
CNN Based on Transfer Learning Models Using Data Augmentation and Transformation for Detection of Concrete Crack

 ,
,  , and
, and
Abstract
:1. Introduction
- We conduct experiments on the CCIC dataset with four different CNN models (VGG16, ResNet18, DenseNet161, and AlexNet), applying the transfer learning technique for detecting concrete surface cracks from images and examination with other models to demonstrate the success of the suggested model.
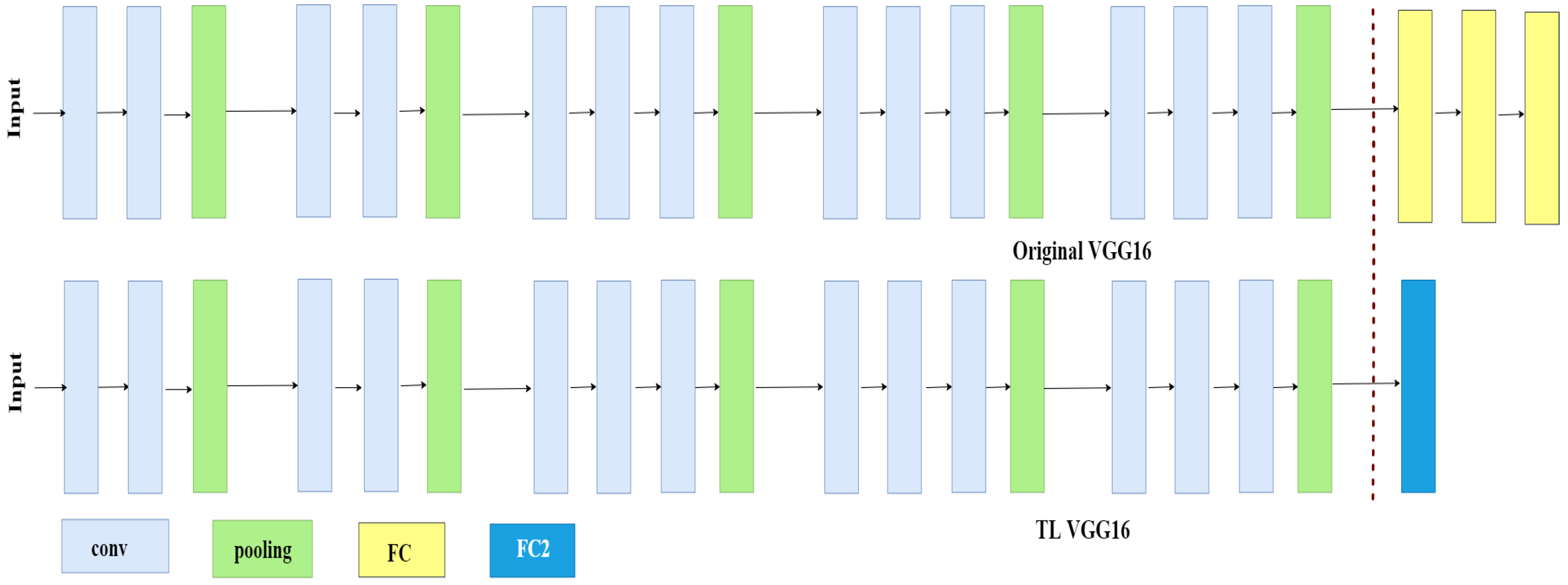
- We designed our model such that every CNN model has only one fully connected (FC) layer, having two output features for binary classification. We modified the VGG16 and AlexNet models by replacing the last three FC layers with only one FC layer.
- Our strategy is the most compatible with AlexNet, and it outperforms the competition. AlexNet achieves accuracy on the validation set on the CCIC dataset.
- The proposed method demonstrates superior crack detection for concrete structures, which can efficiently be utilized for other detection purposes.
2. Literature Review
3. Materials and Methods
3.1. Dataset Description
3.2. Dataset Splitting
3.3. Data Augmentation and Transformation
3.3.1. Random-Resized-Crop Method
3.3.2. Random-Rotation Method
3.3.3. Color-Jitter Method
3.3.4. Random-Horizontal-Flip Method
3.4. Design Transfer Learning Model
3.4.1. VGG16
3.4.2. ResNet18
3.4.3. DenseNet161
3.4.4. AlexNet
3.5. Experimental Setup, Model Training, and Evaluation
4. Result Exploration and Argument
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aggelis, D.G.; Alver, N.; Chai, H.K. Health Monitoring of Civil Infrastructure and Materials. Sci. World J. 2014, 2014, 435238. [Google Scholar] [CrossRef] [PubMed]
- Gavilán, M.; Balcones, D.; Marcos, O.; Llorca, D.F.; Sotelo, M.A.; Parra, I.; Ocaña, M.; Aliseda, P.; Yarza, P.; Amírola, A. Adaptive road crack detection system by pavement classification. Sensors 2011, 11, 9628–9657. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Hu, Y.; Dai, Y.; Tian, M. Asphalt pavement pothole detection and segmentation based on wavelet energy field. Math. Probl. Eng. 2017, 2017, 1604130. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Nakamura, S.; Saegusa, R.; Hashimoto, S. Image-based crack detection for real concrete surfaces. IEEJ Trans. Electr. Electron. Eng. 2008, 31, 128–135. [Google Scholar] [CrossRef]
- Tsai, Y.C.; Kaul, V.; Mersereau, R.M. Critical assessment of pavement distress segmentation methods. J. Transp. Eng. 2010, 136, 11–19. [Google Scholar] [CrossRef]
- Albert, P.; Nii, A. Evaluating pavement cracks with bidimensional empirical mode decomposition. EURASIP J. Adv. Signal Process. 2008, 2008, 861701. [Google Scholar] [CrossRef]
- Peggy, S.; Jean, D.; Vincent, L.; Dominique, B. Automation of pavement surface crack detection using the continuous wavelet transform. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8 October 2006. [Google Scholar]
- Yann, L.; Yoshua, B.; Geoffrey, H. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Valuevaa, M.; Nagornovb, N.; Lyakhovab, P.; Valueva, G.; Chervyakova, N. Application of the residue number system to reduce hardware costs of the convolutional neural network implementation. Math. Comput. Simul. 2020, 177, 232–243. [Google Scholar] [CrossRef]
- Hasan, K.F.; Overall, A.; Ansari, K.; Ramachandran, G.; Jurdak, R. Security, privacy and trust: Cognitive internet of vehicles. arXiv 2021, arXiv:2104.12878. [Google Scholar]
- Jinsong, Z.; Song, J. An intelligent classification model for surface defects on cement concrete bridges. Appl. Sci. 2020, 10, 972. [Google Scholar] [CrossRef]
- Chen, T.; Cai, Z.; Zhao, X.; Chen, C.; Liang, X.; Zou, T.; Wang, P. Pavement crack detection and recognition using the architecture of segNet. J. Ind. Inf. Integr. 2020, 18, 100144. [Google Scholar] [CrossRef]
- Sayyed, B.A.; Reshul, W.; Sameer, K.; Anurag, S.; Santosh, K. Wall Crack Detection Using Transfer Learning-based CNN Models. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020. [Google Scholar]
- Yuqing, G.; Khalid, M.M. Deep transfer learning for image-based structural damage recognition. Comput. Civ. Infrastruct. Eng. 2018, 33, 748–768. [Google Scholar] [CrossRef]
- Zheng, Z.; Qi, H.; Zhuang, L.; Zhang, Z. Automated rail surface crack analytics using deep data-driven models and transfer learning. Sustain. Cities Soc. 2021, 70, 102898. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuen, K.V. Crack detection using fusion features-based broad learning system and image processing. Comput. Civ. Infrastruct. Eng. 2021, 36, 1568–1584. [Google Scholar] [CrossRef]
- Cao, V.D.; Hidehiko, S.; Suichi, H.; Takayuki, O.; Chitoshi, M. A vision-based method for crack detection in gusset plate welded joints of steel bridges using deep convolutional neural networks. Autom. Constr. 2019, 102, 217–229. [Google Scholar] [CrossRef]
- Wilson, R.L.S.; Diogo, S.L. Concrete cracks detection based on deep learning image classification. Multidiscip. Digit. Publ. Inst. Proc. 2018, 2, 489. [Google Scholar] [CrossRef]
- Xiuying, M. Concrete Crack Detection Algorithm Based on Deep Residual Neural Networks. Sci. Program. 2021, 2021, 3137083. [Google Scholar] [CrossRef]
- Ozgenel, Ç.F.; Sorguç, G.A. Performance comparison of pretrained convolutional neural networks on crack detection in buildings. In Proceedings of the 35th International Symposium on Automation and Robotics in Construction (ISARC 2018), Berlin, Germany, 20–25 July 2018. [Google Scholar]
- Tien-Thinh, L.; Van-Hai, N.; Minh Vuong, L.E. Development of deep learning model for the recognition of cracks on concrete surfaces. Appl. Comput. Intell. Soft Comput. 2021, 2021, 18858545. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Yang, C.; Chen, J.; Li, Z.; Huang, Y. Structural Crack Detection and Recognition Based on Deep Learning. Appl. Sci. 2021, 11, 2868. [Google Scholar] [CrossRef]
- Wu, L.; Lin, X.; Chen, Z.; Lin, P.; Cheng, S. Surface crack detection based on image stitching and transfer learning with pretrained convolutional neural network. Struct. Control Health Monit. 2021, 28, e2766. [Google Scholar] [CrossRef]
- Kong, X.; Li, J. Vision-based fatigue crack detection of steel structures using video feature tracking. Comput. Civ. Infrastruct. Eng. 2018, 33, 783–799. [Google Scholar] [CrossRef]
- Guo, X.H.; Bao, L.H.; Zhong, Y.L.; Li, H.; Ping, L. Pavement Crack Detection Method Based on Deep Learning Models. Wirel. Commun. Mob. Comput. 2021, 2021, 5573590. [Google Scholar] [CrossRef]
- Li, W.; Chen, H.; Zhang, Y.; Shi, Y. Track slab crack detection based on full convolutional neural network. In Proceedings of the 2021 4th International Conference on Advanced Algorithms and Control Engineering (ICAACE 2021), Sanya, China, 29–31 January 2021. [Google Scholar]
- Gerivan, S.J.; Janderson, F.; Cristian, M.; Ramiro, D.; Alberto, C.J.; Bruno, J.T.F. Ceramic cracks segmentation with deep learning. Appl. Sci. 2021, 11, 6017. [Google Scholar] [CrossRef]
- Wei, Y.; Wei, Z.; Xue, K.; Yao, W.; Wang, C.; Hong, Y. Automated detection and segmentation of concrete air voids using zero-angle light source and deep learning. Autom. Constr. 2021, 130, 103877. [Google Scholar] [CrossRef]
- Diana, A.A.; Anand, N.; Eva, L.; Prince, A.G. Deep Learning based Thermal Crack Detection on Structural Concrete Exposed to Elevated Temperature. Adv. Struct. Eng. 2021, 24, 1896–1909. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Wang, J.; Wang, L.; Yue, X.G. Concrete cracks detection based on FCN with dilated convolution. Appl. Sci. 2019, 9, 2686. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Lei, Z.; Fan, Y.; Yimin, D.Z.; Ying, J.Z. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Connor, S.; Taghi, M.K. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Talukder, M.A.; Islam, M.M.; Uddin, M.A.; Akhter, A.; Hasan, K.F.; Moni, M.A. Machine learning-based lung and colon cancer detection using deep feature extraction and ensemble learning. Expert Syst. Appl. 2022, 205, 117695. [Google Scholar] [CrossRef]
- Bala, M.; Ali, M.H.; Satu, M.S.; Hasan, K.F.; Moni, M.A. Efficient Machine Learning Models for Early Stage Detection of Autism Spectrum Disorder. Algorithms 2022, 15, 166. [Google Scholar] [CrossRef]
- Bengio, Y.; Lecun, Y.; Hinton, G. Deep learning for AI. Commun. ACM 2021, 64, 58–65. [Google Scholar] [CrossRef]
- Kim, D.; MacKinnon, T. Artificial intelligence in fracture detection: Transfer learning from deep convolutional neural networks. Clin. Radiol. 2018, 73, 439–445. [Google Scholar] [CrossRef]
- Karen, S.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Alex, K. One weird trick for parallelizing convolutional neural networks. arXiv 2014, arXiv:1404.5997. [Google Scholar]
- Christian, S.; Vincent, V.; Sergey, L.; Jon, S.; Zbigniew, W. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Alex, K. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hossain, M.B.; Iqbal, S.H.S.; Islam, M.M.; Akhtar, M.N.; Sarker, I.H. Transfer learning with fine-tuned deep CNN ResNet50 model for classifying COVID-19 from chest X-ray images. Inform. Med. Unlocked 2022, 30, 100916. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crack | Non-Crack | Total | |
|---|---|---|---|
| Train | 16,000 | 15,999 | 31,999 |
| Test | 4000 | 4001 | 8001 |
| Total | 20,000 | 20,000 | 40,000 |
| Parameters | Parameters Value |
|---|---|
| Batch size | 128 |
| Optimizer | Adam |
| Learning rate | 0.001 |
| Betas | (0.9, 0.999) |
| Eps | 1 × |
| Weight decay | 0 |
| Criterion | Cross Entropy Loss |
| Model | P (%) | R (%) | F1 (%) | Sup | A (%) | MCC (%) | CK (%) | |
|---|---|---|---|---|---|---|---|---|
| TL VGG16 | Crack | 99.73 | 99.90 | 99.81 | 4000 | 99.81 | 99.6252 | 99.6250 |
| Non-crack | 99.90 | 99.73 | 99.81 | 4001 | ||||
| TL ResNet18 | Crack | 98.96 | 99.70 | 99.33 | 4000 | 99.33 | 98.6529 | 98.6502 |
| Non-crack | 99.70 | 98.95 | 99.32 | 4001 | ||||
| TLDenseNet161 | Crack | 99.50 | 99.85 | 99.68 | 4000 | 99.68 | 99.3507 | 99.3501 |
| Non-crack | 99.85 | 99.50 | 99.67 | 4001 | ||||
| TL AlexNet | Crack | 99.92 | 99.80 | 99.86 | 4000 | 99.86 | 99.7251 | 99.7250 |
| Non-crack | 99.80 | 99.93 | 99.86 | 4001 |
| Model | Train/Test | Max Acc (%) | MA_E | Min Acc (%) | MinA_E | Avg_acc (%) |
|---|---|---|---|---|---|---|
| TL VGG16 | Train | 99.76 | 30 | 98.06 | 1 | 99.61 |
| Test | 99.86 | 29 | 99.65 | 17 | 99.78 | |
| TL ResNet18 | Train | 99.09 | 29 | 95.31 | 1 | 98.74 |
| Test | 99.41 | 18 | 98.09 | 1 | 99.22 | |
| TL DenseNet161 | Train | 99.51 | 25 | 96.68 | 1 | 99.24 |
| Test | 99.68 | 27 | 99.29 | 1 | 99.60 | |
| TL AlexNet | Train | 99.85 | 24 | 98.34 | 1 | 99.72 |
| Test | 99.90 | 13 | 99.58 | 20 | 99.84 | |
| All | Train Max Acc | 99.85 | TL AlexNet at Epoch 24 | |||
| Test Max Acc | 99.90 | TL AlexNet at Epoch 13 | ||||
| Both Max Acc | 99.90 | TL AlexNet at Epoch 13 | ||||
| Model | Duration Per-Epoch (h:mm:ss) | Remarks |
|---|---|---|
| TL VGG16 | 0:08:46.729322 | 3rd place |
| TL ResNet18 | 0:03:35.636223 | 2nd place |
| TL DenseNet161 | 0:13:39.103467 | Lowest place |
| TL AlexNet | 0:02:53.093954 | 1st place |
| TL AlexNet takes the 1st position by achieving the least training time | ||
| Image Folder | No. of Crack Images | No. of Noncrack Images | Total |
|---|---|---|---|
| Test | 500 | 500 | 1000 |
| Train | 1250 | 1250 | 2500 |
| Validation | 500 | 500 | 1000 |
| Model | P (%) | R(%) | F1 (%) | A (%) | MCC (%) | CK (%) | |
|---|---|---|---|---|---|---|---|
| TL VGG16 | Crack | 99.80 | 1.00 | 99.90 | 99.90 | 99.8000 | 99.7998 |
| Non-crack | 1.00 | 99.80 | 99.90 | ||||
| TL ResNet18 | Crack | 99.40 | 99.80 | 99.60 | 99.60 | 99.1999 | 99.1992 |
| Non-crack | 99.80 | 99.40 | 99.60 | ||||
| TLDenseNet161 | Crack | 99.60 | 1.00 | 99.80 | 99.80 | 99.6004 | 99.5996 |
| Non-crack | 1.00 | 99.60 | 99.80 | ||||
| TL AlexNet | Crack | 1.00 | 99.80 | 99.90 | 99.90 | 99.7999 | 99.7997 |
| Non-crack | 99.80 | 1.00 | 99.90 |
| SN | Reference | Base Model or Method | Accuracy | Dataset |
|---|---|---|---|---|
| 01 | [14] | VGG16 | 90% | Beam, column, wall and joint brace images of a building |
| 02 | [16] | FF-BLS | 96.72% | CCIC dataset |
| 03 | [17] | VGG16 | 94%, 98% | Fatigue cracks in gusset plate joints in steel bridges |
| 04 | [12] | SegNet | 99% | Concrete pavement, asphalt pavement, and bridge deck cracks images |
| 05 | [18] | VGG16 | 92.27% | Concrete surfaces dataset collected from the Danish Technological Institute |
| 06 | [21] | DCNN model | 97.70% | CCIC dataset |
| 07 | [23] | ResNet18 | 98.80% | Roads and bridges crack images |
| 08 | [24] | GoogLeNet Inception V3 | 97.30% | Wall images at college of environmental resources of Fuzhou University |
| 09 | [13] | MobileNet | 99.59% | Wall, pavements, bridge deck images |
| 10 | [26] | YOLOv5 | 88.10% | Asphalt crack pavement images |
| 11 | Proposed | AlexNet | 99.90% | CCIC dataset |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.M.; Hossain, M.B.; Akhtar, M.N.; Moni, M.A.; Hasan, K.F. CNN Based on Transfer Learning Models Using Data Augmentation and Transformation for Detection of Concrete Crack. Algorithms 2022, 15, 287. https://doi.org/10.3390/a15080287
Islam MM, Hossain MB, Akhtar MN, Moni MA, Hasan KF. CNN Based on Transfer Learning Models Using Data Augmentation and Transformation for Detection of Concrete Crack. Algorithms. 2022; 15(8):287. https://doi.org/10.3390/a15080287
Chicago/Turabian StyleIslam, Md. Monirul, Md. Belal Hossain, Md. Nasim Akhtar, Mohammad Ali Moni, and Khondokar Fida Hasan. 2022. "CNN Based on Transfer Learning Models Using Data Augmentation and Transformation for Detection of Concrete Crack" Algorithms 15, no. 8: 287. https://doi.org/10.3390/a15080287