1. Introduction
A large amount of energy is required for thermal production across manufacturing industries. In particular, the cement industry requires thermal heat production through the calcination process. Traditionally, coal is used as fuel to feed the calciner in cement plants. A calciner is a steel cylinder located within a furnace. With a controlled atmosphere, it performs indirect high-temperature raw fuel processing (550–1150 °C) by rotating inside a heated furnace. This fuel is usually dumped in the furnace at an elevated height using bucket elevator technology. An example of such a system can be seen in
Figure 1. For structural reasons, bucket elevator technology is the only viable vertical conveying option for feeding the calciner with fuel in most cement plants. With sustainability and resource conservation, there is an increasing trend towards the substitution of classical fossil fuels, such as coal or gas, by Alternative Fuel Resources (AFRs) across the process industry [
1]. Some of these fuel particles that have been considered include materials such as wood straws, rubber granules, paper waste, wood chips, etc.
The solid waste or AFRs have calorific values that are sufficient to generate the heat needed for the calcination process. Also, high temperatures in the calciner facilitate the complete combustion of these waste products, which minimizes the chances of harmful emissions. The combustion of AFRs results in a byproduct in the form of residual ash. This ash has transformative potential in the cement manufacturing process, as discussed in [
2]. The ash exhibits pozzolanic properties. The durable cement compounds are formed when lime is combined with pozzolan materials. Here, the ash byproduct can be used as an alternative raw material for cement manufacturing. The ash could also replace clinker, another raw material for cement manufacturing, thereby contributing to a significant reduction in CO2 emissions.
The usage of AFRs for cement production at the stage of the cement combustion process has been explored in [
3]. It provided a detailed study of actively monitoring a multi-fuel burner using traditional image analysis concepts for the use of AFRs dynamically in energy production. However, the problem of optimizing an AFR material infeed for such a burner remained an open question. Biomass or waste streams are the primary sources to procure these AFRs. And, as such, they possess inhomogeneous bulk material characteristics, such as humidity, density, and particle size distribution. Although the usage of such materials is environmentally favorable, conventional bucket elevators are not suitable, with the often fluffy and inhomogeneous substitute fuels, to efficiently feed these materials in heat furnaces. The inhomogeneous characteristics of AFRs lead to discharge parabolas of these materials varying over the sample that is discharged. Hence, a need arises to observe these trajectories and estimate a method for their optimal discharge. This article, therefore, aims to develop an intelligent high-performance bucket elevator. The idea is to optimize the speed of the bucket elevator intelligently. A reinforcement learning (RL) algorithm controlled by a vision-based reward function is proposed to achieve this goal. However, training an RL algorithm requires a large amount of quality data. Acquiring high-quality data in large volumes with an actual bucket elevator requires operating the machine multiple times, which is a cumbersome process that leads to high energy consumption along with potential wear and tear on the system. An alternative approach is to collect data from a simulation that replicates the behavior of the system and transfer the learning from the virtual experience to the real world. As such, the research is carried out by optimizing the bucket elevator simulation based on the software coupling of Computational Fluid Dynamics (CFD) and the discrete element method (DEM). The ability to numerically calculate finite element particle displacements and rotations and to automatically perform contact detection for a group of different particle types is called the discrete element method [
4]. The DEM uses Newton’s laws of motion and numerical integration for background computation purposes. As such, the software is capable of calculating forces acting on particles and, thus, acceleration, velocity, and position for every particle. With a discretized approach behind the DEM, the method is well suited for modeling the bulk materials’ behavior. Based on the simulation models, discharge parabolas, and online measurement data, intelligent control of the conveying process is developed.
In order to illustrate the volatility of typical AFRs,
Figure 2 provides an overview of different fuel types typically used as a heat source, e.g., within the cement clinkering process. As is immediately visible from their visual appearance, their general bulk material properties (e.g., humidity, particle size distribution, bulk density, etc.) vary enormously. Furthermore, even the same types of fuel (e.g., wood chips) tend to have inhomogeneous characteristics, since they are mostly produced by different fuel preparation plants and, therefore, originate from different source material streams. It can be stated, in general, that all of the shown fuels have non-supporting characteristics when it comes to their transportation within a bucket elevator. Most of the fuels tend to be quite coarse, lumpy, and fibrous, and have a relatively low bulk density, if compared to homogenous bulk materials, such as sand or cement.
To increase the efficiency of the bucket elevator, it is important to analyze the discharge trajectory of the material and control it. The idea is to ensure that the maximum amount of material gets disposed into the target furnace rather than back into the elevator base. General studies about the discharge behavior of bucket elevators have been carried out for decades, which led to a general theoretical model of bucket elevator discharge trajectories (see [
5]). However, most of the work considers only homogenous bulk materials or the actual mechanical design of the machine itself (see [
6]).
A particular work about inhomogeneous AFRs was done by Rammrath in his thesis (see [
7]). In [
7], a proof of concept was established with respect to calculating the discharge parabolas of these AFRs. The work focused on using tools of the OpenCV (Open Source Computer Vision) library such as morphological operation, canny edge detection, and the RANSAC (Random Sample Consensus) algorithm to estimate the trajectories of AFRs. However, the study was limited to the detection of the external edge of discharge material due to approach implementation restrictions. After computing the theoretical-based discharge parabola representation using Müller’s Theoretical Drop Model, the study concluded that a balancing function needs to be developed to estimate the exact dependence of a discharge parabola on various material properties of AFR particles. The typical properties that define the material behavior are Young’s modulus, the Poisson ratio, the coefficient of friction, the coefficient of restitution, the coefficient of rolling friction, and cohesion. As discussed earlier, the process would be conducted in a CFDEM-based experimental simulation setup. Much research has been done to simulate the exact behavior of bulk materials in DEM simulations. Namely, two common approaches are followed, microscopic and macroscopic approaches to calibrate DEM material parameters. The microscopic approach analyzes the direct contact-level information such as density and the coefficient of friction between particles to simulate bulk materials. On the other hand, the macroscopic approach observes the overall behavior of DEM simulation compared to real work values. A broad application of these approaches to determine and calibrate DEM parameters is available in [
8,
9]. One of the prime studies that piqued our interest was our co-author Elbel’s thesis work where he uses the RL algorithm to estimate the bulk material properties. The concept behind Elbel’s work was to use an Advantage Actor–Critic (A2C) RL algorithm to replicate two targets’ static and dynamic angles of repose in a DEM simulation close to the real-world value. The angle of repose is the measure of the flowability of bulk material and is located between the horizontal plane and the material surface. To achieve this objective, various combinations of four different bulk material properties were tried out in a systematic manner. This idea was also one of the motivations behind the current research.
Optimizing the material discharge parabola requires understanding and correlating various physical properties of materials such as density, particle size distribution (PSD), and flowability. One such work implemented preceding this article was the online PSD estimation based on a DL-based segmentation approach, a detail of which is available in [
10]. This work would also have a significant role in describing the state of the RL system agent. A notable outcome of this work was the use of a synthetically generated image dataset for the segmentation task. The alpha channel of the individual particle images was manipulated to form the superset of images. As the reward function of the RL agent used in this research is based on a combination of computer vision (CV) and the DL concept, a modified version of the synthetic dataset generation algorithm described in [
10] was used to achieve the task of dataset formation. The important objective of that article was to detect the region within an image where the particles were present at a given time. Such a task is referred to as an image segmentation task. During the last decade, researchers have developed a plethora of convolutional-based models for image segmentation. It all started when the image segmentation task became highly efficient with the successful segmentation of biomedical images for brain tumor detection using the deep learning architecture UNET described in article [
11]. The UNET architecture is based on convolutional operators that extract important local features of the image. However, they are still limited in modeling a global context, and this is where a more advanced transformer-based UNET architecture took over. A notable application of these vision transformers can be seen in article [
12]. That paper provides a thorough comparison of vision transformers with different segmentation model variants for a forest fire image segmentation task and ascertains their improved performance compared to more traditional UNET architecture. A similar variant of the vision transformer is also used in this work.
The training or learning of an algorithm based on its interactions with a dynamic environment is the ML branch called reinforcement learning. The reinforcement learning algorithm consists of an agent or a brain that continuously observes the state of the environment and interacts with it to change it to a required or optimized state by performing an action. It can be said to be a trial-and-error process of learning over time. The measure of how good or bad is the action taken by an agent is the reward. The aim is to maximize the reward. One key aspect of RL is the need to find the trade-off between exploration and exploitation of the environment. With the aim to maximize the reward, the agent could get stuck in local minima where the probability of getting a good reward is high. However, there could be another region in the state space where a much better reward can be obtained, and the agent should keep exploring for the same. Hence, the agent must decide whether to take the risk of exploration in an effort to find better rewards or to exploit the current experience of the environment [
13]. This problem scenario of exploration vs. exploitation of the environment, as stated by Sutton, one of the founding members of the RL field, is still in the research stage, and is mostly resolved based on the domain knowledge of RL application [
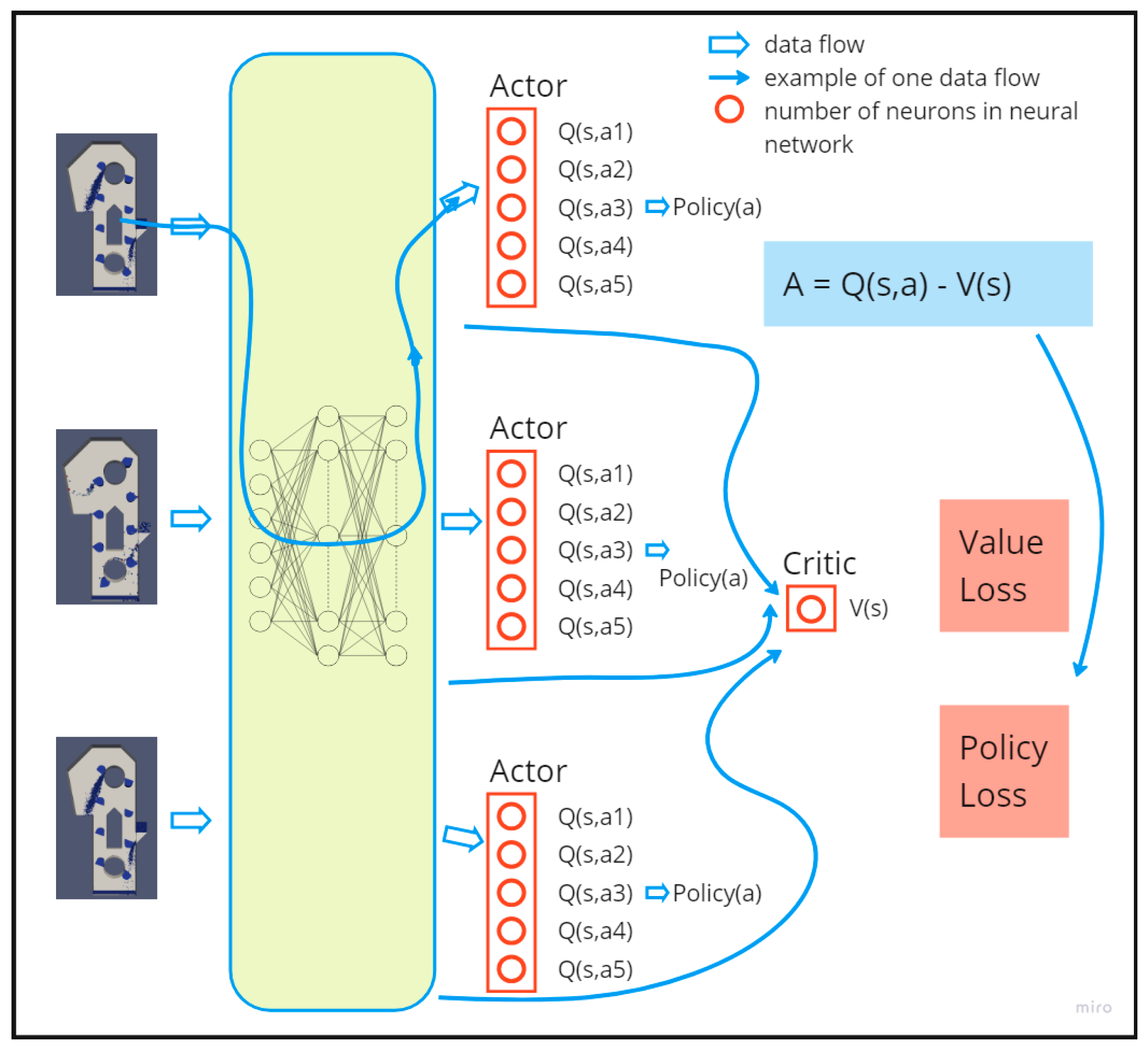
13]. One of the advanced RL algorithms that minimizes the scenario of exploration vs. exploitation is the Asynchronous Advantage Actor–Critic (A3C) algorithm. It enables the agent to explore unique states and at the same time work on the known one. A variant of such an A3C algorithm is used in this work, and the choice of considering such an algorithm is further discussed in the later subsection.
To summarize, this article provides a short overview of the proposed framework in
Section 2. It also consists of discussions of two important parts of the methodology, namely CV and a DL-based approach for detecting discharge parabolas and the optimization of bucket elevator throughput using RL. This is then followed by evaluating the approach to different scenarios in
Section 3. The algorithm for detecting the material discharge parabola and, thereby, the RL reward function will be evaluated. And, this will be followed by the test of the RL algorithm in a test simulation setup. The paper is finalized with a conclusion and discussion of future scope.
4. Conclusions
The objective of this study is to make a provision for the utilization of Alternative Fuel Resources such as wood straws, rubber granules, and paper waste for the combustion process in cement manufacturing plants. As such, the goal is to develop an intelligent bucket elevator system capable of adjusting its velocity to provide an optimum throughput for different AFR material types. A combination of DL and RL algorithm setups based on a DEM simulation as an RL environment was implemented to achieve this goal.
This study focuses on implementing an RL-based approach in a DEM simulated system setup as a background in a way that the process is easily transferable to real-world bucket elevator system optimization. As such, it takes into account every restriction that a programmer might face in a real-world bucket elevator system when considering various parameters of the overall implemented algorithm. These restrictions include the available visibility area (the Plexiglass surface) for tracking the particle discharge motion and difficulties in measuring the mass of the material per bucket at both the inlet and outlet.
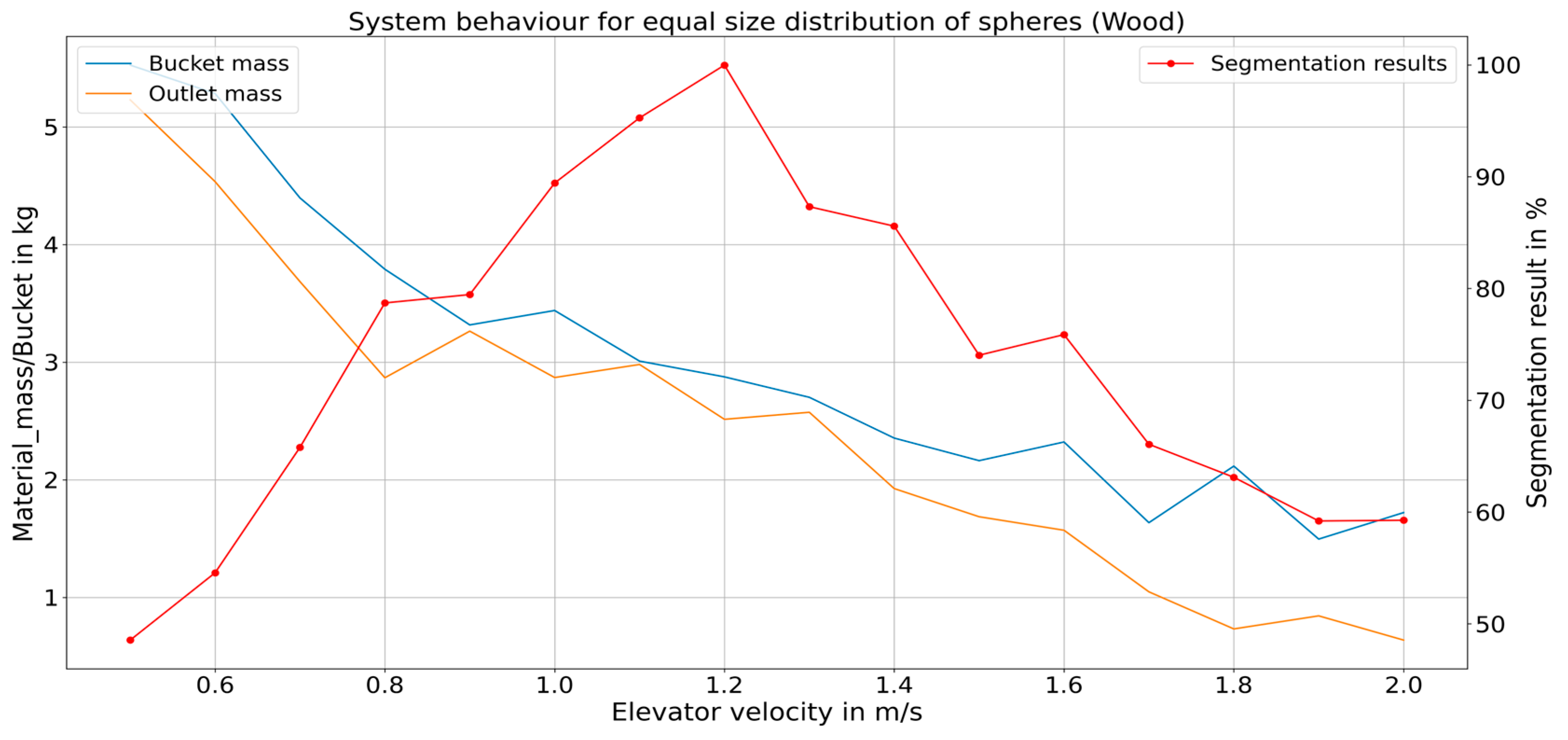
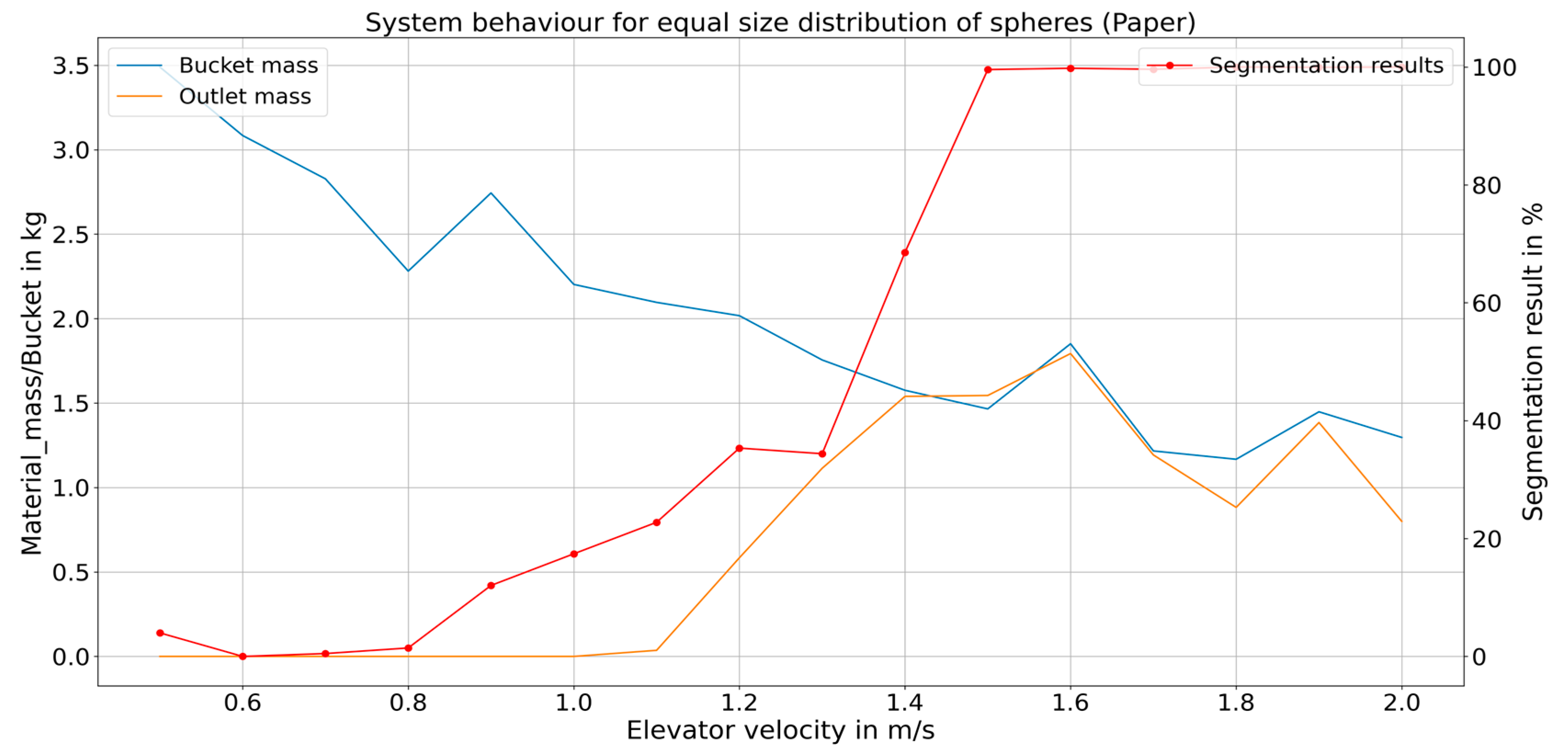
A comparative evaluation was conducted between the UNET and TransUNET DL segmentation techniques, and a slightly better performance was observed in the case of the latter, albeit with higher computational requirements. Hence, the choice of the DL method depends on a compromise between the required accuracy and the available computational power. With the DL-based trajectory segmentation technique able to segment the images with an average dice score of 0.97, the corresponding reward calculation approach is reliable.
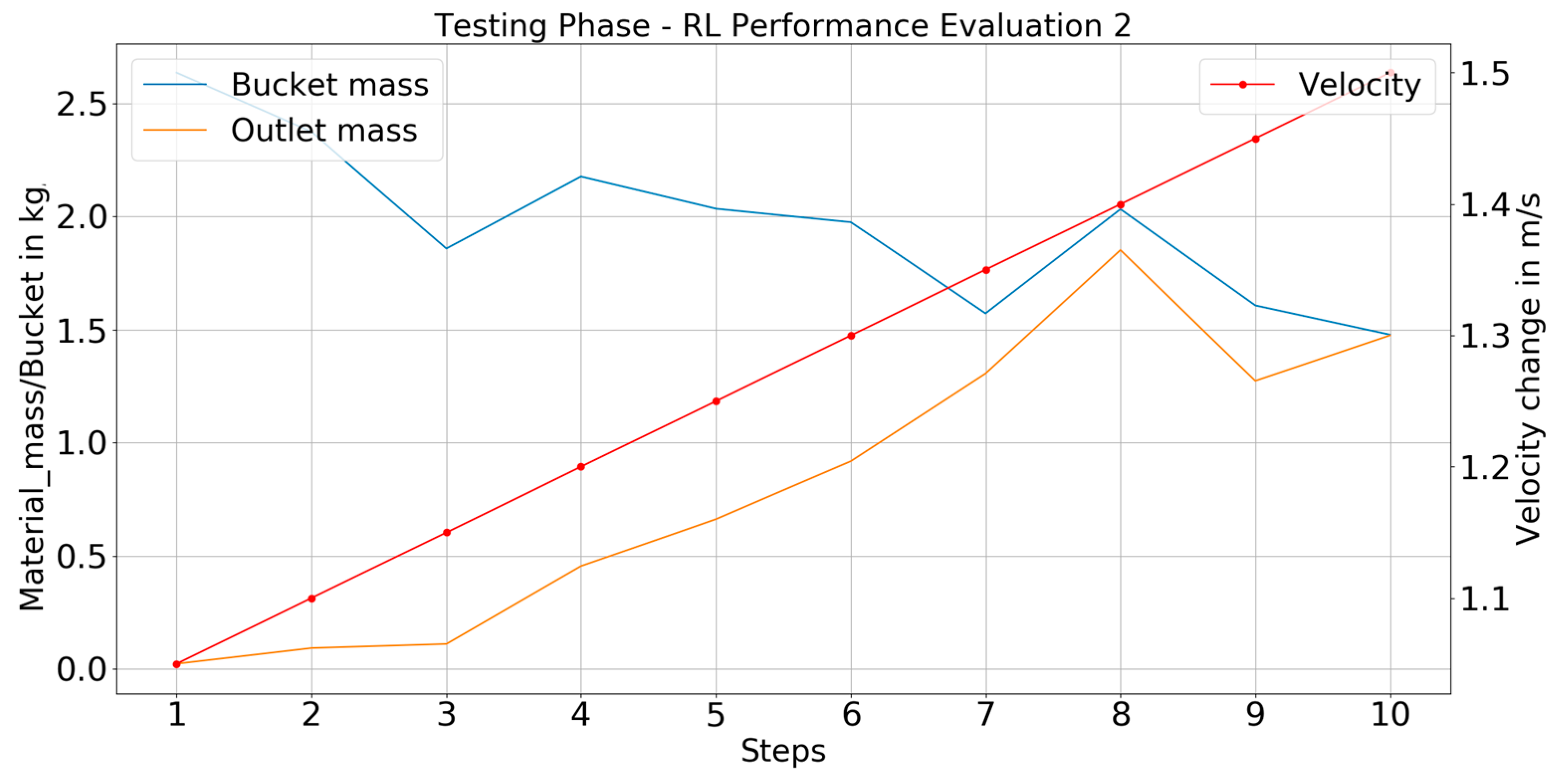
The RL-based optimization process was conducted by observing four important parameters that define the system state at a given instance. These parameters are the magnitude of the current velocity of the bucket elevator, the type of material in the system, the infeed rate of the material, and the PSD of the infeed material. Of these parameters, the infeed rate of the material was kept static and should be further manipulated in future tasks to make the optimization process more robust. Based on the values of these four parameters, the RL system formed a feedback control loop to monitor them and keep the discharge of the material at the outlet at an optimum level. The comparison between the mass of material within a filled bucket at the inlet and the discharge at the outlet was used as a measure to indicate if the system’s process was carried out in a planned manner. This material mass measurement did not have any impact on the RL algorithm itself.
This proposed approach was implemented using the A3C RL algorithm. This powerful algorithm allows the training to be conducted across multiple processors parallelly, wherein each processor was running its own unique DEM-based environment. Thus, a complete use of the available computation power was achieved.
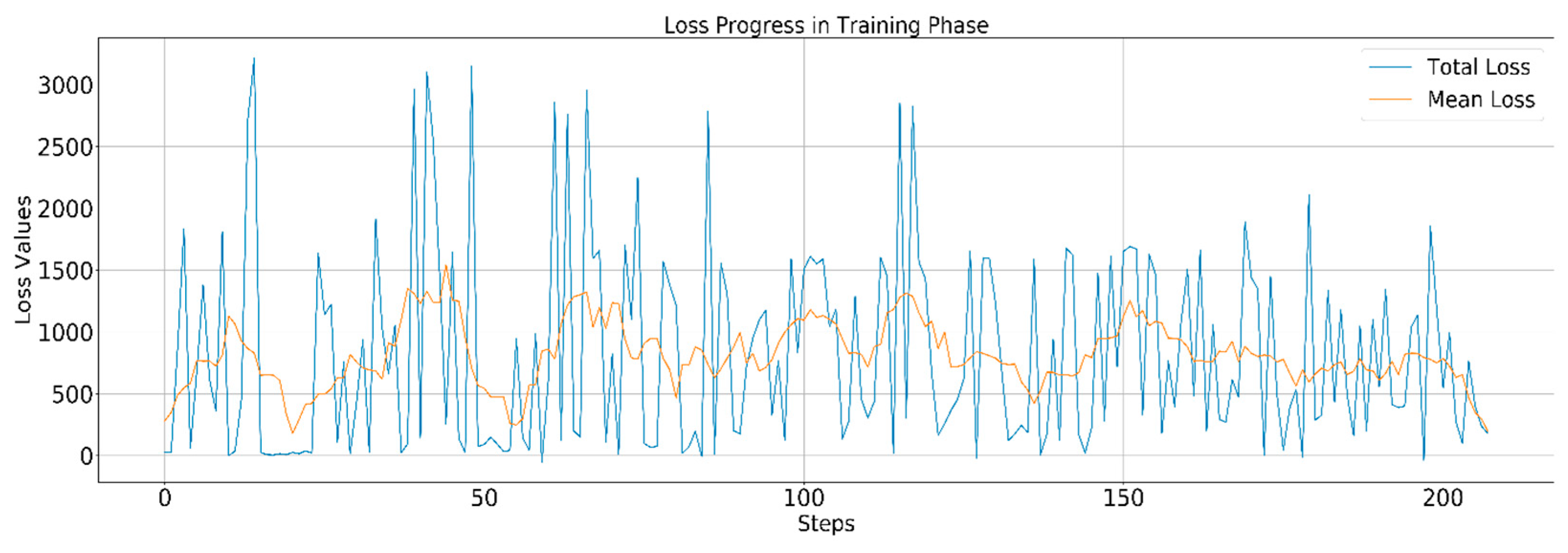
The results obtained in the training phase indicate that this approach to monitoring and optimizing the bucket elevator system using reinforcement learning is practical and usable. With a throughput that transferred 95% of the inlet material within a bucket at the outlet section, it proves the approach to be promising for making the bucket elevator system intelligent.
5. Future Scope
The optimization process of the bucket elevator system can be further boosted by considering the infeed material rate. Here, one can use a multi-objective optimization approach to monitor and control both the infeed rate and bucket velocity parameters. Certain provisions have already been made in the code to consider this in the future.
With the approach proposed by Mr. Elbel, it is possible to generate the DEM parameters replicating the behavior of AFR particles in the simulation. As such, this idea can be used to obtain the simulated behavior of different AFR particles and further optimize their usage in the bucket elevator system using the combination of DL and RL approaches discussed in this work.
One of the roadblocks to training with the RL approach for a satisfactory number of episodes was the allowance of the usage of only CPU cores in the Virtual Machine to run the DEM simulation. The possibility of running this DEM-based simulation on a Graphical User Interface (GPU) needs to be explored. With such a provision, it is possible to make full use of the GPU VRAM cores along with the CPU cores to increase the computational efficiency of the DEM simulation.
The DEM simulation is based on the Lagrangian method that involves solving trajectories or movements of each particle over time within the simulation. This means a higher degree of computation in the background. With a plan to develop a miniature prototype of a bucket elevator system, the use of such a prototype to train the RL agent can be explored. The training involved in such a setup will be a real-time inference and will drastically reduce the training time compared to the time needed in a DEM setup. If the prototype functions similarly to the actual bucket elevator system, the information learned by the RL agent using such a setup can be easily transferred and scaled to the actual system. Hereon, with only a few additional training episodes, the bucket elevator system will be functionally able to intelligently carry out its task. Thus, the training cost can be reduced to a great extent.
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}