Accurate Recognition of Jujube Tree Trunks Based on Contrast Limited Adaptive Histogram Equalization Image Enhancement and Improved YOLOv8

Abstract
:1. Introduction
- An automatic key frame extraction algorithm based on the object detection model is designed, which eliminates a large amount of redundant data and realizes efficient batch sample jujube acquisition from the front and side views of jujube trees in large-scale gardens.
- Focusing on the situation whereby the low quality of data collected in the jujube garden environment with light affects model detection, the CLAHE method was utilized to enhance the image quality of the dataset, which effectively improves the problem of low data quality caused by the lack of light in a dark-side image and the loss of details in a bright-side image’s overexposure.
- A new YOLOv8 network structure based on the GhostNetv2 module is incorporated, which not only improves the speed of object detection for jujube tree trunks but also achieves a better balance between accuracy and efficiency than other existing methods.
- The CA attention mechanism is introduced and improved for the CA-H attention mechanism, which is reasonably integrated into the YOLOv8 trunk network, which helps the model to more accurately locate and identify the object detection region that needs more attention and improves the detection accuracy.
2. Dataset Construction
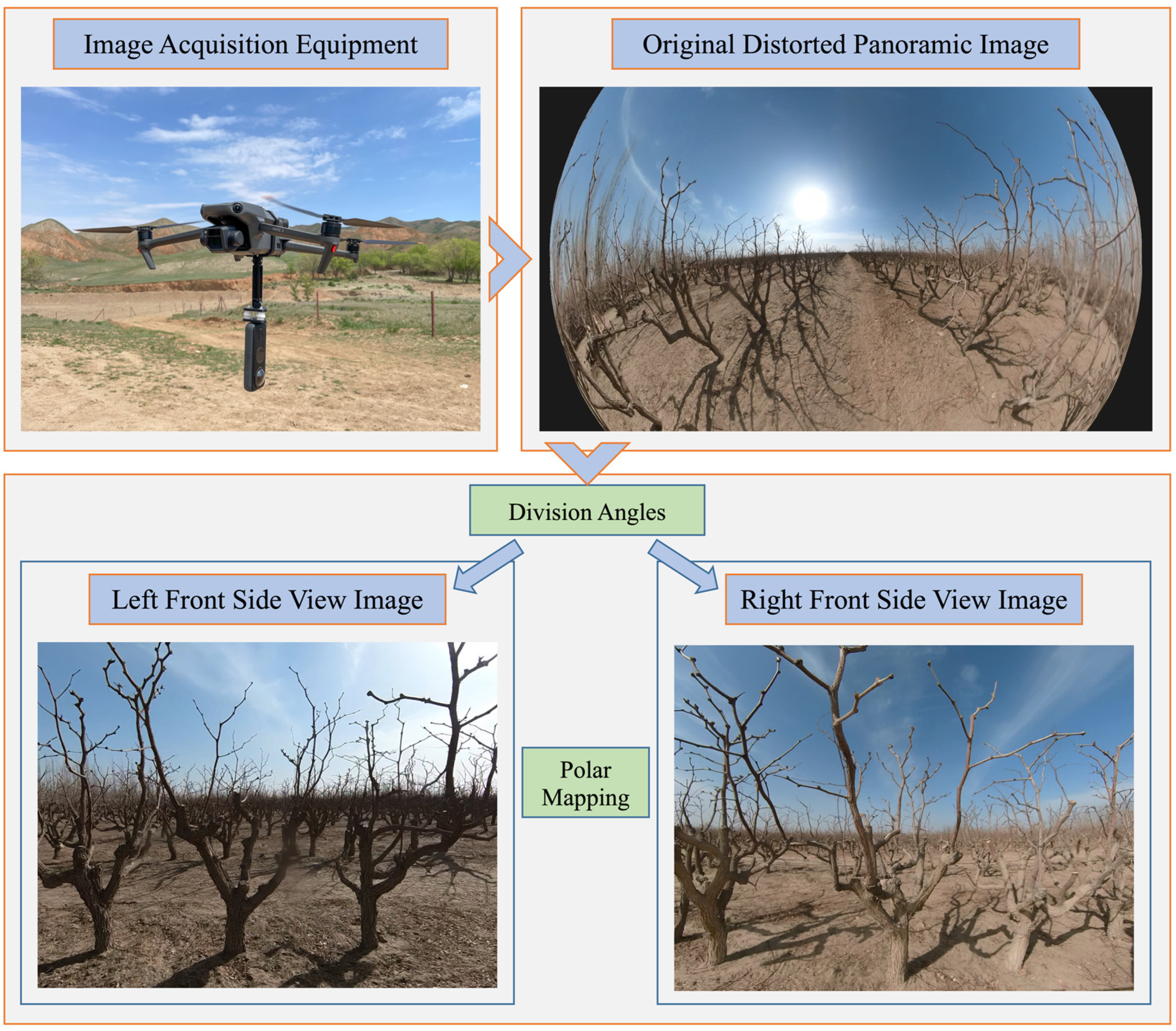
2.1. Dataset Image Acquisition
2.2. Design of Automatic Key Frame Extraction Algorithm
- Initial environment configuration: build the algorithm development environment based on the Pytorch11.0 framework; then, import the toolkits numpy, tqdm, and supervision, etc., in order to realize the functions of data analysis, image processing, and data visualization, etc., of which the supervision toolkit is used as a keyframe that identifies the jujube tree reaching the centerline of the field of view and implements the cross-line extraction function.
- Install the object detection model: the first object detection model needs to utilize the traditional training method, i.e., by manually obtaining a certain amount of jujube tree trunk pictures, labeling, and training an object detection model to have initial trunk detection capability.
- Frame-by-frame detection: Design the path of the video to be detected, and utilize the pre-trained object detection model to detect the trunk. Encapsulate the frame-by-frame detection process into the “Peocess_frame” function, and output the visualized and configured image.
- Cross-line counting: run the frame-by-frame detection function on the video, use supervision to parse the prediction results, traverse all the objects on the screen, and draw the visualization effect of object detection, which is combined with the detection line in the center of the screen, to determine whether the object is over the line and to count the number of objects to be displayed in the visualization.
- Key frame extraction: Firstly, when the trunk object is detected in the image data, use the bounding box function to obtain the position information of the trunk, and then calculate the coordinates of the center point of the area where the trunk is located. Secondly, set up the trigger conditions, and when the coordinates of the center of the trunk are detected to have passed through the vertical line of the screen, then intercept the front and side view of the jujube tree. The key frame image is also labeled with the corresponding counting number and the size of image is cropped in order to make the image complete retention of the corresponding jujube tree at the same time to prevent excessive interference with the information, with the size of the cropped image being 1:1, as shown in Figure 4.
2.3. Dataset Image Enhancement
- Image division: First divide the image into small, non-overlapping rectangular regions; the size of these sub-regions is usually 8 × 8, 16 × 16, etc. The larger the number of pixels, the more obvious the enhancement effect is, but more information about the corresponding image details is lost. In OpenCV, the default tile size is 8 × 8.
- Local histogram equalization: Convert the RGB color space to grayscale HSV space, which is more suitable for brightness and contrast processing, for each small block; then, calculate its grayscale histogram, calculate the mapping function with this histogram, and apply this function to each region. And further calculate the cumulative distribution function (CDF) of the histogram.
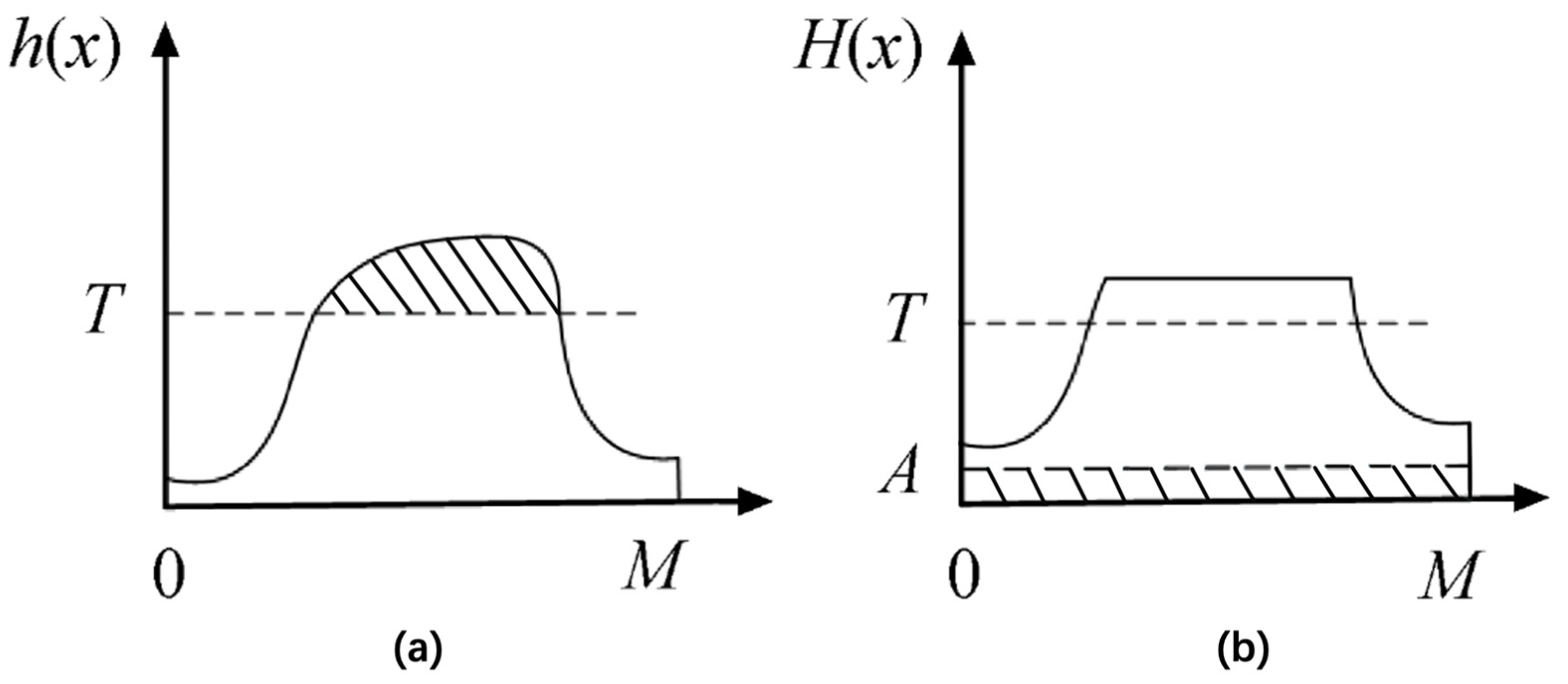
- Contrast limitation: In order to prevent over-enhancement (resulting in noise being amplified) caused by too many values of certain pixels, the frequency of pixels exceeding a predetermined threshold T (contrast limiting parameter) in the original block histogram Figure 5a is “truncated” and the “truncated” portion is evenly distributed among other pixels to obtain the modified histogram, as shown in Figure 5b, where A denotes the pixels equally distributed in each gray level and M denotes the gray value. The principle process is shown in Figure 5.
- Pixel mapping: using the mapping relationship between the image pixels and the transformation function of the gray level of the partitioned region, an interpolation operation is applied to solve the gray level value of the corresponding pixel in order to eliminate the “blocky” image according to the number of neighboring points; the change function is 4, so bilinear interpolation is carried out between the partitioned sub-regions.
- Interpolation Smoothing: Since images are divided into multiple small sub-regions for processing, the direct application of histogram equalization may produce significant boundary effects between adjacent sub-regions [32]. To solve this problem, we use CLAHE with bilinear interpolation to smoothen the transition between neighboring subregions to ensure the continuity and smoothness of the image.
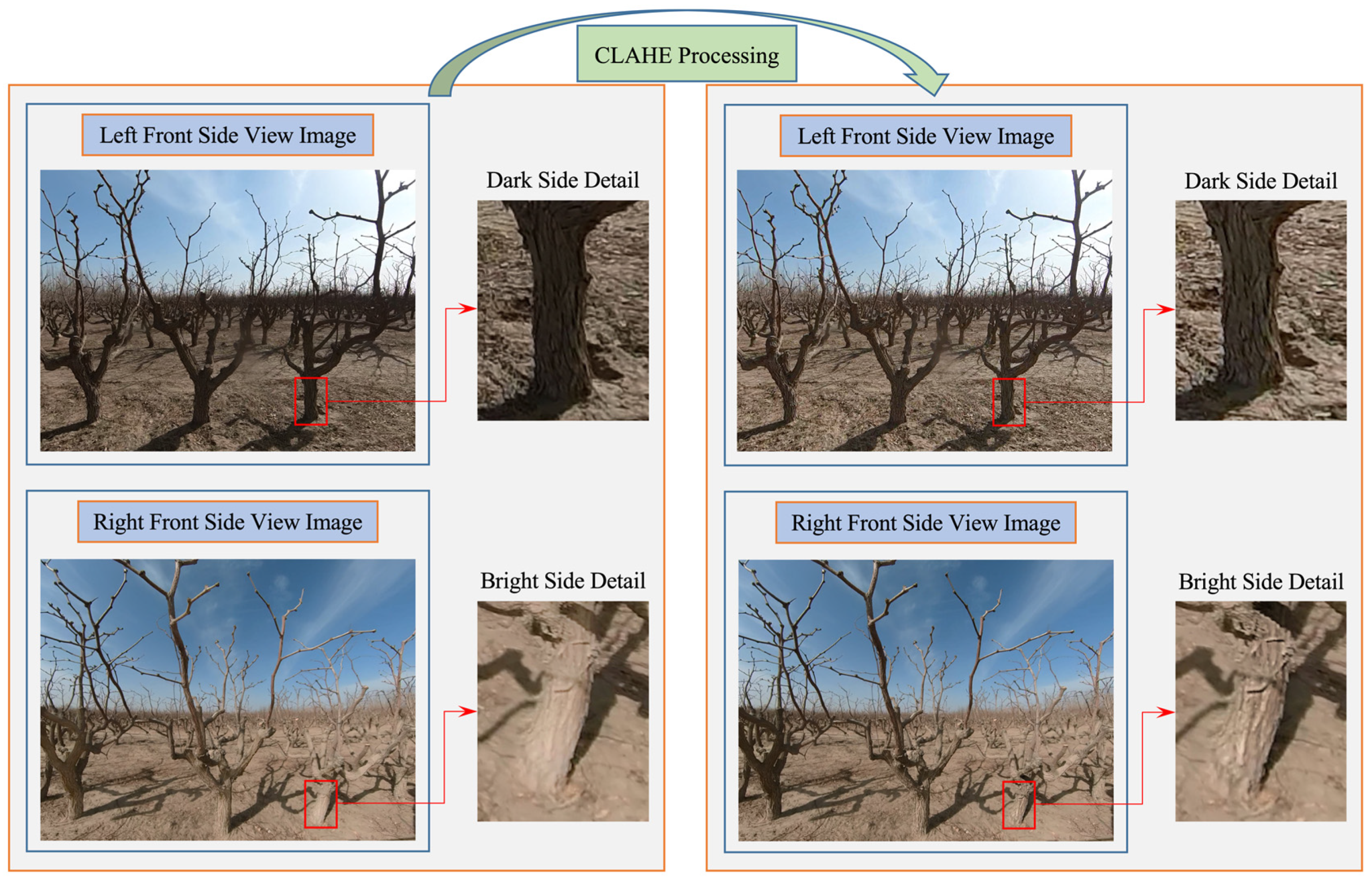
- Merging results: all the processed sub-regions are recombined into a complete image, the processed image is converted back to the RGB color space to complete the image data enhancement process, and finally the effect after enhancement by the CLAHE method is shown in Figure 6.
3. Methods
3.1. YOLOv8 Algorithm Structure
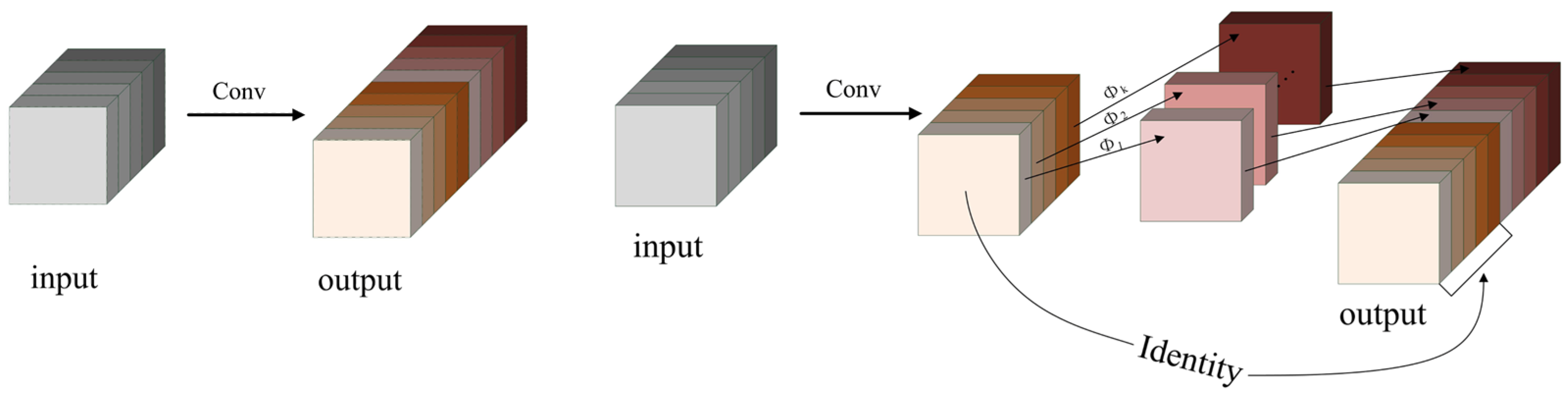
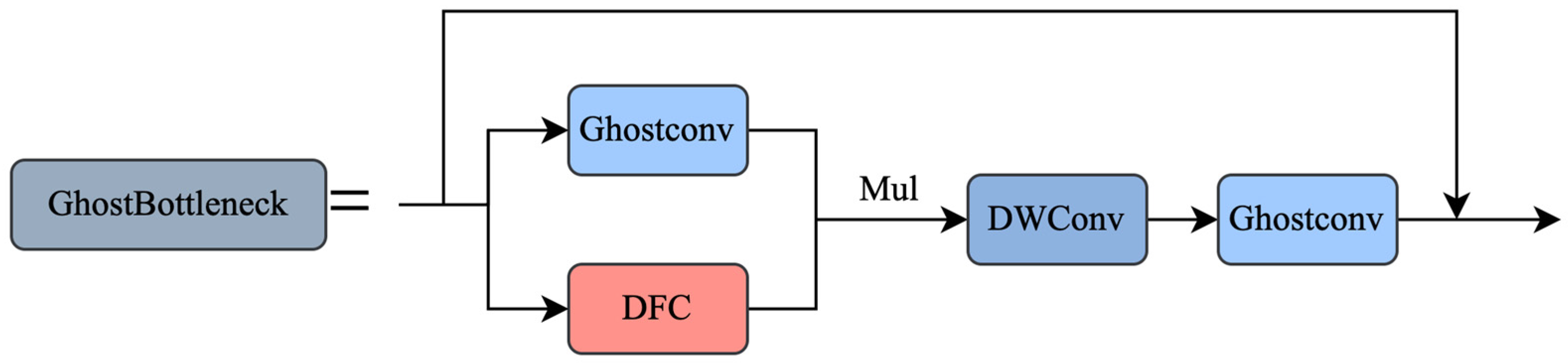
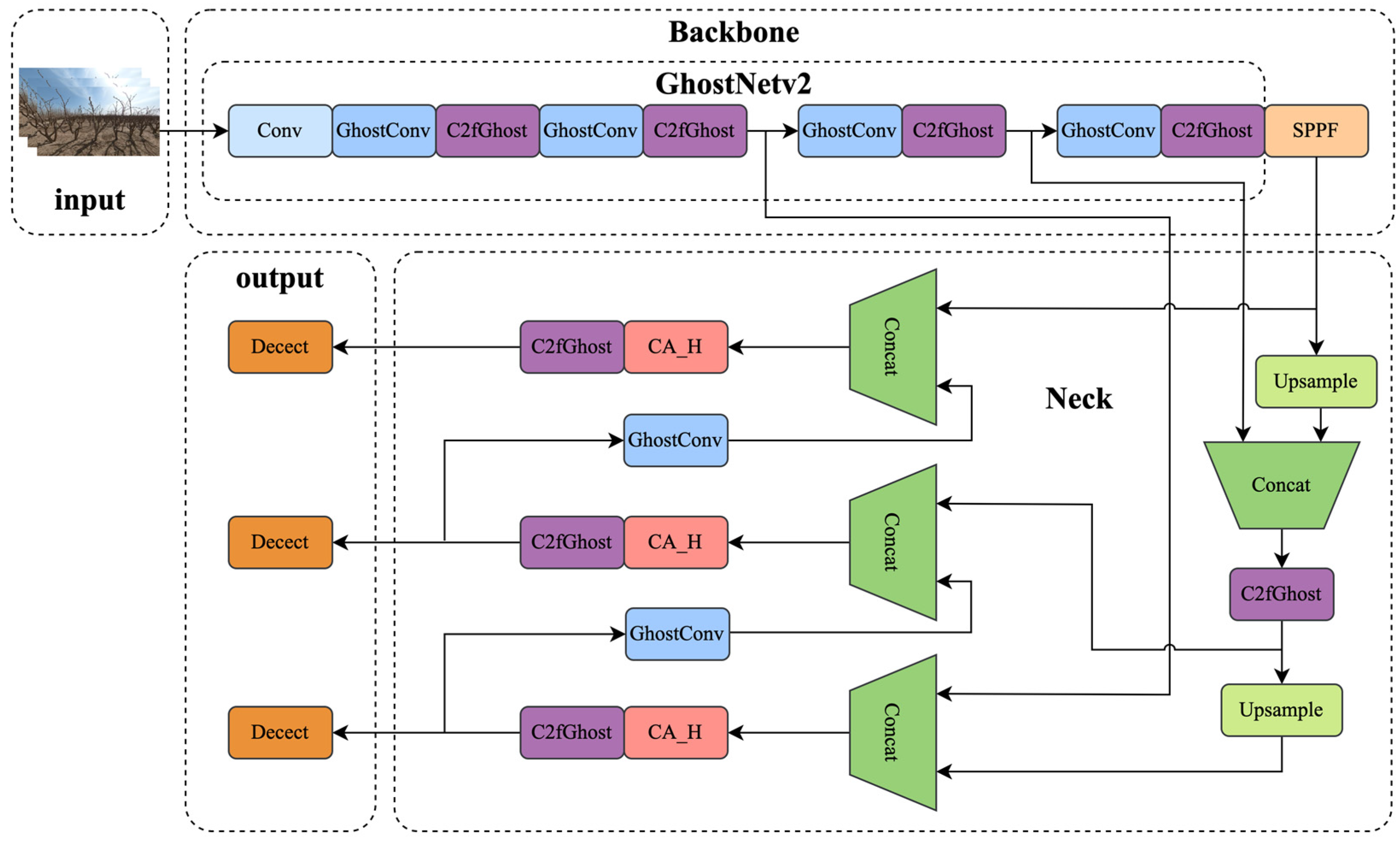
3.2. YOLOv8 Improvement of Backbone Network GhostNetv2
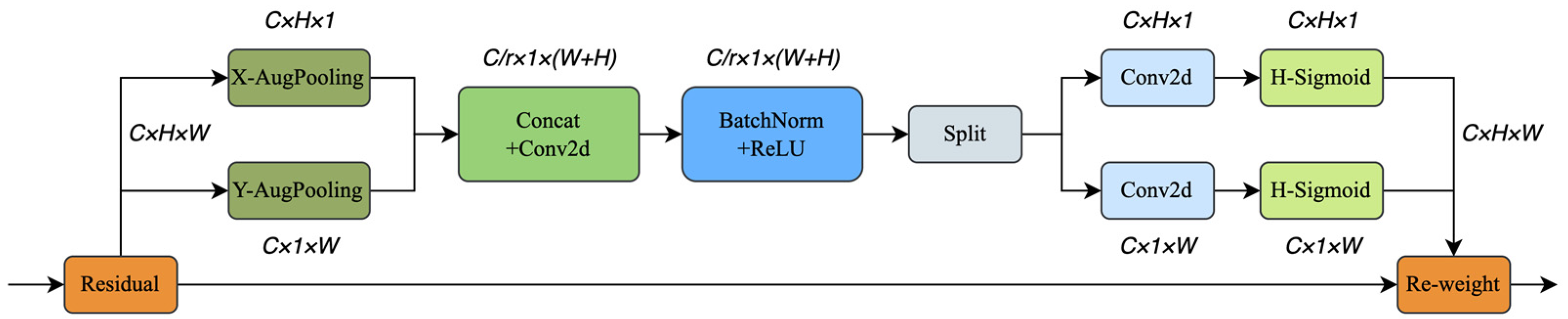
3.3. YOLOv8 Improvement of the CA_H Attention Mechanism
4. Experiment Results with Relevant Analysis
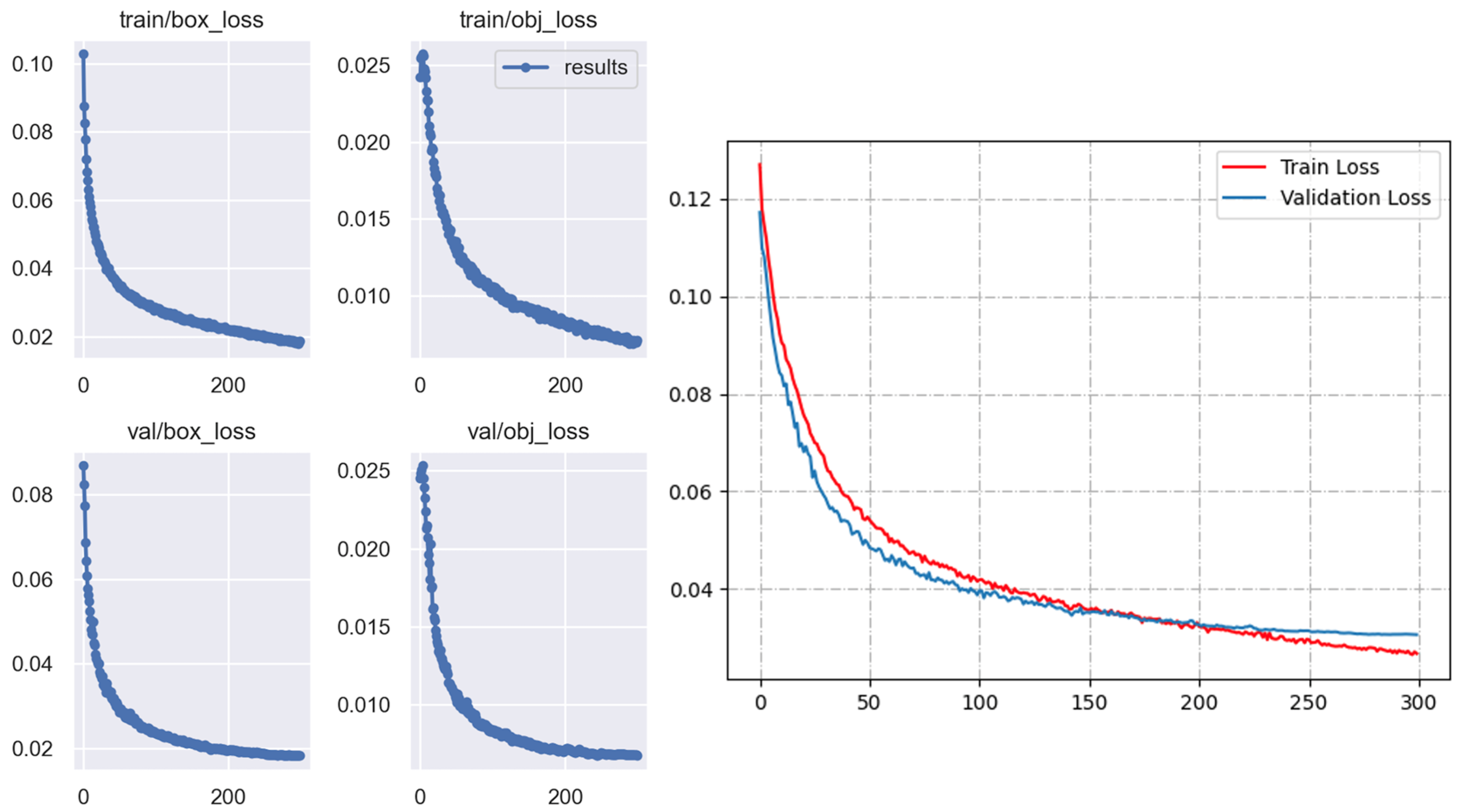
4.1. Experimental Settings
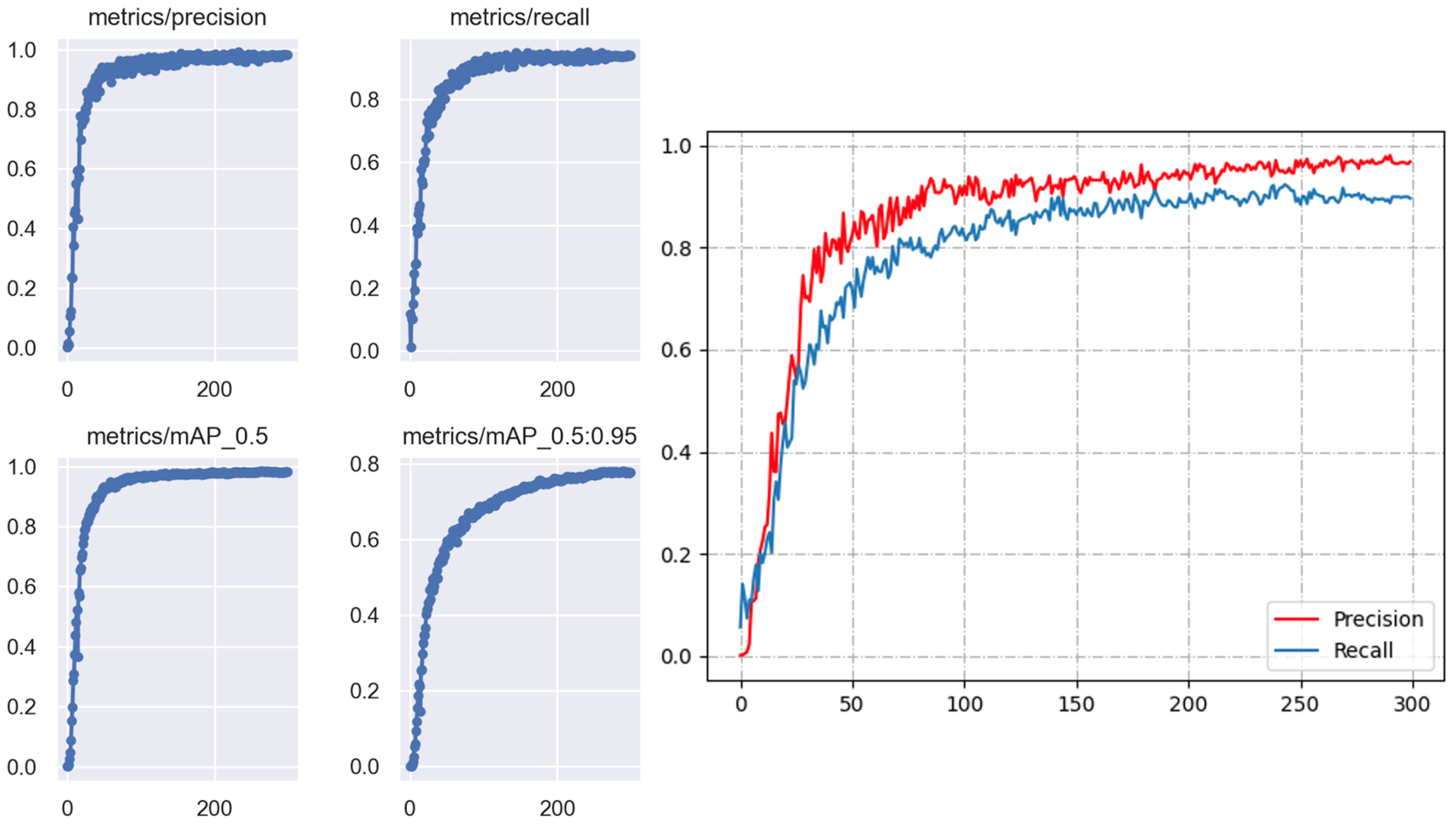
4.2. Qualitative Evaluation
4.3. Data Enhancement Comparison Test
Discussion
- Improving contrast: Due to the high light intensity in the Xinjiang jujube garden, there are cases of overexposure on the sunny side and underexposure on the shady side of the image, which lead to insufficient contrast of the image and have an impact on the accuracy of object detection. CLAHE is precisely the kind of enhancement method needed to address the situation, which is able to improve the contrast of the local area and make the image information more complete.
- Noise reduction: The CLAHE method is processed in chunks of the image, and histogram equalization can greatly reduce the phenomenon of excessive local contrast caused by noise or rapid changes in brightness. In addition, by limiting the contrast (contrast limiting), CLAHE amplifies the noise much less than the global histogram equalization method [39].
- Protection of details: The CLAHE method performs histogram equalization independently for each local region of the image and also ensures that the details are not over-amplified as the contrast limiting mechanism prevents too much concentration of a particular luminance value, thus protecting the details of the image as much as possible. This is especially important for object detection, such as the shape of tree trunks, texture, and other detailed features.
- Reducing the impact of brightness variation: Since the UAV is constantly traveling during the acquisition process, there are light variations. The CLAHE method for localized regions ensures that the contrast of local sub-regions is enhanced while not being affected by the brightness distribution of other regions, reducing the impact of uneven illumination on image characteristics. The accuracy and robustness of model detection is improved by the CLAHE method.
4.4. Lightweighting and Attention Mechanism Improvement Ablation Trial
Discussion
- Lightweight improvement: In this paper, we use the Ghost bottleneck structure instead of the original structure on YOLOv8s to form the main part of the backbone, and we replace the standard convolution module with larger parameter counts in the neck and head with the Ghost bottleneck structure and depth-separable convolution, to generate the new lightweight network model YOLOv8s-GhostNetv2, which has a 21.1% compression in the model size with a 3% reduction in recall and a 21.5% acceleration in computation. Precision and [email protected] are only reduced by 2.8% and 2.5%, respectively, and recall is reduced by 3.3%, the model size is compressed by 21.3%, FPS is improved from 153.5 to 186.3, and computation is accelerated by 21.4%. It is proven that the improved network architecture based on the Ghost module proposed in this paper strongly helps to reduce the number of parameters and the complexity of the model, and the cost of losing precision and recall is exchanged for the speedup. In summary, YOLOv8s-GhostNetv2 maintains relatively efficient detection performance while having a lightweight framework.
- Introducing the attention mechanism: the lightweight improvement reduces the size of the algorithm model to a large extent, but in order to make up for the reduced detection performance caused by the lack of effective feature extraction brought about by the lightweight improvement, the CA_H channel attention is embedded in the Ghost bottleneck structure to generate the YOLOv8s-GhostNetv2-CA_H model, which is the same as the lightweight model. Compared with YOLOv8s-GhostNetv2, precision, recall, and [email protected] are improved by 5.4%, 4.8%, and 4.4%, respectively, while the model size is increased by 2.4%, and the detection speed FPS is slowed down by 6.5 with a loss of 3.5%, which hardly brings too much computational consumption, which is attributed to the fact that the coordinate attention mechanism captures both the cross channel relationship and captures both orientation-aware and position-sensitive information. Compared with the YOLOv8s base model, the introduction of the CA_H attention mechanism mainly has the effect of improving the precision and recall, with the precision improved to 92.3%, recall improved to 89.9%, and [email protected] improved to 91.8%. For the experiments in this paper, the addition of the attention mechanism can filter out the feature regions of important value from a large amount of irrelevant information, helping the model to process the information efficiently and thus obtaining performance gains without losing too much computational performance.
4.5. Comparative Experiments with Classical Algorithms
- When the YOLOv8s base model is compared with the classical object detection algorithm Faster R-CNN, only recall is slightly lower than that of the YOLOv5s model by 0.4%, and the rest of the various aspects of the performance are achieved comprehensively beyond that.
- Compared with the YOLOv8s base model, the YOLOv8s-GhostNetv2-CA_H model proposed in this paper reduces the model size by 19.5%, improves the precision by 2.4% to 92.3%, the recall by 1.4%, [email protected] by 1.8%, and FPS by 17.1%.
Discussion
- Compared to Faster R-CNN, which first uses a region proposal network (RPN) to generate candidate object regions and then performs classification and bounding box regression for each region, the YOLO series predicts the bounding box and category probabilities directly in a single neural network, and this one-step approach is more effective in real-world application scenarios with large amounts of jujube tree garden data because it reduces the steps in the inference process and the computational complexity.
- In addition, YOLO employs more advanced feature fusion mechanisms, such as cross-scale feature fusion, which can help the model better capture trunk targets of different sizes. In contrast, although Faster R-CNN can also handle multi-scale inputs, its feature fusion ability is weak, and its recognition effect is poor when facing the influence of tree branches with more disturbances.
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, J.; Xiang, J.; Jin, Y.; Liu, R.; Yan, J.; Wang, L. Boost precision agriculture with unmanned aerial vehicle remote sensing and edge intelligence: A survey. Remote Sens. 2021, 13, 4387. [Google Scholar] [CrossRef]
- Nie, J.; Jiang, J.; Li, Y.; Wang, H.; Ercisli, S.; Lv, L. Data and domain knowledge dual-driven artificial intelligence: Survey, applications, and challenges. Expert Syst. 2023, e13425. [Google Scholar] [CrossRef]
- Cheng, Z.; Cheng, Y.; Li, M.; Dong, X.; Gong, S.; Min, X. Detection of cherry tree crown based on improved LA-dpv3+ algorithm. Forests 2023, 14, 2404. [Google Scholar] [CrossRef]
- Nie, J.; Wang, Y.; Li, Y.; Chao, X. Artificial intelligence and digital twins in sustainable agriculture and forestry: A survey. Turk. J. Agric. For. 2022, 46, 642–661. [Google Scholar] [CrossRef]
- Donmez, C.; Villi, O.; Berberoglu, S.; Cilek, A. Computer vision-based citrus tree detection in a cultivated environment using UAV imagery. Comput. Electron. Agric. 2021, 187, 106273. [Google Scholar] [CrossRef]
- Zhang, R.; Li, P.; Zhong, S.; Wei, H. An integrated accounting system of quantity, quality and value for assessing cultivated land resource assets: A case study in Xinjiang, China. Glob. Ecol. Conserv. 2022, 36, e02115. [Google Scholar] [CrossRef]
- Li, Y.; Ercisli, S. Data-efficient crop pest detection based on KNN distance entropy. Sustain. Comput. Inform. Syst. 2023, 38, 100860. [Google Scholar]
- Yang, Y.; Li, Y.; Yang, J.; Wen, J. Dissimilarity-based active learning for embedded weed identification. Turk. J. Agric. For. 2022, 46, 390–401. [Google Scholar] [CrossRef]
- Ye, G.; Liu, M.; Wu, M. Double image encryption algorithm based on compressive sensing and elliptic curve. Alex. Eng. J. 2022, 61, 6785–6795. [Google Scholar] [CrossRef]
- Li, Y.; Yang, J.; Zhang, Z.; Wen, J.; Kumar, P. Healthcare data quality assessment for cybersecurity intelligence. IEEE Trans. Ind. Inform. 2022, 19, 841–848. [Google Scholar] [CrossRef]
- Xu, S.; Pan, B.; Zhang, J.; Zhang, X. Accurate and Serialized Dense Point Cloud Reconstruction for Aerial Video Sequences. Remote Sens. 2023, 15, 1625. [Google Scholar] [CrossRef]
- Ahmed, M.; Ramzan, M.; Khan, H.U.; Iqbal, S.; Khan, M.A.; Choi, J.-I.; Nam, Y.; Kadry, S. Real-Time Violent Action Recognition Using Key Frames Extraction and Deep Learning; Tech Science Press: Henderson, NV, USA, 2021. [Google Scholar]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small Object Detection Based on Deep Learning for Remote Sensing: A Comprehensive Review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- Ciarfuglia, A.T.; Motoi, M.I.; Saraceni, L.; Fawakherji, M.; Sanfeliu, A.; Nardi, D. Weakly and semi-supervised detection, segmentation and tracking of table grapes with limited and noisy data. Comput. Electron. Agric. 2023, 205, 107624. [Google Scholar] [CrossRef]
- Ouhami, M.; Hafiane, A.; Es-Saady, Y.; El Hajji, M.; Canals, R. Computer vision, IoT and data fusion for crop disease detection using machine learning: A survey and ongoing research. Remote Sens. 2021, 13, 2486. [Google Scholar] [CrossRef]
- Ling, S.; Wang, N.; Li, J.; Ding, L. Optimization of VAE-CGAN structure for missing time-series data complementation of UAV jujube garden aerial surveys. Turk. J. Agric. For. 2023, 47, 746–760. [Google Scholar] [CrossRef]
- Chao, X.; Li, Y. Semisupervised few-shot remote sensing image classification based on KNN distance entropy. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8798–8805. [Google Scholar] [CrossRef]
- Maity, M.; Banerjee, S.; Chaudhuri, S.S. Faster r-cnn and yolo based vehicle detection: A survey. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 1442–1447. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Junos, M.H.; Khairuddin, A.S.M.; Dahari, M. Automated object detection on aerial images for limited capacity embedded device using a lightweight CNN model. Alex. Eng. J. 2022, 61, 6023–6041. [Google Scholar] [CrossRef]
- Li, Y.; Chao, X.; Ercisli, S. Disturbed-entropy: A simple data quality assessment approach. ICT Express 2022, 8, 309–312. [Google Scholar] [CrossRef]
- Osco, P.L.; de Arruda, S.D.M.; Gonçalves, N.D.; Dias, A.; Batistoti, J.; de Souza, M.; Gomes, F.D.G.; Ramos, A.P.M.; de Castro Jorge, L.A.; Liesenberg, W.; et al. A CNN approach to simultaneously count plants and detect plantation-rows from UAV imagery. ISPRS J. Photogramm. Remote Sens. 2021, 174, 1–17. [Google Scholar] [CrossRef]
- Li, Y.; Ercisli, S. Explainable human-in-the-loop healthcare image information quality assessment and selection. CAAI Trans. Intell. Technol. 2023. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, B.; Zhang, J.; Li, Z.; Pang, C.; Dong, C. Lightweight PM-YOLO Network Model for Moving Object detection on the Distribution Network Side. In Proceedings of the 2022 2nd Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), Shenyang, China, 25–27 February 2022; pp. 508–516. [Google Scholar]
- Li, Y.; Chao, X. Distance-entropy: An effective indicator for selecting informative data. Front. Plant Sci. 2022, 12, 818895. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Chang, S.; Tian, Z.; Gao, C.; Du, Y.; Zhang, X.; Liu, K.; Meng, J.; Xue, L. Automatic polyp detection and segmentation using shuffle efficient channel attention network. Alex. Eng. J. 2022, 61, 917–926. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Detection, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Conroy, L.T.; Moore, B.J. Resolution invariant surfaces for panoramic vision systems. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 1, pp. 392–397. [Google Scholar]
- Wan, S.; Ding, S.; Chen, C. Edge computing enabled video segmentation for real-time traffic monitoring in internet of vehicles. Pattern Detect. 2022, 121, 108146. [Google Scholar] [CrossRef]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-adaptive YOLO for object detection in adverse weather conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 1792–1800. [Google Scholar]
- Reza, M.A. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Ravikumar, M.; Rachana, G.P.; Shivaprasad, J.B.; Guru, S.D. Enhancement of mammogram images using CLAHE and bilateral filter approaches. In Cybernetics, Cognition and Machine Learning Applications: Proceedings of ICCCMLA; Springer: Singapore, 2021; pp. 261–271. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Detection, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance cheap operation with long-range attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, N.A.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, V.Q. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Gu, R.; Wang, G.; Song, T.; Huang, R.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. CA-Net: Comprehensive attention convolutional neural networks for explainable medical image segmentation. IEEE Trans. Med. Imaging 2020, 40, 699–711. [Google Scholar] [CrossRef] [PubMed]
- Zimmerman, B.J.; Pizer, M.S.; Staab, V.E.; Perry, R.J.; McCartney, W.; Brenton, C.B. An evaluation of the effectiveness of adaptive histogram equalization for contrast enhancement. IEEE Trans. Med. Imaging 1988, 7, 304–312. [Google Scholar] [CrossRef]
- Ling, S.; Li, J.; Ding, L.; Wang, N. Multi-View Jujube Tree Trunks Stereo Reconstruction Based on UAV Remote Sensing Imaging Acquisition System. Appl. Sci. 2024, 14, 1364. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Precision (%) | [email protected] (%) | ||||
|---|---|---|---|---|---|---|
| Dark Side | Bright Side | Average | Dark Side | Bright Side | Average | |
| Original | 83.9 | 78.5 | 81.2 | 83.9 | 79.1 | 81.5 |
| Enhanced | 91.3 | 88.9 | 90.1 | 91.3 | 89.1 | 90.2 |
| Model | P (%) | R (%) | FPS | [email protected] (%) | Model Size (M) |
|---|---|---|---|---|---|
| YOLOv8s | 90.1 | 88.7 | 153.5 | 90.2 | 21.5 |
| YOLOv8s + GhostNetv2 | 87.6 | 85.8 | 186.3 | 87.9 | 16.9 |
| YOLOv8s + GhostNetv2 + CA_H | 92.3 | 89.9 | 179.8 | 91.8 | 17.3 |
| Model | P (%) | R (%) | FPS | [email protected] (%) | Model Size (M) |
|---|---|---|---|---|---|
| Faster R-CNN | 81.9 | 85.1 | 8 | 80.7 | 121.4 |
| YOLOv5s | 89.3 | 89.1 | 137.7 | 88.9 | 14.5 |
| YOLOv8s | 90.1 | 88.7 | 153.5 | 90.2 | 21.5 |
| YOLOv8s-GhostNetv2 | 87.6 | 85.8 | 186.3 | 87.9 | 16.9 |
| YOLOv8s-GhostNetv2-CA_H | 92.3 | 89.9 | 179.8 | 91.8 | 17.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ling, S.; Wang, N.; Li, J.; Ding, L. Accurate Recognition of Jujube Tree Trunks Based on Contrast Limited Adaptive Histogram Equalization Image Enhancement and Improved YOLOv8. Forests 2024, 15, 625. https://doi.org/10.3390/f15040625
Ling S, Wang N, Li J, Ding L. Accurate Recognition of Jujube Tree Trunks Based on Contrast Limited Adaptive Histogram Equalization Image Enhancement and Improved YOLOv8. Forests. 2024; 15(4):625. https://doi.org/10.3390/f15040625
Chicago/Turabian StyleLing, Shunkang, Nianyi Wang, Jingbin Li, and Longpeng Ding. 2024. "Accurate Recognition of Jujube Tree Trunks Based on Contrast Limited Adaptive Histogram Equalization Image Enhancement and Improved YOLOv8" Forests 15, no. 4: 625. https://doi.org/10.3390/f15040625