1. Introduction
Benefiting from the huge number of high-quality spectral-temporal images captured from Earth observation satellites, or unmanned aerial vehicles (UAV), automatic crop classification [
1,
2] is becoming a fundamental technology for yield estimation, economic assessment, crop transportation, etc. Conventional classification methods, such as support vector machine (SVM) [
3], K-nearest neighbor (KNN) [
4], maximum likelihood classification (MLC) [
5], etc., have been successfully applied in crop classification. However, these methods may be insufficient under the circumstances vegetation, etc. For example, many agricultural sectors of Chinese local governments are doing heavy manual labelling work to assure accurate reports. Therefore, it is still very important to develop new crop classification technologies.
Classification methods in remote sensing mainly consider two aspects, a feature extractor that transforms spatial, spectral, and/or temporal data into discriminative feature vectors, and a classifier that labels each feature vector to certain types. For crop or vegetation classification, the spatial and spectral features are typically extracted in two ways. One is to aggregate spectral bands into vegetation indices that represent the physical characteristics of vegetation, within which the normalized difference vegetation index (NDVI) is mostly used. Wardlow et al. analyzed the time-series MODIS 250 m enhanced vegetation index (EVI) and NDVI datasets for crop classification [
1]. Xiao et al. utilized NDVI, EVI and land surface water index (LSWI) aggregated from MODIS temporal images to discriminate rice from cloud, water, and evergreen plants [
6]. Conrad et al. divided MODIS 250 m NDVI time series into several temporal segments, from which metrics were derived as input features for crop classification [
7]. Sexton et al. utilized humidity, luminance, NDVI, and their changes extracted from multi-temporal Landsat TM-5 images to classify land cover [
8]. Simonneaux et al. produced NDVI profiles from a time series of ten radiometrically corrected Landsat TM images, and used the profiles to identify four crop types [
9]. In [
10], tasselled cap indices extracted from bi-temporal ASTER data were utilized for classifying crop rotations of cotton, winter wheat, and rice. In [
11], a subset of features was selected out by random forest from 71 multiseasonal spectral and geostatistical features computed from RapidEye time series, to achieve the best crop classification accuracy. The other is to directly use original multi-temporal images for classification. Zhu and Liu classified the plant types of a forest using five Landsat TM-5 images and two Landsat TM-7 images of different times [
12]. Guerschman et al. analyzed the performances of original images and NDVI on a land cover classification from multi-temporal Landsat images, and showed that better accuracy could be obtained by using all the temporal and spectral bands than using NDVI [
13]. Esch et al. used both the multi-seasonal IRS-P6 satellite imagery and the derived NDVI based seasonality indices for crop type classification and a cropland and grassland differentiation [
14].
In addition to spatio-temporal images, other remote sensing data, such as polarimetric synthetic aperture radar (SAR) images, with texture features extracted from them [
15], are also utilized as inputs for a crop classification. McNairn et al. tested PALSAR multipolarization and polarimetric data for crop classification and found their performance to be competitive with that of temporal Landsat images [
16].
As to classifier, SVM [
3,
11], KNN [
4], MLC [
5], artificial neural network (ANN) [
5,
17], decision tree [
9,
14], and random forest [
18] are commonly used for vegetation classification. Murthy et al. compared a MLC, iterative-MLC, Principal Component Analysis (PCA) based MLC, and ANN for wheat extraction from multi-temporal images, and pointed out that ANN performed the better results [
5]. Zhu and Liu utilized a hierarchical classification strategy and a recursive SVM framework to obtain a tree-type forest map [
12]. Omkar et al. utilized a combination of multiple classification technologies, including MLC, particle swarm optimization (PSO), and ant colony optimization (ACO) for crop classification from a high-resolution satellite image [
19]. Gallego et al. assessed the efficiency of different classification algorithms, including neural networks, decision trees, and support vector machines for crop classification based on a time series of satellite images [
20]. Siachalou et al. used Hidden Markov Models (HMM) to set a dynamic model per crop type to represent the biophysical processes of an agricultural land [
21].
In recent years, deep learning has been widely used and has become mainstream in artificial intelligence and machine learning [
22]. Deep learning is a representation-learning method that can automatically learn internal feature representations with multiple levels from original images instead of empirical feature design, and has proved to be very efficient in image classification and object detection. In contrast, vegetation indices such as NDVI only use several bands and may lead to low performance in complicated situations, e.g., crop classification where the spectrums, periods, geometry, and the interactions of various types of crops might be considered. Whereas, original temporal images used as feature input could contain noises or unfavorable information that decrease the performance of a classifier.
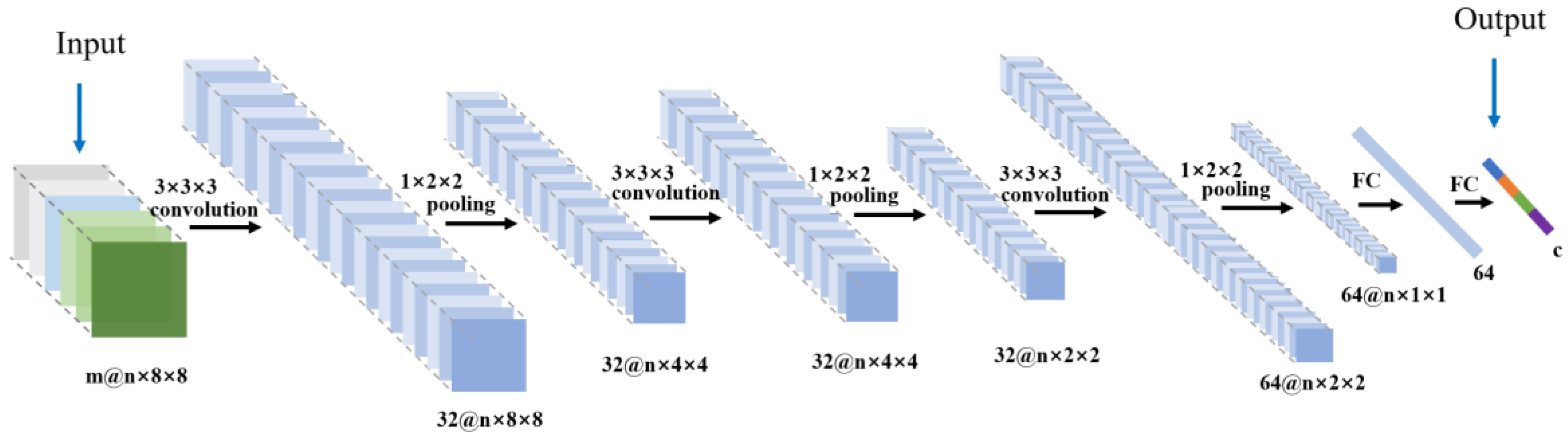
The main objective of our study is to represent distinctive spatio-temporal features of crops by deep learning. In recent years, studies that were related to convolutional neural network (CNN) has been successfully applied in handwriting recognition from binary images [
23], labelling from mainstream RGB image set [
24], classification from multi-spectral or hyperspectral data [
25], learning from videos [
26], classification of brain magnetic resonance imaging (MRI) data [
27], etc. However, a traditional two-dimensional (2D) CNN, mainly designed for RGB images, lacks the ability to extract the third dimensional features accurately. A 2D convolution causes the extracted features in additional dimensions (i.e., spectral or temporal) of a layer to be averaged and collapsed to a scalar. To overcome this, Kussul et al. introduced two CNNs for crop classification, one 2D CNN for spatial feature learning, and the other one-dimensional (1D) CNN for spectral feature learning [
28]. However, this strategy requires additional empirical processing to combine the learned features, and hurdles a full automatic representation learning procedure.
Three-dimensional (3D) convolution naturally suits to spatio-temporal presentations. Recently, some studies have utilized 3D CNN for learning spatio-temporal features from videos [
29,
30], learning 3D structures from LiDAR point clouds [
31], or learning spatio-spectral presentations from hyperspectral images [
32]. In general, 3D CNN is not as widely applied as 2D CNN, as the temporal dimension is usually not considered in computer vision and machine learning. Remote sensing images generally provide dynamic or temporal information, from which more information could be extracted. For example, the relations among multi-temporal pictures of a certain crop are explicit. The rice growth cycle includes germination, tillering, spike differentiation, heading and flowering, milking and a mature stage. But these temporal features are often partially ignored or represented by simplistic models. Some studies [
5,
12,
13], simply concatenate temporal images to represent period information; while in [
8], only images of early growing season, late growing season and dormant stage were selected. In theory, a proper 3D convolution can extract these spatial and temporal features simultaneously in a more delicate and rigorous manner other than a direct concatenation of reflectance images. In this study, we develop a 3D CNN framework to extract information for multi-temporal images and compare it to a 2D CNN and some conventional empirical methods as SVM, KNN, etc.
Deep learning requires sufficient manual samples that are difficult to be obtained in our situation when crop types, varieties of a certain type of crop, and planting season vary from time to time. To achieve a satisfactory learning result with limited samples and reduced amount of labor work, we introduce a semi-automatic semi-supervised active learning strategy [
33]. Active learning is used to pick up the most helpful unlabeled samples (i.e., samples supposed to best improve model performance), according to their scores to each label predicted from the current CNN model, for manual checking, and model retraining, iteratively.
To our knowledge, 3D CNN has not been applied to crop classification using multi-spectral multi-temporal remote sensing images, and compared to 2D CNN and other conventional methods. In
Section 2, we introduce a 3D convolutional kernel, 3D CNN structure, and an active learning strategy for crop classification. In
Section 3, three tests are carried out to evaluate 3D CNN performance, as compared to 2D CNN and conventional methods. Discussions and conclusions are given in
Section 4 and
Section 5, respectively.
4. Discussion
Except for CNN parameters, the quality of original samples is also important for remote sensing classification. A widely used preprocessing is segmenting original images to hyper-pixels for obtaining more “pure” samples. We test the performance of hyper-pixel inputs extracted from the GF1 data, when considering the 8 × 8 window patches we used before may contain mixed classes. The whole image is firstly segmented by the method that is developed by Liu et al. [
39] to hyper-pixels, and every 8 × 8 patch sample (16 × 16 patch shown in
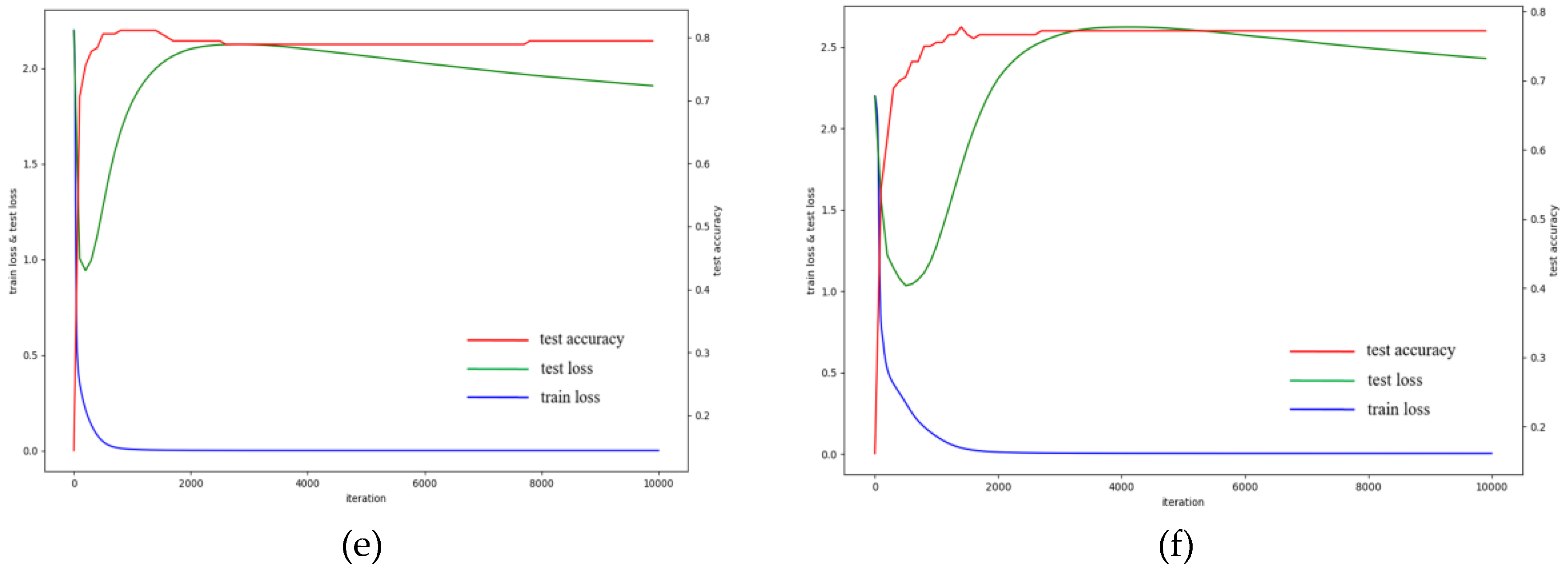
Figure 11 instead for better vision) is then obtained by the superposition of the corresponding hyper-pixel upon 8 × 8 background template. However, the test accuracy decreased near 2 percent when compared to that of our original input. One plausible explanation is that the segmentation operation may introduce confusing information to classification, especially the shapes. The penalty of this exceeds the contribution of pixel purity. We did not test this on 3D CNN because the hyper-pixels containing the same sample points show different shapes in different periods.
Another interesting question is whether spectral features, extracted from the combination of red, green, blue, and infrared bands, also have a high performance on crop classification. The current 3D convolutional network can be easily modified to check this by stacking the spectral images of a certain time first according to
Figure 2. We applied the modified 3D tensor inputs on the GF1 dataset but kept all the CNN parameters the same. From
Table 7, the spatio-spectral 3D CNN obtained much worse result when comparing to the spatio-temporal 3D CNN and a slightly worse result when comparing to the 2D CNN. The latter may be caused by the lack of more spectral bands or the inevitable noise in a “standard” spectral curve of a certain material, which is a common case in multi-spectral images. However, the processing of spatio-spectral information is not the focus of this study, and other recent articles could be referred [
32].
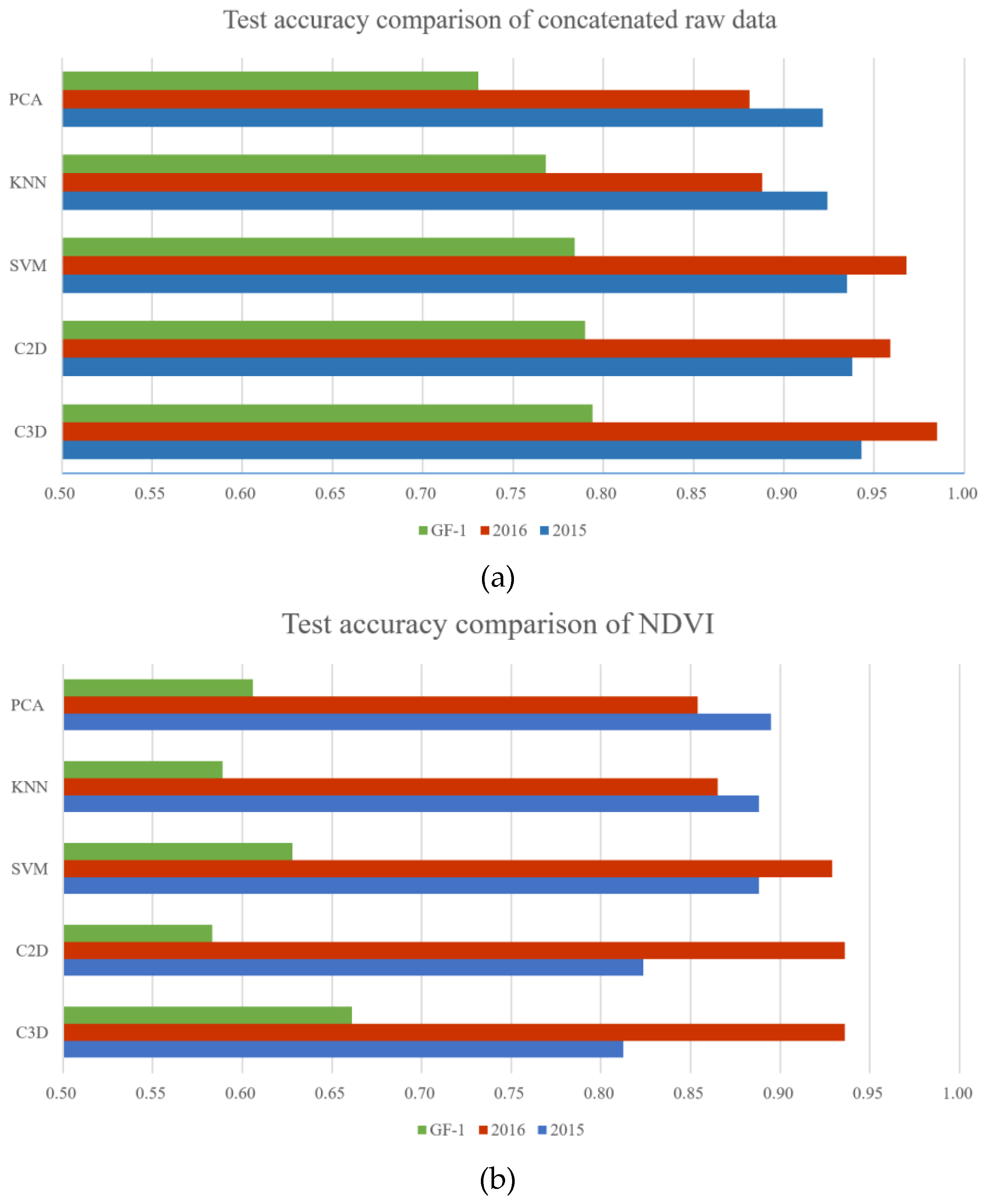
Third, we discuss more on the performance comparison of 2D CNN, 3D CNN, and SVM in pixelwise classification, which is the most common case in remote sensing applications other than the training-test procedure on discrete samples [
8,
12]. The overall accuracy of 3D CNN exceeds that of 2D CNN and SVM about 3% in average, and about 6% in the most challenging GF2 2016 data, where all of the other methods failed to discriminate corn from rice. The 3D CNN outperforms the 2D CNN purely with the learned spatio-temporal representations since they share the same parameters and classifier. The performance of SVM is approaching that of 2D CNN, which indicated that the concatenated temporal images are a good representation and match the state-of-the-art multi-level representation learned by a conventional CNN, if we ignore the classifier difference. It also explains from a side that the concatenated temporal images have been widely used in vegetation classification [
12,
13]. However, representing temporal features only by a concatenation operation is oversimplified and is not as good as spatio-temporal representations extracted by the 3D CNN.
At last, in this study, only temporal images and NDVI are used for feature inputs. We obtained similar result as Guerschman et al. [
13], which also shows that advantage of using the whole spectral profile instead of the NDVI. The other method [
8] utilized a feature combination of NDVI, humidity and luminance. Luminance is a spatial feature that could be extracted from original images, while humidity could be hard to accurately retrieve from spectral sensors with similar vegetarian covers. Testing all types of empirical features that are used before is unrealistic. We are interested in if additional empirical features could help the selectivity of CNN-based representations and further improve the performance of CNN methods. We added every NDVI layer to the corresponding original temporal image to train the 2D CNN.
Table 8 shows they obtained similar performances. It implies that a CNN based method could learn the optimal representations and including new empirical features is unnecessary.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}