Identifying Economic Growth Convergence Clubs and Their Influencing Factors in China


Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
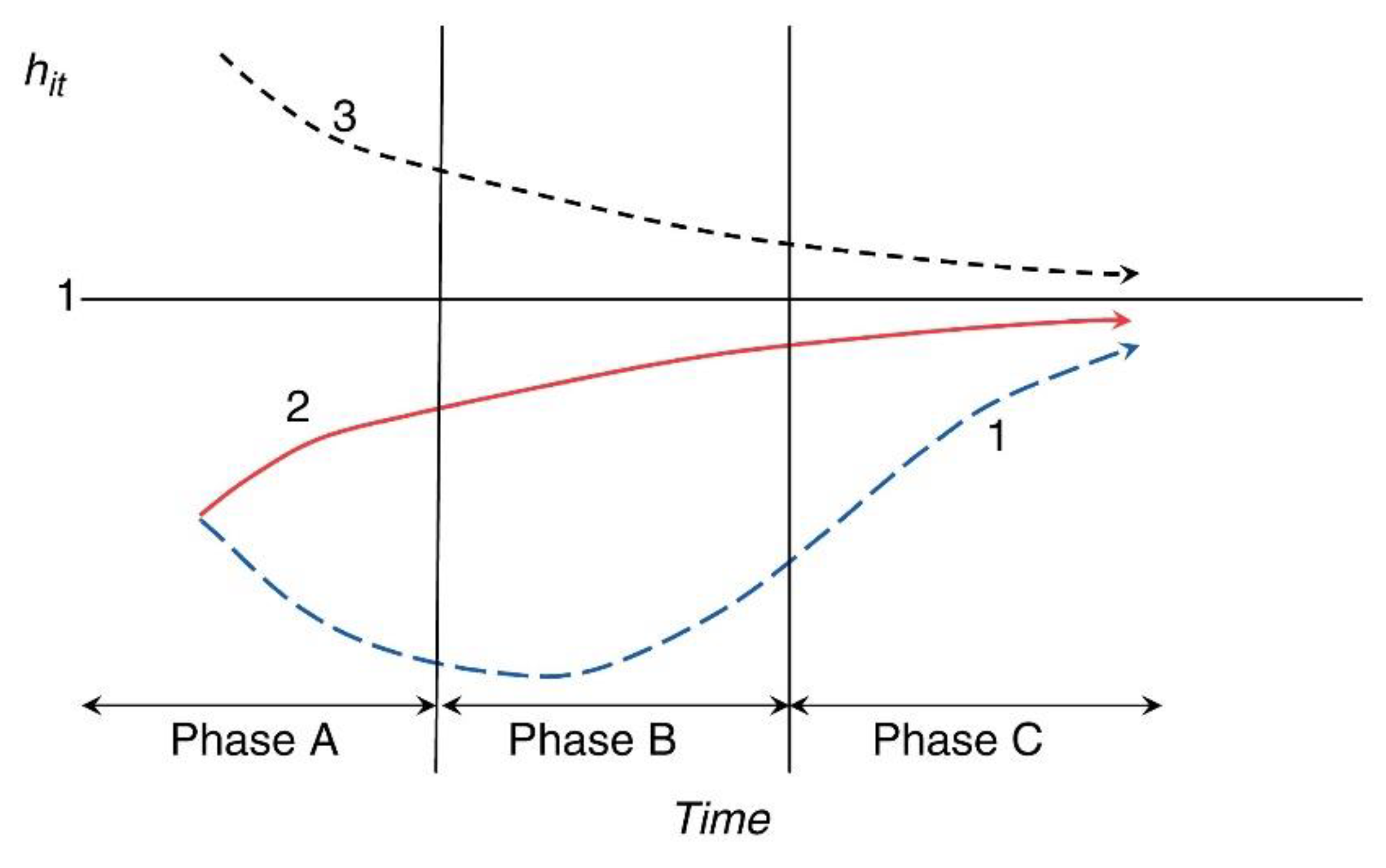
3.1. Log t Convergence Test
3.2. Dynamic Spatial Ordered Probit Regression Model
3.3. Sample Data and Preliminary Processing
4. Results
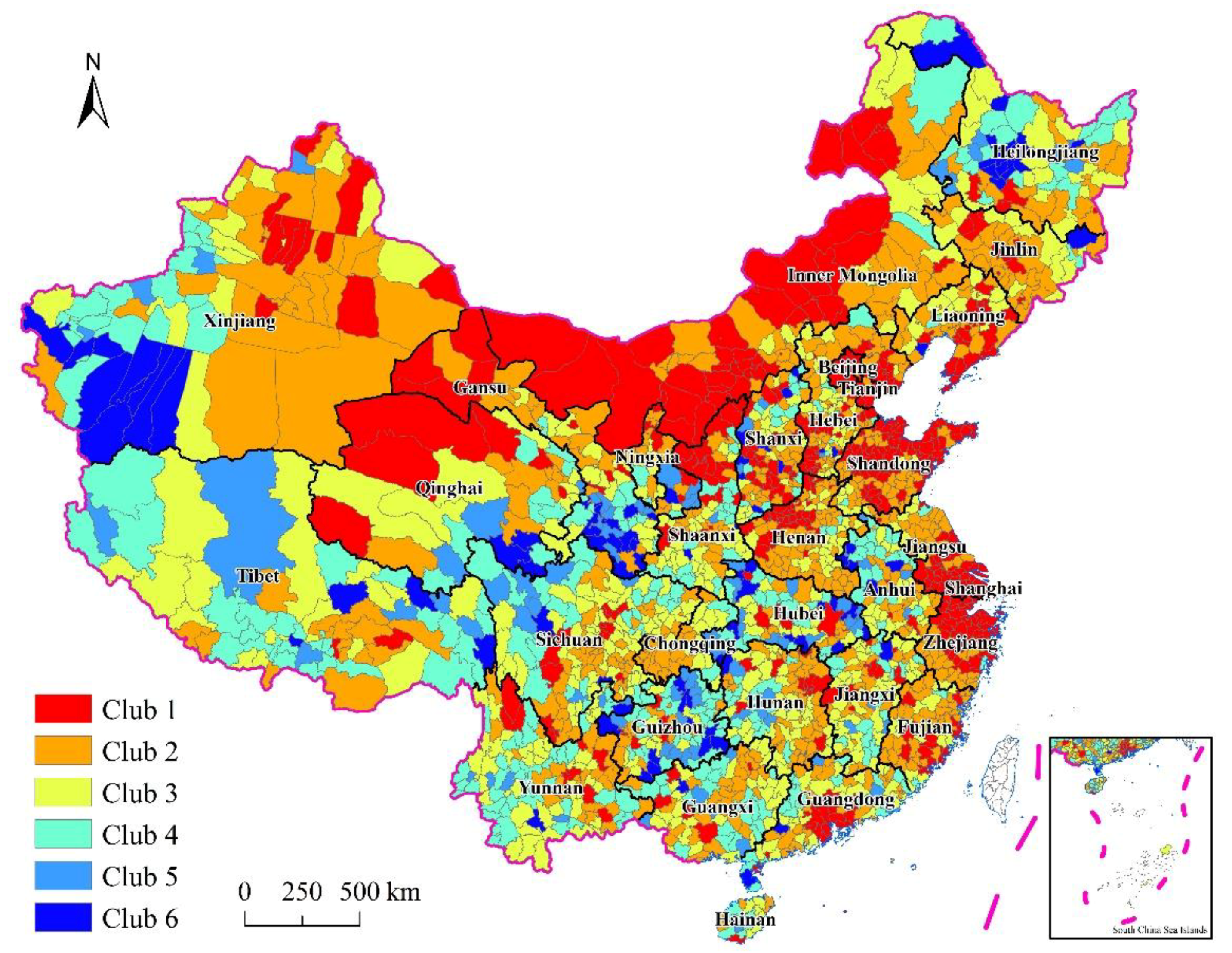
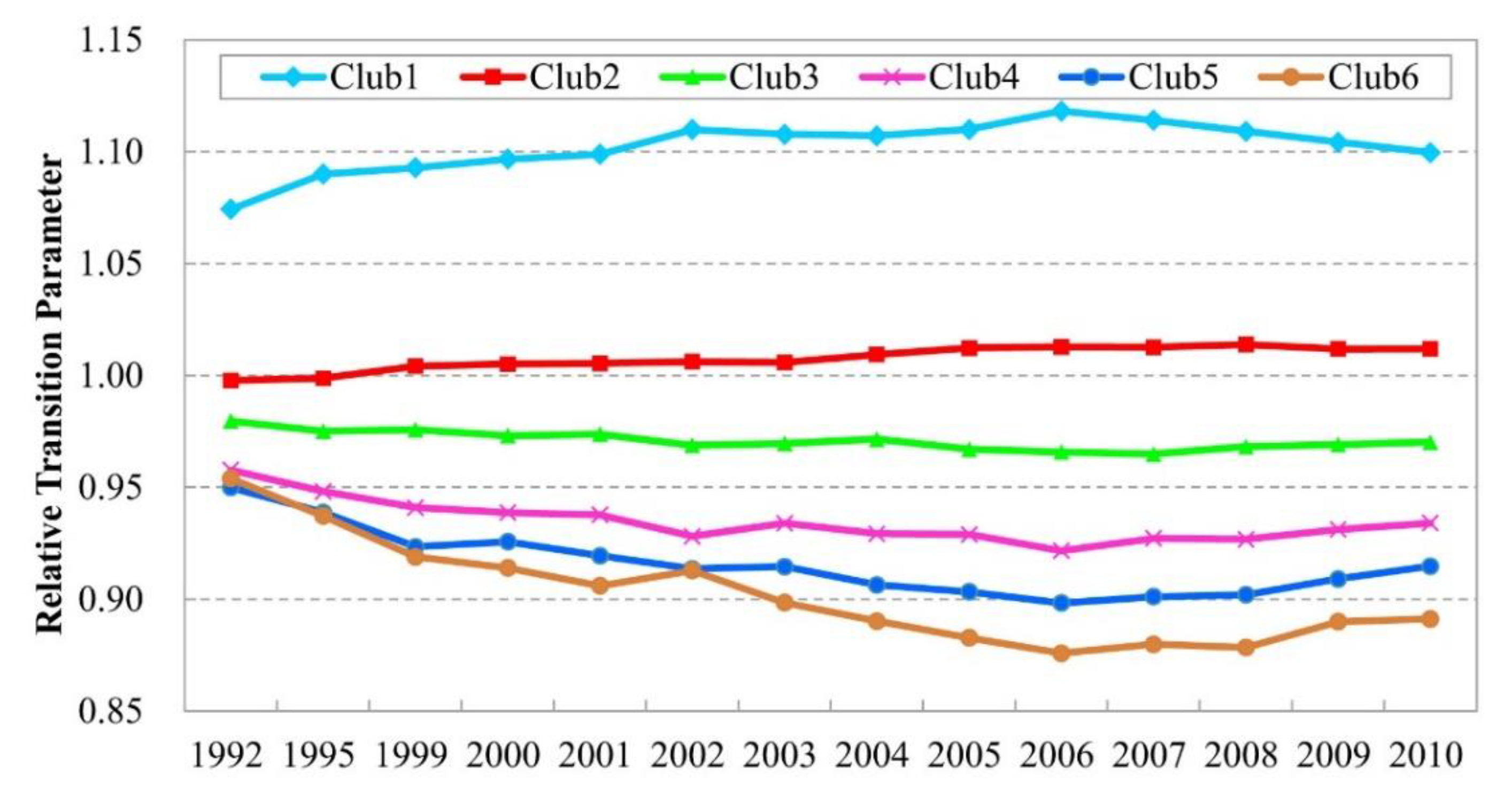
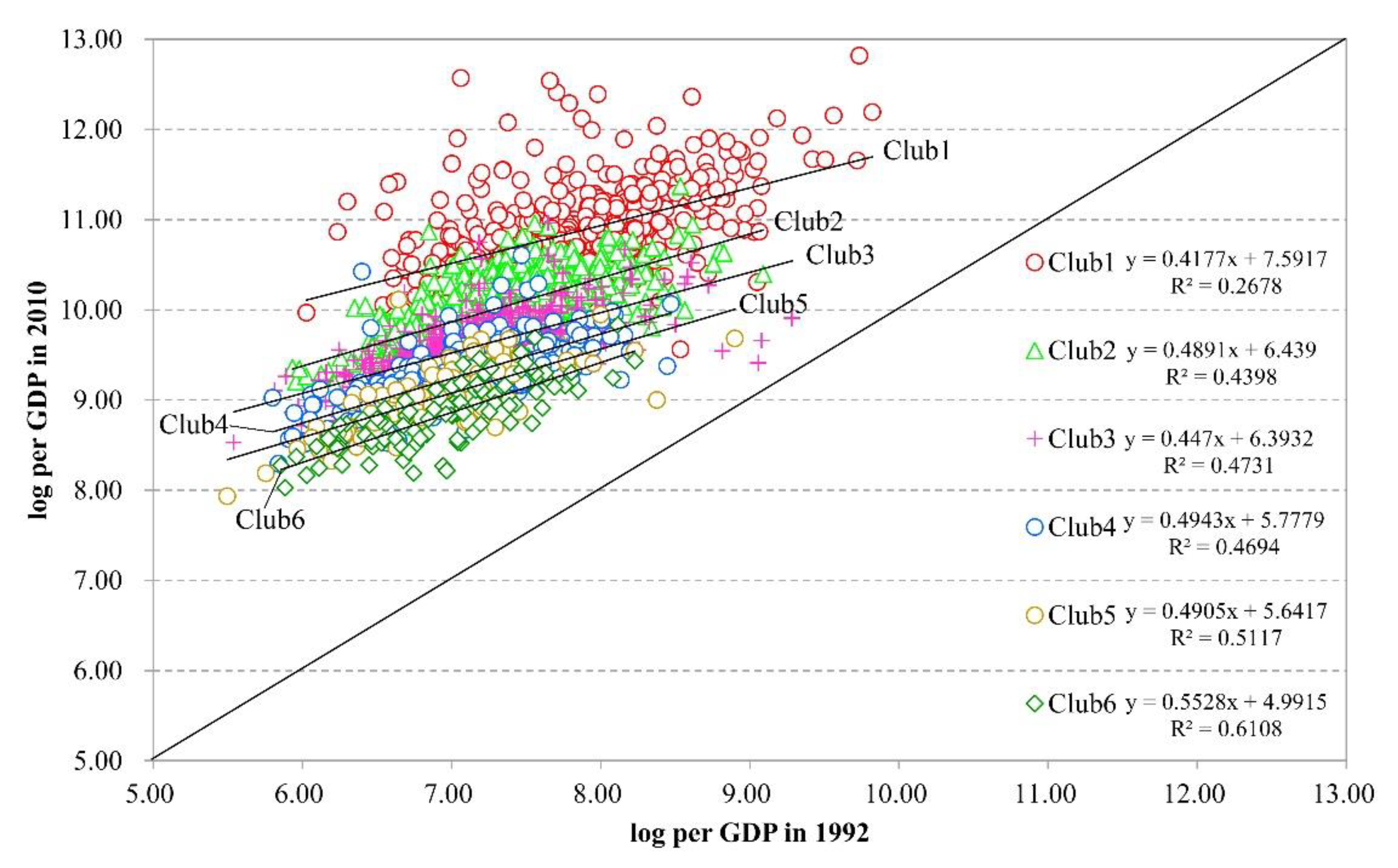
4.1 Convergence Club Identification
4.2. Analysis of Influencing Factors of Convergence Clubs
5. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Solow, R.M. A contribution to the theory of economic growth. Q. J. Econ. 1956, 70, 65–94. [Google Scholar] [CrossRef]
- Phillips, P.C.B.; Sul, D. Economic transition and growth. J. Appl. Econom. 2009, 24, 1153–1185. [Google Scholar] [CrossRef]
- Barro, R.J.; Sala-i-Martin, X. Convergence. J. Political Econ. 1992, 100, 223–251. [Google Scholar] [CrossRef]
- Barro, R.J.; Sala-i-Martin, X. Convergence across states and regions. Brook. Pap. Econ. Act. 1991, 107–158. [Google Scholar] [CrossRef]
- Mankiw, N.G.; Romer, D.; Weil, D.N. A contribution to the empirics of economic growth. Q. J. Econ. 1992, 107, 407–437. [Google Scholar] [CrossRef]
- Phillips, P.C.B.; Sul, D. Transition modeling and econometric convergence tests. Econometrica 2007, 75, 1771–1855. [Google Scholar] [CrossRef]
- Galor, O. Convergence? Inferences from theoretical models. Econ. J. 1996, 106, 1056–1069. [Google Scholar] [CrossRef]
- Alexiadis, S.; Tomkins, J. Convergence clubs in the regions of Greece. Appl. Econ. Lett. 2004, 11, 387–391. [Google Scholar] [CrossRef]
- Ben-David, D. Convergence clubs and subsistence economies. J. Dev. Econ. 1998, 55, 155–171. [Google Scholar] [CrossRef]
- Berthelemy, J.C.; Varoudakis, A. Economic growth, convergence clubs, and the role of financial development. Oxf. Econ. Pap. New Ser. 1996, 48, 300–328. [Google Scholar] [CrossRef]
- Chatterji, M.; Dewhurst, J.H.L. Convergence clubs and relative economic performance in Great Britain: 1977–1991. Reg. Stud. 1996, 30, 31–39. [Google Scholar] [CrossRef]
- Bartkowska, M.; Riedl, A. Regional convergence clubs in Europe: Identification and conditioning factors. Econ. Model. 2012, 29, 22–31. [Google Scholar] [CrossRef]
- Fischer, M.M.; Stirbock, C. Pan-European regional income growth and club-convergence. Ann. Reg. Sci. 2006, 40, 693–721. [Google Scholar] [CrossRef]
- Herrerias, M.J.; Ordonez, J. New evidence on the role of regional clusters and convergence in China (1952–2008). China Econ. Rev. 2012, 23, 1120–1133. [Google Scholar] [CrossRef]
- Higgins, M.J.; Levy, D.; Young, A.T. Growth and convergence across the United States: Evidence from county-level data. Rev. Econ. Stat. 2006, 88, 671–681. [Google Scholar] [CrossRef]
- Young, A.T.; Higgins, M.J.; Levy, D. Sigma convergence versus beta convergence: Evidence from US county-level data. J. Money Credit Bank. 2008, 40, 1083–1093. [Google Scholar] [CrossRef]
- Durlauf, S.N.; Johnson, P.A. Multiple regimes and cross-country growth behaviour. J. Appl. Econom. 1995, 10, 365–384. [Google Scholar] [CrossRef]
- Krugman, P. Geography and Trade; The MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Krugman, P. The role of geography in development. Int. Reg. Sci. Rev. 1999, 22, 142–161. [Google Scholar] [CrossRef]
- Yao, S.J.; Zhang, Z.Y. On regional inequality and diverging clubs: A case study of contemporary China. J. Comp. Econ. 2001, 29, 466–484. [Google Scholar] [CrossRef]
- Zhang, Z.Y.; Liu, A.Y.; Yao, S.J. Convergence of China’s regional incomes 1952–1997. China Econ. Rev. 2001, 12, 243–258. [Google Scholar] [CrossRef]
- Hao, R. Opening up, market reform, and convergence clubs in China. Asian Econ. J. 2008, 22, 133–160. [Google Scholar]
- Pan, W.Q. The economic disparity between different regions of China and its reduction: An analysis from the geographical perspective. Soc. Sci. China 2010, 1, 72–84 and 222–223. (In Chinese) [Google Scholar]
- Liu, X.M.; Wei, Y.Q.; Li, G.P. Convergence or Divergence? Debate on China’s Regional Development. Econ. Res. J. 2004, 7, 70–81. (In Chinese) [Google Scholar]
- Anselin, L. Local indicators of spatial association: LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Corrado, L.; Martin, R.; Weeks, M. Identifying and interpreting regional convergence clusters across Europe. Econ. J. 2005, 115, C133–C160. [Google Scholar] [CrossRef]
- Ghosh, M.; Ghoshray, A.; Malki, I. Regional divergence and club convergence in India. Econ. Model. 2013, 30, 733–742. [Google Scholar] [CrossRef]
- Apergis, N.; Christou, C.; Miller, S. Convergence patterns in financial development: Evidence from club convergence. Empir. Econ. 2012, 43, 1011–1040. [Google Scholar] [CrossRef]
- Ma, H.Y.; Oxley, L. The emergence and evolution of regional convergence clusters in China’s energy markets. Energy Econ. 2012, 34, 82–94. [Google Scholar] [CrossRef]
- Von Lyncker, K.; Thoennessen, R. Regional club convergence in the EU: Evidence from a panel data analysis. Empir. Econ. 2017, 52, 525–553. [Google Scholar] [CrossRef]
- Cliff, A.; Ord, J.K. Testing for spatial autocorrelation among regression residuals. Geogr. Anal. 1972, 4, 267–284. [Google Scholar] [CrossRef]
- Elhorst, J.P. Specification and estimation of spatial panel data models. Int. Reg. Sci. Rev. 2003, 26, 244–268. [Google Scholar] [CrossRef]
- Anselin, L. Issues in Spatial Probit Models. In Proceedings of the Workshop on Qualitative Dependent Variable Estimation and Spatial Effects, College of ACES, University of Illinois, Champaign, IL, USA, 20 April 2001. [Google Scholar]
- McMillen, D.P. Spatial Effects in Probit Models: A Monte Carlo Investigation. In New Directions in Spatial Econometrics; Anselin, L., Florax, R., Eds.; Springer: Heidelberg, Germany, 1995. [Google Scholar]
- LeSage, J.P. Bayesian estimation of limited dependent variable spatial autoregressive models. Geogr. Anal. 2000, 32, 19–35. [Google Scholar] [CrossRef]
- Smith, T.E.; LeSage, J.P. A bayesian probit model with spatial dependencies. In Advances in Econometrics Volume 18: Spatial and Spatiotemporal Econometric; Pace, R.K., LeSage, J.P., Eds.; Elsevier: Oxford, UK, 2004. [Google Scholar]
- Pinkse, J.; Slade, M.E. Contracting in space: An application of spatial statistics to discrete-choice models. J. Econom. 1998, 85, 125–154. [Google Scholar] [CrossRef]
- Wang, X.K.; Kockelman, K.M. Baysian Inference for Ordered Response Data with a Dynamic Spatial-Ordered Probit Model. J. Reg. Sci. 2009, 49, 877–913. [Google Scholar] [CrossRef]
- Wang, X.K. Capturing patterns of spatial and temporal autocorrelation in ordered response data: A case study of land use and air quality changes in Austin, Texas. Ph.D. Dissertation, Department of Civil, Architectural and Environmental Engineering, The University of Texas, Austin, TX, USA, 2007. [Google Scholar]
- Wang, X.K.; Kockelman, K.M. Application of the dynamic spatial ordered probit model: Patterns of land development change in Austin, Texas. Pap. Reg. Sci. 2009, 88, 345–365. [Google Scholar] [CrossRef]
- Girard, P.; Parent, E. Bayesian analysis of autocorrelated ordered categorical data for industrial quality monitoring. Technometrics 2001, 43, 180–191. [Google Scholar] [CrossRef]
- Cai, F. Haste makes waste: Policy options facing China after reaching the Lewis turning point. China World Econ. 2015, 23, 1–20. [Google Scholar] [CrossRef]
- Li, G.; Fang, C. Analyzing the multi-mechanism of regional inequality in China. Ann. Reg. Sci. 2014, 52, 155–182. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Y. Sources of China’s economic growth 1952–1999: Incorporating human capital accumulation. China Econ. Rev. 2003, 14, 32–52. [Google Scholar] [CrossRef]
- Fleisher, B.; Li, H.; Zhao, M.Q. Human capital, economic growth, and regional inequality in China. J. Dev. Econ. 2010, 92, 215–231. [Google Scholar] [CrossRef]
- Pritchett, L. Where has all the education gone? World Bank Econ. Rev. 2001, 15, 367–391. [Google Scholar] [CrossRef]
- Temple, J. A positive effect of human capital on growth. Econ. Lett. 1999, 65, 131–134. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition | Sources |
|---|---|---|
| GDP per capita (Yuan) | The value of all final goods and services produced divided by the resident population at year-end; the GDP data were deflated to the constant price of 1992 using a GDP deflator obtained from the National Bureau of Statistics of China. | China Regional Statistical Yearbook (2002–2011), China City Statistical Yearbook (1993–2011), China Statistical Yearbook (1993–2011). |
| Labor participation rate (%) | The proportion of people who are either employed or are actively looking for work in the total population. | Social and Economic Statistical Yearbook of China’s County and City (2000–2011), China City Statistical Yearbook (1993–2011). |
| Investment in fixed assets per capita (Yuan) | The social fixed asset investment divided by the population; the investment data were deflated to the constant price of 1992 by price index for investment in fixed assets. | China Regional Statistical Yearbook (2002–2011), China City Statistical Yearbook (1993–2011), China Statistical Yearbook (1993–2011). |
| Enrollment of regular secondary schools (Students/10,000 population) | Enrollment of regular secondary schools divided by 10,000 population. | Social and Economic Statistical Yearbook of China’s County and City (2000–2011), China City Statistical Yearbook (1993–2011). |
| Population density (Population/km2) | Population divided by total land area (area in square km). | China Regional Statistical Yearbook (2002–2011), China City Statistical Yearbook (1993–2011). |
| Proportion of the added value of the secondary industry in GDP (%) | GDP in the secondary industry as a share of total GDP, used to characterize industrialization levels. | China Regional Statistical Yearbook (2002–2011), China City Statistical Yearbook (1993–2011). |
| Variables | Sample | Mean | Std. Dev. | Min | Max | Obs. |
|---|---|---|---|---|---|---|
| GDP per capita (Yuan) | China | 11,247.0 | 14,850.0 | 16.3 | 368,704.0 | 2286 × 14 |
| Eastern China | 17,497.9 | 18,702.0 | 654.3 | 368,704.0 | 580 × 14 | |
| Central China | 9239.4 | 10,195.3 | 414.9 | 294,426.5 | 573 × 14 | |
| Western China | 8383.6 | 13,420.0 | 16.3 | 288,043.1 | 951 × 14 | |
| Northeast China | 12,620.5 | 14,324.5 | 545.6 | 197,383.7 | 182 × 14 | |
| Labor participation rate (%) | China | 51.0 | 12.0 | 10.5 | 76.0 | 2286 × 14 |
| Eastern China | 53.7 | 11.1 | 14.8 | 76.0 | 580 × 14 | |
| Central China | 52.1 | 11.5 | 13.6 | 68.0 | 573 × 14 | |
| Western China | 50.3 | 11.7 | 11.2 | 65.0 | 951 × 14 | |
| Northeast China | 46.2 | 15.3 | 10.5 | 71.0 | 182 × 14 | |
| Investment in fixed assets per capita (Yuan) | China | 5285.0 | 10,805.0 | 1.0 | 399,902.0 | 2286 × 14 |
| Eastern China | 7300.0 | 10,884.0 | 1.0 | 162,755.0 | 580 × 14 | |
| Central China | 4319.3 | 7104.2 | 1.0 | 111,809.8 | 573 × 14 | |
| Western China | 4591.4 | 12,535.2 | 1.0 | 399,902.0 | 951 × 14 | |
| Northeast China | 5531.5 | 9514.7 | 6.1 | 94,587.2 | 182 × 14 | |
| Enrollment of regular secondary schools (Students/10,000 population) | China | 589.0 | 204.0 | 1.0 | 9041.7 | 2286 × 14 |
| Eastern China | 646.0 | 170.0 | 1.0 | 4198.0 | 580 × 14 | |
| Central China | 645.1 | 176.7 | 81.6 | 8751.0 | 573 × 14 | |
| Western China | 526.1 | 215.5 | 3.9 | 9041.7 | 951 × 14 | |
| Northeast China | 555.2 | 220.9 | 132.4 | 4139.0 | 182 × 14 | |
| Population density (Population/km2) | China | 377.0 | 539.0 | 0.3 | 14,052.0 | 2286 × 14 |
| Eastern China | 605.0 | 712.0 | 1.0 | 14,052.0 | 580 × 14 | |
| Central China | 487.2 | 550.4 | 5.9 | 5903.0 | 573 × 14 | |
| Western China | 190.7 | 283.0 | 0.3 | 4315.7 | 951 × 14 | |
| Northeast China | 283.4 | 519.6 | 1.6 | 10,172.5 | 182 × 14 | |
| Proportion of the added value of the secondary industry in GDP (%) | China | 38.0 | 17.0 | 1.2 | 92.0 | 2286 × 14 |
| Eastern China | 44.6 | 13.9 | 5.3 | 92.0 | 580 × 14 | |
| Central China | 41.3 | 15.0 | 3.0 | 90.0 | 573 × 14 | |
| Western China | 31.8 | 17.5 | 1.2 | 89.0 | 951 × 14 | |
| Northeast China | 36.4 | 16.9 | 2.5 | 91.0 | 182 × 14 |
| Initial Club | Tests of Club Merging | Final Club | GDP Per Capita (1992–2010) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Club | (SE of ) | (SE of ) | Club | (SE of ) | |||||
| Total sample [2286][M1] | −0.945 (0.014) | 11,247 | |||||||
| Club 1 [491][M2] | 0.259 (0.017) | Club 1 + 2 | Club 1 [491][M3] | 0.259 (0.017) | 16,647 | ||||
| −0.564 * (0.015) | |||||||||
| Club 2 [718][M4] | 0.555 (0.024) | Club 2 + 3 | Club 2 [718][M5] | 0.555 (0.024) | 7187 | ||||
| −0.506 * (0.023) | |||||||||
| Club 3 [540][M6] | 0.840 (0.021) | Club 3 + 4 | Club 3 [540][M7] | 0.840 (0.021) | 5167 | ||||
| −0.468 * (0.045) | |||||||||
| Club 4 [347][M8] | 1.077 (0.089) | Club 4 + 5 | Club 4 [347][M9] | 1.077 (0.089) | 3752 | ||||
| −0.774 * (0.071) | |||||||||
| Club 5 [96][M10] | 1.108 (0.054) | Club 5 + 6 | Club 5 [96][M11] | 1.108 (0.054) | 3165 | ||||
| −0.587 * (0.039) | |||||||||
| Club 6 [94][M12] | 0.698 (0.011) | Club 6 [94][M13] | 0.698 (0.011) | 2779 | |||||
| Coefficient | Std. Dev. | Probability | |
|---|---|---|---|
| LABOR | 0.0505 | 0.0022 | 0.0201 |
| LNFIX | −0.0392 | 0.0137 | 0.0125 |
| LNHUM | 0.0795 | 0.0010 | 0.0055 |
| LNDEN | −0.6624 | 0.1546 | 0.0021 |
| IND | −0.8289 | 0.2357 | 0.0035 |
| λ | 0.0293 | 0.0248 | 0.0025 |
| ρ | 0.9161 | 0.0527 | 0.0034 |
| σ2 | 221.7365 | 15.2944 | 0.0011 |
| γ1 | −0.1564 | 0.9840 | 0.0016 |
| γ2 | 1.1803 | 0.0485 | 0.0045 |
| γ3 | 13.6192 | 0.6545 | 0.0034 |
| γ4 | 26.7520 | 0.9379 | 0.0010 |
| Observations | 2286 | ||
| Eastern China | Central China | Western China | Northeast China | |||||
|---|---|---|---|---|---|---|---|---|
| Coefficient | Std. Dev. | Coefficient | Std. Dev. | Coefficient | Std. Dev. | Coefficient | Std. Dev. | |
| LABOR | 0.6606 | 1.2738 | −0.0034 | 1.1287 | −0.3982 | 0.6255 | −0.0551 | 1.1210 |
| LNFIX | −0.0352 | 0.0477 | −0.0231 | 0.0560 | −0.0355 | 0.0419 | −0.0631 | 0.0906 |
| LNHUM | −0.3431 | 0.1693 | 0.0762 | 0.1672 | −0.0255 | 0.1109 | 0.6106 | 0.1994 |
| LNDEN | −0.5551 | 0.1852 | −0.9314 | 0.2160 | −0.0501 | 0.0980 | −1.1129 | 0.2724 |
| IND | −1.0335 | 1.2612 | −0.5554 | 1.0031 | −0.2256 | 0.3911 | −0.1217 | 1.1535 |
| λ | 0.0528 | 0.0103 | 0.0750 | 0.0075 | 0.0137 | 0.0117 | 0.0432 | 0.0160 |
| ρ | 0.9762 | 0.0089 | 0.8582 | 0.0153 | 0.9558 | 0.0062 | 0.8742 | 0.0137 |
| σ2 | 144.2273 | 11.9852 | 281.3193 | 22.4468 | 216.4823 | 20.1905 | 244.8743 | 32.225 |
| γ1 | −0.9746 | 0.4226 | −0.4771 | 1.0611 | −0.9111 | 0.6498 | −0.5813 | 1.4733 |
| γ2 | 7.3778 | 0.3920 | 3.8012 | 0.5613 | 2.5079 | 0.4307 | 1.2106 | 0.8541 |
| γ3 | 20.5392 | 0.6513 | 10.7966 | 0.6086 | 8.4065 | 0.2703 | 14.7339 | 1.2308 |
| γ4 | 32.8099 | 0.8938 | 23.7232 | 1.2414 | 23.8387 | 0.5904 | 26.6341 | 2.2292 |
| Observations | 580 | 573 | 951 | 182 | ||||
| Probability Change of Marginal Effect at the National Scale (10−2) | |||||
| Club 1 | Club 2 | Club 3 | Club 4 | Club 5 + 6 | |
| LABOR | −0.0329 | 0.0492 | 0.2751 | 0.0082 | −0.0083 |
| LNFIX | 0.0072 | 0.0043 | −0.0029 | −0.0042 | −0.0044 |
| LNHUM | 0.0176 | −0.0072 | −0.0114 | −0.0028 | 0.0037 |
| LNDEN | 0.1180 | 0.0364 | −0.0411 | −0.0543 | −0.0594 |
| IND | 0.1406 | 0.0160 | −0.0453 | −0.0629 | −0.0489 |
| Probability Change of Marginal Effect for Eastern China (10−2) | |||||
| Club 1 | Club 2 | Club 3 | Club4 | Club 5 + 6 | |
| LABOR | −0.2380 | 0.0501 | 0.0816 | 0.0768 | 0.0306 |
| LNFIX | 0.0120 | −0.0001 | −0.0064 | −0.0038 | −0.0018 |
| LNHUM | 0.1166 | −0.0066 | −0.0562 | −0.0378 | −0.0165 |
| LNDEN | 0.1897 | −0.0137 | −0.0928 | −0.0568 | −0.0272 |
| IND | 0.3771 | −0.0723 | −0.1430 | −0.1130 | −0.0508 |
| Probability Change of Marginal Effect for Central China (10−2) | |||||
| Club 1 | Club 2 | Club 3 | Club 4 | Club 5 + 6 | |
| LABOR | 0.0048 | −0.0137 | 0.0111 | 0.0166 | −0.0187 |
| LNFIX | 0.0046 | 0.0027 | −0.0018 | −0.0016 | −0.0039 |
| LNHUM | −0.0188 | −0.0024 | −0.0014 | 0.0094 | 0.0131 |
| LNDEN | 0.2003 | 0.0954 | −0.0421 | −0.1040 | −0.1500 |
| IND | 0.1219 | 0.0636 | −0.0343 | −0.0755 | −0.0788 |
| Probability Change of Marginal Effect for Western China (10−2) | |||||
| Club 1 | Club2 | Club 3 | Club 4 | Club 5 + 6 | |
| LABOR | 0.0593 | 0.0778 | −0.0108 | −0.0634 | −0.0630 |
| LNFIX | 0.0053 | 0.0069 | −0.0012 | −0.0056 | −0.0054 |
| LNHUM | 0.0040 | 0.0037 | 0.0002 | −0.0036 | −0.0044 |
| LNDEN | 0.0075 | 0.0113 | −0.0031 | −0.0077 | −0.0081 |
| IND | 0.0318 | 0.0407 | −0.0010 | −0.0357 | −0.0358 |
| Probability Change of Marginal effect for Northeast China (10−2) | |||||
| Club 1 | Club 2 | Club 3 | Club 4 | Club 5 + 6 | |
| LABOR | 0.0198 | 0.0170 | −0.0105 | −0.0173 | −0.0091 |
| LNFIX | 0.0100 | 0.0100 | −0.0046 | −0.0066 | −0.0090 |
| LNHUM | −0.1116 | −0.0812 | 0.0397 | 0.0731 | 0.0811 |
| LNDEN | 0.2078 | 0.1416 | −0.0714 | −0.1360 | −0.1440 |
| IND | 0.0143 | 0.0101 | 0.0003 | −0.0073 | −0.0175 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Li, G.; Qin, W.; Qin, J.; Ma, H. Identifying Economic Growth Convergence Clubs and Their Influencing Factors in China. Sustainability 2018, 10, 2588. https://doi.org/10.3390/su10082588
Li F, Li G, Qin W, Qin J, Ma H. Identifying Economic Growth Convergence Clubs and Their Influencing Factors in China. Sustainability. 2018; 10(8):2588. https://doi.org/10.3390/su10082588
Chicago/Turabian StyleLi, Feng, Guangdong Li, Weishan Qin, Jing Qin, and Haitao Ma. 2018. "Identifying Economic Growth Convergence Clubs and Their Influencing Factors in China" Sustainability 10, no. 8: 2588. https://doi.org/10.3390/su10082588
APA StyleLi, F., Li, G., Qin, W., Qin, J., & Ma, H. (2018). Identifying Economic Growth Convergence Clubs and Their Influencing Factors in China. Sustainability, 10(8), 2588. https://doi.org/10.3390/su10082588