
Automated Segmentation of Individual Tree Structures Using Deep Learning over LiDAR Point Cloud Data

 ,
,
Abstract
:1. Introduction
- We proposed a new approach that leveraged PointNet++ for segmenting the canopy, trunk, and branches of trees. By applying PointNet++, we addressed the limitations of previous studies that have primarily focused on canopy and trunk segmentation, neglecting branch segmentation.
- We introduced a preprocessing method for LiDAR point cloud data, which was tailored to handle the characteristics of tree-related LiDAR data, leading to improved accuracy in the segmentation results.
- We identified an optimal learning environment for PointNet++ in the context of tree-structure segmentation. We achieved superior segmentation results and enhanced the overall effectiveness of the PointNet++ model.
2. Related Work
3. Materials and Methods
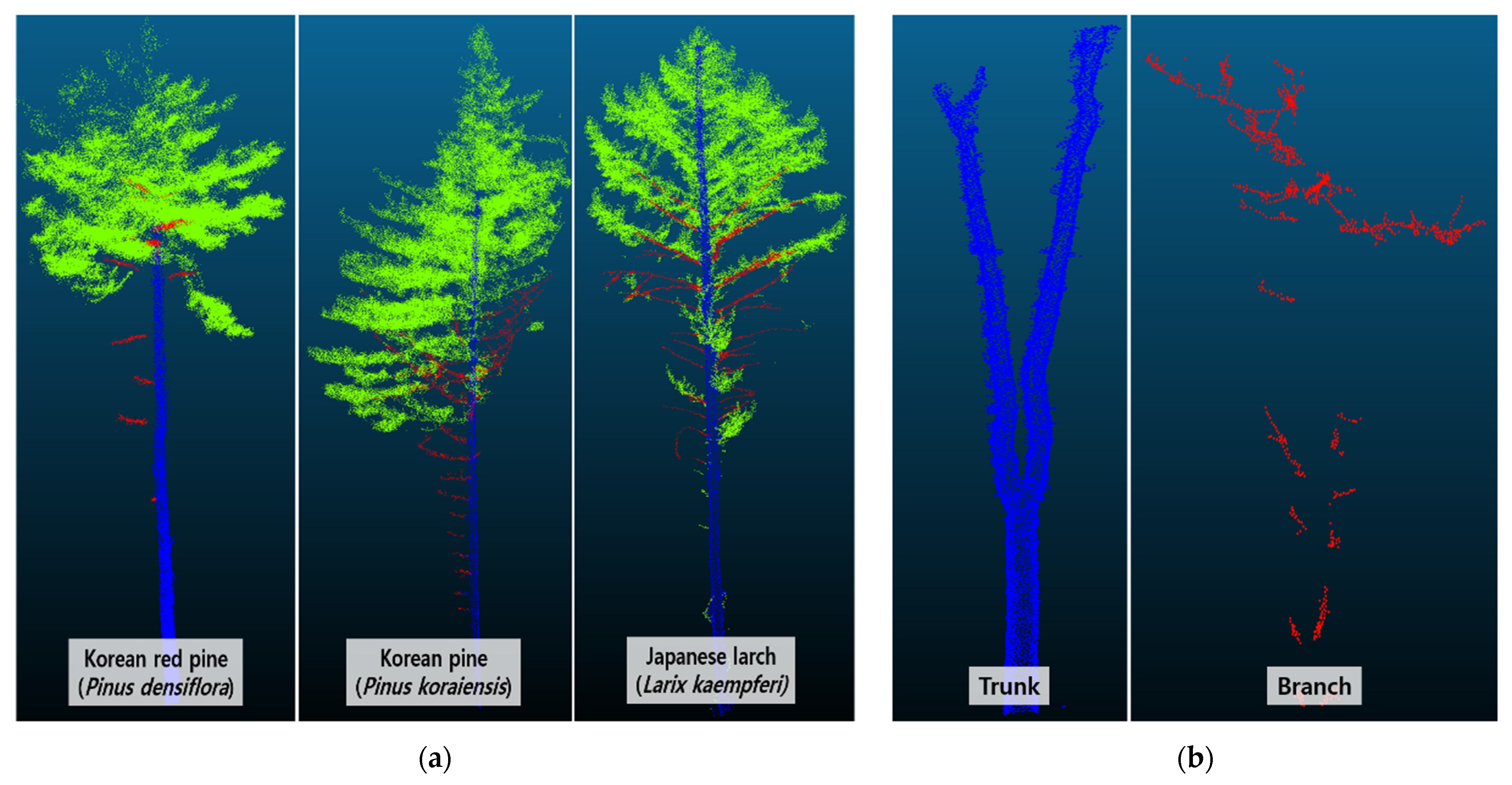
3.1. Data Preparation
3.2. Experiment Environment
- The input data were classified into resampled (canopy, trunk = 10,000 points and branch = 2500, 10,000 points) and non-resampled.
- The learning environment was adjusted by extracting 2048, 4096, and 8196 local and global features at the sampling-layer stage. Setups 1–3 were used for non-resampling as the learning material, whereas Setups 4–6 were used for resampling as a learning environment.
3.3. Evaluation of the Model Performance
4. Statistical and Empirical Analysis of Model Performance
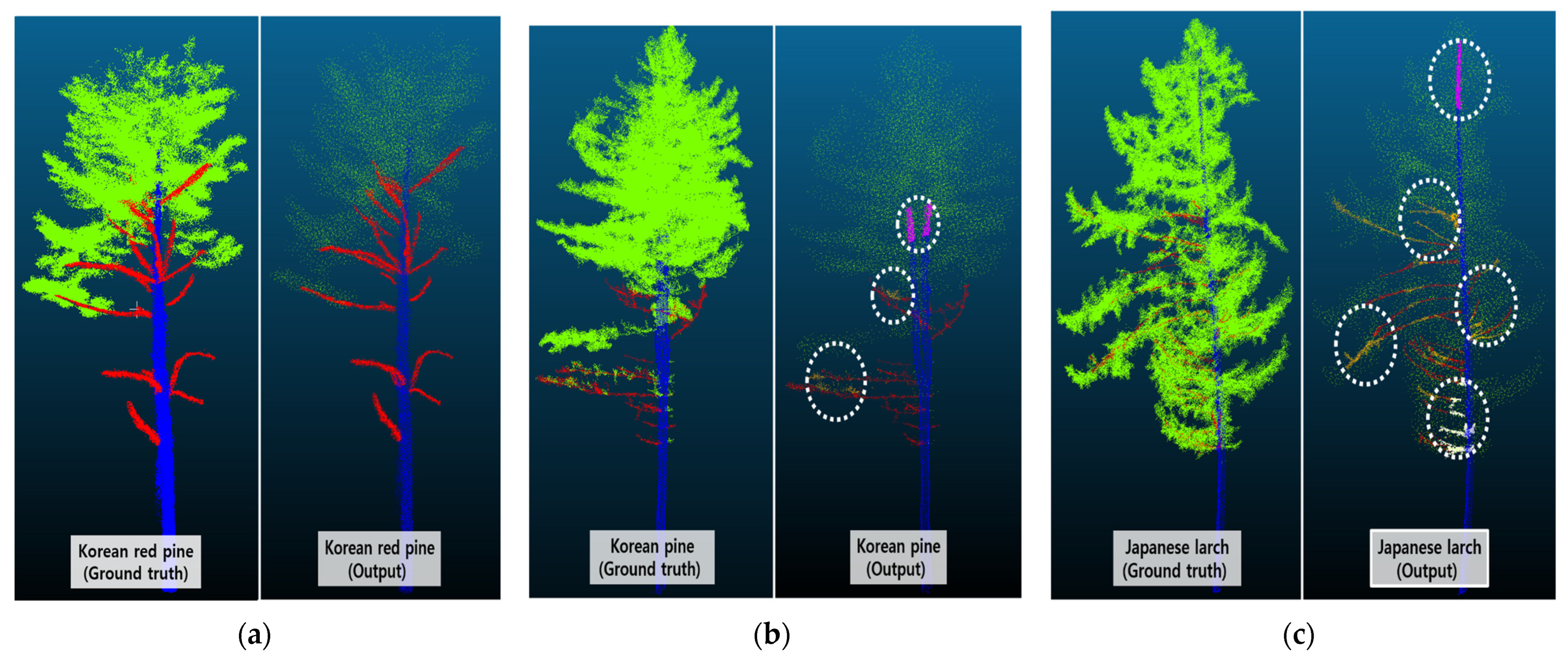
4.1. Experiment A
- For the Korean red pine, precision was the highest for 8192 representative points (86.0%), recall was the highest for 2048 representative points (70.6%), and the best F1 score was achieved for 2048 representative points (0.7), indicating that the segmentation of the Korean red pine without resampling performed well at these numbers of representative points.
- The Korean pine also performed well for 2048 representative points with an F1 score of 0.7.
- The Japanese larch had a lower F1 score of 0.5 in all conditions, which was lower than that of the Korean red pine and Korean pine.
4.2. Experiment B
4.3. Comparative Analysis of Part Segmentation Results in Related Studies
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, H.J.; Ru, J.H. Application of LiDAR Data & High-Resolution Satellite Image for Calculate Forest Biomass. J. Korean Soc. Geospat. Inf. Sci. 2012, 20, 53–63. [Google Scholar]
- Chang, A.J.; Kim, H.T. Study of Biomass Estimation in Forest by Aerial Photograph and LiDAR Data. J. Korean Assoc. Geogr. Inf. Stud. 2008, 11, 166–173. [Google Scholar]
- Lin, Y.C.; Liu, J.; Fei, S.; Habib, A. Leaf-Off and Leaf-On UAV LiDAR Surveys for Single-Tree Inventory in Forest Plantations. Drones 2021, 5, 115. [Google Scholar] [CrossRef]
- Bauwens, S.; Bartholomeus, H.; Calders, K.; Lejeune, P. Forest Inventory with Terrestrial LiDAR: A Comparison of Static and Hand-Held Mobile Laser Scanning. Forests 2016, 7, 127. [Google Scholar] [CrossRef] [Green Version]
- Kankare, V.; Holopainen, M.; Vastaranta, M.; Puttonen, E.; Yu, X.; Hyyppä, J.; Vaaja, M.; Hyyppä, H.; Alho, P. Individual Tree Biomass Estimation using Terrestrial Laser Scanning. ISPRS J. Photogramm. Remote Sens. 2013, 75, 64–75. [Google Scholar] [CrossRef]
- Stovall, A.E.; Shugart, H.H. Improved Biomass Calibration and Validation with Terrestrial LiDAR: Implications for Future LiDAR and SAR Missions. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3527–3537. [Google Scholar] [CrossRef]
- Stovall, A.E.; Vorster, A.G.; Anderson, R.S.; Evangelista, P.H.; Shugart, H.H. Non-Destructive Aboveground Biomass Estimation of Coniferous Trees using Terrestrial LiDAR. Remote Sens. Environ. 2017, 200, 31–42. [Google Scholar] [CrossRef]
- Delagrange, S.; Jauvin, C.; Rochon, P. PypeTree: A Tool for Reconstructing Tree Perennial Tissues from Point Clouds. Sensors 2014, 14, 4271–4289. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Ji, M.; Wang, J.; Wen, W.; Li, T.; Sun, Y. An Improved DBSCAN Method for LiDAR Data Segmentation with Automatic Eps Estimation. Sensors 2019, 19, 172. [Google Scholar] [CrossRef] [Green Version]
- Krisanski, S.; Taskhiri, M.S.; Gonzalez Aracil, S.; Herries, D.; Turner, P. Sensor Agnostic Semantic Segmentation of Structurally Diverse and Complex Forest Point Clouds using Deep Learning. Remote Sens. 2021, 13, 1413. [Google Scholar] [CrossRef]
- Kim, D.W.; Han, B.H.; Park, S.C.; Kim, J.Y. A Study on the Management Method in Accordance with the Vegetation Structure of Geumgang Pine (Pinus densiflora) Forest in Sogwang-ri, Uljin. J. Korean Inst. Landsc. Archit. 2022, 50, 1–19. [Google Scholar]
- Lee, S.J.; Woo, C.S.; Kim, S.Y.; Lee, Y.J.; Kwon, C.G.; Seo, K.W. Drone-Image-Based Method of Estimating Forest-Fire Fuel Loads. J. Korean Soc. Hazard Mitig. 2021, 21, 123–130. [Google Scholar] [CrossRef]
- Brede, B.; Lau, A.; Bartholomeus, H.M.; Kooistra, L. Comparing RIEGL RiCOPTER UAV LiDAR Derived Canopy Height and DBH with Terrestrial LiDAR. Sensors 2017, 17, 2371. [Google Scholar] [CrossRef] [Green Version]
- Trochta, J.; Krůček, M.; Vrška, T.; Král, K. 3D Forest: An Application for Descriptions of Three-Dimensional Forest Structures using Terrestrial LiDAR. PLoS ONE 2017, 12, e0176871. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xi, Z.; Hopkinson, C.; Chasmer, L. Filtering Stems and Branches from Terrestrial Laser Scanning Point Clouds using Deep 3-D Fully Convolutional Networks. Remote Sens. 2018, 10, 1215. [Google Scholar] [CrossRef] [Green Version]
- Moorthy, S.M.K.; Calders, K.; Vicari, M.B.; Verbeeck, H. Improved Supervised Learning-Based Approach for Leaf and Wood Classification from LiDAR Point Clouds of Forests. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3057–3070. [Google Scholar] [CrossRef] [Green Version]
- Gleason, C.J.; Im, J. Forest Biomass Estimation from Airborne LiDAR Data using Machine Learning Approaches. Remote Sens. Environ. 2012, 125, 80–91. [Google Scholar] [CrossRef]
- Zhang, L.; Shao, Z.; Liu, J.; Cheng, Q. Deep Learning Based Retrieval of Forest Aboveground Biomass from Combined LiDAR and Landsat 8 Data. Remote Sens. 2019, 11, 1459. [Google Scholar] [CrossRef] [Green Version]
- Guan, H.; Yu, Y.; Ji, Z.; Li, J.; Zhang, Q. Deep Learning-Based Tree Classification using Mobile LiDAR Data. Remote Sens. Lett. 2015, 6, 864–873. [Google Scholar] [CrossRef]
- Neuville, R.; Bates, J.S.; Jonard, F. Estimating Forest Structure from UAV-Mounted LiDAR Point Cloud using Machine Learning. Remote Sens. 2021, 13, 352. [Google Scholar] [CrossRef]
- Wu, L.; Zhu, X.; Lawes, R.; Dunkerley, D.; Zhang, H. Comparison of Machine Learning Algorithms for Classification of LiDAR Points for Characterization of Canola Canopy Structure. Int. J. Remote Sens. 2019, 40, 5973–5991. [Google Scholar] [CrossRef]
- Su, Z.; Li, S.; Liu, H.; Liu, Y. Extracting Wood Point Cloud of Individual Trees Based on Geometric Features. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1294–1298. [Google Scholar] [CrossRef]
- Wang, D.; Momo Takoudjou, S.; Casella, E. LeWoS: A Universal Leaf-Wood Classification Method to Facilitate the 3D Modelling of Large Tropical Trees using Terrestrial LiDAR. Methods Ecol. Evol. 2020, 11, 376–389. [Google Scholar] [CrossRef]
- Hackenberg, J.; Spiecker, H.; Calders, K.; Disney, M.; Raumonen, P. SimpleTree—An Efficient Open Source Tool to Build Tree Models from TLS Clouds. Forests 2015, 6, 4245–4294. [Google Scholar] [CrossRef]
- Ferrara, R.; Virdis, S.G.; Ventura, A.; Ghisu, T.; Duce, P.; Pellizzaro, G. An Automated Approach for Wood-Leaf Separation from Terrestrial LIDAR Point Clouds using the Density Based Clustering Algorithm DBSCAN. Agric. For. Meteorol. 2018, 262, 434–444. [Google Scholar] [CrossRef]
- Chen, W.; Hu, X.; Chen, W.; Hong, Y.; Yang, M. Airborne LiDAR Remote Sensing for Individual Tree Forest Inventory using Trunk Detection-Aided Mean Shift Clustering Techniques. Remote Sens. 2018, 10, 1078. [Google Scholar] [CrossRef] [Green Version]
- Raumonen, P.; Kaasalainen, M.; Åkerblom, M.; Kaasalainen, S.; Kaartinen, H.; Vastaranta, M.; Holopainen, M.; Disney, M.; Lewis, P. Fast Automatic Precision Tree Models from Terrestrial Laser Scanner Data. Remote Sens. 2013, 5, 491–520. [Google Scholar] [CrossRef] [Green Version]
- Paul, K.I.; Roxburgh, S.H.; Chave, J.; England, J.R.; Zerihun, A.; Specht, A.; Lewis, T.; Bennett, L.T.; Baker, T.G.; Adams, M.A.; et al. Testing the Generality of Above-Ground Biomass Allometry Across Plant Functional Types at the Continent Scale. Glob. Chang. Biol. 2016, 22, 2106–2124. [Google Scholar] [CrossRef]
- Fan, G.; Nan, L.; Dong, Y.; Su, X.; Chen, F. AdQSM: A New Method for Estimating Above-Ground Biomass from TLS Point Clouds. Remote Sens. 2020, 12, 3089. [Google Scholar] [CrossRef]
- Fu, H.; Li, H.; Dong, Y.; Xu, F.; Chen, F. Segmenting Individual Tree from TLS Point Clouds using Improved DBSCAN. Forests 2022, 13, 566. [Google Scholar] [CrossRef]
- Hui, Z.; Jin, S.; Xia, Y.; Wang, L.; Ziggah, Y.Y.; Cheng, P. Wood and Leaf Separation from Terrestrial LiDAR Point Clouds Based on Mode Points Evolution. ISPRS J. Photogramm. Remote Sens. 2021, 178, 219–239. [Google Scholar] [CrossRef]
- Wang, D.; Hollaus, M.; Pfeifer, N. Feasibility of Machine Learning Methods for Separating Wood and Leaf Points from Terrestrial Laser Scanning Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 157–164. [Google Scholar] [CrossRef] [Green Version]
- Windrim, L.; Bryson, M. Detection, Segmentation, and Model Fitting of Individual Tree Stems from Airborne Laser Scanning of Forests using Deep Learning. Remote Sens. 2020, 12, 1469. [Google Scholar] [CrossRef]
- Krisanski, S.; Taskhiri, M.S.; Gonzalez Aracil, S.; Herries, D.; Muneri, A.; Gurung, M.B.; Montgomery, J.; Turner, P. Forest Structural Complexity Tool—An Open Source, Fully-Automated Tool for Measuring Forest Point Clouds. Remote Sens. 2021, 13, 4677. [Google Scholar] [CrossRef]
- Hamraz, H.; Jacobs, N.B.; Contreras, M.A.; Clark, C.H. Deep Learning for Conifer/Deciduous Classification of Airborne LiDAR 3D Point Clouds Representing Individual Trees. ISPRS J. Photogramm. Remote Sens. 2019, 158, 219–230. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Skidmore, A.K.; Wang, T.; Liu, J.; Darvishzadeh, R.; Shi, Y.; Premier, J.; Heurich, M. Improving Leaf Area Index (LAI) Estimation by Correcting for Clumping and Woody Effects using Terrestrial Laser Scanning. Agric. For. Meteorol. 2018, 263, 276–286. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J.; Kaartinen, H.; Lehtomäki, M.; Pyörälä, J.; Pfeifer, N.; Holopainen, M.; Brolly, G.; Francesco, P.; Hackenberg, J.; et al. International Benchmarking of Terrestrial Laser Scanning Approaches for Forest Inventories. ISPRS J. Photogramm. Remote Sens. 2018, 144, 137–179. [Google Scholar] [CrossRef]
- Liu, B.; Chen, S.; Huang, H.; Tian, X. Tree Species Classification of Backpack Laser Scanning Data Using the PointNet++ Point Cloud Deep Learning Method. Remote Sens. 2022, 14, 3809. [Google Scholar] [CrossRef]
- Briechle, S.; Krzystek, P.; Vosselman, G. Classification of Tree Species and Standing Dead Trees by Fusing UAV-Based Lidar Data and Multispectral Imagery in the 3D Deep Neural Network PointNet++. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 2, 203–210. [Google Scholar] [CrossRef]
- Available online: https://github.com/apburt/treeseg (accessed on 4 June 2023).
- Burt, A.; Disney, M.; Calders, K. Extracting Individual Trees from Lidar Point Clouds using treeseg. Methods Ecol. Evol. 2019, 10, 438–445. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. Adv. Neural Inf. Process. Syst. 2017, 30, 1–10. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Kandel, I.; Castelli, M. The Effect of Batch Size on the Generalizability of the Convolutional Neural Networks on a Histopathology Dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Wang, J.; Chen, X.; Cao, L.; An, F.; Chen, B.; Xue, L.; Yun, T. Individual Rubber Tree Segmentation Based on Ground-Based LiDAR Data and Faster R-CNN of Deep Learning. Forests 2019, 10, 793. [Google Scholar] [CrossRef] [Green Version]
- Zou, X.; Cheng, M.; Wang, C.; Xia, Y.; Li, J. Tree Classification in Complex Forest Point Clouds Based on Deep Learning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2360–2364. [Google Scholar] [CrossRef]
- Shen, X.; Huang, Q.; Wang, X.; Li, J.; Xi, B. A Deep Learning-Based Method for Extracting Standing Wood Feature Parameters from Terrestrial Laser Scanning Point Clouds of Artificially Planted Forest. Remote Sens. 2022, 14, 3842. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Method | Deep Learning | Part Segment | Fully Automated | Hyperparameter Tuning Test | Description |
|---|---|---|---|---|---|---|
| [23,24,31] | Random Forest, Data clustering, CPS algorithm | Ⅹ | ◯ | Ⅹ | Ⅹ | A study that combines data clustering and shortest path algorithms to segment the canopy and trunk. |
| [32,33,34,35] | Deep learning, Machine learning | ◯ | ◯ | ◯ | Ⅹ | Validation of deep learning and machine -learning models for canopy and trunk segmentation. |
| Tree Species | Location | Plot Size (n) | Tree Density (Tree/ha−1) | Tree Height (m) | Tree DBH (cm) | LiDAR | Point Density (pts/m2) |
|---|---|---|---|---|---|---|---|
| Korean red pine † | BNA (37°0′27.61″ N, 128°47′45.98″ E) | 30 × 30 m2 (6) | 145 | 26.4 | 51.2 | LiBackpack D50 | 25,579 |
| Korean pine † | LFMZ (37°48′0.86″ N, 127°56′58.08″ E) | 30 × 30 m2 (4) | 278 | 22.3 | 32.1 | Leica RTC360 | 88,746 |
| Japanese larch † | LFMZ (37°48′16.23″ N, 127°56′45.51″ E) | 30 × 30 m2 (7) | 178 | 27.6 | 37.6 | Leica RTC360 | 97,674 |
| Korean red pine ‡ | SEF (36°22′39.60″ N, 128°8′42.49″ E) | 20 × 20 m2 (1) | 550 | 18.3 | 27.3 | LiBackpack D50 | 34,762 |
| Korean pine ‡ | GEF (37°45′32.15″ N, 127°10′52.66″ E) | 30 × 30 m2 (1) | 322 | 22.7 | 23.8 | Leica RTC360 | 84,241 |
| Japanese larch ‡ | GEF (37°45′38.33″ N, 127°10′54.24″ E) | 30 × 30 m2 (1) | 326 | 21.9 | 24.5 | Leica RTC360 | 91,447 |
| Division | Tree Species | Class | |||
|---|---|---|---|---|---|
| Canopy (n) | Trunk (n) | Branch (n) | |||
| Training data | Training | Korean red pine | 102 | 102 | 78 |
| Korean pine | 102 | 102 | 63 | ||
| Japanese larch | 102 | 102 | 74 | ||
| Subtotal | 306 | 306 | 215 | ||
| Validation | Korean red pine | 24 | 24 | 20 | |
| Korean pine | 24 | 24 | 16 | ||
| Japanese larch | 24 | 24 | 19 | ||
| Subtotal | 72 | 72 | 55 | ||
| Test data | Test | Korean red pine | 19 | 19 | 18 |
| Korean pine | 19 | 19 | 14 | ||
| Japanese larch | 19 | 19 | 16 | ||
| Subtotal | 57 | 57 | 48 | ||
| Total | 435 | 435 | 318 | ||
| Hyperparameter | A | B | Description | ||||
|---|---|---|---|---|---|---|---|
| Setup 1 | Setup 2 | Setup 3 | Setup 4 | Setup 5 | Setup 6 | ||
| Batch size | 16 | 2 | 2 | 16 | 2 | 2 | Sample size per batch |
| Representative points | 2048 | 4096 | 8192 | 2048 | 4096 | 8192 | Local and global feature points |
| Resampling | False | True | Resampling of tree points | ||||
| Grouping method | Ball-tree (threshold = 0.05 m) | Feature point grouping method | |||||
| Density-adaptive layer model | Multi-scale grouping | The abstraction level contains grouping and feature extraction of a single scale | |||||
| Optimizer | Adam | Optimization algorithm | |||||
| Epoch | 400 | Number of epochs in training | |||||
| Normal | True | Use normal vector | |||||
| Tree Species | Representative Points | Accuracy (%) | Precision (%) | Recall (%) | F1 Score |
|---|---|---|---|---|---|
| Korean red pint | 2048 | 81.7 | 83.1 | 70.6 | 0.7 |
| 4096 | 80.1 | 85.0 | 67.0 | 0.6 | |
| 8192 | 76.0 | 86.0 | 63.8 | 0.6 | |
| Korean pine | 2048 | 85.5 | 82.8 | 62.9 | 0.7 |
| 4096 | 83.9 | 91.2 | 57.1 | 0.6 | |
| 8192 | 83.9 | 92.7 | 57.7 | 0.6 | |
| Japanese larch | 2048 | 73.4 | 53.5 | 56.0 | 0.5 |
| 4096 | 71.2 | 53.6 | 54.2 | 0.5 | |
| 8192 | 74.2 | 54.3 | 56.7 | 0.5 |
| Division | Korean Red Pine | Korean Pine | Japanese Larch | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Canopy | Trunk | Branch | Canopy | Trunk | Branch | Canopy | Trunk | Branch | |
| Accuracy (%) | 97.5 | 96.6 | 17.5 | 98.6 | 78.2 | 11.8 | 97.8 | 70.1 | 0.00 |
| Precision (%) | 71.4 | 95.9 | 81.9 | 84.1 | 93.1 | 71.2 | 64.9 | 95.7 | 0.00 |
| Recall (%) | 97.5 | 96.9 | 17.5 | 98.6 | 78.2 | 11.8 | 97.8 | 70.1 | 0.00 |
| F1 score | 0.83 | 0.96 | 0.29 | 0.91 | 0.85 | 0.20 | 0.78 | 0.81 | 0.00 |
| Tree Species | Representative Points | OA (%) | Precision (%) | Recall (%) | F1 Score |
|---|---|---|---|---|---|
| Korean red pint | 2048 | 92.4 | 90.8 | 90.2 | 0.9 |
| 4096 | 95.5 | 94.7 | 94.2 | 0.9 | |
| 8192 | 94.8 | 94.2 | 93.1 | 0.9 | |
| Korean pine | 2048 | 89.6 | 81.8 | 81.0 | 0.8 |
| 4096 | 92.7 | 87.8 | 85.4 | 0.9 | |
| 8192 | 91.6 | 88.7 | 79.2 | 0.8 | |
| Japanese larch | 2048 | 82.4 | 75.6 | 74.6 | 0.7 |
| 4096 | 86.3 | 86.8 | 73.9 | 0.8 | |
| 8192 | 83.8 | 86.7 | 67.6 | 0.7 |
| Division | Korean Red Pine | Korean Pine | Japanese Larch | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Canopy | Trunk | Branch | Canopy | Trunk | Branch | Canopy | Trunk | Branch | |
| Accuracy (%) | 96.6 | 98.2 | 87.7 | 95.8 | 96.7 | 63.8 | 94.5 | 98.1 | 29.1 |
| Precision (%) | 95.3 | 97.9 | 91.0 | 94.7 | 93.0 | 75.7 | 80.8 | 94.5 | 85.3 |
| Recall (%) | 96.6 | 98.2 | 87.7 | 95.8 | 96.7 | 63.8 | 94.5 | 98.1 | 29.1 |
| F1 score | 0.96 | 0.96 | 0.89 | 0.95 | 0.95 | 0.69 | 0.87 | 0.96 | 0.43 |
| Related Work | Method | Precision (%) | F1 Score (%) | Tree Species | ||
|---|---|---|---|---|---|---|
| Canopy | Trunk | Canopy | Trunk | |||
| [33] | PointNet | 97.6 | 51.7 * | - | - | Monterey pine (Pinus radiata) |
| [34] | PointNet++ | 97.4 | 94.8 * | - | - | Monterey pine, Eucalyptus (Eucalyptus amygdalina) |
| [47] | PointCNN | 97.2 | 87.0 * | - | - | Camellia (Camellia japonica), Chinese white poplar (Populus x Mentosa) |
| [31] | Unsupervised | - | - | 90.0 | 87.1 * | Sugar maple (Acer saccharum), Norway spruce (Picea abies), Lodgepole pine (Pinus contorata) etc. |
| This study | PointNet++ | 90.3 | 95.1 | 92.7 | 95.7 | Korean red pine, Korean pine, Japanese larch |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.-H.; Ko, C.-U.; Kim, D.-G.; Kang, J.-T.; Park, J.-M.; Cho, H.-J. Automated Segmentation of Individual Tree Structures Using Deep Learning over LiDAR Point Cloud Data. Forests 2023, 14, 1159. https://doi.org/10.3390/f14061159
Kim D-H, Ko C-U, Kim D-G, Kang J-T, Park J-M, Cho H-J. Automated Segmentation of Individual Tree Structures Using Deep Learning over LiDAR Point Cloud Data. Forests. 2023; 14(6):1159. https://doi.org/10.3390/f14061159
Chicago/Turabian StyleKim, Dong-Hyeon, Chi-Ung Ko, Dong-Geun Kim, Jin-Taek Kang, Jeong-Mook Park, and Hyung-Ju Cho. 2023. "Automated Segmentation of Individual Tree Structures Using Deep Learning over LiDAR Point Cloud Data" Forests 14, no. 6: 1159. https://doi.org/10.3390/f14061159
APA StyleKim, D.-H., Ko, C.-U., Kim, D.-G., Kang, J.-T., Park, J.-M., & Cho, H.-J. (2023). Automated Segmentation of Individual Tree Structures Using Deep Learning over LiDAR Point Cloud Data. Forests, 14(6), 1159. https://doi.org/10.3390/f14061159