
Using Spatial Optimization to Create Dynamic Harvest Blocks from LiDAR-Based Small Interpretation Units



Abstract
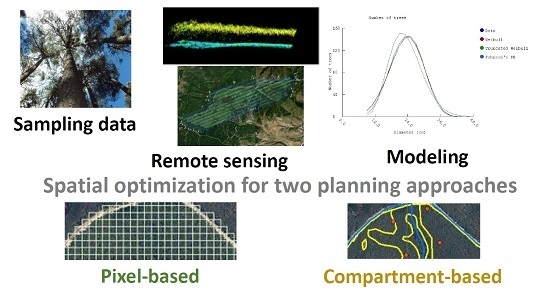
:
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Forest Inventory
2.3. Stand Delineation
2.4. Diameter Distribution Modelling
2.5. Growth Modelling
2.6. Forest Planning and Spatial Optimization
3. Results
3.1. LiDAR-Based Models for Predicting Stand Attributes
3.2. Diameter Distribution Models
- Pinus pinasterb = 98.119 − 15.593 lnN + 14.822 lnG − 0.018 ln(0.01 A),c = 2.902 − 1.264 Dq + 1.377 b,
- Pinus sylvestrisb = 16.253 − 12.018 lnN + 12.249 lnG + 0.039 ln(0.01 A)c = 4.49 − 0.514 Dq + 0.533 b,
3.3. Growth Models
- Pinus pinaster
- Pinus sylvestris
- Pinus pinaster
- Pinus sylvestris
- Pinus pinaster
- Pinus sylvestris
3.4. DTU Results: Pixels versus Predefined Compartments
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kangas, A.; Kangas, J.; Kurttila, M. Introduction. In Decision Support for Forest Management; Managing Forest Ecosystems; Springer: Berlin, Germany, 2008; Volume 16, pp. 1–18. [Google Scholar]
- Pukkala, T. Introduction to multi-objective forest planning. In Managing Forest Ecosystems: Multi-Objective Forest Planning; Managing Forest Ecosystems; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2002; Volume 6, pp. 1–21. [Google Scholar]
- Vauhkonen, J.; Maltamo, M.; McRoberts, R.E.; Næsset, E. Introduction to forestry applications of airborne laser scanning. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Managing Forest Ecosystems; Springer: Berlin, Germany, 2014; Volume 27, pp. 1–21. [Google Scholar]
- Rempel, K.C.; Parker, A.K. An information note on an airborne laser terrain profiler for micro-relief studies. In Proceedings of the 3rd Symposium on Remote Sensing of Environment; University of Michigan Institute of Science and Technology: Michigan, MI, USA, 1964; pp. 321–337. [Google Scholar]
- Hyyppä, J.; Hyyppä, H.; Leckie, D.; Gougeon, F.; Yu, X.; Maltamo, M. Review of methods of small-footprint airborne laser scanning for extracting forest inventory data in boreal forests. Int. J. Remote Sens. 2008, 29, 1339–1366. [Google Scholar] [CrossRef]
- Næsset, E. Area-based inventory in Norway. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Managing Forest Ecosystems; Springer: Berlin, Germany, 2014; Volume 27, pp. 215–240. [Google Scholar]
- Næsset, E.; Gobakken, T.; Holmgren, J.; Hyyppä, H.; Hyyppä, J.; Maltamo, M. Laser scanning of forest resources: the Nordic experience. Scand. J. For. Res. 2004, 19, 482–499. [Google Scholar] [CrossRef]
- Smith, A.M.S.; Falkowski, M.J.; Hudak, A.T.; Evans, J.S.; Robinson, A.P.; Steele, C.M. A cross-comparison of field, spectral, and LiDAR estimates of forest canopy cover. Can. J. Remote Sens. 2009, 35, 447–459. [Google Scholar] [CrossRef]
- García, M.; Riaño, D.; Chuvieco, E.; Danson, F.M. Estimating biomass carbon stocks for a Mediterranean forest in central Spain using LiDAR height and intensity data. Remote Sens. Environ. 2010, 114, 816–830. [Google Scholar] [CrossRef]
- González-Olabarria, J.; Rodríguez, F.; Fernández-Landa, A.; Mola-Yudego, B. Mapping fire risk in the Model Forest of Urbión (Spain) based on airborne LiDAR measurements. For. Ecol. Manag. 2012, 282, 145–156. [Google Scholar] [CrossRef]
- Maltamo, M.; Gobakken, T. Predicting tree diameter distributions. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Managing Forest Ecosystems; Springer: Berlin, Germany, 2014; Volume 27, pp. 177–192. [Google Scholar]
- Lu, F.; Eriksson, L. Formation of harvest units with genetic algorithms. For. Ecol. Manag. 2000, 130, 57–67. [Google Scholar] [CrossRef]
- Pippuri, I.; Kallio, E.; Maltamo, M.; Peltola, H.; Packalén, P. Exploring horizontal area-based metrics to discriminate the spatial pattern of trees and need for the first thinning using airborne laser scanning. Forestry 2012, 85, 305–314. [Google Scholar] [CrossRef]
- Bettinger, P.; Johnson, D.L.; Johnson, K.N. Spatial forest plan development with ecological and economic goals. Ecol. Model. 2003, 169, 215–236. [Google Scholar] [CrossRef]
- Strunk, J.; Temesgen, H.; Andersen, H.E.; Flewelling, J.P.; Madsen, L. Effects of lidar pulse density and sample size on a model-assisted approach to estimate forest inventory variables. Can. J. Remote Sens. 2014, 38, 644–654. [Google Scholar] [CrossRef]
- Magnusson, M.; Fransson, J.E.S.; Holmgren, J. Effects on estimation accuracy of forest variables using different pulse density of laser data. For. Sci. 2007, 53, 619–626. [Google Scholar]
- Packalén, P.; Heinonen, T.; Pukkala, T.; Vauhkonen, J.; Maltamo, M. Dynamic treatment units in Eucalyptus plantation. For. Sci. 2011, 57, 416–426. [Google Scholar]
- De-Miguel, S.; Pukkala, T.; Pasalodos, J. Dynamic treatment units: flexible and adaptive forest management and planning by combining spatial optimization methods and LiDAR. Cuadernos de la Sociedad Española de Ciencias Forestales 2013, 37, 49–54. [Google Scholar]
- Pukkala, T.; Páckalen, P.; Heinonen, T. Dynamic treatment units in forest management planning. In The Management of Industrial Forest Plantations: Theoretical Foundations and Applications; Springer: Berlin, Germany, 2014; Volume 33, pp. 372–392. [Google Scholar]
- Baskent, E.Z.; Keles, S. Spatial forest planning: A review. Ecol. Model. 2005, 188, 145–173. [Google Scholar] [CrossRef]
- Lu, F.; Eriksson, L. Formation of harvest units with genetic algorithms. For. Ecol. Manag. 2000, 130, 57–67. [Google Scholar] [CrossRef]
- Pukkala, T.; Kurttila, M. Examining the performance of six heuristic optimisation techniques in different forest planning problems. Silva Fenn. 2005, 39, 567–80. [Google Scholar] [CrossRef]
- Pukkala, T.; Heinonen, T. Optimizing heuristic search in forest planning. Nonlinear Anal. 2006, 7, 1284–1297. [Google Scholar] [CrossRef]
- McGaughey, R.J.; Carson, W.W. FUSION LIDAR data, photographs, and other data using 2D and 3D visualization techniques. In Proceedings of the Terrain Data: Applications and Visualization—Making the Connection, Charleston, SC, USA, 28 October 2003; American Society for Photogrammetry and Remote Sensing: Bethesda, MD, USA, 2003; pp. 16–24. [Google Scholar]
- Valbuena, R.; Maltamo, M.; Packalen, P. Classification of multilayered forest development classes from low-density national airborne lidar datasets. Forestry 2016, 89, 392–401. [Google Scholar] [CrossRef]
- R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing: Vienna, Austria, 2013; Available online: http://www.R-project.org/ (accessed on 20 March 2014).
- Bailey, R.L.; Dell, T.R. Quantifying diameter distributions with the Weibull function. For. Sci. 1973, 19, 97–104. [Google Scholar]
- Trasobares, A.; Pukkala, T. Using past growth to improve individual-tree diameter growth models for uneven-aged mixtures of Pinus. sylvestris L. and Pinus. nigra Arn. in Catalonia, north-east Spain. Ann. For. Sci. 2004, 61, 409–417. [Google Scholar] [CrossRef]
- Clutter, J.L.; Fortson, J.C.; Pienaar, L.V.; Brister, G.H.; Bailey, R.L. Timber Management: A Quantitative Approach; John Wiley & Sons: Hoboken, NJ, USA, 1983. [Google Scholar]
- Heinonen, T. Developing Spatial Optimization in Forest Planning. Master's Thesis, University of Joensuu, Joensuu, Finland, 2007. [Google Scholar]
- Heinonen, T.; Pukkala, T. A comparison of one- and two-compartment neighborhoods in heuristic search with spatial forest management goals. Silva Fenn. 2004, 38, 319–332. [Google Scholar]
- Dowsland, K.A. Simulated annealing. In Modern Heuristic Techniques for Combinatorial Problems; John Wiley & Sons: Hoboken, NJ, USA, 1993; pp. 20–63. [Google Scholar]
- Öhman, K.; Eriksson, L.O. Allowing for spatial consideration in long-term forest planning by linking linear programming with simulated annealing. For. Ecol. Manag. 2002, 161, 221–230. [Google Scholar] [CrossRef]
- ESRI (Environmental Systems Resource Institute). ArcMap 10.2.1. Smooth Line Command within Data Management Tool; ESRI: Redlands, CA, USA, 2014. [Google Scholar]
- Snowdon, P. A ratio estimator for bias correction in logarithmic regressions. Can. J. For. 1991, 21, 720–724. [Google Scholar] [CrossRef]
- Næsset, E. Determination of mean tree height of forest stands using airborne laser scanner data. J. Photogramm. Remote Sens. 1997, 52, 49–56. [Google Scholar] [CrossRef]
- Packalén, P.; Strunk, J.L.; Pitkänen, J.A.; Temesgen, H.; Maltamo, M. Edge-Tree correction for predicting forest inventory attributes using area-based approach with airborne laser scanning. J. STARS 2015, 8, 1274–1280. [Google Scholar] [CrossRef]
- Palahí, M.; Pukkala, T.; Trasobares, A. Modelling the diameter distribution of Pinus sylvestris, Pinus nigra and Pinus halepensis forest stands in Catalonia using the truncated Weibull function. Forestry 2006, 79, 553–562. [Google Scholar] [CrossRef]
- Bravo-Oviedo, A.; Río, M.; Montero, G. Site index curves and growth model for Mediterranean maritime pine (Pinus pinaster Ait.) in Spain. For. Ecol. Manag. 2004, 201, 187–197. [Google Scholar] [CrossRef]
- Palahí, M.; Miina, J.; Montero, G.; Pukkala, T. Individual-tree growth and mortality models for Scots pine (Pinus sylvestris L.) in north-east Spain. Ann. For. Sci. 2003, 60, 1–10. [Google Scholar] [CrossRef]
- Lizarralde, I. Dinámica de Rodales y Competencia en las Masas de Pino Silvestre (Pinus sylvestris L.) y Pino Negral (Pinus pinaster Ait.) de los Sistemas Central e Ibérico Meridional. Ph.D. Thesis, University of Valladolid, Victoria, Spain, 2008. [Google Scholar]
- Pascual, C.; García-Abril, A.; García-Montero, L.G.; Martín-Fernández, S.; Cohen, W.B. Object-based semi-automatic approach for forest structure characterization using lidar data in heterogeneous Pinus sylvestris stands. For. Ecol. Manag. 2008, 255, 3677–3685. [Google Scholar] [CrossRef]
- Pekkarinen, A. A method for the segmentation of very high spatial resolution images of forested landscapes. Int. J. Remote Sens. 2002, 23, 2817–2836. [Google Scholar] [CrossRef]
- Næsset, E.; Bjerknes, K.O. Estimating tree heights and number of stems in young forest stands using airborne laser scanner data. Remote Sens. Environ. 2001, 78, 328–340. [Google Scholar] [CrossRef]
- Heinonen, T.; Pukkala, T. The use of cellular automaton approach in forest planning. Can. J. For. Res. 2007, 37, 2188–2200. [Google Scholar] [CrossRef]
- Pukkala, T.; Heinonen, T.; Kurttila, M. An application of a reduced cost approach to spatial forest planning. For. Sci. 2009, 55, 13–22. [Google Scholar]
- Mathey, A.H.; Nelson, J. Decentralized forest planning models—A cellular automata framework. In Designing Green Landscapes; Springer: Berlin, Germany, 2008; Volume 15, pp. 69–185. [Google Scholar]
- Öhman, K.; Eriksson, L.O. Aggregating harvest activities in long term forest planning by minimizing harvest area perimeters. Silva Fenn. 2010, 44, 77–89. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measured variables | Pinaster stratum | Mixed stratum | ||||
|---|---|---|---|---|---|---|
| 30 Sample Plots | ||||||
| Min | Mean | Max | Min | Mean | Max | |
| Diameter at breast height (cm) | 7.1 | 14.8 | 22.0 | 6.3 | 12.8 | 19.3 |
| Tree height (m) | 7.1 | 14.8 | 22.0 | 6.3 | 12.8 | 19.3 |
| Stand density (trees·ha−1) | 260.0 | 604.0 | 1080.0 | 360.0 | 797.1 | 1440.0 |
| Stand basal area (m2·ha−1) | 21.2 | 47.4 | 72.1 | 12.9 | 31.6 | 59.2 |
| Stand volume (m3·ha−1) | 102.1 | 363.9 | 640.0 | 76.9 | 219.2 | 463.3 |
| Dominant height (m) | 11.9 | 17.3 | 21.8 | 10.7 | 15.2 | 19.0 |
| Age (year) | 33.0 | 56.4 | 74.0 | 33.0 | 42.4 | 78.0 |
| Treatment | 2014–2023 | 2024–2033 | 2034–2043 | Total | ||||
|---|---|---|---|---|---|---|---|---|
| Pixel | Comp | Pixel | Comp | Pixel | Comp | Pixel | Comp | |
| Light thinning | 32.8 | 40.0 | 52.3 | 17.2 | 56.6 | 18.4 | 141.7 | 75.6 |
| Moderate thinning | 16.9 | 36.4 | 16.7 | 12.2 | 19.5 | 0.0 | 53.1 | 48.6 |
| Heavy thinning | 0.7 | 0.0 | 1.8 | 11.7 | 0.3 | 10.5 | 2.8 | 22.2 |
| Seed tree cut | 30.1 | 23.1 | 39.0 | 32.9 | 9.3 | 21.5 | 78.4 | 77.5 |
| Remove overstory | 0.0 | 0.0 | 4.9 | 0.0 | 32.2 | 32.9 | 37.1 | 32.9 |
| Total | 80.5 | 99.5 | 114.7 | 74.0 | 117.9 | 83.3 | 313.3 | 256.8 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pascual, A.; Pukkala, T.; Rodríguez, F.; De-Miguel, S. Using Spatial Optimization to Create Dynamic Harvest Blocks from LiDAR-Based Small Interpretation Units. Forests 2016, 7, 220. https://doi.org/10.3390/f7100220
Pascual A, Pukkala T, Rodríguez F, De-Miguel S. Using Spatial Optimization to Create Dynamic Harvest Blocks from LiDAR-Based Small Interpretation Units. Forests. 2016; 7(10):220. https://doi.org/10.3390/f7100220
Chicago/Turabian StylePascual, Adrián, Timo Pukkala, Francisco Rodríguez, and Sergio De-Miguel. 2016. "Using Spatial Optimization to Create Dynamic Harvest Blocks from LiDAR-Based Small Interpretation Units" Forests 7, no. 10: 220. https://doi.org/10.3390/f7100220