1. Introduction
Wind power is one of the fastest growing electricity sources in the world [
1]. Despite wind power’s clean benefits, wind power is a non-dispatchable resource which is dependent on weather conditions [
2]. The resultant variable nature of this resource threatens the balance of generation and demand in power systems [
3]. Accordingly, wind power variations increase the regulation requirements and decrease their operational benefits in power systems [
4]. An effective solution for this problem is forecasting wind power [
5]. For this purpose, several methods have been proposed by research in recent years. As some newer examples, a two-stage hybrid network including Bayesian clustering by dynamics and support vector regression has been proposed for wind generation forecasting in [
5]. In [
6], two Neural Network (NN) based approaches have been presented for direct and rapid construction of wind power prediction intervals. Combination of non-parametric and time-varying regression model and time-series model, i.e., Holt–Winters and Autoregressive-moving-Average Model (ARMA), which can consider residual autocorrelation and seasonal dynamics, has been presented in [
7] for wind power prediction. Wind speed prediction by a Hybrid Iterative Forecast Method (HIFM) has been presented in [
8]. A two-stage feature selection technique has been also proposed for selecting the most relevant and least redundant input variables in [
8]. In [
9], wind power forecast by Ridgelet Neural Network (RNN) has been proposed in which Ridgelet is used as the activation function of the hidden nodes. Moreover, a new Differential Evolution (DE) method has been presented in [
9] for training the RNN. A hybrid forecasting method based on Enhanced Particle Swarm Optimization (EPSO) has been introduced in [
10] for wind power prediction. This hybrid method is composed of persistence technique, back propagation neural network, and Radial Basis Function (RBF) neural network. Also, EPSO further optimizes the weight coefficients in this hybrid technique. In [
11], another version of EPSO with a hybrid NN has been proposed for wind power prediction. The training mechanism of the hybrid NN is composed of the EPSO as well as Levenberg–Marquardt (LM), Broyden, Fletcher, Goldfarb, Shannon (BFGS), and Bayesian Regularization (BR) learning algorithms. Wind power forecast methods have been reviewed in [
12,
13,
14,
15].
Various research works have focused on maximum power point tracking (MPPT) in photovoltaic (PV) generation systems, wind generation systems and their hybrid wind-PV systems, such as [
16,
17,
18,
19]. A neuro-fuzzy wavelet-based adaptive MPPT control for PV Systems [
16], dynamic operation and control for a hybrid wind-PV-fuel cell microgrid [
17], intelligent MPPT control for a grid-connected hybrid solar power, wind power, and diesel-engine system [
18], and fuzzy MPPT controller for a hybrid solar power and battery system [
19] have been presented in the literature.
In recent years, different transformation techniques have been presented by researchers to enhance the accuracy of forecast methods. Fourier Transform (FT) is one of the earlier techniques which gives the frequency spectral content of the signal [
20]. However, FT application is limited to stationary signals. It cannot give information about where in time the frequency spectral components appear. Short-time FT (STFT), which provides the time information by calculating many FTs for sequential time windows and putting them together [
21], has been proposed to deal with non-stationary signals. However, STFT provides a fixed resolution at all times, while low/high frequency behaviors require long/short analysis windows. Wavelet Transform (WT) alleviates the limitations of FT and STFT methods by using functions that retain an appropriate compromise between time location and frequency information. The basic concept of this method begins with the selection of a proper wavelet function, called mother wavelet, and then combining its shifted and scaled versions. Several wind power forecast methods using WT have been presented so far, such as [
22,
23,
24,
25]. However, WT is a linear signal-processing tool which may not be able to thoroughly analyze nonlinear signal variations. Additionally, the effectiveness of WT is dependent on the proper selection of mother wavelet, while it has to be given before the analysis. Mother wavelets are usually chosen by trial-and-error and heuristic methods. The problems of WT have been extensively discussed in [
26].
EMD is a well-organized decomposition approach, which can mitigate the problems of WT regarding estimating instantaneous frequency [
27]. EMD has been used for wind power and wind speed prediction in [
28]. However, EMD has a disadvantage to process non-stationary signals. This disadvantage is generating fake extremes [
26]. To alleviate this problem a new version of EMD is proposed in this research work.
The new contributions of this research work are as follows:
- (1)
A new version of KIM, named Improved KIM (IKIM), is presented. The proposed IKIM includes the von Karman covariance model whose settings are optimized based on error variance minimization by an evolutionary algorithm.
- (2)
An improved version of EMD is introduced. Cubic spline fitting of conventional EMD is replaced by IKIM in the proposed EMD. It is shown that the proposed EMD alleviates the problems of conventional EMD.
- (3)
A new closed-loop forecasting engine is proposed for wind power prediction. This forecasting engine is based on NN trained by Levenberg–Marquardt learning algorithm.
- (4)
A new wind power prediction approach is presented, which is composed of the proposed EMD, an information-theoretic feature selection method, and the proposed forecasting engine.
Since stochastic search methods, such as particle swarm optimization (PSO), proceed randomly in the solution space to find the optimal solution, numerical stability is an important concern for these methods. However, we have used Levenberg–Marquardt (LM) learning algorithm, which is an efficient training mechanism for prediction tasks, to train the NN-based forecasting engine. Unlike stochastic search methods, LM does not search randomly the solution space. Instead, LM effectively proceeds in the solution space using Gauss–Newton and steepest descent techniques. Since LM does not have random evolution, numerical stability is not a problem for this method.
Microgrids are small power networks that supply load demands locally. For this purpose, a microgrid provides a system approach to distributed generations. Thus, a microgrid can have both dispatchable units (such as diesel engines and micro-turbines) and renewable units (such as wind units and solar units). If a microgrid has wind units, the proposed wind power prediction approach can be used to forecast its wind power the same as it is used to forecast the wind power of a wind farm. We should give the historical data of the wind power pertaining to the wind units of the microgrid to the proposed prediction approach. The proposed approach decomposes this wind power time series by means of IKIM and EMD, selects most effective features for it by means of Maximum Relevancy, Minimum Redundancy and Maximum Synergy (MRMRMS) feature selection method and provides wind power forecast for the microgrid through the closed-loop forecasting engine. In other words, the proposed wind power prediction approach forecasts wind power of a microgrid based on the same steps and methodology used to forecast wind power of a power system. Thus, the proposed wind power prediction approach can be useful for microgrids the same as it is useful for power systems and wind farms.
The next sections of the paper are structured as follows. In
Section 2, conventional EMD is first introduced and then the proposed EMD based on IKIM is presented. In
Section 3, the proposed closed-loop forecasting engine and the information-theoretic feature selection method are introduced. Afterwards, the proposed wind power prediction approach is constructed by combining its components. The numerical results produced by the proposed wind power prediction approach for real-world wind farms are presented in
Section 4 and compared with the results of many other prediction methods.
Section 5 presents a discussion of the results and
Section 6 concludes the paper.
2. Empirical Mode Decomposition (EMD)
EMD aims at decomposing a volatile signal to more smooth and well-behaved components called Intrinsic Mode Function (IMF). IMF is an oscillating function, as a counterpart to harmonic function, with two main characteristics: (1) IMF has the same number of local maxima, local minima and zero crossings or at most these numbers differ by one, (2) the mean of IMF is zero. To decompose a signal to IMF components, EMD uses an iterative sifting process that can be summarized as the following step-by-step EMD algorithm:
| EMD Algorithm: |
- (1)
Calculate the local maxima and minima of the signal, denoted by x(t), within the considered domain. - (2)
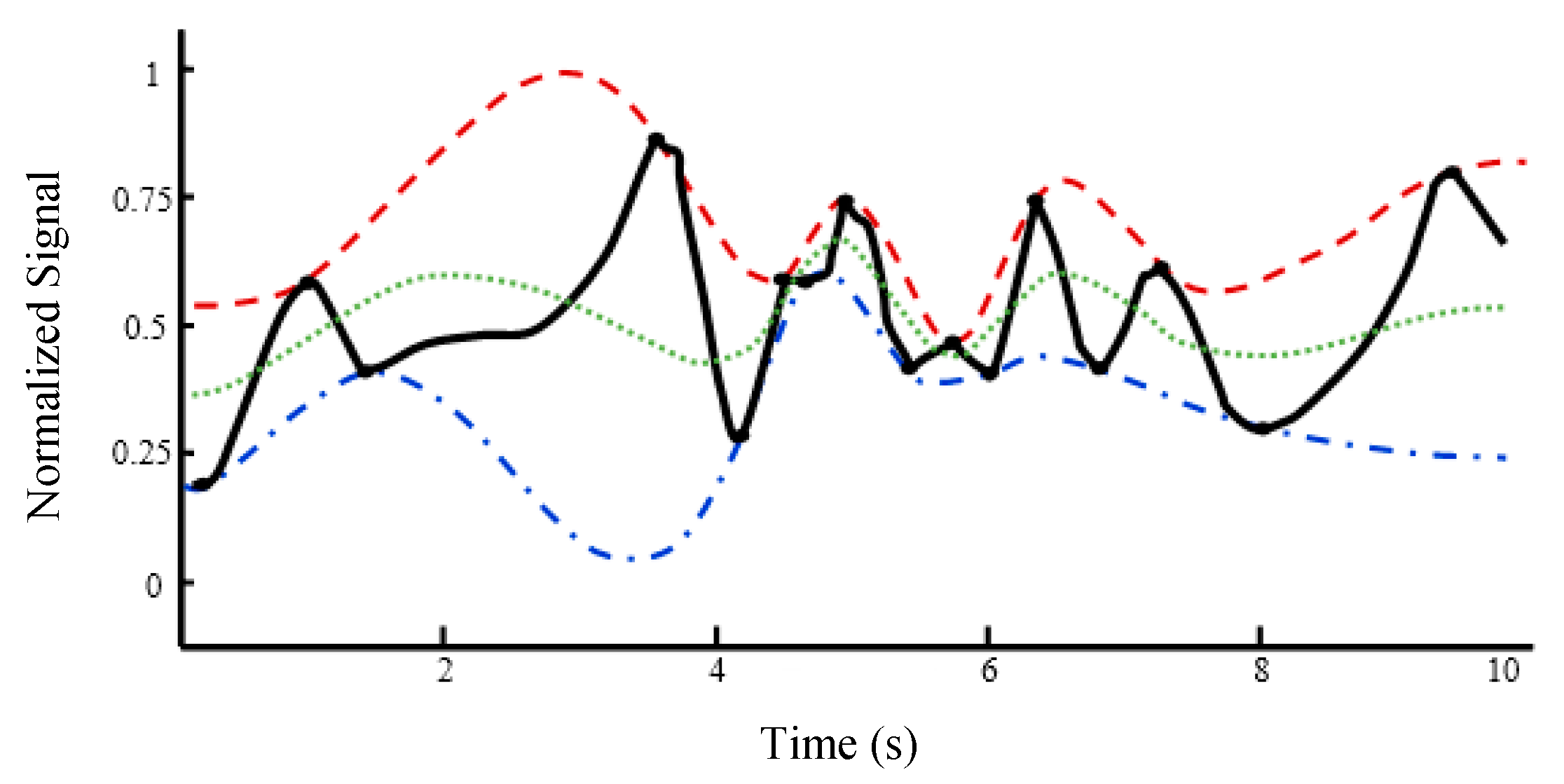
Connect the maxima of x( t) with an interpolating function, such that an upper envelope u( t) is created about the signal. EMD uses spline of order 3, known as Cubic Spline (CS), for the interpolation [ 29]. Similarly, connect the minima of x( t) with the interpolating function to create a lower envelope l( t) around the signal. These envelopes are shown in Figure 1. - (3)
The mean of the upper and lower envelopes, i.e., s( t) = [ u( t) + l( t)]/2, is calculated, which is the curve of local mean in Figure 1. - (4)
If the stopping condition a is satisfied, the local mean s(t) is an IMF and go to step 5; otherwise, substitute the signal with signal minus the local mean, i.e., x(t) − s(t)→x(t), and go back to step 2. - (5)
Suppose n IMF components s1(t), s2(t), …, sn(t) have been produced so far. Compute the residual r(t) = x(t) − [s1(t) + s2(t) + … + sn(t)]. If the stopping condition b is satisfied, terminate the algorithm; otherwise, substitute the signal with the residual, i.e., r(t)→x(t), and go back to step 2.
|
The stopping condition
a expresses that the relative difference between two successive local means should be less than a threshold [
30], which means that iterating the inner loop makes negligible changes in the local mean. The stopping condition
b for the outer loop states that the residual should be monotonically increasing or decreasing, i.e., no oscillation is observed in the residual in the considered domain [
31]. If the algorithm is terminated with
n IMF components, the signal is decomposed as:
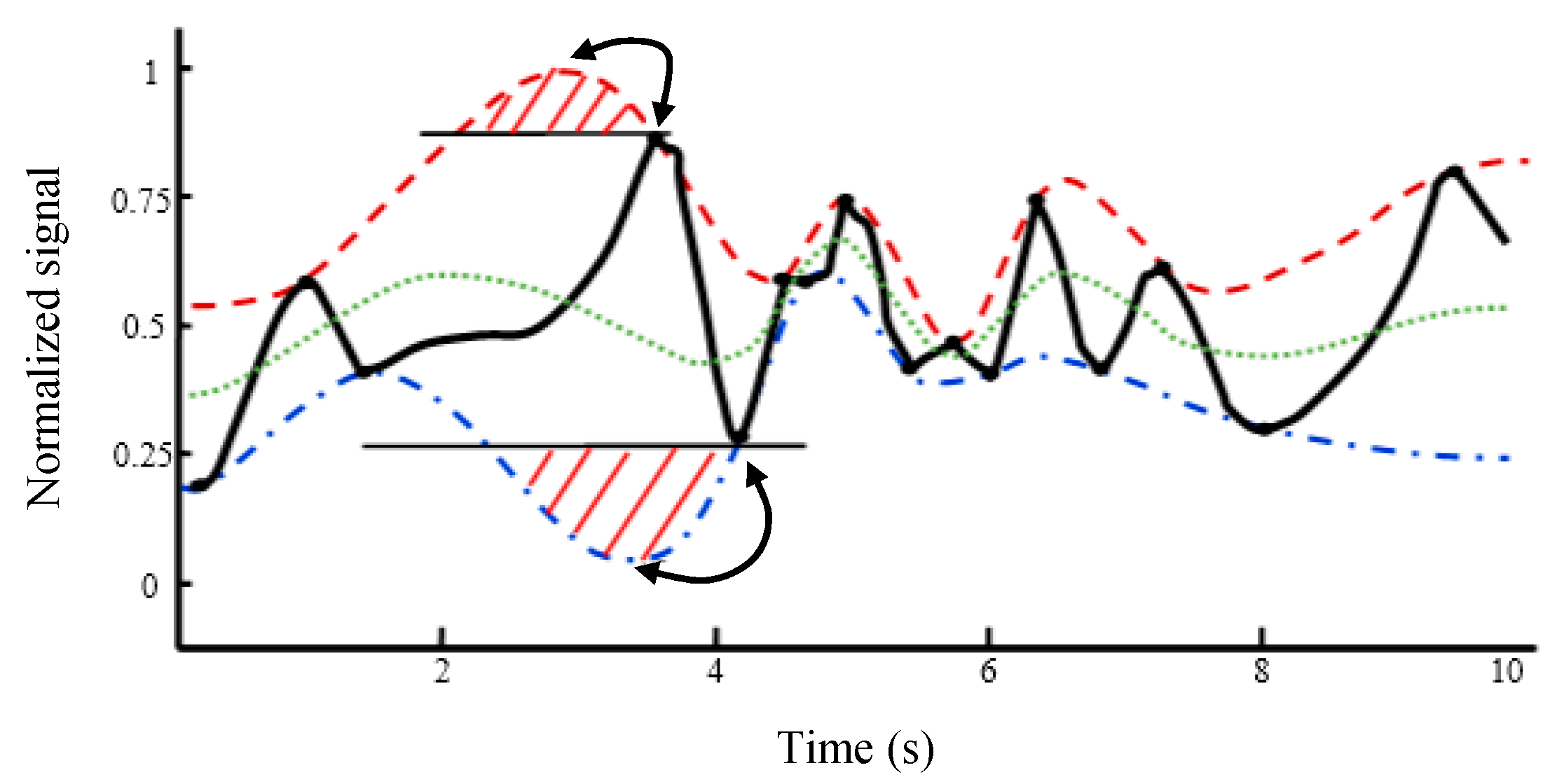
EMD is an effective signal-processing tool to analyze local behaviors through decomposing a volatile signal into less volatile components. However, it has an important disadvantage, which is generating fake extremes introduced by the CS curve fitting. These fake maxima and minima lead to fake overshoots and undershoots, indicated in
Figure 2, which decreases the accuracy of the produced IMFs and also increases the iterations of the sifting process. To cope with these problems and enhance the performance of EMD, a modified version of it is proposed in which the CS interpolation is replaced by IKIM. In the following, ordinary KIM is first reviewed briefly and then an improved version of ordinary KIM, i.e., IKIM, is introduced. Afterwards, the proposed IKIM is applied to EMD.
Kriging is an interpolation method, which estimates the value of a function at a given point as a weighted sum of the function values at the neighboring points [
32]. Kriging has important advantages with respect to other interpolation techniques. It assigns weights based on a data-driven strategy, instead of an arbitrary function, giving higher weights to isolated points compared to points within a cluster. Moreover, Kriging can provide an error estimation through Kriging variance along with estimation of the own variable [
33].
KIM estimates the value of a time series
x(
t) at point
t, through the following weighted sum:
where
indicates KIM estimation of
x(
t);
ti, 1 ≤
i ≤
M, are the neighboring points of
t.
In ordinary KIM [
34], the weights
wi are obtained through variance minimization model. The KIM error, denoted by
e(.), for estimation of
x(
t) is as follows:
which can be written in vector form as below:
where the superscript
T indicates transpose. The error variance, shown by
, can be written as below based on the bilinear form theorem [
35]:
By decomposing the vector
to two sub-vectors
and
, (5) can be reformulated as:
where
Cov(.,.) represents covariance function. Consequently, ordinary KIM determines the weights
w1, …,
wM by solving the following optimization model:
where
is as presented in (6). To compute the variance and covariance terms of (6), KIM assumes Gaussian process for the
M samples (i.e., the prior distribution) and so the resulting posterior distribution becomes Gaussian [
33]. The optimization problem of (7) can be solved by means of Lagrange multipliers’ method, which leads to the following solution [
34]:
where λ is the Lagrange multiplier associated with the constraint
. By determining the weights
w1, …,
wM, the estimation of
, i.e.,
, and the error variance can be obtained through (2) and (6), respectively.
The most time-consuming part of (8) is calculation of the covariance functions. Thus, to decrease the computation burden of the above optimization problem, a well-known approximation for the covariance of Gaussian processes is used here in which the covariance function is approximated based on the covariogram [
33]:
where
dij indicates the Euclidean distance between
ti and
tj. For our one-dimensional problem the Euclidean distance is reduced to
dij = |
ti −
tj|. Also,
C(.) is the covariogram which represents the covariance function based on the distance
dij. For this purpose, several functions have been presented in the literature as
C(.), such as the linear model, the exponential model, the Gaussian model, and the spherical model [
34]. Recently, the von Karman covariance model has been introduced in [
35], which is an effective model considered for calculating the covariance terms in this work. The anisotropic von Karman function can be defined as:
where Γ(.) is the gamma function and
Kv is the modified Bessel function of the second type of order 0 ≤
v ≤ 1 [
36];
r is the lag;
a is correlation length; and
σ2 represents the variance.
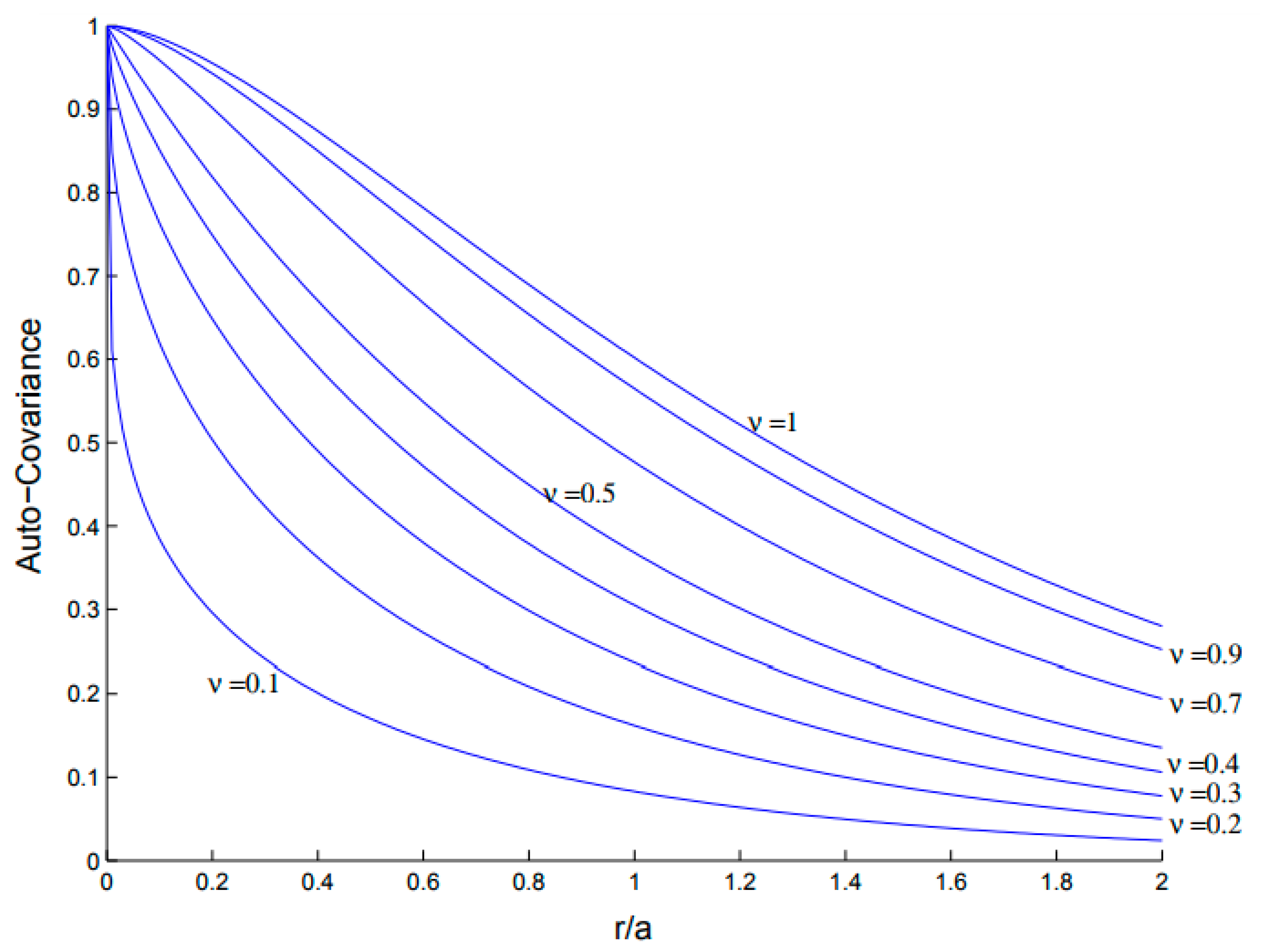
Figure 3 shows
C(
r) in terms of
r/
a for different values of
v. In this paper,
v = 0.5 is adopted, which leads to exponential auto-covariance function. Moreover, the value of
a in
C(
r) is optimized by Shark Smell Optimization (SSO) method which has been recently introduced in [
37]. The objective of this optimization problem is minimizing the error variance. For details of SSO, the interested readers can refer to [
37] The proposed IKIM includes KIM with the von Karman covariance model given in (10) and SSO optimization used to optimize the value of
a.
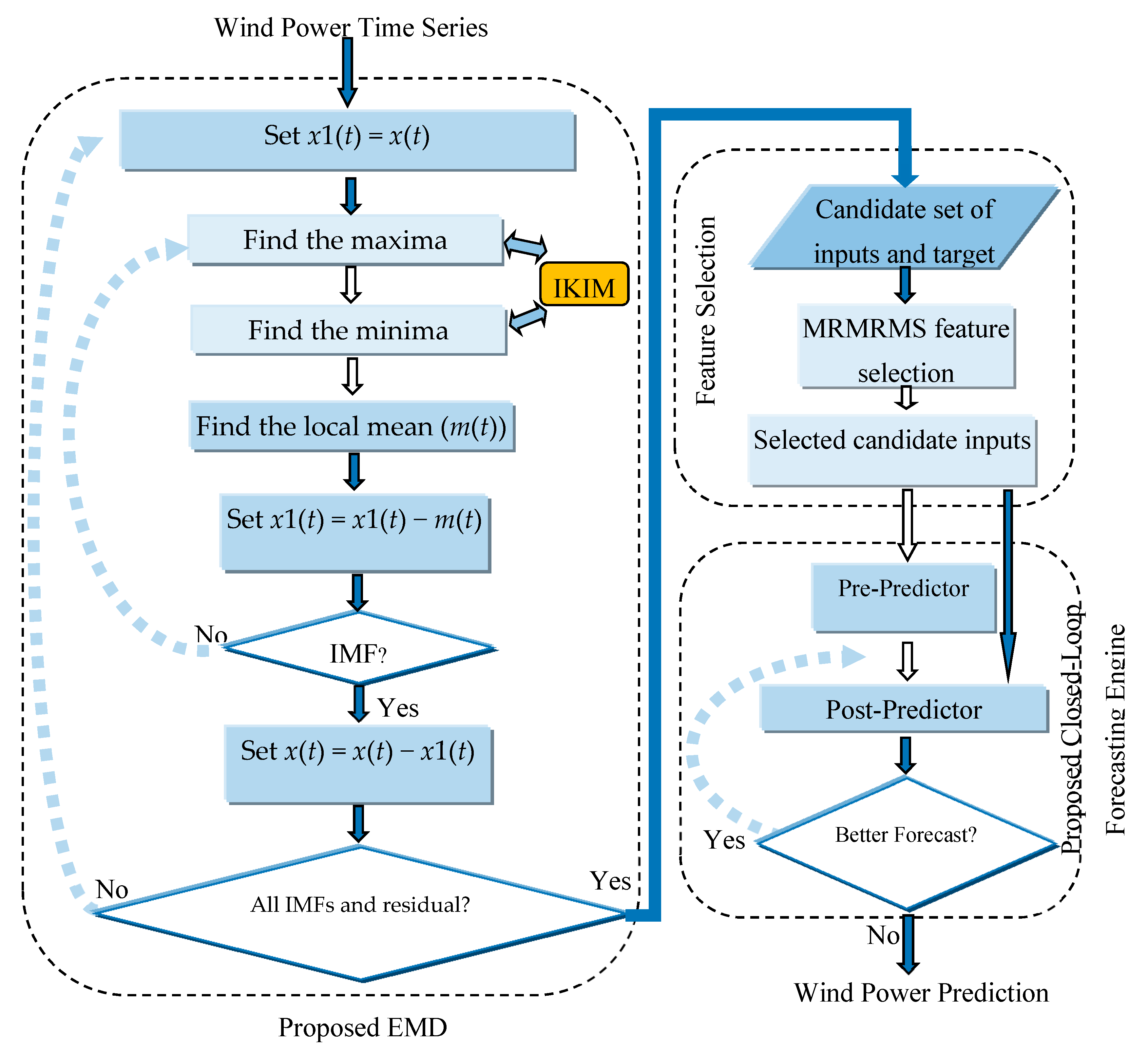
The performance of the proposed EMD based on IKIM to decompose a signal x(t) can be summarized as the following steps:
Set x1(t) = x(t).
Find the maxima of the signal x1(t) and obtain the upper envelope ue(t) using the proposed IKIM.
Find the minima of the signal x1(t) and obtain the lower envelope le(t) using the proposed IKIM.
Find the local mean m(t) = [ue(t) + le(t)]/2.
Set x1(t) = x1(t) − m(t) and determine if x1(t) is an IMF or not by checking the properties of IMF. Repeat steps 2 to 5 until x1(t) becomes an IMF. Store the obtained IMF.
Set x(t) = x(t) − x1(t).
Repeat steps 1 to 6 until all IMFs and residual of signal x(t) are obtained.
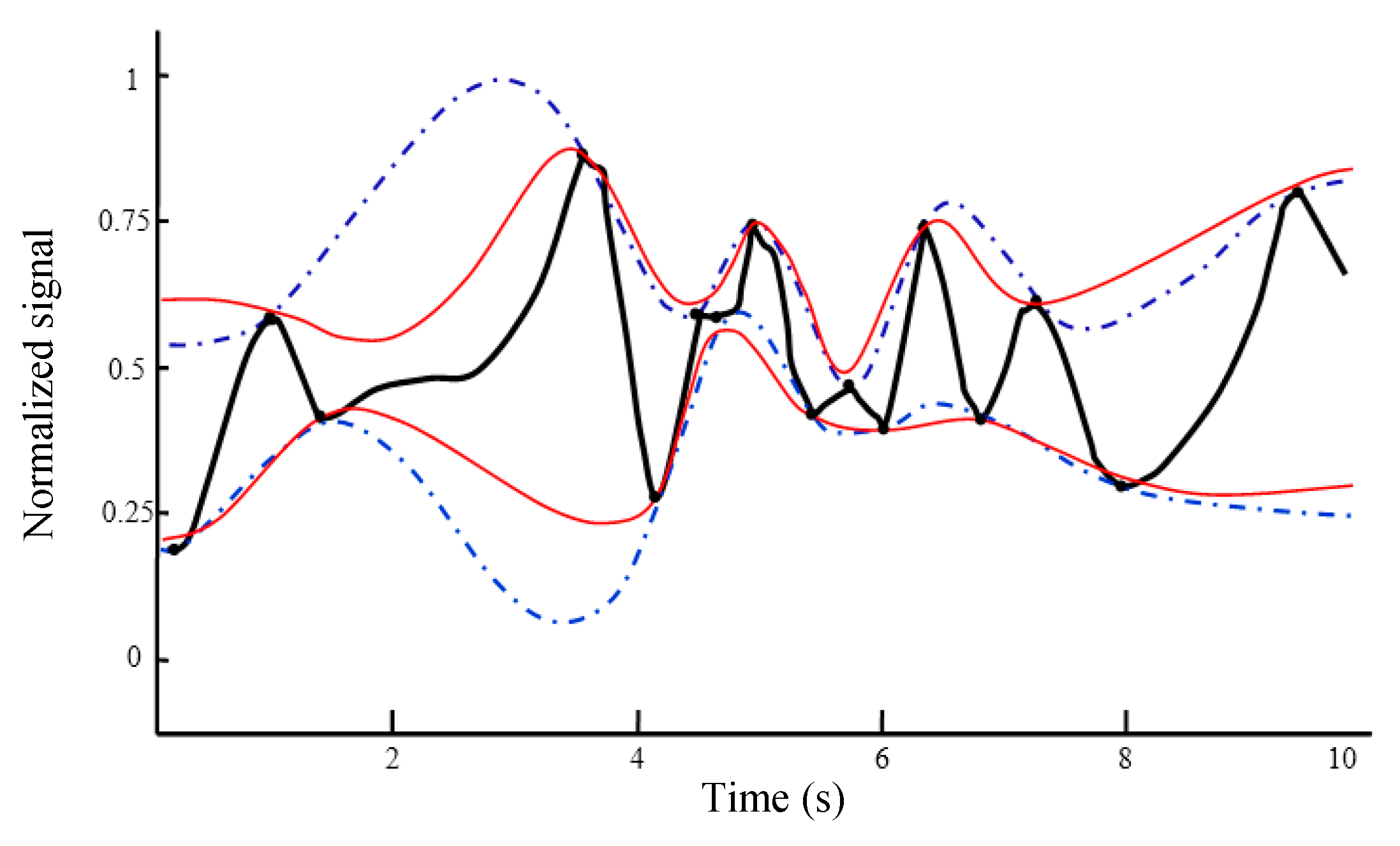
The results obtained from applying the proposed EMD using IKIM to the test case of
Figure 2 are shown in
Figure 4, which are compared with the results of the conventional EMD using CS. It is seen that the proposed EMD results in more accurate envelopes compared with the conventional EMD. The fake overshoots and fake undershoots of the envelopes generated by the conventional EMD are significantly mitigated in the envelopes generated by the proposed EMD. By generating more accurate envelopes, more accurate IMF components can be produced by the proposed EMD.
3. Proposed Wind Power Prediction Approach
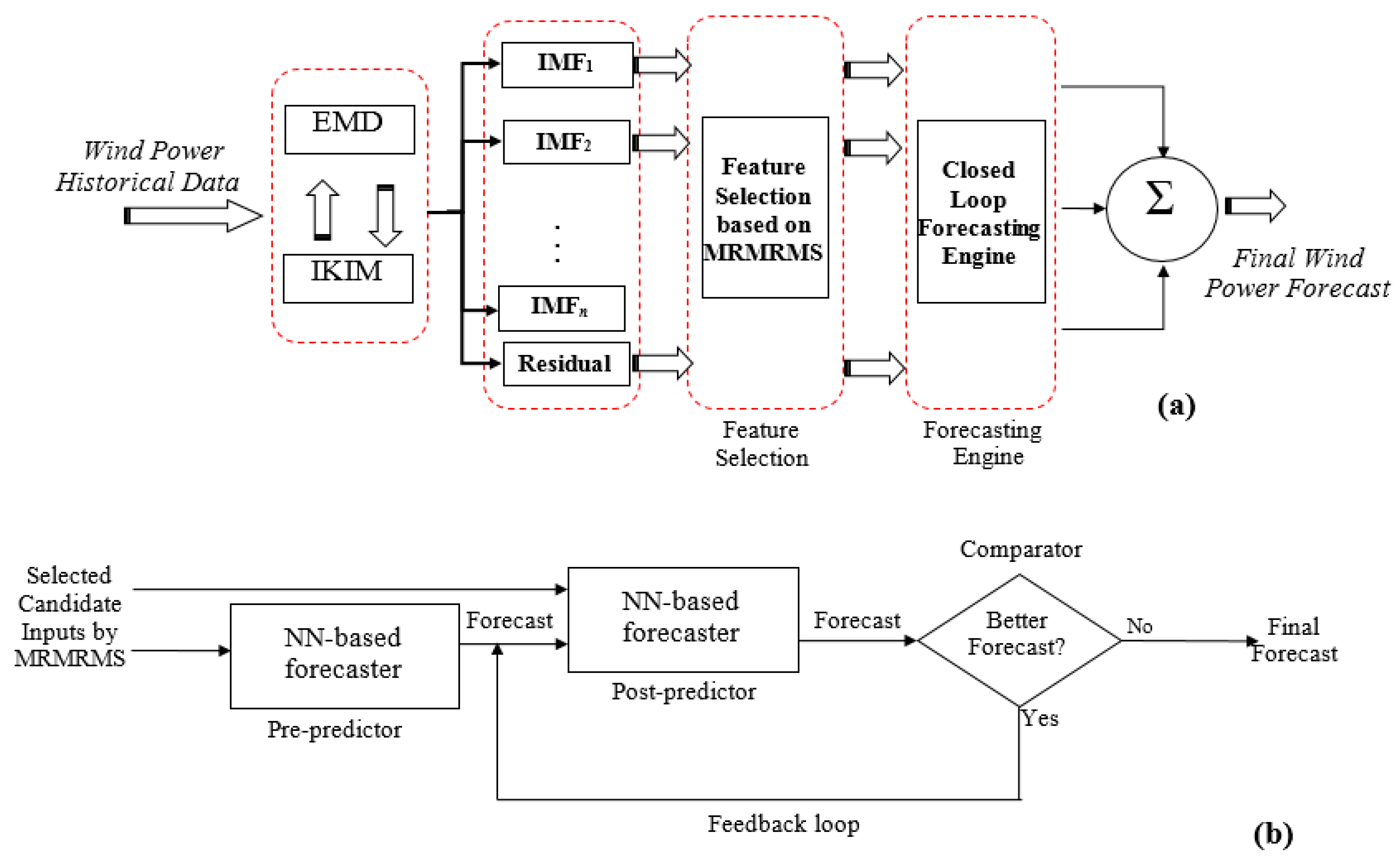
The structure of the wind power prediction approach proposed in this research work is shown in
Figure 5a. Within this approach wind power time series is first decomposed using the proposed EMD based on IKIM. Each of IMFs and residual is separately predicted by means of a feature selection method and a closed-loop forecasting engine. The feature selection method receives the historical data of each IMF/residual time series as well as the historical and forecast values of the exogenous variables, e.g., the historical and predicted values of wind speed and temperature provided by Numerical Weather Prediction (NWP). Subsequently, the feature selection method separately selects the candidate inputs that are informative for the forecast process of each IMF/residual. Since wind power is a nonlinear function of the candidate inputs and these candidate inputs can be redundant and interacting, the information-theoretic feature selection method of Maximum Relevancy.
Maximum Relevancy, Minimum Redundancy and Maximum Synergy (MRMRMS) [
38] has been used in the proposed wind power prediction approach. The forecasting engine of each IMF/residual is fed by the selected candidate inputs of MRMRMS as shown in
Figure 5b. By selecting more relevant, less redundant and more synergetic candidate inputs, the forecasting engine can better extract the input/output mapping function of each IMF/residual. However, since MRMRMS is not a contribution of this article, it is not further discussed here. Details of this method can be found in [
38]. Instead, we focus on the forecasting engine in the following, which is one of contributions of this research work.
As seen from
Figure 5b, the first block of the proposed closed-loop forecasting engine is a pre-predictor, which is an NN-based forecaster. The output of this pre-predictor and the candidate inputs selected by MRMRMS feature selection method are given to a post-predictor, which is another NN-based forecaster. Both of these NN-based forecasters (i.e., pre-predictor and post-predictor) have Multi-Layer Perceptron (MLP) structure and Levenberg–Marquardt (LM) learning algorithm, which is an efficient training mechanism for the prediction tasks [
39]. However, these two forecasters have different roles in the proposed forecasting engine. Pre-predictor forecasts the future values of the associated time series (IMF or residual) using the candidate inputs selected by MRMRMS. This forecast, i.e., the output of pre-predictor, is used as an initial prediction to initialize the feedback loop shown in
Figure 5b. Within this feedback loop, the NN-based forecaster of post-predictor predicts the future values of the associated time series using both the selected candidate inputs of MRMRMS and the output of pre-predictor. Since post-predictor has the forecast generated by pre-predictor, which is an input close to the output, it is expected that post-predictor more accurately predicts the future values of the associated time series compared with pre-predictor. The next element in the feedback loop, i.e., comparator, evaluates this aspect. If the forecast of post-predictor is better than the forecast of pre-predictor, the forecast of post-predictor is feed backed through the feedback loop to replace the forecast of pre-predictor at the input of post-predictor. Then, post-predictor forecasts the output using this more accurate input. Similarly, comparator compares the two forecasts at the input and output of post-predictor and if a more accurate forecast is obtained at the output of post-predictor with respect to its input, the process of the feedback loop is repeated.
When no better forecast can be generated by post-predictor or difference between the two forecasts at the input and output of post-predictor becomes negligible, this process is terminated and the last generated forecast by post-predictor is given as the final forecast of the proposed closed-loop forecasting engine.
In practice, since we do not have the output of forecast samples (e.g., hourly wind powers of the next day), validation samples are used instead of forecast samples to evaluate the accuracy of the forecasts generated by pre-predictor and post-predictor. Validation samples are a part of historical data which is not used as training samples and kept unseen for the forecasting engine. Thus, by evaluating the error of validation samples or validation error we can obtain an estimation from forecast error. To attain an accurate estimation of forecast error, validation samples should be as similar as possible to the forecast samples. Thus, in this research work, the hourly samples of the day before the forecast day (which are the closest samples to the forecast samples) are selected as the validation samples.
The flowchart of the whole proposed wind power prediction approach is shown in
Figure 6. In this flowchart, the performance of the proposed approach including its various components is illustrated.
5. Discussion
In this research work, the effectiveness of the proposed prediction approach has been extensively illustrated through four numerical experiments for both wind speed and wind power forecast on three real-world test cases. In these four numerical experiments, the proposed prediction approach has been compared with many other forecast methods in terms of various error criteria and with different forecast horizons. In the first, second, third, and fourth numerical experiment, the proposed method has been compared with eight other methods, 10 other methods, five other methods, and three other methods, respectively. Thus, the paper presents a total of 26 numerical comparisons between the proposed approach and other wind power forecast methods. Among these 26 numerical comparisons, 21 comparative results have been taken from previous works. It has been shown that the proposed method outperforms all other methods in these 26 numerical comparisons. Moreover, significant differences are seen between the results of the proposed method and other comparative methods. For instance, in terms of average results obtained in the second numerical experiment (which have been presented in the last row of
Table 2), the proposed approach has (7.84 − 5.25)/7.84 × 100% = 33.0% lower MAPE, (4.83 − 3.92)/4.83 × 100% = 18.8% lower NMAE, and (5.99 − 4.65)/5.99 × 100% = 22.4% lower NRMSE than MI-IG+NN+CSSO which is the most accurate comparative method in this numerical experiment. To the best of our knowledge, other published wind power forecast works have less numerical comparisons than our paper.
In addition to tabular results, a graphical illustration of the performance of the proposed approach has been presented. It has been shown that wind power time series has irregular patterns as well as sudden changes and ramps. However, unlike these complex behaviors of wind power time series, the forecast curve generated by the proposed approach reasonably follows the actual curve and the forecast error curve has small values, which indicate good performance of the proposed wind power forecast method.
6. Conclusions
This paper presents a new wind power prediction approach. Higher effectiveness of the proposed approach compared with 26 other wind power forecast methods has been extensively illustrated in the paper. By providing more accurate wind power forecasts than previous methods, the proposed wind power prediction approach can be useful for both wind farm owners and power system operators. With more accurate wind power forecasts, wind farm owners can gain more profits in electricity markets and power system operators need less reserves to cope with the uncertain nature of wind power which in turn decreases the operation cost of wind power-integrated power systems. In addition to wind farms and power systems, the proposed wind power prediction approach can be also useful for microgrids. With more accurate wind power prediction results, a microgrid operator can better manage its wind units and transactions with the upstream grid to decrease its operations costs and obtain more benefits.
Within the proposed approach, wind power time series is first decomposed through a new EMD based on IKIM. In this way, a complex wind power time series is decomposed to its various frequency components, which can be analyzed and predicted more effectively. Afterwards, an information-theoretic feature selection method selects the most effective candidate inputs to predict each component. A closed-loop forecasting engine learns the input/output relation between these selected candidate inputs and the output, i.e., the future value of the associated time series. Unlike conventional open-loop forecast methods, the proposed closed-loop forecasting engine uses an effective feedback of the output to enhance the efficiency of the training process.
While the proposed prediction approach has high forecast accuracy, it can provide point forecast for wind power. Extending the proposed approach to probabilistic forecast, i.e., predicting wind power density function, can be considered as the future work. Predicting wind power density function can be used, for instance, to generate scenarios which are required in stochastic programming methods.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}