1. Introduction
Synthetic aperture radar (SAR) imaging is an all-day, all-weather, high-resolution and wide-coverage remote sensing technology. With the evolution of SAR technologies, massive SAR images with abundant characteristics (e.g., high resolution, multi-aspect, multi-dimension, multi-polarization) have been provided for important applications in geo-graphical survey, climate change research, environment, Earth system monitoring and so on [
1,
2]. Due to the complex scattering mechanisms, geometric distortions and speckle noises in SAR image, the interpretation and understanding of SAR images are much different from optical image analysis. The intelligent processing of signal and information has created huge demands in practical electronic intelligence systems [
3,
4,
5]. Accordingly, to bridge the SAR systems and their applications, SAR image automatic interpretation, especially automatic target recognition (ATR), has become an important research topic in surveillance, military tasks, etc., and has been studied continuously for more than 20 years [
6].
The MIT Lincoln Laboratory proposed a standard architecture of SAR ATR, which contains three stage: detection, discrimination, and classification [
7,
8]. Detection is to extract candidate target region from SAR images. Essentially, it is a binary classification problem to determine the target and background. The output might include not only the targets of interests such as tanks, armored vehicles, and missile launchers, but also the false alarm clutter such as trees, buildings, bridges, and cars. At the discrimination stage, in order to eliminate false alarms, several features are selected to train a discriminator to solve the two-class (target and clutter) problem [
9]. Finally, the classifier is used to categorize each input sample to a specific target type. On the final classification stage, there are four mainstream paradigms: template matching, model-based methods, neural networks, and machine learning [
8,
10,
11,
12,
13,
14,
15,
16]. Recently, the emerging deep learning methods demonstrate their excellent target feature extraction and recognition capability in natural and optical imagery, which has motivated many researchers to study convolutional neural networks (CNN) [
17], deep convolutional autoencoder (CAE) [
18], deep belief network (DBN) [
19], and restricted Boltzmann machine (RBM) [
20] in SAR image classification and target recognition issues.
At the beginning of deep learning research for SAR ATR, the recognition performance improvement is the main objective of method innovation. Due to limited training samples, the SAR ATR networks are usually more shallower than the natural image recognition case. As for the type identification, both shallow CAE and CNN are employed to conduct MSTAR and TerraSAR-X data recognition with sparsely connected convolution architectures and fine-tuning strategies, and achieve high recognition accuracy over
[
17,
21,
22]. Lately, various handcrafted features combined with deep learning for precise recognition, like multi-aspect scattering feature, texture feature and so on. Except for the CNN framework, the bidirectional LSTM (Long Short-Term Memory) networks and multi-channel CNN networks are introduced to learn the multi-aspect scattering features of targets [
23,
24]. Compared with existing single aspect scattering feature learning methods, these two methods can achieve the more robust and precise recognition.
Although being powerful in segmentation, detection and classification, CNN as a supervised discriminative network is highly sensitive to the selection and size of training samples and thus it is susceptible to the overfitting problems, which is known as data dependency issue [
25,
26,
27]. The most straightforward idea is to generate artificial target images under different conditions augment training data set and thus generalize the discriminative model. Based on this idea, Generative Adversarial Networks (GANs) have been introduced to generate simulated massive image samples based on limited training images [
28,
29]. Similarly, the transfer learning methods are employed to solve the limited data sample problem by transferring the knowledge learned from unlabeled sample to the labeled target data in an assembled CNN architecture [
30]. Meanwhile, some improved deep neural network frameworks are proposed to adapt to limited sample learning or zero-shot learning [
25,
31]. Through the recent small sample oriented SAR-ATR research, the data dependency of deep neural network can be greatly reduced, which improves the applicability of the deep ATR networks.
In practical ATR applications, the resources of a data processing platform including power consumption, computation and storage are always very expensive and limited. In the field of general deep learning, how to maintain recognition accuracy while reducing resource requirements has become a hot topic in the past few years. To achieve a high classification accuracy, researchers have built deeper and larger convolutional neural networks and have to train them on large computer clusters with high-performance graphics cards, e.g., the power-consuming VGG-16 model is over 500 MB and requires hours or even days to finish training. On the other hand, there is a growing demand to deploy the SAR ATR algorithms in mobile and low-power platforms to realize realtime processing, e.g., airborne SAR and spaceborne SAR platforms. Such applications depend on the local trained deep neural network, and require model to learn high-level features quickly and energy-efficiently. Regardless of computing power, power consumption, and storage, the performance of mobile platform is much lower than that of computing servers. Therefore, there is a great demand for the solution that can greatly reduce the training time, inference time, storage size and power consumption of deep neural network. These computing, memory and power resources are dominated by the number of total multiplications and memory access of network weights. So, efficient computation and compression algorithms for deep neural networks are being studied extensively in both academia and industry.
To solve the problem of large model size, Songhan proposed two kinds of compression method: SqueezeNet [
32] and Deep Compression [
33], which include pruning, quantization and Huffman coding methods. These methods achieve a high compression ratio in AlexNet, VGG-16 and LeNet-5 and make it possible to fit them in on-chip SRAM cache. However, Deep Compression discussed in Songhan’s work mainly focused on compression rather than acceleration which is also important for real-time image processing. Moreover, AlexNet, VGG-16 and LeNet-5 are over-parameters which possess millions amount of parameters in their fully connected layers. While the networks designed for SAR-ATR are mainly consisted of convolutional layers which have much fewer parameters than fully connected layers and more sensitive to pruning, the method in Deep Compression is likely to harm the performance of these networks. Besides, the SqueezeNet squeezes network through trial and error, and does not quantify the squeezing ratio. In our paper, we propose to use pruning to give a quantified squeezing ratio and then carefully combine two compression method to achieve a high compression ratio in CNN. Many other compression works like HashedNets (Chen et al., 2015) [
34] reduce model sizes by using a hash function to randomly group connection weights, so that all connections within the same hash bucket share a single parameter value. Gong et al. (2014) [
35] compressed deep convolutional networks using vector quantization. Both methods studied only the fully connected layer and ignored the convolutional layers, while our work mainly focus on the compression of convolutional layer.
In addition to compressing the networks, there is also a practical need for reducing the computational workload. Xingyu Liu et al. (2018) [
36] suggest that pruning the weight matrix and exploiting the dynamic sparsity of activations can reduce multiplication count in forward propagation. However, such method still needs to perform
in selection to find out non-zero values at each convolution computation, which is quiet wasteful, and thus leading to no training time saving. In order to speed up the basic process step, we propose a novel computation method based on sparsity to save a significant amount of time in selection. Although there have been various deep learning based SAR ATR methods to focus on improving the accuracy, seldom studies have discussed the deep network compression while maintaining competitive accuracy. Compared to the past works, we make the following contributions in this paper:
We introduce a quantified squeezing method based on pruning, which can find the appropriate squeezing ratio quickly for a sensitive convolutional neural network.
We propose a novel fast convolution computation method for pruned convolutional neural network that can be applied during training and inference process, which can save a significant amount of computation and training time.
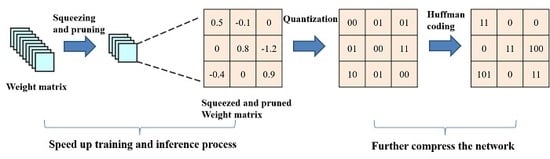
We design a resource-constrained environment oriented CNN for SAR ATR using the pruning, compression and the fast convolution computation to achieve a high compression ratio efficiently while maintaining the considerable accuracy. (The whole process is shown in
Figure 1)
The rest of this paper is organized as follows.
Section 2 explains the details of our compression method and fast algorithm. Then experimental statistics and analysis are presented in
Section 3. Finally our conclusions are drawn in
Section 4.
2. The Proposed Method
Recent research on CNN-based SAR ATR has focused on the accuracy improvement. Due to the deep neural network model and large amount of convolution calculations, it is difficult to deploy the ATR networks on mobile platform with limited hardware resources. The need for real-time target recognition will be hindered, thus limiting the ATR applications. However, the compression of deep neural networks is the most straightforward solution for the case. The network pruning method is a classical way to reduce the model size in that certain weights in each layer are too small to contribute to the feature transmission. Similarly, the cropping of convolution kernel, namely the squeezing method, will greatly reduce the number of model parameters. Moreover, the ATR problem is essentially a qualitative determination of the target category. In the sense, the representation of model does not have to be as high precision. After those structural level compression, the quantization and coding will be applied for further compression.
2.1. Quantified Microarchitecture Squeezing Method
We know that for a given accuracy level, there are multiple CNN architectures that can achieve that accuracy. However, the problem of identifying a slimmer CNN architecture is challenging. Recent works squeeze the architecture through a few basic guidelines or principles such as decreasing the number of input channels, but none of them quantify the squeezing ratio.
Here, we deploy the network pruning method to help us squeeze CNN architecture rather than trial and error. Network pruning is proved to be a efficient way to reduce the network complexity in early work [
37]. All connections with weights below a threshold are removed from the network and neurons with zero input connections or zero output connections will also be pruned, as shown in
Figure 2.
Based on network pruning, we define pruning ratio:
and squeezing ratio:
in each layer as follows:
We start training the network and then pruning the weight matrix in each layer without causing accuracy loss. According to the pruning ratio in each layer, we can measure the redundancy of each layer and squeeze those layers that have a large pruning ratio and redundancy. Because pruning only impacts the computation in one specific layer but squeezing will change the size of output and computation in the next layer, we should be careful when doing squeezing and choose a smaller squeezing ratio than the pruning ratio. Moreover, we do not squeeze the kernel size in small networks, e.g., squeezing a kernel to a kernel, since it is too aggressive and will cause great accuracy loss if only small-scale redundancies exist in the weight matrix. Instead, we reduce the number of channels in convolutional kernels or the number of hidden units in fully connected layers according to the squeezing ratio.
Finding the slim architecture could be an iterative process. Each iteration consists of a network retraining process followed by a network squeezing process. In first iteration, we can employ an aggressive squeezing strategy because the original network has the most significant redundancies. After first time iteration, the new and squeezed network needs to be retrained until it reaches the same accuracy level as the original network. If the accuracy of squeezed network drops a lot, we should reduce the squeezing ratio. Although the new network becomes much more sensitive to pruning and squeezing, we may do gentle pruning and squeezing to it. We will end the iterative process until the pruning ratio is small since it shows that the redundancy is small and keep squeezing the network is likely to hurt the performance.
Suppose we do iterative squeezing in a
convolutional kernel. In first iteration,
of weights in the kernel are pruned without accuracy loss, then we may squeeze it to a
one. Here the pruning ratio is
and the squeezing ratio is only
. In second iteration, we pruned
of weights and squeeze
of the kernel to a
. In third iteration, we can only prune
of weights and will stop squeezing since the pruning ratio is too small. The process is shown in
Figure 3.
2.2. Fast Algorithm for Pruned Network
After the pruning and squeezing process, we obtain a pruned network with a small pruning ratio. Like the example in
Figure 3, the kernel will be squeezed untile the pruning ratio is small enough. In the end, the squeezed kernel has only
weights pruned. So, the weight matrix in each convolutional layer of the network is not sparse enough to be stored in compressed sparse row (CSR) or compressed sparse columns (CSC) format. Here, we propose a new convolutional computation method to exploit the light-degree sparsity of pruned weights and activation input. Typically, a 2D-convolutional layer performs the computation as follows:
where
(Rectified Linear Unit) indicates the commonly used activation function,
w is the weight matrix with dimension
,
i represents the row number of
w,
j represents the column number of
w,
A is the input feature map,
b is the bias,
Z indicates the output feature map,
m represents the row number of
Z,
n represents the column number of
Z.
We perform the multiplication only for non-zero
and elements
. To fully exploit the sparsity of the activation input, we first store the non-zero values and indexes of each
in dictionaries. It is a single-time cost computation and we do not need to pick out non-zero values
in future computation any more. The detail of the computation approach is shown in
Figure 4. Here, the size of kernel is
, so we partition the activation input into 4 groups and store the non-zero values in each group. Then, we calculate each non-zero weights, that is
and
, and their corresponding non-zero input values. At last, we will add up the results of these two groups according to the index of each result. The results with same index in different group will be added together.
2.3. Weight Sharing and Quantization
Weight sharing is a common technique used to compress the network and reduce the number of bits needed to store for every weight. According to the weight sharing method discussed in Deep Compression, we adopt k-means weight sharing algorithm and take linear initialization between of the pruned weights, which helps to maintain the large weights. Then suppose that we can use k cluster indexes to represent n weights, we only need bits to encode every cluster index.
Another thing we should notice is that our CPU does not allocate space in individual bits, but in bytes. Typically on a 32-bit processor, the compiler will allocate memory size as
, where
N is the bits sizes and
S is the byte sizes. So we cannot store cluster indexes separately which will cause memory wasted, instead we should store all indexes together.The details of the algorithms is illustrated in
Figure 5.
Commonly, we use 4 bytes to store each weight, then the compression ratio can be calculated as:
In
Figure 5, we have a layer that has 4 input neurons and 4 output neurons, the weight is a
matrix, some weights in the matrix are pruned to zero. In weight sharing, the weights are clustered to 4 bins (denoted with 4 colors), and all the weights in the same bin share the same cluster index and cluster center. Each cluster index is represented with 2 bits. The compression ratio is:
2.4. Huffman Coding
The occurrence probability of each weight index is different, especially in the pruned layer. In pruned layers, the remained zero weights and weights with small absolute value can be easily clustered into one bin.
Figure 6 shows the count of weight indexes in conv4 layer. It shows that large number of quantized weights are distributed around the mid-value, which is close to zero.
By adopting the Huffman coding which is an optimal prefix code used for lossless data compression, we can exploit the biased weights distributions and further compress the storage. More common weight indexes are represented with shorter coding and fewer bits. The experiment shows that the Huffman coding can save another of weights storage.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}