Learning Representations of Natural Language Texts with Generative Adversarial Networks at Document, Sentence, and Aspect Level


Abstract
:1. Introduction
- We investigate whether GANs can be used to learn representations of natural language in an unsupervised setting at the document, sentence, and aspect level.
- Among the various methods of learning representations, we focus on deep learning methods to yield more abstract—and, ultimately, more useful—representations.
- We bridge the unsupervised learning approach with GANs and denoising autoencoders.
- We revisit the traditional GAN framework from an alternative energy-based perspective.
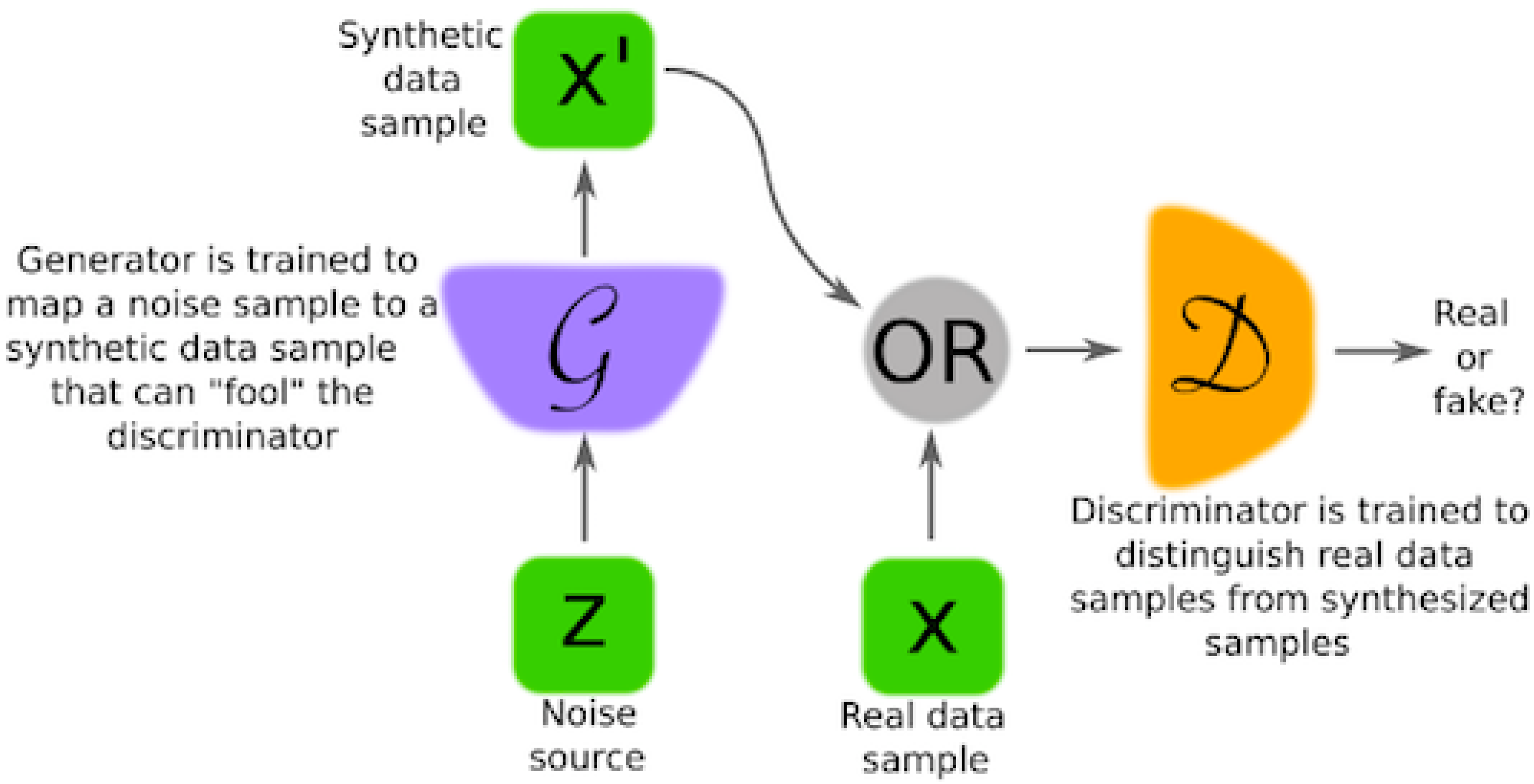
- We propose a neural network architecture that is based on a variation of the energy-based GAN formulation [10] for generative adversarial training. Our contribution is based on the use of a simple hinge loss, at the point when the system reaches convergence, so that the generator of the energy-based GAN produces points that follow the underlying data distribution.
- We propose to use an autoencoder architecture as a discriminator in which the energy is a reconstruction error.
- We focus on the unsupervised benefit of GANs to process a large amount of unlabeled data and not on its ability to generate new data.
- We conducted extensive experiments by leveraging data of different in types, lengths, and genres: the 20 Newsgroups corpus, the Movie Review (MR) Dataset, and the Finegrained Sentiment Dataset (FSD).
2. Related Work
2.1. Machine Learning Approaches for NLP Tasks
2.2. Deep Neural Network Approaches at Document, Sentence, and Aspect Level
2.3. Generative Adversarial Networks for NLP Tasks
3. Proposed Approach
3.1. Problem Formulation
3.2. Adversarial Document-Level Neural Network Architecture
4. Experimental Validation
4.1. Datasets
4.2. Baseline System
4.3. Implementation
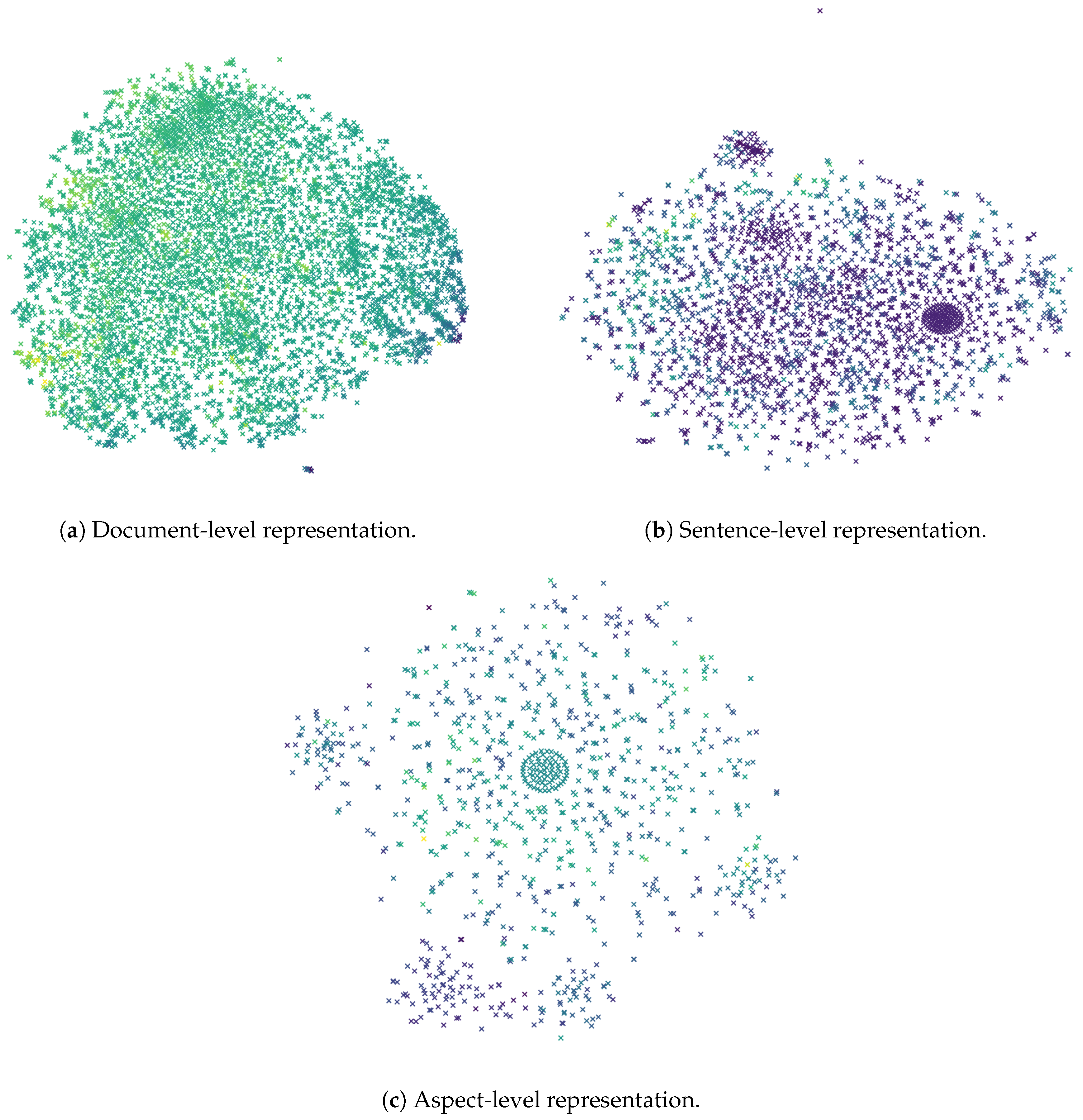
4.4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. Mach. Learn. 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Mach. Learn. 2014, arXiv:1406.2661, 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. Mach. Learn. 2015, arXiv:1511.06434. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.; Wierstra, D. DRAW: A Recurrent Neural Network For Image Generation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1462–1471. [Google Scholar]
- Bowman, S.R.; Vilnis, L.; Vinyals, O.; Dai, A.; Jozefowicz, R.; Bengio, S. Generating Sentences from a Continuous Space. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 10–21. [Google Scholar]
- Miao, Y.; Yu, L.; Blunsom, P. Neural variational inference for text processing. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1727–1736. [Google Scholar]
- Salant, S.W.; Switzer, S.; Reynolds, R.J. Losses from Horizontal Merger: The Effects of an Exogenous Change in Industry Structure on Cournot-Nash Equilibrium. Q. J. Econ. 1983, 98, 185–199. [Google Scholar] [CrossRef]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. Mach. Learn. 2016, arXiv:1609.03126. [Google Scholar]
- Deng, L. The MNIST database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.; Bengio, Y. Deep directed generative models with energy-based probability estimation. Mach. Learn. 2016, arXiv:1606.03439. [Google Scholar]
- Yu, Y.; Gong, Z.; Zhong, P.; Shan, J. Unsupervised Representation Learning with Deep Convolutional Neural Network for Remote Sensing Images. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 97–108. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the 30th Conference on Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up: Sentiment classification using machine learning techniques. In Proceedings of the ACL Conference on Empirical Methods in Natural Language Processing-Volume 10. Association for Computational Linguistics, Stroudsburg, PA, USA, 9–11 October 2002; pp. 79–86. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar]
- Qu, L.; Ifrim, G.; Weikum, G. The bag-of-opinions method for review rating prediction from sparse text patterns. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 913–921. [Google Scholar]
- Mejova, Y.; Srinivasan, P. Exploring Feature Definition and Selection for Sentiment Classifiers. In Proceedings of the Fifth International Conference on Weblogs and Social Media (ICWSM), Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Ling. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, B. Extracting resource terms for sentiment analysis. In Proceedings of the 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand, 8–13 November 2011; pp. 1171–1179. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.J.; Boureau, Y.L.; LeCun, Y. Unsupervised learning of invariant feature hierarchies with applications to object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR’07, Honolulu, HI, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Chen, D.; Manning, C. A fast and accurate dependency parser using neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 740–750. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. Computa. Lang. 2015, arXiv:1506.06726, 3294–3302. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. Mach. Learn. 2016, arXiv:1607.06450. [Google Scholar]
- Rahman, L.; Mohammed, N.; Al Azad, A.K. A new LSTM model by introducing biological cell state. In Proceedings of the 3rd International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Dhaka, Bangladesh, 22–24 September 2016; pp. 1–6. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 333, pp. 2267–2273. [Google Scholar]
- Shen, Q.; Wang, Z.; Sun, Y. Sentiment Analysis of Movie Reviews Based on CNN-BLSTM. In Proceedings of the International Conference on Intelligence Science, Dalian, China, 23–24 September 2017; pp. 164–171. [Google Scholar]
- Yenter, A.; Verma, A. Deep CNN-LSTM with combined kernels from multiple branches for IMDB Review Sentiment Analysis. In Proceedings of the 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, USA, 8–10 November 2017; pp. 540–546. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. Comput. Lang. 2016, arXiv:1605.05101. [Google Scholar]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, W.; Luo, Z. Combination of convolutional and recurrent neural network for sentiment analysis of short texts. In Proceedings of the 26th International Conference on Computational Linguistics (COLING): Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2428–2437. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very deep convolutional networks for text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Long Papers, Valencia, Spain, 3–7 April 2017; Volume 1, pp. 1107–1116. [Google Scholar]
- Wang, J.; Yu, L.C.; Lai, K.R.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Short Papers), Berlin, Germany, 7–12 August 2016; Volume 2, pp. 225–230. [Google Scholar]
- Du, H.; Xu, X.; Cheng, X.; Wu, D.; Liu, Y.; Yu, Z. Aspect-specific sentimental word embedding for sentiment analysis of online reviews. In Proceedings of the 25th International Conference Companion on World Wide Web Conferences Steering Committee, Montreal, QC, Canada, 11–15 April 2016; pp. 29–30. [Google Scholar]
- Wang, Y.; Huang, M.; Zhao, L.; Zhao, L. Attention-based lstm for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl.-Based Syst. 2016, 108, 42–49. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Aspect level sentiment classification with deep memory network. Comput. Lang. 2016, arXiv:1605.08900. [Google Scholar]
- Zhang, Y.; Gan, Z.; Carin, L. Generating text via adversarial training. Comput. Lang. 2016, arXiv:1808.0870321. [Google Scholar]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. Mach. Learn. 2015, arXiv:1506.03099, 1171–1179. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. Mach. Learn. 2017, arXiv:1609.05473, 2852–2858. [Google Scholar]
- Subramanian, S.; Rajeswar, S.; Dutil, F.; Pal, C.; Courville, A. Adversarial generation of natural language. In Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, BC, Canada, 17 January 2017; pp. 241–251. [Google Scholar]
- Mogren, O. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. Artif. Intell. 2016, arXiv:1611.09904. [Google Scholar]
- Hu, Z.; Yang, Z.; Liang, X.; Salakhutdinov, R.; Xing, E.P. Controllable text generation. Mach. Learn. 2017, arXiv:1703.00955. [Google Scholar]
- Semeniuta, S.; Severyn, A.; Barth, E. A hybrid convolutional variational autoencoder for text generation. Comput. Lang. 2017, arXiv:1702.02390. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. Mach. Learn. 2014, arXiv:1411.1784. [Google Scholar]
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2089–2093. [Google Scholar]
- Lin, K.; Li, D.; He, X.; Zhang, Z.; Sun, M.T. Adversarial Ranking for Language Generation. Advances in Neural Information Processing Systems. 2017. Available online: http://students.washington.edu/kvlin/RankGAN_poster.pdf (accessed on 19 October 2018).
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. Mach. Learn. 2016, arXiv:1605.09782. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. Mach. Learn. 2015, arXiv:1511.05644. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 271. [Google Scholar]
- Täckström, O.; McDonald, R. Discovering Finegrained sentiment with latent variable structured prediction models. In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 18–21 April 2011; pp. 368–374. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Comput. Lang. 2013, arXiv:1310.4546, 3111–3119. [Google Scholar]
- Socher, R.; Lin, C.C.Y.; Ng, A.Y.; Manning, C.D. Parsing Natural Scenes and Natural Language with Recursive Neural Networks. 2011. Available online: https://nlp.stanford.edu/pubs/SocherLinNgManning_ICML2011.pdf (accessed on 19 October 2018).
- Wang, P.; Xu, J.; Xu, B.; Liu, C.; Zhang, H.; Wang, F.; Hao, H. Semantic clustering and convolutional neural network for short text categorization. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Short Papers), Beijing, China, 26–31 July 2015; Volume 2, pp. 352–357. [Google Scholar]
- Labutov, I.; Lipson, H. Re-embedding words. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Short Papers), Sofia, Bulgaria, 4–9 August 2013; Volume 2, pp. 489–493. [Google Scholar]
- Chollet, F. Keras: Deep Learning Library for Theano and Tensorflow. Date Sci. 2015, 7, 8. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. Artif. Intell. 2016, 16, 265–283. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Replicated softmax: An undirected topic model. In Proceedings of the 23rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1607–1614. [Google Scholar]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on Machine Learning, Omnipress, Washington, DC, USA, 28 June–2 July 2011; pp. 265–272. [Google Scholar]
- Bernardi, R.; Cakici, R.; Elliott, D.; Erdem, A.; Erdem, E.; Ikizler-Cinbis, N.; Keller, F.; Muscat, A.; Plank, B. Automatic description generation from images: A survey of models, datasets, and evaluation measures. J. Artif. Intell. Res. 2016, 55, 409–442. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar]
- Van Hulse, J.; Khoshgoftaar, T.M.; Napolitano, A. Experimental perspectives on learning from imbalanced data. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 935–942. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V. Data Mining for Imbalanced Datasets: An Overview. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin, Germany, 2009; pp. 875–886. [Google Scholar]
- Van Der Maaten, L. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. Mach. Learn. 2017, arXiv:1701.04862. [Google Scholar]
- Theis, L.; Oord, A.V.D.; Bethge, M. A note on the evaluation of generative models. Mach. Learn. 2015, arXiv:1511.01844. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised visual domain adaptation using subspace alignment. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- LeCun, Y.; Chopra, S.; Hadsell, R.; Ranzato, M.; Huang, F. A tutorial on energy-based learning. In Predicting Structured Data; MIT Press: Cambridge, MA, USA, 2006; Volume 1. [Google Scholar]
- Denton, E.; Chintala, S.; Szlam, A.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. Comput. Vis. Pattern Recogn. 2015, arXiv:1506.05751, 1486–1494. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Level of Analysis | Model | Dataset | Task | Evaluation Metrics |
|---|---|---|---|---|---|
| Rahman et al. [32] | Docs. | LSTM | Large Movie Review (50,000 reviews) | classification | Acc.: 80% |
| Lai et al. [33] | Docs. | RCNN | 20 Newsgroups; Fudan Set; ACL Anthology Network; SST | classification | Macro-F1: 96.49% Acc.: 95.2% Acc.: 49.19% Acc.: 47.21% |
| Shen et al. [34] | Docs. | CNN + BLSTM | Large Movie Review (50,000 reviews) | classification | Acc.: 89.7% |
| Yender and Verna [35] | Docs. | CNN + LSTM | Large Movie Review (50,000 reviews) | classification | Acc.: 89.5% |
| Liu et al. [36] | Docs. Sents. | RNN | SST1 (Sents.); SST2 (Sents.); Movie Reviews (subj/obj. reviews); Large Movie Review (50,000 reviews) | classification | Acc.: 49.6% Acc.: 87.9% Acc.: 94.1% Acc.: 91.3% |
| Chen et al. [37] | Sents. | BiLSTM-CRF CNN | MPQA opinion corpus; SST; Movie Reviews (polarity v1.0) | classification; target extraction | - Acc.: up to 88.3% Acc.: 82.3% |
| Wang X et al. [38] | Sents. | CNN + RNN | SST1; SST2; Movie Reviews | classification | Acc.: 51.50% Acc.: 89.95% Acc.: 82.28% |
| Conneau et al. [39] | Sents. | Very Deep CNN | Product Reviews; News | classification | not reported |
| Wang J et al. [40] | Sents. | CNN + LSTM | SST; Chinese VA Texts | dimensional regression | RMSE/MAE/r: 1.341/0.987/0.778 RMSE/MAE/r: 0.874/0.689/0.557 |
| Du et al. [41] | Docs. | Deep CNN | Amazon reviews | aspect classification | Acc.: 94.38% |
| Wang Y et al. [42] | Sents. | attention based LSTM | SemEval 2014 (Task 4) | aspect (binary) classification | Acc.: 89.9% |
| Poria et al. [43] | Sents. | Deep CNN | SemEval 2014; Aspect-based dataset | aspect extraction; classification | Acc.: up to 87.2% |
| Tang et al. [44] | Sents. | Deep Memory Network | SemEval 2014 | aspect classification | Acc.: 80.95% |
| Datasets | Training | Validation | Test |
|---|---|---|---|
| 20 Newsgroup (http://qwone.com/~jason/20Newsgroups/) | 10.163 | 1130 | 7528 |
| Movie Reviews [58] | 7424 | 76 | 2500 |
| Finegrained Dataset (FSD) [59] | 2582 | 287 | 956 |
| Baseline | Proposed GAN | |||||
|---|---|---|---|---|---|---|
| Dataset | Precision | Recall | F-measure | Precision | Recall | F-measure |
| 20 Newsgroups | 0.2521 | 0.0001 | 0.996 × | 0.4188 | 0.0001 | 1.999 × |
| 0.2099 | 0.0002 | 3.996 × | 0.4012 | 0.0002 | 3.996 × | |
| 0.1005 | 0.0005 | 9 × | 0.3648 | 0.0005 | 9.986 × | |
| Movie Reviews | 0.3637 | 0.0001 | 1.999 × | 0.6376 | 0.0001 | 1.999 × |
| 0.3637 | 0.0002 | 3.978 × | 0.6376 | 0.0002 | 3.998 × | |
| 0.3901 | 0.0005 | 9.871 × | 0.6202 | 0.0005 | 9.991 × | |
| Finegrained Dataset (FSD) | 0.1022 | 0.0001 | 2.101 × | 0.3522 | 0.0001 | 2 × |
| 0.1152 | 0.0002 | 3.993 × | 0.3483 | 0.0002 | 3.997 × | |
| 0.3185 | 0.0005 | 9 × | 0.3483 | 0.0005 | 9.985 × | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vlachostergiou, A.; Caridakis, G.; Mylonas, P.; Stafylopatis, A. Learning Representations of Natural Language Texts with Generative Adversarial Networks at Document, Sentence, and Aspect Level. Algorithms 2018, 11, 164. https://doi.org/10.3390/a11100164
Vlachostergiou A, Caridakis G, Mylonas P, Stafylopatis A. Learning Representations of Natural Language Texts with Generative Adversarial Networks at Document, Sentence, and Aspect Level. Algorithms. 2018; 11(10):164. https://doi.org/10.3390/a11100164
Chicago/Turabian StyleVlachostergiou, Aggeliki, George Caridakis, Phivos Mylonas, and Andreas Stafylopatis. 2018. "Learning Representations of Natural Language Texts with Generative Adversarial Networks at Document, Sentence, and Aspect Level" Algorithms 11, no. 10: 164. https://doi.org/10.3390/a11100164