An Efficient Hyperspectral Image Retrieval Method: Deep Spectral-Spatial Feature Extraction with DCGAN and Dimensionality Reduction Using t-SNE-Based NM Hashing

Abstract
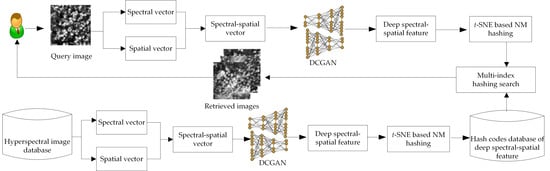
:
1. Introduction
- (1)
- Differently to previous work in this field, deep spectral-spatial features are extracted to represent the hyperspectral image by using the DCGAN model. Considering the limitations of the human visual system, it is hard to obtain a large volume of labeled data. DCGAN can learn the high-level features jointly in supervised and unsupervised ways when the labeled data is scarce, which is suitable for the characteristics of hyperspectral image data. Therefore, we firstly attempt to extract the deep spectral-spatial features with the DCGAN model for hyperspectral image retrieval.
- (2)
- t-Distributed Stochastic Neighbor Embedding Nonlinear Manifold (t-SNE-based NM) hashing is introduced to make dimensionality reduction of deep spectral-spatial features by projecting the original deep spectral-spatial features into short hash codes. In this way, the dimensionality of deep spectral-spatial features not only can be reduced from tens of thousands to tens of dimensions, but also preserves the semantic information of the deep spectral-spatial feature more effectively.
- (3)
- Multi-index hashing is utilized for similarity measurement in Hamming space for hyperspectral image retrieval. Considering the traditional hashing method will consume a large amount of storage space resulting in too much time being lost in searching for a similar one’s process, the multi-index hashing search method is explored to further reduce the space complexity with highly efficient retrieval, especially for large-scale hyperspectral image retrieval.
2. Our Proposed Method
2.1. Deep Spectral-Spatial Feature Extraction with DCGAN
- (1)
- Obtain the spectral-spatial vectors. Spectral vectors and spatial vectors are extracted respectively, and then spectral-spatial vectors can be obtained by combining spectral and spatial vectors using a Vector Stacking (VS) approach;
- (2)
- Train the DCGAN model. The DCGAN model is trained by spectral-spatial vectors as training samples and then optimized by using the Adaptive Moment Estimation (Adam) algorithm [31];
- (3)
- Extract the deep spectral-spatial features with the DCGAN model. The samples of the pixels are taken from hyperspectral images with a sliding window. The spatial vector and spectral vector of sampled pixels are extracted with Step 1). Finally, deep spectral-spatial features are extracted with the trained DCGAN model.
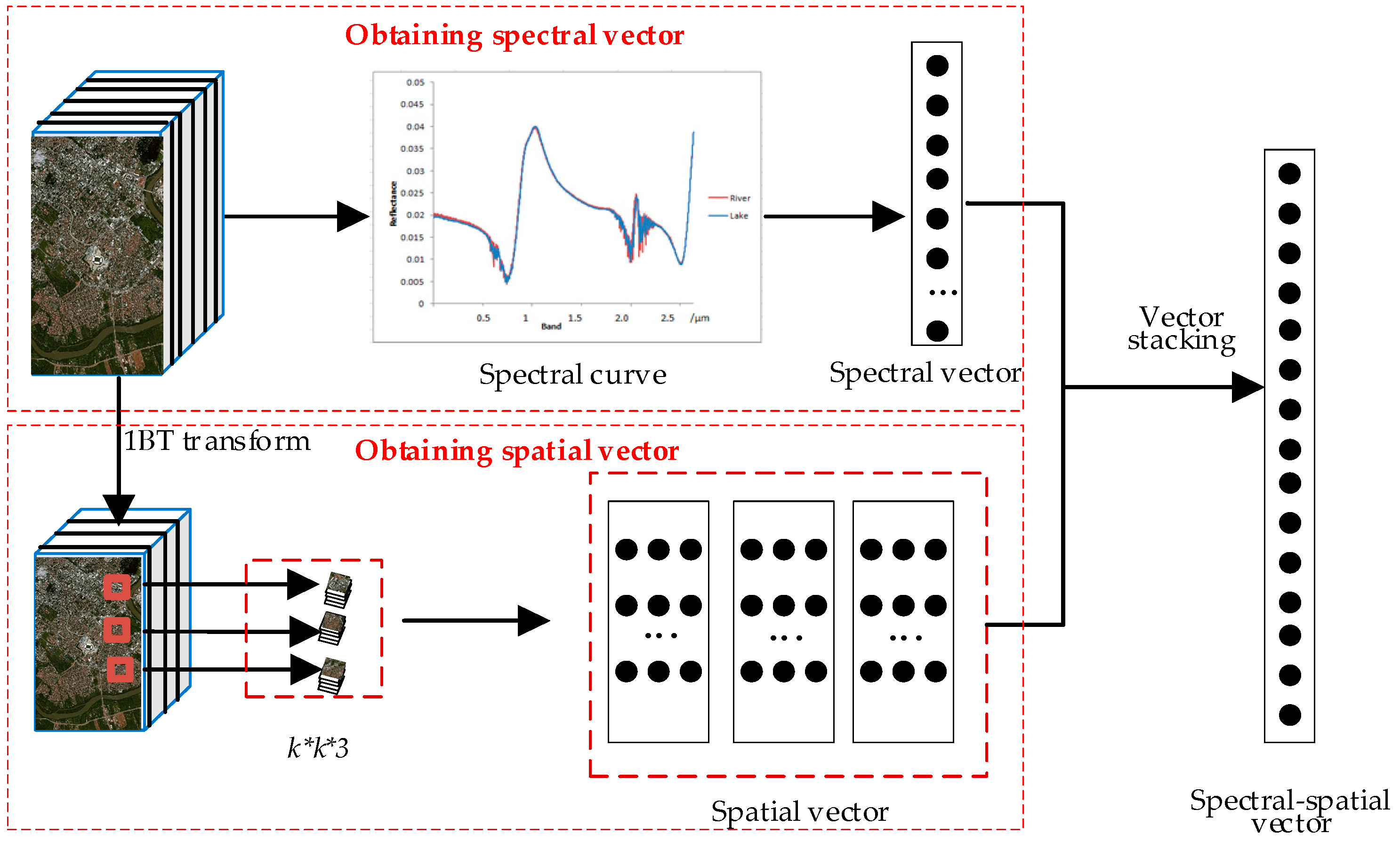
2.1.1. Obtaining Spectral-Spatial Vector
- (1)
- A multi band-pass filter kernel is used to filter the image frames for obtaining the one-bit band images (1BTs).
- (2)
- The spatial bit transitions A(l) in 1BTs (changes from 1 to 0, and vice-versa) are counted in horizontal and vertical directions.
- (3)
2.1.2. Training DCGAN Model
- (1)
- Normalize all training samples to the range of [−1, 1] using the tanh activation function. In the generator, the output layer uses the tanh activation function. It means that the generated sample is normalized to the range of [−1, 1] by the tanh activation function through the output layer. After that, the generated samples and training samples need to be put into the discriminator respectively. Finally, the discriminator outputs the probability value that the input sample is real training data. To be consistent with the generated samples, all the training samples need to be scaled to the range of [−1, 1] with the tanh activation function before being put into the discriminator:
- (2)
- Train all models using mini-batch Stochastic Gradient Descent (SGD) with a mini-batch size of 64. All weights of parameters in the DCGAN model are initialized from a zero-centered normal distribution with standard deviation 0.02.
- (3)
- Generate the image g(Z) is by using a generator. First, the uniform distribution of the 100-dimensional noise vector Z is input into the generator, and then the Z is reshaped for the 4 × 4 × 1024 dimensional image through the full connection layer to finally generate the image after four times deconvolution.
- (4)
- Put the generated image g(Z) and the training image h into the discriminator network respectively. In the discriminator, a four-convolution layer and a fully connected layer are used to output a probability value that the input sample is real training data.
- (5)
- Calculate the loss V(G,D) of generated image g(Z) and the training image h in the discriminator, and update the variables in the generator and discriminator. The loss V(G,D) can be calculated as follows:
2.1.3. Deep Spectral-Spatial Feature Extraction
2.2. Dimensionality Reduction of Deep Spectral-Spatial Features by Using the t-SNE-Based Nonlinear Manifolds Hashing Method
- (1)
- The FCM clustering method is utilized to partition Y{y1, y2, …, yn} observations into m clusters C (c1, c2, …, cm), in which each observation belongs to the cluster with the nearest mean [37].
- (2)
- The t-SNE method is applied into C (c1, c2, …, cm) to obtain its low-dimensional embedding EC{E1, E2,…,Em}.
- ∙
- Kullback-Leibler divergences is utilized to measure the faithfulness with the symmetrized conditional probability pij in the high-dimensional space and the joint probability qij defined using t-distribution in the low-dimensional embedding space.
- ∙
- Then Ec can be obtained by minimizing Kullback-Leibler divergence over cluster center C using a gradient descent method. Kullback-Leibler divergence is a quantitative measurement of the information loss when choosing an approximation; means relative entropy, representing the lost information.
- ∙
- The low-dimensional embedding EC can be obtained by minimizing the value of Kullback-Leibler divergence.
- (3)
- The low-dimensional embedding for the entire dataset Y{y1, y2, …, yn} can be computed by (4), which is an inductive formulation derived from the inductive learning framework, as in [20]. The low-dimensional embedding EY can be computed with all cluster centers instead of the entire dataset Y because cluster centers have the overall weight with respect to the neighboring points.where w(yi, ci) is the element of graph affinity matrix that denotes the similarity correlation between data point yi and cluster center cj, which can be predicted as:where N(yi) is the neighbor of yi, and σ is the bandwidth parameter.
- (4)
- After obtaining the embeddings of samples yi, the hash codes h(yi) for the entire dataset Y{y1, y2, …, yn} can be easily binaried by using (6).
2.3. Similarity Measurement with Multi-Index Hashing in Hamming Space
- (1)
- Hash table building.
- ∙
- Divide the length of hash code b into m disjointed substrings. The length of each substring is b/m, i.e., it is indexed m times into m different hash tables.
- ∙
- Insert the hash code into jth (j = 1, 2, …, m) hash table. There are 2b/m hash buckets in each hash table, and the total number of hash buckets H for the entire hash code is m × 2b/m, which is much less than 2b.
- (2)
- r-neighbor search.For query substring qj (j = 1, 2, …, a + 1, a + 2, …, m):
- ∙
- When j = 1 to a + 1, look up the neighbors of qj(j = 1, …, a + 1) with radius less than r’ in jth substring of H, in which the substring radius r’ and parameter a can be calculated as [28]:r’ = ⌊r/m⌋, a = r − mr’
- ∙
- When j = a + 1 to m, look up the neighbors of qj(j = a + 2, …, m) with radius less than r’ − 1 in jth substring of H.
- ∙
- Merge the m substrings and remove the non r-neighbors to obtain the r-radius neighbors of qj.
3. Experimental Results and Analysis
3.1. Experimental Dataset and Setting
3.2. Experiment I: Top-10 Retrieved Hyperspectral Images Based on Deep Spectral-Spatial Feature
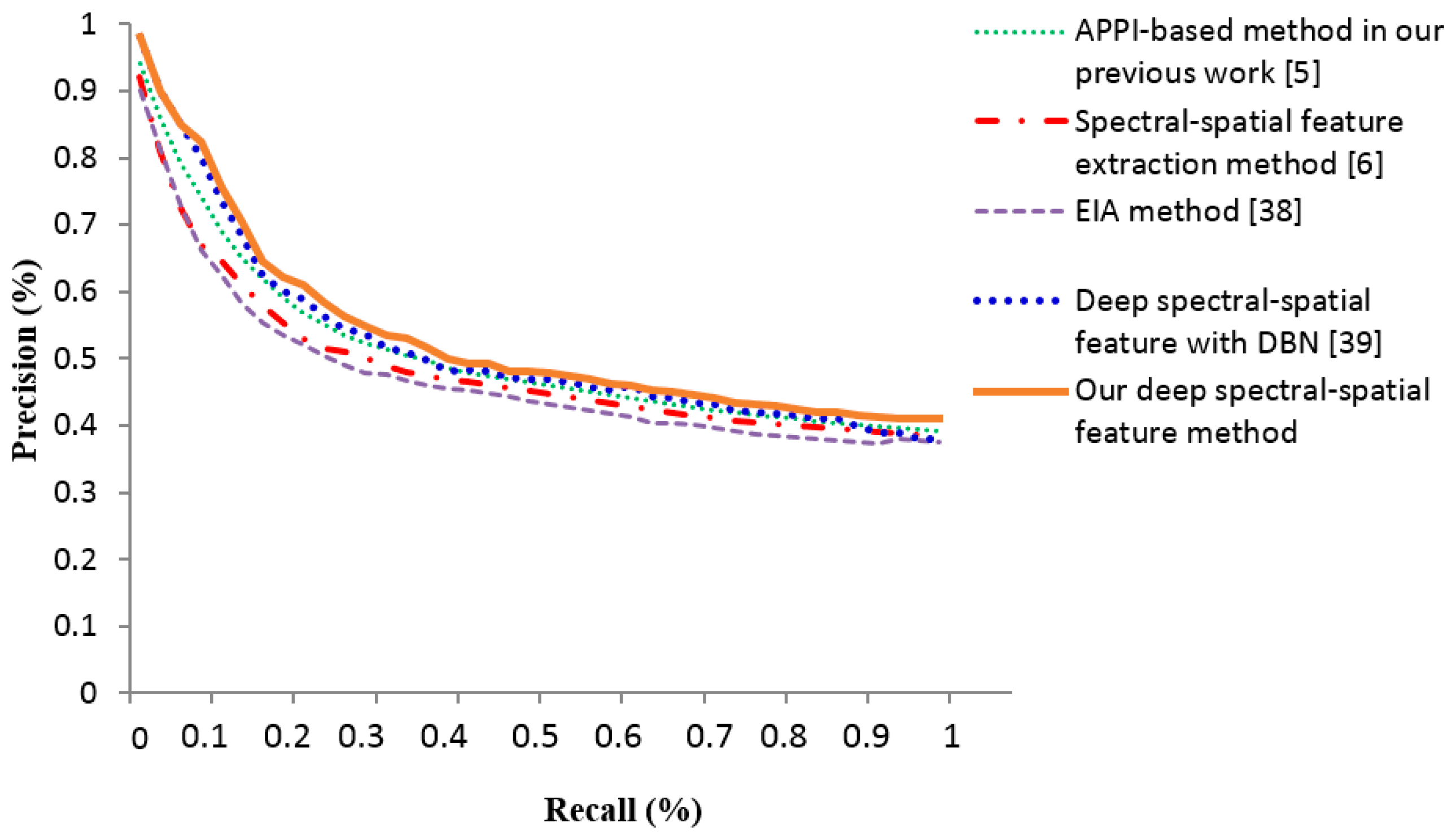
3.3. Experiment II: The Precision-Recall Curves and Average Precision Ratios Analysis of Deep Spectral-Spatial Features
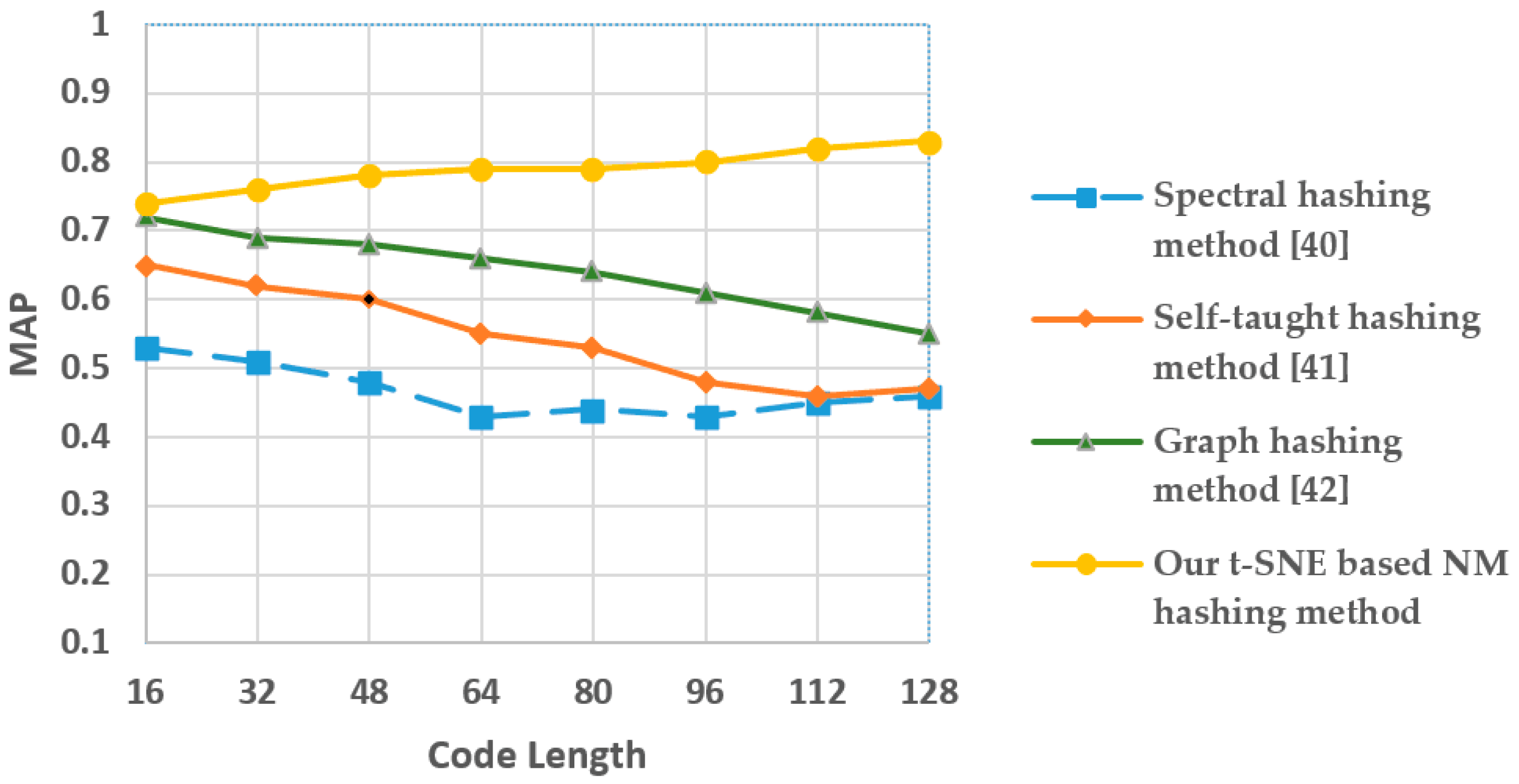
3.4. Experiment III: MAP Scores Analysis after Dimensionality Reduction of Hashing
3.5. Experiment IV: Time Complexity and Average Precision Ratio Analysis before and after Dimensionality Reduction
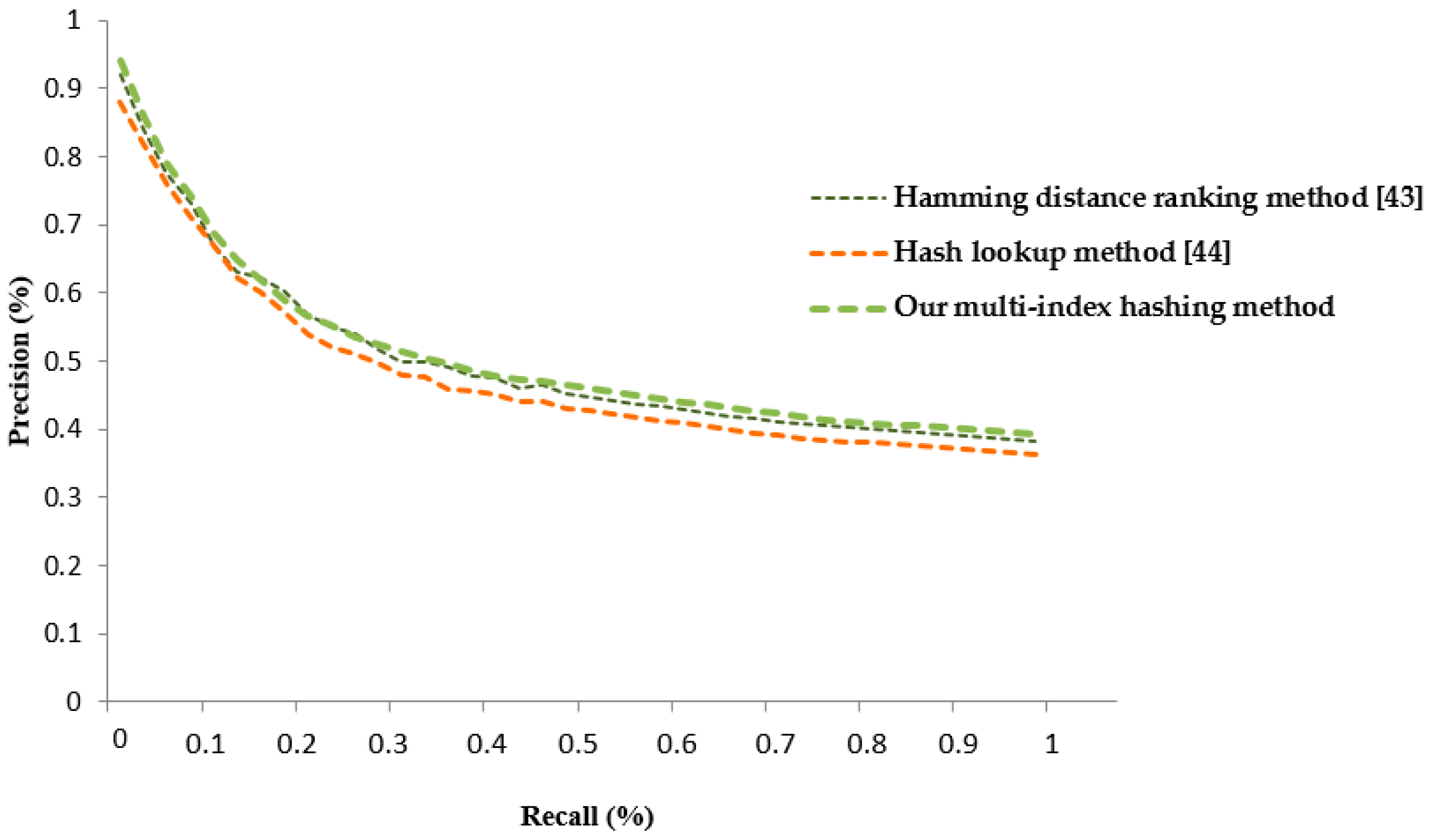
3.6. Experiment V: Precision-Recall Curves, Time Cost and Storage Complexity Analysis of Multi-Index Hashing
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhong, Z.; Fan, B.; Duan, J. Discriminant tensor spectral–spatial feature extraction for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2017, 12, 1028–1032. [Google Scholar] [CrossRef]
- Zhang, E.; Zhang, X.; Yang, S. Improving hyperspectral image classification using spectral information divergence. IEEE Geosci. Remote Sens. Lett. 2014, 51, 249–253. [Google Scholar] [CrossRef]
- Zhou, W.; Li, C. Deep feature representations for high-resolution remote-sensing imagery retrieval. Remote Sens. 2017, 9, 489. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, W.; Cheng, Q. An effective hyperspectral image retrieval method using integrated spectral and textural features. Sens. Rev. 2015, 35, 274–281. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Q.L.; Zhuo, L.; Geng, W.H.; Wang, S. A CBIR system for hyperspectral remote sensing images using endmember extraction. Pattern Recognit. 2017, 31, 1752001. [Google Scholar] [CrossRef]
- Graña, M. A spectral/spatial CBIR system for hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 488–500. [Google Scholar]
- Ye, Z.; Tan, L.; Bai, L. Hyperspectral image classification based on spectral-spatial feature extraction. In Proceedings of the International Workshop on Remote Sensing with Intelligent Processing, Shanghai, China, 19–21 May 2017; pp. 489–499. [Google Scholar]
- Deng, S.B. Image enhancement. In ENVI Remote Sensing Image Processing Method, 1rd ed.; Peng, S.C., Zhang, J.F., Eds.; Science Press: Beijing, China, 2010; ISBN 978703027600. [Google Scholar]
- Li, C.; Ma, Y.; Mei, X.; Liu, C.; Ma, J. Hyperspectral image classification with robust sparse representation. IEEE Geosci. Remote Sens. Lett. 2017, 13, 641–645. [Google Scholar]
- Zhu, Y.; Huang, X.; Huang, Q.; Tian, Q. Large-scale video copy retrieval with temporal-concentration sift. Neurocomputing 2016, 187, 83–91. [Google Scholar] [CrossRef]
- Zhu, Y.; Jiang, J.; Han, W.; Ding, Y.; Tian, Q. Interpretation of users’ feedback via swarmed particles for content-based image retrieval. Inf. Sci. 2017, 375, 246–257. [Google Scholar] [CrossRef]
- Li, Y.; Xie, W.; Li, H. Hyperspectral image reconstruction by deep convolutional neural network for classification. Pattern Recognit. 2017, 63, 371–383. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Salman, M.; Yüksel, S.E. Hyperspectral data classification using deep convolutional neural networks. In Proceedings of the Signal Processing and Communication Application Conference, Budapest, Hungary, 29 August–2 September 2016; pp. 2129–2132. [Google Scholar]
- Zhang, Z.; Liu, X.; Cui, Y. Multi-phase offline signature verification system using deep convolutional generative adversarial Networks. In Proceedings of the International Symposium on Computational Intelligence and Design, Hangzhou, China, 10–11 December 2016; pp. 103–107. [Google Scholar]
- Han, M.; Zhang, C. Spectral-spatial classification of hyperspectral image based on discriminant sparsity preserving embedding. Neurocomputing 2017, 243, 133–141. [Google Scholar] [CrossRef]
- Malik, M.R.; Isaac, B.J.; Coussement, A. Principal component analysis coupled with nonlinear regression for chemistry reduction. Combust. Flame 2017, 187, 30–41. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Feng, J.; Fang, Q. Query-aware locality-sensitive hashing scheme for norm. VLDB J. 2017, 26, 683–708. [Google Scholar] [CrossRef]
- Shen, F.; Shen, C.; Liu, W. Supervised discrete hashing. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 37–45. [Google Scholar]
- Talwalkar, A.; Kumar, S.; Rowley, H.A. Large-scale manifold learning. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Shen, F.; Shen, C.; Shi, Q. Hashing on nonlinear manifolds. IEEE Trans. Image Process. 2015, 24, 1839–1851. [Google Scholar] [CrossRef] [PubMed]
- Gu, H.; Wang, X.; Chen, X. Manifold learning by curved cosine mapping. IEEE Trans. Knowl. Data Eng. 2017, 29, 2236–2248. [Google Scholar] [CrossRef]
- Maaten, L.V.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Cakir, F.; Sclaroff, S. Adaptive hashing for fast similarity search. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 8–10 June 2015; pp. 1044–1052. [Google Scholar]
- Norouzi, M.; Punjani, A.; Fleet, D.J. Fast search in Hamming space with multi-index hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3108–3115. [Google Scholar]
- Norouzi, M.; Punjani, A.; Fleet, D.J. Fast exact search in Hamming space with multi-index hashing. IEEE Trans. Pattern Anal. 2014, 36, 1107–1119. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Woodcock, C.E.; Rogan, J.; Kellndorfer, J. Assessment of spectral, polarimetric, temporal, and spatial dimensions for urban and peri-urban land cover classification using Landsat and SAR data. Remote Sens. Environ. 2012, 117, 72–82. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Demir, B.; Celebi, A. A low-complexity approach for the color display of hyperspectral remote-sensing images using One-Bit-Transform-Based band selection. IEEE Trans. Geosci. Remote Sens. 2009, 47, 97–105. [Google Scholar] [CrossRef]
- Natarajan, B.; Bhaskaran, V.; Konstantinides, K. Low-complexity block-based motion estimation via one-bit transforms. IEEE Trans. Circuits Syst. Video Technol. 1997, 7, 702–706. [Google Scholar] [CrossRef]
- Urhan, O.; Erturk, S. Constrained one-bit transform for low complexity block motion estimation. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 478–482. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the IEEE Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Chen, L.; Zhang, J.; Liang, X.; Li, J.F.; Zhuo, L. Deep spectral-spatial feature extraction based on DCGAN for hyperspectral image retrieval. In Proceedings of the IEEE Conference on Pervasive Intelligence and Computing, Orlando, FL, USA, 6–10 November 2017; pp. 1–8. [Google Scholar]
- Yang, M.S.; Nataliani, Y. Robust-learning fuzzy c-means clustering algorithm with unknown number of clusters. Pattern Recognit. 2017, 71, 45–59. [Google Scholar] [CrossRef]
- Graña, M. An endmember-based distance for content based hyperspectral image retrieval. Pattern Recognit. 2012, 45, 3472–3489. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; The, Y.W. A fast learning algorithm for deep belief net. Neural Comput. 2014, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Weiss, Y.; Torralba, A.; Fergus, R. Spectral hashing. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 1753–1760. [Google Scholar]
- Zhang, D.; Wang, J.; Cai, D.; Lu, J. Self-taught hashing for fast similarity search. In Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 18–25. [Google Scholar]
- Liu, W.; Wang, J.; Kumar, S.; Chang, S.F. Hashing with graphs. In Proceedings of the International Conference on Machine Learning, Washington, DC, USA, 28 June–2 July 2011; pp. 1–8. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Hamming embedding and weak geometric consistency for large scale image search. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 304–317. [Google Scholar]
- Liu, X.L.; Fan, X.J.; Deng, C.; Li, Z.J.; Su, H.; Tao, D.C. Multilinear hyperplane hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Paris, France, 26–27 September 2016; pp. 5119–5127. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction Methods | APPI in our Previous Work [5] | Spectral-Spatial Features [6] | EIA [38] | Deep Spectral-Spatial Features with DBN [39] | Our Deep Spectral-Spatial Feature |
|---|---|---|---|---|---|
| Average precision ratios (%) | 78.49 | 73.22 | 73.18 | 81.33 | 86.49 |
| Methods | Spectral Hashing [40] | Self-Taught Hashing [41] | Graph Hashing [42] | Our t-SNE Based NM Hashing |
|---|---|---|---|---|
| MAP (64 bits) | 43.50% | 54.90% | 66.45% | 79.20% |
| Features | Original Feature | Hash Feature (64 bits) |
|---|---|---|
| Time cost (s) | 1860 | 11.3 + 4.5 × 10−5 |
| Average precision ratios (%) | 86.49 | 86.10 |
| Methods | Hamming Rank [43] | Hash Look Up [44] | Our Multi-Index Hashing |
|---|---|---|---|
| Average precision ratios (%) | 79.33% | 77.50% | 80.60% |
| Methods | Hamming Rank [43] | Hash Look Up [44] | Our Multi-Index Hashing |
|---|---|---|---|
| Time cost (s) | 4.5 × 10−5 | 5.0 × 10−7 | 5.8 × 10−8 |
| Space complexity | O(N × q) | O(q × 2q) | O(q × 2q/m) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Chen, L.; Zhuo, L.; Liang, X.; Li, J. An Efficient Hyperspectral Image Retrieval Method: Deep Spectral-Spatial Feature Extraction with DCGAN and Dimensionality Reduction Using t-SNE-Based NM Hashing. Remote Sens. 2018, 10, 271. https://doi.org/10.3390/rs10020271
Zhang J, Chen L, Zhuo L, Liang X, Li J. An Efficient Hyperspectral Image Retrieval Method: Deep Spectral-Spatial Feature Extraction with DCGAN and Dimensionality Reduction Using t-SNE-Based NM Hashing. Remote Sensing. 2018; 10(2):271. https://doi.org/10.3390/rs10020271
Chicago/Turabian StyleZhang, Jing, Lu Chen, Li Zhuo, Xi Liang, and Jiafeng Li. 2018. "An Efficient Hyperspectral Image Retrieval Method: Deep Spectral-Spatial Feature Extraction with DCGAN and Dimensionality Reduction Using t-SNE-Based NM Hashing" Remote Sensing 10, no. 2: 271. https://doi.org/10.3390/rs10020271