1. Introduction
In recent years, wildfires have been a growing concern around the world. These wildland fires have devastated vast areas of forest and other plants, forcing tens of thousands of people to evacuate their homes and causing irreparable damage to the ecology. The increasing frequency of forest fires can be attributed to a variety of factors, such as climate change, drought, and human activities. Consequently, governments are confronted with substantial management expenses on an annual basis in order to address this pressing issue. Forest fires have become more severe and frequent in many parts of the world, including Australia, California, the Amazon rainforest, and the Mediterranean region [
1]. Despite efforts to regulate and minimize them, forest fires continue to be a huge problem for governments, environmental groups, and people all over the world. Thus, the implementation of efficient forest fire monitoring holds significant importance in protecting forest resources and ensuring the well-being of human life and property [
2].
Recent forest fire data confirms a long-standing concern: the increasing prevalence of forest fires, now consuming almost double the amount of tree cover as two decades ago. In 2021, which marked one of the worst years for forest fires since the beginning of the century, 9.3 million hectares of tree cover were lost worldwide—equivalent to more than a third of all tree cover loss for that year [
3]. Over the past three years, statistics reveal a concerning trend in the scale and intensity of wildfires. In 2021, despite the relatively low number of fires, a significant area of 7.1 M acres was consumed, resulting in a relatively high average of 121.56 acres burned per fire in the US. Similarly, in 2022, while the number of fires remained relatively low, the burned area increased to 7.5 M acres, with an average of 113.72 acres burned per fire. The data for January to April 2023 indicate a continuation of this worrisome trend in the US, with a relatively low number of fires but a substantial average of 30.24 acres burned per fire [
4]. Canada has also experienced a total of 5738 fires this year, resulting in the scorching of 13.7 million hectares (equivalent to 33.9 million acres) [
5]. Moreover, recurring environmental problems in Southeast Asia include wildfires, notably linked to land and forest fires, mainly affecting nations such as Indonesia and Malaysia. The devastating 1997–1998 forest fires devoured roughly 8 million hectares of land, leading to an estimated economic loss of approximately USD 4.47 billion, with Indonesia bearing the largest share of this burden [
6]. In 2019, intense forest fires in the Indonesian regions of Sumatra and Kalimantan burned over 930,000 hectares, leading to evacuations and the deployment of over 9000 personnel to combat the flames [
7]. These figures underscore the urgent need for proactive measures to mitigate and prevent the devastating impact of forest fires on our environment and communities.
Various fire detection sensors, including those measuring smoke, temperature, gas, flame, etc., face limitations such as restricted coverage, delayed response, and challenges with public accessibility. The advancements in image processing and computer vision technology have made substantial contributions to the timely identification, surveillance, and control of forest wildfires. Consequently, the conventional methods for traditional fire detection, like flame-smoke sensors, are being substituted by vision-based models. These models offer numerous advantages over traditional sensors, including greater accuracy, reduced susceptibility to errors, environmental robustness, lower cost, and broader coverage [
8].
Thoroughly observing fires can be achieved through the integration of data obtained from many sources, including infrared cameras, thermal sensors, and visible-light cameras. The utilization of image processing, computer vision, and deep learning techniques enables the fusion of these data streams, thereby increasing the precision of fire detection and analysis. Researchers have attempted to offer numerous unique strategies based on computer vision and image processing over the years to set up the most accurate, efficient, and optimized fire detection system conceivable. The color analysis method is commonly used to identify fire based on its color. This approach involves transforming the image into a different color space, such as YCbCr [
9,
10]. In this color space, the Y component represents the luma (brightness) or luminance, while the Cb and Cr components represent the blue and red components, respectively. While feature-based strategies have performed well in fire detection tasks, machine learning (ML) techniques [
11,
12] have surpassed them. Support Vector Machine (SVM), Markov models [
13], Instance-Based Learning classifiers [
14], and Bayesian classifiers [
15] are popular fire classification algorithms that are specifically designed to predict the likelihood of a wildfire occurrence within an input image.
The primary challenge of the mentioned strategies lies in identifying relevant attributes that best describe the topic at present. As an alternative, a self-learning network can be employed to acquire relevant features autonomously. Deep learning (DL) techniques can deliver excellent accuracy for fire classification and detection if a sufficiently extensive dataset is utilized during the training process. The capacity of DL-based fire classification and detection algorithms to automatically learn high-level features provides a key advantage over conventional techniques. In the existing literature, it has been observed that to detect forest fires, multiple pre-trained DL algorithms have been incorporated such as ResNet50, AlexNet, GoogleNet, VGG16, and MobileNetV2 [
16,
17,
18]. In recent studies, we have observed the extensive exploration of various attention mechanisms in the context of image classification and segmentation tasks. Forest fire classification utilizing attention mechanisms leverages advanced neural network techniques to efficiently identify and respond to critical patterns and features in imagery, enhancing the accuracy of fire detection and prevention [
19,
20]. Accordingly, we introduce an attention-guided multi-stream hybrid model for forest fire classification. The proposed approach is straightforward, employing two streams for effective feature extraction. One stream employs the pre-trained EfficientNetB7 [
21] method, while the other utilizes a custom-built Attention Connected Network (ACNet). EfficientNet is chosen for its reliable scalability, achieved through uniform scaling of network dimensions. Specifically, EfficientNetB7 is utilized for its exceptional feature extraction capabilities from fire images. ACNet, on the other hand, enhances the model’s ability to capture both low-level and high-level features, offering multiple perspectives on feature importance and interdependencies. We also employ the Bayesian optimization (BO) [
22] method to optimize the model’s hyperparameters. The objective is to optimize the key parameters of classifiers through the utilization of BO. Therefore, it is expected that the accuracy of the model is going to improve. Furthermore, we implement the GRAD-CAM [
23] technique to enhance the model’s interpretability. Our attention-guided dual-stream hybrid model not only enhances forest fire classification accuracy, but also holds the potential for real-world applications in forest and wildfire management. By enabling more precise and interpretable forest fire classification, our approach can play a pivotal role in early detection of fire, rapid response, and optimized resource allocation, ultimately contributing to the mitigation and control of forest fires. The major contributions of this study can be summarized as follows:
We introduce a novel dual stream attention guided network for the classification of forest fires.
In the first stream, we use EfficientNetB7 as a feature extractor to efficiently extract high-level features from images.
In the second stream, we incorporate the newly proposed attention connected module, comprising a fusion of both Efficient Channel Attention and Squeeze-and-Excitation Network modules within the network architecture. This integration not only brought selective attention, but also featured enhancement, effectively optimizing the model’s forest fire classification capabilities. Bayesian optimization was employed to fine-tune hyper-parameters, enhancing the model’s performance.
Our proposed architecture’s effectiveness is being thoroughly demonstrated on two widely recognized benchmark datasets. Comprehensive analyses demonstrate its superiority over several state-of-the-art methods.
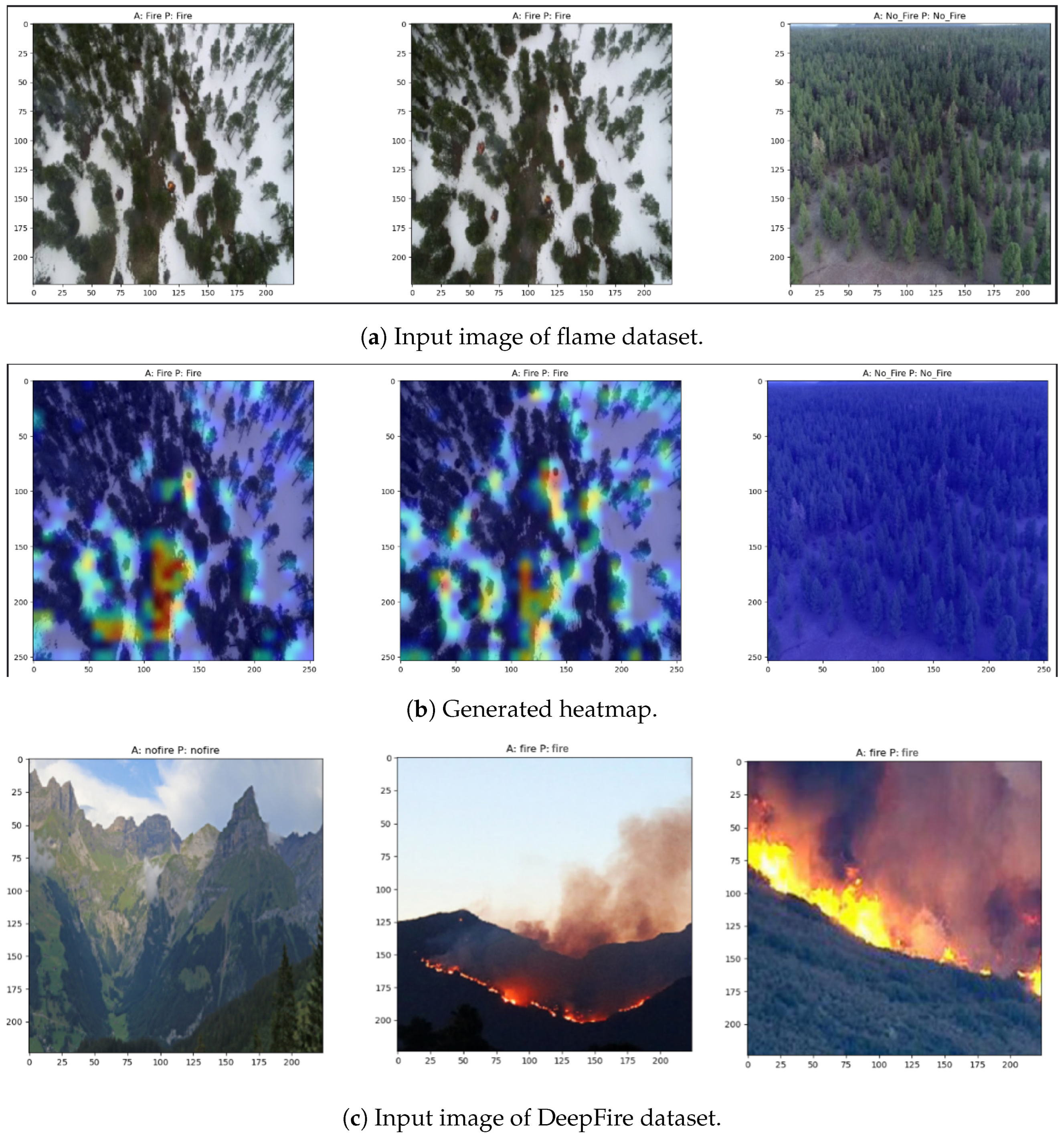
To enhance model interpretability, we integrate the GRAD-CAM technique to understand which parts of the images were most important in guiding the model’s decision-making process.
The rest of the paper is organized as follows. The related works
Section 2 contains a full review of previous approaches for detecting forest fires. The Materials and Methods
Section 3 provides a full explanation of the proposed model. The result analysis
Section 4 gives an overview of the results obtained. Finally, in
Section 6, the paper is brought to a close.
6. Conclusions
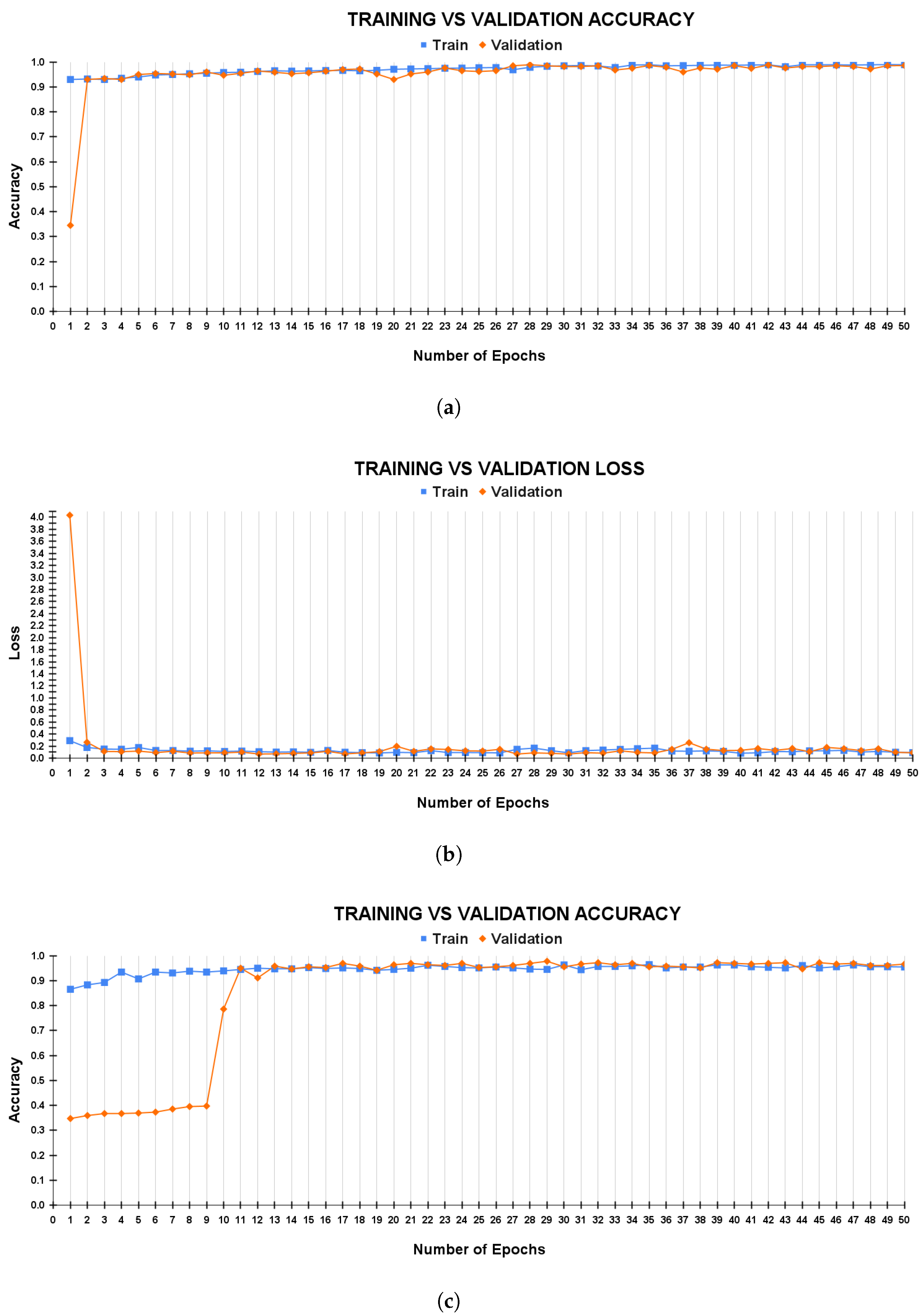
In this paper, we present a novel model that incorporates a pre-trained EfficientNetB7, a customized Attention Guided Network called ACNet, and the BO technique. This model provides high accuracy for forest fire classification. To enhance the interpretability of this model, we implemented GRAD-CAM, which allows us to localize the fire within the feature map. This enables a deeper understanding of the model’s decision-making process and provides valuable insights for fire detection. Furthermore, k-fold cross-validation was conducted to rigorously assess the model’s performance. On the FLAME dataset, the model attained an accuracy of 97.45%, precision of 98.20%, recall of 97.10%, and an F1-score of 97.12%. Similarly, on the DeepFire dataset, the model demonstrated an accuracy of 95.97%, precision of 95.19%, recall of 96.01%, and an F1-score of 95.54%. The F1-score of the both dataset indicates that the model achieved a strong balance between precision and recall. This is a positive sign as it suggests that the model is effective at both correctly identifying positive cases (fire region) and minimizing false positives. The high accuracy also indicates overall strong performance. Additionally, the ablation study delves into the contributions of each individual component, providing a deeper understanding of how they impact the overall performance of the model. The ablation study showed that our proposed ACM plays a vital role in the model’s performance. Without the ACM, the model’s F1-score dropped to 94.09%, which is significantly lower than the model’s F1-score with the ACM. In other words, the ACM is a key component of the model, and it is essential for achieving good performance. The numerical results along with interpretation through GRAD-CAM provides proof of our proposed model’s efficiency in classifying forest fire. In our future work, we hope to optimize training time for larger network sizes, enabling the training of more powerful and accurate models. We also intend to enhance preprocessing techniques to improve classification outcomes, facilitating more effective learning and producing more precise results. Furthermore, we plan to reduce the model’s computational cost, allowing for seamless integration into mobile devices.



 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}