1. Introduction
Forests are estimated to account for up to 80% of the earth’s total biomass [
1] but cover only 30% of the land surface [
2], mainly occurring in temperate, boreal, and tropical regions. Although forests are quantitatively scarce in arid and semiarid regions, their role in those areas is especially relevant to mitigate desertification processes or land degradation due to both climatic and anthropogenic causes [
3]. It is widely known that vegetation plays a major role in maintaining soil fertility by limiting the loss of fertile soil due to erosion processes. In fact, Andréassian [
4] points out the effects of deforestation on the environment and the consequences that can occur at various levels of the ecosystem. From the hydrological point of view, the vegetation affects water balance, surface or underground, because of its role in the interception of rainfall, infiltration, and evapotranspiration, especially in surface runoff and erosion. Some studies have shown that the rate of erosion and runoff decreases exponentially with increased vegetation cover in Mediterranean semiarid environments [
5]. In addition, erosion can also lead to problems of silting in reservoirs and therefore reduce its storage capacity [
6]. It is worth noting that future scenarios suggest that the semiarid regions of the planet, which extend over 42% of the globe and in which a third of the world population lives, can be turned into arid areas as a result of the effect of global climate change. In particular, Mediterranean semiarid regions are subject to environmental constraints such as low and unpredictable seasonal rainfall, high mean annual temperatures and high evaporative demand. Those existing constraints are likely to be exacerbated by climate change, with temperatures expected to rise and water supplies to become increasingly scarce [
7], particularly in Africa [
8].
Forests also perform a critical role in the terrestrial carbon cycle since they are extremely relevant features in the global carbon budget [
9,
10]. The importance of forests relies on the fact that general forest CO
2 uptake by assimilation is greater than CO
2 losses through vegetation and soil respiration [
11]. In this way, they are considered as valuable carbon sinks, thus yielding a positive net ecosystem production (
i.e., a positive net forest carbon balance). This carbon storage capacity can be reasonably computed by modelling the relationship between the net biomass increment and the corresponding carbon uptake, which is typical for each forest typology and vegetal species [
12]. Therefore, atmospheric carbon sequestration by forest stands is considered a vital strategy to assume the obligations arising under Article 3.3 of the Kyoto Protocol (UN) in terms of credits earned through carbon set in the forests of new implementations after 1990 [
13]. As a reference to the importance of forest in atmospheric carbon sequestration, and focusing on the case of Morocco where this work was conducted, the estimation of net emissions of Greenhouse Gases in 2010 was about 75.4 Mt E-CO
2 (2.27 t E-CO
2/inhabitant). Notice that only the Moroccan oak forests, mainly localized in the Atlas, were able to store approximately 1/8 of Greenhouse Gases issued by the entire country [
14].
Since making right decisions largely depends on the quality of the available information, the aforementioned article of the Kyoto Protocol requires an annual transparent, systematic and consistent report regarding the storage by absorption of CO
2 from the land-use change and forestry activities. Thus, an effective and accurate monitoring of forest areas is clearly needed because the vegetation mass continuously changes at time and space scale on account of various natural or anthropic facts. This task can be efficiently undertaken by satellite-based remote sensing methods, which have become a major data source for mapping and monitoring land use and land cover (LULC) dynamic change over time because they can capture land surface information at the time when satellites pass through. Particularly, medium spatial resolution images, especially Landsat images due to their long history of data availability and suitable spectral and spatial resolutions, have become a common data source for making up LULC maps on a regional scale [
15,
16]. Regarding forest evolution studies, the comparison of multitemporal LULC thematic maps based on multitemporal satellite images has turned out to be an appropriate and simple method for extracting forested and deforested areas (binary change and non-change areas). Since Landsat data are available for public access at no cost, the time series of Landsat images have been largely applied to determine forest change [
17,
18,
19,
20,
21].
In this sense, it is important to highlight the recently published work by Hansen
et al. [
21], where results from a time-series analysis of Landsat images in characterizing the global forest extent and change from 2000 through 2013 can be downloaded.
Though an OBIA has recently proved to be a very efficient approach to construct meaningful objects for improving land cover mapping and change analysis, even when working on medium resolution satellite imagery [
22,
23,
24], the hypothesis on which this paper is based claims that there is still room for improvement. In fact, since mixed pixels in medium and coarse spatial resolution images have been regarded as an important factor influencing the LULC results [
25,
26], subpixel-based methods have been developed to provide a more appropriate representation and accurate area estimation of land covers than per-pixel approaches, especially when coarse spatial resolution data are used [
27,
28].
On the other hand, the spatial extent of vegetation and bare soil is notoriously difficult to measure in arid and semiarid ecosystems using satellite imagery because variation occurs on the scale of a few meters or less [
29]. Moreover, arid and semiarid environments endure strong spatial and temporal variations of climate and land use that result in uniquely dynamic vegetation, cover and leaf area characteristics. As a result, we can deduce that previous remote sensing efforts have not fully captured the spatial heterogeneity of vegetation properties required to carry out an accurate forest monitoring of these ecosystems. From our point of view, new remote-sensing-based methods are needed to cope with this pending issue, and this is precisely the gap that our article is to cover.
Therefore, the main goal and novelty of this paper relies on integrating object-based computed features and subpixel-derived ones to utilize all available information in medium resolution satellite images to help increase class discrimination between forested and non-forested areas in arid and semiarid environments. In this way, a new Landsat imagery processing method was developed and applied to carry out a regional scale quantitative assessment of forest cover change in the semiarid area of the Moulouya River watershed (Morocco) from atmospherically corrected reflectance Landsat images corresponding to 1984 (Landsat 5 Thematic Mapper; TM) and 2013 (Landsat 8 Operational Land Imager; OLI).
2. Study Site and Data Sets
Moroccan forests are mostly composed of fragile, diverse and varied ecosystems covering an area of nearly 9 million hectares, of which 5.8 million hectares correspond to real woodland areas, the rest belonging to shrubland and scrubland ecosystems [
30]. The Moroccan government, fully aware of the risk and impact of deforestation processes in Morocco, developed a ten-year programme (2005–2014) for the primary purpose of combating desertification and deforestation through Haut Commissariat aux Eaux et Forêts et à la Lutte Contre la Désertification. The ten-year programme was composed of several sub-projects, which were territorialized projects adapted to local realities, to reforest a total of 400,000 hectares [
30]. The general strategic objective of this ten-year programme would be to increase the multifunctionality of forest ecosystems in Morocco by combating desertification, maintaining and developing forest resources and ensuring human development in forest areas and their surroundings.
2.1. Study Site
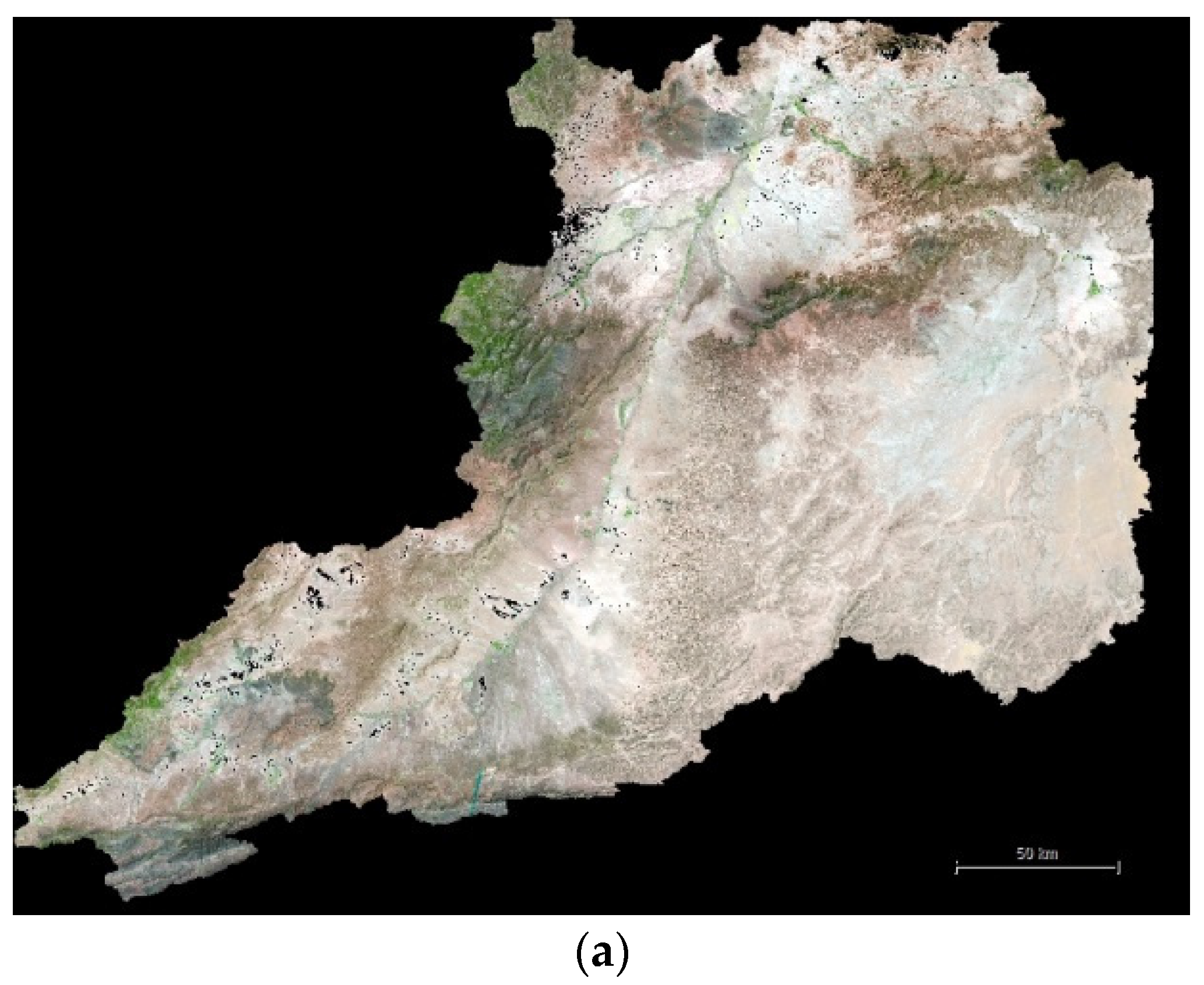
The study area encompassed the Moulouya River watershed upstream of the dam Mohammed V (
Figure 1), the largest river basin in Morocco, covering about 55,000 km
2. The Moulouya River is the chief river of Northeastern Morocco. Rising in the High Atlas mountains in central Morocco, it flows for around 600 km northeastward through a semiarid valley to the Mediterranean Sea just west of the Algerian border. Along its riverbed we can find the watershed that feeds the dam Mohammed V, consisting of a semiarid plain with low specific degradation in principle, though concentrated forms of erosion can be periodically reactivated.
The study site has a semiarid Mediterranean climate with relatively low and irregular annual rainfall (average annual values between 200 and 400 mm). Average temperatures usually range between 5 °C and 18 °C in the cold seasons and between 18 °C and 31 °C in hot weather.
According to FAO [
31], the term “Forest” involves areas that span over more than 0.5 hectares of trees taller than 5 m and canopy cover of more than 10% (or areas of trees able to reach these characteristics
in situ). This definition clearly excludes both agricultural and urban areas and shrubland and scrubland ecosystems. In the context of this work, and bearing in mind that we are dealing with Mediterranean arid and semiarid areas in which forest stands are sparse and frequently appear in the form of degraded bush that is clearly lower than 5 m in height, the term “Forest” has been slightly modified to account for forest stands larger than 0.5 hectares, containing trees taller than 2.5 m (as an estimated average height), and presenting a canopy cover of more than 10%. The so-called “alpha grass,” mainly composed of dense perennial herbs and dwarf shrubs such as
Stipa tenacissima L. (esparto grass), covers most of the natural forests situated in Northeastern Morocco, representing a surface close to 2.2 million hectares. Another important LC (Land Cover) in the study area would be composed of shrubland vegetation such as
Rosmarinus officinalis (rosemary),
Lavandula dentate L. (fringed lavender),
Thymus vulgaris (thyme), and aromatic and medicinal plants. The forested area, which is the target LC in this work, mostly consisting of conifers and some hardwood forests, represents only 9.4% of the total forest area in the region.
Figure 1.
Location and delineation of the Moulouya River watershed upstream of the dam Mohammed V (UTM 30N projection and WGS84 reference system).
Figure 1.
Location and delineation of the Moulouya River watershed upstream of the dam Mohammed V (UTM 30N projection and WGS84 reference system).
2.2. Data Sets
Satellite images were obtained from the NASA Landsat series [
32], distributed by the USGS through the display GLOVIS (Global Visualization Viewer). To ensure complete coverage of the study area, five cloud-free Landsat L1T scenes were acquired for both 1984 (sensor Landsat 5 TM) and 2013 (sensor Landsat 8 OLI) (
Table 1).
Table 1.
Characteristics of the input data (Landsat images). Multispectral bands R, G, B, Nir, Swir1 and Swir2 (30 m ground pixel size) were used in all the cases.
Table 1.
Characteristics of the input data (Landsat images). Multispectral bands R, G, B, Nir, Swir1 and Swir2 (30 m ground pixel size) were used in all the cases.
| Sensor | Date | Sensor | Date | Footprint: Path/Row |
|---|
| Landsat 5 TM | 27 August 1984 | Landsat 8 OLI | 26 July 2013 | 200/36 |
| Landsat 5 TM | 27 August 1984 | Landsat 8 OLI | 26 July 2013 | 200/37 |
| Landsat 5 TM | 27 August 1984 | Landsat 8 OLI | 26 July 2013 | 200/38 |
| Landsat 5 TM | 7 October 1984 | Landsat 8 OLI | 4 August 2013 | 199/36 |
| Landsat 5 TM | 7 October 1984 | Landsat 8 OLI | 4 August 2013 | 199/37 |
The Level 1T (L1T) data product provides systematic radiometric and geometric corrections by incorporating ground control points (GCPs), while also employing a digital elevation model (DEM) to undertake terrain correction. L1T products had been previously orthorectified (UTM projection and WGS84 reference system) and corrected for terrain relief. Geodetic accuracy of these products depends on the accuracy of the ground control points and the resolution of the DEM used. According to the corresponding metadata files, the georeferencing mean error (expressed as RMSE2D or planimetric error computed at GCPs) was always notably lower than 30 m (i.e., subpixel error), which means that images may have been considered suitable for the purposes of the study.
4. Results and Discussion
4.1. Results from Random Forest Classification Including All Object-Based Features
A proper feature selection improves the performance of the classification process by identifying the most relevant features. It reduces the computational complexity and increases the generalization capability of the supervised classifier. The relative importance for the general classification of every feature extracted from the 2013 Landsat dataset according to RF classification and the Gini index is depicted in
Table 3. It was found that many different types of features were regarded as important, although all object features based on standard deviation were poorly ranked. Moreover, PV, NPV and S fractions derived from SMA (subpixel approach), along with most vegetation indices, were ranked among the ten best features for “Forest” and “Non-Forest” classifications. Notice that NDVI is located at the top, demonstrating its ability to provide information about the density of green biomass, vegetation status and canopy structure in a given image object [
63].
As previously reported by Asner and Heidebrecht [
41], the Swir2 spectral region turns out to be one of the best ways to estimate the fractional cover of photosynthetic vegetation, non-photosynthetic vegetation and bare soils in arid regions. In fact, Mean Swir2 was ranked the third feature in relative importance, although it has also been somehow included in the computed fractions of PV, NPV and Soil obtained from SMA approach.
Table 3.
Relative importance of every object-based feature according to Random Forest training stage (all object-based features were computed from 2013 Landsat dataset).
Table 3.
Relative importance of every object-based feature according to Random Forest training stage (all object-based features were computed from 2013 Landsat dataset).
| Features | Relative Importance |
|---|
| NDVI_2013 | 100.00 |
| Mean Green_2013 | 92.08 |
| Mean Swir2_2013 | 90.53 |
| MSR_2013 | 86.35 |
| Fraction PV 2013 | 86.14 |
| Mean Red_2013 | 82.57 |
| Fraction Soil 2013 | 79.92 |
| Mean Blue_2013 | 71.63 |
| Fraction NPV 2013 | 71.57 |
| GVI_2013 | 68.37 |
| NDSVI_2013 | 68.34 |
| Standard deviation Fraction NPV 2013 | 61.10 |
| Standard deviation Fraction PV 2013 | 60.36 |
| Mean Nir_2013 | 58.42 |
| Mean Swir1_2013 | 55.06 |
| Standard deviation Swir1_2013 | 45.58 |
| Standard deviation Fraction Soil 2013 | 44.91 |
| Standard deviation Nir_2013 | 41.44 |
| Standard deviation Red_2013 | 37.58 |
| Standard deviation Blue_2013 | 32.98 |
| Standard deviation Swir2_2013 | 31.66 |
| Standard deviation Green_2013 | 24.90 |
A summary of the results of the accuracy assessment, along with the 95% confidence intervals for each accuracy descriptor, is presented in
Table 4. The overall accuracy (OA) took a value of 89.1%, statistically varying from 85.7% to 92.0%. Those results were considered to be suitable since the OA was always higher than 85%, which has been established as the minimum acceptable value for the classification results by different authors ([
64,
65]). That minimum seemed to be a reasonable reference for the required accuracy in this work since there was a large variability within the classes that were labelled.
The user’s accuracy (UA) for each target class indicated the expected error when using the classification map in field or commission error (
Table 4). The reliability of the classification was very high for the class “Non-Forest”, with a probability of success greater than 91%. However, this probability was slightly lower in the case of the “Forest” class with a value of 84.7%.
The “Non-Forest” class also attained higher values than the “Forest” class with respect to the producer’s accuracy (PA) (
Table 4), an accuracy measure related to error of omission that represents the probability of leaving without classifying a pixel belonging to one of the target classes. Briefly, and working with the whole object-based features vector, RF classifier performed worse when dealing with the “Forest” class, likely because of the unexpected high spectral variability of the vegetated ecosystems apparently included in this target class. Indeed, the complexity of landscapes and spectral confusion amongst the different land covers potentially constituting the “Forest” class (fruit crops, shrubland vegetation, croplands, Alpha grass and so on) helped to worsen the expected results.
Table 4.
Classification accuracy assessment computed from the Random Forest out-of-bag subset (estimate of misclassification rate). The whole object-based features vector was used in training. Confidence Intervals (CI) were calculated at
p < 0.05 signification level according to [
62].
Table 4.
Classification accuracy assessment computed from the Random Forest out-of-bag subset (estimate of misclassification rate). The whole object-based features vector was used in training. Confidence Intervals (CI) were calculated at p < 0.05 signification level according to [62].
| | Classification Data Predicted by Random Forest Model | Total |
|---|
| Forest | Non-Forest |
|---|
| Observed Data (Ground Truth) | Forest | 122 | 22 | 144 |
| Non-Forest | 22 | 238 | 260 |
| Total | 144 | 260 | 404 |
| User’s accuracy | Producer’s accuracy | Overall accuracy |
| Forest | 84.7% (CI: 77.8% to 90.2%) | 84.7% (CI: 77.8% to 90.2%) | 89.1% (CI: 85.7% to 92.0%) |
| Non-Forest | 91.5% (CI: 87.5% to 94.6%) | 91.5% (CI: 87.5% to 94.6%) |
4.2. Results from Random Forest Classification Only Including Object-Based Indices’ Features
As was said before, by extracting as much information as possible from a given data set while using the smallest number of features, we can save significant computation time and build models that generalize better for unseen data points. According to Yang and Honavar [
66], the choice of features used to represent patterns that are presented to a classifier affects several pattern classification aspects, including the accuracy of the learned classification algorithm, the time needed for learning a classification function, the number of training instances needed for learning, and the cost associated with the features. In fact, if two numerical features are perfectly correlated, then one does not add any additional information to the machine learning process and only contributes with confusion, a phenomenon widely known as “the curse of dimensionality”. Thus, if the number of features is too high (relative to the training sample size), then it is usually beneficial to reduce the number of features through a feature space optimization technique based, for example, on the relative importance of every object-based feature, provided in
Table 3. Furthermore, it seems reasonable to take advantage of those features computed as ratios (normalized values) more than those based on mean values of ground reflectance. This strategy could help to apply the obtained RF classification model to other Landsat datasets located at similar arid and semiarid areas regardless of the type of atmospheric correction carried out.
In this sense, the original feature space was significantly reduced from 22 features to only 7 based on four vegetation indices and three SMA derived fractions (PV, NPV and Soil). The relative importance of every feature belonging to this new features vector, again according to RF classification and the Gini index, is shown in
Table 5. It is worth noting that NDVI continued being the most relevant feature, closely followed by the photosynthetic vegetation fraction provided by SMA approach. A little more detached is the feature fraction of soil.
Table 5.
Relative importance of every object-based feature according to Random Forest training stage (only object-based indices’ features for 2013 Landsat dataset).
Table 5.
Relative importance of every object-based feature according to Random Forest training stage (only object-based indices’ features for 2013 Landsat dataset).
| Features | Importance |
|---|
| NDVI_2013 | 100.00 |
| Fraction PV 2013 | 97.70 |
| Fraction Soil 2013 | 83.43 |
| GVI_2013 | 77.34 |
| MSR_2013 | 75.31 |
| NDSVI_2013 | 74.85 |
| Fraction_NPV_2013 | 61.54 |
The results from applying RF classifier on the new reduced feature space can be observed in
Table 6. It is relevant to underline a significant improvement of the initial classification accuracy results shown in
Table 4, reaching an OA value of 92.3% with a minimum statistically estimated value of 89.3%. Similarly, the UA and PA indicator notably improved, both for the “Forest” and “Non-Forest” classes, denoting a better performance of the RF classifier working on a significantly reduced features vector. As has been previously reported, the RF classifier usually achieves high accuracy compared to other supervised classifiers such as maximum likelihood, spectral angle, single classification trees ([
67,
68]) and neural network [
69], although there are other non-parametric classifiers that can overcome, in certain conditions, the results provided by RF, such as support vector machines [
70]. Furthermore, the RF model provides quantitative measurements of each feature’s relative contribution to the classification result for users to evaluate the importance of input variables.
The accuracy results provided for the “Forest” class continued to be worse than those achieved in the case of the “Non-Forest” class, although they can be considered adequate to reasonably detect a change in the surface components of the vegetation cover or, additionally, spectral/spatial movement of vegetation in time, thereby generating location maps that help in the process of decision-making and possible intervention and correction works.
Table 6.
Classification accuracy assessment computed from the Random Forest out-of-bag (estimate of misclassification rate). Only object-based indices’ features were used in training. Confidence intervals (CI) were calculated at
p < 0.05 signification level according to [
62].
Table 6.
Classification accuracy assessment computed from the Random Forest out-of-bag (estimate of misclassification rate). Only object-based indices’ features were used in training. Confidence intervals (CI) were calculated at p < 0.05 signification level according to [62].
| | Classification Data Predicted by Random Forest Model | Total |
|---|
| Forest | Non-Forest |
|---|
| Observed data (Ground Truth) | Forest | 127 | 15 | 142 |
| Non-Forest | 16 | 247 | 263 |
| Total | 143 | 262 | 405 |
| User’s accuracy | Producer’s accuracy | Overall accuracy |
| Forest | 88.8% (CI: 82.5% to 93.5%) | 89.4% (CI: 83.2% to 94.0%) | 92.3% (CI: 89.3% to 94.7%) |
| Non-Forest | 94.3% (CI: 90.7% to 96.8%) | 93.9% (CI: 90.3% to 96.5%) |
4.3. Forest Cover Change between 1984 and 2013
The RF model calibrated from the 2013 Landsat dataset was directly applied to the 1984 Landsat dataset, allowing us to obtain binary maps “Forest-Non-Forest” for the Moulouya River watershed for the years 1984 and 2013 (
Figure 4 and
Figure 5 respectively).
From these maps, it could be estimated that the forest land cover in 1984 was close to 165,061 has, while in 2013 it was about 173,865 has. That meant a very small net increase of forest cover (5.3%) from 1984 to 2013, which can be qualified as a somewhat disappointing situation from the point of view of the aforementioned ten-year programme (2005–2014), meant to mitigate the risk and impact of deforestation processes in Morocco by undertaking an intense plan of reforestation.
Although difficult to pin down since the scheduled hectares for reforestation in the ten-year programme were related to provinces, and the Moulouya River watershed partly occupies several Moroccan ones, it was estimated that the reforested area planned in our working zone should be around 20,000–25,000 has, a value significantly higher than the data provided in this study. In brief, although the reforestation process is ongoing, it should be intensified over the years to come. It is beyond the scope of this article to review the consequences that the failure of this programme may have on the sustainability of the irrigated perimeters located downstream the Mohammed V dam, such as Triffa, Zebra, Garet and Bouareg areas, in the medium to long term.
Figure 4.
Binary map Forest-Non-Forest for the Moulouya River watershed (area located upstream the dam Mohammed V) from Landsat image data corresponding to 1984.
Figure 4.
Binary map Forest-Non-Forest for the Moulouya River watershed (area located upstream the dam Mohammed V) from Landsat image data corresponding to 1984.
Figure 5.
Binary map Forest-Non-Forest for the Moulouya River watershed (area located upstream the dam Mohammed V) from Landsat image data corresponding to 2013.
Figure 5.
Binary map Forest-Non-Forest for the Moulouya River watershed (area located upstream the dam Mohammed V) from Landsat image data corresponding to 2013.
The forested and non-forested areas presented in
Figure 4 and
Figure 5 can be compared to the results obtained by Hansen
et al. [
21], corresponding to Landsat image data taken in 2000 (
Figure 6). It is interesting to note that the spatial distribution pattern of forested areas turned out to be quite similar, although data from Hansen
et al. depicted a significantly smaller forest land cover comprising an area of about 62,995 has. It should be remembered that, according to our results, the forest land cover in 1984 was close to 165,061 has, while in 2013 it was about 173,865 has.
In fact, the study from Hansen et al., despite being very exhaustive and worldwide scale, necessarily tends to generalize with respect to canopy closure for all vegetation taller than 5 m. Notice that within the context of this study, and taking into account the singularity of forests located at arid and semiarid areas, the semantic definition of “Forest” has been slightly changed to only consider those containing trees taller than 2.5 m in average as forest stands. Therefore, global forest land cover maps should be carefully applied to regional or local scale, especially when dealing with arid and semiarid Mediterranean areas where forest stands are sparse and not very strong, and often appear in the form of degraded bush clearly shorter than 5 m. Hence, regarding studies of a more local type, it is important to count on appropriate training that enables the supervised classifier to discriminate between forested/reforested areas and “alpha grass”/shrubland ecosystems typical of semiarid regions.
Figure 6.
Binary map Forest-Non-Forest for the Moulouya River watershed (30 m ground spatial resolution). Tree cover in the year 2000, defined as canopy closure for all vegetation taller than 5 m as average height. Data taken from Hansen
et al. [
21].
Figure 6.
Binary map Forest-Non-Forest for the Moulouya River watershed (30 m ground spatial resolution). Tree cover in the year 2000, defined as canopy closure for all vegetation taller than 5 m as average height. Data taken from Hansen
et al. [
21].
5. Conclusions
This study was intended as a methodological approach headed up to integrate subpixel-based (spectral mixture analysis; SMA) and pixel-based information (spectral values and vegetation indices) from Landsat data in the context of an object-based image analysis (OBIA) to efficiently map forest and non-forest areas located in arid and semiarid regions. Random Forest was applied to classify objects according to several object-based computed features.
The accuracy of the results attained in this work, especially the ability to work on a normalized and reduced set of features, makes our approach highly recommended to multi-temporal monitoring of forest evolution on a regional scale in arid and semiarid areas. Notice that most existing methods need the ground reference data to be collected for each image dataset, causing considerable cost in time and labor resources. If a trained classification algorithm could be utilized repeatedly for multiple years without the need for reformulation each year, mapping cost would be significantly reduced and the timeliness of the map products would be improved. Therefore, the approach proposed in this work, based on an innovative method using an OBIA, SMA and Random Forest classifier, has been successfully tested to automatically classify previously segmented multi-temporal Landsat imagery as forest or non-forest image objects. This information can be used to assess the efficacy of past actions and design future strategies to preserve and improve the vulnerable and scarce forests located in the working area.
It is beyond the scope of this paper to discuss the patterns or driving factors of the forest cover change in the Moulouya river watershed. This would require not only a quantitative net balance between forest and non-forest areas, but a spatially focused change detection study designed to locate spatial distribution of change detection results, or even a detailed “ from-to ” change trajectories study. This relevant issue should be addressed through rigorous and exhaustive further works.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





