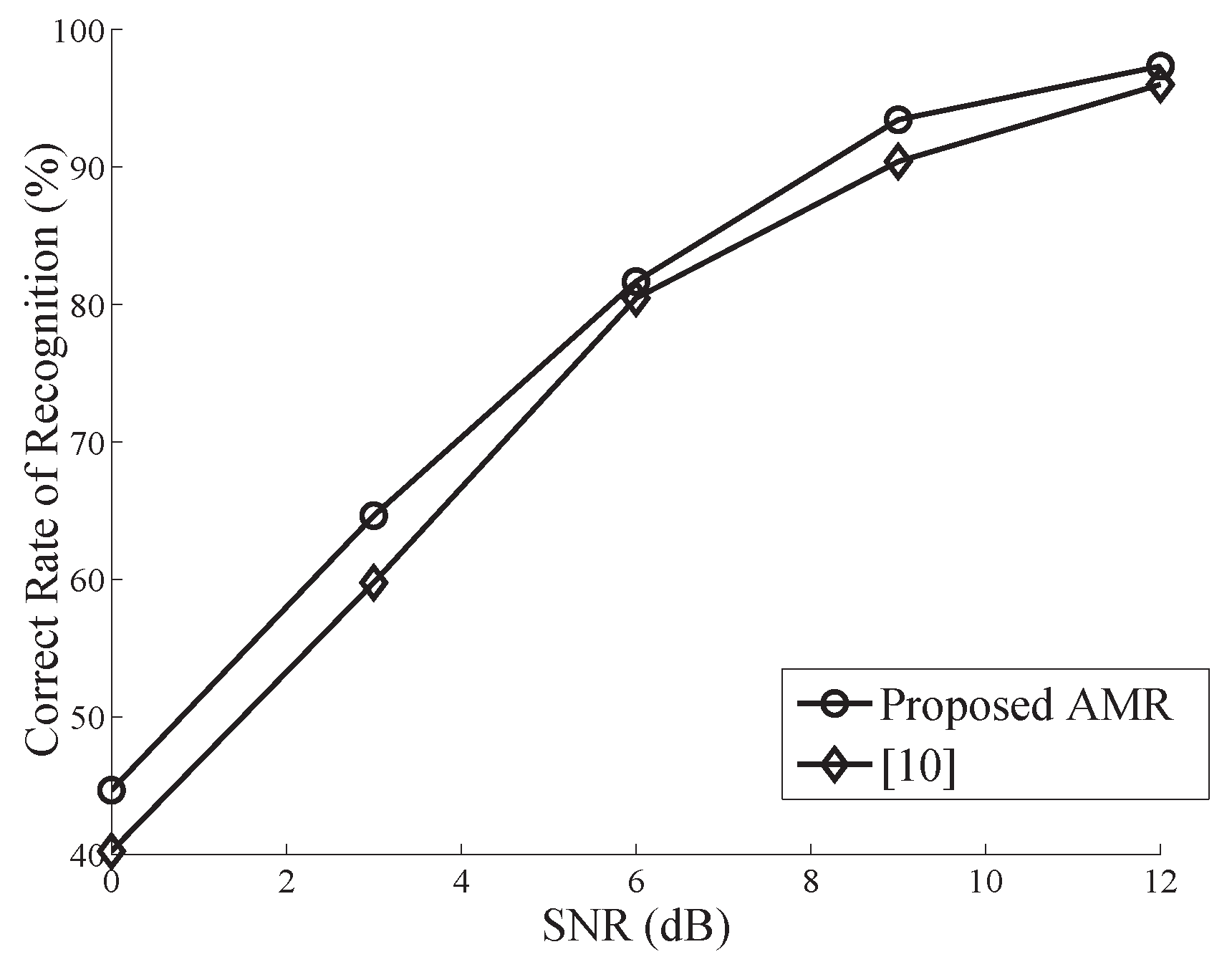
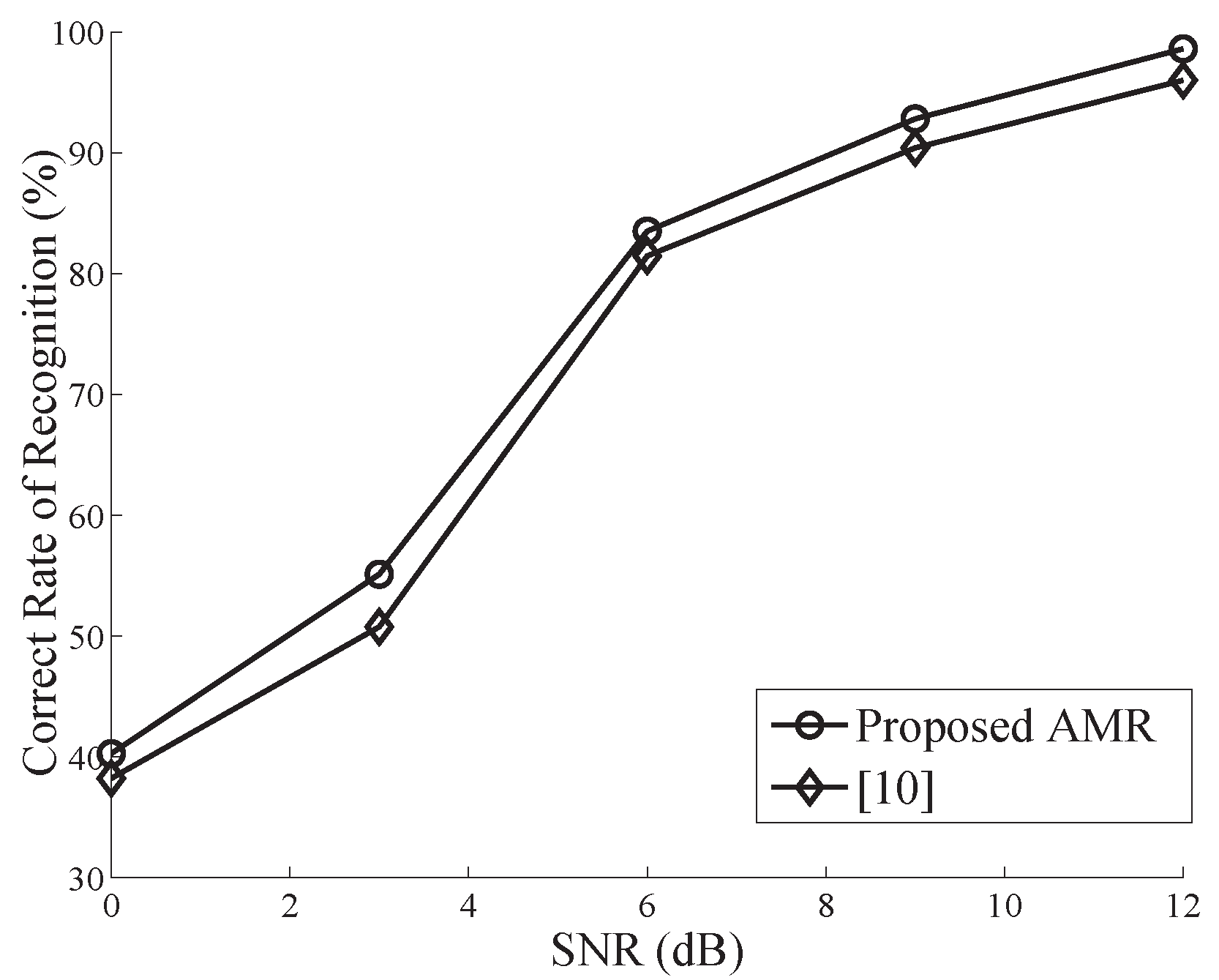
Figure 3 and Figure 4 compare the performance of the proposed algorithm to the CS-based AMR proposed in [11] for . It is apparent that these two curves almost converge, and the former slightly outperforms the latter in both cases. This mainly results from the fact that in the algorithm of [11], several lower-order CMs need to be estimated, which yields bias accumulation in the computation of CCs. With the SNR degrading, these two classifiers both exhibit unacceptably poor performance when SNR dB (not shown in Figure 3 and Figure 4).
The results above reveal the fact that for a fixed observation, the proposed AMR performance degrades as decreases. As a special case of , the performance of the classical algorithm provides an upper bound. On the other hand, as shown in Table 2 and Table 3, for an equivalent number of samples, nonuniform sampling has better classification performance than uniform sampling. This results from the larger observation interval (larger symbol number), which is required by the nonuniform sampling. As is well known, a larger observation interval always guarantees a more reliable feature estimation.
5. Conclusions
In this paper, we utilize the theory of CS to perform a CC-based AMR. Except for the significant reduction of sampling burden compared with previously proposed algorithms, this algorithm includes following advantages: Firstly, the CC estimator is developed without multiple times calculations of CMs. Secondly, the feature extraction is implemented by a more convenient CS reconstruction algorithm rather than a full-scale recovery. Both make the proposed AMR simple and efficient.
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (NSFC) under Grant U1533125, National Science and Technology Major Project under Grant 2016ZX03001022, and the Fundamental Research Funds for the Central Universities under Grant ZYGX2015Z011.
Author Contributions
Lijin Xie derived the AMR algorithm and wrote the paper; Qun Wan is in charge of the whole research project; Qun Wan also offered guidance for paper writing.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Su, W. Feature space analysis of modulation classification using very high-order statistics. Commun. Lett. 2013, 17, 1688–1691. [Google Scholar] [CrossRef]
- Swami, A.; Sadler, B.M. Hierarchical digital modulation classification using cumulants. Trans. Commun. 2000, 48, 416–429. [Google Scholar] [CrossRef]
- Dobre, O.A.; Bar-Ness, Y.; Su, W. Higher-order cyclic cumulants for high order modulation classification. Milit. Commun. Conf. 2003, 10, 112–117. [Google Scholar]
- Spooner, C.M. Classification of co-channel communication signals using cyclic cumulants. Signal. Syst. Comput. 2002, 8, 531–536. [Google Scholar]
- Spooner, C.M. On the utility of sixth-order cyclic cumulants for RF signal classification. Asilomar 2002, 8, 890–897. [Google Scholar]
- Dobre, O.A.; Rajan, S.; Inkol, R. Cyclostationarity-based robust algorithms for QAM signal identification. Commun. Lett. 2012, 16, 12–15. [Google Scholar] [CrossRef] [Green Version]
- Xie, L.; Wan, Q. Cyclic feature based modulation recognition using compressive sensing. Wirel. Commun. Lett. 2017, 6, 402–405. [Google Scholar] [CrossRef]
- Eric, L.; Chakravarthy, D.V.; Ratazzi, P.; Wu, Z.Q. Signal classification in fading channels using cyclic spectral analysis. Eurasip J. Wirel. Commun. Netw. 2009, 1, 3129–3142. [Google Scholar]
- Dobre, O.A.; Ali, A.; Yeheskel, B.-N.; Wei, S. Cyclostationarity-based modulation classification of linear digital modulations in flat fading channels. Wirel. Pers. Commun. Int. J. 2010, 1, 699–717. [Google Scholar] [CrossRef]
- Zhou, L.; Hong, M. Distributed automatic modulation classification based on cyclic feature via compressive sensing. Milit. Commun. Conf. 2013, 11, 40–45. [Google Scholar]
- Lim, C.; Wakin, M.B. Compressive temporal higher order cyclostationary statistics. IEEE Trans. Signal Process. 2015, 63, 2942–2956. [Google Scholar] [CrossRef]
- Spooner, C.M.; Gardner, W.A. The cumulant theory of cyclostationary time-series. II. Development and applications. IEEE Trans. Signal Process. 1994, 42, 3409–3429. [Google Scholar] [CrossRef]
- Donoho, D.L.; Tsaig, Y.; Drori, I.; Starck, J.-L. Sparse solution of underdetermined systems of linear equations by stagewise orthogonal matching pursuit. IEEE Trans. Inf. Theory 2012, 58, 1094–1121. [Google Scholar] [CrossRef]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef]
- Dandawate, A.V.; Giannakis, G.B. Asymptotic theory of mixed time averages and kth-order cyclic-moment and cumulant statistics. IEEE Trans. Inf. Theory 1995, 41, 216–232. [Google Scholar] [CrossRef]
- Candesy, E.; Rombergy, J.; Tao, T. Robust uncertainty principles: Exact signal seconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar]
- Nakamura, E. Compressive samplers for RF environments. IEEE Commun. Mag. 2013, 51, 124–129. [Google Scholar] [CrossRef]
- Xie, L.J.; Qun, W. Blind symbol-rate estimation based on ompressive cyclic statistics. ICIC Express Lett. 2017, 11, 1199–1206. [Google Scholar]
- Davenport, M.A.; Wakin, M.B. Analysis of orthogonal matching pursuit using the restricted isometry property. IEEE Trans. Inf. Theory 2010, 56, 4395–4401. [Google Scholar] [CrossRef]
- Brereton, R.G.; Lloyd, G.R. Support vector machines for classification and regression. Analyst 2009, 135, 230–267. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Performance versus signal-to-noise ratio (SNR) for .
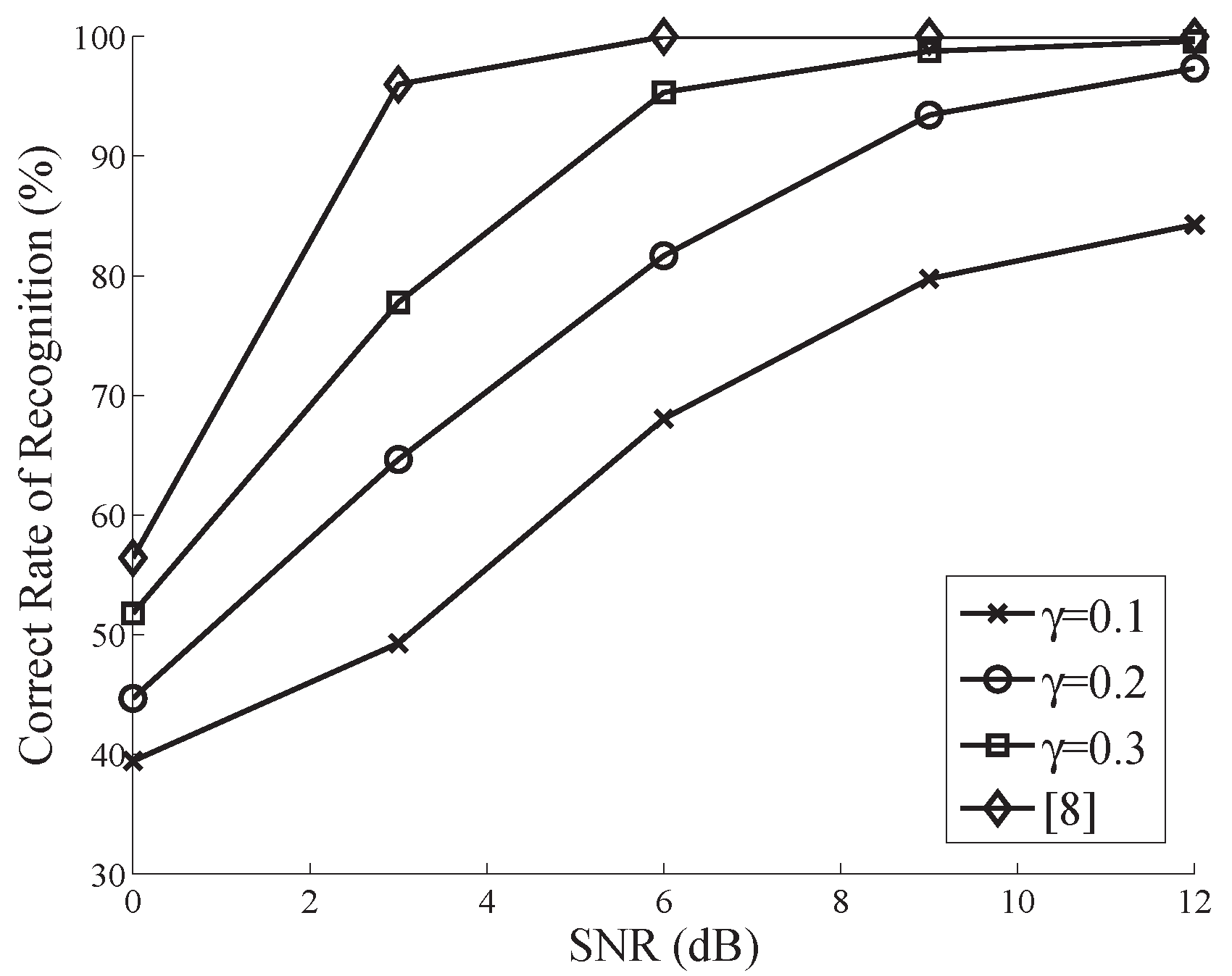
Figure 2.
Performance versus SNR for .
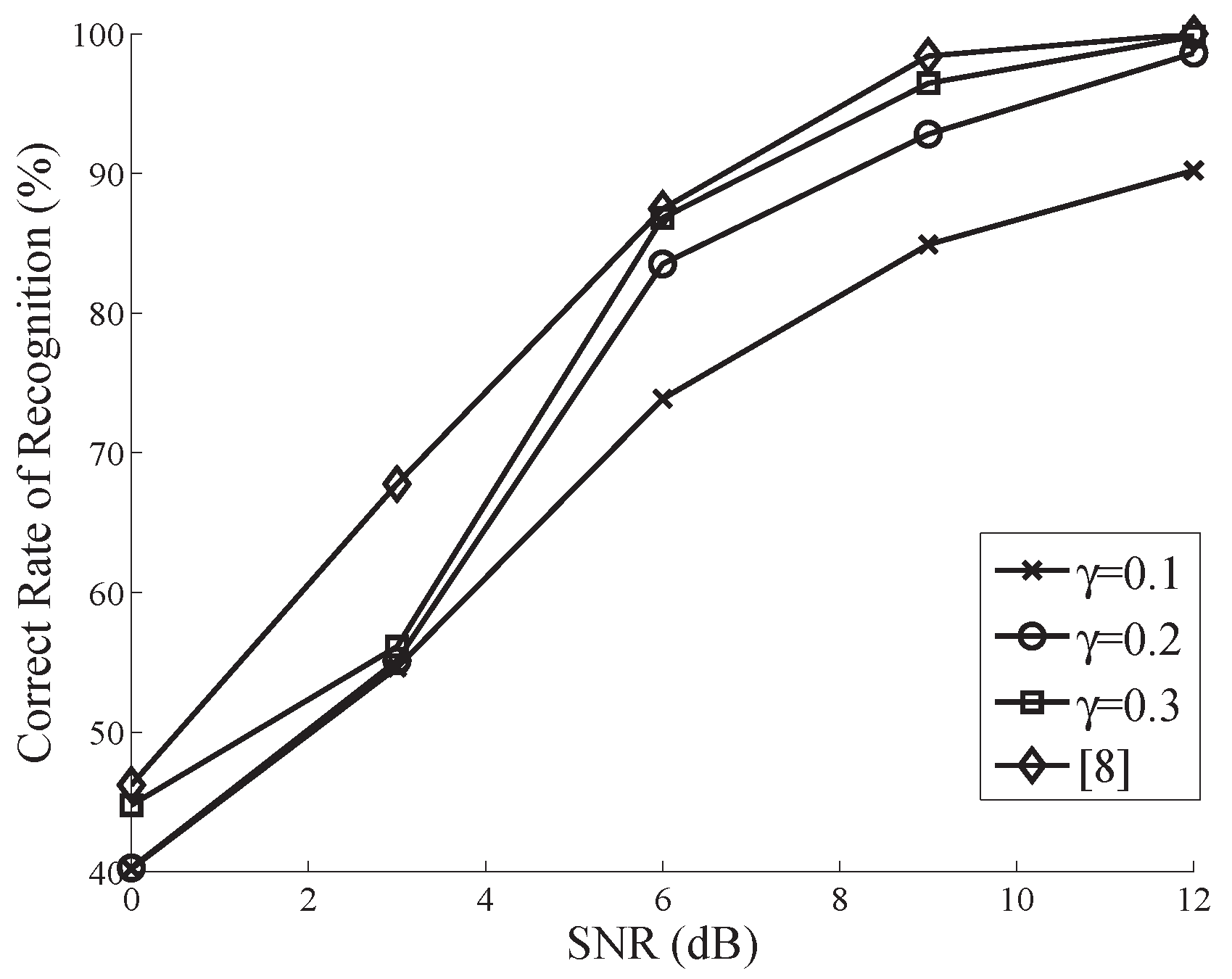
Figure 3.
Performance versus SNR for . AMR: automatic modulation recognition.
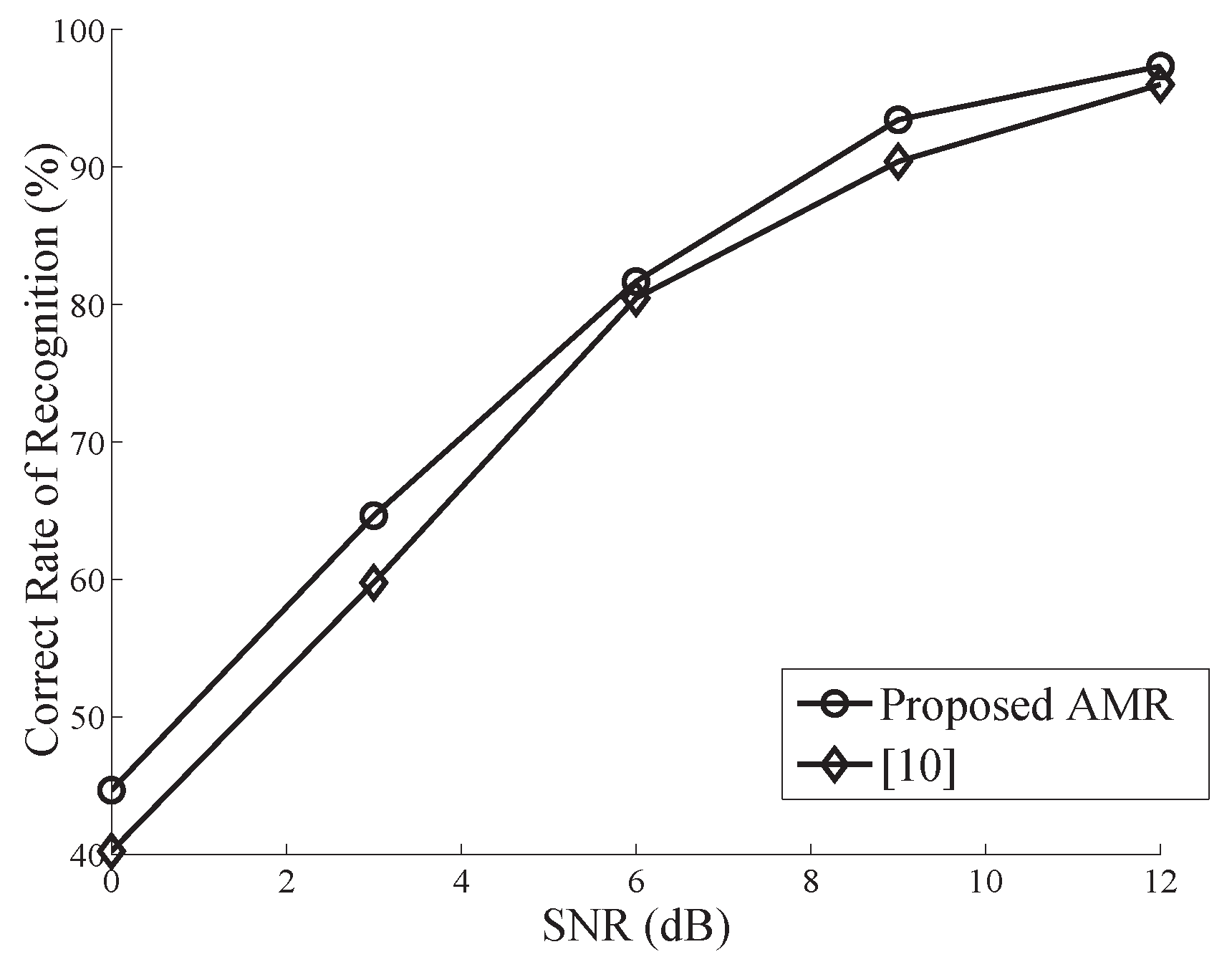
Figure 4.
Performance versus SNR for .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Cumulant values of candidate constellations.
| 4QAM | 1 | 0 | −34 |
| 32QAM | −0.19 | 0 | −1.9926 |
| 16QAM | −0.68 | 0 | −13.9808 |
| 8ASK | −1.2381 | 7.1889 | −92.018 |
| 16PSK | 0 | 0 | 0 |
Table 2.
Comparison for between compressive sensing (CS) method and classical method with equivalent number of samples.
Table 2.
Comparison for between compressive sensing (CS) method and classical method with equivalent number of samples.
| Samples | 10,240 | 15,360 | 20,480 | |||
|---|---|---|---|---|---|---|
| Symbols | 4096 | 640 | 4096 | 960 | 4096 | 1280 |
| 0 dB | 39.4% | 38.4% | 44.7% | 40.9% | 51.8% | 44.4% |
| 3 dB | 52.8% | 49.2 % | 64.6% | 62.3% | 77.8% | 71.3% |
| 6 dB | 68.0% | 59.6% | 82.1 % | 81.7% | 95.3% | 90.2% |
| 9 dB | 79.7% | 78.4% | 93.4% | 92.7% | 98.8% | 97.2% |
| 12dB | 84.2% | 72.1% | 97.3% | 94.1% | 99.6% | 97.4% |
Table 3.
Comparison for between CS method and classical method with equivalent number of samples.
| Samples | 10,240 | 15,360 | 20,480 | |||
|---|---|---|---|---|---|---|
| Symbols | 4096 | 640 | 4096 | 960 | 4096 | 1280 |
| 0 dB | 40.2% | 37.8% | 42.9% | 40.3% | 46.2% | 40.9% |
| 3 dB | 57.7% | 55.1% | 68.6% | 56.1 % | 62.9% | 54.6% |
| 6 dB | 73.9% | 71.9% | 88.3% | 83.5% | 86.8% | 84.6% |
| 9 dB | 86.8% | 84.9% | 92.8% | 92.8% | 98.4% | 97.3% |
| 12dB | 90.2% | 88.7% | 98.6% | 96.0% | 99.8% | 98.8% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xie, L.; Wan, Q. Automatic Modulation Recognition Using Compressive Cyclic Features. Algorithms 2017, 10, 92. https://doi.org/10.3390/a10030092
AMA Style
Xie L, Wan Q. Automatic Modulation Recognition Using Compressive Cyclic Features. Algorithms. 2017; 10(3):92. https://doi.org/10.3390/a10030092
Chicago/Turabian StyleXie, Lijin, and Qun Wan. 2017. "Automatic Modulation Recognition Using Compressive Cyclic Features" Algorithms 10, no. 3: 92. https://doi.org/10.3390/a10030092
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.