Influential Factors on Injury Severity for Drivers of Light Trucks and Vans with Machine Learning Methods

 , , and
, , and
Abstract
:
1. Introduction
2. Literature Review
3. Materials and Methods
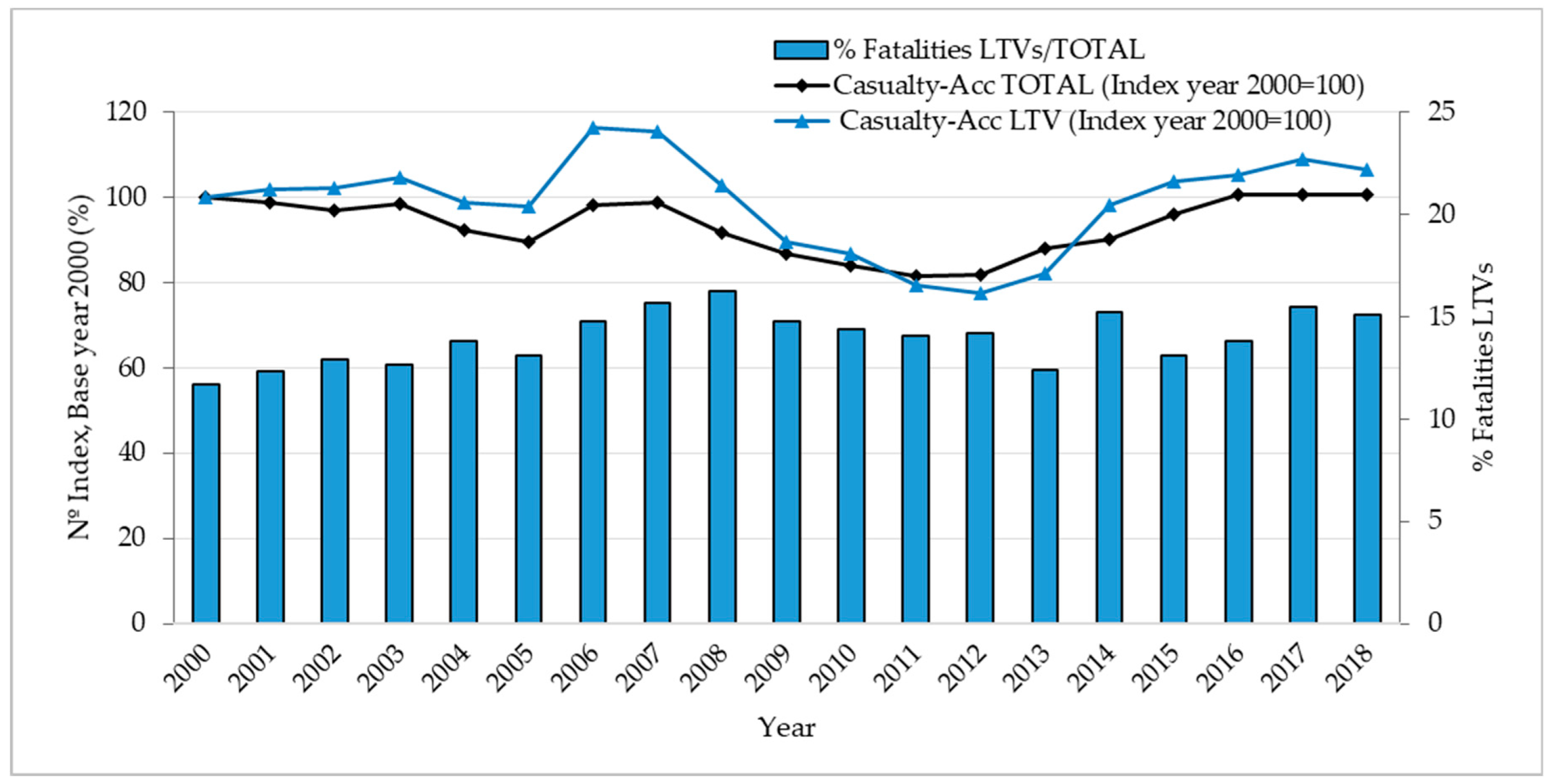
3.1. Data Description
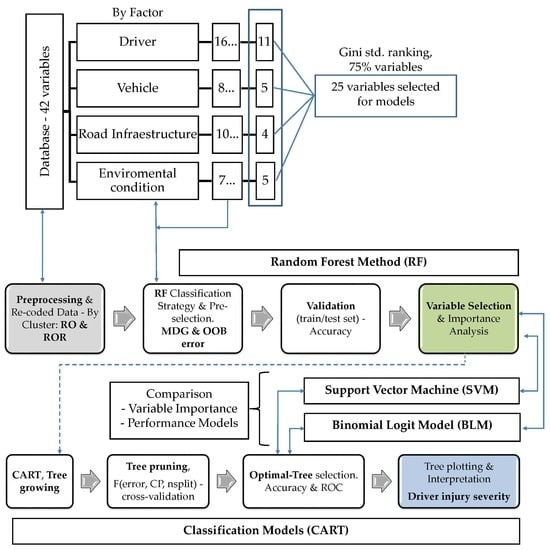
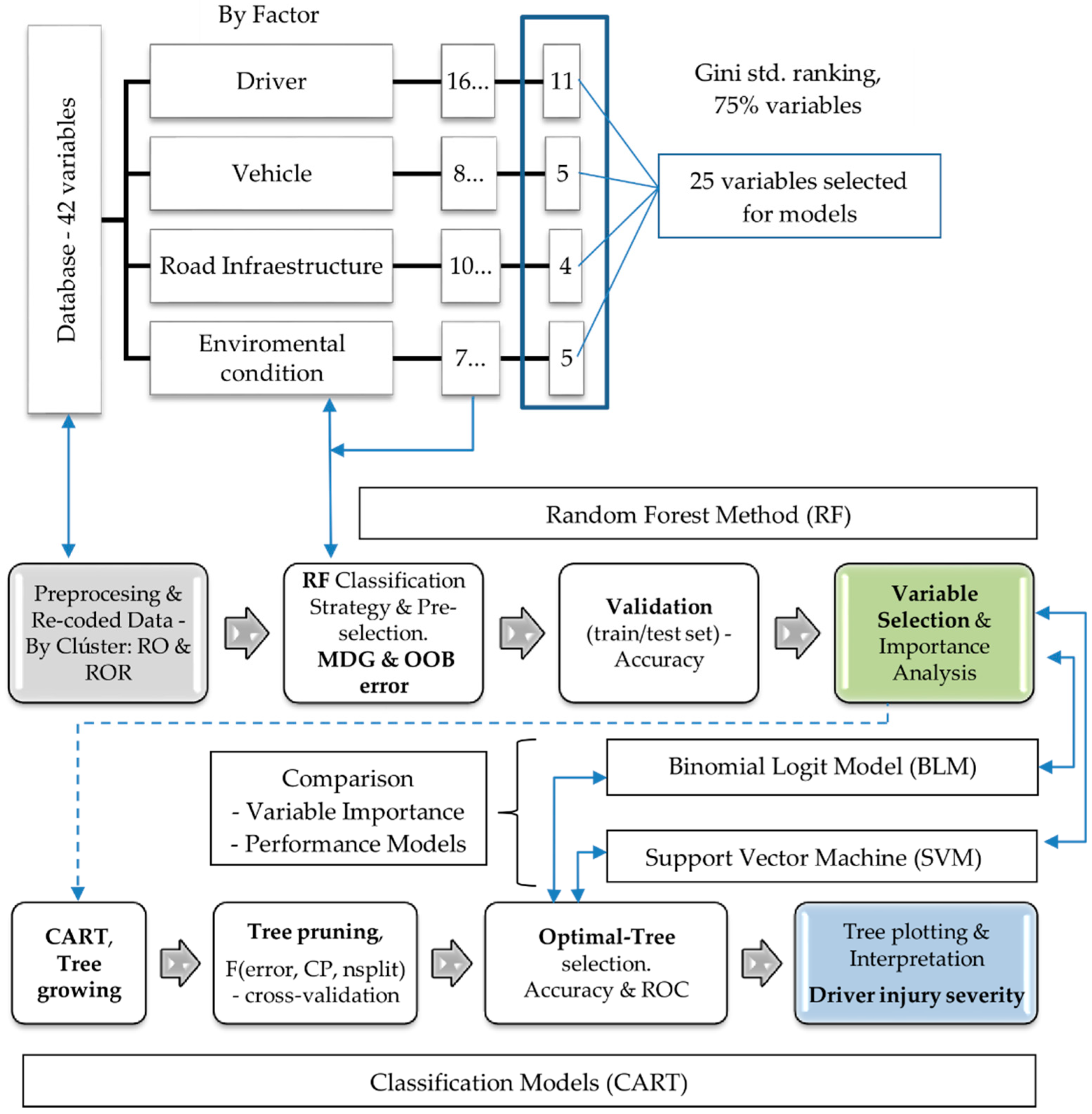
3.2. Methodology: An RF+CART Approach for LTV Driver-Injury Severity
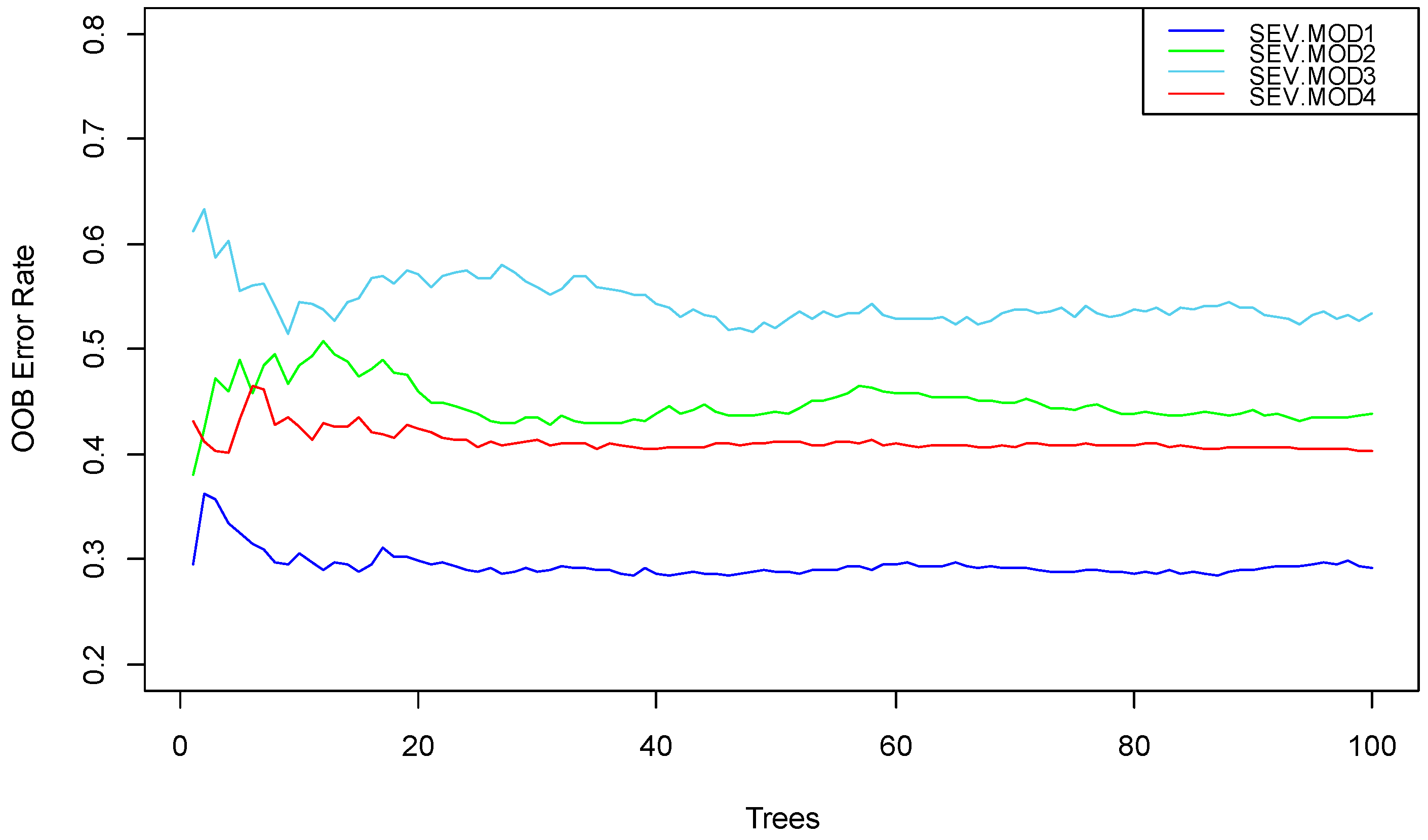
3.2.1. Random Forest Method—Variable Importance Ranking and Variable Selection
- Generate a bootstrap sample of size Nc from the overall data N to grow a treeB by randomly selecting the predictors X = {xi, i = 1, …, I} (this bootstrap sample will be identified as a cluster).
- Use the predictor xi at the node n of the treeB to vote for class label kB in this node. At each node, the sample is refined until obtaining the best predictor for the split.
- Run the out-of-bag (OOB) data (N-Nc) down the treeB to obtain the misclassification rate, and OOBERB is selected.
- Repeat (1–2–3) for a large number of trees until the minimum out-of-bag error rate, OOBERB, is obtained.
- Assign each observation to a final class k through a majority vote by averaging over the set of trees.
3.2.2. Classification Tree Model (CART)
3.3. The Contrasting Purposes of Models
3.3.1. Binary Logit Model (BLM)
3.3.2. Support Vector Machine (SVM)
3.4. Performance of Classification Models
4. Results
4.1. Analysis of the Importance of the Variables
4.2. CART Models
4.2.1. Driver Injury Severity in a Rollover (RO Collision)
- SEATBELT: Safety belt use/non-use.
- ROADFUN: Urban/rural roads.
- PSYCHOP: Psychophysical driver condition.
- AGE: Age.
- LANEWD: Road lane width.
- LTV: Type of vehicle.
- OCUPANT: Number of passengers.
- SEASON: Season of the year.
- PLANTRIP: Planning a trip.
- HOUR: Hour of the accident occurrence.
- BODYINJURY: Injury localization.
4.2.2. Driver Injury Severity by Run-Off-Roadway (ROR Collision)
- SEATBELT: Safety belt use/non-use.
- PSYCHOP: Psychophysical driver conditions.
- BODYINJURY: Injury location.
- SEASON: Season of the year.
- AGELTV: Age of the vehicle.
- TRIPPURP: Trip purpose.
4.3. Performance Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- United Nations (UN). Transforming our World: The 2030 Agenda for Sustainable Development. Available online: https://sustainabledevelopment.un.org/post2015/summit (accessed on 5 December 2019).
- World Health Organization. Decade of Action for Road Safety 2011–2020. Available online: http://www.who.int/roadsafety/decade_of_action/en/ (accessed on 18 November 2019).
- World Health Organization (WHO). Road Traffic Injuries. 2018. Available online: http://www.who.int/mediacentre/factsheets/fs358/en/ (accessed on 17 November 2019).
- United Nations (UN). Special Edition: Progress towards the Sustainable Development Goals. 2019. Available online: https://sustainabledevelopment.un.org/sdgsummit#documentation (accessed on 5 December 2019).
- Directorate General of Traffic (DGT). Las Principales Cifras de la Siniestralidad Vial. España. 2018. Available online: http://www.dgt.es/es/seguridad-vial/estadisticas-e-indicadores/publicaciones/principales-cifras-siniestralidad/ (accessed on 18 November 2019).
- World Health Organization (WHO). Global Status Report on Road Safety 2015. Available online: http://www.who.int/violence_injury_prevention/road_safety_status/2015/en/ (accessed on 18 November 2019).
- Instituto para la Diversificación y Ahorro de la Energía, (IDAE). Plan Nacional Integrado de Energía y Clima 2021–2030 (PNIEC) España. Available online: https://energia.gob.es/es-es/Participacion/Paginas/PNIEC.aspx (accessed on 10 January 2020).
- Transport & Environment. Emission Reduction Strategies for the Transport Sector in Spain. Available online: https://www.transportenvironment.org/publications/emission-reduction-strategies-transport-sector-spain (accessed on 10 January 2020).
- European Commission. A Clean Planet for all A European strategic Long-Term Vision for a Prosperous, modern, Competitive and Climate Neutral Economy COM/2018/773. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52018DC0773 (accessed on 10 January 2020).
- Development and application of an integrated methodology for the study of road accidents with involvement of vans of the Spanish national research plan 2008–2011. Available online: http://insia-upm.es/portfolio-items/proyecto-furgoseg/?lang=en (accessed on 2 September 2019).
- Aparicio, F.; Arenas, B. An integrated methodology for the scientific research of road accidents. Gen. Overv. Secur. Vialis 2017, 9, 57–67. [Google Scholar] [CrossRef]
- Automotive Studies Institute. Intern report FURGOSEG project. Available online: http://www.ideauto.es/ (accessed on 2 September 2019).
- Dadashova, B.; Arenas, B.; Mira, J.; Izquierdo, F. Explanatory and prediction power of two macro models. An application to van-involved accidents in Spain. Transp. Policy 2014, 32, 203–217. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- The R Foundation. R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 30 November 2019).
- Savolainen, P.T.; Mannering, F.L.; Lord, D.; Quddus, M.A. The statistical analysis of highway crash-injury severities: A review and assessment of methodological alternatives. Accid. Anal. Prev. 2011, 43, 1666–1676. [Google Scholar] [CrossRef]
- Mannering, F.L.; Bhat, C.R. Analytic methods in accident research: Methodological frontier and future directions. Anal. Methods Accid. Res. 2014, 1, 1–22. [Google Scholar] [CrossRef]
- Toy, E.L.; Hammitt, J.K. Safety impacts of SUVs, vans, and pickup trucks in two-vehicle crashes. Risk Anal. 2003, 23, 641–650. [Google Scholar] [CrossRef]
- Kononen, D.W.; Flannagan, C.A.C.; Wang, S.C. Identification and validation of a logistic regression model for predicting serious injuries associated with motor vehicle crashes. Accid. Anal. Prev. 2011, 43, 112–122. [Google Scholar] [CrossRef]
- Zhu, X.; Srinivasan, S. A comprehensive analysis of factors influencing the injury severity of large-truck crashes. Accid. Anal. Prev. 2011, 43, 49–57. [Google Scholar] [CrossRef]
- Khorashadi, A.; Niemeier, D.; Shankar, V.; Mannering, F. Differences in rural and urban driver-injury severities in accidents involving large-trucks: An exploratory analysis. Accid. Anal. Prev. 2005, 37, 910–921. [Google Scholar] [CrossRef]
- Ulfarsson, G.F.; Mannering, F.L. Differences in male and female injury severities in sport-utility vehicle, minivan, pickup and passenger car accidents. Accid. Anal. Prev. 2004, 36, 135–147. [Google Scholar] [CrossRef]
- Behnood, A.; Mannering, F. The effect of passengers on driver-injury severities in single-vehicle crashes: A random parameters heterogeneity-in-means approach. Anal. Methods Accid. Res. 2017, 14, 41–53. [Google Scholar] [CrossRef]
- Li, Z.; Ci, Y.; Chen, C.; Zhang, G.; Wu, Q.; Qian, Z.; Prevedouros, P.D.; Ma, D.T. Investigation of driver injury severities in rural single-vehicle crashes under rain conditions using mixed logit and latent class models. Accid. Anal. Prev. 2019, 124, 219–229. [Google Scholar] [CrossRef]
- Delen, D.; Sharda, R.; Bessonov, M. Identifying significant predictors of injury severity in traffic accidents using a series of artificial neural networks. Accid. Anal. Prev. 2006, 38, 434–444. [Google Scholar] [CrossRef]
- Chang, L.; Wang, H. Analysis of traffic injury severity: An application of non-parametric classification tree techniques. Accid. Anal. Prev. 2006, 38, 1019–1027. [Google Scholar] [CrossRef]
- Chang, L.; Chien, J. Analysis of driver injury severity in truck-involved accidents using a non-parametric classification tree model. Saf. Sci. 2013, 51, 17–22. [Google Scholar] [CrossRef]
- Das, A.; Abdel-Aty, M.; Pande, A. Using conditional inference forests to identify the factors affecting crash severity on arterial corridors. J. Saf. Res. 2009, 40, 317–327. [Google Scholar] [CrossRef] [Green Version]
- Abellan, J.; Lopez, G.; de Ona, J. Analysis of traffic accident severity using Decision Rules via Decision Trees. Expert Syst. Appl. 2013, 40, 6047–6054. [Google Scholar] [CrossRef] [Green Version]
- De Oña, J.; López, G.; Abellán, J. Extracting decision rules from police accident reports through decision trees. Accid. Anal. Prev. 2013, 50, 1151–1160. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Zhang, X.; Zhang, S.; Li, Z.; Liu, X. Analysis of Factors Affecting Real-Time Ridesharing Vehicle Crash Severity. Sustainability 2019, 11, 3334. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.; Li, X. Predicting Driver Injury Severity in Single-Vehicle and Two-Vehicle Crashes with Boosted Regression Trees. Transp. Res. Rec. 2015, 2514, 138–148. [Google Scholar] [CrossRef]
- Wu, J.; Xu, H. Driver behavior analysis on rural 2-lane, 2-way highways using SHRP 2 NDS data. Traffic Inj. Prev. 2018, 19, 838–843. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, G.; Qian, Z.; Tarefder, R.A.; Tian, Z. Investigating driver injury severity patterns in rollover crashes using support vector machine models. Accid. Anal. Prev. 2016, 90, 128–139. [Google Scholar] [CrossRef]
- Zhu, M.; Li, Y.; Wang, Y. Design and experiment verification of a novel analysis framework for recognition of driver injury patterns: From a multi-class classification perspective. Accid. Anal. Prev. 2018, 120, 152–164. [Google Scholar] [CrossRef]
- Mafi, S.; AbdelRazig, Y.; Doczy, R. Machine Learning Methods to Analyze Injury Severity of Drivers from Different Age and Gender Groups. Transp. Res. Rec. 2018, 2672, 171–183. [Google Scholar] [CrossRef]
- Theofilatos, A.; Chen, C.; Antoniou, C. Comparing Machine Learning and Deep Learning Methods for Real-Time Crash Prediction. Transp. Res. Rec. 2019, 2673, 169–178. [Google Scholar] [CrossRef]
- Tavakoli Kashani, A.; Shariat-Mohaymany, A.; Ranjbari, A. A data mining approach to identify key factors of traffic injury severity. PROMET-Traffic Transp. 2011, 23, 11–17. [Google Scholar] [CrossRef] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Grömping, U. Variable importance assessment in regression: Linear regression versus random forest. Am. Stat. 2009, 63, 308–319. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Fernandez-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Al-Ghamdi, A.S. Using logistic regression to estimate the influence of accident factors on accident severity. Accid. Anal. Prev. 2002, 34, 729–741. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Cioca, L.; Ivascu, L. Risk Indicators and Road Accident Analysis for the Period 2012–2016. Sustainability 2017, 9, 1530. [Google Scholar] [CrossRef] [Green Version]
- Laureshyn, A.; Svensson, Å.; Hydén, C. Evaluation of traffic safety, based on micro-level behavioural data: Theoretical framework and first implementation. Accid. Anal. Prev. 2010, 42, 1637–1646. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Zhang, G.; Zhu, X.; Liu, X.C.; Tarefder, R. Analysis of driver injury severity in single-vehicle crashes on rural and urban roadways. Accid. Anal. Prev. 2016, 94, 35–45. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.C.; Lee, A.H.; Cameron, D.; Li-Tsang, C. Using a driving simulator to identify older drivers at inflated risk of motor vehicle crashes. J. Saf. Res. 2003, 34, 453–459. [Google Scholar] [CrossRef] [PubMed]
- Jeong, H.; Jang, Y.; Bowman, P.J.; Masoud, N. Classification of motor vehicle crash injury severity: A hybrid approach for imbalanced data. Accid. Anal. Prev. 2018, 120, 250–261. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Categories | Code | Driver Injury Severity | ||||
|---|---|---|---|---|---|---|---|
| DKSI: Driver Killed and Seriously Injured | % | DSI: Driver Slightly Injured | % | Total | |||
| SEVERITY: Driver Injury Severity | DKSI/DSI | 2076 | 22.93% | 6976 | 77.07% | 9052 | |
| ACCTYPE: collision type | |||||||
| Rollover | RO | 711 | 20.64% | 2734 | 79.36% | 3445 | |
| Run-Off-Roadway | ROR | 1365 | 24.34% | 4242 | 75.66% | 5607 | |
| Explanatory variables | |||||||
| Driver Characteristics | |||||||
| TRIPPURP: trip purpose | |||||||
| Within work | WW | 886 | 23.27% | 2922 | 76.73% | 3808 | |
| Non-work related | NW | 260 | 25.59% | 756 | 74.41% | 1016 | |
| Leisure time | LT | 921 | 23.79% | 2951 | 76.21% | 3872 | |
| ACTION: action of driver | |||||||
| Go straight | GOS | 1933 | 24.17% | 6063 | 75.83% | 7996 | |
| Stop | STP | 4 | 1.61% | 245 | 98.39% | 249 | |
| Overtaking | OVT | 67 | 18.46% | 296 | 81.54% | 363 | |
| Sudden maneuver | SM | 15 | 9.74% | 139 | 90.26% | 154 | |
| Other | OT | 47 | 18.22% | 211 | 81.78% | 258 | |
| LICENSE: driver license | |||||||
| Type B | B | 1842 | 24.08% | 5806 | 75.92% | 7648 | |
| With restriction | WR | 226 | 16.74% | 1124 | 83.26% | 1350 | |
| Other | OT | 7 | 13.73% | 44 | 86.27% | 51 | |
| PSYCHOP: psychophysical conditions | |||||||
| With defects | WD | 1415 | 20.60% | 5453 | 79.40% | 6868 | |
| Without defects | WOD | 194 | 18.56% | 851 | 81.44% | 1045 | |
| Unknown | UKN | 467 | 41.00% | 672 | 59.00% | 1139 | |
| INFSPEED: infractions for speeding | |||||||
| Infraction | INF | 716 | 23.28% | 2360 | 76.72% | 3076 | |
| No infraction | NINF | 883 | 21.87% | 3154 | 78.13% | 4037 | |
| Unknown | UKN | 477 | 24.60% | 1462 | 75.40% | 1939 | |
| INFDRIV: driver’s infractions | |||||||
| Distraction | DIST | 461 | 20.80% | 1755 | 79.20% | 2216 | |
| Infraction | INF | 345 | 16.02% | 1809 | 83.98% | 2154 | |
| No infraction | NINF | 1270 | 27.24% | 3393 | 72.76% | 4663 | |
| PLANTRIP: Planned trip (km) | |||||||
| <50 | <50 | 922 | 24.16% | 2895 | 75.84% | 3817 | |
| 50–200 | 50–200 | 615 | 24.12% | 1935 | 75.88% | 2550 | |
| >200 | >200 | 289 | 23.55% | 938 | 76.45% | 1227 | |
| Unknown | UKN | 250 | 17.15% | 1208 | 82.85% | 1458 | |
| SEATBELT: driver seatbelt use | |||||||
| Seatbelt is used—YES | YES | 1313 | 19.17% | 5537 | 80.83% | 6850 | |
| Seatbelt not used—NO | NO | 600 | 46.51% | 690 | 53.49% | 1290 | |
| Unknown | UKN | 163 | 17.87% | 749 | 82.13% | 912 | |
| BODYINJURY: location of serious injury | |||||||
| Upper body | UP | 705 | 25.88% | 2019 | 74.12% | 2724 | |
| Center | C | 523 | 24.76% | 1589 | 75.24% | 2112 | |
| Lower body | LW | 240 | 42.33% | 327 | 57.67% | 567 | |
| Whole body | WB | 291 | 43.56% | 377 | 56.44% | 668 | |
| Unknown | UKN | 291 | 13.76% | 1824 | 86.24% | 2115 | |
| AGE: driver age | |||||||
| <25 | <25 | 345 | 19.87% | 1391 | 80.13% | 1736 | |
| 25–35 | 25–35 | 648 | 20.88% | 2455 | 79.12% | 3103 | |
| 36–60 | 36–60 | 903 | 25.22% | 2677 | 74.78% | 3580 | |
| >60 | >60 | 180 | 28.44% | 453 | 71.56% | 633 | |
| GENDER: driver gender | |||||||
| Male | M | 1903 | 23.25% | 6281 | 76.75% | 8184 | |
| Female | F | 173 | 19.93% | 695 | 80.07% | 868 | |
| Vehicle Characteristics | |||||||
| AGELTV: vehicle age | |||||||
| <2 | <2 | 657 | 24.34% | 2042 | 75.66% | 2699 | |
| 3–5 | 3–5 | 431 | 22.34% | 1498 | 77.66% | 1929 | |
| 6–10 | 6–10 | 479 | 24.06% | 1512 | 75.94% | 1991 | |
| >10 | >10 | 459 | 25.43% | 1346 | 74.57% | 1805 | |
| CONDICLTV: condition of vehicle | |||||||
| With defects | WD | 79 | 21.01% | 297 | 78.99% | 376 | |
| Without defects | WOD | 1951 | 22.91% | 6564 | 77.09% | 8515 | |
| Unknown | UKN | 46 | 28.57% | 115 | 71.43% | 161 | |
| LTV: group of light trucks and vans | |||||||
| Pick-up | G1 | 59 | 30.26% | 136 | 69.74% | 195 | |
| Chassis-cabin truck | G2 | 289 | 22.39% | 1002 | 77.61% | 1291 | |
| Van and combi | G3 | 868 | 23.16% | 2880 | 76.84% | 3748 | |
| Passenger car-derived vehicle | G4 | 860 | 22.52% | 2958 | 77.48% | 3818 | |
| OCUPANT: occupants involved | |||||||
| 1 | 1 | 1466 | 26.74% | 4017 | 73.26% | 5483 | |
| 2–3 | 2–3 | 519 | 17.57% | 2435 | 82.43% | 2954 | |
| 4–9 | 4–9 | 88 | 15.09% | 495 | 84.91% | 583 | |
| Unknown | UKN | 3 | 9.38% | 29 | 90.62% | 32 | |
| GROSSW: gross vehicle weight (kg) | |||||||
| <1500 | <1500 | 274 | 27.29% | 730 | 72.71% | 1004 | |
| 1500–1999 | 1500–2000 | 677 | 21.08% | 2535 | 78.92% | 3212 | |
| 2000–2499 | 2000–2500 | 228 | 25.19% | 677 | 74.81% | 905 | |
| 2500–3000 | 2500–3000 | 317 | 24.73% | 965 | 75.27% | 1282 | |
| >3000 | >3000 | 580 | 21.90% | 2069 | 78.10% | 2649 | |
| Road Infrastructure Characteristics | |||||||
| ROADFUN: road function | |||||||
| Urban | URB | 93 | 16.01% | 488 | 83.99% | 581 | |
| Rural | RUR | 1983 | 23.41% | 6488 | 76.59% | 8471 | |
| LANEWD: lane width (m) | |||||||
| <3.25 | <3.25 | 470 | 27.68% | 1228 | 72.32% | 1698 | |
| 3.25–3.75 | 3.25–3.75 | 1489 | 23.11% | 4954 | 76.89% | 6443 | |
| >3.75 | >3.75 | 113 | 21.24% | 419 | 78.76% | 532 | |
| SHOULDR: shoulder type, width (m) | |||||||
| Non-existent or impassable | NE | 608 | 21.70% | 2194 | 78.30% | 2802 | |
| <1.5 | <1.5 | 710 | 24.24% | 2219 | 75.76% | 2929 | |
| 1.5–2.49 | 1.5–2.5 | 663 | 22.71% | 2256 | 77.29% | 2919 | |
| >2.5 | >2.5 | 94 | 24.87% | 284 | 75.13% | 378 | |
| ACCLOC: accident location—road curvature or intersection | |||||||
| Straight road | SR | 954 | 22.96% | 3201 | 77.04% | 4155 | |
| Curve road | CR | 1003 | 23.41% | 3281 | 76.59% | 4284 | |
| At Intersection with street | IS | 26 | 15.57% | 141 | 84.43% | 167 | |
| At Intersection with highway | IH | 93 | 20.85% | 353 | 79.15% | 446 | |
| Environmental Conditions | |||||||
| VISIBLTY: sight distance | |||||||
| Restriction: building, topography, atmospheric, other | VR | 404 | 23.95% | 1283 | 76.05% | 1687 | |
| Without restriction | OKV | 1670 | 23.88% | 5322 | 76.12% | 6992 | |
| LIGHT: lighting condition | |||||||
| Daylight, sufficient (night) | DLS | 1244 | 20.89% | 4711 | 79.11% | 5955 | |
| Dusk, insufficient, without lighting (night) | INL | 832 | 26.86% | 2265 | 73.14% | 3097 | |
| WEATHER: weather | |||||||
| Sunny | SUN | 1681 | 24.00% | 5323 | 76.00% | 7004 | |
| Adverse | ADV | 395 | 19.29% | 1653 | 80.71% | 2048 | |
| HOUR: crash time | |||||||
| 00:00–05:59 | 0–6 | 288 | 27.56% | 757 | 72.44% | 1045 | |
| 07:00–11:59 | 6–12 | 594 | 20.94% | 2242 | 79.06% | 2836 | |
| 12:00–17:59 | 12–18 | 627 | 21.22% | 2328 | 78.78% | 2955 | |
| 18:00–23:59 | 18–24 | 526 | 25.35% | 1549 | 74.65% | 2075 | |
| SEASON: month—season | |||||||
| Autumn | AUT | 510 | 23.09% | 1699 | 76.91% | 2209 | |
| Spring | SPR | 521 | 23.56% | 1690 | 76.44% | 2211 | |
| Summer | SUM | 557 | 21.37% | 2050 | 78.63% | 2607 | |
| Winter | WIN | 488 | 24.10% | 1537 | 75.90% | 2025 | |
| Variable | RF | BLM * | SVM (Kernel RBF) | |||
|---|---|---|---|---|---|---|
| MDG Nrm (%) | MDA Nrm (%) | Coef. B | Pr | OR | Metric | |
| SEATBELT | 100.00 | 100.00 | −1.26 (YES) | 0.0000 ** | 3.57 | 0.551 |
| BODYINJURY | 50.68 | 73.90 | 0.79 (LW) | 0.0000 ** | 2.19 | 0.082 |
| PSYCHOP | 24.28 | 55.62 | −1.18 (WOD) | 0.0000 ** | 3.22 | 0.034 |
| AGE | 11.80 | 19.71 | 0.47 ([>60]) | 0.0000 ** | 1.61 | 0.014 |
| OCUPANT | 11.34 | 23.00 | 0.17 ([1]) | 0.0065 ** | 1.19 | 0.025 |
| ACTION | 10.08 | 19.29 | - | 0.1026 | - | 0.018 |
| ROADFUN | 9.12 | 29.02 | −0.50 (URB) | 0.0005 ** | 1.64 | 0.110 |
| ACCLOC | 7.86 | 23.28 | - | 0.9167 | - | 0.017 |
| INFDRIV | 7.1 | 22.58 | −0.406 (NINF) | 0.0000 ** | 1.50 | 0.007 |
| LTV | 5.87 | 4.43 | - | 0.3397 | - | 0.024 |
| Variable | RF | BLM * | SVM (Kernel RBF) | |||
|---|---|---|---|---|---|---|
| MDG Nrm (%) | MDA Nrm (%) | Coef. B | Pr | OR | Metric | |
| SEATBELT | 62.04 | 100.00 | −1.11 (YES) | 0.0000 ** | 3.03 | 0.4860 |
| PSYCHOP | 48.26 | 60.02 | −1.17 (WOD) | 0.0000 ** | 3.22 | 0.1360 |
| BODYINJURY | 100.00 | 87.25 | 0.87 (LW) | 0.0000 ** | 2.38 | 0.1650 |
| SEASON | 69.43 | 3.92 | - | 0.9129 | - | 0.0220 |
| AGELTV | 65.14 | - | 0.32 (>10) | 0.0072 ** | 1.38 | 0.0040 |
| TRIPPURP | 41.76 | - | - | 0.9754 | - | 0.0280 |
| HOUR | 58.62 | 6.00 | - | 0.8692 | - | 0.0010 |
| PLANTRIP | 58.52 | 6.20 | - | 0.4117 | - | 0.0010 |
| ACCLOC | 40.58 | 9.06 | - | 0.6063 | - | 0.0050 |
| INFDRIV | 38.29 | 16.57 | 0.31 (NINF) | 0.0062 ** | 1.37 | 0.0150 |
| OCUPANT | 33.31 | 10.25 | - | 0.9039 | - | 0.0080 |
| RO-Type | RF | CART | BLM | SVM |
|---|---|---|---|---|
| Accuracy | 0.7740 | 0.7807 | 0.7919 | 0.7908 |
| Sensitivity | 0.5714 | 0.4051 | 0.6571 | 0.7083 |
| Specificity | 0.7824 | 0.7976 | 0.7974 | 0.7931 |
| ROC area | 0.6580 | 0.6397 | 0.7264 | 0.6561 |
| ROR-Type | ||||
| Accuracy | 0.7325 | 0.7705 | 0.7384 | 0.7428 |
| Sensitivity | 0.7549 | 0.7611 | 0.7462 | 0.7435 |
| Specificity | 0.5805 | 0.5081 | 0.6552 | 0.7333 |
| ROC area | 0.6738 | 0.6242 | 0.7065 | 0.7042 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pillajo-Quijia, G.; Arenas-Ramírez, B.; González-Fernández, C.; Aparicio-Izquierdo, F. Influential Factors on Injury Severity for Drivers of Light Trucks and Vans with Machine Learning Methods. Sustainability 2020, 12, 1324. https://doi.org/10.3390/su12041324
Pillajo-Quijia G, Arenas-Ramírez B, González-Fernández C, Aparicio-Izquierdo F. Influential Factors on Injury Severity for Drivers of Light Trucks and Vans with Machine Learning Methods. Sustainability. 2020; 12(4):1324. https://doi.org/10.3390/su12041324
Chicago/Turabian StylePillajo-Quijia, Giovanny, Blanca Arenas-Ramírez, Camino González-Fernández, and Francisco Aparicio-Izquierdo. 2020. "Influential Factors on Injury Severity for Drivers of Light Trucks and Vans with Machine Learning Methods" Sustainability 12, no. 4: 1324. https://doi.org/10.3390/su12041324