Sales Prediction by Integrating the Heat and Sentiments of Product Dimensions


1
School of Management, Hefei University of Technology, Hefei 230009, China
2
Key Laboratory of Process Optimization and Intelligent Decision Making of Ministry of Education, Hefei 230009, China
*
Authors to whom correspondence should be addressed.
Sustainability 2019, 11(3), 913; https://doi.org/10.3390/su11030913
Submission received: 20 January 2019
/
Revised: 2 February 2019
/
Accepted: 7 February 2019
/
Published: 11 February 2019
(This article belongs to the Special Issue Big Data Research for Social Sciences and Social Impact)
Abstract
:Online word-of-mouth (eWOM) disseminated on social media contains a considerable amount of important information that can predict sales. However, the accuracy of sales prediction models using big data on eWOM is still unsatisfactory. We argue that eWOM contains the heat and sentiments of product dimensions, which can improve the accuracy of prediction models based on multiattribute attitude theory. In this paper, we propose a dynamic topic analysis (DTA) framework to extract the heat and sentiments of product dimensions from big data on eWOM. Ultimately, we propose an autoregressive heat-sentiment (ARHS) model that integrates the heat and sentiments of dimensions into the benchmark predictive model to forecast daily sales. We conduct an empirical study of the movie industry and confirm that the ARHS model is better than other models in predicting movie box-office revenues. The robustness check with regard to predicting opening-week revenues based on a back-propagation neural network also suggests that the heat and sentiments of dimensions can improve the accuracy of sales predictions when the machine-learning method is used.
1. Introduction
Social media are forms of electronic communication (such as Facebook, WeChat, and IMDb.com) through which people create online communities to share information, ideas, personal messages, etc. Consumers increasingly use online word-of-mouth (eWOM) on social media for decision support before making purchases [1]. Therefore, social media marketing has recently appeared as an interdisciplinary and cross-functional concept that uses social media to achieve organizational goals by creating value for stakeholders [2]. Sales prediction is a foundation for social media marketing. Highly accurate and timely sales predictions can allow firms to reduce their profit losses and to improve their market performance [3]. Due to the superiority of big data on social media, sales predictions are being produced more than ever before to increase their accuracy and to enable them to support real-time marketing strategies for online retailers and enterprises. However, the accuracy of these models is still unsatisfactory. We need to extract more predictive information from high-frequency social media data to improve the accuracy of sales predictions.
High-frequency big data, such as eWOM on social media [4] and Google search index (GSI) data on the Google search engine [5], contain timely information and can improve the accuracy of sales predictions [6]. However, the accuracy of sales predictions is still unsatisfactory for irregular or nonseasonal sales trends [7,8]. Based on multiattribute attitude theory [9,10], we argue that the heat and sentiments of product dimensions discussed in eWOM, which previous predictive models do not consider, can improve the accuracy of sales predictions. These factors have effects on product sales [11,12]. Therefore, this paper proposes a framework to simultaneously extract the heat and sentiments of product dimensions from eWOM and to then integrate them into a sales prediction model.
We chose the movie industry as our research context. We obtain reviews from IMDb.com, online search data from Google.com, and film-related data from BoxOfficeMojo.com. Finally, we construct a large dataset including data on films, Google Trends, and 349,269 reviews of 122 movies.
To extract the heat and sentiments of product dimensions, in this study, we developed a dynamic topic analysis (DTA) framework that integrates machine-learning techniques and lexicon-based methods. The framework has two major functions. First, DTA captures key product dimensions from eWOM without manual annotation. Second, DTA simultaneously extracts the heat and sentiments of the extracted dimensions. Next, we integrate the heat and sentiments of the dimensions to construct a new sales prediction model, called the autoregressive heat-sentiment (ARHS) model, to dynamically predict sales. We focused on the three most important dimensions discussed in movie eWOM: the star, the genre, and the plot. We found that the proposed ARHS model has better accuracy than previous models in predicting movie box-office revenues. Furthermore, the ARHS model can predict sales of all kinds of products if the products have multiple attributes and sufficient eWOM. The robustness check with regard to forecasting opening-week revenues using a back-propagation (BP) neural network demonstrates that the predictive model integrating the heat and sentiments of dimensions is more accurate.
2. Literature Review
eWOM influences consumer purchase intentions by changing the preferences for alternatives and in turn influences product sales based on information theory [13,14]. We introduce multiattribute attitude theory in this research domain.
2.1. eWOM’s Effect on Sales
Some research on eWOM has shown mixed findings regarding the direct effects of eWOM on product sales [15,16]. Other research shows the moderating effects of rating variance [17], review helpfulness [18], and the features of reviewers [19], products [20,21], and social media platforms [22,23,24]. In this paper, we focus on the direct effects of eWOM.
The volume of eWOM represents the popularity (overall heat) of products supplied by reviewers, such as the number of online reviews. Previous studies have found mixed results regarding the effects of eWOM volume on sales [25,26]. Many studies have found that eWOM volume positively affects sales [25,27,28,29], whereas several other studies have not found a significant effect [30,31]. Xu [32] found that more information could even reduce sales under certain conditions. Therefore, under some conditions, volume cannot be used to predict sales. The multiattribute attitude model demonstrates that only the most important attributes that reflect consumers’ perceptual dimensions can influence consumer purchasing decisions [33]. In this paper, we divide the overall heat of products into the heat of their important attributes. Previous research has proven that the heat of key product dimensions can influence product sales [11]. In this paper, we demonstrate that the heat of dimensions has predictive power in predicting movie box-office revenues.
The valence of eWOM can be the average rating on the rating scale (e.g., 1–5), or it can be binary (positive and negative). It can also be regarded as the overall sentiment of eWOM [34,35]. Most studies have reported a significant, positive effect of valence [27,36], but other studies have not found a significant effect [29,37]. The overall sentiment of eWOM represents the emotion conveyed by reviewers to consumers. However, the overall sentiment represents the aggregation of the sentiments of all attributes discussed in eWOM, which include irrelevant and abundant attributes. Perhaps for this reason, prior studies have found that the overall sentiment of eWOM has no effect on movie box-office revenues [38,39]. Chen and Xie [40] demonstrate that eWOM provides product-dimension preference information that helps consumers find products that match their needs. Potential consumers will change their purchase intentions regarding a product after perceiving the sentiments of important product dimensions from online reviews [12]. We argue that analyzing the eWOM sentiments of key product dimensions can provide new insights for sales prediction and overcome the weakness of overall sentiment.
2.2. eWOM-Based and GSI-Based Sales Prediction
Online search data include indexes (from zero to 100) of the frequency of the object searched in an online search engine, such as Google.com. This type of data has been used to predict movie box-office revenues [41]. Bughin [42] finds that the valence of eWOM influences sales more than Google Trends. Geva et al. [5] find that adding Google search data to models based on the more commonly used eWOM data improves the accuracy of sale predictions for search products. Regarding the different natures of search products and experience products, the effect of online information is always different in these two kinds of products [27]. In this paper, we aim to demonstrate whether the model used for search products is valid for experience products. Geva et al. [5] also found that for search products, Google search index (GSI) models based on inexpensive Google Trends provide accuracy that is at least comparable to that of eWOM-based prediction models. These studies have proven that both online search data and eWOM have powerful predictive ability. To date, however, the predictive ability of the heat and sentiments of product dimensions has not been researched. This study attempts to improve the prediction accuracy of movie box-office revenues by proposing a comprehensive model that simultaneously integrates the heat and sentiments of product dimensions.
3. Materials and Methods
3.1. Research Framework
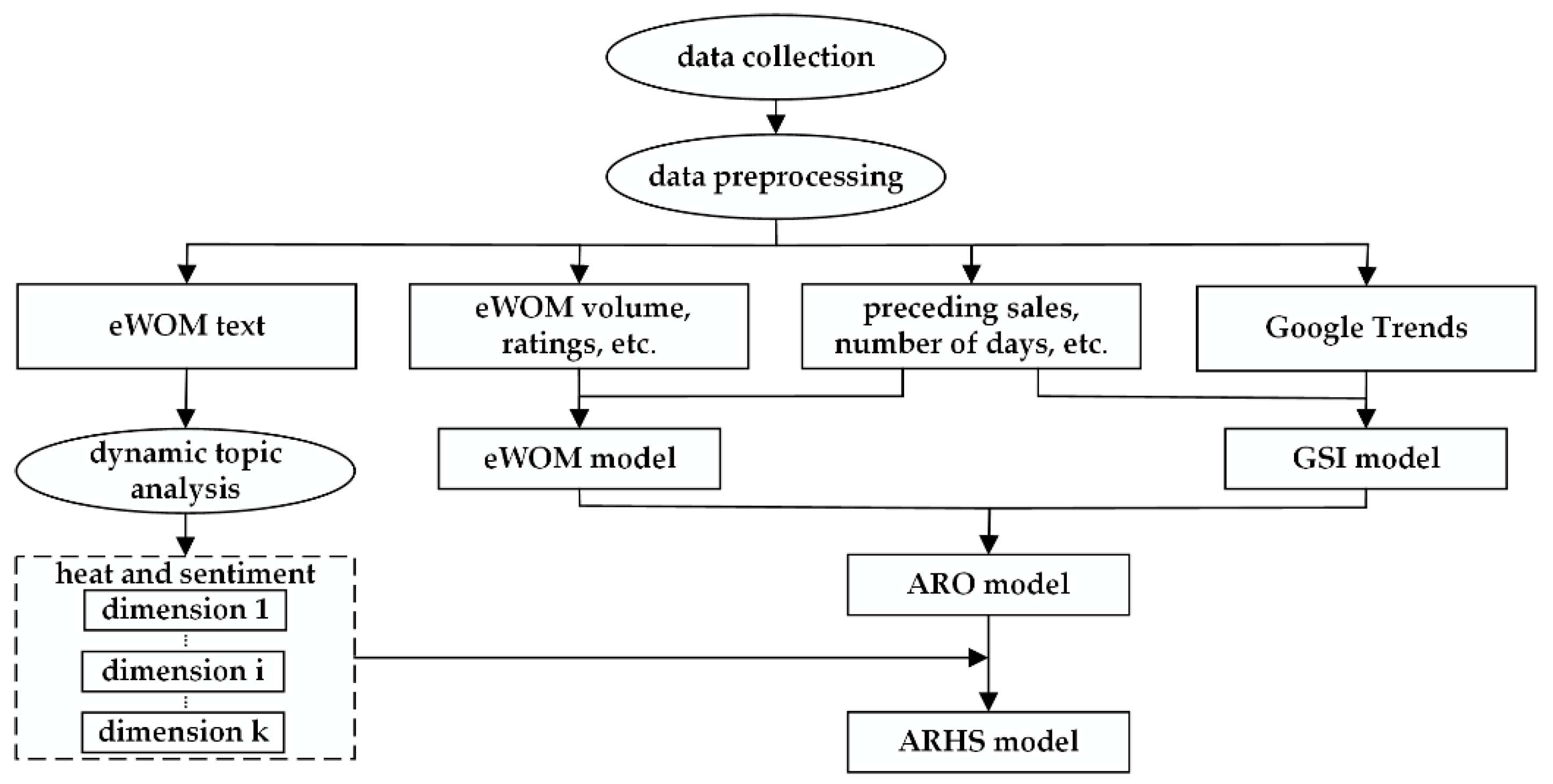
Figure 1 shows the framework of our study; it will help researchers develop a sales prediction model for products with abundant eWOM and multiple attributes. First, based on the findings that eWOM volume [25,27,28,29] and ratings [27,36] positively affect sales, we developed the eWOM model by integrating eWOM variables into the autoregressive (AR) model. Additionally, we developed the GSI model by integrating Google Trends into the AR model based on findings in the literature [41]. We then integrated Google Trends into the eWOM model following the method of [5] and named this benchmark model the autoregressive online (ARO) model.
The above models consider volume (heat) and valence as a whole. Multiattribute attitude theory decomposes a consumer’s overall attitude toward a product into smaller components [9,10]. These components, which are the most important attributes, reflect only consumers’ perceptual dimensions rather than product characteristics that are directly controllable and measurable by marketing managers [33]. Multiattribute attitude theory shows that only the importance and valence of important product attributes can predict consumer purchase predispositions. Volume and sentiment, which represent the sum of the heat and sentiments of all attributes implied in eWOM, may have little effect on sales because of the offset effects of irrelevant and redundant attributes. This may be why some research finds that the volume and valence of eWOM have no effect on sales [15,38,39]. In previous studies, attributes were generated based on expert judgment and in-depth interviews. Additionally, the measures of attribute importance and valence in the attitude model were obtained by surveying a sample of respondents [43]. Recent research shows that topic models can be used to generate important attributes that reflect consumers’ perceptual dimensions, and the heat and sentiment of these product dimensions can be used as a proxy for attribute importance and valence [44,45,46]. Therefore, the heat and sentiments of dimensions are more suitable than eWOM volume and valence for predicting sales.
Thus, according to the discussion above, we hypothesize the following:
H1.
The heat and sentiments of dimensions have predictive power for sales and can improve the performance of the benchmark model.
Finally, to verify the hypothesis, we used DTA to extract the heat and sentiments of product dimensions from eWOM and integrated them into the benchmark model to determine whether the new model, the ARHS model, has better prediction accuracy.
3.2. Data and Variables
3.2.1. Data Collection
This paper focuses on online reviews of movies because within the film industry, online reviews are more popular than other types of eWOM [29]. In this study, IMDb.com, Google.com, and BoxOfficeMojo.com are the data sources. We examined movie reviews on IMDb.com, the most popular and authoritative information source for movies worldwide, for approximately seven weeks after movie releases. We then collected daily data on box-office revenues, budgets, and distributors as well as other movie information from BoxOfficeMojo.com. Our unit of time was one day; however, we aggregated the reviews published before the release day into one time window. The weekly Google Trends before a movie release and the daily Google Trends one day before and 49 days after a movie release were obtained and reviewed. Because the unit of time was one day, we had a sufficiently long study period with enough observations to provide credible results. The final dataset included Google Trends and eWOM information for 50 consecutive time windows and revenue information for 49 time windows. All movies were released in the US from 2010 to 2016.
After filtering out movies with fewer than 100 reviews by the end of the data period, we identified 349,269 reviews for 122 sample movies. We chose a threshold of 100 reviews to ensure that we have sufficient reviews to train the topic model used in the DTA. As shown in Table 1, our sample movies exhibited great diversity in terms of film distributor, movie genre, release month, and Motion Picture Association of America (MPAA) rating. Table 2 indicates that the total domestic gross and production budgets of the movies are right-skewed; that is, all but a few movies have low box-office revenues and product budgets.
Table 3 and Table 4 list the definitions of and statistics regarding eWOM, Google Trends, and our film-related variables. First, we measured the eWOM volume and valence, which are represented by and , respectively. Volume is the log-transformation of the daily number of reviews. We added one to the daily number of reviews to ensure that the log-transformation result was not negative [47]. Valence is the mean of the daily review ratings, reflecting the overall sentiment of reviewers with regard to a specific movie [28]. If there were no reviews on one day, then we used the average valence of the preceding days as a proxy [48]. Second, we used the variable to denote the number of days since the movie release to consider the time effect. Third, we set the dummy variable to one if the day was on the weekend and zero otherwise to consider the seasonal effect. Fourth, the variable represents the number of cinemas at which a film was being shown [17]. Finally, we used the Google Trends of movie names, and the initial trends range from 0 to 100 in terms of online search data. Table 4 shows that sales, volume (), and theaters () have right-skewed distributions and that the skewness of volume and sales is very large. This result means that very few movies had high box-office revenues or high heat and that most movies had low box-office revenues or low heat. The distributions of valence () are relatively evenly distributed.
Figure 2a shows the relationship between Google Trends and the box-office revenues of the movie Gravity. Figure 2b shows the relationship between eWOM volume and the box-office revenues of the movie Gravity. We observe that both the eWOM and GSI data have high correlations with movie box-office revenues.
3.2.2. Dynamic Topic Analysis
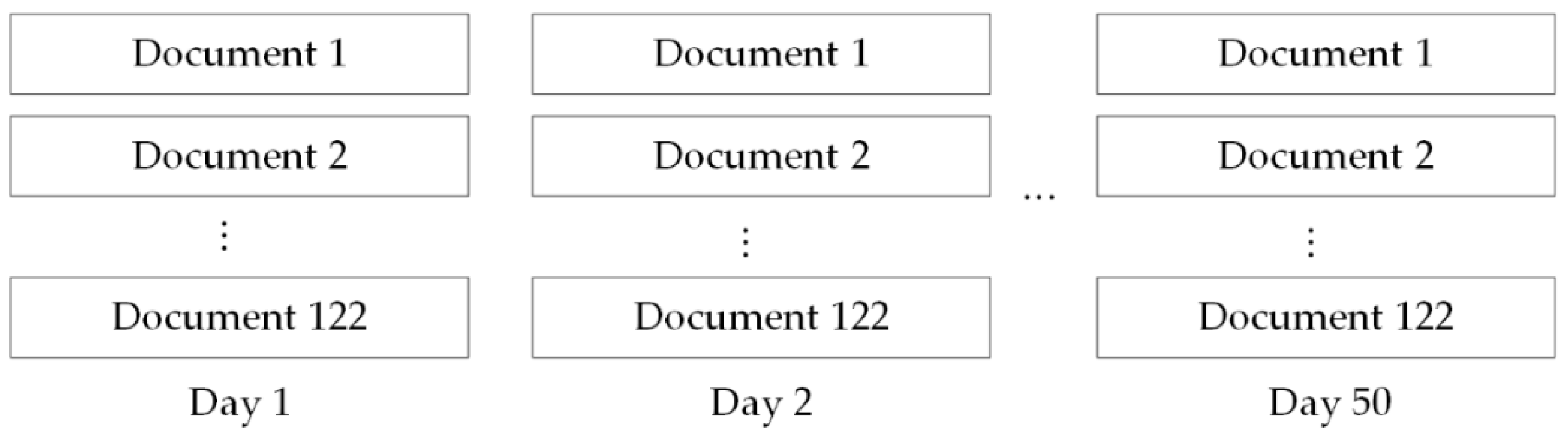
For 122 movies, we constructed a DTA framework by integrating the dynamic topic model (DTM) [49], the lexicon-based method [50], and the Stanford natural language processing (NLP) technique [51] to derive the heat and sentiments of dimensions from online reviews. We obtained 122 daily documents by integrating hundreds of daily reviews for each movie into one document. Finally, the daily documents compiled over 50 days constitute our review corpus, which contains 349,269 reviews. Figure 3 shows the structure of the corpus.
We preprocessed each document by using the steps used in a study by Guo et al. [45]. First, we eliminated non-English words and spelling errors, such as web sites, punctuation marks, and numbers. We then used the Stanford NLP package for word text tokenization, part-of-speech tagging, and word stemming. Finally, each document became a word-of-bag.
To extract key product dimensions from a large corpus of text data in an effective manner, previous studies have used the latent Dirichlet allocation (LDA) model [44,45]. The DTM is more suitable for extracting key product dimensions from our structured review set [49] and is an extended LDA method [52]. The DTM can quickly identify a conglomeration of connected topics from a very large number of documents over different time windows, which LDA alone cannot do.
As a machine-learning method, the DTM is highly efficient in handling online big data. We used the DTM to extract key product dimensions, the heat of these dimensions, words that represent each dimension and the changes in these factors over different time windows. The DTM assumes that a review comprises a sequence of words, , reviews form a review set, , and review sets form a corpus over time windows, . The DTM also assumes that reviewers share dimensions across the corpus over the time windows. In each time window, the DTM assumes that reviewers express their experience with a product or service over dimensions. For instance, a reviewer may comment about a movie in a review by focusing on three dimensions with different heat and sentiments: 30% and 4.9 for movie stars, 40% and 3.4 for the story plot, and 30% and 2.1 for the background music. Thirty percent is the dimension heat of movie stars, which means that one-third of the review is about movie stars; additionally, 4.9 is the sentiment strength of movie stars, which means that the reviewer has a strong sentiment toward movie stars.
Comparing the perplexity of the DTM and the semantics of the dimensions when using different values of K, we determine the optimal number of key product dimensions [11]. Ultimately, we find three movie dimensions that can perfectly represent the review corpus. The formula for the perplexity of the DTM for the document set on day is as follows:
where is the document set on day ; is the number of documents on day ; is the number of words in document ; is the number of dimensions; is the heat of word in dimension ; is the heat of dimension in document . DTM learning with Gibbs sampling can simultaneously generate the heat of the words in each dimension and the heat of the dimensions in each document. Readers can refer to [49] for details on the DTM. Let be the heat of the th dimension of the th movie on day . can be calculated as follows:
where is the heat of dimension k in document d of movie i, and is the number of documents for movie i on day t. In our research context, equals one.
We name the three dimensions plot, star, and genre, following the method of Guo et al. [45]; these dimensions have been regarded as the three most important attributes of movies [7,53]. Table 5 shows the changes in the dimension plot in different time windows.
The heat of a dimension refers to the proportion of reviewers’ discussion concerned with the dimension of a product in eWOM. For example, the heat of the dimension plot denotes the proportion of consumers’ discussion concerned with plot-related information in reviews. Figure 4 shows the changes in the heat of the three movie dimensions over 50 days. Consumers talk more about movie stars and the story plot in the early days after a movie’s release than they do at the end of the release.
We then used the sentiment lexicon and syntax relation to calculate the sentiments of dimensions. Lexicon-based methods that use a publicly recognized sentiment lexicon are more objective and suitable for big data sentiment analysis than machine-learning-based methods that require expert annotations because expert annotation has a high cost and there are artificial deviations. Most studies on dimension sentiment analysis divide dimensions into positive and negative classes [54], and sentiment analysis methods are different based on different applications. We calculated the sentiment strength of each dimension that can forecast movie box-office revenues. We extracted the syntactic relations between the dimension words and sentiment words in the daily review sentences using the Stanford NLP package, and we obtained the sentiments of the dimension words based on the extracted relations. Table 6 shows the main sentiment mining rules used in our framework.
Finally, we calculated the average daily sentiment strength of the dimensions for each movie. Let be the sentiment value for the th dimension word at the th time (location) in document d for one movie. The sentiment of the th dimension for one movie on the th day can then be formulated as follows:
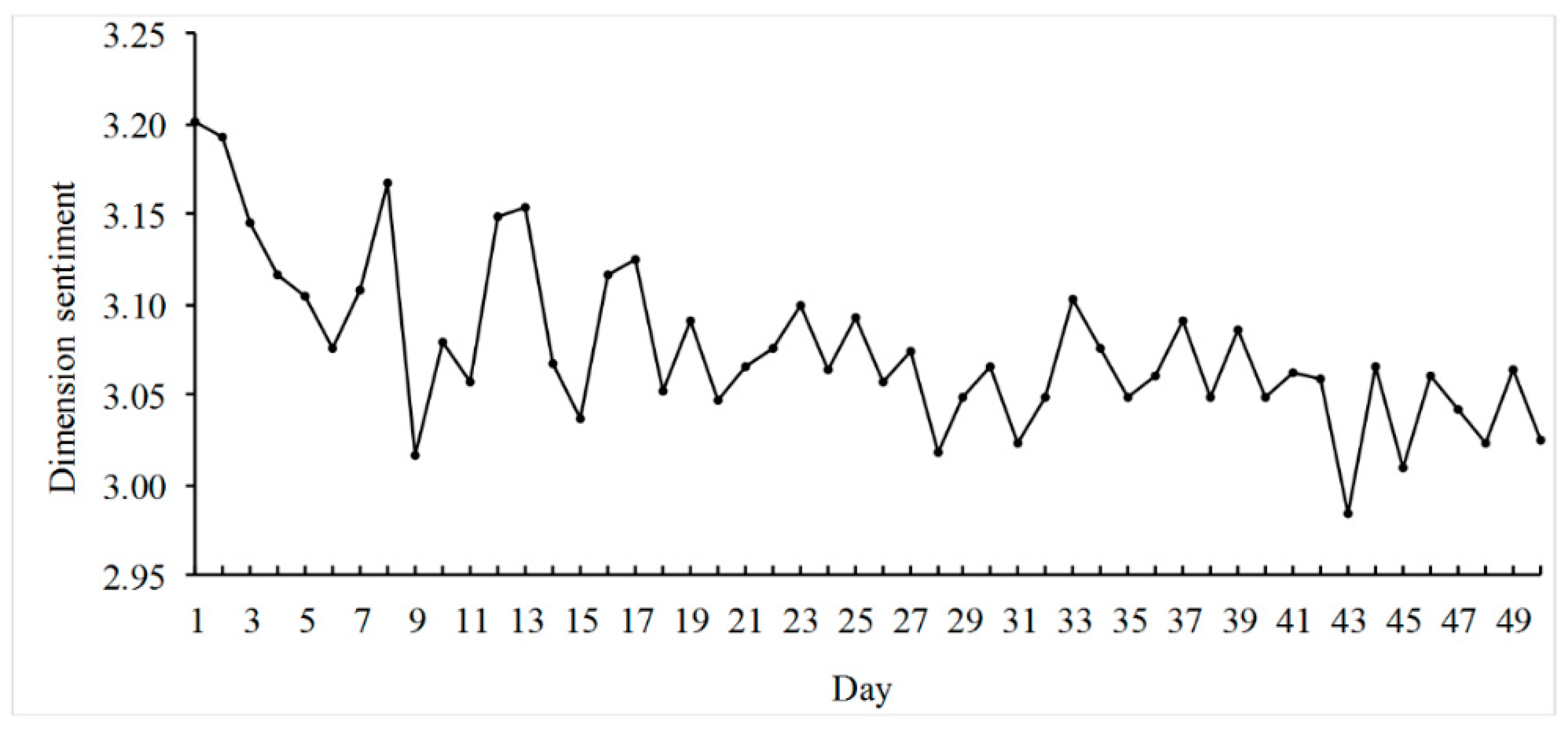
Intuitively, represents the average strength of the sentiment of the th dimension. Figure 5 shows the average sentiments of the dimension plot for 122 movies. Using Figure 4 and Figure 5, we can easily monitor consumer feedbacks (heat and sentiments) on product dimensions over time.
In Table 7, we describe the key variables of the dimensions.
Table 8 shows the summary statistics of the variables. The heat of the dimensions () is between zero and one. The median of the sentiments of the dimensions () is three.
3.3. Predictive Model
We used the first 40 days of data to train the predictive model and the last 9 days of data to test the trained model. The regressive model can have better forecasting performance than the machine-learning models when the amount of relevant information is sufficient and when the variation in box-office revenues is small [55]. However, if there is not enough information, then the machine-learning model can help improve the forecasting accuracy by more thoroughly utilizing the limited information given. According to the sufficient predictors discussed in Section 3.2 and the relatively stable revenues in the test period, the proposed approach that we constructed was based on the autoregressive model because the regressive model is the most efficient predictive model [7]. We also needed to address some methodological concerns. First, we log-transformed some skewed variables to give them similar normal distributions. Second, we used the variance inflation factor (VIF) to assess multivariate multicollinearity. The VIF values were lower than the threshold of five; thus, multicollinearity was not a serious issue [56].
3.3.1. Autoregressive Model
We started with an AR model as our base model to forecast movie box-office revenues. We used this AR model with the parameter to model the relationship between preceding box-office revenues and current box-office revenues as follows:
where , are the parameters to be estimated, is the effect of the combination of time-invariant variables, such as the production budgets and genres of movies, and is an error term. The AR model uses only preceding sales to predict current or future sales.
3.3.2. ARO Model
In addition to preceding box-office revenues, online information, such as Google Trends and eWOM volume, might greatly influence box-office revenues. According to the discussion above, we propose a predictive model by integrating online information into the AR model. This model includes all the variables of previous GSI models and eWOM models. Our ARO model is similar to that proposed in [5], and it can be formulated as follows:
where represents the th online information variable on day . We determined by comparing model accuracy when using different values of . and are parameters that need to be estimated. The parameter q specifies the lags of the preceding days of the online information variables; J indicates the number of these variables. The ARO model uses preceding sales, Google Trends, the eWOM variables and other predictors in Table 4 to predict current and future sales.
3.3.3. The ARHS Model
According to previous studies, the heat and sentiments of product dimensions are very important for sales [11,12]; thus, it is desirable to integrate the heat and sentiments of movie dimensions into predictive models to achieve better accuracy. In this section, we extend the ARO model to the ARHS model. We formulate the ARHS model as follows:
where and are user-defined parameters, is an error term, and , and are parameters that need to be estimated. and are the heat and sentiments, respectively, of the dimension at time , and are obtained by using DTA. and specify how far the model “looks back” into the past, whereas and specify how many related variables we would like to consider. and are fitted as described in Section 3.1. We used the least squares method to train all the models. The ARHS model extends the ARO model by integrating the preceding heat and sentiments of the movie dimensions into the ARO model.
4. Results
In this section, we compare the ARHS model with the AR model, the eWOM-based model, the GSI-based model, and the ARO model to validate its effectiveness.
In this paper, we use the mean absolute percentage error (MAPE) to measure the performance of the predictive models:
where is the number of predictions made on the test data, is the predicted box-office revenues, and represents the true value of the box-office revenues. In statistics, MAPE is a suitable measure of accuracy for time-series-value predictions. We can compare the error of the fitted time series because it is a percentage error. All the MAPE results reported herein are the mean value of the independent runs of 122 movies on different days. This metric is robust to comparing the performance of the sales prediction models [5,57]. For brevity, we removed the percent sign (%) of the MAPE value from Figure 6, Figure 7, Figure 8 and Figure 9.
4.1. Performance of the Parameters in the ARHS Model
In the ARHS model, the parameters , and provide the flexibility to fine tune the model for optimal performance. We now explore how the choices of these parameter values affect prediction accuracy.
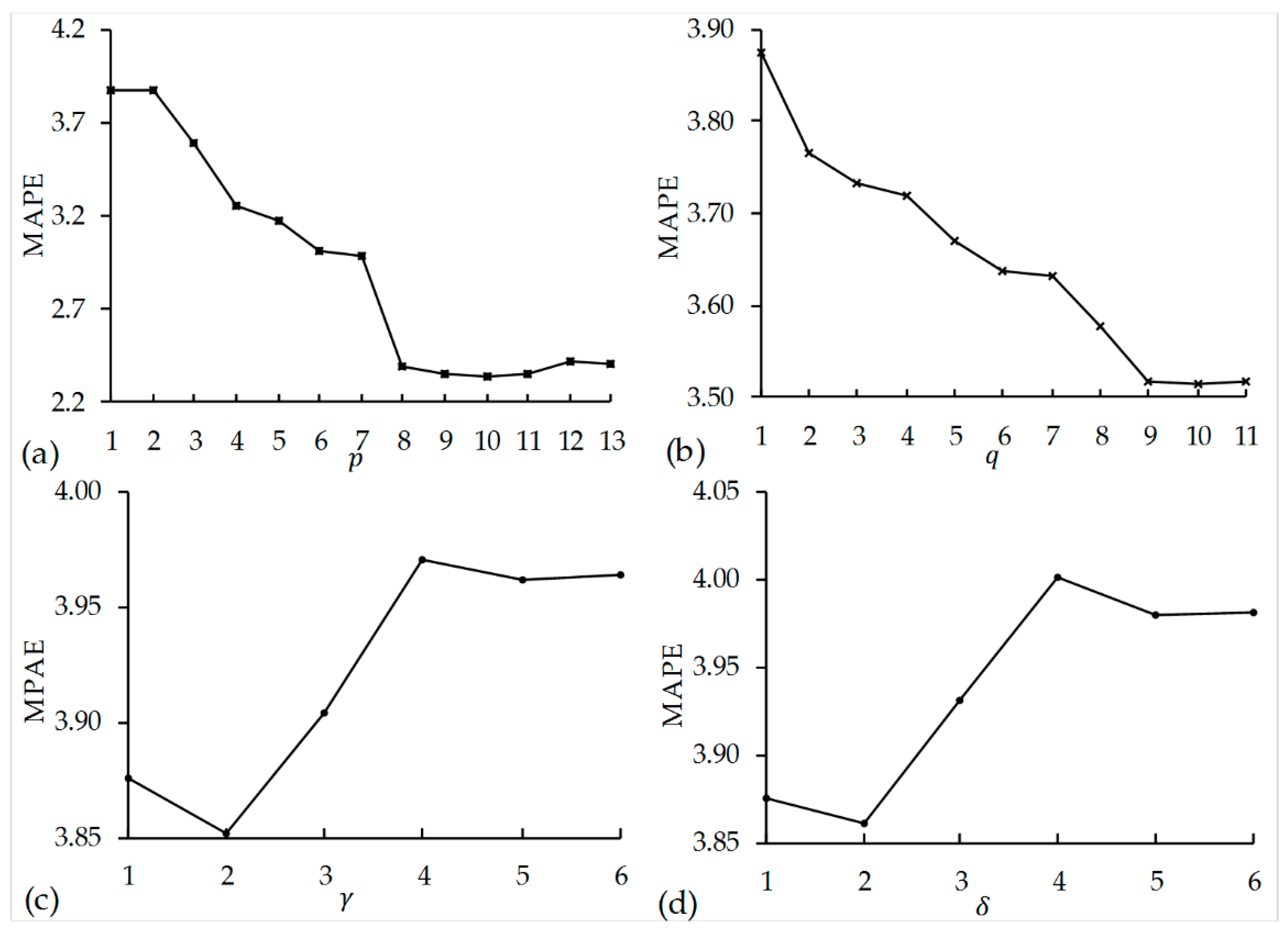
First, we varied with fixed values of parameters and () to study how preceding box-office revenues affect the prediction accuracy of the ARHS model. As shown in Figure 6a, the model achieves its best prediction accuracy when . The change in accuracy is minor after , and the accuracy even decreases after . These findings suggest that should be large enough to factor in all significant influences of preceding box-office revenues but that it should not be so large that it lets irrelevant preceding box-office revenues reduce prediction accuracy.
Next, using a fixed value of , and (), we varied the value of from 1 to 11 to study its effect on prediction accuracy. Figure 6b shows that the model achieves its best performance when . However, the accuracy is basically the same after , which means that numerical online information will affect box-office revenues over the following nine days. Based on the above results, we suggest that the predictive power of numerical online information for box-office revenues lasts slightly longer than the preceding box-office revenues.
By using fixed values for and (), we varied from 1 to 6 to study the prediction accuracy of the ARHS model. As shown in Figure 6c, the ARHS model achieves the best prediction accuracy at , which implies that the effect of the heat of dimensions captured from the text of eWOM lasts two days.
We also varied from 1 to 6, using fixed values for and (). As shown in Figure 6d, the ARHS model achieves the highest accuracy at , which implies that the effects of the sentiments of dimensions on box-office revenues also last two days.
From the results above, we conclude that the product-dimension information captured from online comments has a shorter effect on box-office revenues than numerical online information. We think the reason for this result is that consumers look through the text of eWOM posted only in recent days but glance at the numerical information of eWOM posted over a longer period of time before they decide to see a movie. The optimal parameter values of the ARHS model should be simultaneously searched ( from 1 to 12; from 1 to 6). After comparing 4356 experimental results, we found that the optimal parameter values are .
4.2. Comparison of the Predictive Models
To verify the superiority of the ARHS model, we compared its performance with that of the other models.
First, we compared the ARHS model () with the AR model. As shown in Figure 7, the ARHS model consistently outperforms the AR model as ranges from 1 to 10. We observe that the ARHS model has much higher accuracy when is small, which implies that the eWOM of a movie has more predictive power when we know little about the preceding box-office revenues. When = 4, our proposed sales prediction model improves the MAPE of the AR model by 27.65%. When the lag of sales is 8, the improvement of the MAPE is the smallest, 2.69%. These improvements suggest that the ARHS model has higher accuracy.
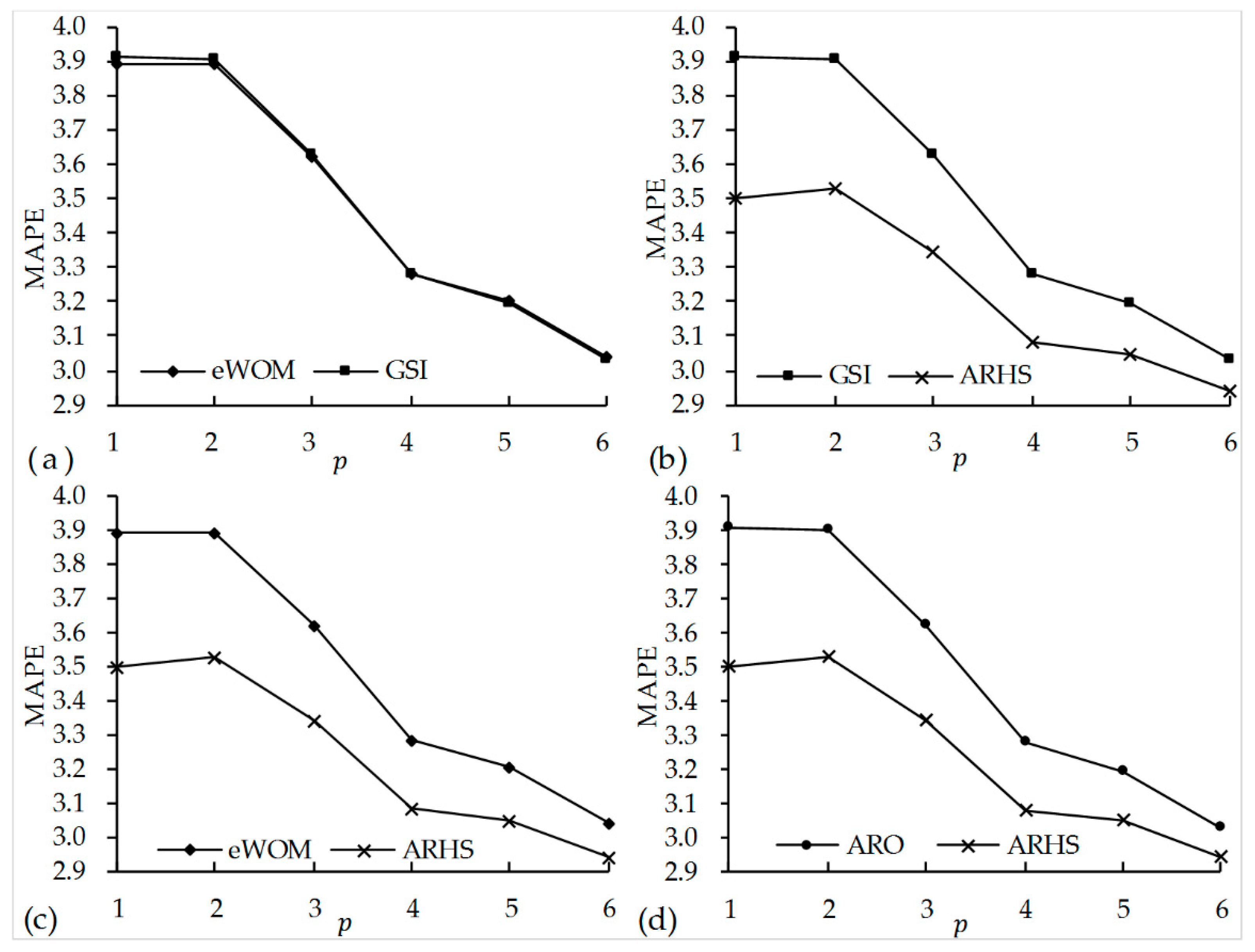
We then conducted experiments to compare the ARHS () model with the eWOM model, the GSI model [41], and the ARO model. Both our study and previous studies prove that these models are better than the AR model. As shown in Figure 8a, the eWOM model and the GSI model have nearly the same accuracy performance with regard to forecasting the sales of experience products. As shown in Figure 8b–d, the ARHS model always outperforms the eWOM model, the GSI model, and the ARO model when ranges from 1 to 6. Thus, the ARHS model is the best among these models, which supports our hypothesis. The effects of the eWOM text on box-office revenues decrease over time, and our test occurs at the end of the release period of the movie. Therefore, compared with the eWOM model, the GSI model, and the ARO model, the ARHS model improves the MAPE, but not much. We argue that the improvement in accuracy of the ARHS model will be higher earlier after a movie is released. Because of the high gross of movies, a very small improvement in forecasting accuracy might result in a difference of millions of dollars. Therefore, the ARHS model should be meaningful to movie marketers and theater managers.
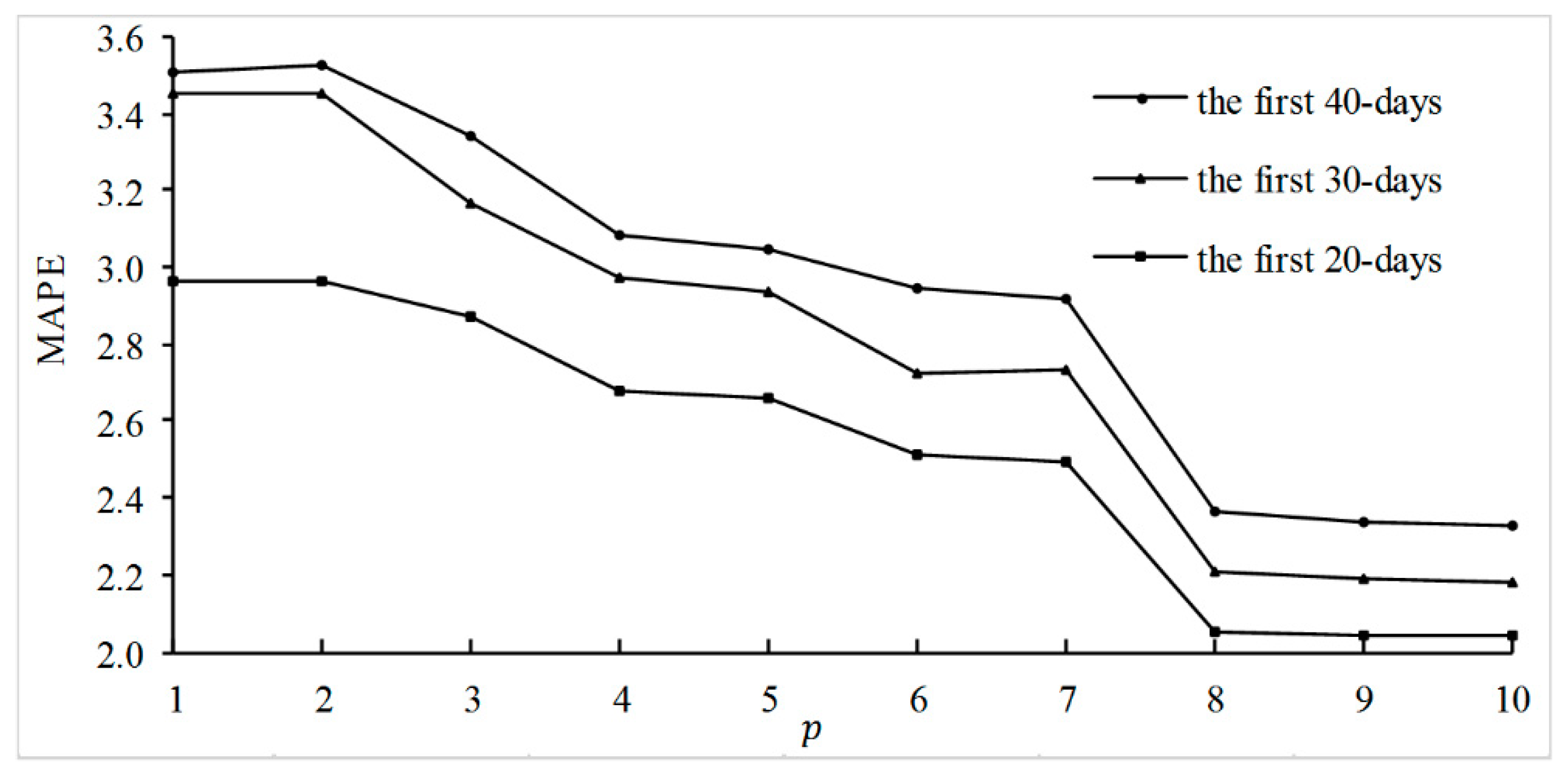
To verify the time robustness of the ARHS model, we compared its accuracy for different predictive periods. We use the first 20, 30, and 40 days of data as training data and the following 9 days of data as test data. Figure 9 shows the results. The prediction accuracy increases when () increases, and it barely changes after . The prediction accuracy for 21–29 days is always higher than that for 31–39 days, and the prediction accuracy for 31–39 days is higher than that for 41–49 days. This means that the prediction performance of the ARHS model is higher in the initial stage of a movie’s release and that earlier is better. Therefore, we conclude that the heat and sentiments of dimensions have greater predictive power in the early days after a movie’s release.
4.3. Robustness of the Predictive Power of the Heat and Sentiments of Dimensions
To further verify the predictive power of the heat and sentiments of dimensions, we conduct a robustness check with regard to predicting the opening-week revenues of movies, which determines the gross of movies, by using a BP neural network with 10-fold cross validation. We filtered out the movies that did not have any online reviews before being released. The final dataset comprises 111 movies with 14,328 online reviews, Google Trends and film-related factors; however, it does not include preceding revenues.
We calculated the overall sentiment of the reviews using the previous method [12]. To verify the forecasting performance of the extracted dimension-specific information, we included the predicted factors in the ARO model without volume in the BP neural network as a benchmark model [41]. We then constructed a new predictive model by integrating the volume and overall sentiment into the benchmark model, which we call the volume–overall–sentiment (VOS) model. Finally, we constructed the dimension-heat-sentiment (DHS) model by integrating the heat and sentiments of dimensions. We used the root mean squared error (RMSE) and MAPE to measure the prediction accuracy of the BP neural network:
where is the sample size, is the actual box-office revenues, and represents the predicted box-office revenues.
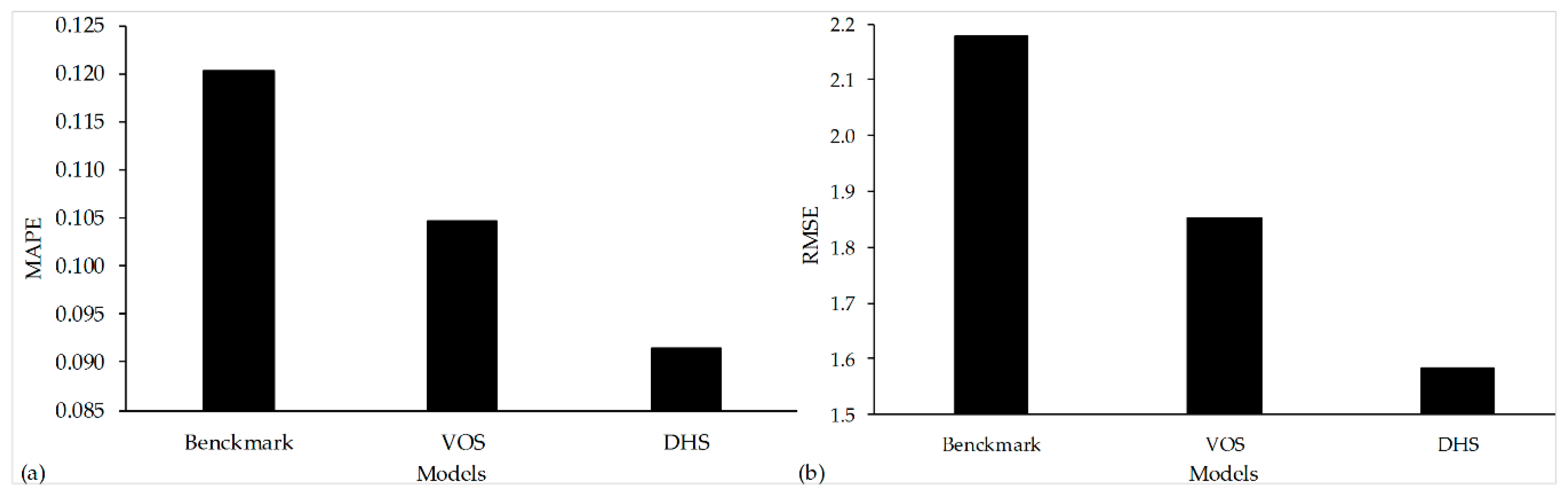
Figure 10 shows the RMSE and MAPE of these models for predicting the opening-week box-office revenues. We found that the VOS model is always better than the benchmark model and that the DHS model is better than the VOS for opening-week revenue prediction. Therefore, the heat and sentiments of dimensions have better prediction performance for movie opening-week revenues when the machine-learning method is used.
5. Conclusion and Discussion
Previous research demonstrates that eWOM text implies the heat and sentiments of product dimensions that influence product sales [11,12,43]. Thus, we propose a method called DTA to extract the heat and sentiments of product dimensions from big data on eWOM. Previous research has proven that the multiattribute attitude model with three attributes is sufficiently concise and effective [43,58]. Based on our DTA results, we obtained the dynamic heat and sentiments of three key movie dimensions: the plot, the genre, and the star. These dimensions have also been regarded as important movie dimensions in previous studies, but the heat and sentiments of these dimensions had not been investigated [7,53]. To improve accuracy, we propose the ARHS model by integrating the heat and sentiments of dimensions into a prediction model for movie daily ticket sales. This model’s performance was compared with that of other predictive models, and the results indicate that the ARHS model is more accurate than the benchmark model [5], which supports our hypothesis. We also found that the ARHS model performs much better in the early stage of product release. The robustness check with regard to predicting opening-week revenues using the machine-learning method also demonstrates that the heat and sentiments of dimensions have more predictive power.
Our research has some theoretical implications. First, our research extends the use of multiattribute attitude theory to a big data environment using DTA, which is a framework based on a machine-learning method, syntactic method, and lexicon-based method. In previous research, attributes used to predict consumer purchase predispositions were generated based on expert judgment and in-depth interviews. Additionally, the measures of attribute importance and valence were obtained by surveying a sample of respondents [43]. However, individual deviations, the limited number of survey samples and halo effects may bias the results [59], and these methods often have high manpower and time costs that are not suitable for big data. Therefore, we propose DTA to extract the heat and sentiments of the most important dimensions from eWOM big data as a proxy for attribute importance and valence in social media marketing research, making it possible to avoid the issues of the methods used in previous studies. Second, we demonstrate that multiattribute attitude theory [9,10] is valid for forecasting sales in a big data environment. Previous research used eWOM volume and sentiment as a whole to predict sales, with limited performance. Our research shows that the heat and sentiment of dimensions extracted from social media based on multiattribute attitude theory can improve the predictive performance of the benchmark model. Third, compared with the results regarding search products [5], our study proves that integrating social media data and online search data together can improve the performance of sales predictions for experience products. Fourth, our research demonstrates that the heat and sentiments of dimensions implied in social media improve the accuracy of predictive models. Therefore, related research, such as studies that predict election outcomes, stock prices, and internet security, can use the heat and sentiments of dimensions to construct predictive models.
Additionally, our paper has some practical implications. First, using the DTA, we can extract the heat and sentiments of dimensions in a timely way and can then monitor consumer feedbacks on brand dimensions by analyzing the dynamic heat and sentiments of brand dimensions over time. There may be an initial collaborative attack on a brand dimension when the heat of the brand dimension suddenly increases and the sentiment of the brand dimension decreases suddenly and simultaneously. At that point, we can provide a warning of “collaborative brand attacks” to enterprises. The stakeholders can then confirm it in social media and carry out certain activities to stop the attack if the information is accurate. Second, we find that the predictive power of the volume and ratings of eWOM lasts longer than that of eWOM text: the heat and sentiments of product dimensions. Therefore, managers should pay attention to the volume and ratings of eWOM over a long period and pay attention to the text of new eWOM only. Third, the proposed ARHS model has better predictive performance for sales. Therefore, marketing managers can provide an early warning with regard to a sales explosion or collapse and more accurately determine whether and when to carry out promotion activities using our method. In the movie industry, marketers can provide an early warning with regard to ticket sales before a movie is released, and theaters can adjust the number of screens for different movies based on accurate daily box-office predictions. Fourth, we can determine the strength and weakness of relevant product attributes by comparing the DTA results of different products. For example, if one dimension of a product has the lowest sentiment among all competitive products, this dimension can be the weakness of the product. Therefore, this method can also be used to suggest specific changes in product design and the marketing support for the product.
This paper also has some limitations. Our research can only benefit the social media marketing of products and brands with multiple attributes and abundant social media data. We predict only box-office revenues in America to demonstrate the predictive power of the heat and sentiments of dimensions. To improve our theory, we plan to conduct further research that forecasts the sales of other products in different regions. Additionally, in this paper, we use only one type of eWOM and social media data. We should use multiple types of eWOM and data in other forms of media in future research to obtain results that are more robust. Future research can be conducted to examine how dimension-specific information influences product sales differently, which can help to identify the different economic effects of each product attribute.
Author Contributions
Conceptualization, X.L. and C.J.; methodology, X.L.; software, X.L.; validation, X.L., Y.D., and Z.W.; formal analysis, X.L. and Y.L.; investigation, X.L.; resources, X.L.; data curation, X.L.; writing—original draft preparation, X.L.; writing—review and editing, X.L. and C.J.; visualization, X.L.; supervision, X.L., Z.W., and Y.L.; project administration, C.J. and Y.D.; funding acquisition, C.J.
Funding
This research was funded by the National Natural Science Foundation of China (NSFC), key grant number 71731005 and grant number 71571059.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Wang, X.; Yu, C.; Wei, Y. Social media peer communication and impacts on purchase intentions: A consumer socialization framework. J. Interact. Mark. 2012, 26, 198–208. [Google Scholar] [CrossRef]
- Felix, R.; Rauschnabel, P.A.; Hinsch, C. Elements of strategic social media marketing: A holistic framework. J. Bus. Res. 2017, 70, 118–126. [Google Scholar] [CrossRef]
- Amornpetchkul, T.; Duenyas, I.; Şahin, Ö. Mechanisms to induce buyer forecasting: Do suppliers always benefit from better forecasting? Prod. Oper. Manag. 2015, 24, 1724–1749. [Google Scholar] [CrossRef]
- Hu, N.; Koh, N.S.; Reddy, S.K. Ratings lead you to the product, reviews help you clinch it? The mediating role of online review sentiments on product sales. Decis. Support Syst. 2014, 57, 42–53. [Google Scholar] [CrossRef]
- Geva, T.; Oestreicher-Singer, G.; Efron, N.; Shimshoni, Y. Using forum and search data for sales prediction of high-involvement products. MIS Q. 2017, 41, 65–82. [Google Scholar] [CrossRef]
- Chern, C.C.; Wei, C.P.; Shen, F.Y.; Fan, Y.N. A sales forecasting model for consumer products based on the influence of online word-of-mouth. Inf. Syst. e-Bus. Manag. 2015, 13, 445–473. [Google Scholar] [CrossRef]
- Ghiassi, M.; Lio, D.; Moon, B. Pre-production forecasting of movie revenues with a dynamic artificial neural network. Expert Syst. Appl. 2015, 42, 3176–3193. [Google Scholar] [CrossRef]
- See-To, E.W.K.; Ngai, E.W.T. Customer reviews for demand distribution and sales nowcasting: A big data approach. Ann. Oper. Res. 2018, 270, 415–431. [Google Scholar] [CrossRef]
- Fishbein, M. An investigation of the relationships between beliefs about an object and the attitude toward that object. Hum. Relations 1963, 16, 233–239. [Google Scholar] [CrossRef]
- Rosenberg, M.J. Cognitive structure and attitudinal affect. J. Abnorm. Psychol. 1956, 53, 367–372. [Google Scholar] [CrossRef]
- Li, X.; Wu, C.; Mai, F. The effect of online reviews on product sales: A joint sentiment-topic analysis. Inf. Manag. 2018. [Google Scholar] [CrossRef]
- Liang, T.P.; Li, X.; Yang, C.T.; Wang, M. What in consumer reviews affects the sales of mobile apps: A multifacet sentiment analysis approach. Int. J. Electron. Commer. 2015, 20, 236–260. [Google Scholar] [CrossRef]
- Siering, M.; Muntermann, J.; Rajagopalan, B. Explaining and predicting online review helpfulness: The role of content and reviewer-related signals. Decis. Support Syst. 2018, 108, 1–12. [Google Scholar] [CrossRef]
- Yang, D.; Zhang, L.; Wu, Y.; Guo, S.; Zhang, H.; Xiao, L. A sustainability analysis on retailer’s sales effort in a closed-loop supply chain. Sustainability 2019, 11, 18. [Google Scholar] [CrossRef]
- Floyd, K.; Freling, R.; Alhoqail, S.; Cho, H.Y.; Freling, T. How online product reviews affect retail sales: A meta-analysis. J. Retail. 2014, 90, 217–232. [Google Scholar] [CrossRef]
- Ghose, A.; Ipeirotis, P.G.; Li, B. Designing ranking systems for hotels on travel search engines by mining user-generated and crowd-sourced content. Mark. Sci. 2012, 31, 493–520. [Google Scholar] [CrossRef]
- Wang, F.; Liu, X.; Fang, E. User reviews variance, critic reviews variance, and product sales: An exploration of customer breadth and depth effects. J. Retail. 2015, 91, 372–389. [Google Scholar] [CrossRef]
- Chen, P.-Y.; Dhanasobhon, S.; Smith, M.D. All reviews are not created equal: The disaggregate impact of reviews and reviewers at Amazon.com. 2006. Available online: http://archive.nyu.edu/bitstream/2451/14961/2/USEDBOOK19.pdf (accessed on 20 July 2006).
- Baker, A.M.; Donthu, N.; Kumar, V. Investigating how word-of-mouth conversations about brands influence purchase and retransmission intentions. J. Mark. Res. 2016, 53, 225–239. [Google Scholar] [CrossRef]
- Gu, B.; Tang, Q.; Whinston, A.B. The influence of online word-of-mouth on long tail formation. Decis. Support Syst. 2013, 56, 474–481. [Google Scholar] [CrossRef]
- Kostyra, D.S.; Reiner, J.; Natter, M.; Klapper, D. Decomposing the effects of online customer reviews on brand, price, and product attributes. Int. J. Res. Mark. 2016, 33, 11–26. [Google Scholar] [CrossRef]
- Hafeez, H.A.; Manzoor, A.; Salman, F. Impact of social networking sites on consumer purchase intention: An analysis of restaurants in Karachi. J. Bus. Strateg. 2017, 11, 1–20. [Google Scholar] [CrossRef]
- Yan, Q.; Wu, S.; Wang, L.; Wu, P.; Chen, H.; Wei, G. E-WOM from e-commerce websites and social media: Which will consumers adopt? Electron. Commer. Res. Appl. 2016, 17, 62–73. [Google Scholar] [CrossRef]
- Parboteeah, V.; Valacich, J.; Wells, J. Online impulse buying: understanding the interplay between consumer impulsiveness and website quality. J. Assoc. Inf. Syst. 2011, 12, 32. [Google Scholar]
- Dewan, S.; Ramaprasad, J. Social media, traditional media, and music sales. MIS Q. 2014, 38, 101–121. [Google Scholar] [CrossRef]
- Allan J., K.; Philip J., K. WOM and social media: Presaging future directions for research and practice. J. Mark. Commun. 2014, 20, 5–20. [Google Scholar]
- Cui, G.; Lui, H.; Guo, X. The effect of online consumer reviews on new product sales. Int. J. Electron. Commer. 2012, 17, 39–57. [Google Scholar] [CrossRef]
- Chevalier, J.A.; Mayzlin, D. The effect of word of mouth on sales: Online book reviews. J. Mark. Res. 2006, 43, 345–354. [Google Scholar] [CrossRef]
- Duan, W.; Gu, B.; Whinston, A.B. Do online reviews matter?—An empirical investigation of panel data. Decis. Support Syst. 2008, 45, 1007–1016. [Google Scholar] [CrossRef]
- Clemons, E.K.; Gao, G.G.; Hitt, L.M. When online reviews meet the hyperdifferentiation: A study of craft beer industry. J. Manag. Inf. Syst. 2006, 23, 149–171. [Google Scholar] [CrossRef]
- Chintagunta, P.K.; Gopinath, S.; Venkataraman, S. The effects of online user reviews on movie box-office performance: Accounting for sequential rollout and aggregation across local markets. Mark. Sci. 2010, 29, 944–957. [Google Scholar] [CrossRef]
- Xu, H. Is More Information Better? An Economic Analysis of Group-Buying Platforms. J. Assoc. Inf. Syst. 2018, 19, 1130–1144. [Google Scholar] [CrossRef]
- Hansen, F. Consumer choice behavior: An experimental approach. J. Mark. Res. 1969, 6, 436–443. [Google Scholar] [CrossRef]
- Relling, M.; Schnittka, O.; Sattler, H.; Johnen, M. Each can help or hurt: Negative and positive word of mouth in social network brand communities. Int. J. Res. Mark. 2016, 33, 42–58. [Google Scholar] [CrossRef]
- Sweeney, J.C.; Soutar, G.N.; Mazzarol, T. Word of mouth: Measuring the power of individual messages. Eur. J. Mark. 2012, 46, 237–257. [Google Scholar] [CrossRef]
- Lin, Z.; Wang, Q. E-commerce product networks, word-of-mouth convergence, and product sales. J. Assoc. Inf. Syst. 2018, 18, 848–871. [Google Scholar] [CrossRef]
- Amblee, N.; Bui, T. Harnessing the influence of social proof in online shopping: The effect of electronic word of mouth on sales of digital microproducts. Int. J. Electron. Commer. 2011, 16, 91–114. [Google Scholar] [CrossRef]
- Liu, Y. Word of mouth for movies: Its dynamics and impact on box office revenue. J. Mark. 2006, 70, 74–89. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, X.; Chen, Y. Deciphering word-of-mouth in social media: Text-based metrics of consumer reviews. ACM Trans. Manag. Inf. Syst. 2012, 3, 1–23. [Google Scholar] [CrossRef]
- Chen, Y.; Xie, J. Online consumer review: Word-of-mouth as a new element of marketing communication mix. Manag. Sci. 2008, 54, 477–491. [Google Scholar] [CrossRef]
- Lee, C.; Jung, M. Predicting movie incomes using search engine query data. In Proceedings of the International Conference on Artificial Intelligence and Pattern Recognition, Kuala Lumpur, Malaysia, 17–19 November 2014; pp. 45–49. [Google Scholar]
- Bughin, J. Google searches and twitter mood: nowcasting telecom sales performance. NETNOMICS Econ. Res. Electron. Netw. 2015, 16, 87–105. [Google Scholar] [CrossRef]
- Wilkie, W.L.; Pessemier, E.A. Issues in marketing’s use of multi-attribute attitude models. J. Mark. Res. 1973, 10, 428. [Google Scholar] [CrossRef]
- Tirunillai, S.; Tellis, G.J. Mining marketing meaning from online chatter: Strategic brand analysis of big data using latent Dirichlet allocation. J. Mark. Res. 2014, 51, 463–479. [Google Scholar] [CrossRef]
- Guo, Y.; Barnes, S.J.; Jia, Q. Mining meaning from online ratings and reviews: Tourist satisfaction analysis using latent Dirichlet allocation. Tour. Manag. 2017, 59, 467–483. [Google Scholar] [CrossRef]
- Cheung, C.M.K.; Thadani, D.R. The impact of electronic word-of-mouth communication: A literature analysis and integrative model. Decis. Support Syst. 2012, 54, 461–470. [Google Scholar] [CrossRef]
- Duan, W.; Gu, B.; Whinston, A.B. The dynamics of online word-of-mouth and product sales-An empirical investigation of the movie industry. J. Retail. 2008, 84, 233–242. [Google Scholar] [CrossRef]
- Hur, M.; Kang, P.; Cho, S. Box-office forecasting based on sentiments of movie reviews and independent subspace method. Inf. Sci. 2016, 372, 608–624. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. Dynamic topic models. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 113–120. [Google Scholar]
- Guerini, M.; Gatti, L.; Turchi, M. Sentiment analysis: How to derive prior polarities from SentiWordNet. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1259–1269. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.; Ng, A.; Christopher, P. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Lash, M.T.; Zhao, K. Early predictions of movie success: The who, what, and when of profitability. J. Manag. Inf. Syst. 2016, 33, 874–903. [Google Scholar] [CrossRef]
- Schouten, K.; Frasincar, F. Survey on aspect-level sentiment analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 813–830. [Google Scholar] [CrossRef]
- Moon, S.; Bergey, P.K.; Iacobucci, D. Dynamic effects among movie ratings, movie revenues, and viewer satisfaction. J. Mark. 2010, 74, 108–121. [Google Scholar] [CrossRef]
- Kleinbaum, D.; Kupper, L.; Nizam, A.; Rosenberg, E. Applied Regresion Analysis and Other Multivariable Methods; Duxbury Press: Pacific Grove, CA, USA, 2013. [Google Scholar]
- Yu, X.; Liu, Y.; Huang, X.; An, A. Mining online reviews for predicting sales performance: A case study in the movie domain. IEEE Trans. Knowl. Data Eng. 2012, 24, 720–734. [Google Scholar] [CrossRef]
- Kraft, F.B.; Granbois, D.H.; Summers, J.O. Brand evaluation and brand choice: A longitudinal study. J. Mark. Res. 1973, 10, 235–241. [Google Scholar] [CrossRef]
- Lehmann, D.R. Television show preference: Application of a choice model. J. Mark. Res. 1971, 8, 47. [Google Scholar] [CrossRef]
Figure 1.
Framework for constructing the autoregressive heat-sentiment (ARHS) model.

Figure 2.
The relationship between online information and the box-office revenues of the movie Gravity. (a) The relationship between Google Trends and box-office revenues; (b) the relationship between the number of reviews and box-office revenues.
Figure 2.
The relationship between online information and the box-office revenues of the movie Gravity. (a) The relationship between Google Trends and box-office revenues; (b) the relationship between the number of reviews and box-office revenues.

Figure 3.
The structure of our review set.

Figure 4.
Average heat of the three dimensions for 122 movies. (a) The average heat of the dimension plot; (b) the average heat of dimension star; (c) the average heat of dimension genre.
Figure 4.
Average heat of the three dimensions for 122 movies. (a) The average heat of the dimension plot; (b) the average heat of dimension star; (c) the average heat of dimension genre.

Figure 5.
Average sentiments of the dimension for 122 movies.

Figure 6.
The effects of the parameters on prediction accuracy. (a) Effects of ; (b) effects of ; (c) effects of ; (d) effects of .
Figure 6.
The effects of the parameters on prediction accuracy. (a) Effects of ; (b) effects of ; (c) effects of ; (d) effects of .

Figure 7.
Comparison with the autoregressive prediction model.

Figure 8.
Comparisons of model accuracy. (a) Comparison of the eWOM model and the GSI model; (b) comparison of the GSI model and the ARHS model; (c) comparison of the eWOM model and the ARHS model; (d) comparison of the ARO model and the ARHS model.
Figure 8.
Comparisons of model accuracy. (a) Comparison of the eWOM model and the GSI model; (b) comparison of the GSI model and the ARHS model; (c) comparison of the eWOM model and the ARHS model; (d) comparison of the ARO model and the ARHS model.

Figure 9.
Comparison of different prediction intervals.

Figure 10.
Accuracy of models predicting opening-week revenues. (a) MAPE of the three models; (b) RMSE of the three models.
Figure 10.
Accuracy of models predicting opening-week revenues. (a) MAPE of the three models; (b) RMSE of the three models.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The diversity of movies.
| Distributor | Freq. | Genre | Freq. | Release Month | Freq. | MPAA Ratings | Freq. |
|---|---|---|---|---|---|---|---|
| Warner Bros. | 18 | Drama | 38 | January | 10 | R | 57 |
| Lionsgate | 16 | Comedy | 37 | February | 11 | PG-13 | 50 |
| Paramount | 12 | Thriller | 14 | March | 12 | PG | 14 |
| Weinstein | 10 | Action | 13 | April | 7 | NC-17 | 1 |
| Fox | 10 | Sci-Fi | 10 | May | 10 | Total | 122 |
| Sony | 9 | Horror | 9 | June | 6 | ||
| Universal | 7 | Animation | 8 | July | 7 | ||
| Open Road Films | 7 | Crime | 6 | August | 11 | ||
| Focus Features | 6 | Fantasy | 5 | September | 11 | ||
| Roadside Attractions | 6 | Adventure | 3 | October | 12 | ||
| FilmDistrict | 4 | Sports | 2 | November | 11 | ||
| Relativity | 4 | Music | 2 | December | 14 | ||
| Buena Vista | 4 | Romance | 2 | ||||
| CBS Films | 2 | Documentary | 1 | ||||
| Bleecker Street | 2 | War | 1 | ||||
| TriStar | 2 | ||||||
| A24 | 1 | ||||||
| Radius-TWC | 1 | ||||||
| Rogue Pictures | 1 |
Table 2.
The distribution of movie gross and budgets.
| Domestic Gross (Million) | Freq. | Production Budget (Million) | Freq. |
|---|---|---|---|
| ≤ 25 | 40 | ≤25 | 59 |
| 25–50 | 32 | 25–50 | 30 |
| 50–75 | 21 | 50–75 | 11 |
| 75–100 | 10 | 75–100 | 7 |
| 100–125 | 9 | 100–125 | 3 |
| 125–150 | 1 | 125–150 | 6 |
| 150–175 | 3 | 150–175 | 1 |
| 175–200 | 3 | 175–200 | 5 |
| 200–225 | 1 | Total | 122 |
| 225–250 | 1 | ||
| 250–275 | 1 |
Table 3.
Key variables for each movie: numerical.
| Variable | Description (for Each Movie) | Measure and Data Sources |
|---|---|---|
| Sales | Daily domestic box-office revenues | Dollars (log-transformation); BoxOfficeMojo.com |
| Daily number of reviews | Number (log-transformation); IMDb.com | |
| Daily valence of reviews | Average of daily ratings (0–10); IMDb.com | |
| Days from initial release | Number (1–49) | |
| Whether the day is on the weekend | 1 = the day is on the weekend (Fri, Sat, and Sun), 0 = others | |
| Daily number of cinemas | Number (log-transformation); BoxOfficeMojo.com | |
| Daily Google Trends of movie name | Number (0–100); Google.com |
Table 4.
Summary statistics of the key variables.
| Variable | Mean | Median | Maximum | Minimum | Std. Dev. | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| Sales | 1,039,207 | 263,875 | 35,167,017 | 10 | 2,204,483.7 | 5.351 | 46.855 |
| 22.11526 | 11 | 506 | 0 | 38.754737 | 3.956 | 26.541 | |
| 3.801627 | 4 | 10 | 0 | 3.6083277 | 0.162 | 1.410 | |
| 1483.412 | 1195 | 4324 | 1 | 1264.8718 | 0.343 | 1.634 | |
| 33.49281 | 28 | 100 | 2 | 21.922873 | 1.101 | 3.815 |
Table 5.
The change in words and the weight of the dimension plot.
| plot | weight | plot | weight | plot | weight |
|---|---|---|---|---|---|
| story | 0.9% | plot | 0.5% | plot | 0.5% |
| plot | 0.4% | story | 0.4% | story | 0.4% |
| book | 0.4% | book | 0.3% | book | 0.4% |
| horror | 0.3% | horror | 0.3% | horror | 0.3% |
| dark | 0.2% | dark | 0.3% | dark | 0.2% |
| original | 0.3% | original | 0.2% | original | 0.2% |
| scary | 0.2% | scary | 0.2% | scary | 0.2% |
| real | 0.2% | maze | 0.2% | maze | 0.2% |
| pretty | 0.2% | pretty | 0.2% | pretty | 0.2% |
| action | 0.2% | love | 0.2% | house | 0.2% |
Table 6.
The main rules for mining the sentiments of dimension words.
| Syntax Relations | Examples | Word Sentiments |
|---|---|---|
| Nominal subject | The plot is boring. | Plot: 3.0 |
| Adjectival modifier | She is a good actor. | Actor: 3.8612 |
| Direct object | I enjoy 3D. | 3D: 3.9782 |
| Open clausal complement | I think the actor enjoys acting. | Acting: 3.9782 |
| Adverb modifier | Tom performed earnestly. | Perform: 3.5 |
| Relative clause modifier | I saw an actor who people dislike. | Actor: 3.5417 |
Table 7.
Key variables for each movie: dimensions.
| Variable | Description | Measures |
|---|---|---|
| The heat of the dimension plot on day t | Probabilistic | |
| The heat of the dimension star on day t | Probabilistic | |
| The heat of the dimension genre on day t | Probabilistic | |
| The sentiment of the dimension plot on day t | Numerical value | |
| The sentiment of the dimension star on day t | Numerical value | |
| The sentiment of the dimension genre on day t | Numerical value |
Table 8.
Summary statistics of the dimension variables.
| Variable | Mean | Median | Maximum | Minimum | Std. Dev. | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| 0.26932 | 0.00971 | 0.9999957 | 1.93 × 10−6 | 0.4063216 | 1.082 | 2.284 | |
| 0.13574 | 0.00971 | 0.9999957 | 2.16 × 10−6 | 0.3078812 | 2.184 | 5.992 | |
| 0.59495 | 0.95943 | 0.9999949 | 1.43 × 10−6 | 0.4544953 | −0.426 | 1.250 | |
| 3.07341 | 3 | 4.83333 | 0.130435 | 0.3685301 | −3.347 | 28.987 | |
| 3.09445 | 3 | 4.90476 | 0.130435 | 0.3519009 | −2.837 | 28.437 | |
| 3.08610 | 3 | 4.60417 | 0.130435 | 0.299457 | −3.282 | 35.261 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lyu, X.; Jiang, C.; Ding, Y.; Wang, Z.; Liu, Y. Sales Prediction by Integrating the Heat and Sentiments of Product Dimensions. Sustainability 2019, 11, 913. https://doi.org/10.3390/su11030913
AMA Style
Lyu X, Jiang C, Ding Y, Wang Z, Liu Y. Sales Prediction by Integrating the Heat and Sentiments of Product Dimensions. Sustainability. 2019; 11(3):913. https://doi.org/10.3390/su11030913
Chicago/Turabian StyleLyu, Xiaozhong, Cuiqing Jiang, Yong Ding, Zhao Wang, and Yao Liu. 2019. "Sales Prediction by Integrating the Heat and Sentiments of Product Dimensions" Sustainability 11, no. 3: 913. https://doi.org/10.3390/su11030913
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.