This section first provides a general background of prediction in education. Next, articles that specifically address and/or consider the generalizability of predictive models are discussed to justify the main contributions of the article.
2.1. Prediction in Education
In literature, there is an increasing interest in developing predictive models in education. These models can be useful to anticipate learners’ behaviors and/or outcomes so as to improve both engagement and performance. In order to develop those models, one of the important aspects is the variables used to predict, i.e., prediction features. Research has currently focused on the use of variables related to learners’ activity; interactions with videos, exercises, and the forum; and demographic variables. However, the latter usually achieve worse predictive power than the variables obtained from the tracking logs [
14]. Among the variables obtained from the logs, for example, Ruipérez-Valiente et al. [
15] predicted certificate earners by using variables related to activity (e.g., number of days the student accessed), interactions with videos (e.g., total time invested in videos), and interactions with exercises (e.g., grade in the assignments). They found that the grade in the assignments was the best predictor. Apart from those variables, Moreno-Marcos et al. [
16] indicated that there can be many possible prediction features and that new ones could be introduced (e.g., self-regulated learning variables, as used by Maldonado-Mahauad et al. [
17] to forecast success). Nevertheless, it is important to note that not all variables are always available. Alamri et al. [
18] experienced this issue when some courses did not have quizzes every week, so they could not gather information about how students performed in the quizzes. However, they achieved good accuracies with just the time spent in the platform and the number of accesses.
Another important aspect when developing the models is the variable to predict, i.e., prediction outcome. Some of the most typical cases are related to predicting dropout (e.g., References [
19,
20]) and student success (e.g., References [
21,
22,
23,
24]). For the first case, Aguiar et al. [
19] predicted dropouts in engineering students and found that variables related to performance, such as the Cumulative Grade Point Average (CPGA), were not enough to predict and that variables related to activity increased the predictive power. Regarding student success, which will be the focus of this paper, Polyzou and Karypis [
21], for example, considered several classifications to identify undergraduate students with poor performance at the University of Minnesota (i.e., failing students, students achieving grades considerably lower than their Grade Point Average, etc.). A particular case of student success is the prediction of test scores. For example, Okubo et al. [
22] used a Recurrent Neural Network (RNN) to predict the grade (between A–F) in a university course about information science and compared the predictive power during the 15 weeks of the course. Moreover, Ashenafi, Riccardi, and Ronchetti [
23] predicted exam scores in two programming courses based on the results of the tasks carried out throughout the course.
While it has been shown that there can be many possible prediction features and outcomes, the context where predictions are carried out is also important. Many researchers have analyzed prediction in MOOCs, which have a similar format to SPOCs, although their contexts and learner characteristics are different. SPOCs offer a similar structure of videos, exercises, etc. in a digital platform, and the content can be even the same as used in a MOOC (some MOOCs can also be offered for university students as a SPOC). However, SPOCs are intended for closed courses, and the fact that students are part of a closed group, which usually have face-to-face lessons, allows for their combination methodologies such as blended learning or flipped classroom. Particularly in MOOCs, a literature review [
16] showed that dropout is the most used outcome variable (e.g., Reference [
25]), followed by final or assignment scores (e.g., Reference [
26]) and certificate earners (e.g., Reference [
27]). The high interest of dropout prediction can be due to the high attrition rates that are typical for MOOCs [
28]. As an example, Xing and Du [
29] predicted dropouts in a project management MOOC. Their work showed strong predictive power from week 1, and it also highlighted the importance of providing intervention personalization using drop out probabilities to make impact on learners.
Despite the high number of contributions in MOOCs, fewer contributions focus on SPOCs. Yu [
30] used combined linear regression and deep neural network (DNN) to predict the final score of a computer science course. Moreover, Ruipérez-Valiente et al. [
31] predicted learning gains in a preparatory course for freshmen students. This article presents a similar kind of study, although the variables related to learners’ interactions and context (e.g., course duration and objective, pedagogy, etc.) are different. Finally, regarding state exams, Feng, Heffernan, and Koedinger [
32] developed a regression model to forecast grades in the exam based on interactions with an Intelligent Tutoring System (ITS). More recently, Fancsali et al. [
33] also predicted a math state exam from logs of their ITS (MATHia), such as solving time, knowledge components (KC) mastered, etc.
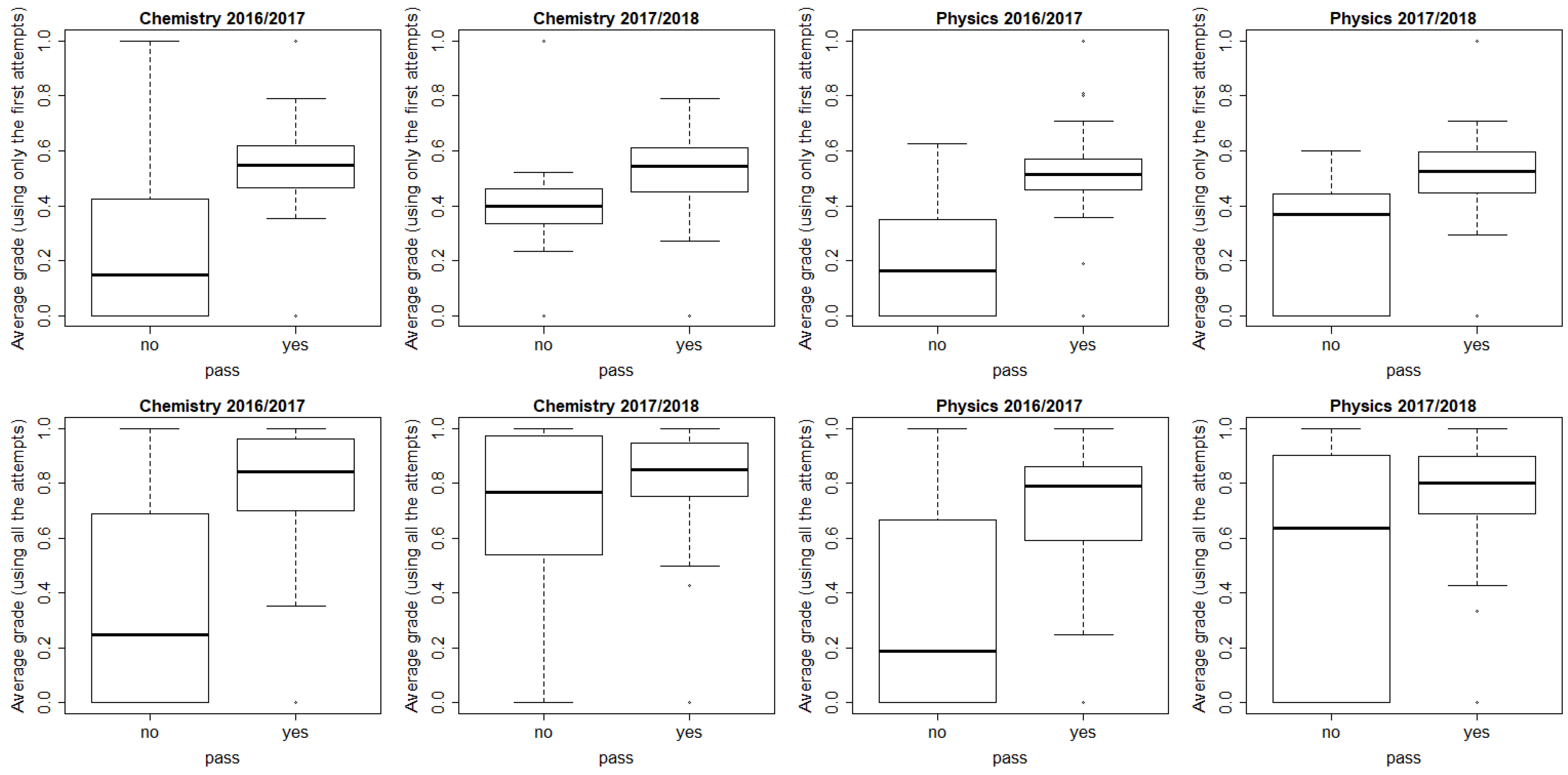
This paper presents a study that analyzes how admission test success can be predicted from learners’ interactions in a SPOC and which variables affect the prediction. One of the differences with previous research is the analysis of the best moment to predict in order to analyze at which moment in the course it is possible to anticipate students’ success. Moreover, this paper includes new variables (e.g., variables related to the run of consecutive actions, pauses in videos, and whether a student asks for the answer) and particularly the analysis of which variables have a higher effect on the predictive models (related to objective O1). In addition, the context of the SPOCs is different (e.g., sequence of activities, pedagogy, purpose of the SPOCs, etc.) from other contributions in the literature, which will be useful to get insight on the study of prediction. Nevertheless, the main contributions of this paper are related to the analysis of generalizability, which are justified in
Section 2.2.
2.2. Generalizability and Sustainability of Predictions
Many researchers have developed predictive models in many different contexts, as presented in
Section 2.1. The intention is that these models can be widely used or, at least, that they can be used in new courses in real time, as models are usually developed using past data. However, an important issue is how to ensure that models can be transferred to new courses with a high degree of reliability [
10]. One of the problems to make models transferrable and generalizable is that the context can be different across courses, which can cause a model to not be applicable to another course. Ocumpaugh, Baker, and Gowda [
34] already experienced this problem when they developed predictive models to detect affective states with different populations and found that detectors trained on one population could not generalize to other populations. Moreover, Olivé et al. [
35] developed predictive models with neural network, and although they achieved good accuracy in their models, they concluded that results can vary depending on how institutions and instructors use the Learning Management System (LMS). Merceron [
36] also recognized this issue and pointed out that models should be checked regularly to evaluate their validity, which can slow down the adoption of learning analytics.
While this problem can suppose an important challenge in the development of predictive models, very few studies have addressed how it is possible to transfer models to other courses. Some contributions have mentioned the sample size as a factor for the generalizability (e.g., Reference [
37]) and/or have acknowledged the generalizability as a limitation of the paper (e.g., Reference [
38]), but they do not analyze this issue in detail. Among those articles that have specifically analyzed this issue, Boyer and Veeramachaneni [
39] evaluated different methods to transfer models and found that models performed worse when transferred. Particularly, they found a drop of at least 0.1 in Area Under the Curve (AUC) when transferring from a previous edition of the MOOC. He et al. [
40], however, found that predictive models trained on a first edition performed well on a second edition of a MOOC. In addition, Gitinabard et al. [
41] analyzed the generalizability in four courses and found accurate results when transferring models, although they were better when the course was the same but in another offering. Furthermore, Hung et al. [
42] proposed three models to predict successful students and at-risk students and a third model to optimize the thresholds of the previous models. They used K–12 and high-school contexts and found important differences in the context as well as the best predictors.
Kidzinsk et al. [
43] also analyzed how to generalize models in other instances of the same course and other courses and concluded that there is a trade-off between specificity and generalizability. They also indicated that, in order to achieve high performance in a small variety of courses, it was best to use variables that depend on the context but that, at the same time, the use of these variables can affect generalizability. Therefore, in order to achieve generalizability, the predictive power should be compromised with course independent variables. In order to achieve generalizability across many courses, Kizilzec and Halawa [
44] trained predictive models with data from 20 MOOCs: they also mentioned that a large number of courses could improve the transferability. This resulted in a high predictive power (AUC over 0.92). While this positive result suggests that it is possible to make models generalizable, other studies (as seen previously) show the opposite (e.g., References [
34,
39]). In order to make predictions sustainable, some researchers (e.g., Reference [
45]) have proposed in situ models, i.e., models that use the available data in an ongoing course (e.g., using data from the first week in week 2), so that there are no differences in the course context. For example, Whitehill et al. [
46] concluded that post hoc models (those using past data of only one course) can overestimate accuracy whereas in situ models could achieve high performance. However, a limitation of those models is that they cannot be used when the dependent variable is only available at the end of the course, such as the grade of an admission test, which will be analyzed in this paper. They can be used, for example, to predict engagement [
45] as this can be measured each week.
Taking this into account, this paper will focus on transferring models to other courses and will analyze the generalizability of the findings. Particularly, this article will contribute with an analysis of the best predictors in different courses with the same target audience to check whether they differ or generalize (related to objective O2). This is also important because many articles just consider one course [
16], and although some articles, as shown before, have focused on transferring models to other courses, it is also relevant to analyze the generalizability of the predictors. A similar work in this line was made by Hung et al. [
42], who analyzed this issue in several educational stages, although this article will analyze different contexts within the same stage.
Moreover, this paper innovates with an analysis of how models can be transferred to other courses in different contexts (different cohort, different course, etc.) to delve into the generalizability issue (related to objective O3). Previous contributions, such as the article by Kidzinsk et al. [
43], only focused on a single context (e.g., transferring the model to another edition of the same course) or developed models joining data from several MOOCs [
44]. This work, however, analyzes generalizability with different contexts (same/different cohort, same/different course, etc.). One of the most similar works is the article by Gitinabard et al. [
41]. They had two courses with two offerings each, so they could evaluate transferability in another edition and in another course. They could not, however, analyze the differences of the cohorts (i.e., the effect of having another course with the same students). Their data were also very specific and was mainly about social information and activity on sessions, while this work focuses on edX data (particularly Edge edX data), which allows for the gathering of more interactions, and can be more easily extended to other courses given the popularity of the Open edX platform. Another difference, which is also an innovation of this work, is the discussion about the conditions to achieve generalizability of the models and what can be done to make the use of predictive models sustainable in the long term (related to objective O4). While previous articles have provided some results about generalizability, there is still a need to discuss when models may be generalized (which is why the analysis of different contexts is also relevant) in order to design future interventions that make impact learners. Our paper contributes to this discussion.

 ,
, 

{kind=link}