
A New Generation of Collaborative Immersive Analytics on the Web: Open-Source Services to Capture, Process and Inspect Users’ Sessions in 3D Environments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
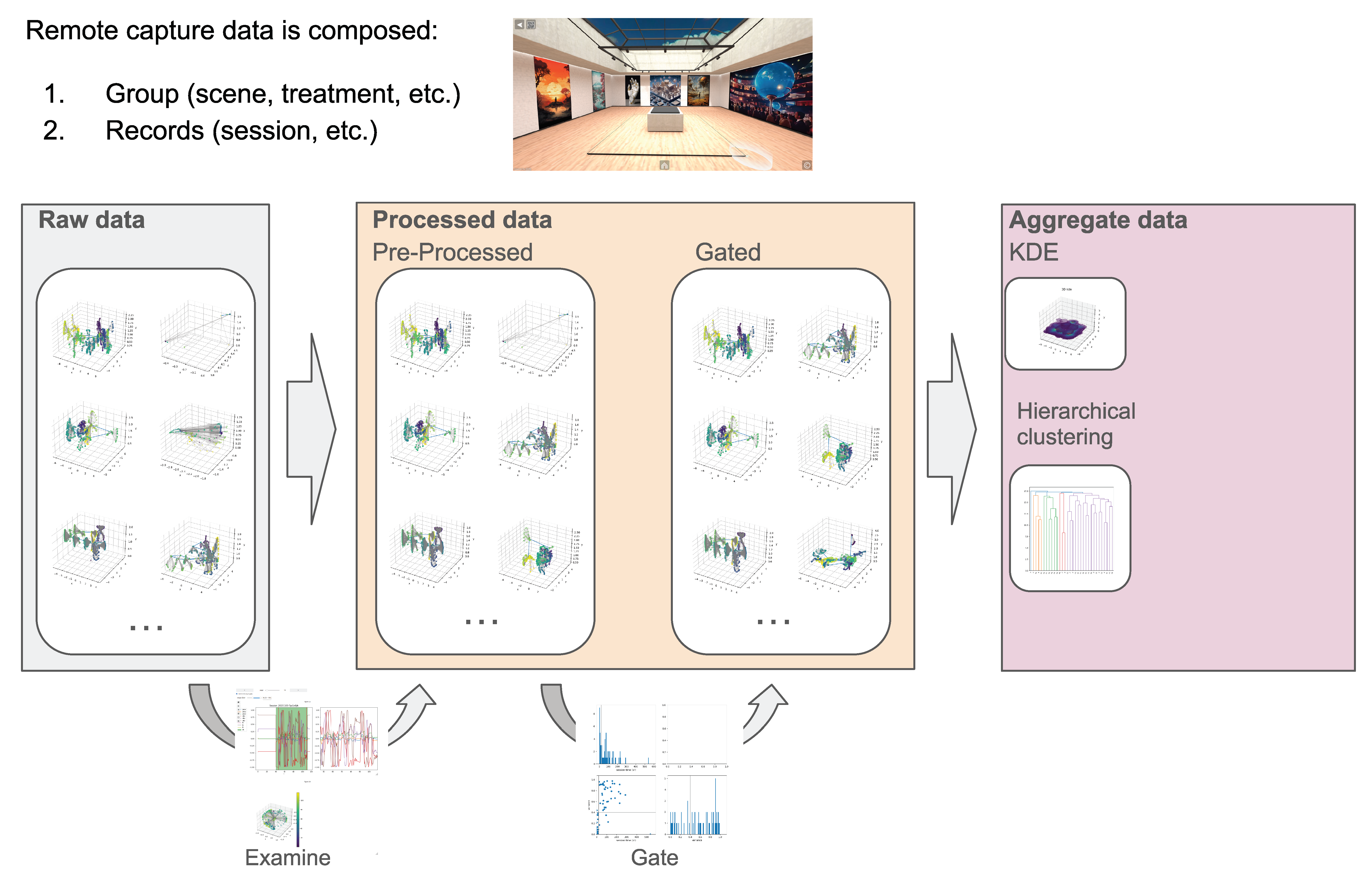
- A fully web-based, collaborative, modular, open-source pipeline to capture, process and inspect remote interactive sessions. The pipeline components can be deployed on single or multiple dedicated hubs.
- A scalable and flexible capture service designed and developed to allow remote nodes to request session recording with custom attributes, also offering an accessible REST API for easy integration in other platforms, pilots or federated scenarios (Section 3.1).
- An advanced WebXR immersive analytics tool (“Merkhet”) to inspect records and data aggregates collected on remote hubs (Section 3.3), offering (A) spatial interfaces and elements to access, visualize and annotate spatio-temporal data records and aggregates, using immersive VR or augmented/mixed reality devices; (B) synchronous collaboration among multiple online analysts to discuss volumetric data records/aggregates together; (C) cross-device inspection using mobile devices, desktop devices and XR devices, through a standard web browser.
- A suite of web-based services to develop analytics workflows, which will allow us first to examine and filter incoming raw data (Section 3.2) and then process the data using machine learning models. This stage is also designed to integrate novel encoding models specifically targeting massive data.
2. Related Work
3. Proposed Pipeline
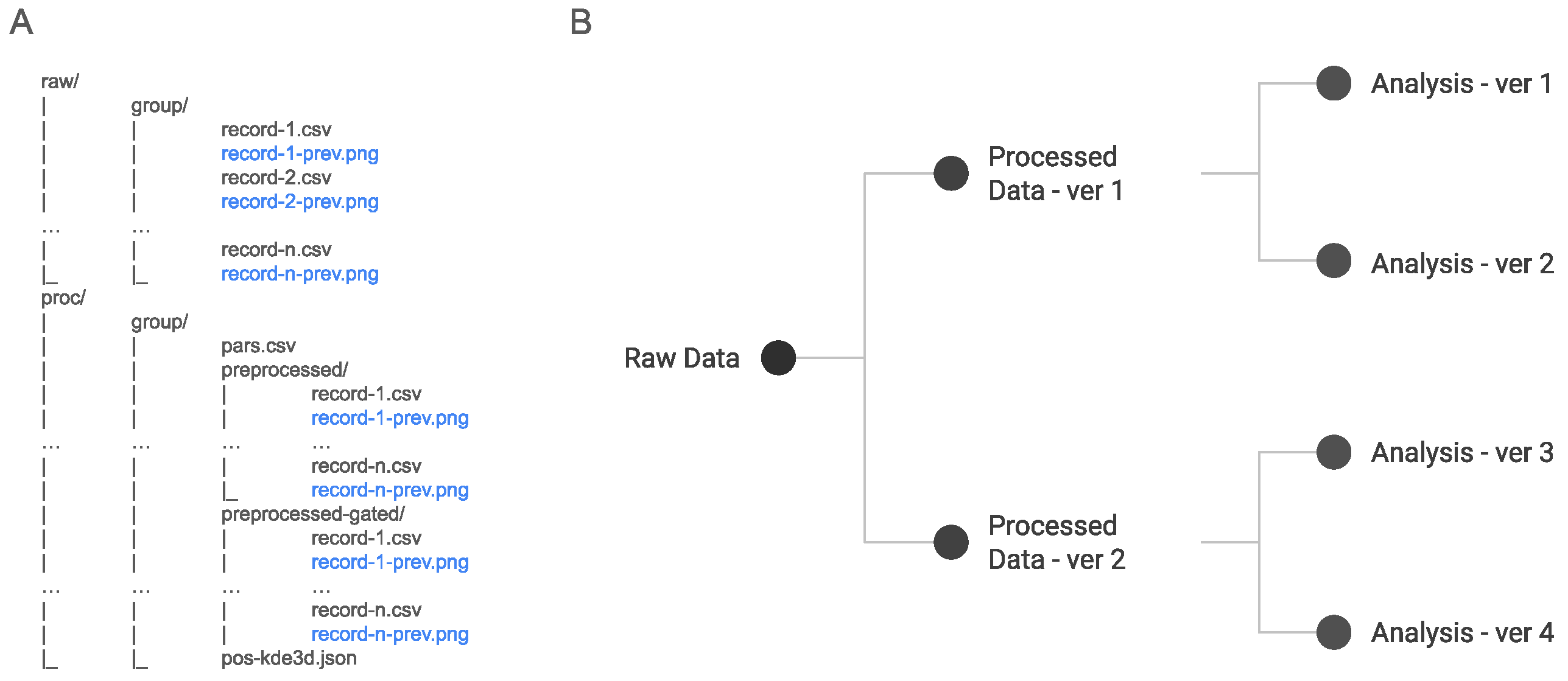
3.1. Capture
- The client application requests a new session, including the intended attributes to record;
- If the capture service responds successfully, a new session is initiated on the hub and the unique ID is sent to the client;
- The client is now able to send progressive data chunks to the hub, with custom policies.
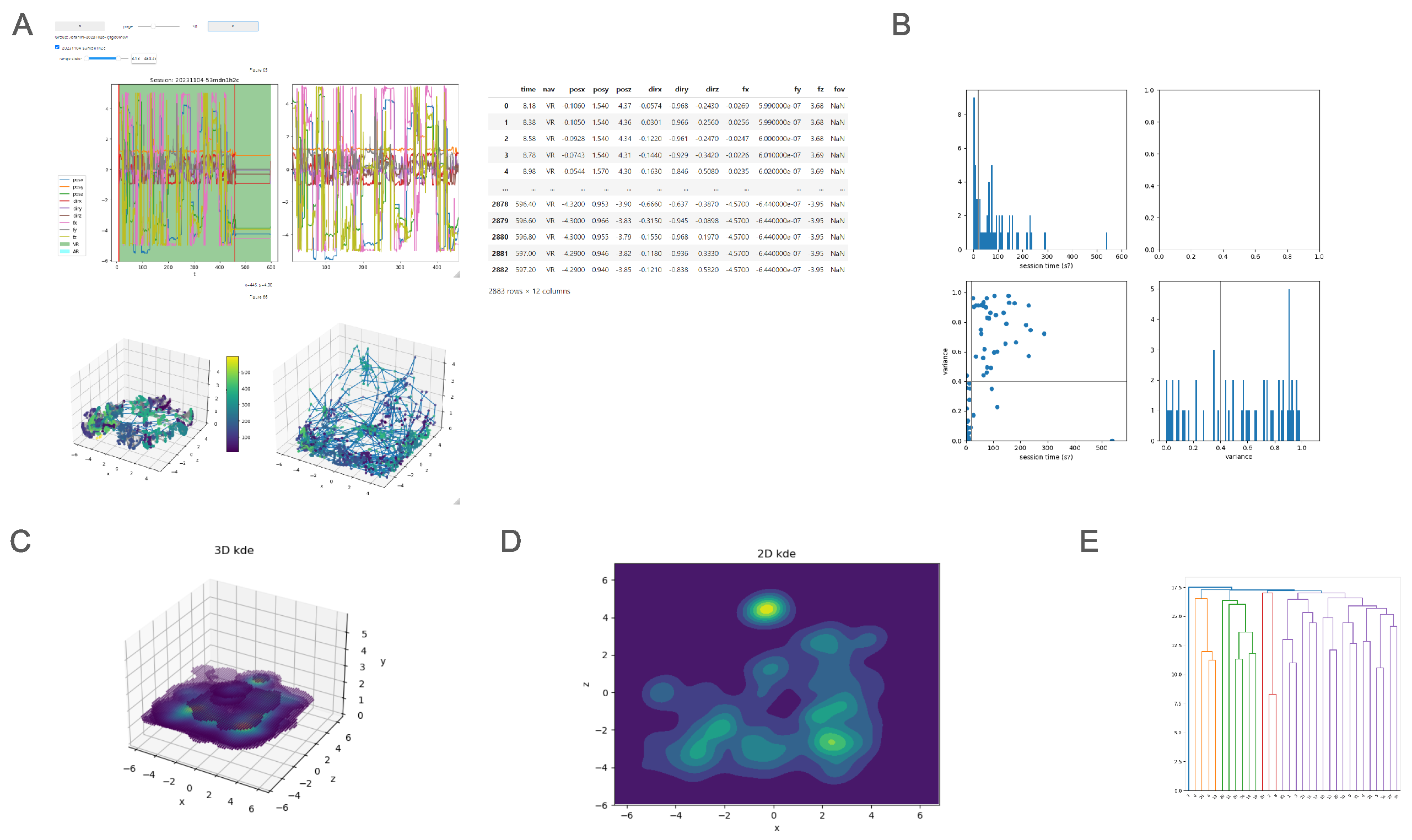
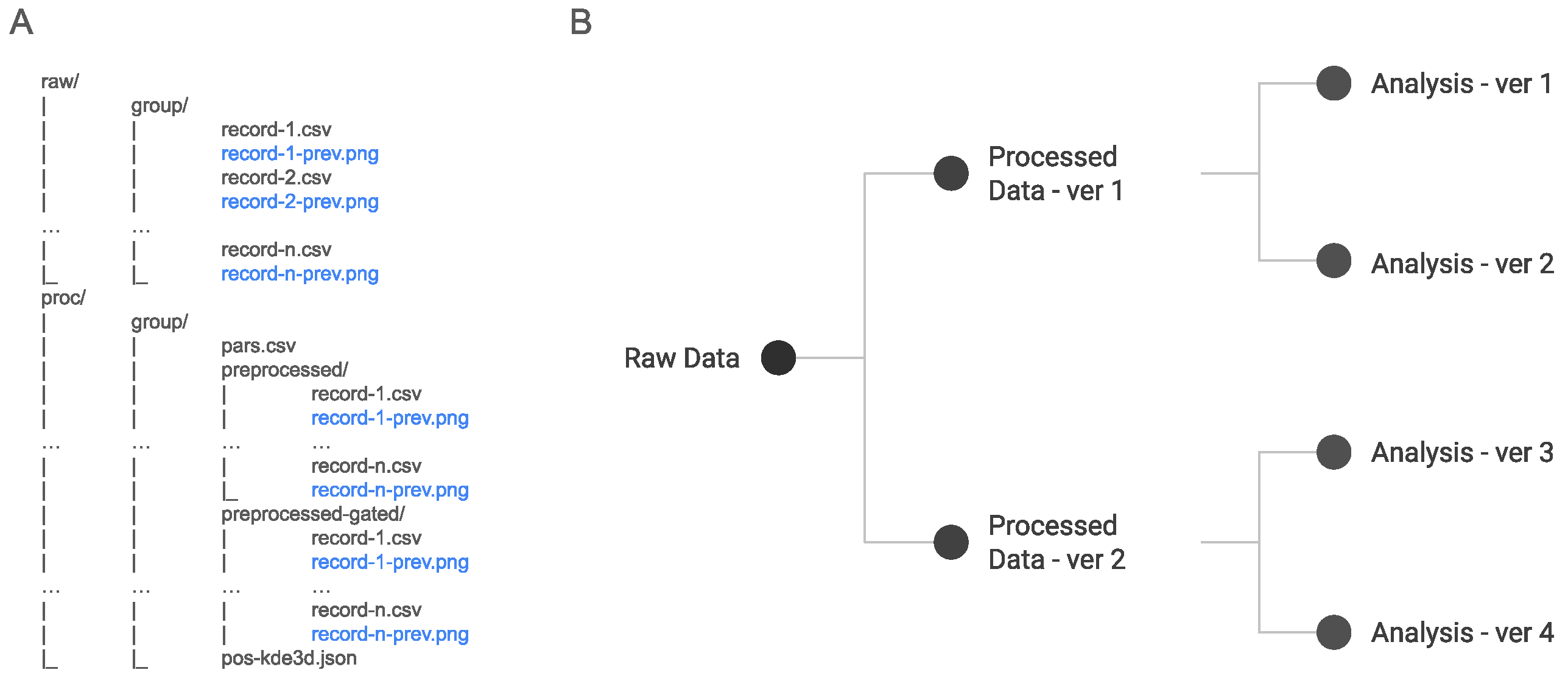
3.2. Process
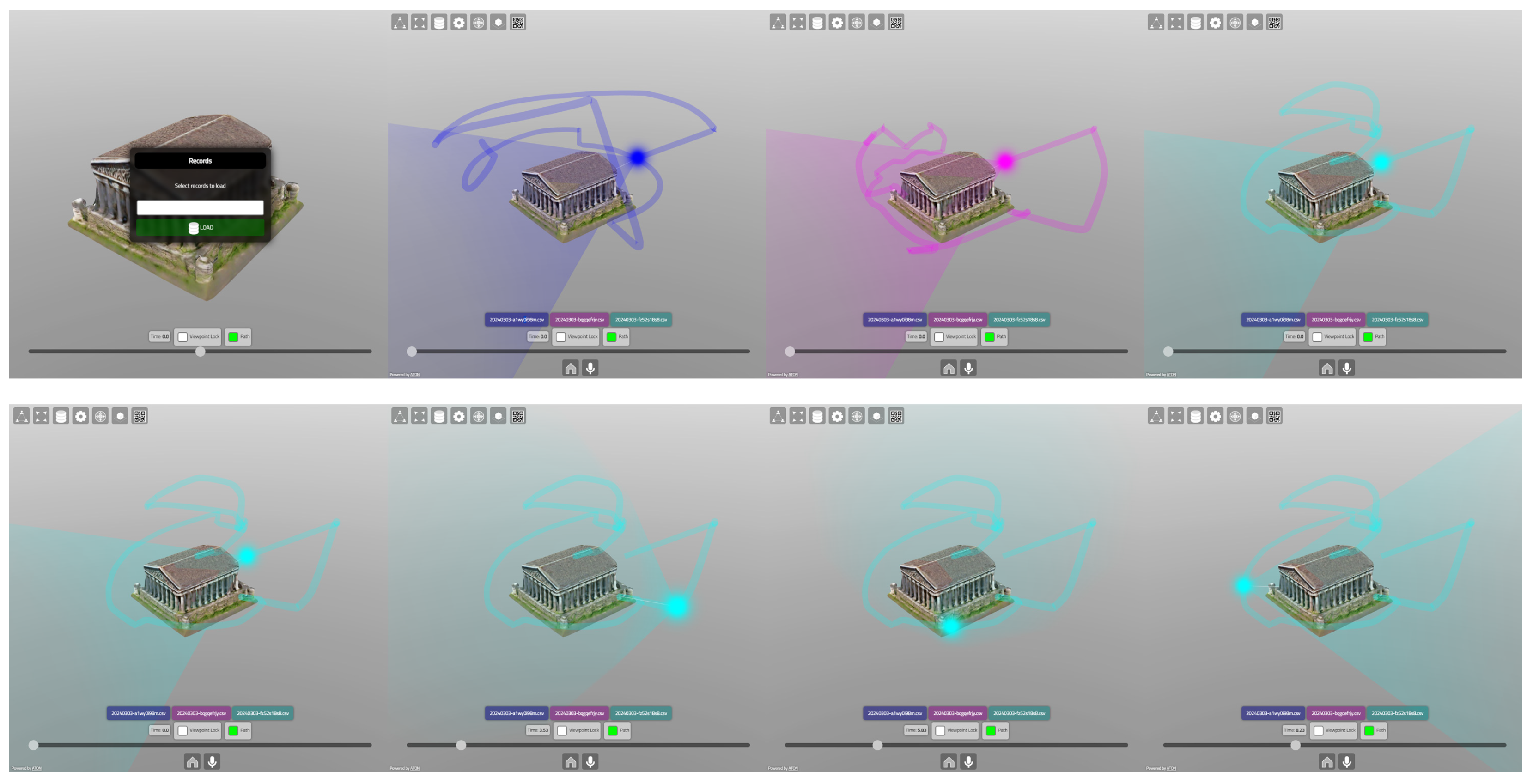
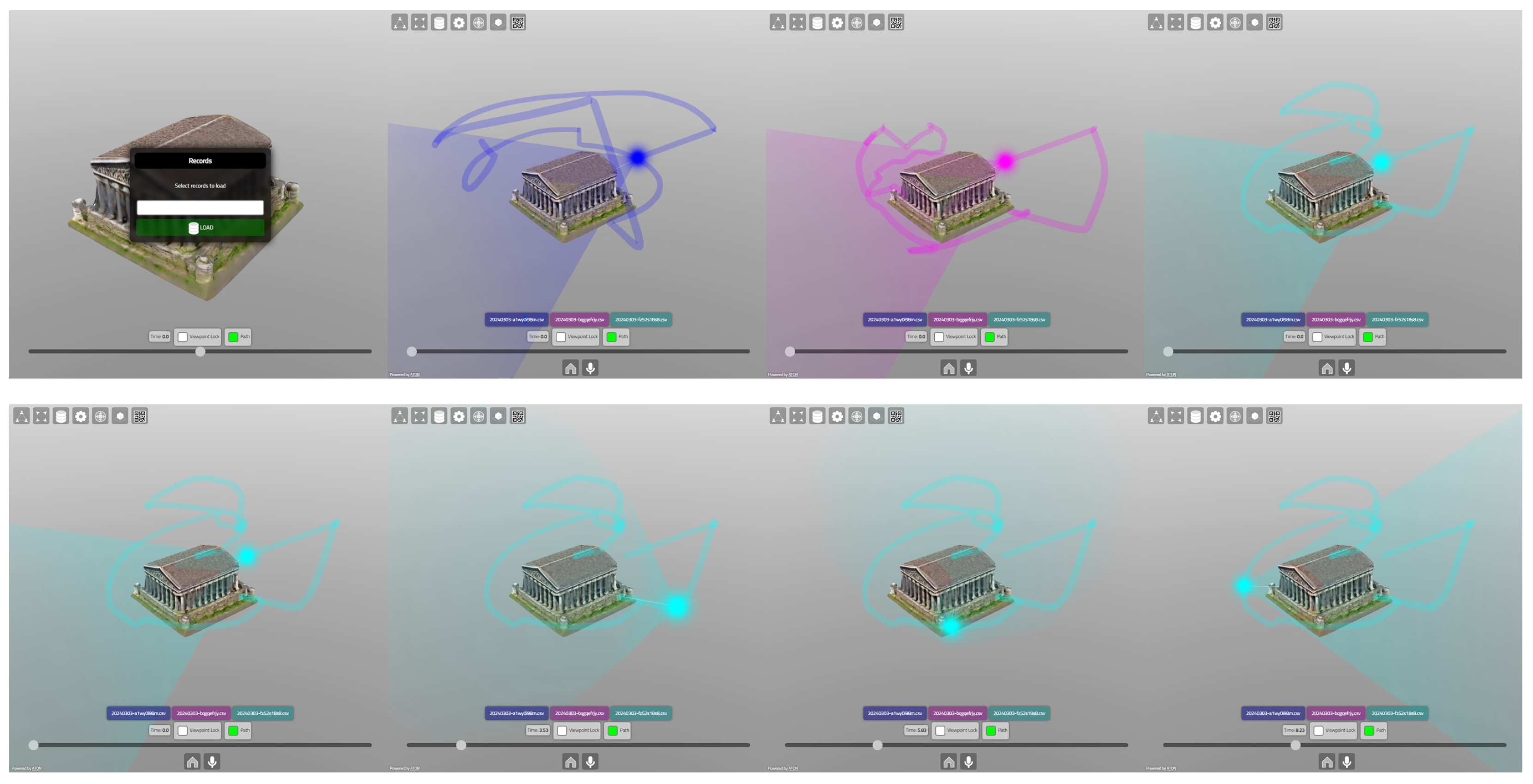
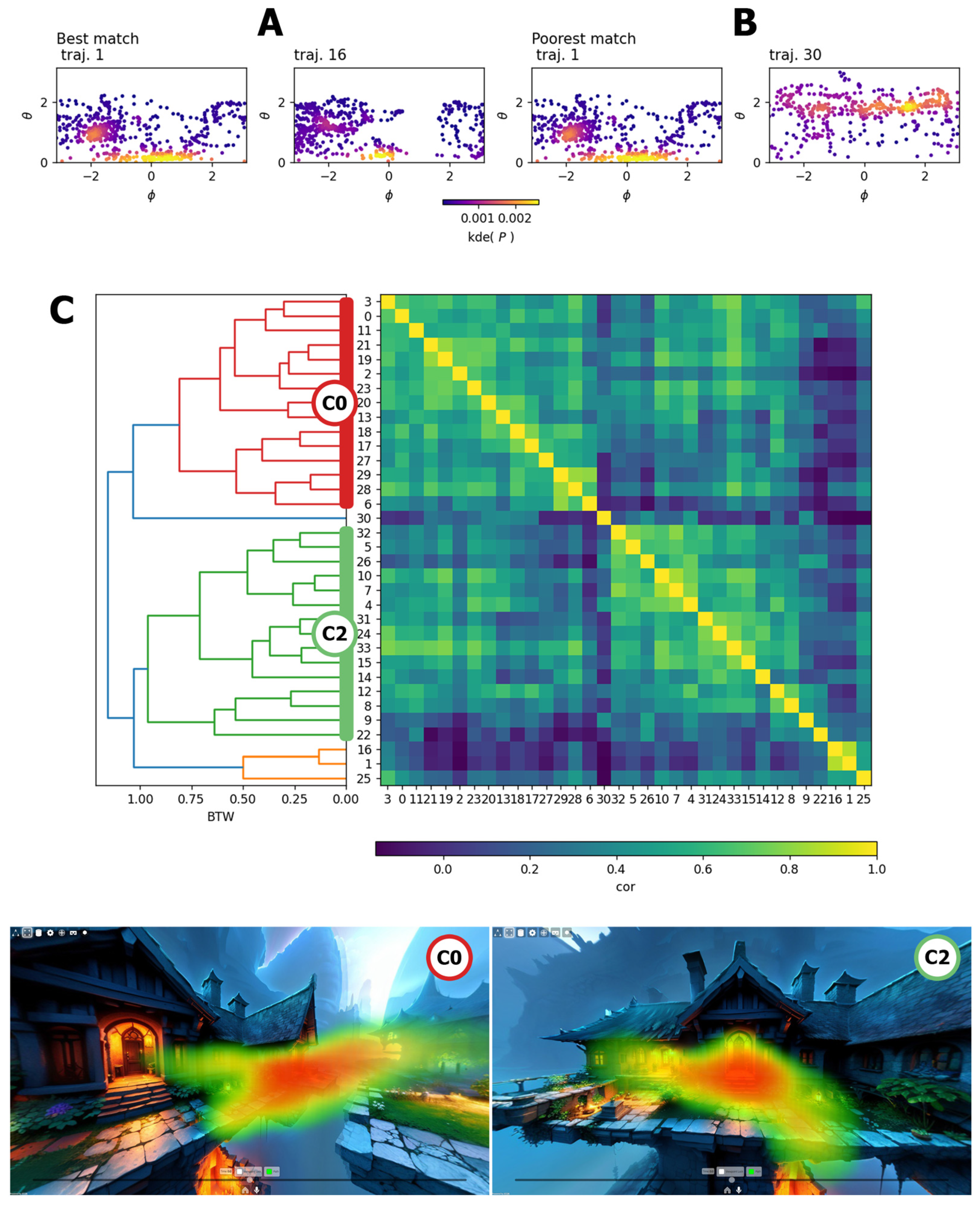
3.3. Inspect
4. Experimental Results
- the physical distance between the public hub (server located in main CNR research area, in Rome) and the actual location where users performed their sessions, thus involving an internet connection for data transmission;
- the number of visitors attending both events, with exhibit spaces focused on heritage and AI;
- the opportunity to study and investigate how people respond to and interact with generative AI content, using HMDs (immersive VR and MR).
4.1. Service Setup and Exhibit Equipment
- Analytics hub: this dedicated server hosted the stages described in Section 3.1 (capture) and Section 3.2 (process), under the H2IOSC project.
- ATON server: this dedicated server hosted the main instance of the ATON framework, providing web applications and 3D content. In this case, this was the “/imagine” WebXR application and its generative AI content, as well as the “Merkhet” WebXR tool (inspect stage, described in Section 3.3).
- A single workstation and one HMD (HP Reverb G2 Headset) were used to experience an immersive VR mode for the ArcheoVirtual event;
- A standalone HMD (Meta Quest PRO) was used to experience both the VR and MR modes (see Figure 6) for the TourismA event.
4.2. The WebXR App “/Imagine”
4.3. Panoramic Generative Tales
4.4. Generative Art Gallery
4.5. The Tomb
4.6. Generative 3D Models with Mixed Reality
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IA | Immersive analytics |
| HMD | Head-mounted display |
| BCI | Brain–computer interface |
| RI | Research Infrastructure |
| DoF | Degrees of freedom |
| AI | Artificial intelligence |
| ML | Machine learning |
| KDE | Kernel density estimation |
| WCD | Within-cluster distance |
References
- Klein, K.; Sedlmair, M.; Schreiber, F. Immersive analytics: An overview. It-Inf. Technol. 2022, 64, 155–168. [Google Scholar] [CrossRef]
- Dwyer, T.; Marriott, K.; Isenberg, T.; Klein, K.; Riche, N.; Schreiber, F.; Stuerzlinger, W.; Thomas, B.H. Immersive Analytics: An Introduction. In Immersive Analytics; Springer: Cham, Switzerland, 2018; pp. 1–23. [Google Scholar]
- Saffo, D.; Di Bartolomeo, S.; Crnovrsanin, T.; South, L.; Raynor, J.; Yildirim, C.; Dunne, C. Unraveling the design space of immersive analytics: A systematic review. IEEE Trans. Vis. Comput. Graph. 2023, 30. [Google Scholar] [CrossRef]
- Fonnet, A.; Prie, Y. Survey of immersive analytics. IEEE Trans. Vis. Comput. Graph. 2019, 27, 2101–2122. [Google Scholar] [CrossRef] [PubMed]
- Marai, G.E.; Leigh, J.; Johnson, A. Immersive analytics lessons from the electronic visualization laboratory: A 25-year perspective. IEEE Comput. Graph. Appl. 2019, 39, 54–66. [Google Scholar] [CrossRef] [PubMed]
- Kraus, M.; Fuchs, J.; Sommer, B.; Klein, K.; Engelke, U.; Keim, D.; Schreiber, F. Immersive analytics with abstract 3D visualizations: A survey. Comput. Graph. Forum 2022, 41, 201–229. [Google Scholar] [CrossRef]
- Sorger, J.; Waldner, M.; Knecht, W.; Arleo, A. Immersive analytics of large dynamic networks via overview and detail navigation. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), San Diego, CA, USA, 9–11 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 144–1447. [Google Scholar]
- Riecke, B.E.; LaViola, J.J., Jr.; Kruijff, E. 3D user interfaces for virtual reality and games: 3D selection, manipulation, and spatial navigation. In Proceedings of the ACM SIGGRAPH 2018 Courses: Special Interest Group on Computer Graphics and Interactive Techniques Conference, Vancouver, BC, Canada, 12–16 August 2018; pp. 1–94. [Google Scholar]
- Hayatpur, D.; Xia, H.; Wigdor, D. Datahop: Spatial data exploration in virtual reality. In Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology, Virtual, 20–23 October 2020; pp. 818–828. [Google Scholar]
- Liu, J.; Ens, B.; Prouzeau, A.; Smiley, J.; Nixon, I.K.; Goodwin, S.; Dwyer, T. Datadancing: An exploration of the design space for visualisation view management for 3d surfaces and spaces. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–17. [Google Scholar]
- Satriadi, K.A.; Ens, B.; Cordeil, M.; Czauderna, T.; Jenny, B. Maps around me: 3d multiview layouts in immersive spaces. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–20. [Google Scholar] [CrossRef]
- Fouché, G.; Argelaguet Sanz, F.; Faure, E.; Kervrann, C. Timeline design space for immersive exploration of time-varying spatial 3d data. In Proceedings of the 28th ACM Symposium on Virtual Reality Software and Technology, Tsukuba, Japan, 29 November–1 December 2022; pp. 1–11. [Google Scholar]
- Ens, B.; Bach, B.; Cordeil, M.; Engelke, U.; Serrano, M.; Willett, W.; Prouzeau, A.; Anthes, C.; Büschel, W.; Dunne, C.; et al. Grand challenges in immersive analytics. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Online, 8–13 May 2021; pp. 1–17. [Google Scholar]
- Garrido, D.; Jacob, J.; Silva, D.C. Performance Impact of Immersion and Collaboration in Visual Data Analysis. In Proceedings of the 2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Sydney, Australia, 16–20 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 780–789. [Google Scholar]
- Billinghurst, M.; Cordeil, M.; Bezerianos, A.; Margolis, T. Collaborative Immersive Analytics. In Immersive Analytics; Springer: Cham, Switzerland, 2018; pp. 221–257. [Google Scholar]
- Lee, B.; Hu, X.; Cordeil, M.; Prouzeau, A.; Jenny, B.; Dwyer, T. Shared surfaces and spaces: Collaborative data visualisation in a co-located immersive environment. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1171–1181. [Google Scholar] [CrossRef] [PubMed]
- González-Zúñiga, L.D.; O’Shaughnessy, P. Virtual Reality… in the Browser. In VR Developer Gems; CRC Press: Boca Raton, FL, USA, 2019; p. 101. [Google Scholar]
- Maclntyre, B.; Smith, T.F. Thoughts on the Future of WebXR and the Immersive Web. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Munich, Germany, 16–20 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 338–342. [Google Scholar]
- Rodríguez, F.C.; Dal Peraro, M.; Abriata, L.A. Democratizing interactive, immersive experiences for science education with WebXR. Nat. Comput. Sci. 2021, 1, 631–632. [Google Scholar] [CrossRef] [PubMed]
- Rivas Pagador, H.; Cabrero Barros, S.; Pacho Rodríguez, G.; Zorrilla, M. HiruXR: A Web library for Collaborative and Interactive Data Visualizations in XR and 2D. In Proceedings of the 2022 ACM International Conference on Interactive Media Experiences, Aveiro, Portugal, 22–24 June 2022; pp. 319–324. [Google Scholar]
- Butcher, P.; John, N.W.; Ritsos, P.D. Towards a framework for immersive analytics on the web. In Proceedings of the Posters of the IEEE Conference on Visualization (IEEE VIS 2018), Berlin, Germany, 21–26 October 2018; pp. 9–100. [Google Scholar]
- Fanini, B.; Demetrescu, E.; Bucciero, A.; Chirivi, A.; Giuri, F.; Ferrari, I.; Delbarba, N. Building blocks for multi-dimensional WebXR inspection tools targeting cultural heritage. In Proceedings of the International Conference on Extended Reality, Lecce, Italy, 6–8 July 2022; Springer: Cham, Switzerland, 2022; pp. 373–390. [Google Scholar]
- Salazar, M.; Louka, M.N. CoEditAR: A Framework for Collaborative Interaction in WebXR-enabled Spatial Computing. In Proceedings of the 28th International ACM Conference on 3D Web Technology, San Sebastian, Spain, 9–11 October 2023; pp. 1–2. [Google Scholar]
- Fanini, B.; Ferdani, D.; Demetrescu, E.; Berto, S.; d’Annibale, E. ATON: An open-source framework for creating immersive, collaborative and liquid web-apps for cultural heritage. Appl. Sci. 2021, 11, 11062. [Google Scholar] [CrossRef]
- Chacon, S.; Straub, B. Pro Git; Apress: New York, NY, USA, 2014. [Google Scholar]
- Zandstra, M. Version Control with Subversion. In PHP Objects, Patterns, and Practice; Apress: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A Publishing Format for Reproducible Computational Workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; Loizides, F., Schmidt, B., Eds.; IOS Press: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar]
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress: Berkeley, CA, USA, 2019. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://tensorflow.org (accessed on 22 April 2024).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS-W, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Rosenblatt, M. Remarks on Some Nonparametric Estimates of a Density Function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Nielsen, F. Introduction to HPC with MPI for Data Science; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Freeman, L.; Freeman, S.; Michaelson, A. On human social intelligence. J. Soc. Biol. Syst. 1988, 11, 415–425. [Google Scholar] [CrossRef]
- Wei, D.; Jiang, Q.; Wei, Y.; Wang, S. A novel hierarchical clustering algorithm for gene sequences. BMC Bioinform. 2012, 13, 174. [Google Scholar] [CrossRef] [PubMed]
- Chapman, P.; Clinton, J.; Kerber, R.; Khabaza, T.; Reinartz, T.; Shearer, C.; Wirth, R. CRISP-DM 1.0: Step-by-Step Data Mining Guide: SPSS, USA. 2000. Available online: https://www.kde.cs.uni-kassel.de/lehre/ws2012-13/kdd/files/CRISPWP-0800.pdf (accessed on 23 April 2024).
- Martinez-Plumed, F.; Contreras-Ochando, L.; Ferri, C.; Hernandez-Orallo, J.; Kull, M.; Lachiche, N.; Ramirez-Quintana, M.J.; Flach, P. CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories. IEEE Trans. Knowl. Data Eng. 2021, 33, 3048–3061. [Google Scholar] [CrossRef]
- Bucchiarone, A.; Dragoni, N.; Dustdar, S.; Lago, P.; Mazzara, M.; Rivera, V.; Sadovykh, A. Microservices. In Science and Engineering; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Rodríguez, C.; Baez, M.; Daniel, F.; Casati, F.; Trabucco, J.C.; Canali, L.; Percannella, G. REST APIs: A large-scale analysis of compliance with principles and best practices. In Proceedings of the Web Engineering: 16th International Conference, ICWE 2016, Lugano, Switzerland, 6–9 June 2016; Proceedings 16. Springer: Cham, Switzerland, 2016; pp. 21–39. [Google Scholar]
- Subramanian, H.; Raj, P. Hands-On RESTful API Design Patterns and Best Practices: Design, Develop, and Deploy Highly Adaptable, Scalable, and Secure RESTful Web APIs; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Doglio, F.; Doglio; Corrigan. REST API Development with Node. js; Springer: Berkeley, CA, USA, 2018; Volume 331. [Google Scholar]
- Tzavaras, A.; Mainas, N.; Petrakis, E.G. OpenAPI framework for the Web of Things. Internet Things 2023, 21, 100675. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Bar-Joseph, Z.; Gifford, D.K.; Jaakkola, T.S. Fast optimal leaf ordering for hierarchical clustering. Bioinformatics 2001, 17, S22–S29. [Google Scholar] [CrossRef]
- Lance, G.N.; Williams, W.T. A General Theory of Classificatory Sorting Strategies: 1. Hierarchical Systems. Comput. J. 1967, 9, 373–380. [Google Scholar] [CrossRef]
- Tandel, S.; Jamadar, A. Impact of progressive web apps on web app development. Int. J. Innov. Res. Sci. Eng. Technol. 2018, 7, 9439–9444. [Google Scholar]
- Stein, C.; Limper, M.; Kuijper, A. Spatial data structures for accelerated 3D visibility computation to enable large model visualization on the web. In Proceedings of the 19th International ACM Conference on 3D Web Technologies, Vancouver, BC, Canada, 8–10 August 2014; pp. 53–61. [Google Scholar]
- Upenik, E.; Ebrahimi, T. A simple method to obtain visual attention data in head mounted virtual reality. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 73–78. [Google Scholar]
- Boletsis, C. The new era of virtual reality locomotion: A systematic literature review of techniques and a proposed typology. Multimodal Technol. Interact. 2017, 1, 24. [Google Scholar] [CrossRef]
- Scott, D.W. Multivariate Density Estimation; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar] [CrossRef]
- Ceccarelli, S.; Cesta, A.; Cortellessa, G.; De Benedictis, R.; Fracasso, F.; Leopardi, L.; Ligios, L.; Lombardi, E.; Malatesta, S.G.; Oddi, A.; et al. Artificial Intelligence Algorithms for the Analysis of User Experience in Palazzo Braschi Museum. In Proceedings of the GCH 2023—Eurographics Workshop on Graphics and Cultural Heritage, Lecce, Italy, 4–6 September 2023. [Google Scholar]
- Fanini, B.; Cinque, L. Encoding immersive sessions for online, interactive VR analytics. Virtual Real. 2020, 24, 423–438. [Google Scholar] [CrossRef]
- Fanini, B.; Cinque, L. Encoding, exchange and manipulation of captured Immersive VR sessions for learning environments: The PRISMIN framework. Appl. Sci. 2020, 10, 2026. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fanini, B.; Gosti, G. A New Generation of Collaborative Immersive Analytics on the Web: Open-Source Services to Capture, Process and Inspect Users’ Sessions in 3D Environments. Future Internet 2024, 16, 147. https://doi.org/10.3390/fi16050147
Fanini B, Gosti G. A New Generation of Collaborative Immersive Analytics on the Web: Open-Source Services to Capture, Process and Inspect Users’ Sessions in 3D Environments. Future Internet. 2024; 16(5):147. https://doi.org/10.3390/fi16050147
Chicago/Turabian StyleFanini, Bruno, and Giorgio Gosti. 2024. "A New Generation of Collaborative Immersive Analytics on the Web: Open-Source Services to Capture, Process and Inspect Users’ Sessions in 3D Environments" Future Internet 16, no. 5: 147. https://doi.org/10.3390/fi16050147