An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features


Abstract
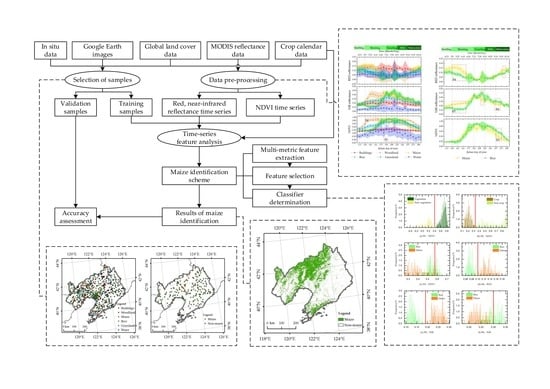
:
1. Introduction
- (1)
- For this study, differences between maize and other land cover types may be more obvious in the red and/or near-infrared band than NDVI in some certain phenological stages of maize.
- (2)
- Since time-series data can reflect the growing rhythm of vegetation, the selected phenological features based on prior knowledge may be better than the statistical features derived from the PCA method.
- (3)
- In this study, the decision tree classifier based on expert knowledge may be more matched than the maximum likelihood classifier based on statistics according to the selected features.
2. Study Area and Materials
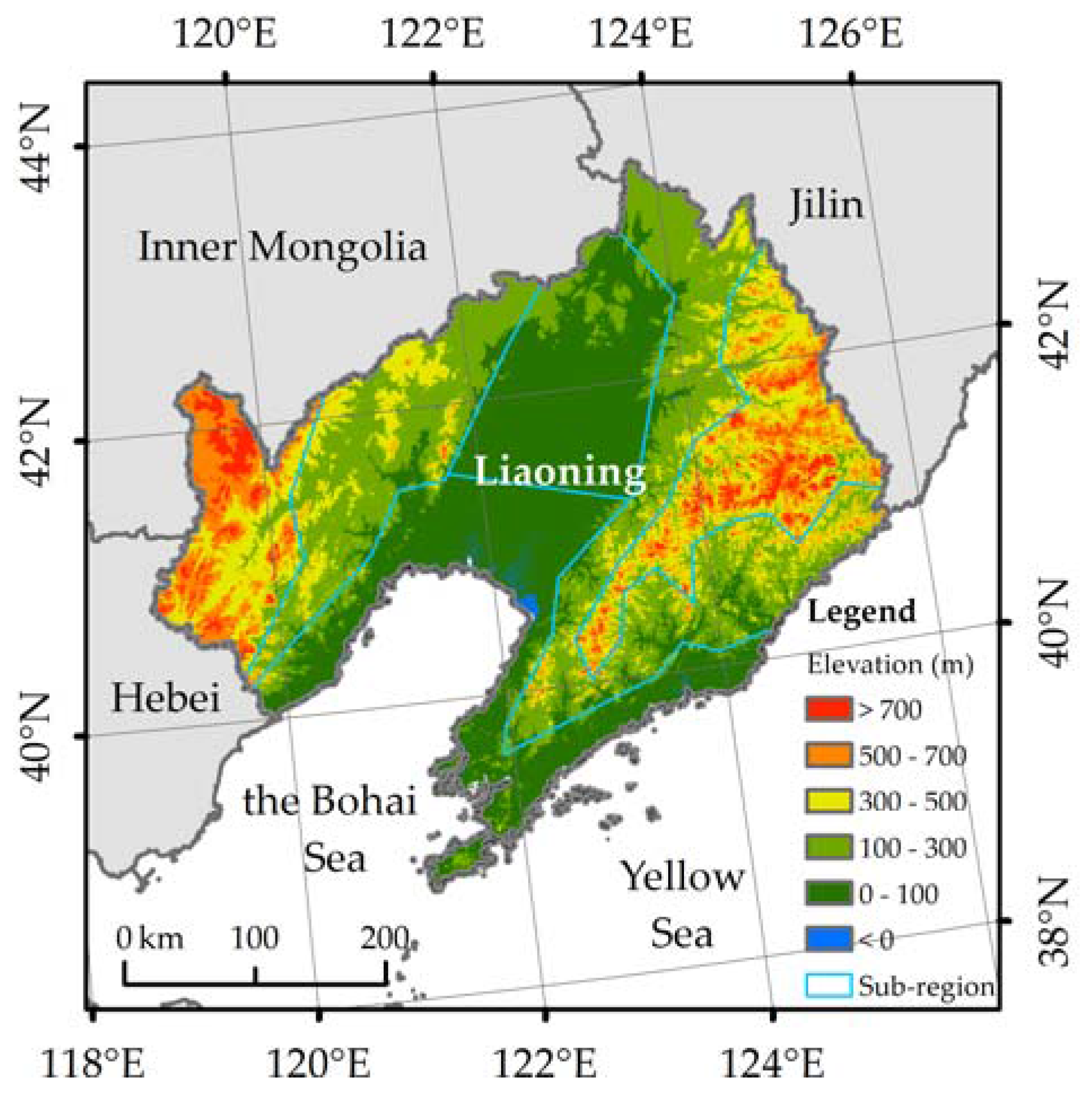
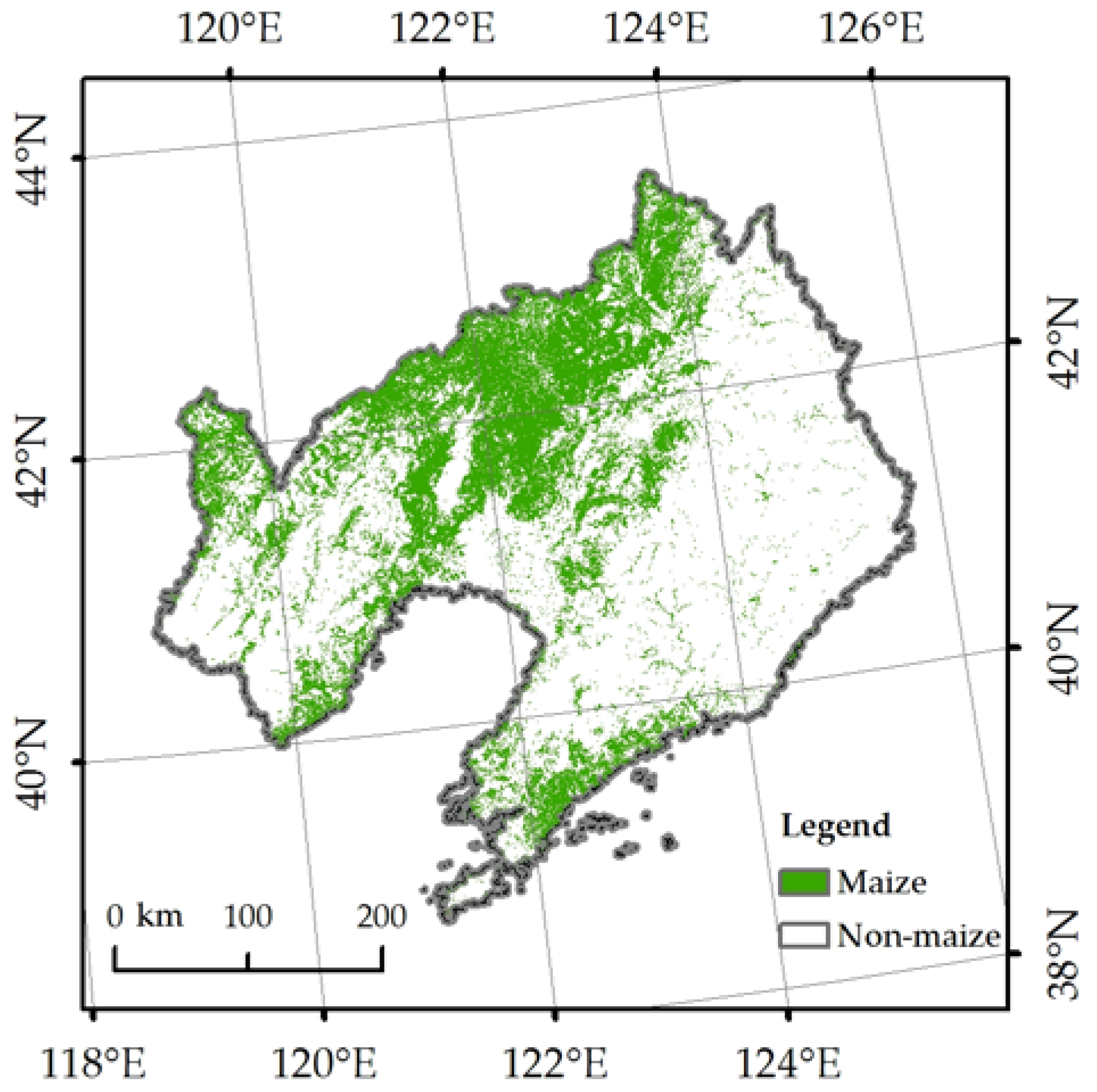
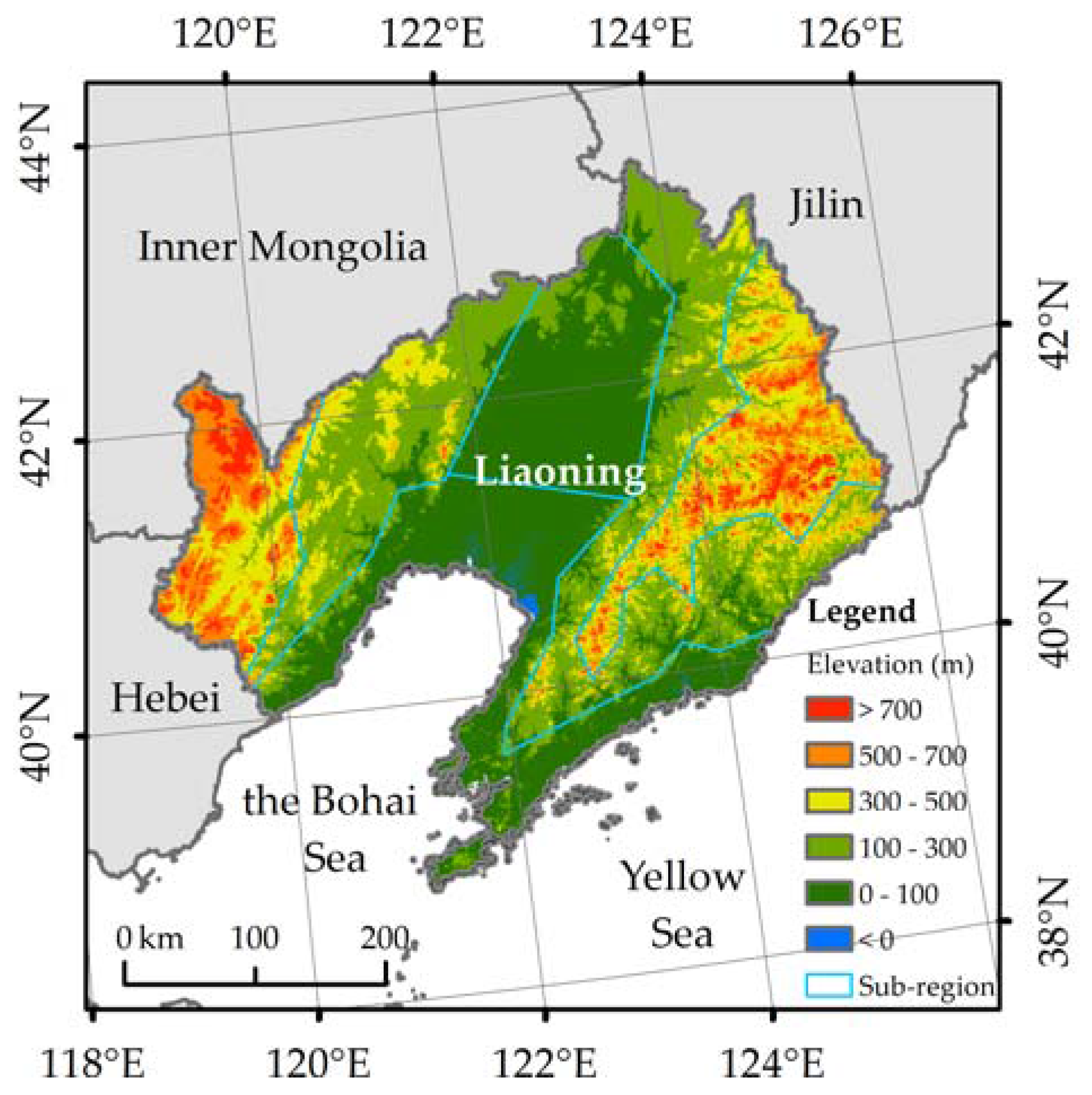
2.1. Study Area
2.2. Materials
2.2.1. Time-Series Data
2.2.2. Other Ancillary Data
- Eighty in-situ maize samples of 200 m × 200 m in 2015 from the Survey Office of the National Bureau of Statistics in Liaoning for the selection of samples. This data came from field surveys, and they were mainly used as the base to select maize samples.
- Google Earth high-resolution images in 2015 for the replenishment of samples. Google Earth provides high-resolution images and user-submitted location-based pictures that can be used to select samples by visual interpretation based on the textures, colors and shapes of different land cover types.
- Global land cover data (finer resolution observation and monitoring of global land cover, FROM-GLC) in 2010 from the Department of Earth System Science, Tsinghua University, for the selection of samples. FROM-GLC was only used as an ancillary reference for sample selection to help determine the type of a given land cover, since its overall classification accuracy is 64.9% and its phase is in 2010.
- Crop calendar data of Liaoning province in 2015 from the Department of Planting Management, Ministry of Agriculture, China, for analyzing the phenological features of crops.
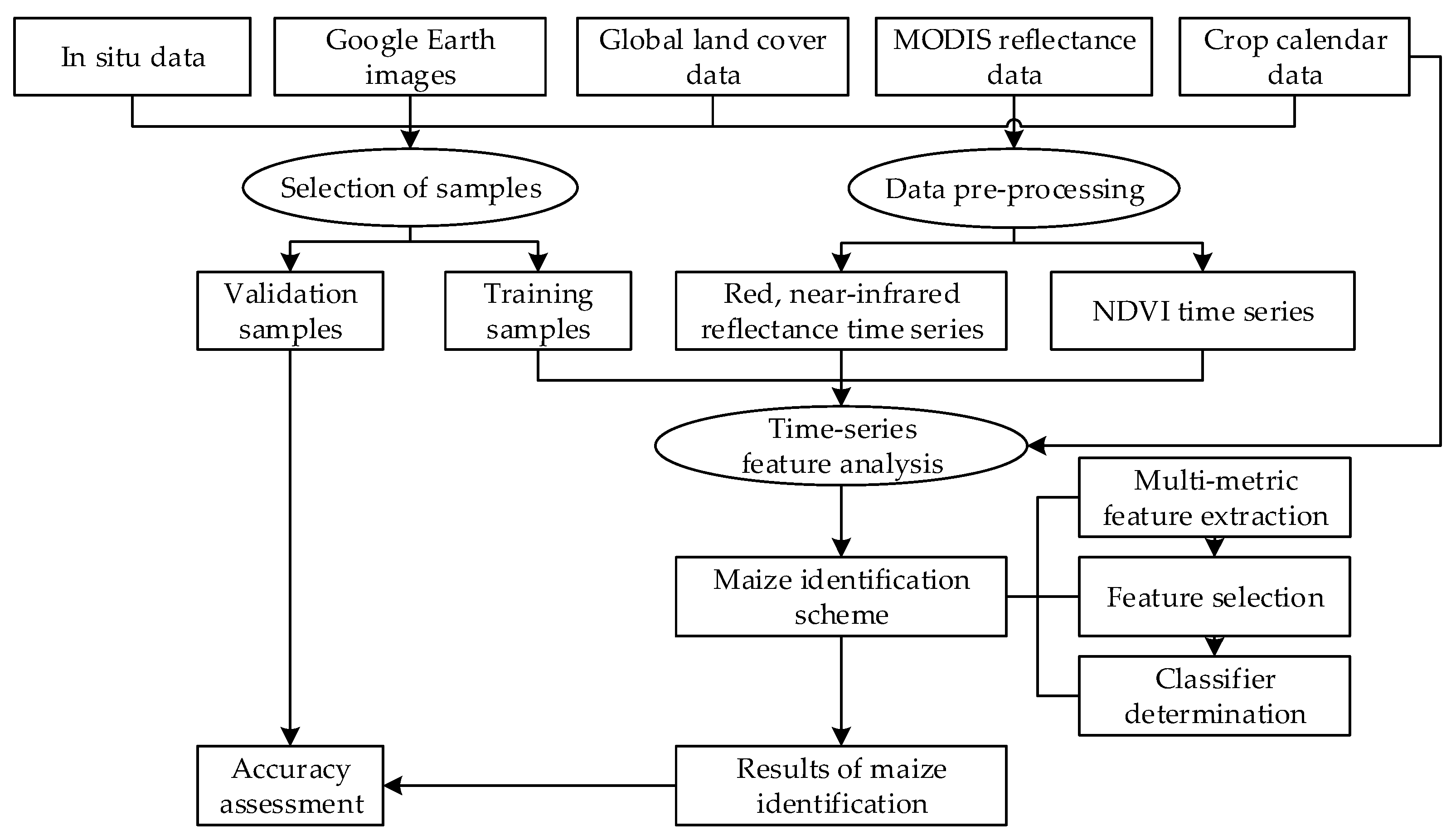
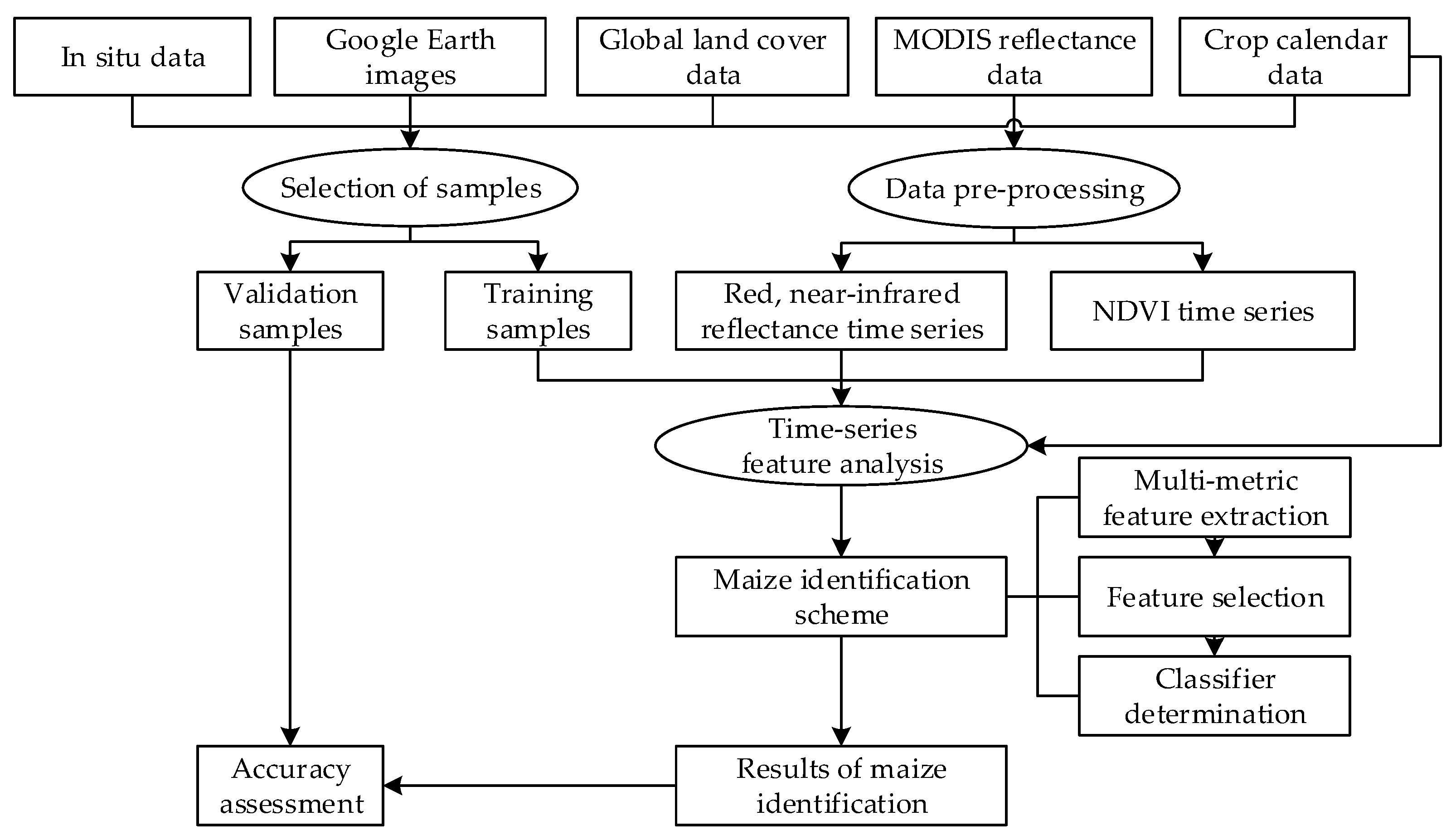
3. Methods
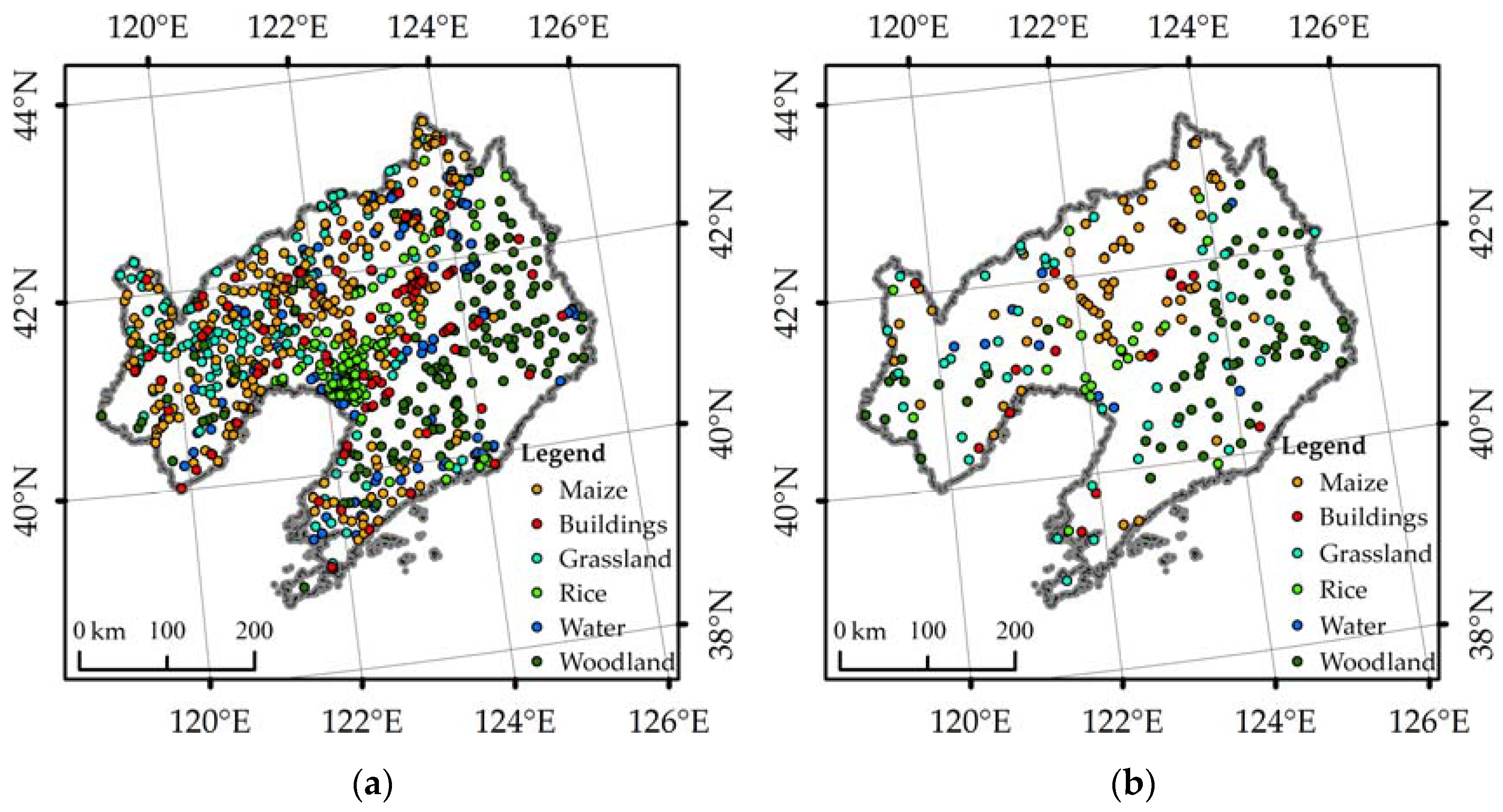
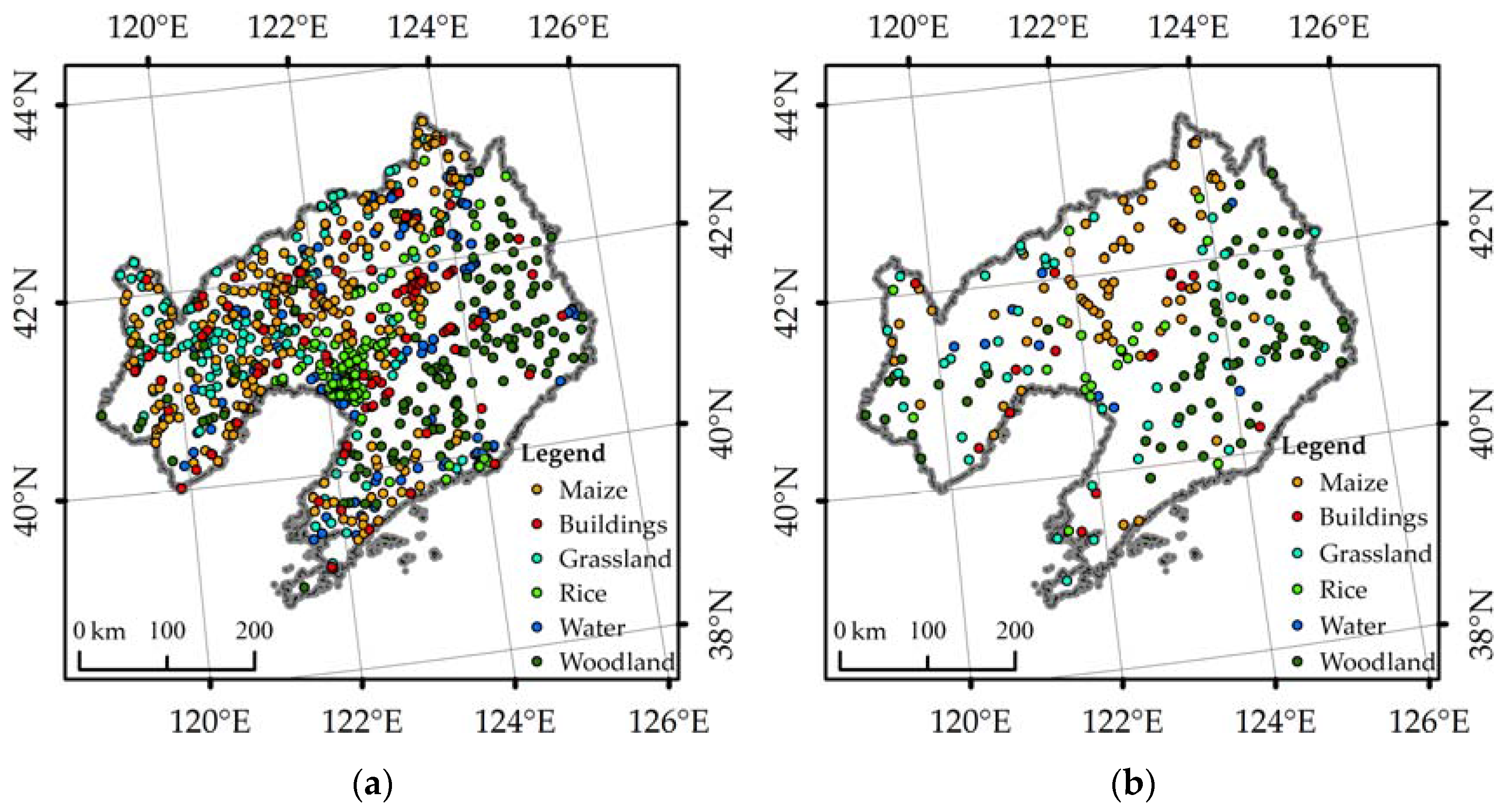
3.1. Selection of Samples
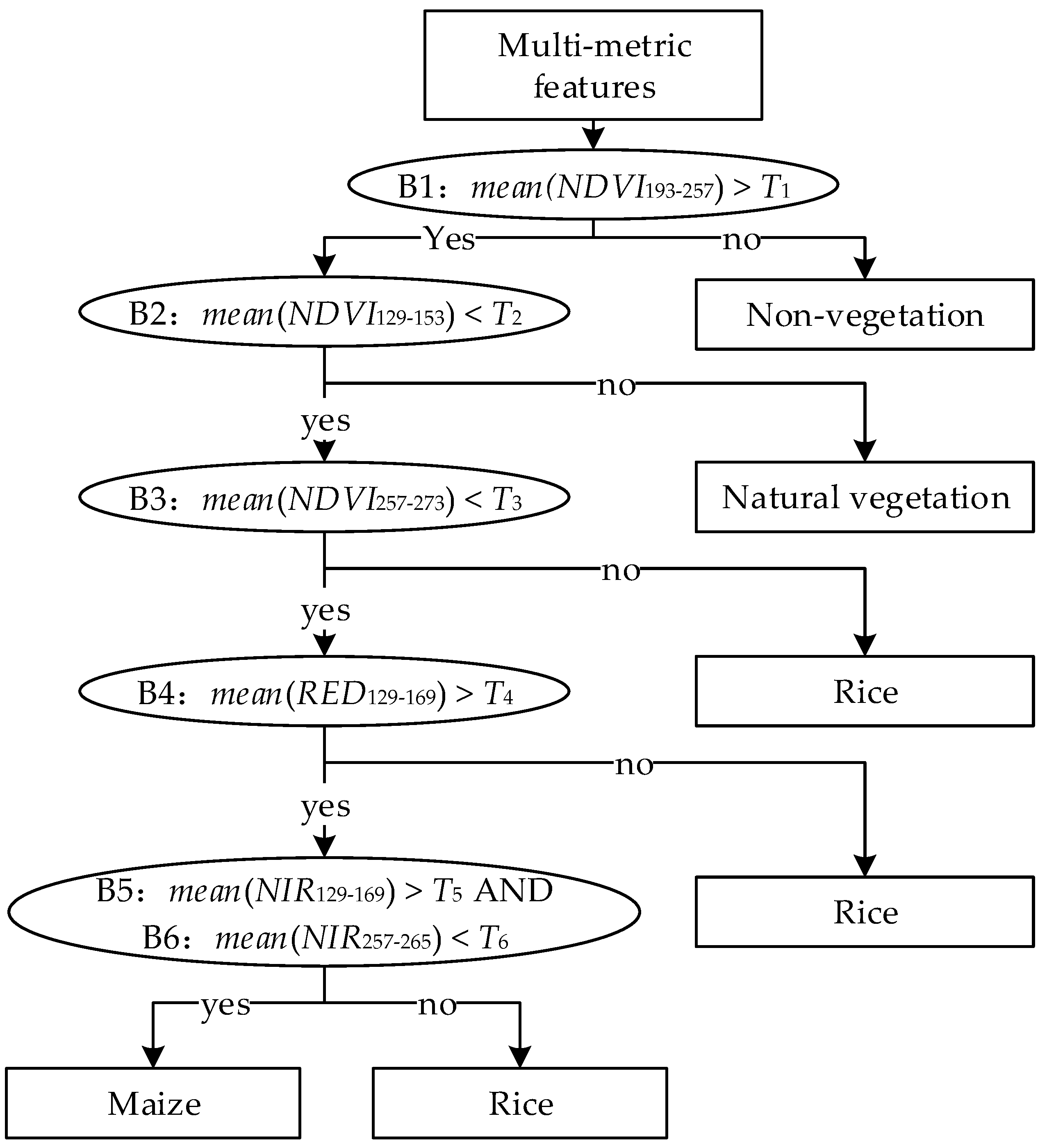
3.1.1. Design of Classification System
3.1.2. Selection of Samples
3.2. Analysis of Phenological Features for Different Land Cover Types
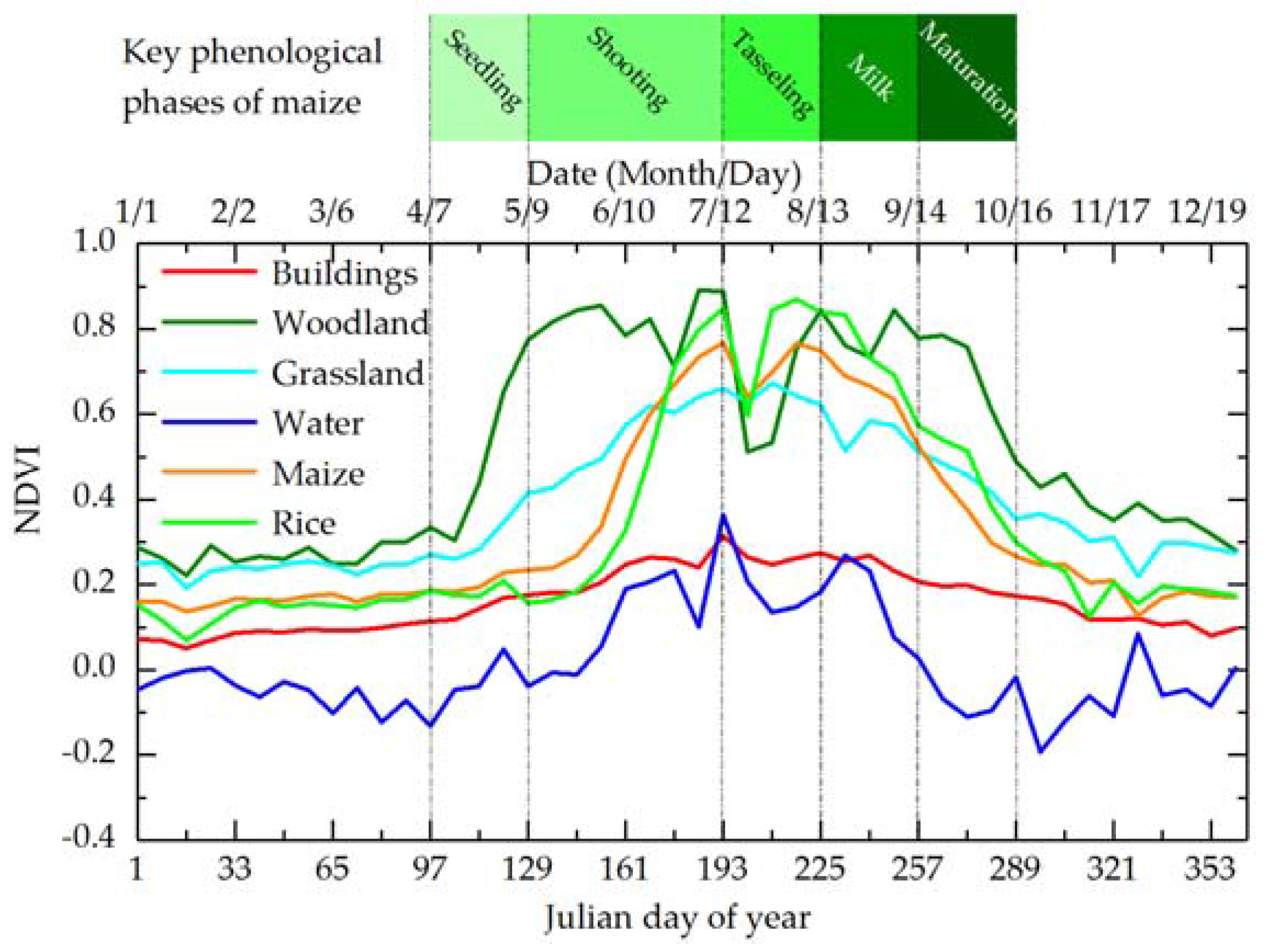
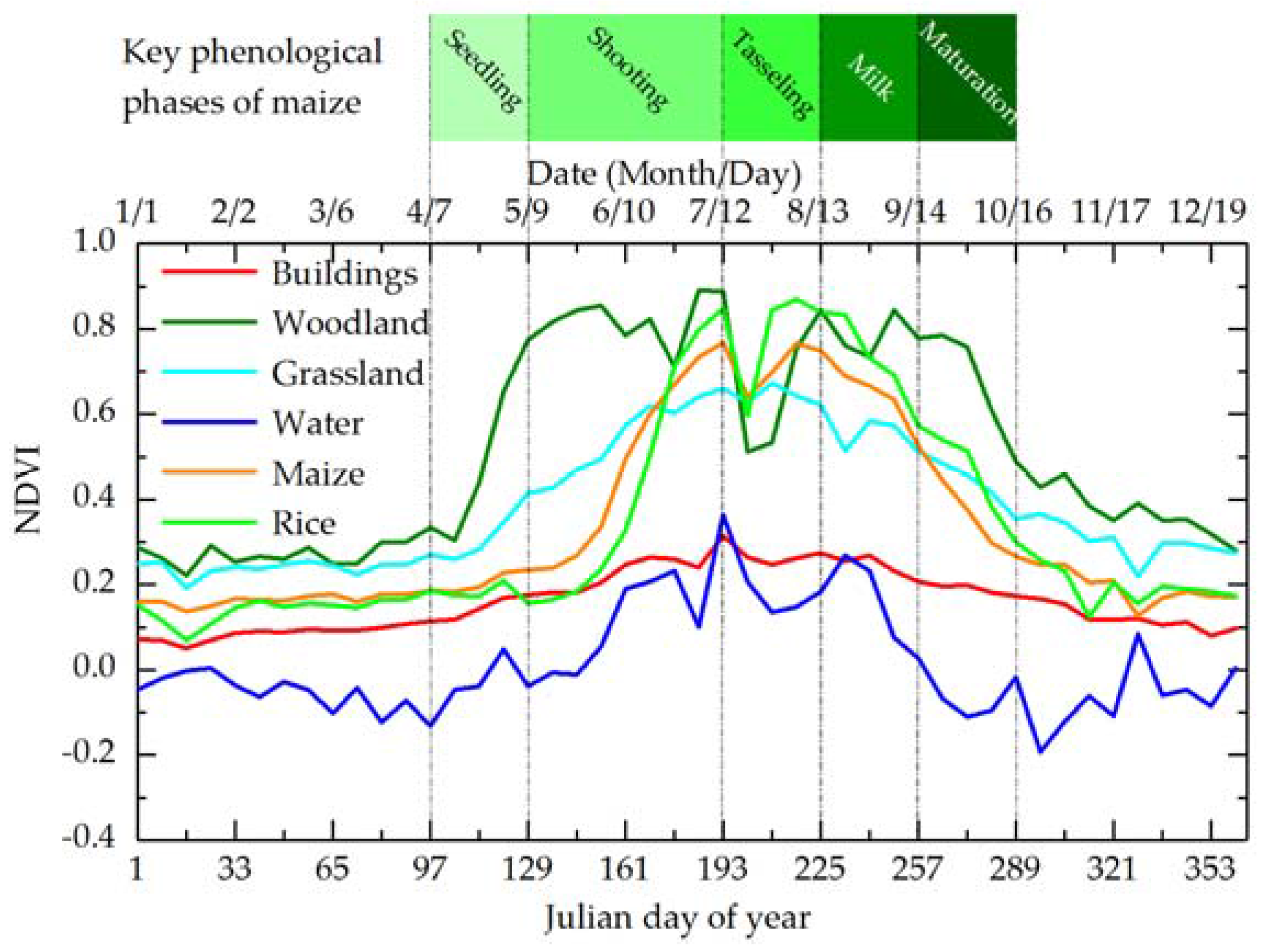
3.2.1. Characteristics of Different Land Cover Types in NDVI Time Series
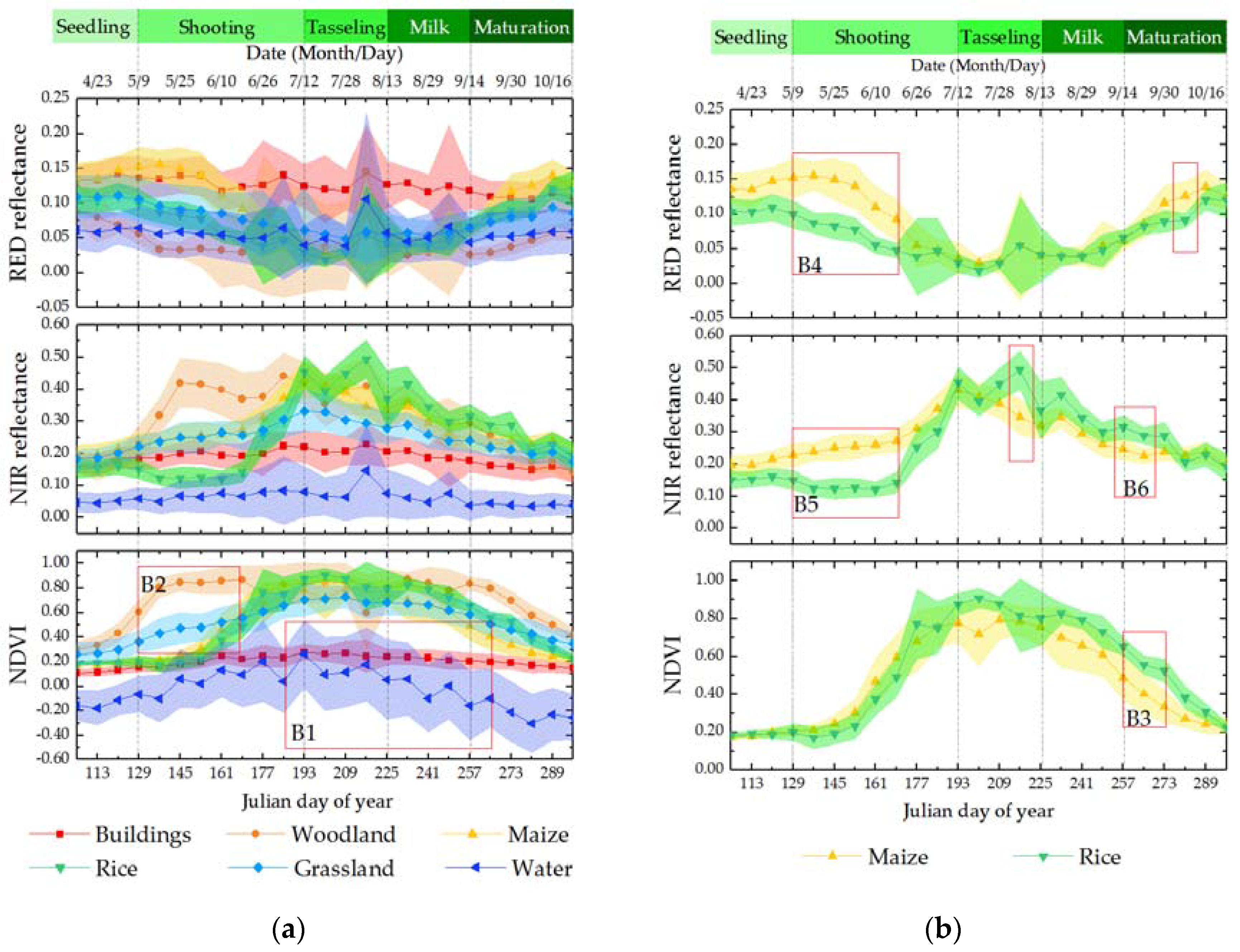
3.2.2. Characteristics of Different Land Cover Types in the Red and Near-Infrared Reflectance Time Series
3.3. Comparison of Different Features for Maize Identification
3.4. Comparison of Different Feature Extraction and Selection Methods for Maize Identification
3.5. Comparison of Different Classifiers for Maize Identification
3.6. Statistical Significance Test Among Different Comparisons
4. Results
4.1. Identification Accuracy of Maize Based on Different Metrics
4.2. Identification Accuracy of Maize Based on Different Feature Datasets
4.3. Identification Accuracy of Maize Based on Different Classifiers
5. Discussion
5.1. Advantages of Phenological Features from Multiple Metrics in Identifying Maize
5.2. The Importance of Feature Extraction and Selection in Identifying Maize
5.3. Determination of the Matched Classifier Based on the Supervised Phenological Features in Identifying Maize
5.4. The Optimal Identification Method of Maize Based on Remote Sensing Time-Series Data and Further Improvements
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Food and Agriculture Organization (FAO). Fao Statistical Pocketbook 2015; FAO: Rome, Italy, 2015; p. 28. [Google Scholar]
- Thenkabail, P.S.; Hanjra, M.A.; Dheeravath, V.; Gumma, M. A holistic view of global croplands and their water use for ensuring global food security in the 21st century through advanced remote sensing and non-remote sensing approaches. Remote Sens. 2010, 2, 211–261. [Google Scholar] [CrossRef] [Green Version]
- He, Q.; Zhou, G. The climatic suitability for maize cultivation in China. Chin. Sci. Bull. 2012, 57, 395–403. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; McCallum, I.; You, L.; Bun, A.; Moltchanova, E.; Duerauer, M.; Albrecht, F.; Schill, C.; Perger, C. Mapping global cropland and field size. Glob. Chang. Biol. 2015, 21, 1980–1992. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thenkabail, P.S.; Biradar, C.M.; Noojipady, P.; Dheeravath, V.; Li, Y.; Velpuri, M.; Gumma, M.; Gangalakunta, O.R.P.; Turral, H.; Cai, X.; et al. Global Irrigated Area Map (GIAM), derived from remote sensing, for the end of the last millennium. Int. J. Remote Sens. 2009, 30, 3679–3733. [Google Scholar] [CrossRef]
- Atzberger, C. Advances in remote sensing of agriculture: Context description, existing operational monitoring systems and major information needs. Remote Sens. 2013, 5, 949–981. [Google Scholar] [CrossRef]
- Frolking, S.; Qiu, J.; Boles, S.; Xiao, X.; Liu, J.; Zhuang, Y.; Li, C.; Qin, X. Combining remote sensing and ground census data to develop new maps of the distribution of rice agriculture in China. Glob. Biogeochem. Cycles 2002, 16, 38-1–38-10. [Google Scholar] [CrossRef]
- Chang, J.; Hansen, M.C.; Pittman, K.; Carroll, M.; DiMiceli, C. Corn and soybean mapping in the United States using MODIS time-series data sets. Agron. J. 2007, 99, 1654–1664. [Google Scholar] [CrossRef]
- Pan, Y.; Li, L.; Zhang, J.; Liang, S.; Zhu, X.; Sulla-Menashe, D. Winter wheat area estimation from MODIS-EVI time series data using the crop proportion phenology index. Remote Sens. Environ. 2012, 119, 232–242. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Wardlow, B.; Egbert, S.; Kastens, J. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the U.S. Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. Large-area crop mapping using time-series MODIS 250 m NDVI data: An assessment for the U.S. Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, R.; Zhang, B.; Tong, Q. Land cover classification of the North China Plain using MODIS_EVI time series. ISPRS J. Photogramm. Remote Sens. 2008, 63, 476–484. [Google Scholar] [CrossRef]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Mingwei, Z.; Qingbo, Z.; Zhongxin, C.; Jia, L.; Yong, Z.; Chongfa, C. Crop discrimination in Northern China with double cropping systems using fourier analysis of time-series MODIS data. Int. J. Appl. Earth Obs. Geoinf. 2008, 10, 476–485. [Google Scholar] [CrossRef]
- Lunetta, R.S.; Shao, Y.; Ediriwickrema, J.; Lyon, J.G. Monitoring agricultural cropping patterns across the Laurentian Great Lakes Basin using MODIS-NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 81–88. [Google Scholar] [CrossRef]
- De la Casa, A.C.; Ovando, G.G.; Ravelo, A.C.; Abril, E.G.; Bergamaschi, H. Estimating maize ground cover using spectral data from AQUA-MODIS in Córdoba, Argentina. Int. J. Remote Sens. 2014, 35, 1295–1308. [Google Scholar] [CrossRef]
- Xiao, X.; Boles, S.; Liu, J.; Zhuang, D.; Frolking, S.; Li, C.; Salas, W.; Moore, B. Mapping paddy rice agriculture in Southern China using multi-temporal MODIS images. Remote Sens. Environ. 2005, 95, 480–492. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Yu, L.; Gong, P.; Biging, G.S. Automated mapping of soybean and corn using phenology. ISPRS J. Photogramm. Remote Sens. 2016, 119, 151–164. [Google Scholar] [CrossRef]
- Lobell, D.B.; Asner, G.P. Cropland distributions from temporal unmixing of MODIS data. Remote Sens. Environ. 2004, 93, 412–422. [Google Scholar] [CrossRef]
- Jiang, L.; Shang, S.; Yang, Y.; Guan, H. Mapping interannual variability of maize cover in a large irrigation district using a vegetation index—Phenological index classifier. Comput. Electron. Agric. 2016, 123, 351–361. [Google Scholar] [CrossRef]
- Chen, Y.; Song, X.; Wang, S.; Huang, J.; Mansaray, L.R. Impacts of spatial heterogeneity on crop area mapping in Canada using MODIS data. ISPRS J. Photogramm. Remote Sens. 2016, 119, 451–461. [Google Scholar] [CrossRef]
- Velpuri, N.M.; Thenkabail, P.S.; Gumma, M.K.; Biradar, C.; Dheeravath, V.; Noojipady, P.; Yuanjie, L. Influence of resolution in irrigated area mapping and area estimation. Photogramm. Eng. Remote Sens. 2009, 75, 1383–1395. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LIDAR data. Remote Sens. Environ. 2012, 123, 258–270. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, F.; Sun, P.; Pan, Y.; Yuan, Z.; Yun, Y. A stratified temporal spectral mixture analysis model for mapping cropland distribution through MODIS time-series data. J. Agric. Sci. 2015, 7. [Google Scholar] [CrossRef]
- Xie, D.; Zhang, J.; Zhu, X.; Pan, Y.; Liu, H.; Yuan, Z.; Yun, Y. An improved STARFM with help of an unmixing-based method to generate high spatial and temporal resolution remote sensing data in complex heterogeneous regions. Sensors 2016, 16, 207. [Google Scholar] [CrossRef] [PubMed]
- Carrão, H.; Gonçalves, P.; Caetano, M. Contribution of multispectral and multitemporal information from MODIS images to land cover classification. Remote Sens. Environ. 2008, 112, 986–997. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemometr. Intell. Lab. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Cheriyadat, A.; Bruce, L.M. Why principal component analysis is not an appropriate feature extraction method for hyperspectral data. In Proceedings of the 2003 IEEE International Geoscience and Remote Sensing Symposium, Toulouse, France, 21–25 July 2003; Volume 3426, pp. 3420–3422. [Google Scholar]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recogn. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef]
- Yang, J.; Honavar, V. Feature subset selection using a Genetic Algorithm. IEEE Intell. Syst. App. 1998, 13, 44–49. [Google Scholar] [CrossRef]
- Wang, X.; Yang, J.; Teng, X.; Xia, W.; Jensen, R. Feature selection based on rough sets and Particle Swarm Optimization. Pattern Recognit. Lett. 2007, 28, 459–471. [Google Scholar] [CrossRef] [Green Version]
- National Bureau of Statistics of China. China Statistical Yearbook, 1st ed.; China Statistics Press: Beijing, China, 2016.
- Bruzzone, L.; Roli, F.; Serpico, S.B. An extension of the Jeffreys-Matusita distance to multiclass cases for feature selection. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1318–1321. [Google Scholar] [CrossRef]
- Story, M. Accuracy assessment: A user’s perspective. Photogramm. Eng. Remote Sens. 1986, 52, 397–399. [Google Scholar]
- Jia, K.; Liang, S.; Wei, X.; Yao, Y.; Su, Y.; Jiang, B.; Wang, X. Land cover classification of Landsat data with phenological features extracted from time series MODIS NDVI data. Remote Sens. 2014, 6, 11518–11532. [Google Scholar] [CrossRef]
- Gong, P.; Marceau, D.J.; Howarth, P.J. A comparison of spatial feature extraction algorithms for land-use classification with SPOT HRV data. Remote Sens. Environ. 1992, 40, 137–151. [Google Scholar] [CrossRef]
- Comber, A.J.; Harris, P.; Tsutsumida, N. Improving land cover classification using input variables derived from a geographically weighted principal components analysis. ISPRS J. Photogramm. Remote Sens. 2016, 119, 347–360. [Google Scholar] [CrossRef]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature selection of time series MODIS data for early crop classification using Random Forest: A case study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef]
- Belward, A.S.; de Hoyos, A. A comparison of supervised maximum likelihood and decision tree classification for crop cover estimation from multitemporal LANDSAT MSS data. Int. J. Remote Sens. 1987, 8, 229–235. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Massey, R.; Sankey, T.T.; Congalton, R.G.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M.; Sánchez Meador, A.J. MODIS phenology-derived, multi-year distribution of conterminous U.S. crop types. Remote Sens. Environ. 2017, 198, 490–503. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Tso, B.; Mather, P.M. Crop discrimination using multi-temporal SAR imagery. Int. J. Remote Sens. 1999, 20, 2443–2460. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. A comparison of MODIS 250-m EVI and NDVI data for crop mapping: A case study for Southwest Kansas. Int. J. Remote Sens. 2010, 31, 805–830. [Google Scholar] [CrossRef]
- Sonobe, R.; Tani, H.; Wang, X.; Kobayashi, N.; Shimamura, H. Random Forest classification of crop type using multi-temporal TerraSAR-X dual-polarimetric data. Remote Sens. Lett. 2014, 5, 157–164. [Google Scholar] [CrossRef]
- Ornella, L.; Tapia, E. Supervised machine learning and heterotic classification of maize (Zea mays l.) using molecular marker data. Comput. Electron. Agric. 2010, 74, 250–257. [Google Scholar] [CrossRef]
- Sonobe, R.; Tani, H.; Wang, X. An experimental comparison between KELM and CART for crop classification using Landsat-8 OLI data. Geocarto Int. 2017, 32, 128–138. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
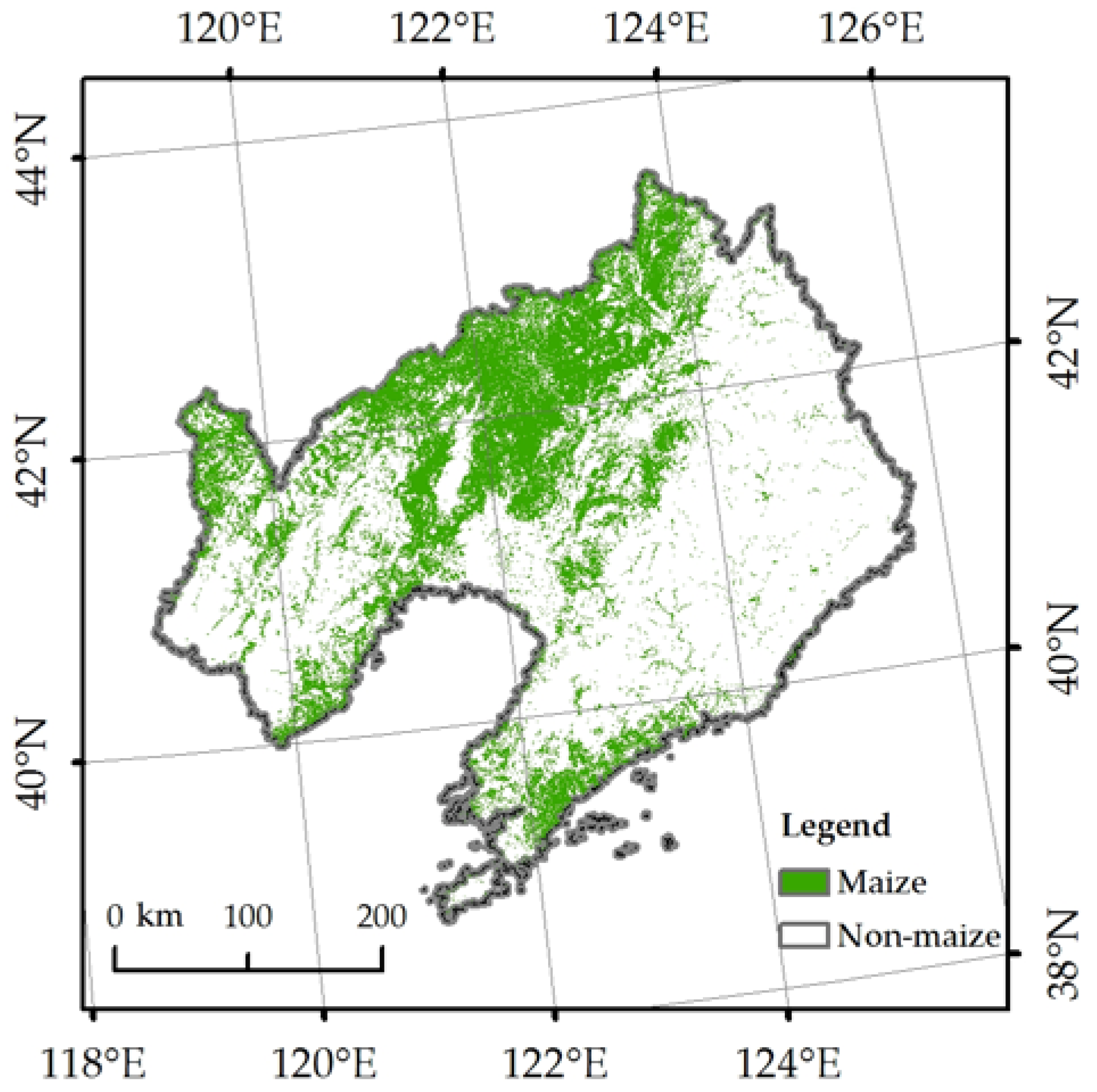{kind=link}
| Type of Sample | Maize | Rice | Woodland 1 | Grassland 2 | Buildings | Water | Total |
|---|---|---|---|---|---|---|---|
| Training samples | 150 | 150 | 150 | 150 | 150 | 150 | 900 |
| Validation samples | 70 | 20 | 76 | 45 | 14 | 10 | 230 |
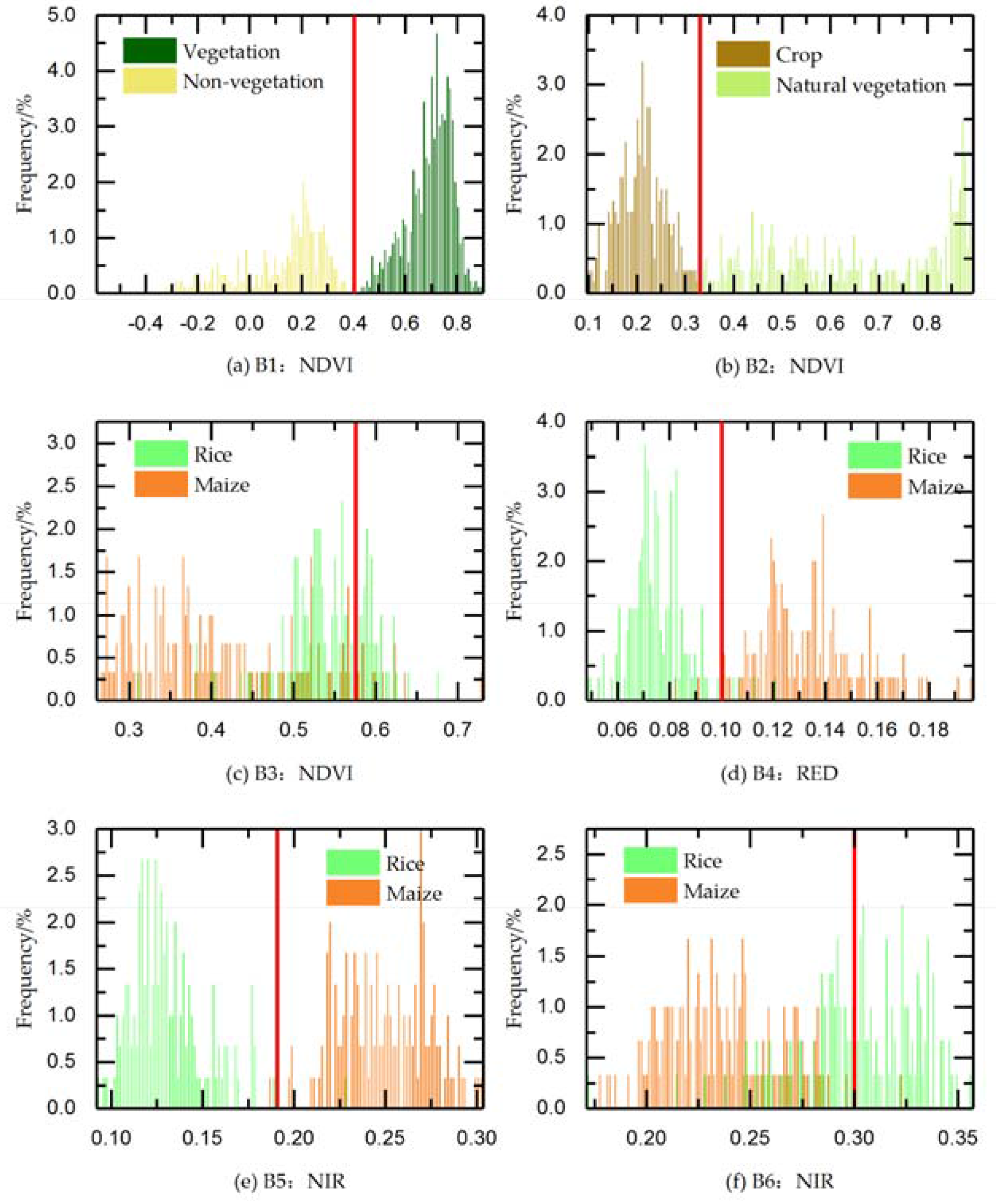
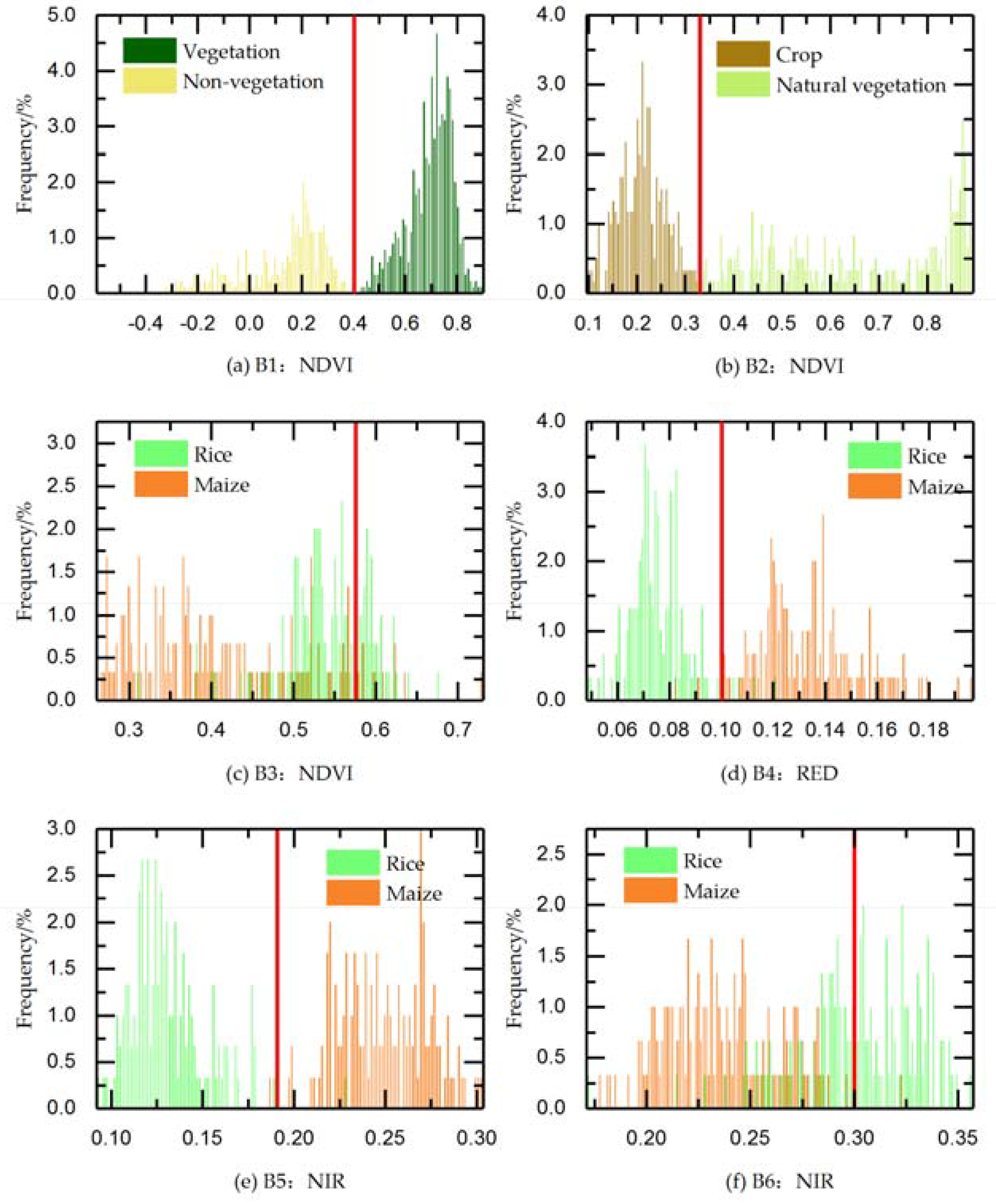
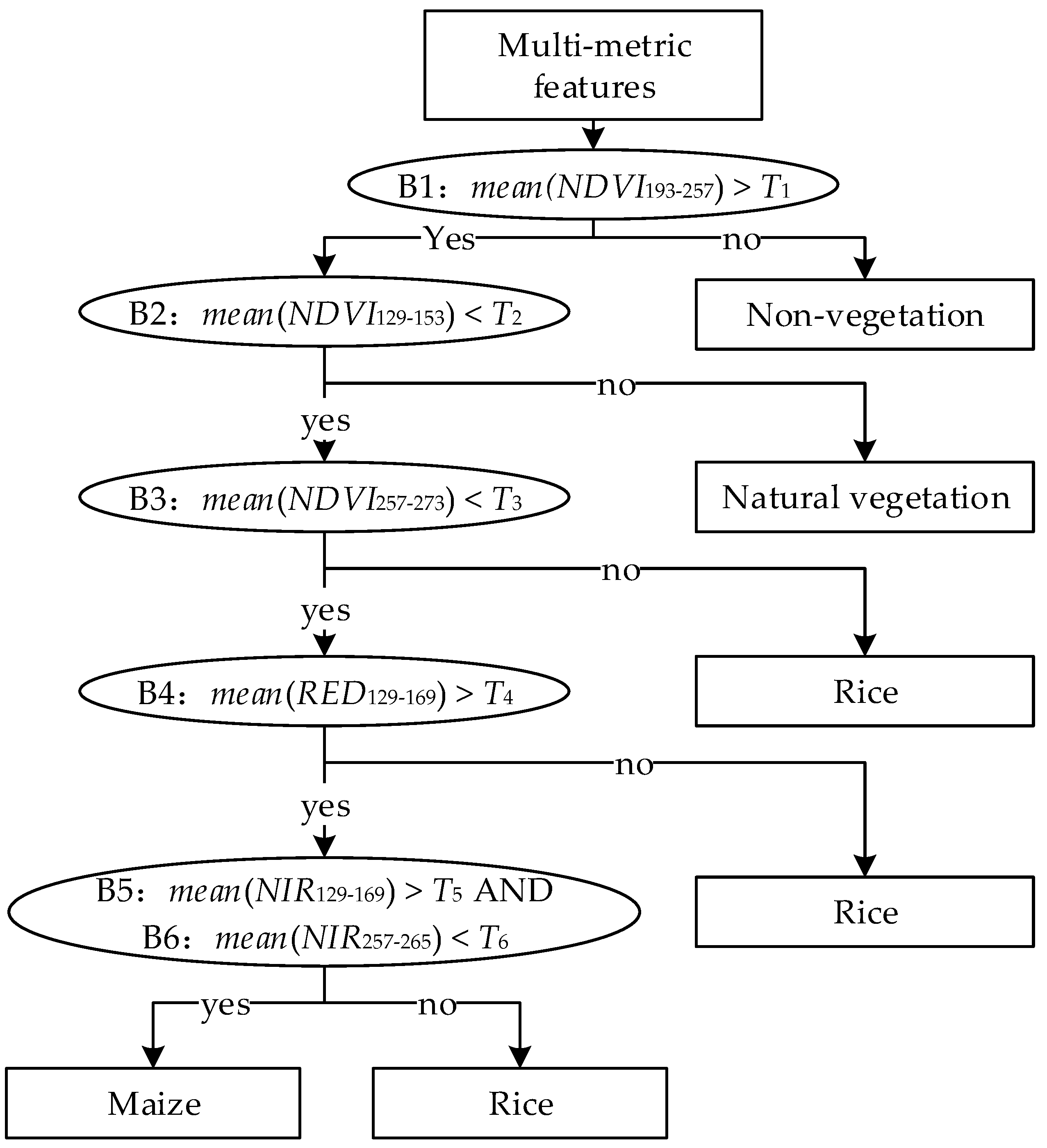
| Metric | Period * | DOY | Phenophase | Criterion | Threshold |
|---|---|---|---|---|---|
| NDVI | B1 | 193–257 | Tasseling to milk stage | Vegetation types with a higher value are distinguished from non-vegetation type with a lower value | T1: 0.40 |
| NDVI | B2 | 129–153 | Early stage of tillering and shooting | Crops with a lower value are distiguished from natural vegetation with a higher value | T2: 0.33 |
| NDVI | B3 | 257–273 | Early stage of maturation | Maize with a lower value is distinguished from rice with a higher value | T3: 0.57 |
| Red reflectance | B4 | 129–169 | Early stage of tillering and shooting | Maize with a higher value is distinguished from rice with a lower value | T4: 0.10 |
| Near-infrared reflectance | B5 | 129–169 | Early stage of tillering and shooting | Maize with a higher value is distinguished from rice with a lower value | T5: 0.18 |
| Near-infrared reflectance | B6 | 257–265 | Early stage of maturation | Maize with a lower value is distinguished from rice with a higher value | T6: 0.30 |
| Item | Features * | Type | Producer’s Accuracy/% | Omission/% | User’s Accuracy/% | Commission/% | Overall Accuracy/% | Kappa Coefficient |
|---|---|---|---|---|---|---|---|---|
| (1) | B1–B3 | Maize | 100.00 | 0.00 | 70.00 | 30.00 | 81.74 | 0.7011 |
| Rice | 25.00 | 75.00 | 83.33 | 16.67 | ||||
| Natural vegetation | 91.38 | 8.62 | 92.98 | 7.02 | ||||
| Non-vegetation | 29.17 | 70.83 | 70.00 | 30.00 | ||||
| (2) | B1–B4 | Maize | 98.57 | 1.43 | 76.67 | 23.33 | 83.91 | 0.7407 |
| Rice | 55.00 | 45.00 | 68.75 | 31.25 | ||||
| Natural vegetation | 91.38 | 8.62 | 92.98 | 7.02 | ||||
| Non-vegetation | 29.17 | 70.83 | 70.00 | 30.00 | ||||
| (3) | B1–B6 | Maize | 98.57 | 1.43 | 81.18 | 18.82 | 83.91 | 0.7426 |
| Rice | 55.00 | 45.00 | 52.38 | 47.62 | ||||
| Natural vegetation | 91.38 | 8.62 | 92.98 | 7.02 | ||||
| Non-vegetation | 29.17 | 70.83 | 70.00 | 30.00 |
| Item | Feature Datasets | Type | Producer’s Accuracy/% | Omission/% | User’s Accuracy/% | Commission/% | Overall Accuracy/% | Kappa Coefficient |
|---|---|---|---|---|---|---|---|---|
| (1) | Phenological features | Maize | 91.43 | 8.57 | 77.11 | 22.89 | 81.30 | 0.6883 |
| Rice | 40.00 | 60.00 | 100.00 | 0.00 | ||||
| Natural vegetation | 93.10 | 6.90 | 83.72 | 16.28 | ||||
| Non-vegetation | 29.17 | 70.83 | 70.00 | 30.00 | ||||
| (2) | Statistical features | Maize | 77.14 | 22.86 | 65.85 | 34.15 | 69.13 | 0.5069 |
| Rice | 35.00 | 65.00 | 31.82 | 68.18 | ||||
| Natural vegetation | 77.59 | 22.41 | 78.26 | 21.74 | ||||
| Non-vegetation | 33.33 | 66.67 | 72.73 | 27.27 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, K.; Zhu, W.; Zhan, P.; Ding, S. An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features. Remote Sens. 2018, 10, 193. https://doi.org/10.3390/rs10020193
Tang K, Zhu W, Zhan P, Ding S. An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features. Remote Sensing. 2018; 10(2):193. https://doi.org/10.3390/rs10020193
Chicago/Turabian StyleTang, Ke, Wenquan Zhu, Pei Zhan, and Siyang Ding. 2018. "An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features" Remote Sensing 10, no. 2: 193. https://doi.org/10.3390/rs10020193
APA StyleTang, K., Zhu, W., Zhan, P., & Ding, S. (2018). An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features. Remote Sensing, 10(2), 193. https://doi.org/10.3390/rs10020193