1. Introduction
Melt water from snow and glaciers plays a key role in the hydrological cycle by contributing to the river flow and water resources in many parts of the world. It is estimated that about one-sixth of the world’s population depends on snow- and ice-melt for the supply with drinking water [
1]. Therefore, for hydrological assessments in these regions, knowledge about the spatial and temporal distribution of the snow water equivalent (SWE) is of uttermost importance.
SWE is defined as the amount of water contained within the snowpack: It can be thought as the depth of water that would theoretically result if the entire snowpack would melt instantaneously [
2]. Where available, point ground measurements of SWE remain the main direct information about the snow mass. However, given the large spatial heterogeneity of snow they may not be representative of large areas. A spatialized estimation of SWE in mountain areas, which are typically complex terrains with high topographic heterogeneity, is currently one of the most important challenges of snow hydrology [
3]. An improved knowledge of the spatial distribution of SWE and its evolution over time would allow a better management of mountain water resources for drinking water supply, agriculture and hydropower, as well as for flood protection.
In literature, several approaches to the estimation of the spatial distribution of SWE exist. One of the most common methods is the interpolation of SWE ground measurements, constrained by remotely sensed maps of the snow extent. If enough ground measurements with a good spatial distribution are available, this approach may produce accurate SWE results [
4]. Two different types of snow extent products derived from satellite exist: fractional and binary snow cover maps. Fassnacht et al. [
4] and Molotch et al. [
5] use of the fractional product that provides information about the percentage (from 0% to 100%) of snow coverage for each pixel. Elder et al. [
6], instead, utilize binary mapping techniques with a set of thresholds to determine whether a pixel is snow-covered or not. A common statistical technique for spatial interpolation is based on binary regression trees that have been successfully applied to obtain interpolated SWE values from ground observations [
6,
7]. However, numerous studies show that individual point observations of SWE are not necessarily representative of the surrounding area [
8,
9,
10], thus limiting the feasibility of this approach.
Several statistical models have been developed to spatially interpolate the point-based snow information, e.g., multivariate linear regression can relate physiographic variables, historical SWE data and snow-covered area imagery to the observed SWE. The accuracy of this simple method can be better than those of more complex techniques such as inverse-distance weighting [
11].
Due to their accuracy and ability to preserve patterns from observations [
12], nearest-neighbor approaches are an alternative methodical approach for spatio-temporal modeling biophysical parameters. However, in literature, only few studies exist based on the use of k-NN algorithms for modeling snow parameters. Among them, Zheng et al. [
12] developed an approach to estimate SWE through the interpolation of spatially representative point measurements using a k-NN algorithm and historical spatial SWE data. Schneider et al. [
13] estimated the relationships between SWE, snow covered area and topography to extend the Airborne Snow Observatory (ASO) dataset. In their analysis, they also used a nearest neighbor approach for resampling fractional snow-covered area maps.
Another common approach for retrieving spatially distributed SWE is the reconstruction based on both remotely sensed snow cover maps and the estimation of snowmelt. The main idea, developed by Martinec and Rango [
14], is to identify the date of snow disappearance for each pixel starting from Landsat snow cover maps; then, through a backward calculation of the melt rate, the accumulated SWE for each day back to the last significant snowfall is reconstructed. The sources of uncertainty for this approach are mainly related to the melt model structure and its meteorological forcing. Moreover, the main disadvantage of this approach is that it works properly only in areas with distinct accumulation and ablation periods. Furthermore, it operates retroactively only after snow disappearance, and hence does not enable the application for streamflow forecasting. Bair et al. [
15] validated two different SWE reconstruction methods with the NASA ASO data in the upper Tuolumne River Basin in California’s Sierra Nevada. The first approach uses an energy balance model to calculate snowmelt, integrating different remotely sensed products like daily MODIS fractional snow-covered area and albedo; it also considers ephemeral snow (i.e., snow that rapidly appears and disappears). The second reconstruction model implements a net radiation restricted degree-day approach [
16]. The first method results, on average, more accurate than the second one in the SWE reconstruction, by showing no bias (0%) and a low mean absolute error (26%). Other successful examples of reconstructed SWE for basins in Sierra Nevada are shown by Girotto et al. [
17], Guan et al. [
18] and Rittger et al. [
19].
An accurate estimation of SWE from remotely sensed images represents a longstanding challenge. Satellite data in the visible bands may provide information about the presence or absence of snow cover [
20] but require cloud-free conditions. However, no indication on the total amount of the snow mass can be derived. Passive microwave (PM) instruments are able to estimate the brightness temperature naturally emitted from the Earth and can be used to estimate SWE. When snow covers the ground, microwave radiation transmitted through the snowpack is absorbed and scattered by snow grains by decreasing the measured radiation. A deeper snowpack includes a larger number of snow grains, which are the main responsible for signal attenuation. This inverse relationship between snow depth and temperature brightness is the basis of SWE retrieval from PM measurements [
21]. Vuyovich and Jacobs [
21] compared snow hydrology model results to remotely sensed data to determine if passive microwave estimates of SWE can be used to characterize the snowpack and estimate runoff from snowmelt in the Helmand River, in Afghanistan. Mizukami and Perica [
22] tried to identify SWE retrieval algorithms feasible for large-scale operational applications. In their study, Vuyovich et al. [
23] compared the daily AMSR-E and SSM/I SWE products over nine winter seasons with spatially distributed model output of the SNOw Data Assimilation System (SNODAS) at watershed scale (25 km of spatial resolution) for 2100 watersheds in the United States. Results show large areas where the passive microwave SWE products are highly correlated to the SNODAS data, except in heavily forested areas and regions with a deep snowpack, where passive microwave SWE is significantly underestimated with respect to SNODAS. The best correlation is associated with basins in which maximum annual SWE value is lower than 200 mm and forest fraction is less than 20%. Forest cover has been proven to be one of the most relevant sources of uncertainty in SWE retrieval with PM sensors by acting as a mask for the snowpack microwave emission [
24,
25]. Moreover, snow metamorphism affects the snowpack microwave emission by changing the crystal sizes, caused by temperature and water vapor gradients [
26,
27]. Finally, SWE estimation from PM sensors suffers from several issues related to the coarse spatial resolution of the sensors (~25 km): In mountain regions, indeed, the spatial variability of snow cover and snow properties over a 25-km grid is large due to topographic influences.
In the last decades, scientists have also extensively investigated the potential of Synthetic Aperture Radar (SAR) data for deriving SWE. Sun et al. [
28] used microwave scattering models to analyze the C-band SAR scattering characteristics of snow-covered areas and estimated the distribution of the SWE using SAR data and snow cover data measured in the field. Conde et al. [
29] presented a methodology for mapping the temporal variation of SWE through the SAR Interferometry technique and Sentinel-1 data.
Information about snow state variables can also be obtained from hydrological models. Many of the existing snowpack models are based on the same physical principles and solve the surface energy balance problem of a snowpack [
30]. The main difference among these models is related to the way they represent physical processes in the snowpack such as absorption of incoming radiation, advection and convection, and how they represent the internal structure of the snowpack. In a cross-comparison with 33 models, Rutter et al. [
30] found that the correlation of models’ performance between years is always stronger at the open sites than in the forest, suggesting that models are more robust at open sites.
The increasing complexity of snow-cover models demands high-quality forcing data. However, meteorological forcing data as provided by weather station recordings or atmospheric simulations suffer from several errors such as those induced by inaccuracy of the measurement, the regionalization scheme or boundary conditions. The process representations in deterministic, physically based snow models (which simulate physical processes in the snowpack) are an abstraction of reality, and hence inherently introduce uncertainty through simplification and the choice of parameter values. For fully distributed snow models, the spatial resolution is a compromise between computational feasibility and adequacy in mirroring the spatial scale of physical processes. Especially if the resolution (i.e., cell size) is much larger than the processes considered in the model, this choice is associated with uncertainty.
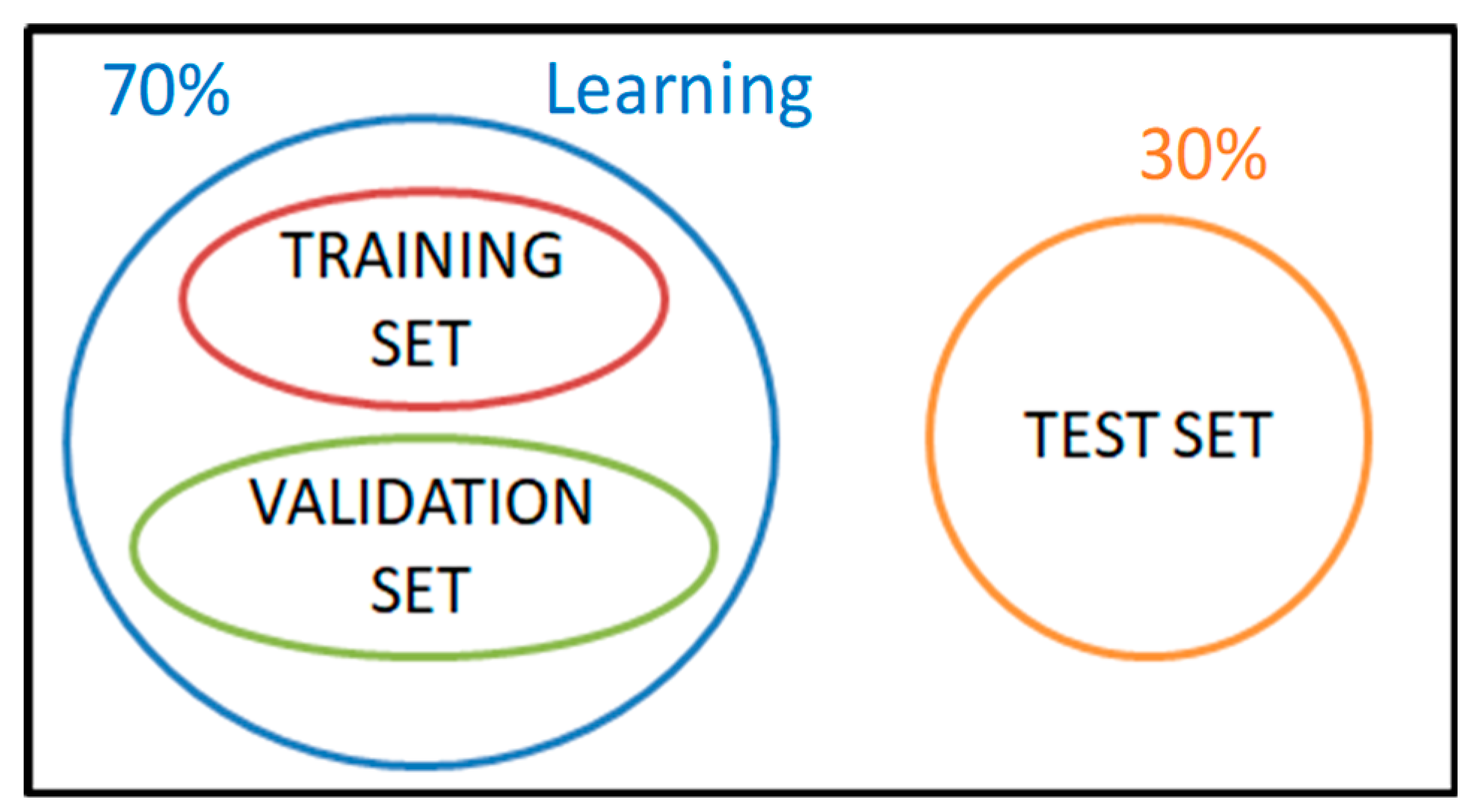
On the basis of this analysis, the main objective of this work is to generate a spatialized product of SWE over an Alpine area composed of Tyrol, South Tyrol and Trentino (Euregio region), by overcoming the aforementioned problems of hydrological models related to intrinsic uncertainty of the forcing data and correcting the spatial-temporal distribution of SWE as simulated by the snow model AMUNDSEN. The correction is performed using a specific k-NN algorithm and exploiting ground measurement-derived SWE data. The innovative aspect of our work is the joint use of snow model simulations, ground data, auxiliary products based on remote sensing and an advanced estimation technique to derive SWE. In this way our approach differs from traditional data assimilation techniques.
The paper is organized as follows:
Section 2 introduces the study area and, after a description of the dataset, the method for SWE retrieval is presented in the last part of the section results are then shown and discussed in
Section 3 and, finally, conclusions and future perspectives are drawn in
Section 4.
4. Conclusions
In this paper a new concept to improve the distributed estimation of snow water equivalent (SWE) is presented. The proposed method exploits a physically based model (AMUNDSEN), field observations, some topographic and auxiliary parameters and products from optical remote sensing for creating a time series of SWE maps for a region including Tyrol, South Tyrol and Trentino (Euregio area). Available ground reference samples are used for characterizing deviations of the snow model simulations affected, as any theoretical model, by uncertainties from approximations in the analytical formulation with respect to the observation. The hypothesis is that such deviations are varying depending on their location in the feature space. This behavior can be characterized by exploiting the properties of a specific k-Nearest Neighbor (k-NN) estimator, based on a “feature
Similarity” principle, to predict values of any new data point. Once the deviation is computed, it is added to the modelled SWE in order to obtain a corrected value.
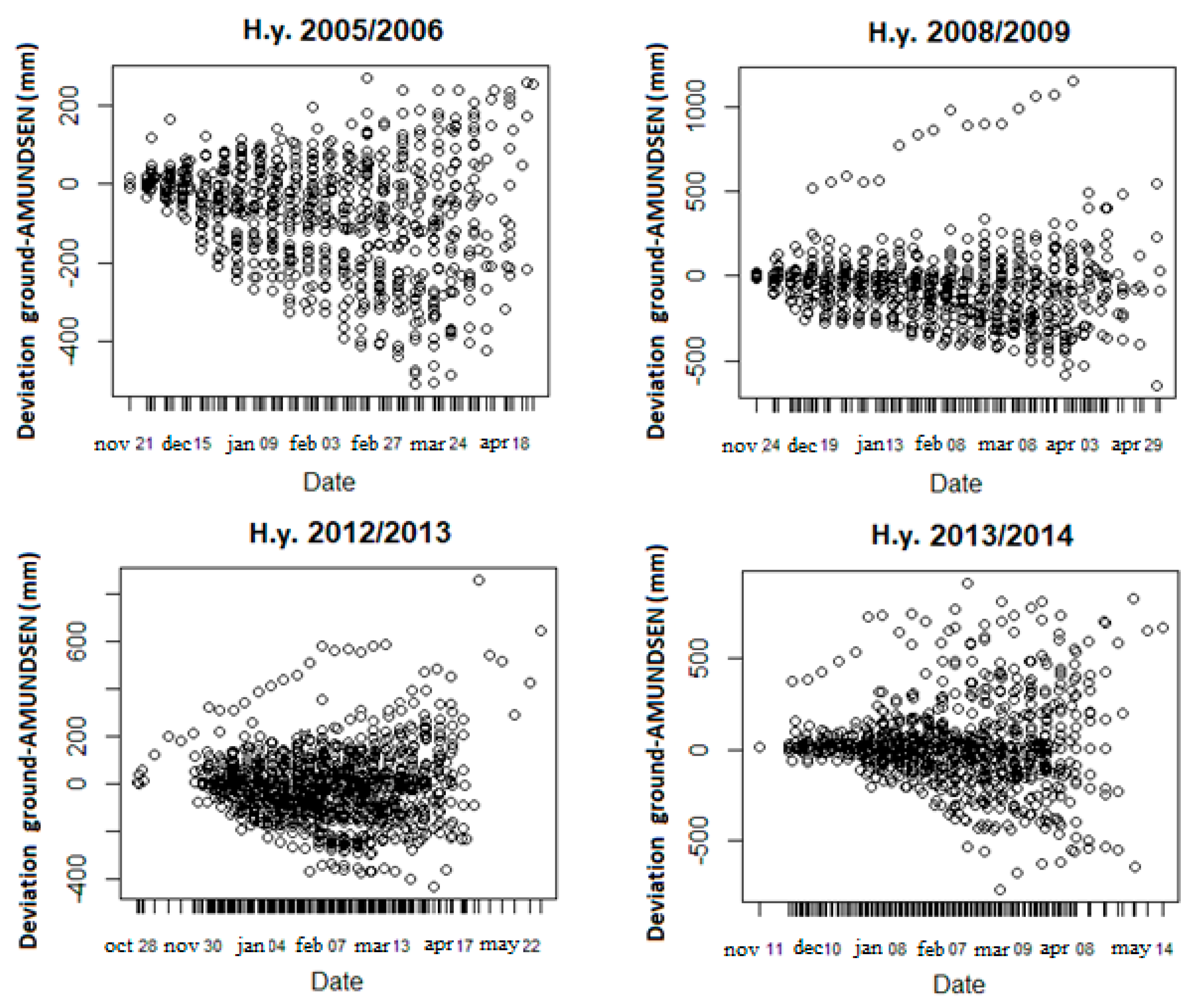
Obtained results are promising with a significant improvement of performance: the new method in our data decreased, on average, the RMSE and the MAE from 154 to 75 mm and from 99 to 45 mm, respectively compared to the AMUNDSEN simulations. Furthermore, the slope of the regression line between estimated SWE and ground observations increases from 0.6 to 0.9 by reducing the data spread and the number of outliers.
In the approach presented in this study, two aspects are critical: The feature selection and the amount of observation samples. In this work, the feature selection in this work was performed through a genetic algorithm, by considering several variables supposed to be related to SWE computation. Different products from optical remote sensing were included in the feature selection, such as snow cover duration, snow cover fraction, different reflectance bands and the land surface temperature. The latter was found to be the only product relevant in our analysis. In particular, we exploited the mean surface temperature and the number of positive-temperature days, both computed on the last 30 days with respect to the date of ground acquisition. Certainly, many other parameters from remote sensing could be tested, such as products from radar sensors that are sensitive to the water presence in the snowpack [
55]. A deeper and more extensive feature selection could for sure improve the results obtained.
Regarding the amount of ground observations, an improvement to the proposed approach could be achieved by increasing the dataset variability in the feature space. This could be done by acquiring, for example, ground measurements that are more differentiated in the feature space, such as different altitudes or different percentage of forest cover or slope.
We can conclude that the proposed approach effectively handles the variability of deviations between simulations and observations in the feature space and can be applied to other study areas and to other physically based snow models.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}