In this paper we propose the adoption of a hierarchy multitier scheme for the deployment and organization of governmental service providers’ privacy policies in e-Government environments. Based on the concept of embodying privacy policy and privacy preference, towards advancing and simplifying the provision of electronic services, presented in [
8,
9], it was evident that due to the size and total length of the privacy policy documents, especially for composite or multi-entry electronic services, they could not be easily administered and updated. Through the exploitation of existing governmental hierarchies the proposed multitier approach enables the formulation of light-weight documents. Such adoption will facilitate the consistent deployment and re-configuration of e-Government services while preserving compliance with the underlying legal and regulatory framework.
3.1. Hierarching Privacy Policies
In e-Government environments, data is structured at different abstraction levels, and service providers have different data needs and processing requests when requested to provide an electronic service. These needs and requests may deviate from each other but they are also bound to the restrictions opposed by corresponding ministerial departments and subsequently by legal requirements. Thus, from a modeling prospective, a privacy policy document, for a given electronic service, adheres and complies to the following hierarchy, where each arrow indicates a further level of generalization; Electronic Service → Service Provider → Ministerial Department → Central Government. A similar generalization level for e-Health environments has also been proposed at [
10].
To make the above statement more formal, let us denote
PCG as the privacy policy elements of the central government,
PMD as the privacy policy elements of ministerial department,
PSP as the privacy policy elements of the service provider, and
PES as the privacy policy elements of electronic service. Therefore,
PES can be regarded as proper subset of
PSP,
PSP as a proper subset of
PMD, and
PMD as a proper subset of
PCG, as depicted in Equation (1), below:
The expected inclusion of the aforementioned sets would be that PES is a subset of PSP, PSP a subset of PMD, and PMD a subset of PCG. However, as we move towards supersets, the specification of elements regards different levels of abstraction. For example, PCG will contain an element regarding Social Security Number (SSN); based on the underlying legal and regulatory framework SSN falls under the category of personal identifiers (PId) and, consequently, should be treated as confidential data. Thus, PCG states that SSN should be treated as confidential data during processing and storage. At the next level of abstraction, PMD assents to the classification of SSN as PId and only specifies that, for the purposes of the specific ministerial department, it can be retained for a specific amount of time (days). Moving along to lower superset levels, PSP specifies if it will be processed and how by the specific service provider and, finally, PES specifies only the purposes for collecting this PId. Depending on the e-Government environment and the structure of the central government (unitary, federal, or con-federal) we consider, the number of sets and subsets could vary; however, the organization and the representation is always viable.
3.2. Privacy Policies Formation
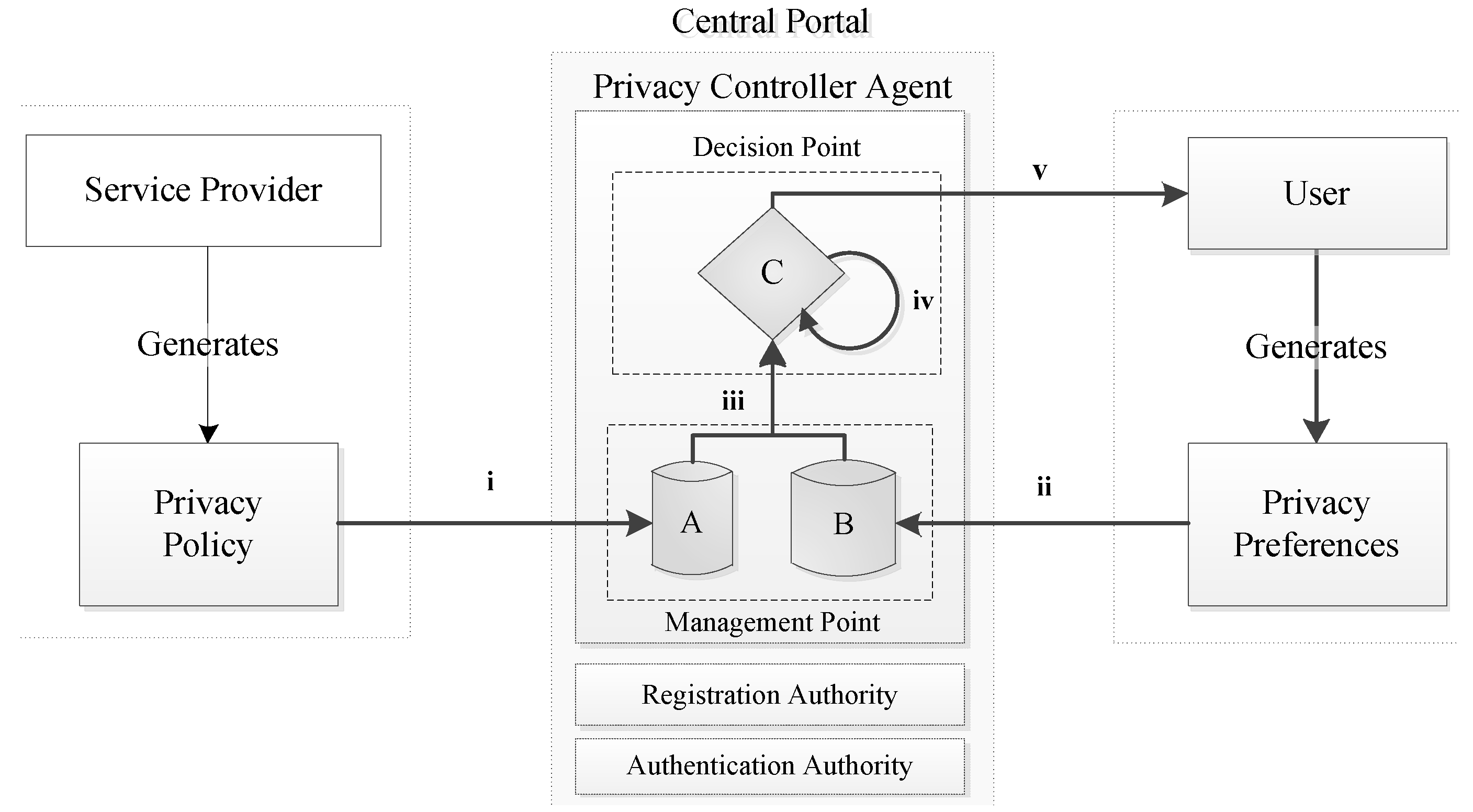
Based on the architecture of the Privacy Controller Agent (PCA), presented at
Section 2 above, when the PCA receives a user’s request for an electronic service, two documents must be retrieved and compared against each other; (i) the user’s privacy preferences; and (ii) the electronic service privacy policy. The first is submitted by user and stored at the preferences repository and the second is submitted by the service provider, specifically for each electronic service, and is stored at the policy repository. Taking into account the hierarchy scheme discussed in
Section 3.1 and the identified proper subsets, the central government issues a generic privacy policy document that describes, in a broad level, how specific data types can be accessed, processed, and stored, based on the underlying legal and regulatory framework at level
(1). As we move down on the hierarchy, privacy policy documents are issued from specific ministerial departments, level
(2), and further down from specific electronic services, level
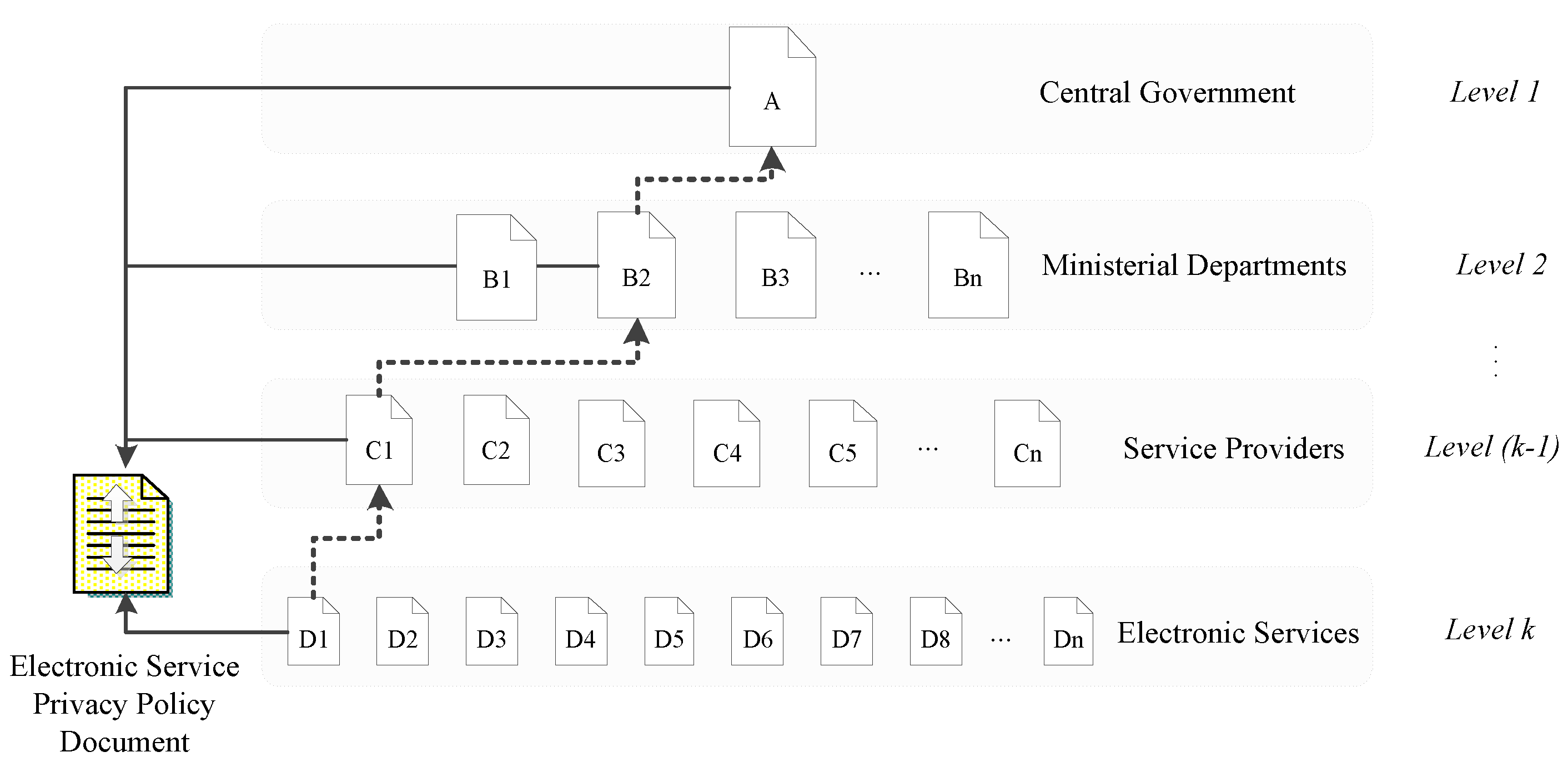
(k). At each one of these levels, an acknowledgement of previously-made acceptations, through reference, is included along to a more explicit expression of data access, process, storage, and retention period, if required. A schematic representation of privacy policy documents creation is depicted in
Figure 2 below:
Figure 2.
Electronic Service Privacy Policy Formation.
Figure 2.
Electronic Service Privacy Policy Formation.
The number of references to previous levels may vary on each document depending on the provider of the electronic service and the structure of government. In every case, all documents should obligatorily contain a reference to the higher level (1) since it comprises a representation of the underlying legal and regulatory framework. To ensure a seamless transition of privacy requirements to lower levels we define the following mandatory rules which accompany the proposed approach.
Rule 1: Each one of the {Level(k), Level (k−1), ··· , Level 3, Level 2} privacy policy documents must comply to Level 1 document.
Privacy policy document compliance is defined as the absence of negation or generalization from the stipulations and clauses it imposes.
Rule 2: Each one of the {Level(k), Level (k−1), ··· , Level 3, Level 2} privacy policy documents must include direct or indirect reference to Level 1 document.
Rule 3: Each one of the {Level(k), Level (k−1), ··· , Level 3, Level 2} privacy policy documents can introduce new stipulations and clauses, provided that they contradict to the existing ones.
Rule 4: Each one of the {Level(k), Level (k−1), ··· , Level 3, Level 2} privacy policy documents can only particularize stipulations and clauses imposed by higher level documents.
Particularization of stipulations (S) and clauses (C) is valid only if the introduced stipulation (S’) or clause (C’) are subsets of S or C respectively.
3.3. Approach Evaluation
The deployment of the proposed approach promotes the interoperability of electronic services along to the compliance with underlying legal and regulatory framework. This can be regarded not only as a control but also as an enforce mechanism for any alterations that may occur. A newly-introduced legislative amendment does not normally propagate seamlessly into the corresponding e-Government services; each service provider has to perform the appropriate modifications which take time and effort to be completed efficiently. Regardless if such a change occurs, ministerial departments and service providers cannot deviate from upper level stipulations and clauses, ensuring an overall comprehensive compliance. Moreover, the produced policy documents have significantly reduced length compared to the traditional approach which improves their manageability. Finally, it could be deployed in federated environments where data protection and privacy requirements are imposed by multiple providers or in cross border electronic service delivery. Within EU, such federated environments could enable the pan-European e-Government services provision, as described in the Interoperable Delivery of Pan-European e-Government Services to Public Administrations, Business, and Citizens (IDABC) (Interoperable Delivery of European eGovernment Services to public Administrations, Businesses and Citizens) and the Interoperability Solutions for European Public Administrations (ISA) (Interoperability Solutions for European Public Administrations) Programs of the European Commission.
From a security perspective, privacy policy documents do not contain any restricted information on the service provider and they are meant to be publicly available. Thus, the preservation of their integrity can be ensured by central portals’ underlying public key infrastructure through digital signatures. An important issue that must be addressed during deployment of the proposed approach is the XML schema to be utilized, as well as the creation and administration of the XML documents that will support the hierarchy scheme. Selecting the appropriate schema can be a complicated task. Existing schemas have not been designed taking into consideration specific needs and requirements of e-government environments. Thus, several aspects have been left uncovered and post-design modifications may be necessary. The proposal of a new schema oriented to e-government environments seems to be a promising path. Yet, the deployment of newly proposed schemas introduces the challenges of compatibility, up keeping, evaluating and updating procedures. In addition to that, depending on the environment, additional data interchange formats could also be explored, especially since XML is regarded to have significant consequences on data transmission rates and performance compared to JSON [
11].
One drawback of the approach is the workload and computational cost introduced to the central portal since for every electronic service request, the PCA is obliged to perform a root back retrieval of all referenced policy documents. Similarly to X.509-based PKIs as discussed in [
12,
13,
14,
15,
16], which are generally hierarchical and centralized, it can be resolved if actual policy documents are retained at the PCA for certain time periods, based on service request. In the event of a change in a higher level privacy policy document, PCA will be informed to rescind all related documents. Similarly, in the event of a central government organizational restructure, the PCA will also have to retract all affected documents. However, this would also be the case is the non-hierarchical approach presented in [
8].








{kind=link}
{kind=link}
{kind=link}